 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Single-Camera 3D Head Fitting for Mixed Reality Clinical Applications
Sep 06, 2021

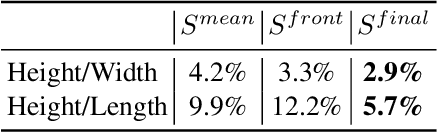


We address the problem of estimating the shape of a person's head, defined as the geometry of the complete head surface, from a video taken with a single moving camera, and determining the alignment of the fitted 3D head for all video frames, irrespective of the person's pose. 3D head reconstructions commonly tend to focus on perfecting the face reconstruction, leaving the scalp to a statistical approximation. Our goal is to reconstruct the head model of each person to enable future mixed reality applications. To do this, we recover a dense 3D reconstruction and camera information via structure-from-motion and multi-view stereo. These are then used in a new two-stage fitting process to recover the 3D head shape by iteratively fitting a 3D morphable model of the head with the dense reconstruction in canonical space and fitting it to each person's head, using both traditional facial landmarks and scalp features extracted from the head's segmentation mask. Our approach recovers consistent geometry for varying head shapes, from videos taken by different people, with different smartphones, and in a variety of environments from living rooms to outdoor spaces.
Faster Than Real-time Facial Alignment: A 3D Spatial Transformer Network Approach in Unconstrained Poses
Sep 08, 2017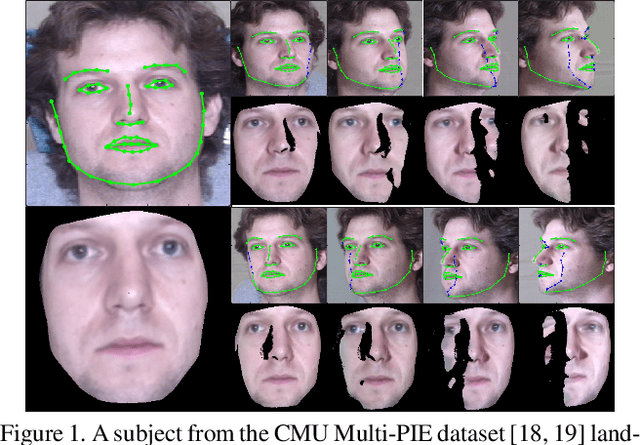
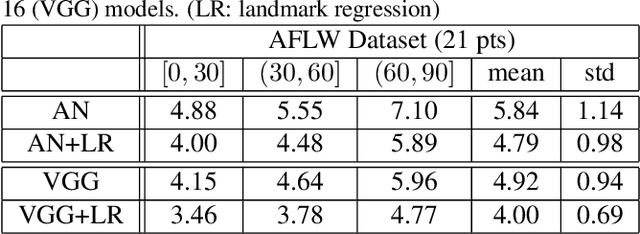

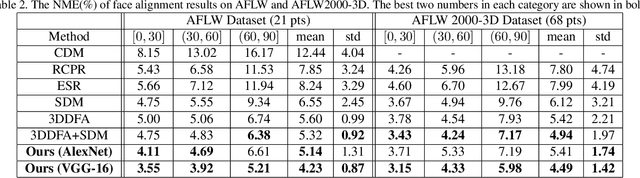
Facial alignment involves finding a set of landmark points on an image with a known semantic meaning. However, this semantic meaning of landmark points is often lost in 2D approaches where landmarks are either moved to visible boundaries or ignored as the pose of the face changes. In order to extract consistent alignment points across large poses, the 3D structure of the face must be considered in the alignment step. However, extracting a 3D structure from a single 2D image usually requires alignment in the first place. We present our novel approach to simultaneously extract the 3D shape of the face and the semantically consistent 2D alignment through a 3D Spatial Transformer Network (3DSTN) to model both the camera projection matrix and the warping parameters of a 3D model. By utilizing a generic 3D model and a Thin Plate Spline (TPS) warping function, we are able to generate subject specific 3D shapes without the need for a large 3D shape basis. In addition, our proposed network can be trained in an end-to-end framework on entirely synthetic data from the 300W-LP dataset. Unlike other 3D methods, our approach only requires one pass through the network resulting in a faster than real-time alignment. Evaluations of our model on the Annotated Facial Landmarks in the Wild (AFLW) and AFLW2000-3D datasets show our method achieves state-of-the-art performance over other 3D approaches to alignment.
