 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
An Improved Model for Voicing Silent Speech
Jun 21, 2021
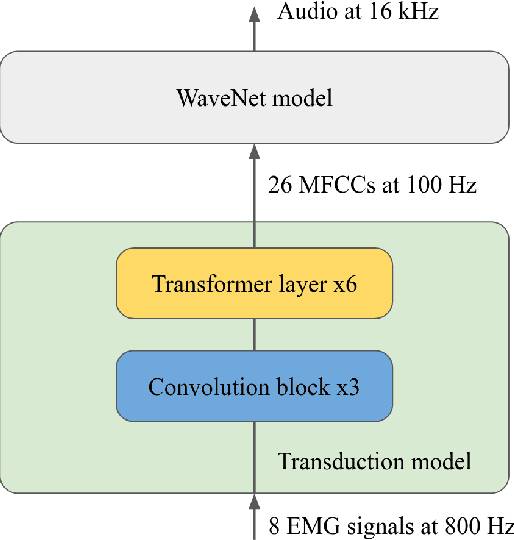

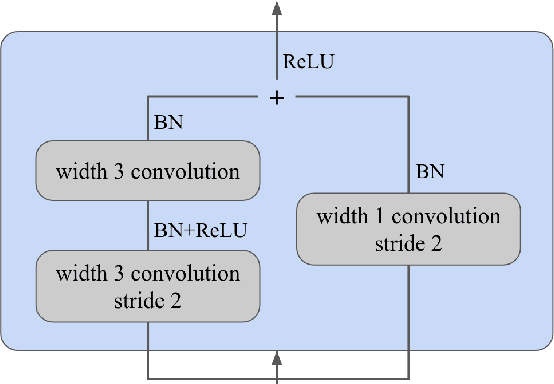
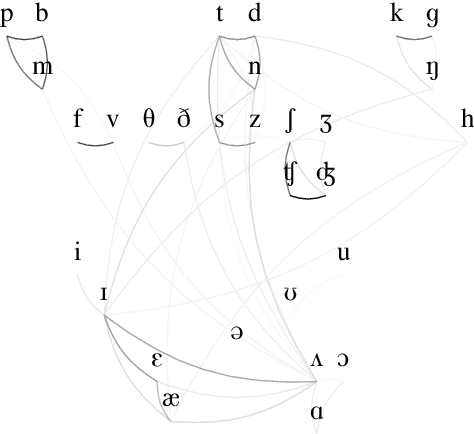
In this paper, we present an improved model for voicing silent speech, where audio is synthesized from facial electromyography (EMG) signals. To give our model greater flexibility to learn its own input features, we directly use EMG signals as input in the place of hand-designed features used by prior work. Our model uses convolutional layers to extract features from the signals and Transformer layers to propagate information across longer distances. To provide better signal for learning, we also introduce an auxiliary task of predicting phoneme labels in addition to predicting speech audio features. On an open vocabulary intelligibility evaluation, our model improves the state of the art for this task by an absolute 25.8%.
A Multi-task Mean Teacher for Semi-supervised Facial Affective Behavior Analysis
Jul 09, 2021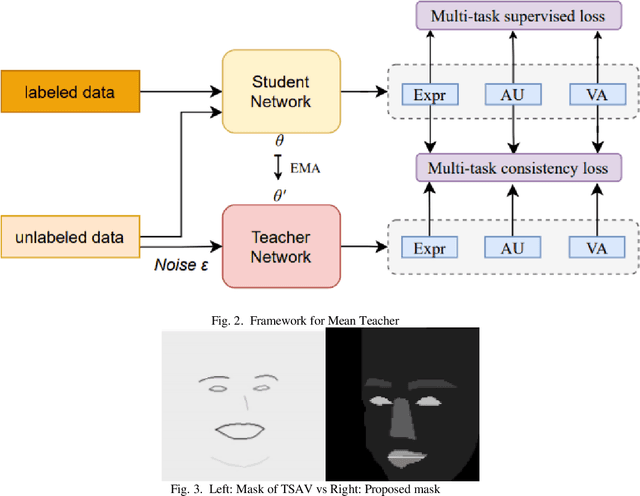
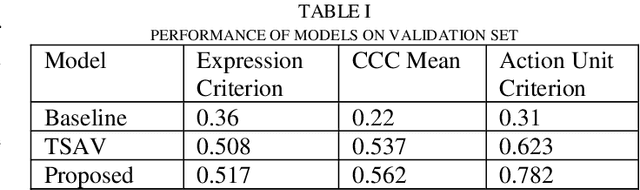
Affective Behavior Analysis is an important part in human?computer interaction. Existing successful affective behavior analysis method such as TSAV[9] suffer from challenge of incomplete labeled datasets. To boost its performance, this paper presents a multi-task mean teacher model for semi?supervised Affective Behavior Analysis to learn from missing labels and exploring the learning of multiple correlated task simultaneously. To be specific, we first utilize TSAV as baseline model to simultaneously recognize the three tasks. We have modified the preprocessing method of rendering mask to provide better semantics information. After that, we extended TSAV model to semi-supervised model using mean teacher, which allow it to be benefited from unlabeled data. Experimental results on validation datasets show that our method achieves better performance than TSAV model, which verifies that the proposed network can effectively learn additional unlabeled data to boost the affective behavior analysis performance.
