 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
On Recognizing Occluded Faces in the Wild
Sep 11, 2021


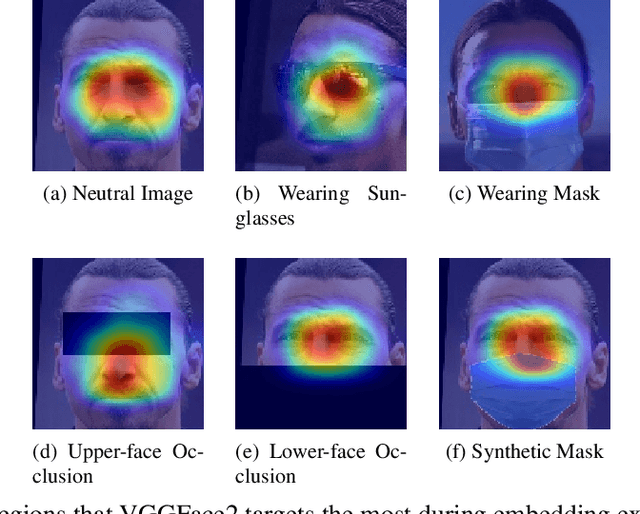
Facial appearance variations due to occlusion has been one of the main challenges for face recognition systems. To facilitate further research in this area, it is necessary and important to have occluded face datasets collected from real-world, as synthetically generated occluded faces cannot represent the nature of the problem. In this paper, we present the Real World Occluded Faces (ROF) dataset, that contains faces with both upper face occlusion, due to sunglasses, and lower face occlusion, due to masks. We propose two evaluation protocols for this dataset. Benchmark experiments on the dataset have shown that no matter how powerful the deep face representation models are, their performance degrades significantly when they are tested on real-world occluded faces. It is observed that the performance drop is far less when the models are tested on synthetically generated occluded faces. The ROF dataset and the associated evaluation protocols are publicly available at the following link https://github.com/ekremerakin/RealWorldOccludedFaces.
Attribute-Based Deep Periocular Recognition: Leveraging Soft Biometrics to Improve Periocular Recognition
Nov 02, 2021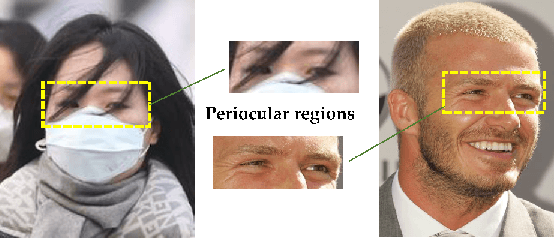
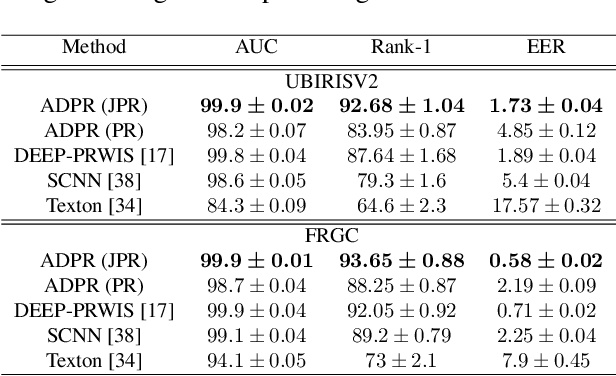

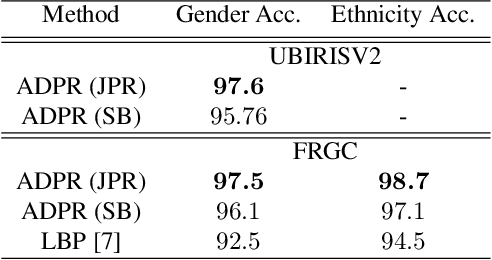
In recent years, periocular recognition has been developed as a valuable biometric identification approach, especially in wild environments (for example, masked faces due to COVID-19 pandemic) where facial recognition may not be applicable. This paper presents a new deep periocular recognition framework called attribute-based deep periocular recognition (ADPR), which predicts soft biometrics and incorporates the prediction into a periocular recognition algorithm to determine identity from periocular images with high accuracy. We propose an end-to-end framework, which uses several shared convolutional neural network (CNN)layers (a common network) whose output feeds two separate dedicated branches (modality dedicated layers); the first branch classifies periocular images while the second branch predicts softn biometrics. Next, the features from these two branches are fused together for a final periocular recognition. The proposed method is different from existing methods as it not only uses a shared CNN feature space to train these two tasks jointly, but it also fuses predicted soft biometric features with the periocular features in the training step to improve the overall periocular recognition performance. Our proposed model is extensively evaluated using four different publicly available datasets. Experimental results indicate that our soft biometric based periocular recognition approach outperforms other state-of-the-art methods for periocular recognition in wild environments.
