 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Transferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021




Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.
Unobtrusive Pain Monitoring in Older Adults with Dementia using Pairwise and Contrastive Training
Jan 08, 2021
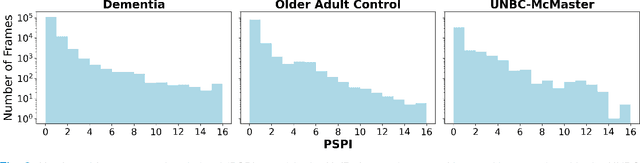
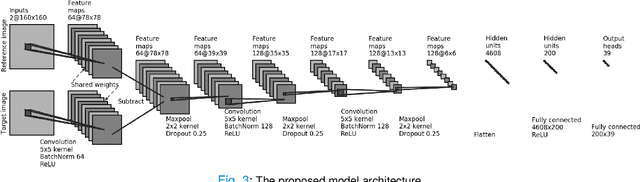
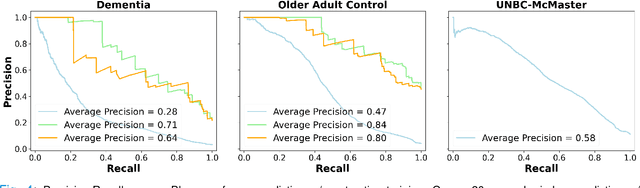
Although pain is frequent in old age, older adults are often undertreated for pain. This is especially the case for long-term care residents with moderate to severe dementia who cannot report their pain because of cognitive impairments that accompany dementia. Nursing staff acknowledge the challenges of effectively recognizing and managing pain in long-term care facilities due to lack of human resources and, sometimes, expertise to use validated pain assessment approaches on a regular basis. Vision-based ambient monitoring will allow for frequent automated assessments so care staff could be automatically notified when signs of pain are displayed. However, existing computer vision techniques for pain detection are not validated on faces of older adults or people with dementia, and this population is not represented in existing facial expression datasets of pain. We present the first fully automated vision-based technique validated on a dementia cohort. Our contributions are threefold. First, we develop a deep learning-based computer vision system for detecting painful facial expressions on a video dataset that is collected unobtrusively from older adult participants with and without dementia. Second, we introduce a pairwise comparative inference method that calibrates to each person and is sensitive to changes in facial expression while using training data more efficiently than sequence models. Third, we introduce a fast contrastive training method that improves cross-dataset performance. Our pain estimation model outperforms baselines by a wide margin, especially when evaluated on faces of people with dementia. Pre-trained model and demo code available at https://github.com/TaatiTeam/pain_detection_demo
Learning Emotional-Blinded Face Representations
Sep 18, 2020
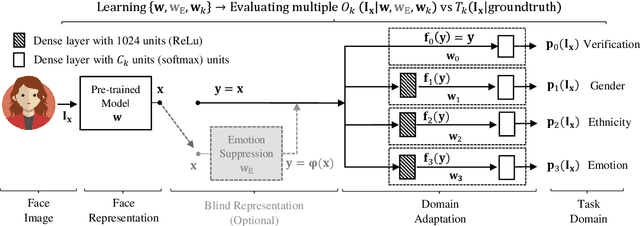
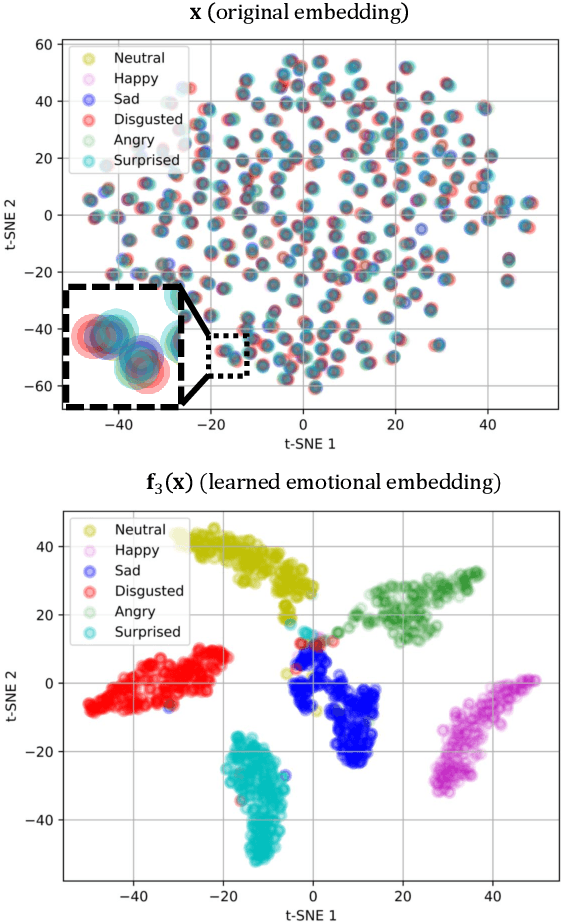
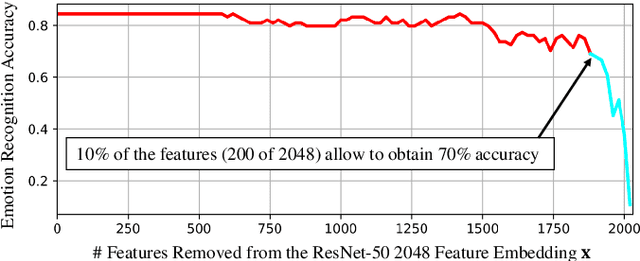