A Transfer Learning approach to Heatmap Regression for Action Unit intensity estimation
Apr 14, 2020
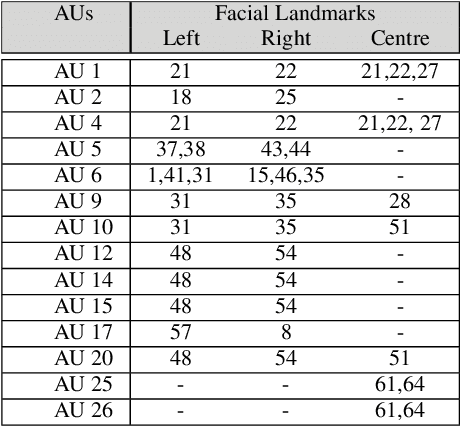
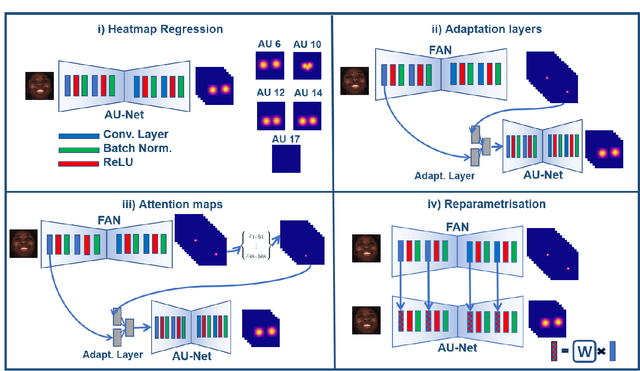
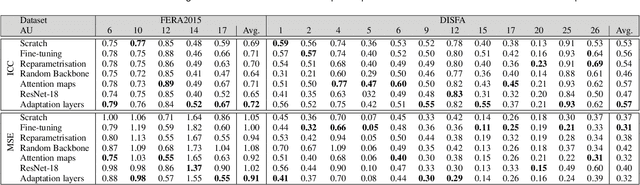
Action Units (AUs) are geometrically-based atomic facial muscle movements known to produce appearance changes at specific facial locations. Motivated by this observation we propose a novel AU modelling problem that consists of jointly estimating their localisation and intensity. To this end, we propose a simple yet efficient approach based on Heatmap Regression that merges both problems into a single task. A Heatmap models whether an AU occurs or not at a given spatial location. To accommodate the joint modelling of AUs intensity, we propose variable size heatmaps, with their amplitude and size varying according to the labelled intensity. Using Heatmap Regression, we can inherit from the progress recently witnessed in facial landmark localisation. Building upon the similarities between both problems, we devise a transfer learning approach where we exploit the knowledge of a network trained on large-scale facial landmark datasets. In particular, we explore different alternatives for transfer learning through a) fine-tuning, b) adaptation layers, c) attention maps, and d) reparametrisation. Our approach effectively inherits the rich facial features produced by a strong face alignment network, with minimal extra computational cost. We empirically validate that our system sets a new state-of-the-art on three popular datasets, namely BP4D, DISFA, and FERA2017.