A trained humanoid robot can perform human-like crossmodal social attention conflict resolution
Nov 02, 2021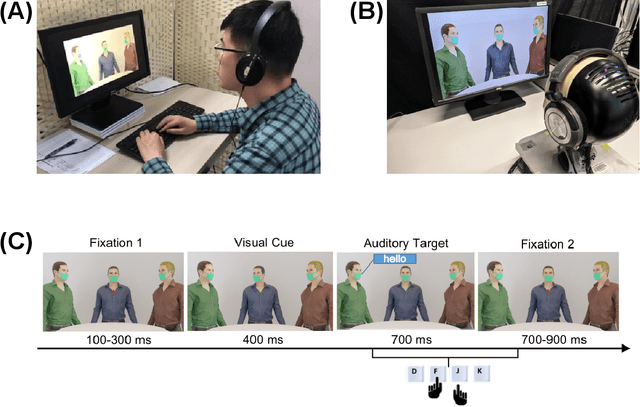
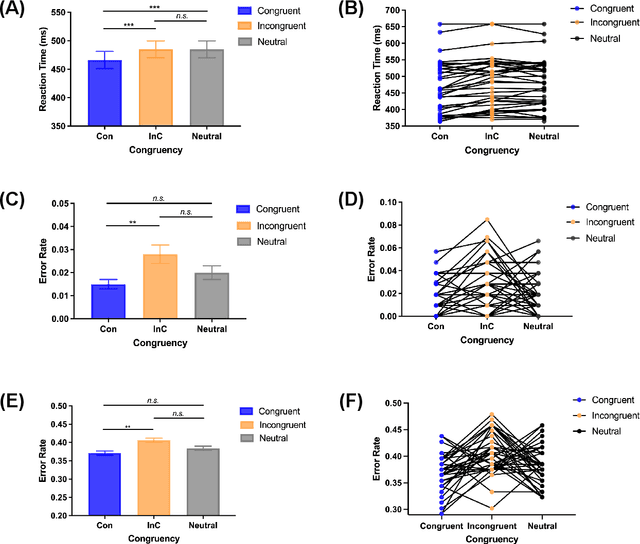
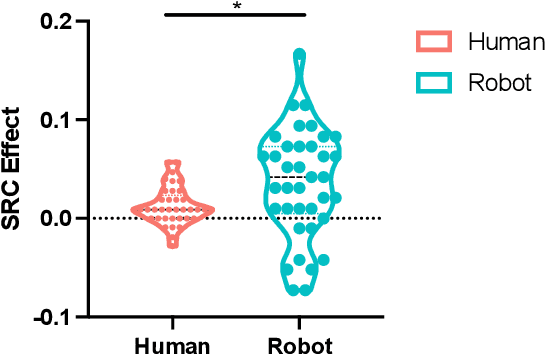

Due to the COVID-19 pandemic, robots could be seen as potential resources in tasks like helping people work remotely, sustaining social distancing, and improving mental or physical health. To enhance human-robot interaction, it is essential for robots to become more socialised, via processing multiple social cues in a complex real-world environment. Our study adopted a neurorobotic paradigm of gaze-triggered audio-visual crossmodal integration to make an iCub robot express human-like social attention responses. At first, a behavioural experiment was conducted on 37 human participants. To improve ecological validity, a round-table meeting scenario with three masked animated avatars was designed with the middle one capable of performing gaze shift, and the other two capable of generating sound. The gaze direction and the sound location are either congruent or incongruent. Masks were used to cover all facial visual cues other than the avatars' eyes. We observed that the avatar's gaze could trigger crossmodal social attention with better human performance in the audio-visual congruent condition than in the incongruent condition. Then, our computational model, GASP, was trained to implement social cue detection, audio-visual saliency prediction, and selective attention. After finishing the model training, the iCub robot was exposed to similar laboratory conditions as human participants, demonstrating that it can replicate similar attention responses as humans regarding the congruency and incongruency performance, while overall the human performance was still superior. Therefore, this interdisciplinary work provides new insights on mechanisms of crossmodal social attention and how it can be modelled in robots in a complex environment.
