 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Multi-Scale Spatio-Temporal Graph Convolutional Network for Facial Expression Spotting
Mar 24, 2024
Facial expression spotting is a significant but challenging task in facial expression analysis. The accuracy of expression spotting is affected not only by irrelevant facial movements but also by the difficulty of perceiving subtle motions in micro-expressions. In this paper, we propose a Multi-Scale Spatio-Temporal Graph Convolutional Network (SpoT-GCN) for facial expression spotting. To extract more robust motion features, we track both short- and long-term motion of facial muscles in compact sliding windows whose window length adapts to the temporal receptive field of the network. This strategy, termed the receptive field adaptive sliding window strategy, effectively magnifies the motion features while alleviating the problem of severe head movement. The subtle motion features are then converted to a facial graph representation, whose spatio-temporal graph patterns are learned by a graph convolutional network. This network learns both local and global features from multiple scales of facial graph structures using our proposed facial local graph pooling (FLGP). Furthermore, we introduce supervised contrastive learning to enhance the discriminative capability of our model for difficult-to-classify frames. The experimental results on the SAMM-LV and CAS(ME)^2 datasets demonstrate that our method achieves state-of-the-art performance, particularly in micro-expression spotting. Ablation studies further verify the effectiveness of our proposed modules.
Emotic Masked Autoencoder with Attention Fusion for Facial Expression Recognition
Mar 26, 2024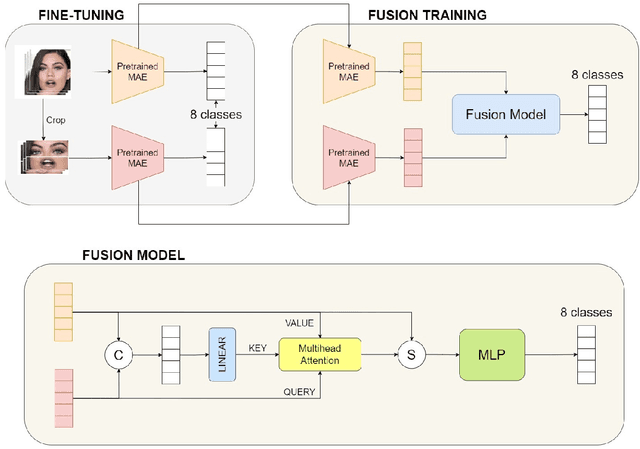

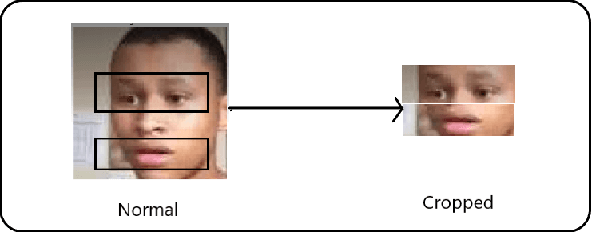
Facial Expression Recognition (FER) is a critical task within computer vision with diverse applications across various domains. Addressing the challenge of limited FER datasets, which hampers the generalization capability of expression recognition models, is imperative for enhancing performance. Our paper presents an innovative approach integrating the MAE-Face self-supervised learning (SSL) method and Fusion Attention mechanism for expression classification, particularly showcased in the 6th Affective Behavior 32 pages harvmac; added references for section 5Analysis in-the-wild (ABAW) competition. Additionally, we propose preprocessing techniques to emphasize essential facial features, thereby enhancing model performance on both training and validation sets, notably demonstrated on the Aff-wild2 dataset.