Imitating Arbitrary Talking Style for Realistic Audio-DrivenTalking Face Synthesis
Oct 30, 2021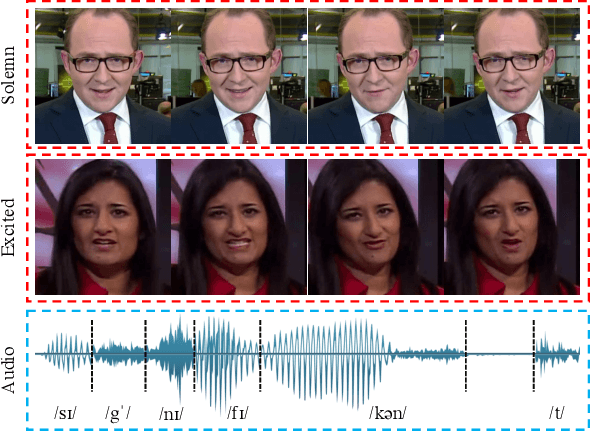
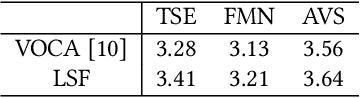
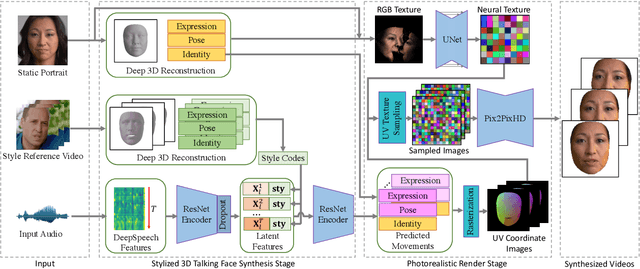
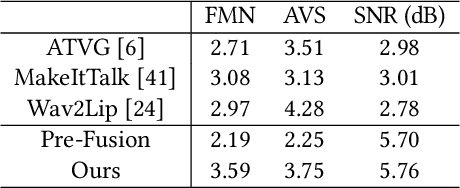
People talk with diversified styles. For one piece of speech, different talking styles exhibit significant differences in the facial and head pose movements. For example, the "excited" style usually talks with the mouth wide open, while the "solemn" style is more standardized and seldomly exhibits exaggerated motions. Due to such huge differences between different styles, it is necessary to incorporate the talking style into audio-driven talking face synthesis framework. In this paper, we propose to inject style into the talking face synthesis framework through imitating arbitrary talking style of the particular reference video. Specifically, we systematically investigate talking styles with our collected \textit{Ted-HD} dataset and construct style codes as several statistics of 3D morphable model~(3DMM) parameters. Afterwards, we devise a latent-style-fusion~(LSF) model to synthesize stylized talking faces by imitating talking styles from the style codes. We emphasize the following novel characteristics of our framework: (1) It doesn't require any annotation of the style, the talking style is learned in an unsupervised manner from talking videos in the wild. (2) It can imitate arbitrary styles from arbitrary videos, and the style codes can also be interpolated to generate new styles. Extensive experiments demonstrate that the proposed framework has the ability to synthesize more natural and expressive talking styles compared with baseline methods.
Shuffled Patch-Wise Supervision for Presentation Attack Detection
Sep 09, 2021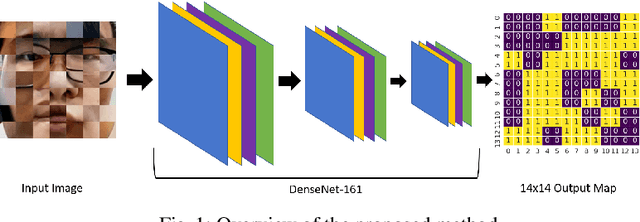
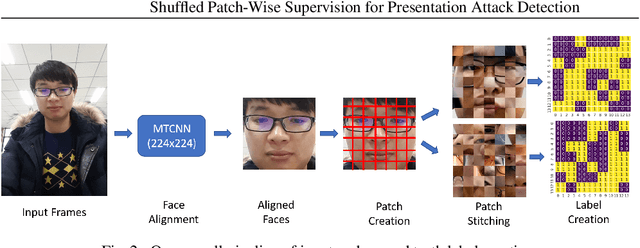

Face anti-spoofing is essential to prevent false facial verification by using a photo, video, mask, or a different substitute for an authorized person's face. Most of the state-of-the-art presentation attack detection (PAD) systems suffer from overfitting, where they achieve near-perfect scores on a single dataset but fail on a different dataset with more realistic data. This problem drives researchers to develop models that perform well under real-world conditions. This is an especially challenging problem for frame-based presentation attack detection systems that use convolutional neural networks (CNN). To this end, we propose a new PAD approach, which combines pixel-wise binary supervision with patch-based CNN. We believe that training a CNN with face patches allows the model to distinguish spoofs without learning background or dataset-specific traces. We tested the proposed method both on the standard benchmark datasets -- Replay-Mobile, OULU-NPU -- and on a real-world dataset. The proposed approach shows its superiority on challenging experimental setups. Namely, it achieves higher performance on OULU-NPU protocol 3, 4 and on inter-dataset real-world experiments.