Detecting Autism Spectrum Disorders with Machine Learning Models Using Speech Transcripts
Oct 07, 2021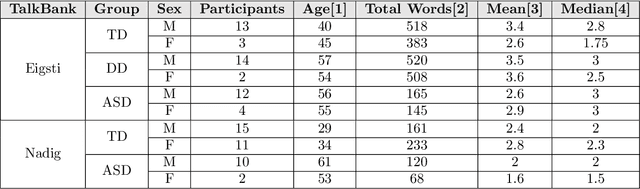
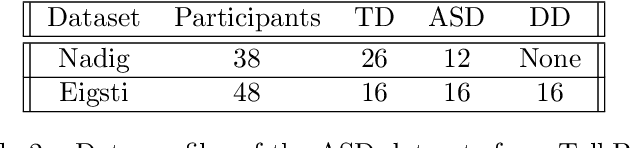
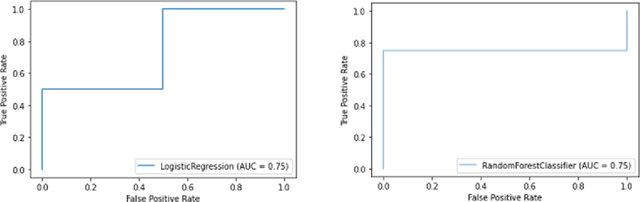
Autism spectrum disorder (ASD) can be defined as a neurodevelopmental disorder that affects how children interact, communicate and socialize with others. This disorder can occur in a broad spectrum of symptoms, with varying effects and severity. While there is no permanent cure for ASD, early detection and proactive treatment can substantially improve the lives of many children. Current methods to accurately diagnose ASD are invasive, time-consuming, and tedious. They can also be subjective perspectives of a number of clinicians involved, including pediatricians, speech pathologists, psychologists, and psychiatrists. New technologies are rapidly emerging that include machine learning models using speech, computer vision from facial, retinal, and brain MRI images of patients to accurately and timely detect this disorder. Our research focuses on computational linguistics and machine learning using speech data from TalkBank, the world's largest spoken language database. We used data of both ASD and Typical Development (TD) in children from TalkBank to develop machine learning models to accurately predict ASD. More than 50 features were used from specifically two datasets in TalkBank to run our experiments using five different classifiers. Logistic Regression and Random Forest models were found to be the most effective for each of these two main datasets, with an accuracy of 0.75. These experiments confirm that while significant opportunities exist for improving the accuracy, machine learning models can reliably predict ASD status in children for effective diagnosis.
Recursively Conditional Gaussian for Ordinal Unsupervised Domain Adaptation
Aug 17, 2021
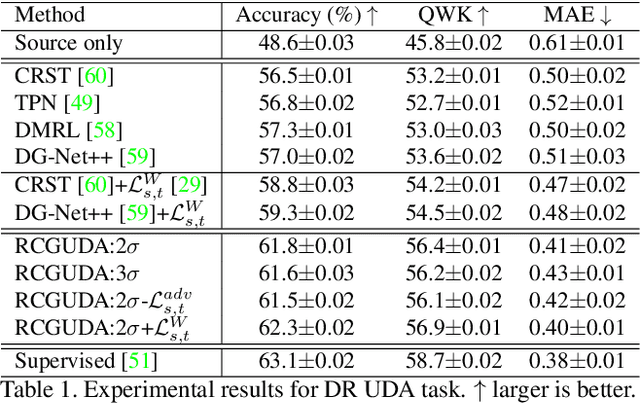
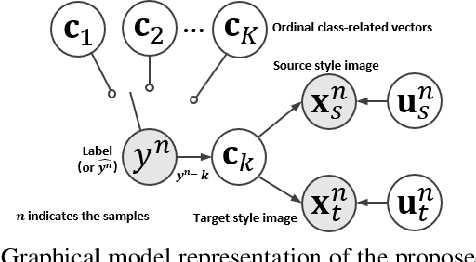
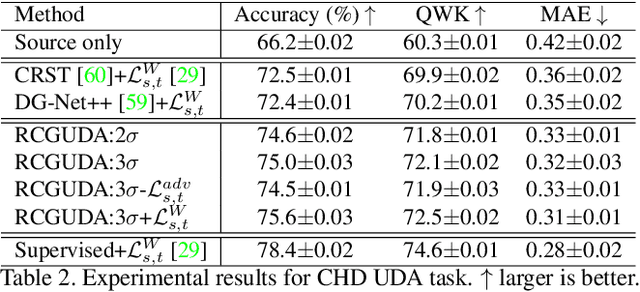
The unsupervised domain adaptation (UDA) has been widely adopted to alleviate the data scalability issue, while the existing works usually focus on classifying independently discrete labels. However, in many tasks (e.g., medical diagnosis), the labels are discrete and successively distributed. The UDA for ordinal classification requires inducing non-trivial ordinal distribution prior to the latent space. Target for this, the partially ordered set (poset) is defined for constraining the latent vector. Instead of the typically i.i.d. Gaussian latent prior, in this work, a recursively conditional Gaussian (RCG) set is adapted for ordered constraint modeling, which admits a tractable joint distribution prior. Furthermore, we are able to control the density of content vector that violates the poset constraints by a simple "three-sigma rule". We explicitly disentangle the cross-domain images into a shared ordinal prior induced ordinal content space and two separate source/target ordinal-unrelated spaces, and the self-training is worked on the shared space exclusively for ordinal-aware domain alignment. Extensive experiments on UDA medical diagnoses and facial age estimation demonstrate its effectiveness.