We propose two face representations that are blind to facial expressions associated to emotional responses. This work is in part motivated by new international regulations for personal data protection, which enforce data controllers to protect any kind of sensitive information involved in automatic processes. The advances in Affective Computing have contributed to improve human-machine interfaces but, at the same time, the capacity to monitorize emotional responses triggers potential risks for humans, both in terms of fairness and privacy. We propose two different methods to learn these expression-blinded facial features. We show that it is possible to eliminate information related to emotion recognition tasks, while the performance of subject verification, gender recognition, and ethnicity classification are just slightly affected. We also present an application to train fairer classifiers in a case study of attractiveness classification with respect to a protected facial expression attribute. The results demonstrate that it is possible to reduce emotional information in the face representation while retaining competitive performance in other face-based artificial intelligence tasks.
Speech Dialogue with Facial Displays: Multimodal Human-Computer Conversation
Jun 01, 1994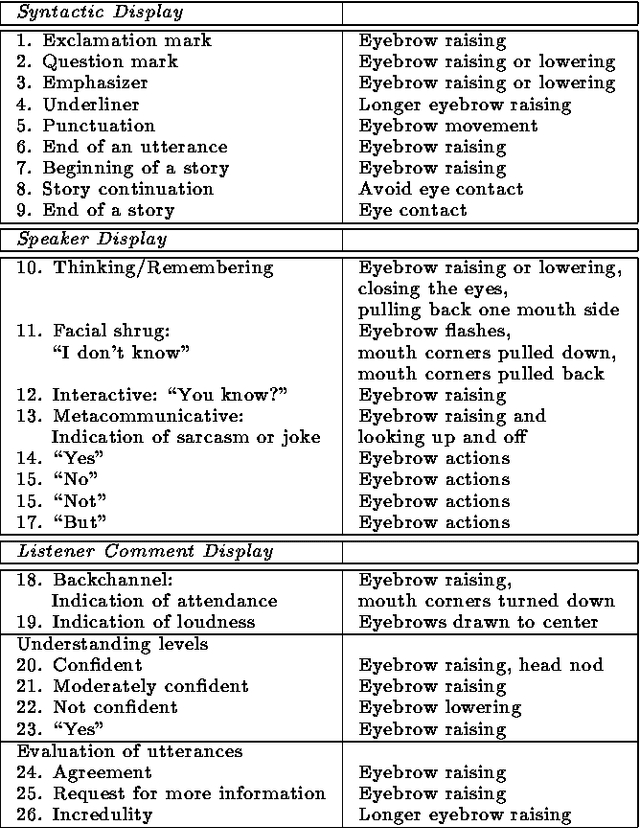
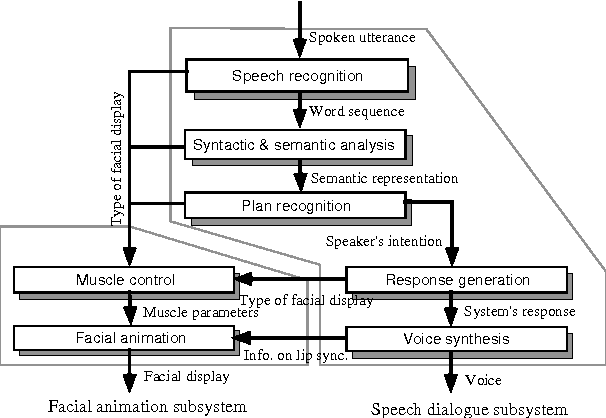

Human face-to-face conversation is an ideal model for human-computer dialogue. One of the major features of face-to-face communication is its multiplicity of communication channels that act on multiple modalities. To realize a natural multimodal dialogue, it is necessary to study how humans perceive information and determine the information to which humans are sensitive. A face is an independent communication channel that conveys emotional and conversational signals, encoded as facial expressions. We have developed an experimental system that integrates speech dialogue and facial animation, to investigate the effect of introducing communicative facial expressions as a new modality in human-computer conversation. Our experiments have shown that facial expressions are helpful, especially upon first contact with the system. We have also discovered that featuring facial expressions at an early stage improves subsequent interaction.