AgeFlow: Conditional Age Progression and Regression with Normalizing Flows
May 15, 2021
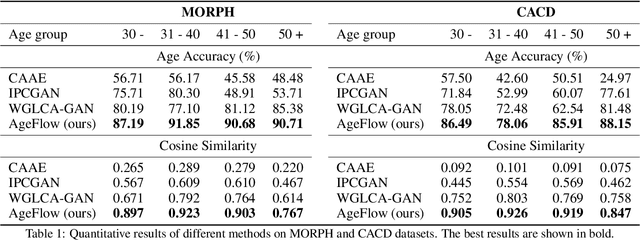
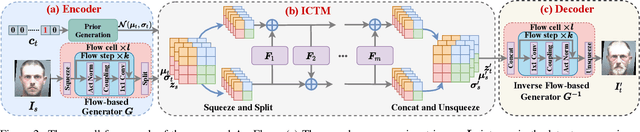
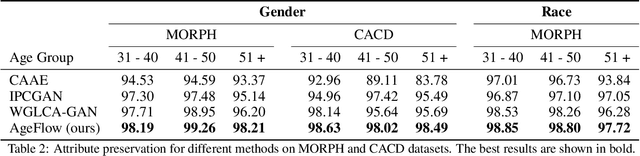
Age progression and regression aim to synthesize photorealistic appearance of a given face image with aging and rejuvenation effects, respectively. Existing generative adversarial networks (GANs) based methods suffer from the following three major issues: 1) unstable training introducing strong ghost artifacts in the generated faces, 2) unpaired training leading to unexpected changes in facial attributes such as genders and races, and 3) non-bijective age mappings increasing the uncertainty in the face transformation. To overcome these issues, this paper proposes a novel framework, termed AgeFlow, to integrate the advantages of both flow-based models and GANs. The proposed AgeFlow contains three parts: an encoder that maps a given face to a latent space through an invertible neural network, a novel invertible conditional translation module (ICTM) that translates the source latent vector to target one, and a decoder that reconstructs the generated face from the target latent vector using the same encoder network; all parts are invertible achieving bijective age mappings. The novelties of ICTM are two-fold. First, we propose an attribute-aware knowledge distillation to learn the manipulation direction of age progression while keeping other unrelated attributes unchanged, alleviating unexpected changes in facial attributes. Second, we propose to use GANs in the latent space to ensure the learned latent vector indistinguishable from the real ones, which is much easier than traditional use of GANs in the image domain. Experimental results demonstrate superior performance over existing GANs-based methods on two benchmarked datasets. The source code is available at https://github.com/Hzzone/AgeFlow.
