 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
EmoTalker: Emotionally Editable Talking Face Generation via Diffusion Model
Jan 16, 2024
In recent years, the field of talking faces generation has attracted considerable attention, with certain methods adept at generating virtual faces that convincingly imitate human expressions. However, existing methods face challenges related to limited generalization, particularly when dealing with challenging identities. Furthermore, methods for editing expressions are often confined to a singular emotion, failing to adapt to intricate emotions. To overcome these challenges, this paper proposes EmoTalker, an emotionally editable portraits animation approach based on the diffusion model. EmoTalker modifies the denoising process to ensure preservation of the original portrait's identity during inference. To enhance emotion comprehension from text input, Emotion Intensity Block is introduced to analyze fine-grained emotions and strengths derived from prompts. Additionally, a crafted dataset is harnessed to enhance emotion comprehension within prompts. Experiments show the effectiveness of EmoTalker in generating high-quality, emotionally customizable facial expressions.
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer
Nov 18, 2023In this work, we propose MagicDance, a diffusion-based model for 2D human motion and facial expression transfer on challenging human dance videos. Specifically, we aim to generate human dance videos of any target identity driven by novel pose sequences while keeping the identity unchanged. To this end, we propose a two-stage training strategy to disentangle human motions and appearance (e.g., facial expressions, skin tone and dressing), consisting of the pretraining of an appearance-control block and fine-tuning of an appearance-pose-joint-control block over human dance poses of the same dataset. Our novel design enables robust appearance control with temporally consistent upper body, facial attributes, and even background. The model also generalizes well on unseen human identities and complex motion sequences without the need for any fine-tuning with additional data with diverse human attributes by leveraging the prior knowledge of image diffusion models. Moreover, the proposed model is easy to use and can be considered as a plug-in module/extension to Stable Diffusion. We also demonstrate the model's ability for zero-shot 2D animation generation, enabling not only the appearance transfer from one identity to another but also allowing for cartoon-like stylization given only pose inputs. Extensive experiments demonstrate our superior performance on the TikTok dataset.
GPAvatar: Generalizable and Precise Head Avatar from Image(s)
Jan 18, 2024Head avatar reconstruction, crucial for applications in virtual reality, online meetings, gaming, and film industries, has garnered substantial attention within the computer vision community. The fundamental objective of this field is to faithfully recreate the head avatar and precisely control expressions and postures. Existing methods, categorized into 2D-based warping, mesh-based, and neural rendering approaches, present challenges in maintaining multi-view consistency, incorporating non-facial information, and generalizing to new identities. In this paper, we propose a framework named GPAvatar that reconstructs 3D head avatars from one or several images in a single forward pass. The key idea of this work is to introduce a dynamic point-based expression field driven by a point cloud to precisely and effectively capture expressions. Furthermore, we use a Multi Tri-planes Attention (MTA) fusion module in the tri-planes canonical field to leverage information from multiple input images. The proposed method achieves faithful identity reconstruction, precise expression control, and multi-view consistency, demonstrating promising results for free-viewpoint rendering and novel view synthesis.
Contrastive Learning of View-Invariant Representations for Facial Expressions Recognition
Nov 12, 2023Although there has been much progress in the area of facial expression recognition (FER), most existing methods suffer when presented with images that have been captured from viewing angles that are non-frontal and substantially different from those used in the training process. In this paper, we propose ViewFX, a novel view-invariant FER framework based on contrastive learning, capable of accurately classifying facial expressions regardless of the input viewing angles during inference. ViewFX learns view-invariant features of expression using a proposed self-supervised contrastive loss which brings together different views of the same subject with a particular expression in the embedding space. We also introduce a supervised contrastive loss to push the learnt view-invariant features of each expression away from other expressions. Since facial expressions are often distinguished with very subtle differences in the learned feature space, we incorporate the Barlow twins loss to reduce the redundancy and correlations of the representations in the learned representations. The proposed method is a substantial extension of our previously proposed CL-MEx, which only had a self-supervised loss. We test the proposed framework on two public multi-view facial expression recognition datasets, KDEF and DDCF. The experiments demonstrate that our approach outperforms previous works in the area and sets a new state-of-the-art for both datasets while showing considerably less sensitivity to challenging angles and the number of output labels used for training. We also perform detailed sensitivity and ablation experiments to evaluate the impact of different components of our model as well as its sensitivity to different parameters.