SeFFeC: Semantic Facial Feature Control for Fine-grained Face Editing
Mar 20, 2024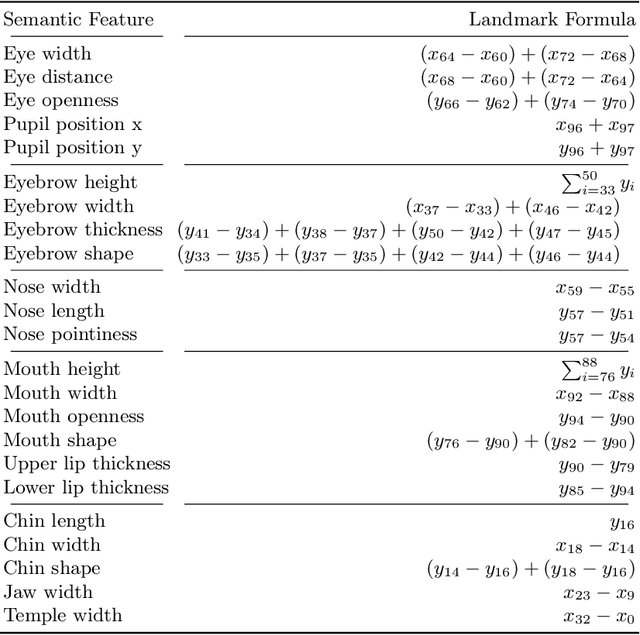
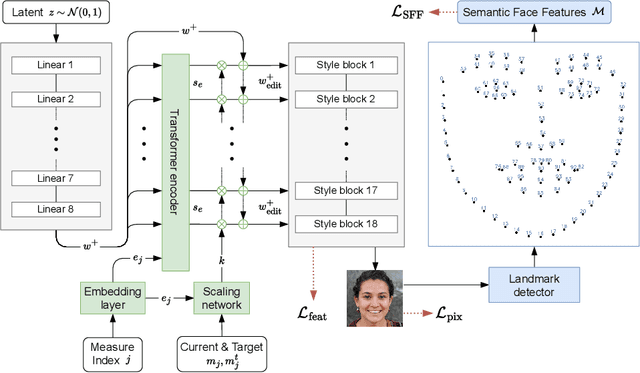


We propose Semantic Facial Feature Control (SeFFeC) - a novel method for fine-grained face shape editing. Our method enables the manipulation of human-understandable, semantic face features, such as nose length or mouth width, which are defined by different groups of facial landmarks. In contrast to existing methods, the use of facial landmarks enables precise measurement of the facial features, which then enables training SeFFeC without any manually annotated labels. SeFFeC consists of a transformer-based encoder network that takes a latent vector of a pre-trained generative model and a facial feature embedding as input, and learns to modify the latent vector to perform the desired face edit operation. To ensure that the desired feature measurement is changed towards the target value without altering uncorrelated features, we introduced a novel semantic face feature loss. Qualitative and quantitative results show that SeFFeC enables precise and fine-grained control of 23 facial features, some of which could not previously be controlled by other methods, without requiring manual annotations. Unlike existing methods, SeFFeC also provides deterministic control over the exact values of the facial features and more localised and disentangled face edits.
The Power of Properties: Uncovering the Influential Factors in Emotion Classification
Apr 11, 2024Facial expression-based human emotion recognition is a critical research area in psychology and medicine. State-of-the-art classification performance is only reached by end-to-end trained neural networks. Nevertheless, such black-box models lack transparency in their decision-making processes, prompting efforts to ascertain the rules that underlie classifiers' decisions. Analyzing single inputs alone fails to expose systematic learned biases. These biases can be characterized as facial properties summarizing abstract information like age or medical conditions. Therefore, understanding a model's prediction behavior requires an analysis rooted in causality along such selected properties. We demonstrate that up to 91.25% of classifier output behavior changes are statistically significant concerning basic properties. Among those are age, gender, and facial symmetry. Furthermore, the medical usage of surface electromyography significantly influences emotion prediction. We introduce a workflow to evaluate explicit properties and their impact. These insights might help medical professionals select and apply classifiers regarding their specialized data and properties.
DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation
Mar 26, 2024Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.
Makeup Prior Models for 3D Facial Makeup Estimation and Applications
Mar 26, 2024In this work, we introduce two types of makeup prior models to extend existing 3D face prior models: PCA-based and StyleGAN2-based priors. The PCA-based prior model is a linear model that is easy to construct and is computationally efficient. However, it retains only low-frequency information. Conversely, the StyleGAN2-based model can represent high-frequency information with relatively higher computational cost than the PCA-based model. Although there is a trade-off between the two models, both are applicable to 3D facial makeup estimation and related applications. By leveraging makeup prior models and designing a makeup consistency module, we effectively address the challenges that previous methods faced in robustly estimating makeup, particularly in the context of handling self-occluded faces. In experiments, we demonstrate that our approach reduces computational costs by several orders of magnitude, achieving speeds up to 180 times faster. In addition, by improving the accuracy of the estimated makeup, we confirm that our methods are highly advantageous for various 3D facial makeup applications such as 3D makeup face reconstruction, user-friendly makeup editing, makeup transfer, and interpolation.