CapsField: Light Field-based Face and Expression Recognition in the Wild using Capsule Routing
Jan 10, 2021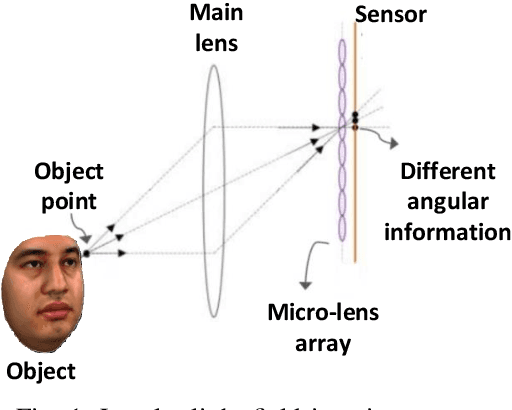
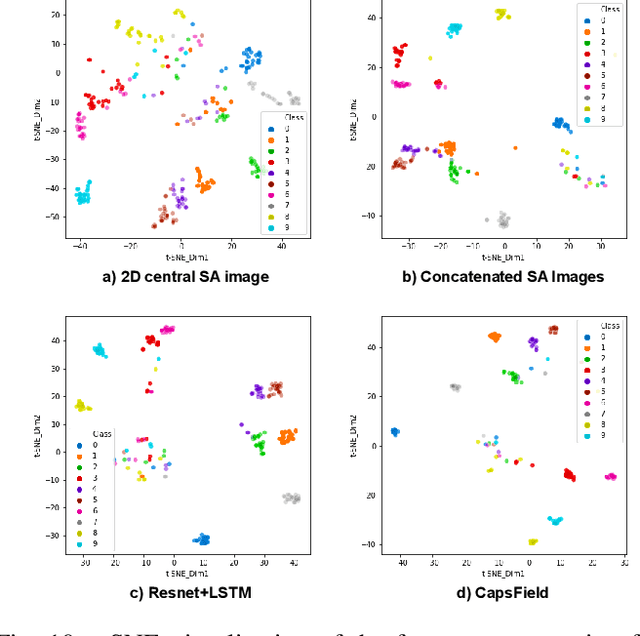
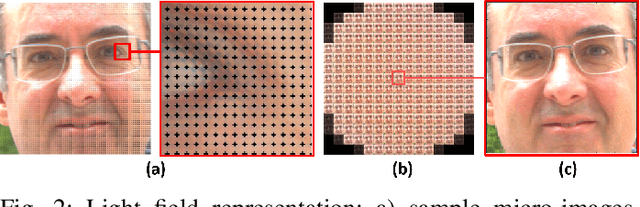
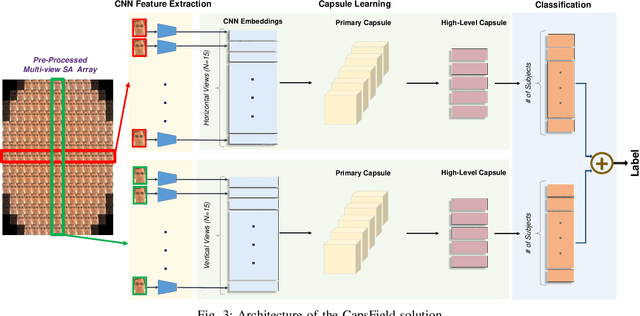
Light field (LF) cameras provide rich spatio-angular visual representations by sensing the visual scene from multiple perspectives and have recently emerged as a promising technology to boost the performance of human-machine systems such as biometrics and affective computing. Despite the significant success of LF representation for constrained facial image analysis, this technology has never been used for face and expression recognition in the wild. In this context, this paper proposes a new deep face and expression recognition solution, called CapsField, based on a convolutional neural network and an additional capsule network that utilizes dynamic routing to learn hierarchical relations between capsules. CapsField extracts the spatial features from facial images and learns the angular part-whole relations for a selected set of 2D sub-aperture images rendered from each LF image. To analyze the performance of the proposed solution in the wild, the first in the wild LF face dataset, along with a new complementary constrained face dataset captured from the same subjects recorded earlier have been captured and are made available. A subset of the in the wild dataset contains facial images with different expressions, annotated for usage in the context of face expression recognition tests. An extensive performance assessment study using the new datasets has been conducted for the proposed and relevant prior solutions, showing that the CapsField proposed solution achieves superior performance for both face and expression recognition tasks when compared to the state-of-the-art.
