 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
360° Volumetric Portrait Avatar
Dec 08, 2023
We propose 360{\deg} Volumetric Portrait (3VP) Avatar, a novel method for reconstructing 360{\deg} photo-realistic portrait avatars of human subjects solely based on monocular video inputs. State-of-the-art monocular avatar reconstruction methods rely on stable facial performance capturing. However, the common usage of 3DMM-based facial tracking has its limits; side-views can hardly be captured and it fails, especially, for back-views, as required inputs like facial landmarks or human parsing masks are missing. This results in incomplete avatar reconstructions that only cover the frontal hemisphere. In contrast to this, we propose a template-based tracking of the torso, head and facial expressions which allows us to cover the appearance of a human subject from all sides. Thus, given a sequence of a subject that is rotating in front of a single camera, we train a neural volumetric representation based on neural radiance fields. A key challenge to construct this representation is the modeling of appearance changes, especially, in the mouth region (i.e., lips and teeth). We, therefore, propose a deformation-field-based blend basis which allows us to interpolate between different appearance states. We evaluate our approach on captured real-world data and compare against state-of-the-art monocular reconstruction methods. In contrast to those, our method is the first monocular technique that reconstructs an entire 360{\deg} avatar.
VectorTalker: SVG Talking Face Generation with Progressive Vectorisation
Dec 18, 2023High-fidelity and efficient audio-driven talking head generation has been a key research topic in computer graphics and computer vision. In this work, we study vector image based audio-driven talking head generation. Compared with directly animating the raster image that most widely used in existing works, vector image enjoys its excellent scalability being used for many applications. There are two main challenges for vector image based talking head generation: the high-quality vector image reconstruction w.r.t. the source portrait image and the vivid animation w.r.t. the audio signal. To address these, we propose a novel scalable vector graphic reconstruction and animation method, dubbed VectorTalker. Specifically, for the highfidelity reconstruction, VectorTalker hierarchically reconstructs the vector image in a coarse-to-fine manner. For the vivid audio-driven facial animation, we propose to use facial landmarks as intermediate motion representation and propose an efficient landmark-driven vector image deformation module. Our approach can handle various styles of portrait images within a unified framework, including Japanese manga, cartoon, and photorealistic images. We conduct extensive quantitative and qualitative evaluations and the experimental results demonstrate the superiority of VectorTalker in both vector graphic reconstruction and audio-driven animation.
Distribution Matching for Multi-Task Learning of Classification Tasks: a Large-Scale Study on Faces & Beyond
Jan 03, 2024Multi-Task Learning (MTL) is a framework, where multiple related tasks are learned jointly and benefit from a shared representation space, or parameter transfer. To provide sufficient learning support, modern MTL uses annotated data with full, or sufficiently large overlap across tasks, i.e., each input sample is annotated for all, or most of the tasks. However, collecting such annotations is prohibitive in many real applications, and cannot benefit from datasets available for individual tasks. In this work, we challenge this setup and show that MTL can be successful with classification tasks with little, or non-overlapping annotations, or when there is big discrepancy in the size of labeled data per task. We explore task-relatedness for co-annotation and co-training, and propose a novel approach, where knowledge exchange is enabled between the tasks via distribution matching. To demonstrate the general applicability of our method, we conducted diverse case studies in the domains of affective computing, face recognition, species recognition, and shopping item classification using nine datasets. Our large-scale study of affective tasks for basic expression recognition and facial action unit detection illustrates that our approach is network agnostic and brings large performance improvements compared to the state-of-the-art in both tasks and across all studied databases. In all case studies, we show that co-training via task-relatedness is advantageous and prevents negative transfer (which occurs when MT model's performance is worse than that of at least one single-task model).
