 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Real time facial expression recognition using a novel method
May 08, 2012
This paper discusses a novel method for Facial Expression Recognition System which performs facial expression analysis in a near real time from a live web cam feed. Primary objectives were to get results in a near real time with light invariant, person independent and pose invariant way. The system is composed of two different entities trainer and evaluator. Each frame of video feed is passed through a series of steps including haar classifiers, skin detection, feature extraction, feature points tracking, creating a learned Support Vector Machine model to classify emotions to achieve a tradeoff between accuracy and result rate. A processing time of 100-120 ms per 10 frames was achieved with accuracy of around 60%. We measure our accuracy in terms of variety of interaction and classification scenarios. We conclude by discussing relevance of our work to human computer interaction and exploring further measures that can be taken.
Deepfake Video Detection Using Convolutional Vision Transformer
Feb 28, 2021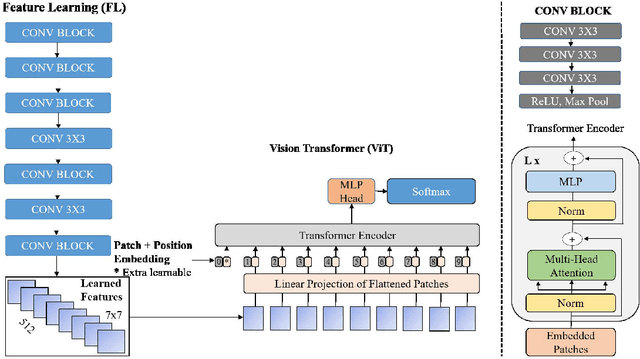



The rapid advancement of deep learning models that can generate and synthesis hyper-realistic videos known as Deepfakes and their ease of access to the general public have raised concern from all concerned bodies to their possible malicious intent use. Deep learning techniques can now generate faces, swap faces between two subjects in a video, alter facial expressions, change gender, and alter facial features, to list a few. These powerful video manipulation methods have potential use in many fields. However, they also pose a looming threat to everyone if used for harmful purposes such as identity theft, phishing, and scam. In this work, we propose a Convolutional Vision Transformer for the detection of Deepfakes. The Convolutional Vision Transformer has two components: Convolutional Neural Network (CNN) and Vision Transformer (ViT). The CNN extracts learnable features while the ViT takes in the learned features as input and categorizes them using an attention mechanism. We trained our model on the DeepFake Detection Challenge Dataset (DFDC) and have achieved 91.5 percent accuracy, an AUC value of 0.91, and a loss value of 0.32. Our contribution is that we have added a CNN module to the ViT architecture and have achieved a competitive result on the DFDC dataset.
Face Identification from Manipulated Facial Images using SIFT
Jun 24, 2011



Editing on digital images is ubiquitous. Identification of deliberately modified facial images is a new challenge for face identification system. In this paper, we address the problem of identification of a face or person from heavily altered facial images. In this face identification problem, the input to the system is a manipulated or transformed face image and the system reports back the determined identity from a database of known individuals. Such a system can be useful in mugshot identification in which mugshot database contains two views (frontal and profile) of each criminal. We considered only frontal view from the available database for face identification and the query image is a manipulated face generated by face transformation software tool available online. We propose SIFT features for efficient face identification in this scenario. Further comparative analysis has been given with well known eigenface approach. Experiments have been conducted with real case images to evaluate the performance of both methods.
Detection of Makeup Presentation Attacks based on Deep Face Representations
Jun 09, 2020