Real-time Emotion and Gender Classification using Ensemble CNN
Nov 15, 2021

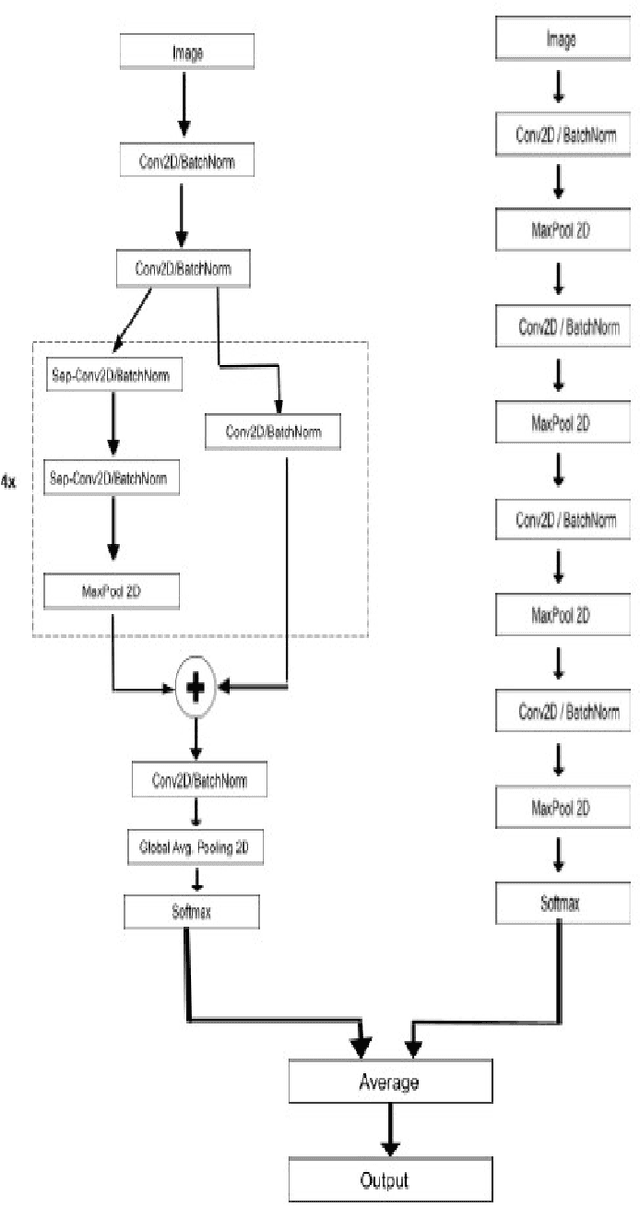
Analysing expressions on the person's face plays a very vital role in identifying emotions and behavior of a person. Recognizing these expressions automatically results in a crucial component of natural human-machine interfaces. Therefore research in this field has a wide range of applications in bio-metric authentication, surveillance systems , emotion to emoticons in various social media platforms. Another application includes conducting customer satisfaction surveys. As we know that the large corporations made huge investments to get feedback and do surveys but fail to get equitable responses. Emotion & Gender recognition through facial gestures is a technology that aims to improve product and services performance by monitoring customer behavior to specific products or service staff by their evaluation. In the past few years there have been a wide variety of advances performed in terms of feature extraction mechanisms , detection of face and also expression classification techniques. This paper is the implementation of an Ensemble CNN for building a real-time system that can detect emotion and gender of the person. The experimental results shows accuracy of 68% for Emotion classification into 7 classes (angry, fear , sad , happy , surprise , neutral , disgust) on FER-2013 dataset and 95% for Gender classification (Male or Female) on IMDB dataset. Our work can predict emotion and gender on single face images as well as multiple face images. Also when input is given through webcam our complete pipeline of this real-time system can take less than 0.5 seconds to generate results.