Subject-Based Domain Adaptation for Facial Expression Recognition
Dec 09, 2023Adapting a deep learning (DL) model to a specific target individual is a challenging task in facial expression recognition (FER) that may be achieved using unsupervised domain adaptation (UDA) methods. Although several UDA methods have been proposed to adapt deep FER models across source and target data sets, multiple subject-specific source domains are needed to accurately represent the intra- and inter-person variability in subject-based adaption. In this paper, we consider the setting where domains correspond to individuals, not entire datasets. Unlike UDA, multi-source domain adaptation (MSDA) methods can leverage multiple source datasets to improve the accuracy and robustness of the target model. However, previous methods for MSDA adapt image classification models across datasets and do not scale well to a larger number of source domains. In this paper, a new MSDA method is introduced for subject-based domain adaptation in FER. It efficiently leverages information from multiple source subjects (labeled source domain data) to adapt a deep FER model to a single target individual (unlabeled target domain data). During adaptation, our Subject-based MSDA first computes a between-source discrepancy loss to mitigate the domain shift among data from several source subjects. Then, a new strategy is employed to generate augmented confident pseudo-labels for the target subject, allowing a reduction in the domain shift between source and target subjects. Experiments\footnote{\textcolor{red}{\textbf{Supplementary material} contains our code, which will be made public, and additional experimental results.}} on the challenging BioVid heat and pain dataset (PartA) with 87 subjects shows that our Subject-based MSDA can outperform state-of-the-art methods yet scale well to multiple subject-based source domains.
DualTalker: A Cross-Modal Dual Learning Approach for Speech-Driven 3D Facial Animation
Nov 08, 2023In recent years, audio-driven 3D facial animation has gained significant attention, particularly in applications such as virtual reality, gaming, and video conferencing. However, accurately modeling the intricate and subtle dynamics of facial expressions remains a challenge. Most existing studies approach the facial animation task as a single regression problem, which often fail to capture the intrinsic inter-modal relationship between speech signals and 3D facial animation and overlook their inherent consistency. Moreover, due to the limited availability of 3D-audio-visual datasets, approaches learning with small-size samples have poor generalizability that decreases the performance. To address these issues, in this study, we propose a cross-modal dual-learning framework, termed DualTalker, aiming at improving data usage efficiency as well as relating cross-modal dependencies. The framework is trained jointly with the primary task (audio-driven facial animation) and its dual task (lip reading) and shares common audio/motion encoder components. Our joint training framework facilitates more efficient data usage by leveraging information from both tasks and explicitly capitalizing on the complementary relationship between facial motion and audio to improve performance. Furthermore, we introduce an auxiliary cross-modal consistency loss to mitigate the potential over-smoothing underlying the cross-modal complementary representations, enhancing the mapping of subtle facial expression dynamics. Through extensive experiments and a perceptual user study conducted on the VOCA and BIWI datasets, we demonstrate that our approach outperforms current state-of-the-art methods both qualitatively and quantitatively. We have made our code and video demonstrations available at https://github.com/sabrina-su/iadf.git.
AdaMesh: Personalized Facial Expressions and Head Poses for Speech-Driven 3D Facial Animation
Oct 11, 2023
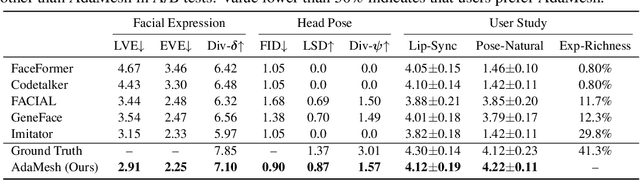
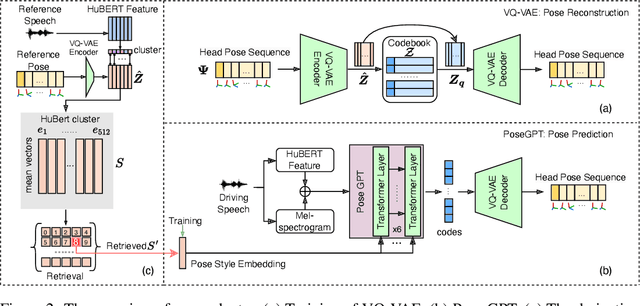

Speech-driven 3D facial animation aims at generating facial movements that are synchronized with the driving speech, which has been widely explored recently. Existing works mostly neglect the person-specific talking style in generation, including facial expression and head pose styles. Several works intend to capture the personalities by fine-tuning modules. However, limited training data leads to the lack of vividness. In this work, we propose AdaMesh, a novel adaptive speech-driven facial animation approach, which learns the personalized talking style from a reference video of about 10 seconds and generates vivid facial expressions and head poses. Specifically, we propose mixture-of-low-rank adaptation (MoLoRA) to fine-tune the expression adapter, which efficiently captures the facial expression style. For the personalized pose style, we propose a pose adapter by building a discrete pose prior and retrieving the appropriate style embedding with a semantic-aware pose style matrix without fine-tuning. Extensive experimental results show that our approach outperforms state-of-the-art methods, preserves the talking style in the reference video, and generates vivid facial animation. The supplementary video and code will be available at https://adamesh.github.io.