MetaBalance: High-Performance Neural Networks for Class-Imbalanced Data
Jun 17, 2021
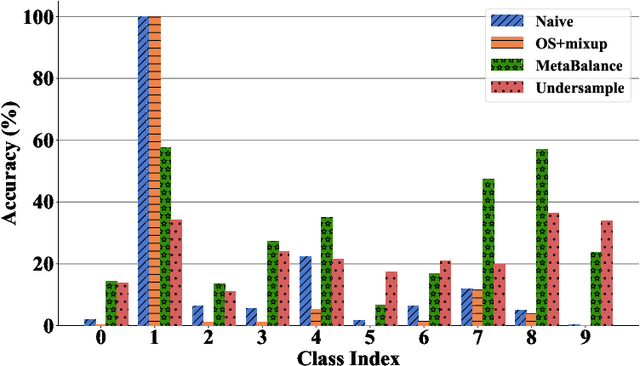
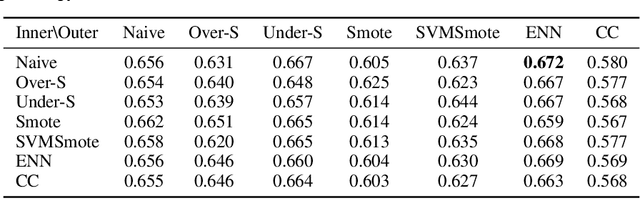
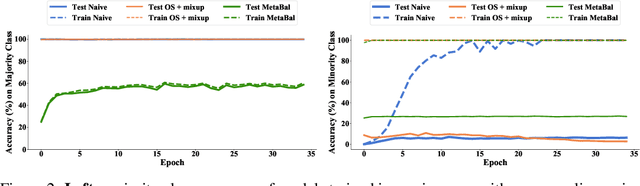
Class-imbalanced data, in which some classes contain far more samples than others, is ubiquitous in real-world applications. Standard techniques for handling class-imbalance usually work by training on a re-weighted loss or on re-balanced data. Unfortunately, training overparameterized neural networks on such objectives causes rapid memorization of minority class data. To avoid this trap, we harness meta-learning, which uses both an ''outer-loop'' and an ''inner-loop'' loss, each of which may be balanced using different strategies. We evaluate our method, MetaBalance, on image classification, credit-card fraud detection, loan default prediction, and facial recognition tasks with severely imbalanced data, and we find that MetaBalance outperforms a wide array of popular re-sampling strategies.
A Framework for Understanding AI-Induced Field Change: How AI Technologies are Legitimized and Institutionalized
Aug 18, 2021
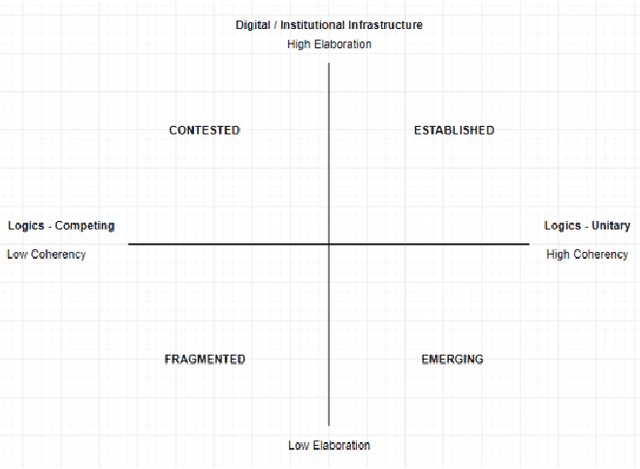
Artificial intelligence (AI) systems operate in increasingly diverse areas, from healthcare to facial recognition, the stock market, autonomous vehicles, and so on. While the underlying digital infrastructure of AI systems is developing rapidly, each area of implementation is subject to different degrees and processes of legitimization. By combining elements from institutional theory and information systems-theory, this paper presents a conceptual framework to analyze and understand AI-induced field-change. The introduction of novel AI-agents into new or existing fields creates a dynamic in which algorithms (re)shape organizations and institutions while existing institutional infrastructures determine the scope and speed at which organizational change is allowed to occur. Where institutional infrastructure and governance arrangements, such as standards, rules, and regulations, still are unelaborate, the field can move fast but is also more likely to be contested. The institutional infrastructure surrounding AI-induced fields is generally little elaborated, which could be an obstacle to the broader institutionalization of AI-systems going forward.