DiffusionTalker: Personalization and Acceleration for Speech-Driven 3D Face Diffuser
Dec 02, 2023Speech-driven 3D facial animation has been an attractive task in both academia and industry. Traditional methods mostly focus on learning a deterministic mapping from speech to animation. Recent approaches start to consider the non-deterministic fact of speech-driven 3D face animation and employ the diffusion model for the task. However, personalizing facial animation and accelerating animation generation are still two major limitations of existing diffusion-based methods. To address the above limitations, we propose DiffusionTalker, a diffusion-based method that utilizes contrastive learning to personalize 3D facial animation and knowledge distillation to accelerate 3D animation generation. Specifically, to enable personalization, we introduce a learnable talking identity to aggregate knowledge in audio sequences. The proposed identity embeddings extract customized facial cues across different people in a contrastive learning manner. During inference, users can obtain personalized facial animation based on input audio, reflecting a specific talking style. With a trained diffusion model with hundreds of steps, we distill it into a lightweight model with 8 steps for acceleration. Extensive experiments are conducted to demonstrate that our method outperforms state-of-the-art methods. The code will be released.
Development of the Lifelike Head Unit for a Humanoid Cybernetic Avatar `Yui' and Its Operation Interface
Dec 11, 2023In the context of avatar-mediated communication, it is crucial for the face-to-face interlocutor to sense the operator's presence and emotions via the avatar. Although androids resembling humans have been developed to convey presence through appearance and movement, few studies have prioritized deepening the communication experience for both operator and interlocutor using android robot as an avatar. Addressing this gap, we introduce the ``Cybernetic Avatar `Yui','' featuring a human-like head unit with 28 degrees of freedom, capable of expressing gaze, facial emotions, and speech-related mouth movements. Through an eye-tracking unit in a Head-Mounted Display (HMD) and degrees of freedom on both eyes of Yui, operators can control the avatar's gaze naturally. Additionally, microphones embedded in Yui's ears allow operators to hear surrounding sounds in three dimensions, enabling them to discern the direction of calls based solely on auditory information. An HMD's face-tracking unit synchronizes the avatar's facial movements with those of the operator. This immersive interface, coupled with Yui's human-like appearance, enables real-time emotion transmission and communication, enhancing the sense of presence for both parties. Our experiments demonstrate Yui's facial expression capabilities, and validate the system's efficacy through teleoperation trials, suggesting potential advancements in avatar technology.
InFER: A Multi-Ethnic Indian Facial Expression Recognition Dataset
Sep 30, 2023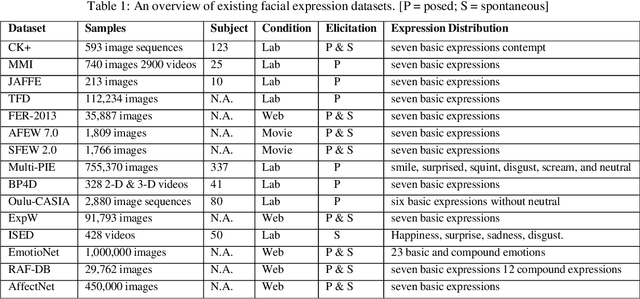
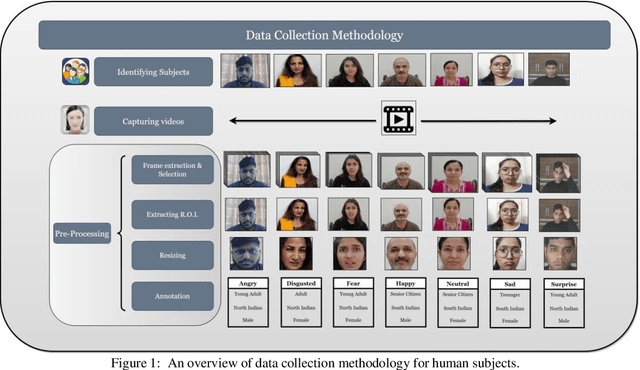
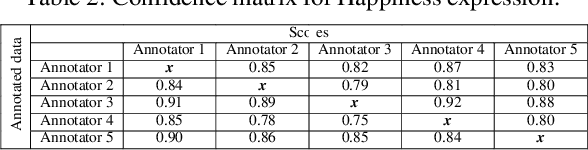

The rapid advancement in deep learning over the past decade has transformed Facial Expression Recognition (FER) systems, as newer methods have been proposed that outperform the existing traditional handcrafted techniques. However, such a supervised learning approach requires a sufficiently large training dataset covering all the possible scenarios. And since most people exhibit facial expressions based upon their age group, gender, and ethnicity, a diverse facial expression dataset is needed. This becomes even more crucial while developing a FER system for the Indian subcontinent, which comprises of a diverse multi-ethnic population. In this work, we present InFER, a real-world multi-ethnic Indian Facial Expression Recognition dataset consisting of 10,200 images and 4,200 short videos of seven basic facial expressions. The dataset has posed expressions of 600 human subjects, and spontaneous/acted expressions of 6000 images crowd-sourced from the internet. To the best of our knowledge InFER is the first of its kind consisting of images from 600 subjects from very diverse ethnicity of the Indian Subcontinent. We also present the experimental results of baseline & deep FER methods on our dataset to substantiate its usability in real-world practical applications.