Detailed Region-Adaptive Normalization for Heavy Makeup Transfer
Sep 30, 2021

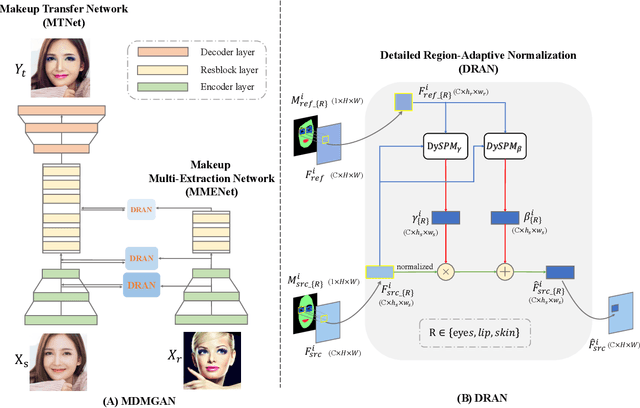
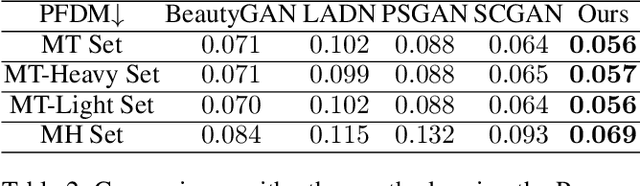
In recent years, facial makeup transfer has attracted growing attention due to its efficiency and flexibility in transferring makeup styles between different faces. Although recent works have achieved realistic results, most of them fail to handle heavy makeup styles with multiple colors and subtle details. Hence we propose a novel GAN model to handle heavy makeup transfer, while maintaining the robustness to different poses and expressions. Firstly, a Makeup Multi-Extraction Network is introduced to learn region-wise makeup features from multiple layers. Then, a key transferring module called Detailed Region-Adaptive Normalization is proposed to fuse different levels of makeup styles in an adaptive way, making great improvement to the quality of heavy makeup transfer. With the outputs from the two components, Makeup Transfer Network is used to perform makeup transfer. To evaluate the efficacy of our proposed method, we collected a new makeup dataset containing a wide range of heavy styles. Experiments show that our method achieves state-of-the-art results both on light and heavy makeup styles, and is robust to different poses and expressions.