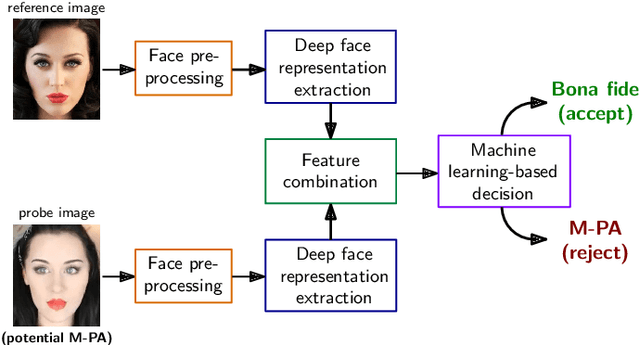
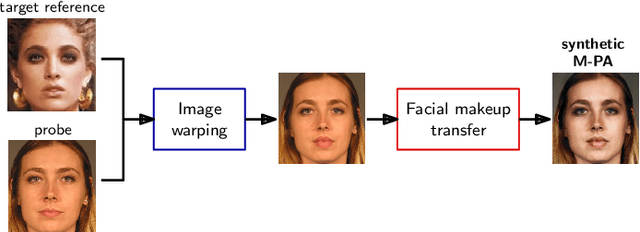
Facial cosmetics have the ability to substantially alter the facial appearance, which can negatively affect the decisions of a face recognition. In addition, it was recently shown that the application of makeup can be abused to launch so-called makeup presentation attacks. In such attacks, the attacker might apply heavy makeup in order to achieve the facial appearance of a target subject for the purpose of impersonation. In this work, we assess the vulnerability of a COTS face recognition system to makeup presentation attacks employing the publicly available Makeup Induced Face Spoofing (MIFS) database. It is shown that makeup presentation attacks might seriously impact the security of the face recognition system. Further, we propose an attack detection scheme which distinguishes makeup presentation attacks from genuine authentication attempts by analysing differences in deep face representations obtained from potential makeup presentation attacks and corresponding target face images. The proposed detection system employs a machine learning-based classifier, which is trained with synthetically generated makeup presentation attacks utilizing a generative adversarial network for facial makeup transfer in conjunction with image warping. Experimental evaluations conducted using the MIFS database reveal a detection equal error rate of 0.7% for the task of separating genuine authentication attempts from makeup presentation attacks.
Segmentation of Facial Expressions Using Semi-Definite Programming and Generalized Principal Component Analysis
Jun 10, 2009
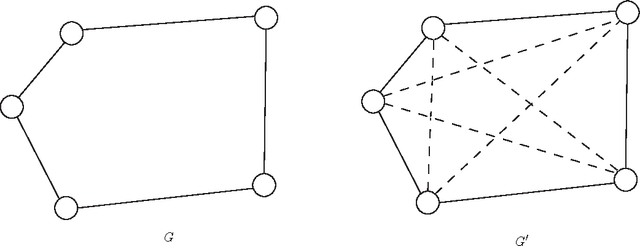

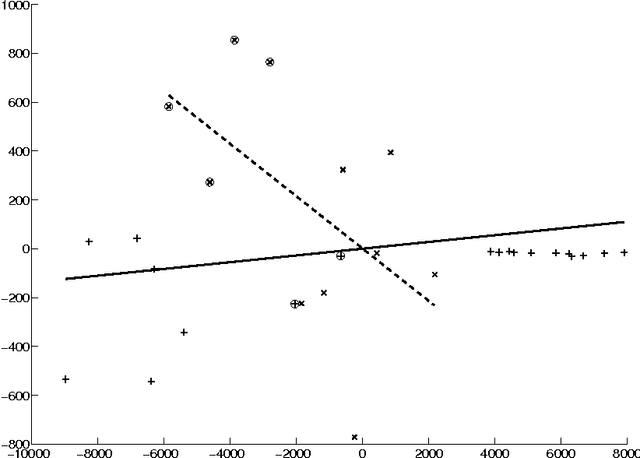
In this paper, we use semi-definite programming and generalized principal component analysis (GPCA) to distinguish between two or more different facial expressions. In the first step, semi-definite programming is used to reduce the dimension of the image data and "unfold" the manifold which the data points (corresponding to facial expressions) reside on. Next, GPCA is used to fit a series of subspaces to the data points and associate each data point with a subspace. Data points that belong to the same subspace are claimed to belong to the same facial expression category. An example is provided.
The color of smiling: computational synaesthesia of facial expressions
May 16, 2015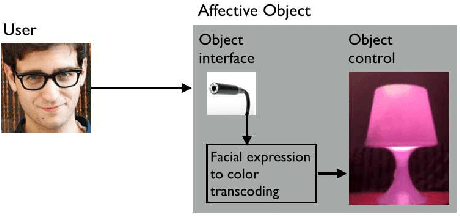