Dynamic Pose-Robust Facial Expression Recognition by Multi-View Pairwise Conditional Random Forests
Jul 21, 2016
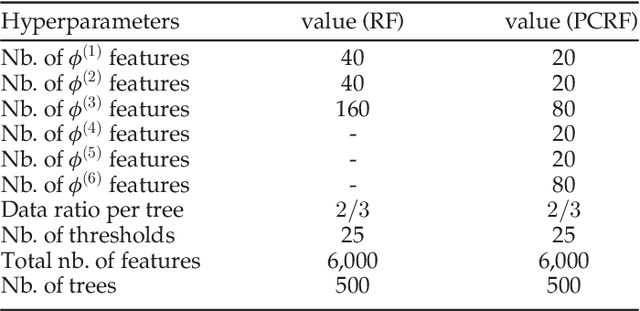
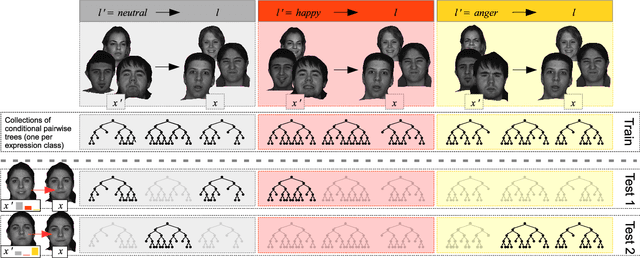
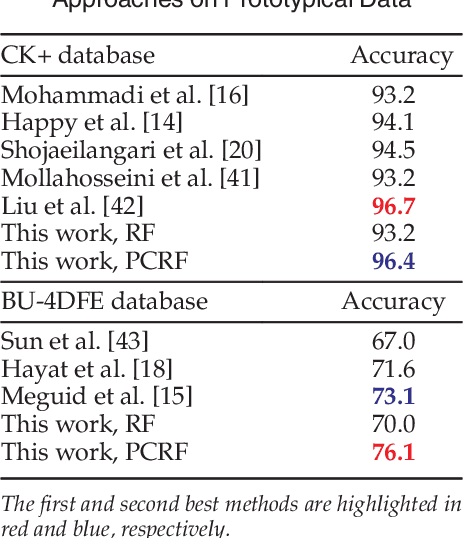
Automatic facial expression classification (FER) from videos is a critical problem for the development of intelligent human-computer interaction systems. Still, it is a challenging problem that involves capturing high-dimensional spatio-temporal patterns describing the variation of one's appearance over time. Such representation undergoes great variability of the facial morphology and environmental factors as well as head pose variations. In this paper, we use Conditional Random Forests to capture low-level expression transition patterns. More specifically, heterogeneous derivative features (e.g. feature point movements or texture variations) are evaluated upon pairs of images. When testing on a video frame, pairs are created between this current frame and previous ones and predictions for each previous frame are used to draw trees from Pairwise Conditional Random Forests (PCRF) whose pairwise outputs are averaged over time to produce robust estimates. Moreover, PCRF collections can also be conditioned on head pose estimation for multi-view dynamic FER. As such, our approach appears as a natural extension of Random Forests for learning spatio-temporal patterns, potentially from multiple viewpoints. Experiments on popular datasets show that our method leads to significant improvements over standard Random Forests as well as state-of-the-art approaches on several scenarios, including a novel multi-view video corpus generated from a publicly available database.