UltrAvatar: A Realistic Animatable 3D Avatar Diffusion Model with Authenticity Guided Textures
Jan 20, 2024Recent advances in 3D avatar generation have gained significant attentions. These breakthroughs aim to produce more realistic animatable avatars, narrowing the gap between virtual and real-world experiences. Most of existing works employ Score Distillation Sampling (SDS) loss, combined with a differentiable renderer and text condition, to guide a diffusion model in generating 3D avatars. However, SDS often generates oversmoothed results with few facial details, thereby lacking the diversity compared with ancestral sampling. On the other hand, other works generate 3D avatar from a single image, where the challenges of unwanted lighting effects, perspective views, and inferior image quality make them difficult to reliably reconstruct the 3D face meshes with the aligned complete textures. In this paper, we propose a novel 3D avatar generation approach termed UltrAvatar with enhanced fidelity of geometry, and superior quality of physically based rendering (PBR) textures without unwanted lighting. To this end, the proposed approach presents a diffuse color extraction model and an authenticity guided texture diffusion model. The former removes the unwanted lighting effects to reveal true diffuse colors so that the generated avatars can be rendered under various lighting conditions. The latter follows two gradient-based guidances for generating PBR textures to render diverse face-identity features and details better aligning with 3D mesh geometry. We demonstrate the effectiveness and robustness of the proposed method, outperforming the state-of-the-art methods by a large margin in the experiments.
1DFormer: Learning 1D Landmark Representations via Transformer for Facial Landmark Tracking
Nov 01, 2023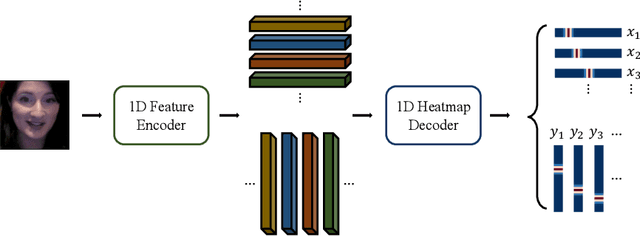
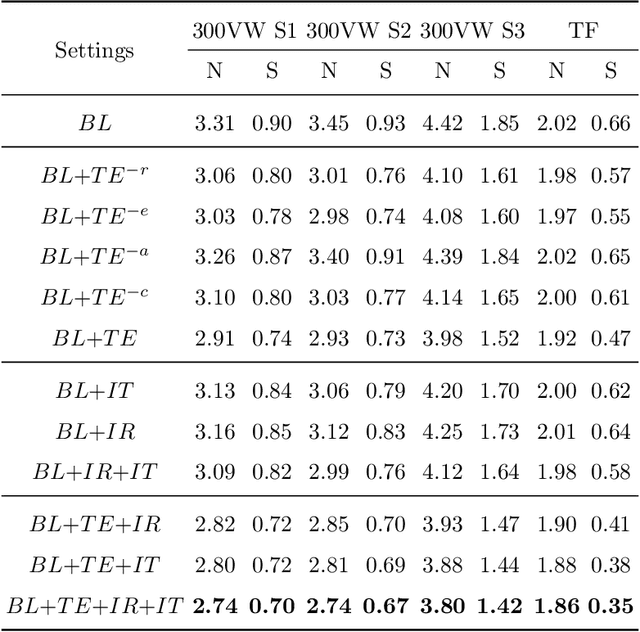
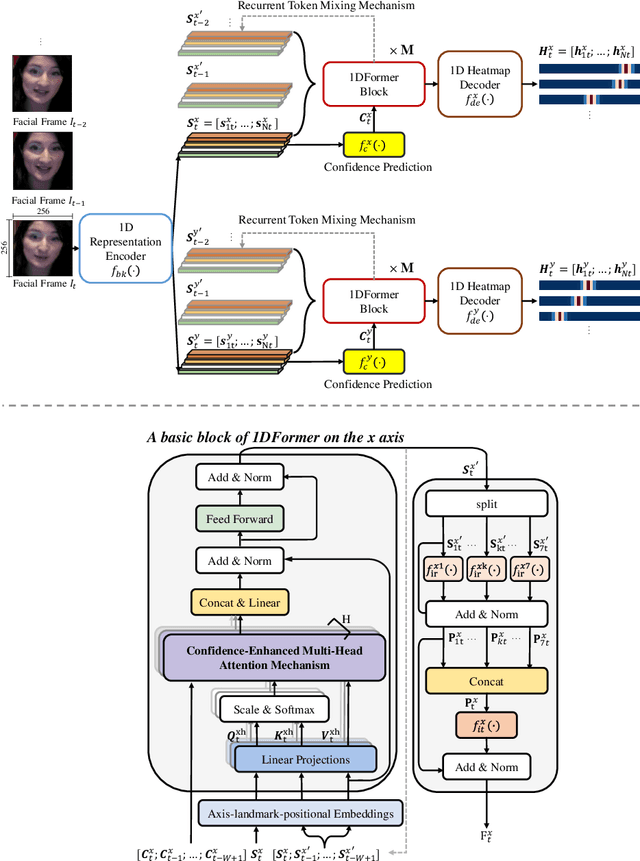
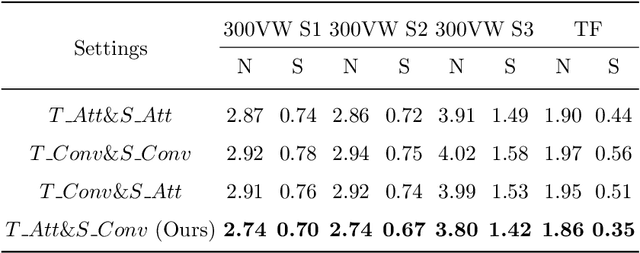
Recently, heatmap regression methods based on 1D landmark representations have shown prominent performance on locating facial landmarks. However, previous methods ignored to make deep explorations on the good potentials of 1D landmark representations for sequential and structural modeling of multiple landmarks to track facial landmarks. To address this limitation, we propose a Transformer architecture, namely 1DFormer, which learns informative 1D landmark representations