Self-Supervised Facial Representation Learning with Facial Region Awareness
Mar 04, 2024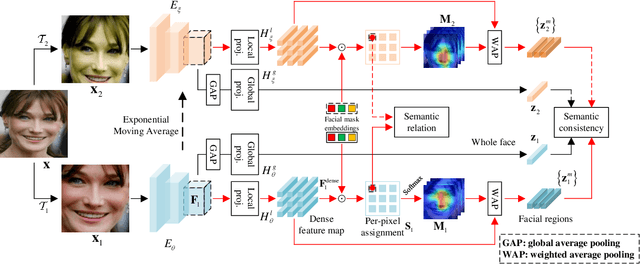

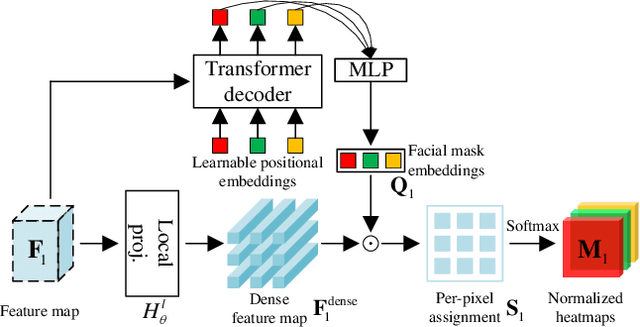
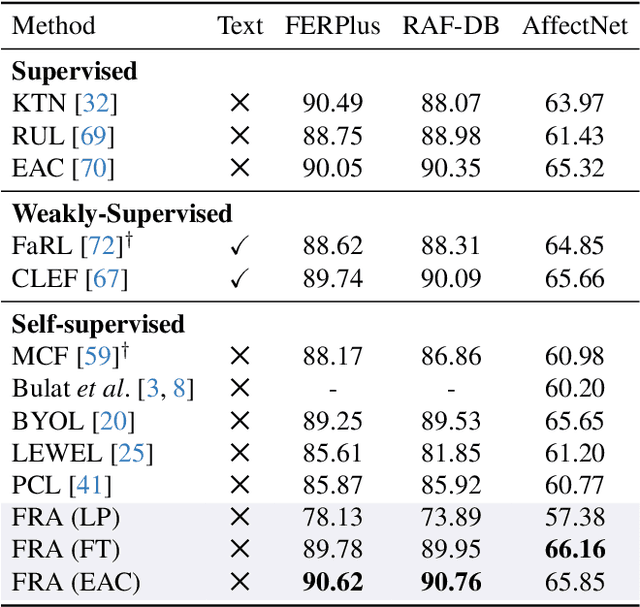
Self-supervised pre-training has been proved to be effective in learning transferable representations that benefit various visual tasks. This paper asks this question: can self-supervised pre-training learn general facial representations for various facial analysis tasks? Recent efforts toward this goal are limited to treating each face image as a whole, i.e., learning consistent facial representations at the image-level, which overlooks the consistency of local facial representations (i.e., facial regions like eyes, nose, etc). In this work, we make a first attempt to propose a novel self-supervised facial representation learning framework to learn consistent global and local facial representations, Facial Region Awareness (FRA). Specifically, we explicitly enforce the consistency of facial regions by matching the local facial representations across views, which are extracted with learned heatmaps highlighting the facial regions. Inspired by the mask prediction in supervised semantic segmentation, we obtain the heatmaps via cosine similarity between the per-pixel projection of feature maps and facial mask embeddings computed from learnable positional embeddings, which leverage the attention mechanism to globally look up the facial image for facial regions. To learn such heatmaps, we formulate the learning of facial mask embeddings as a deep clustering problem by assigning the pixel features from the feature maps to them. The transfer learning results on facial classification and regression tasks show that our FRA outperforms previous pre-trained models and more importantly, using ResNet as the unified backbone for various tasks, our FRA achieves comparable or even better performance compared with SOTA methods in facial analysis tasks.
Skull-to-Face: Anatomy-Guided 3D Facial Reconstruction and Editing
Mar 24, 2024Deducing the 3D face from a skull is an essential but challenging task in forensic science and archaeology. Existing methods for automated facial reconstruction yield inaccurate results, suffering from the non-determinative nature of the problem that a skull with a sparse set of tissue depth cannot fully determine the skinned face. Additionally, their texture-less results require further post-processing stages to achieve a photo-realistic appearance. This paper proposes an end-to-end 3D face reconstruction and exploration tool, providing textured 3D faces for reference. With the help of state-of-the-art text-to-image diffusion models and image-based facial reconstruction techniques, we generate an initial reference 3D face, whose biological profile aligns with the given skull. We then adapt these initial faces to meet the statistical expectations of extruded anatomical landmarks on the skull through an optimization process. The joint statistical distribution of tissue depths is learned on a small set of anatomical landmarks on the skull. To support further adjustment, we propose an efficient face adaptation tool to assist users in tuning tissue depths, either globally or at local regions, while observing plausible visual feedback. Experiments conducted on a real skull-face dataset demonstrated the effectiveness of our proposed pipeline in terms of reconstruction accuracy, diversity, and stability.
