 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
From Covert Hiding to Visual Editing: Robust Generative Video Steganography
Jan 01, 2024
Traditional video steganography methods are based on modifying the covert space for embedding, whereas we propose an innovative approach that embeds secret message within semantic feature for steganography during the video editing process. Although existing traditional video steganography methods display a certain level of security and embedding capacity, they lack adequate robustness against common distortions in online social networks (OSNs). In this paper, we introduce an end-to-end robust generative video steganography network (RoGVS), which achieves visual editing by modifying semantic feature of videos to embed secret message. We employ face-swapping scenario to showcase the visual editing effects. We first design a secret message embedding module to adaptively hide secret message into the semantic feature of videos. Extensive experiments display that the proposed RoGVS method applied to facial video datasets demonstrate its superiority over existing video and image steganography techniques in terms of both robustness and capacity.
Individualized Deepfake Detection Exploiting Traces Due to Double Neural-Network Operations
Dec 13, 2023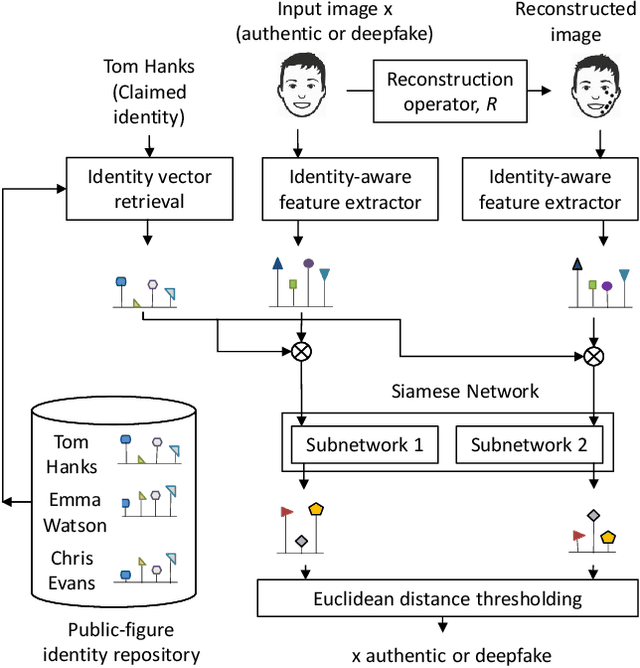
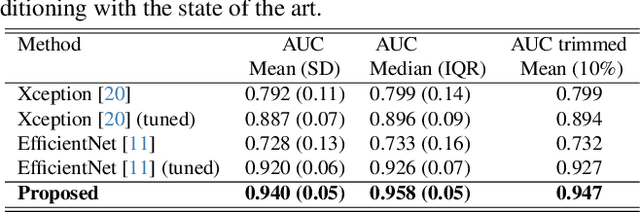
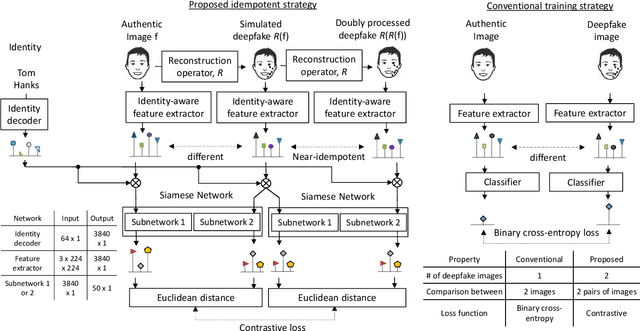
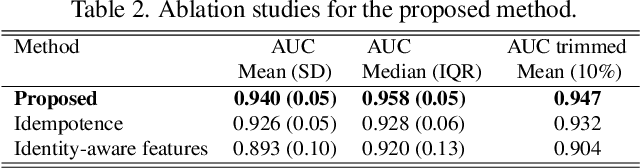
In today's digital landscape, journalists urgently require tools to verify the authenticity of facial images and videos depicting specific public figures before incorporating them into news stories. Existing deepfake detectors are not optimized for this detection task when an image is associated with a specific and identifiable individual. This study focuses on the deepfake detection of facial images of individual public figures. We propose to condition the proposed detector on the identity of the identified individual given the advantages revealed by our theory-driven simulations. While most detectors in the literature rely on perceptible or imperceptible artifacts present in deepfake facial images, we demonstrate that the detection performance can be improved by exploiting the idempotency property of neural networks. In our approach, the training process involves double neural-network operations where we pass an authentic image through a deepfake simulating network twice. Experimental results show that the proposed method improves the area under the curve (AUC) from 0.92 to 0.94 and reduces its standard deviation by 17\%. For evaluating the detection performance of individual public figures, a facial image dataset with individuals' names is required, a criterion not met by the current deepfake datasets. To address this, we curated a dataset comprising 32k images featuring 45 public figures, which we intend to release to the public after the paper is published.