* In Proceedings of the 15th International Conference on Agents and Artificial Intelligence Volume 3: ICAART; ISBN 978-989-758-623-1; ISSN 2184-433X, SciTePress, pages 550-557. DOI: 10.5220/0011699400003393
Facial Emotion Recognition in VR Games
Dec 12, 2023Emotion detection is a crucial component of Games User Research (GUR), as it allows game developers to gain insights into players' emotional experiences and tailor their games accordingly. However, detecting emotions in Virtual Reality (VR) games is challenging due to the Head-Mounted Display (HMD) that covers the top part of the player's face, namely, their eyes and eyebrows, which provide crucial information for recognizing the impression. To tackle this we used a Convolutional Neural Network (CNN) to train a model to predict emotions in full-face images where the eyes and eyebrows are covered. We used the FER2013 dataset, which we modified to cover eyes and eyebrows in images. The model in these images can accurately recognize seven different emotions which are anger, happiness, disgust, fear, impartiality, sadness and surprise. We assessed the model's performance by testing it on two VR games and using it to detect players' emotions. We collected self-reported emotion data from the players after the gameplay sessions. We analyzed the data collected from our experiment to understand which emotions players experience during the gameplay. We found that our approach has the potential to enhance gameplay analysis by enabling the detection of players' emotions in VR games, which can help game developers create more engaging and immersive game experiences.
Pain Analysis using Adaptive Hierarchical Spatiotemporal Dynamic Imaging
Dec 12, 2023Automatic pain intensity estimation plays a pivotal role in healthcare and medical fields. While many methods have been developed to gauge human pain using behavioral or physiological indicators, facial expressions have emerged as a prominent tool for this purpose. Nevertheless, the dependence on labeled data for these techniques often renders them expensive and time-consuming. To tackle this, we introduce the Adaptive Hierarchical Spatio-temporal Dynamic Image (AHDI) technique. AHDI encodes spatiotemporal changes in facial videos into a singular RGB image, permitting the application of simpler 2D deep models for video representation. Within this framework, we employ a residual network to derive generalized facial representations. These representations are optimized for two tasks: estimating pain intensity and differentiating between genuine and simulated pain expressions. For the former, a regression model is trained using the extracted representations, while for the latter, a binary classifier identifies genuine versus feigned pain displays. Testing our method on two widely-used pain datasets, we observed encouraging results for both tasks. On the UNBC database, we achieved an MSE of 0.27 outperforming the SOTA which had an MSE of 0.40. On the BioVid dataset, our model achieved an accuracy of 89.76%, which is an improvement of 5.37% over the SOTA accuracy. Most notably, for distinguishing genuine from simulated pain, our accuracy stands at 94.03%, marking a substantial improvement of 8.98%. Our methodology not only minimizes the need for extensive labeled data but also augments the precision of pain evaluations, facilitating superior pain management.