Heteroscedastic Conditional Ordinal Random Fields for Pain Intensity Estimation from Facial Images
Apr 03, 2013We propose a novel method for automatic pain intensity estimation from facial images based on the framework of kernel Conditional Ordinal Random Fields (KCORF). We extend this framework to account for heteroscedasticity on the output labels(i.e., pain intensity scores) and introduce a novel dynamic features, dynamic ranks, that impose temporal ordinal constraints on the static ranks (i.e., intensity scores). Our experimental results show that the proposed approach outperforms state-of-the art methods for sequence classification with ordinal data and other ordinal regression models. The approach performs significantly better than other models in terms of Intra-Class Correlation measure, which is the most accepted evaluation measure in the tasks of facial behaviour intensity estimation.
Synthesizing facial photometries and corresponding geometries using generative adversarial networks
Jan 19, 2019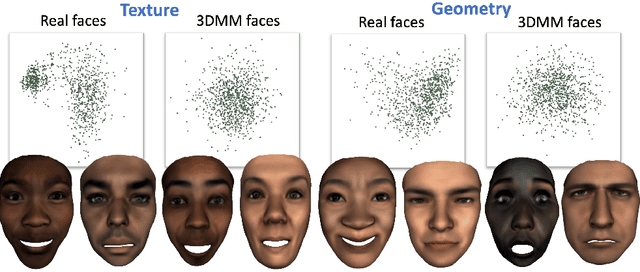
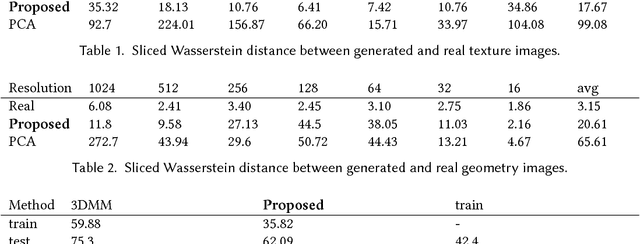
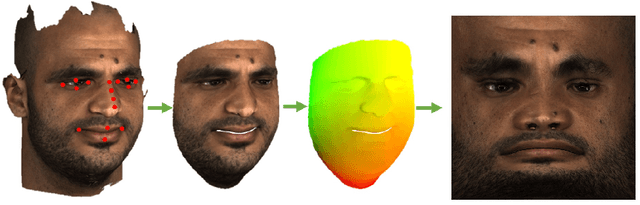

Artificial data synthesis is currently a well studied topic with useful applications in data science, computer vision, graphics and many other fields. Generating realistic data is especially challenging since human perception is highly sensitive to non realistic appearance. In recent times, new levels of realism have been achieved by advances in GAN training procedures and architectures. These successful models, however, are tuned mostly for use with regularly sampled data such as images, audio and video. Despite the successful application of the architecture on these types of media, applying the same tools to geometric data poses a far greater challenge. The study of geometric deep learning is still a debated issue within the academic community as the lack of intrinsic parametrization inherent to geometric objects prohibits the direct use of convolutional filters, a main building block of today's machine learning systems. In this paper we propose a new method for generating realistic human facial geometries coupled with overlayed textures. We circumvent the parametrization issue by imposing a global mapping from our data to the unit rectangle. We further discuss how to design such a mapping to control the mapping distortion and conserve area within the mapped image. By representing geometric textures and geometries as images, we are able to use advanced GAN methodologies to generate new geometries. We address the often neglected topic of relation between texture and geometry and propose to use this correlation to match between generated textures and their corresponding geometries. We offer a new method for training GAN models on partially corrupted data. Finally, we provide empirical evidence demonstrating our generative model's ability to produce examples of new identities independent from the training data while maintaining a high level of realism, two traits that are often at odds.