by capturing the dynamic and the geometric patterns of landmarks via token communications in both temporal and spatial dimensions for facial landmark tracking. For temporal modeling, we propose a recurrent token mixing mechanism, an axis-landmark-positional embedding mechanism, as well as a confidence-enhanced multi-head attention mechanism to adaptively and robustly embed long-term landmark dynamics into their 1D representations; for structure modeling, we design intra-group and inter-group structure modeling mechanisms to encode the component-level as well as global-level facial structure patterns as a refinement for the 1D representations of landmarks through token communications in the spatial dimension via 1D convolutional layers. Experimental results on the 300VW and the TF databases show that 1DFormer successfully models the long-range sequential patterns as well as the inherent facial structures to learn informative 1D representations of landmark sequences, and achieves state-of-the-art performance on facial landmark tracking.
EFHQ: Multi-purpose ExtremePose-Face-HQ dataset
Dec 30, 2023The existing facial datasets, while having plentiful images at near frontal views, lack images with extreme head poses, leading to the downgraded performance of deep learning models when dealing with profile or pitched faces. This work aims to address this gap by introducing a novel dataset named Extreme Pose Face High-Quality Dataset (EFHQ), which includes a maximum of 450k high-quality images of faces at extreme poses. To produce such a massive dataset, we utilize a novel and meticulous dataset processing pipeline to curate two publicly available datasets, VFHQ and CelebV-HQ, which contain many high-resolution face videos captured in various settings. Our dataset can complement existing datasets on various facial-related tasks, such as facial synthesis with 2D/3D-aware GAN, diffusion-based text-to-image face generation, and face reenactment. Specifically, training with EFHQ helps models generalize well across diverse poses, significantly improving performance in scenarios involving extreme views, confirmed by extensive experiments. Additionally, we utilize EFHQ to define a challenging cross-view face verification benchmark, in which the performance of SOTA face recognition models drops 5-37% compared to frontal-to-frontal scenarios, aiming to stimulate studies on face recognition under severe pose conditions in the wild.