A Multi-task Mean Teacher for Semi-supervised Facial Affective Behavior Analysis
Jul 13, 2021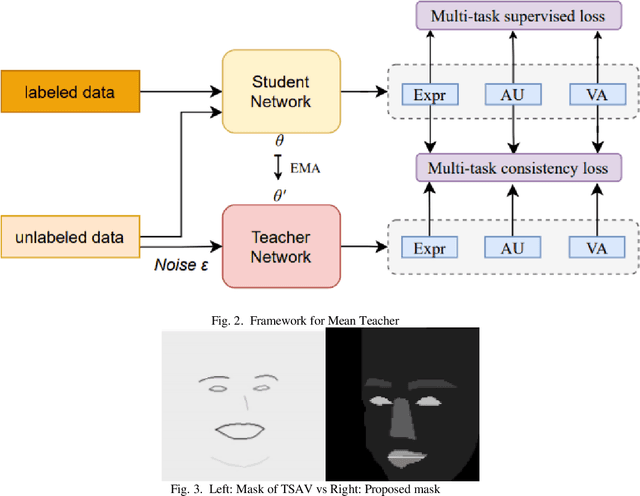
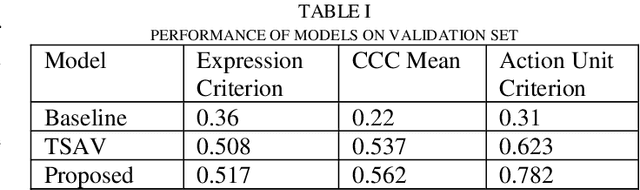
Affective Behavior Analysis is an important part in human-computer interaction. Existing successful affective behavior analysis method such as TSAV[9] suffer from challenge of incomplete labeled datasets. To boost its performance, this paper presents a multi-task mean teacher model for semi-supervised Affective Behavior Analysis to learn from missing labels and exploring the learning of multiple correlated task simultaneously. To be specific, we first utilize TSAV as baseline model to simultaneously recognize the three tasks. We have modified the preprocessing method of rendering mask to provide better semantics information. After that, we extended TSAV model to semi-supervised model using mean teacher, which allow it to be benefited from unlabeled data. Experimental results on validation datasets show that our method achieves better performance than TSAV model, which verifies that the proposed network can effectively learn additional unlabeled data to boost the affective behavior analysis performance.
Feature Pyramid Network for Multi-task Affective Analysis
Jul 09, 2021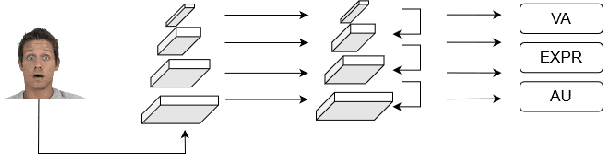
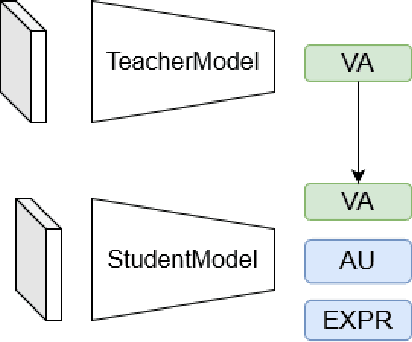
Affective Analysis is not a single task, and the valence-arousal value, expression class and action unit can be predicted at the same time. Previous researches failed to take them as a whole task or ignore the entanglement and hierarchical relation of this three facial attributes. We propose a novel model named feature pyramid networks for multi-task affect analysis. The hierarchical features are extracted to predict three labels and we apply teacher-student training strategy to learn from pretrained single-task models. Extensive experiment results demonstrate the proposed model outperform other models.This is a submission to The 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). The code and model are available for research purposes at https://github.com/ryanhe312/ABAW2-FPNMAA.