About Face: A Survey of Facial Recognition Evaluation
Feb 01, 2021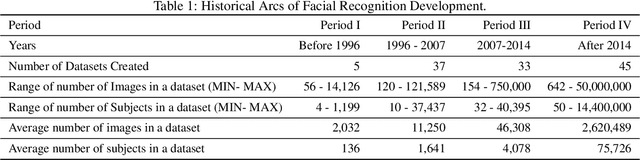
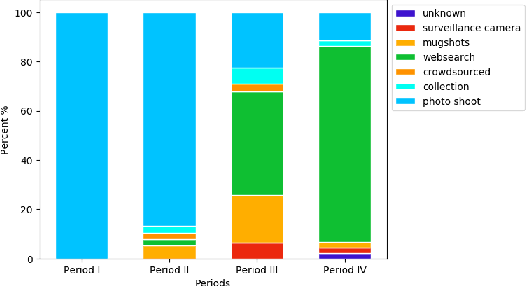
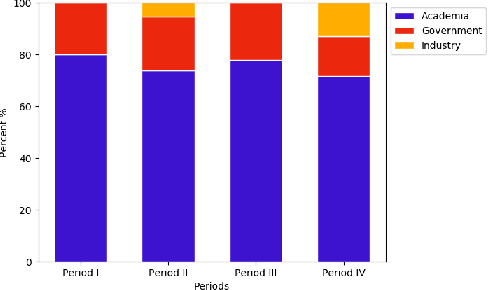
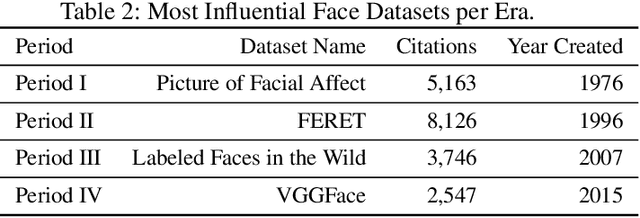
We survey over 100 face datasets constructed between 1976 to 2019 of 145 million images of over 17 million subjects from a range of sources, demographics and conditions. Our historical survey reveals that these datasets are contextually informed, shaped by changes in political motivations, technological capability and current norms. We discuss how such influences mask specific practices (some of which may actually be harmful or otherwise problematic) and make a case for the explicit communication of such details in order to establish a more grounded understanding of the technology's function in the real world.
HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping
Jun 18, 2021
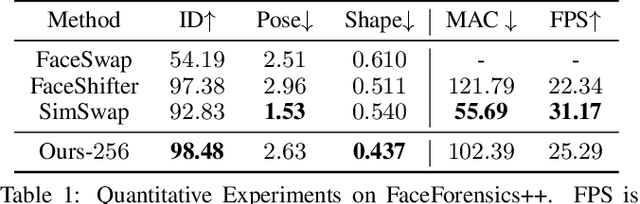
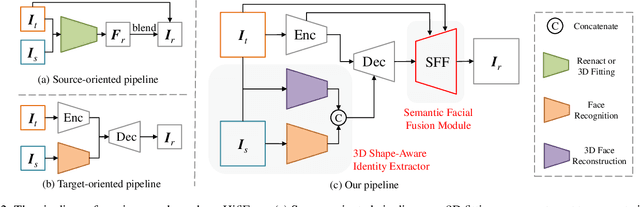
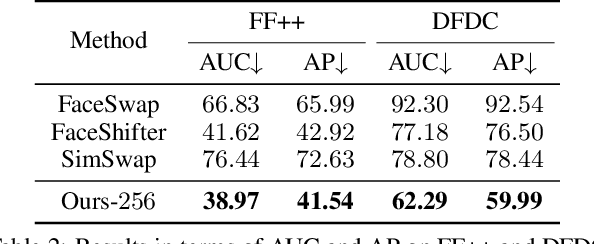
In this work, we propose a high fidelity face swapping method, called HifiFace, which can well preserve the face shape of the source face and generate photo-realistic results. Unlike other existing face swapping works that only use face recognition model to keep the identity similarity, we propose 3D shape-aware identity to control the face shape with the geometric supervision from 3DMM and 3D face reconstruction method. Meanwhile, we introduce the Semantic Facial Fusion module to optimize the combination of encoder and decoder features and make adaptive blending, which makes the results more photo-realistic. Extensive experiments on faces in the wild demonstrate that our method can preserve better identity, especially on the face shape, and can generate more photo-realistic results than previous state-of-the-art methods.