Hyper-Skin: A Hyperspectral Dataset for Reconstructing Facial Skin-Spectra from RGB Images
Oct 27, 2023We introduce Hyper-Skin, a hyperspectral dataset covering wide range of wavelengths from visible (VIS) spectrum (400nm - 700nm) to near-infrared (NIR) spectrum (700nm - 1000nm), uniquely designed to facilitate research on facial skin-spectra reconstruction. By reconstructing skin spectra from RGB images, our dataset enables the study of hyperspectral skin analysis, such as melanin and hemoglobin concentrations, directly on the consumer device. Overcoming limitations of existing datasets, Hyper-Skin consists of diverse facial skin data collected with a pushbroom hyperspectral camera. With 330 hyperspectral cubes from 51 subjects, the dataset covers the facial skin from different angles and facial poses. Each hyperspectral cube has dimensions of 1024$\times$1024$\times$448, resulting in millions of spectra vectors per image. The dataset, carefully curated in adherence to ethical guidelines, includes paired hyperspectral images and synthetic RGB images generated using real camera responses. We demonstrate the efficacy of our dataset by showcasing skin spectra reconstruction using state-of-the-art models on 31 bands of hyperspectral data resampled in the VIS and NIR spectrum. This Hyper-Skin dataset would be a valuable resource to NeurIPS community, encouraging the development of novel algorithms for skin spectral reconstruction while fostering interdisciplinary collaboration in hyperspectral skin analysis related to cosmetology and skin's well-being. Instructions to request the data and the related benchmarking codes are publicly available at: \url{https://github.com/hyperspectral-skin/Hyper-Skin-2023}.
Exploration of Adolescent Depression Risk Prediction Based on Census Surveys and General Life Issues
Jan 06, 2024In contemporary society, the escalating pressures of life and work have propelled psychological disorders to the forefront of modern health concerns, an issue that has been further accentuated by the COVID-19 pandemic. The prevalence of depression among adolescents is steadily increasing, and traditional diagnostic methods, which rely on scales or interviews, prove particularly inadequate for detecting depression in young people. Addressing these challenges, numerous AI-based methods for assisting in the diagnosis of mental health issues have emerged. However, most of these methods center around fundamental issues with scales or use multimodal approaches like facial expression recognition. Diagnosis of depression risk based on everyday habits and behaviors has been limited to small-scale qualitative studies. Our research leverages adolescent census data to predict depression risk, focusing on children's experiences with depression and their daily life situations. We introduced a method for managing severely imbalanced high-dimensional data and an adaptive predictive approach tailored to data structure characteristics. Furthermore, we proposed a cloud-based architecture for automatic online learning and data updates. This study utilized publicly available NSCH youth census data from 2020 to 2022, encompassing nearly 150,000 data entries. We conducted basic data analyses and predictive experiments, demonstrating significant performance improvements over standard machine learning and deep learning algorithms. This affirmed our data processing method's broad applicability in handling imbalanced medical data. Diverging from typical predictive method research, our study presents a comprehensive architectural solution, considering a wider array of user needs.
Benchmarking Deep Facial Expression Recognition: An Extensive Protocol with Balanced Dataset in the Wild
Nov 06, 2023Facial expression recognition (FER) is a crucial part of human-computer interaction. Existing FER methods achieve high accuracy and generalization based on different open-source deep models and training approaches. However, the performance of these methods is not always good when encountering practical settings, which are seldom explored. In this paper, we collected a new in-the-wild facial expression dataset for cross-domain validation. Twenty-three commonly used network architectures were implemented and evaluated following a uniform protocol. Moreover, various setups, in terms of input resolutions, class balance management, and pre-trained strategies, were verified to show the corresponding performance contribution. Based on extensive experiments on three large-scale FER datasets and our practical cross-validation, we ranked network architectures and summarized a set of recommendations on deploying deep FER methods in real scenarios. In addition, potential ethical rules, privacy issues, and regulations were discussed in practical FER applications such as marketing, education, and entertainment business.