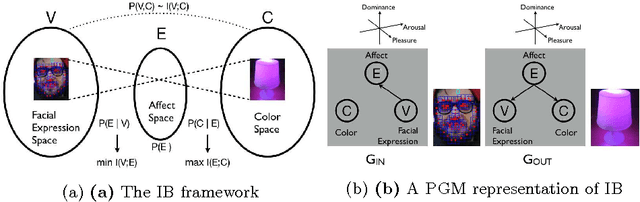
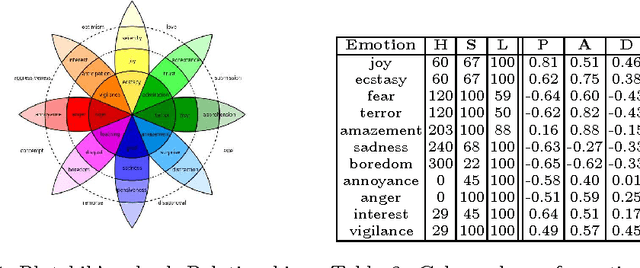
This note gives a preliminary account of the transcoding or rechanneling problem between different stimuli as it is of interest for the natural interaction or affective computing fields. By the consideration of a simple example, namely the color response of an affective lamp to a sensed facial expression, we frame the problem within an information- theoretic perspective. A full justification in terms of the Information Bottleneck principle promotes a latent affective space, hitherto surmised as an appealing and intuitive solution, as a suitable mediator between the different stimuli.
Master Face Attacks on Face Recognition Systems
Sep 08, 2021
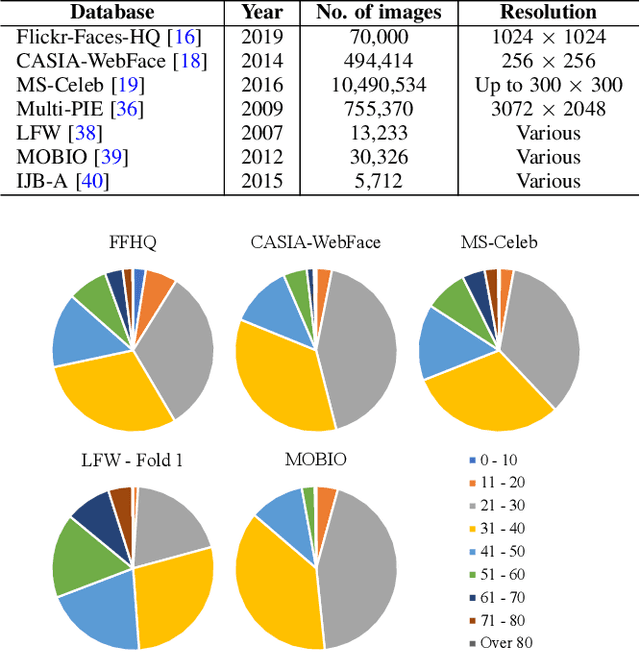
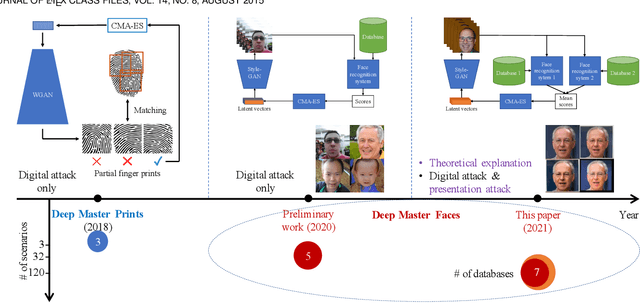