Spatio-Temporal Attention Mechanism and Knowledge Distillation for Lip Reading
Aug 07, 2021
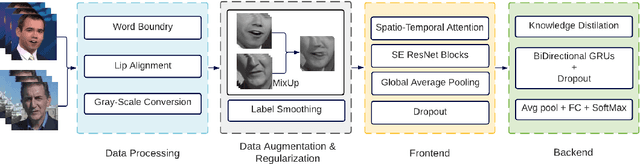
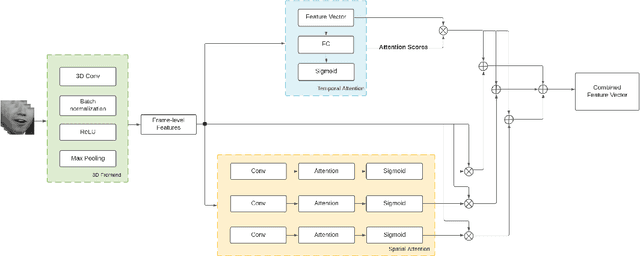

Despite the advancement in the domain of audio and audio-visual speech recognition, visual speech recognition systems are still quite under-explored due to the visual ambiguity of some phonemes. In this work, we propose a new lip-reading model that combines three contributions. First, the model front-end adopts a spatio-temporal attention mechanism to help extract the informative data from the input visual frames. Second, the model back-end utilizes a sequence-level and frame-level Knowledge Distillation (KD) techniques that allow leveraging audio data during the visual model training. Third, a data preprocessing pipeline is adopted that includes facial landmarks detection-based lip-alignment. On LRW lip-reading dataset benchmark, a noticeable accuracy improvement is demonstrated; the spatio-temporal attention, Knowledge Distillation, and lip-alignment contributions achieved 88.43%, 88.64%, and 88.37% respectively.
Disentangling Latent Space for Unsupervised Semantic Face Editing
Nov 05, 2020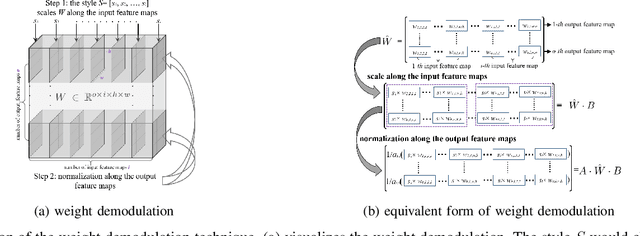
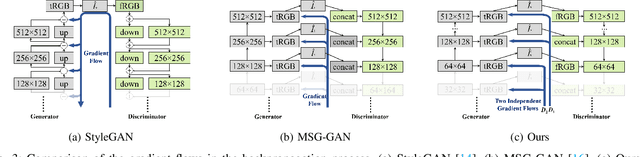

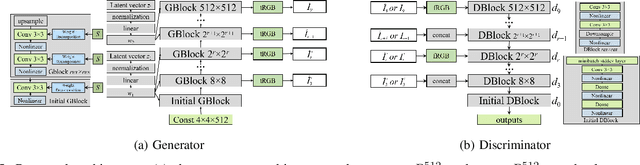
Editing facial images created by StyleGAN is a popular research topic with important applications. Through editing the latent vectors, it is possible to control the facial attributes such as smile, age, \textit{etc}. However, facial attributes are entangled in the latent space and this makes it very difficult to independently control a specific attribute without affecting the others. The key to developing neat semantic control is to completely disentangle the latent space and perform image editing in an unsupervised manner. In this paper, we present a new technique termed Structure-Texture Independent Architecture with Weight Decomposition and Orthogonal Regularization (STIA-WO) to disentangle the latent space. The GAN model, applying STIA-WO, is referred to as STGAN-WO. STGAN-WO performs weight decomposition by utilizing the style vector to construct a fully controllable weight matrix for controlling the image synthesis, and utilizes orthogonal regularization to ensure each entry of the style vector only controls one factor of variation. To further disentangle the facial attributes, STGAN-WO introduces a structure-texture independent architecture which utilizes two independently and identically distributed (i.i.d.) latent vectors to control the synthesis of the texture and structure components in a disentangled way.Unsupervised semantic editing is achieved by moving the latent code in the coarse layers along its orthogonal directions to change texture related attributes or changing the latent code in the fine layers to manipulate structure related ones. We present experimental results which show that our new STGAN-WO can achieve better attribute editing than state of the art methods (The code is available at https://github.com/max-liu-112/STGAN-WO)