Towards Machine Unlearning Benchmarks: Forgetting the Personal Identities in Facial Recognition Systems
Nov 03, 2023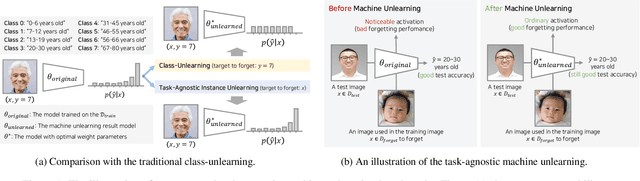

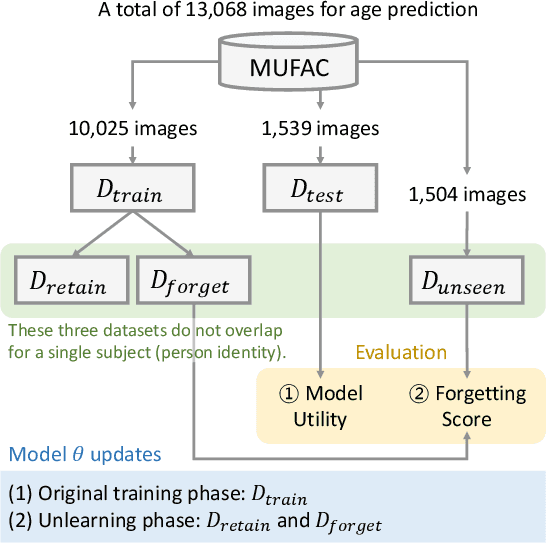

Machine unlearning is a crucial tool for enabling a classification model to forget specific data that are used in the training time. Recently, various studies have presented machine unlearning algorithms and evaluated their methods on several datasets. However, most of the current machine unlearning algorithms have been evaluated solely on traditional computer vision datasets such as CIFAR-10, MNIST, and SVHN. Furthermore, previous studies generally evaluate the unlearning methods in the class-unlearning setup. Most previous work first trains the classification models and then evaluates the machine unlearning performance of machine unlearning algorithms by forgetting selected image classes (categories) in the experiments. Unfortunately, these class-unlearning settings might not generalize to real-world scenarios. In this work, we propose a machine unlearning setting that aims to unlearn specific instance that contains personal privacy (identity) while maintaining the original task of a given model. Specifically, we propose two machine unlearning benchmark datasets, MUFAC and MUCAC, that are greatly useful to evaluate the performance and robustness of a machine unlearning algorithm. In our benchmark datasets, the original model performs facial feature recognition tasks: face age estimation (multi-class classification) and facial attribute classification (binary class classification), where a class does not depend on any single target subject (personal identity), which can be a realistic setting. Moreover, we also report the performance of the state-of-the-art machine unlearning methods on our proposed benchmark datasets. All the datasets, source codes, and trained models are publicly available at https://github.com/ndb796/MachineUnlearning.
ImFace++: A Sophisticated Nonlinear 3D Morphable Face Model with Implicit Neural Representations
Dec 07, 2023Accurate representations of 3D faces are of paramount importance in various computer vision and graphics applications. However, the challenges persist due to the limitations imposed by data discretization and model linearity, which hinder the precise capture of identity and expression clues in current studies. This paper presents a novel 3D morphable face model, named ImFace++, to learn a sophisticated and continuous space with implicit neural representations. ImFace++ first constructs two explicitly disentangled deformation fields to model complex shapes associated with identities and expressions, respectively, which simultaneously facilitate the automatic learning of correspondences across diverse facial shapes. To capture more sophisticated facial details, a refinement displacement field within the template space is further incorporated, enabling a fine-grained learning of individual-specific facial details. Furthermore, a Neural Blend-Field is designed to reinforce the representation capabilities through adaptive blending of an array of local fields. In addition to ImFace++, we have devised an improved learning strategy to extend expression embeddings, allowing for a broader range of expression variations. Comprehensive qualitative and quantitative evaluations demonstrate that ImFace++ significantly advances the state-of-the-art in terms of both face reconstruction fidelity and correspondence accuracy.