* 10 pages, 2 figures
Spatiotemporal Inconsistency Learning for DeepFake Video Detection
Sep 07, 2021
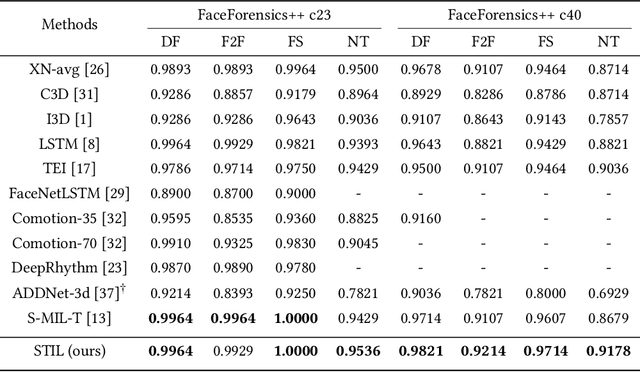
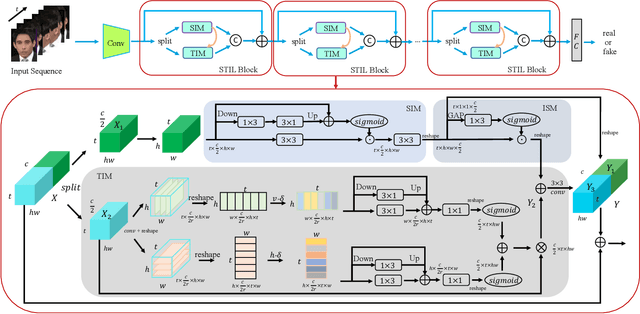
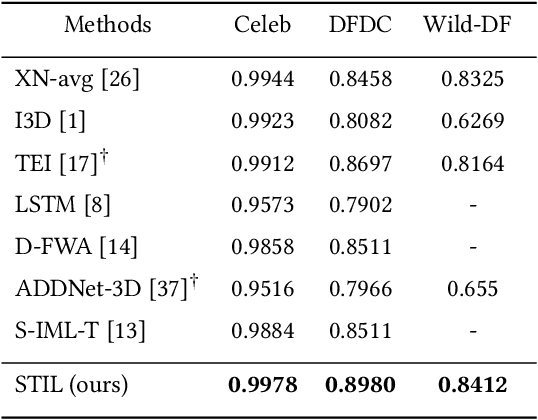
The rapid development of facial manipulation techniques has aroused public concerns in recent years. Following the success of deep learning, existing methods always formulate DeepFake video detection as a binary classification problem and develop frame-based and video-based solutions. However, little attention has been paid to capturing the spatial-temporal inconsistency in forged videos. To address this issue, we term this task as a Spatial-Temporal Inconsistency Learning (STIL) process and instantiate it into a novel STIL block, which consists of a Spatial Inconsistency Module (SIM), a Temporal Inconsistency Module (TIM), and an Information Supplement Module (ISM). Specifically, we present a novel temporal modeling paradigm in TIM by exploiting the temporal difference over adjacent frames along with both horizontal and vertical directions. And the ISM simultaneously utilizes the spatial information from SIM and temporal information from TIM to establish a more comprehensive spatial-temporal representation. Moreover, our STIL block is flexible and could be plugged into existing 2D CNNs. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the state-of-the-art competitors.
MakeupBag: Disentangling Makeup Extraction and Application
Dec 03, 2020
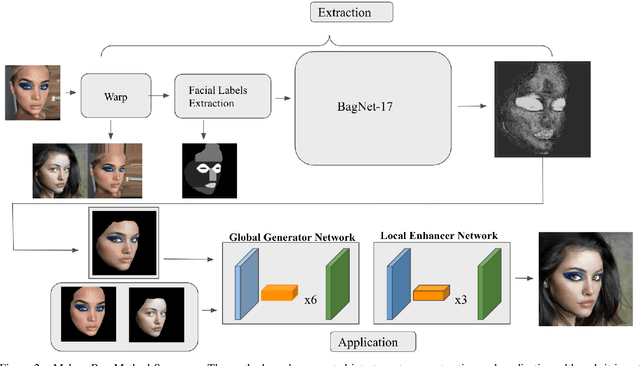


This paper introduces MakeupBag, a novel method for automatic makeup style transfer. Our proposed technique can transfer a new makeup style from a reference face image to another previously unseen facial photograph. We solve makeup disentanglement and facial makeup application as separable objectives, in contrast to other current deep methods that entangle the two tasks. MakeupBag presents a significant advantage for our approach as it allows customization and pixel specific modification of the extracted makeup style, which is not possible using current methods. Extensive experiments, both qualitative and numerical, are conducted demonstrating the high quality and accuracy of the images produced by our method. Furthermore, in contrast to most other current methods, MakeupBag tackles both classical and extreme and costume makeup transfer. In a comparative analysis, MakeupBag is shown to outperform current state-of-the-art approaches.