NimbRo Avatar: Interactive Immersive Telepresence with Force-Feedback Telemanipulation
Sep 28, 2021

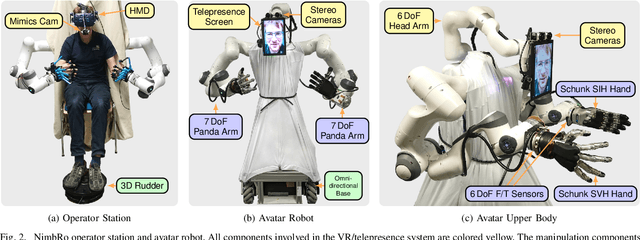
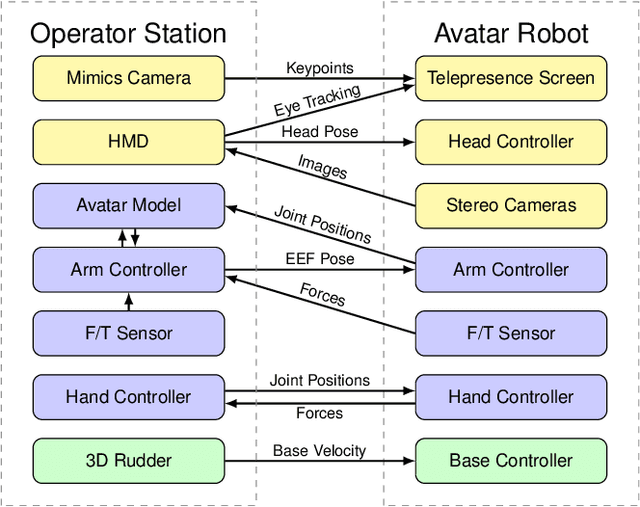
Robotic avatars promise immersive teleoperation with human-like manipulation and communication capabilities. We present such an avatar system, based on the key components of immersive 3D visualization and transparent force-feedback telemanipulation. Our avatar robot features an anthropomorphic bimanual arm configuration with dexterous hands. The remote human operator drives the arms and fingers through an exoskeleton-based operator station, which provides force feedback both at the wrist and for each finger. The robot torso is mounted on a holonomic base, providing locomotion capability in typical indoor scenarios, controlled using a 3D rudder device. Finally, the robot features a 6D movable head with stereo cameras, which stream images to a VR HMD worn by the operator. Movement latency is hidden using spherical rendering. The head also carries a telepresence screen displaying a synthesized image of the operator with facial animation, which enables direct interaction with remote persons. We evaluate our system successfully both in a user study with untrained operators as well as a longer and more complex integrated mission. We discuss lessons learned from the trials and possible improvements.
Sequential Clustering based Facial Feature Extraction Method for Automatic Creation of Facial Models from Orthogonal Views
Dec 03, 2009
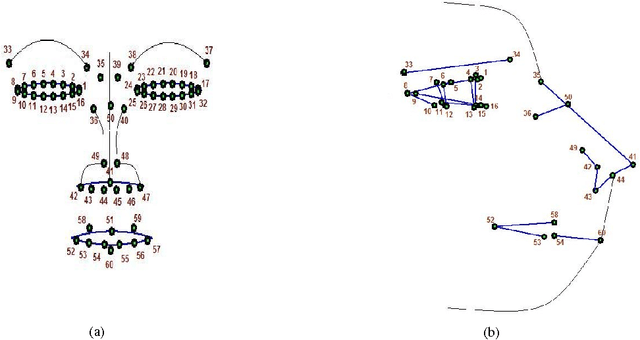

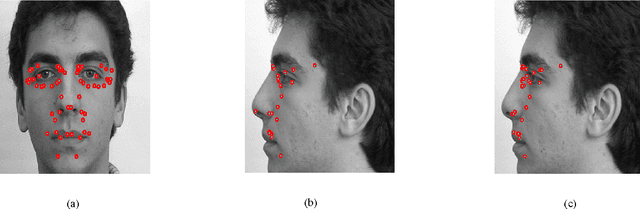
Multiview 3D face modeling has attracted increasing attention recently and has become one of the potential avenues in future video systems. We aim to make more reliable and robust automatic feature extraction and natural 3D feature construction from 2D features detected on a pair of frontal and profile view face images. We propose several heuristic algorithms to minimize possible errors introduced by prevalent nonperfect orthogonal condition and noncoherent luminance. In our approach, we first extract the 2D features that are visible to both cameras in both views. Then, we estimate the coordinates of the features in the hidden profile view based on the visible features extracted in the two orthogonal views. Finally, based on the coordinates of the extracted features, we deform a 3D generic model to perform the desired 3D clone modeling. Present study proves the scope of resulted facial models for practical applications like face recognition and facial animation.