Face authentication is now widely used, especially on mobile devices, rather than authentication using a personal identification number or an unlock pattern, due to its convenience. It has thus become a tempting target for attackers using a presentation attack. Traditional presentation attacks use facial images or videos of the victim. Previous work has proven the existence of master faces, i.e., faces that match multiple enrolled templates in face recognition systems, and their existence extends the ability of presentation attacks. In this paper, we perform an extensive study on latent variable evolution (LVE), a method commonly used to generate master faces. We run an LVE algorithm for various scenarios and with more than one database and/or face recognition system to study the properties of the master faces and to understand in which conditions strong master faces could be generated. Moreover, through analysis, we hypothesize that master faces come from some dense areas in the embedding spaces of the face recognition systems. Last but not least, simulated presentation attacks using generated master faces generally preserve the false-matching ability of their original digital forms, thus demonstrating that the existence of master faces poses an actual threat.
Point detection through multi-instance deep heatmap regression for sutures in endoscopy
Nov 16, 2021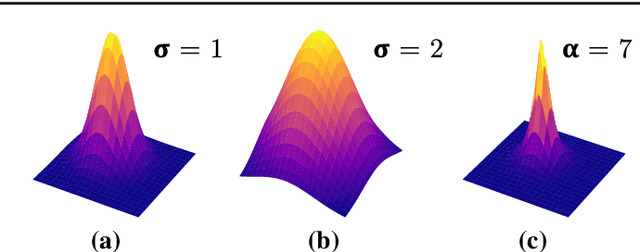
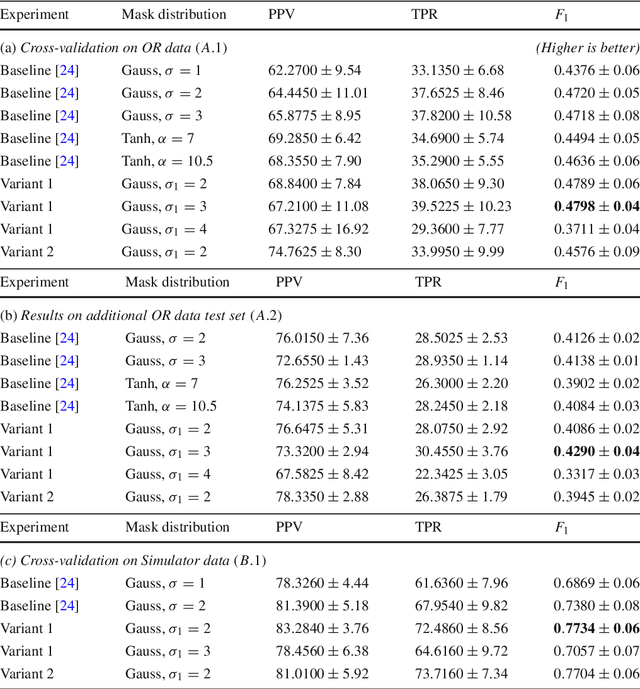
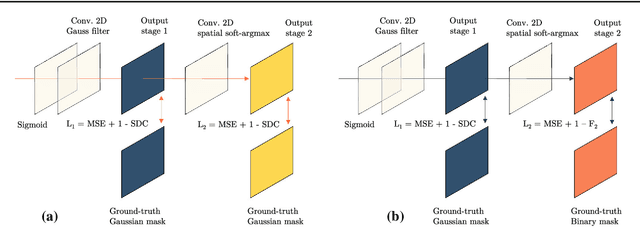
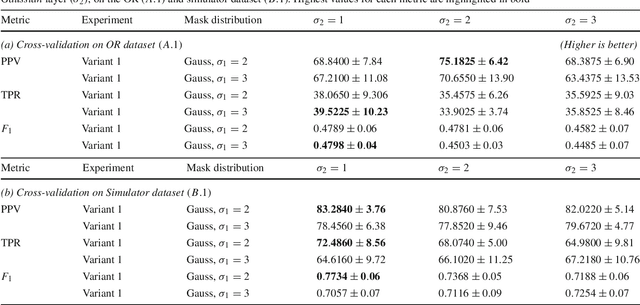
Purpose: Mitral valve repair is a complex minimally invasive surgery of the heart valve. In this context, suture detection from endoscopic images is a highly relevant task that provides quantitative information to analyse suturing patterns, assess prosthetic configurations and produce augmented reality visualisations. Facial or anatomical landmark detection tasks typically contain a fixed number of landmarks, and use regression or fixed heatmap-based approaches to localize the landmarks. However in endoscopy, there are a varying number of sutures in every image, and the sutures may occur at any location in the annulus, as they are not semantically unique. Method: In this work, we formulate the suture detection task as a multi-instance deep heatmap regression problem, to identify entry and exit points of sutures. We extend our previous work, and introduce the novel use of a 2D Gaussian layer followed by a differentiable 2D spatial Soft-Argmax layer to function as a local non-maximum suppression. Results: We present extensive experiments with multiple heatmap distribution functions and two variants of the proposed model. In the intra-operative domain, Variant 1 showed a mean F1 of +0.0422 over the baseline. Similarly, in the simulator domain, Variant 1 showed a mean F1 of +0.0865 over the baseline. Conclusion: The proposed model shows an improvement over the baseline in the intra-operative and the simulator domains. The data is made publicly available within the scope of the MICCAI AdaptOR2021 Challenge https://adaptor2021.github.io/, and the code at https://github.com/Cardio-AI/suture-detection-pytorch/. DOI:10.1007/s11548-021-02523-w. The link to the open access article can be found here: https://link.springer.com/article/10.1007%2Fs11548-021-02523-w
* Accepted to International Journal of Computer Assisted Radiology and Surgery, 15 pages, 5 figures
Single-Camera 3D Head Fitting for Mixed Reality Clinical Applications
Sep 06, 2021
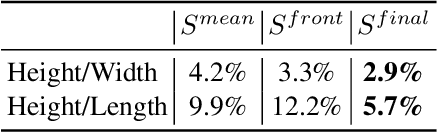


We address the problem of estimating the shape of a person's head, defined as the geometry of the complete head surface, from a video taken with a single moving camera, and determining the alignment of the fitted 3D head for all video frames, irrespective of the person's pose. 3D head reconstructions commonly tend to focus on perfecting the face reconstruction, leaving the scalp to a statistical approximation. Our goal is to reconstruct the head model of each person to enable future mixed reality applications. To do this, we recover a dense 3D reconstruction and camera information via structure-from-motion and multi-view stereo. These are then used in a new two-stage fitting process to recover the 3D head shape by iteratively fitting a 3D morphable model of the head with the dense reconstruction in canonical space and fitting it to each person's head, using both traditional facial landmarks and scalp features extracted from the head's segmentation mask. Our approach recovers consistent geometry for varying head shapes, from videos taken by different people, with different smartphones, and in a variety of environments from living rooms to outdoor spaces.