Low-cost Geometry-based Eye Gaze Detection using Facial Landmarks Generated through Deep Learning
Dec 31, 2023Introduction: In the realm of human-computer interaction and behavioral research, accurate real-time gaze estimation is critical. Traditional methods often rely on expensive equipment or large datasets, which are impractical in many scenarios. This paper introduces a novel, geometry-based approach to address these challenges, utilizing consumer-grade hardware for broader applicability. Methods: We leverage novel face landmark detection neural networks capable of fast inference on consumer-grade chips to generate accurate and stable 3D landmarks of the face and iris. From these, we derive a small set of geometry-based descriptors, forming an 8-dimensional manifold representing the eye and head movements. These descriptors are then used to formulate linear equations for predicting eye-gaze direction. Results: Our approach demonstrates the ability to predict gaze with an angular error of less than 1.9 degrees, rivaling state-of-the-art systems while operating in real-time and requiring negligible computational resources. Conclusion: The developed method marks a significant step forward in gaze estimation technology, offering a highly accurate, efficient, and accessible alternative to traditional systems. It opens up new possibilities for real-time applications in diverse fields, from gaming to psychological research.
Gaussian Harmony: Attaining Fairness in Diffusion-based Face Generation Models
Dec 21, 2023Diffusion models have achieved great progress in face generation. However, these models amplify the bias in the generation process, leading to an imbalance in distribution of sensitive attributes such as age, gender and race. This paper proposes a novel solution to this problem by balancing the facial attributes of the generated images. We mitigate the bias by localizing the means of the facial attributes in the latent space of the diffusion model using Gaussian mixture models (GMM). Our motivation for choosing GMMs over other clustering frameworks comes from the flexible latent structure of diffusion model. Since each sampling step in diffusion models follows a Gaussian distribution, we show that fitting a GMM model helps us to localize the subspace responsible for generating a specific attribute. Furthermore, our method does not require retraining, we instead localize the subspace on-the-fly and mitigate the bias for generating a fair dataset. We evaluate our approach on multiple face attribute datasets to demonstrate the effectiveness of our approach. Our results demonstrate that our approach leads to a more fair data generation in terms of representational fairness while preserving the quality of generated samples.
Exploring 3D-aware Lifespan Face Aging via Disentangled Shape-Texture Representations
Dec 28, 2023Existing face aging methods often focus on modeling either texture aging or using an entangled shape-texture representation to achieve face aging. However, shape and texture are two distinct factors that mutually affect the human face aging process. In this paper, we propose 3D-STD, a novel 3D-aware Shape-Texture Disentangled face aging network that explicitly disentangles the facial image into shape and texture representations using 3D face reconstruction. Additionally, to facilitate high-fidelity texture synthesis, we propose a novel texture generation method based on Empirical Mode Decomposition (EMD). Extensive qualitative and quantitative experiments show that our method achieves state-of-the-art performance in terms of shape and texture transformation. Moreover, our method supports producing plausible 3D face aging results, which is rarely accomplished by current methods.
Cross-Age Contrastive Learning for Age-Invariant Face Recognition
Dec 18, 2023Cross-age facial images are typically challenging and expensive to collect, making noise-free age-oriented datasets relatively small compared to widely-used large-scale facial datasets. Additionally, in real scenarios, images of the same subject at different ages are usually hard or even impossible to obtain. Both of these factors lead to a lack of supervised data, which limits the versatility of supervised methods for age-invariant face recognition, a critical task in applications such as security and biometrics. To address this issue, we propose a novel semi-supervised learning approach named Cross-Age Contrastive Learning (CACon). Thanks to the identity-preserving power of recent face synthesis models, CACon introduces a new contrastive learning method that leverages an additional synthesized sample from the input image. We also propose a new loss function in association with CACon to perform contrastive learning on a triplet of samples. We demonstrate that our method not only achieves state-of-the-art performance in homogeneous-dataset experiments on several age-invariant face recognition benchmarks but also outperforms other methods by a large margin in cross-dataset experiments.
Anatomically Constrained Implicit Face Models
Dec 12, 2023Coordinate based implicit neural representations have gained rapid popularity in recent years as they have been successfully used in image, geometry and scene modeling tasks. In this work, we present a novel use case for such implicit representations in the context of learning anatomically constrained face models. Actor specific anatomically constrained face models are the state of the art in both facial performance capture and performance retargeting. Despite their practical success, these anatomical models are slow to evaluate and often require extensive data capture to be built. We propose the anatomical implicit face model; an ensemble of implicit neural networks that jointly learn to model the facial anatomy and the skin surface with high-fidelity, and can readily be used as a drop in replacement to conventional blendshape models. Given an arbitrary set of skin surface meshes of an actor and only a neutral shape with estimated skull and jaw bones, our method can recover a dense anatomical substructure which constrains every point on the facial surface. We demonstrate the usefulness of our approach in several tasks ranging from shape fitting, shape editing, and performance retargeting.