* 6 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS November 2009, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
Pipeline Generative Adversarial Networks for Facial Images Generation with Multiple Attributes
Nov 29, 2017
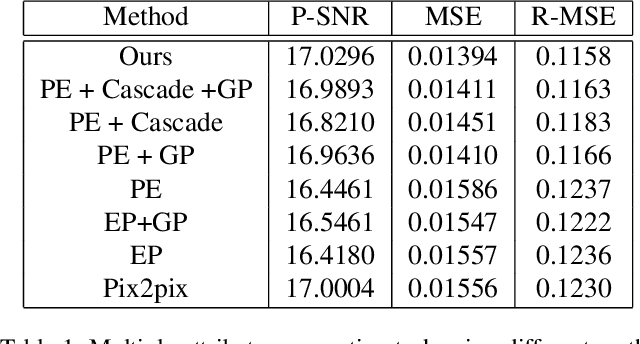
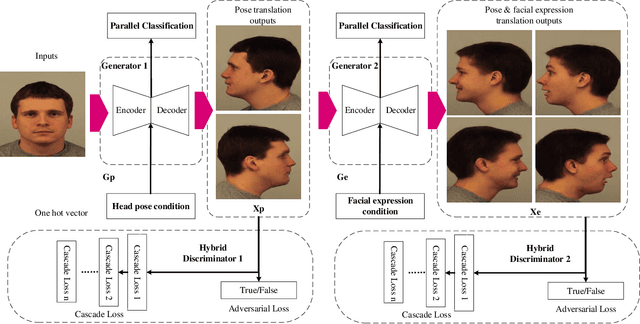
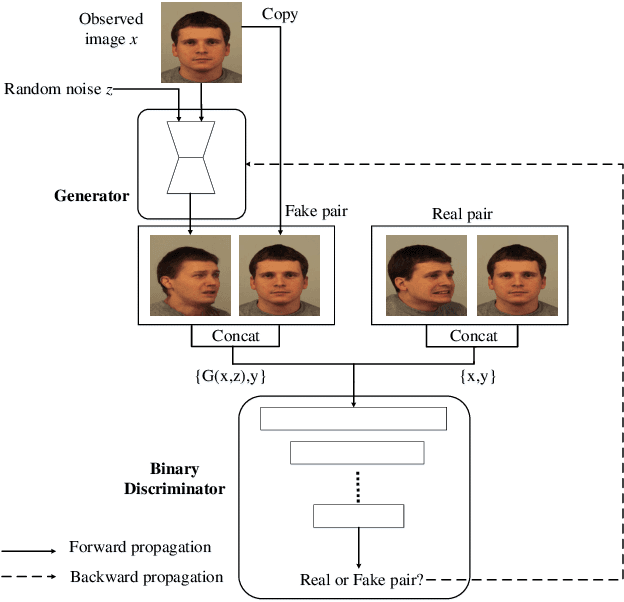
Generative Adversarial Networks are proved to be efficient on various kinds of image generation tasks. However, it is still a challenge if we want to generate images precisely. Many researchers focus on how to generate images with one attribute. But image generation under multiple attributes is still a tough work. In this paper, we try to generate a variety of face images under multiple constraints using a pipeline process. The Pip-GAN (Pipeline Generative Adversarial Network) we present employs a pipeline network structure which can generate a complex facial image step by step using a neutral face image. We applied our method on two face image databases and demonstrate its ability to generate convincing novel images of unseen identities under multiple conditions previously.