Lie-Sensor: A Live Emotion Verifier or a Licensor for Chat Applications using Emotional Intelligence
Feb 11, 2021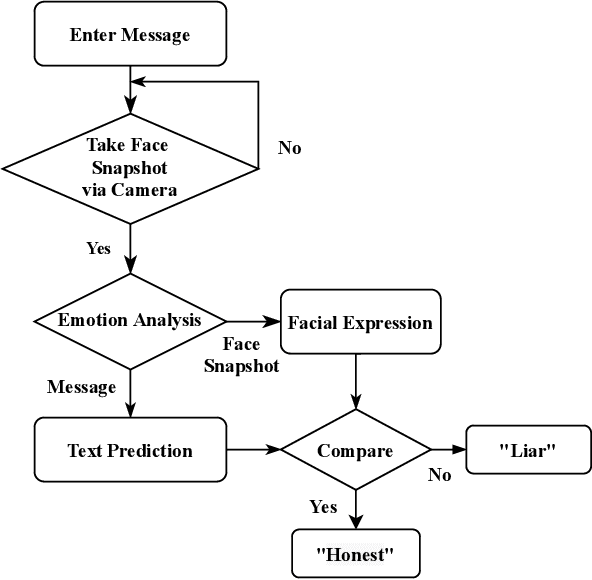
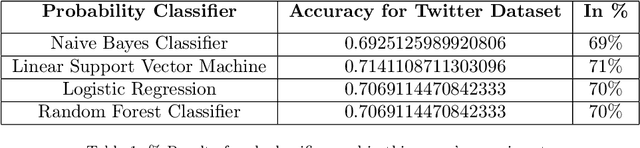
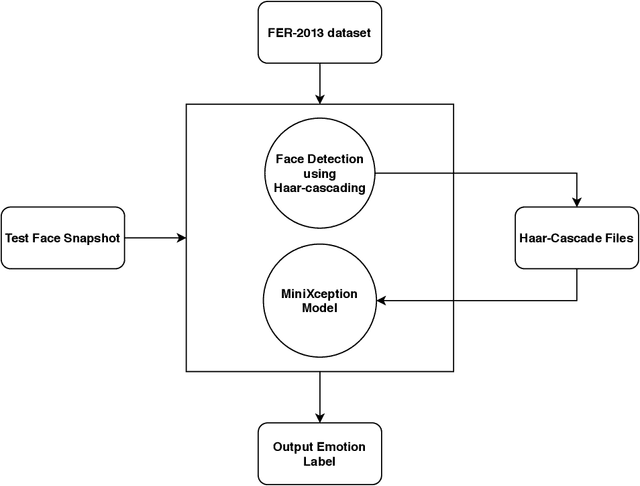

Veracity is an essential key in research and development of innovative products. Live Emotion analysis and verification nullify deceit made to complainers on live chat, corroborate messages of both ends in messaging apps and promote an honest conversation between users. The main concept behind this emotion artificial intelligent verifier is to license or decline message accountability by comparing variegated emotions of chat app users recognized through facial expressions and text prediction. In this paper, a proposed emotion intelligent live detector acts as an honest arbiter who distributes facial emotions into labels namely, Happiness, Sadness, Surprise, and Hate. Further, it separately predicts a label of messages through text classification. Finally, it compares both labels and declares the message as a fraud or a bonafide. For emotion detection, we deployed Convolutional Neural Network (CNN) using a miniXception model and for text prediction, we selected Support Vector Machine (SVM) natural language processing probability classifier due to receiving the best accuracy on training dataset after applying Support Vector Machine (SVM), Random Forest Classifier, Naive Bayes Classifier, and Logistic regression.