rFaceNet: An End-to-End Network for Enhanced Physiological Signal Extraction through Identity-Specific Facial Contours
Mar 17, 2024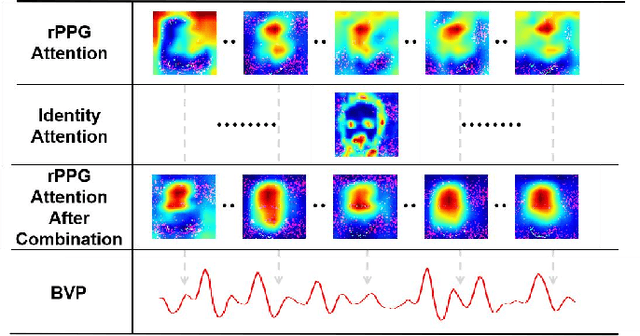
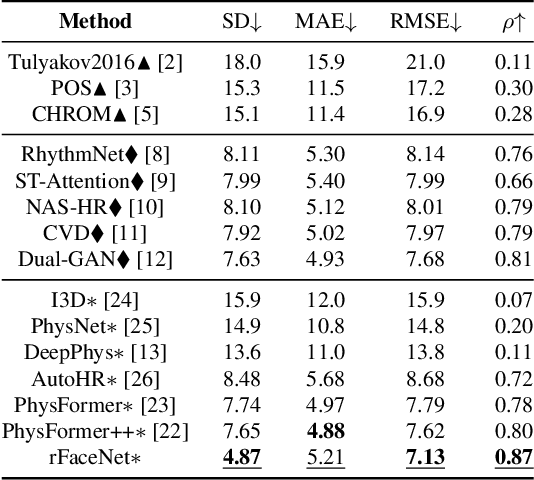
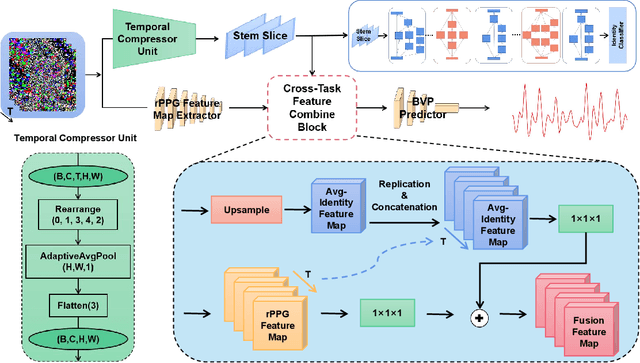
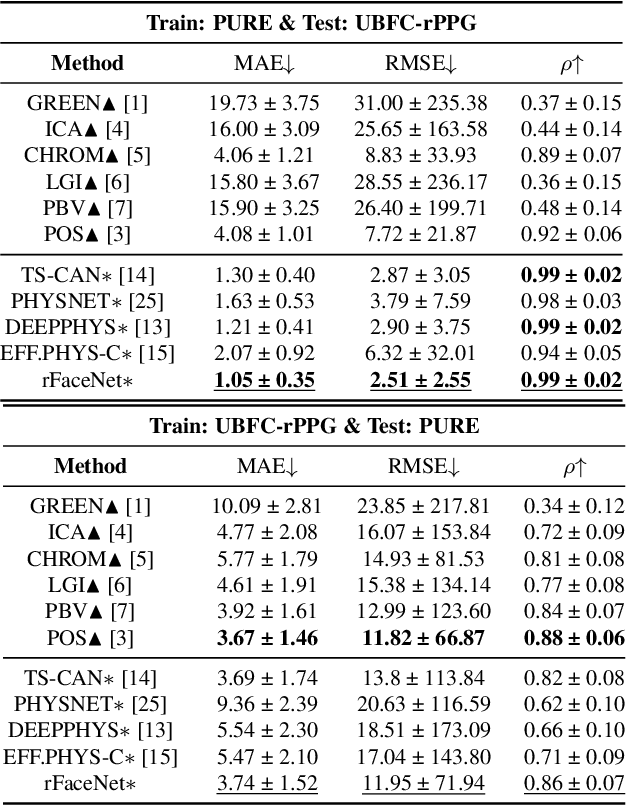
Remote photoplethysmography (rPPG) technique extracts blood volume pulse (BVP) signals from subtle pixel changes in video frames. This study introduces rFaceNet, an advanced rPPG method that enhances the extraction of facial BVP signals with a focus on facial contours. rFaceNet integrates identity-specific facial contour information and eliminates redundant data. It efficiently extracts facial contours from temporally normalized frame inputs through a Temporal Compressor Unit (TCU) and steers the model focus to relevant facial regions by using the Cross-Task Feature Combiner (CTFC). Through elaborate training, the quality and interpretability of facial physiological signals extracted by rFaceNet are greatly improved compared to previous methods. Moreover, our novel approach demonstrates superior performance than SOTA methods in various heart rate estimation benchmarks.