MOS: A Low Latency and Lightweight Framework for Face Detection, Landmark Localization, and Head Pose Estimation
Nov 01, 2021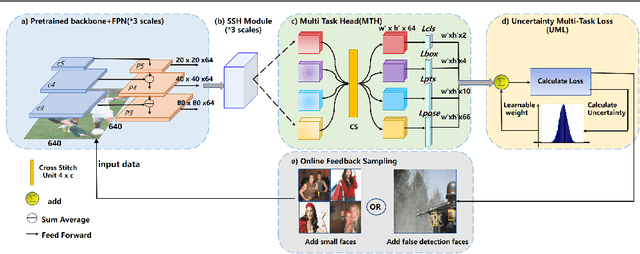
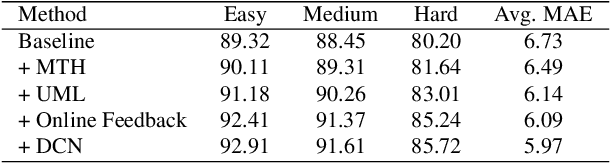
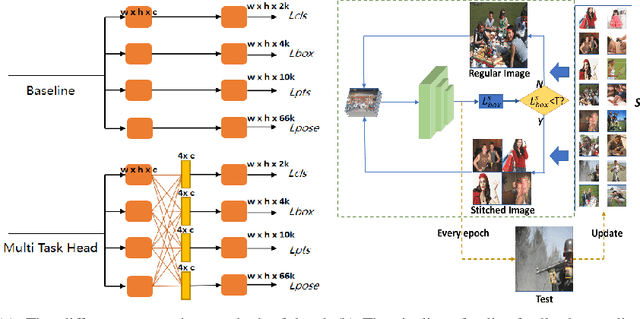
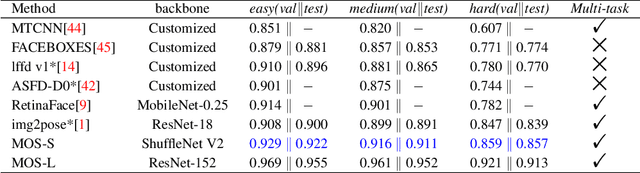
With the emergence of service robots and surveillance cameras, dynamic face recognition (DFR) in wild has received much attention in recent years. Face detection and head pose estimation are two important steps for DFR. Very often, the pose is estimated after the face detection. However, such sequential computations lead to higher latency. In this paper, we propose a low latency and lightweight network for simultaneous face detection, landmark localization and head pose estimation. Inspired by the observation that it is more challenging to locate the facial landmarks for faces with large angles, a pose loss is proposed to constrain the learning. Moreover, we also propose an uncertainty multi-task loss to learn the weights of individual tasks automatically. Another challenge is that robots often use low computational units like ARM based computing core and we often need to use lightweight networks instead of the heavy ones, which lead to performance drop especially for small and hard faces. In this paper, we propose online feedback sampling to augment the training samples across different scales, which increases the diversity of training data automatically. Through validation in commonly used WIDER FACE, AFLW and AFLW2000 datasets, the results show that the proposed method achieves the state-of-the-art performance in low computational resources. The code and data will be available at https://github.com/lyp-deeplearning/MOS-Multi-Task-Face-Detect.
Fawkes: Protecting Personal Privacy against Unauthorized Deep Learning Models
Feb 19, 2020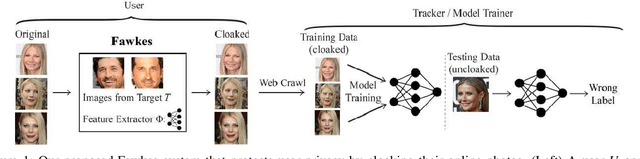

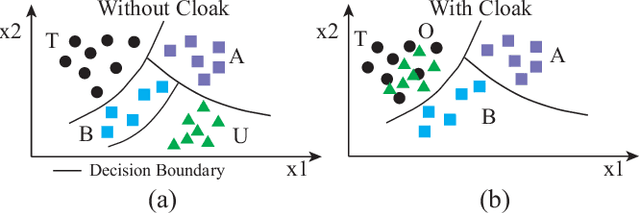
Today's proliferation of powerful facial recognition models poses a real threat to personal privacy. As Clearview.ai demonstrated, anyone can canvas the Internet for data, and train highly accurate facial recognition models of us without our knowledge. We need tools to protect ourselves from unauthorized facial recognition systems and their numerous potential misuses. Unfortunately, work in related areas are limited in practicality and effectiveness. In this paper, we propose Fawkes, a system that allow individuals to inoculate themselves against unauthorized facial recognition models. Fawkes achieves this by helping users adding imperceptible pixel-level changes (we call them "cloaks") to their own photos before publishing them online. When collected by a third-party "tracker" and used to train facial recognition models, these "cloaked" images produce functional models that consistently misidentify the user. We experimentally prove that Fawkes provides 95+% protection against user recognition regardless of how trackers train their models. Even when clean, uncloaked images are "leaked" to the tracker and used for training, Fawkes can still maintain a 80+% protection success rate. In fact, we perform real experiments against today's state-of-the-art facial recognition services and achieve 100% success. Finally, we show that Fawkes is robust against a variety of countermeasures that try to detect or disrupt cloaks.