 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Partial Attack Supervision and Regional Weighted Inference for Masked Face Presentation Attack Detection
Nov 08, 2021

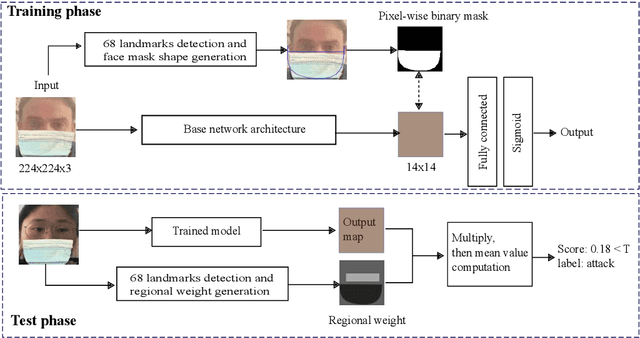
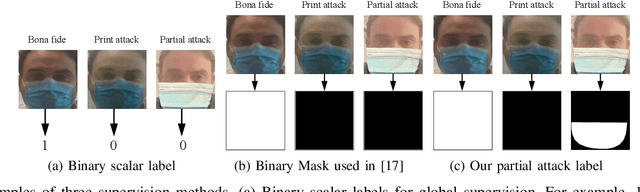
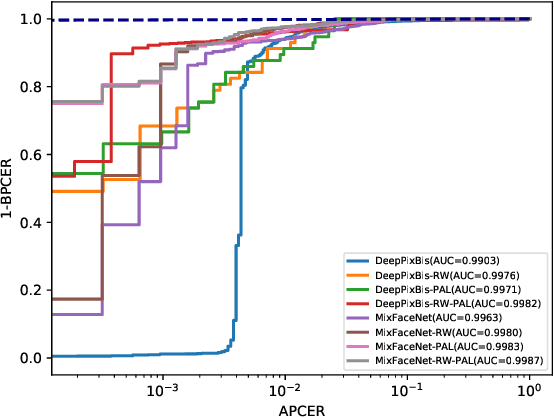
Wearing a mask has proven to be one of the most effective ways to prevent the transmission of SARS-CoV-2 coronavirus. However, wearing a mask poses challenges for different face recognition tasks and raises concerns about the performance of masked face presentation detection (PAD). The main issues facing the mask face PAD are the wrongly classified bona fide masked faces and the wrongly classified partial attacks (covered by real masks). This work addresses these issues by proposing a method that considers partial attack labels to supervise the PAD model training, as well as regional weighted inference to further improve the PAD performance by varying the focus on different facial areas. Our proposed method is not directly linked to specific network architecture and thus can be directly incorporated into any common or custom-designed network. In our work, two neural networks (DeepPixBis and MixFaceNet) are selected as backbones. The experiments are demonstrated on the collaborative real mask attack (CRMA) database. Our proposed method outperforms established PAD methods in the CRMA database by reducing the mentioned shortcomings when facing masked faces. Moreover, we present a detailed step-wise ablation study pointing out the individual and joint benefits of the proposed concepts on the overall PAD performance.
An Empirical Study of Dimensional Reduction Techniques for Facial Action Units Detection
Mar 25, 2016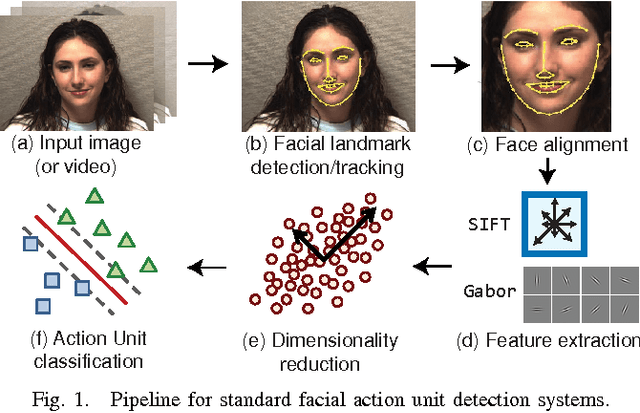

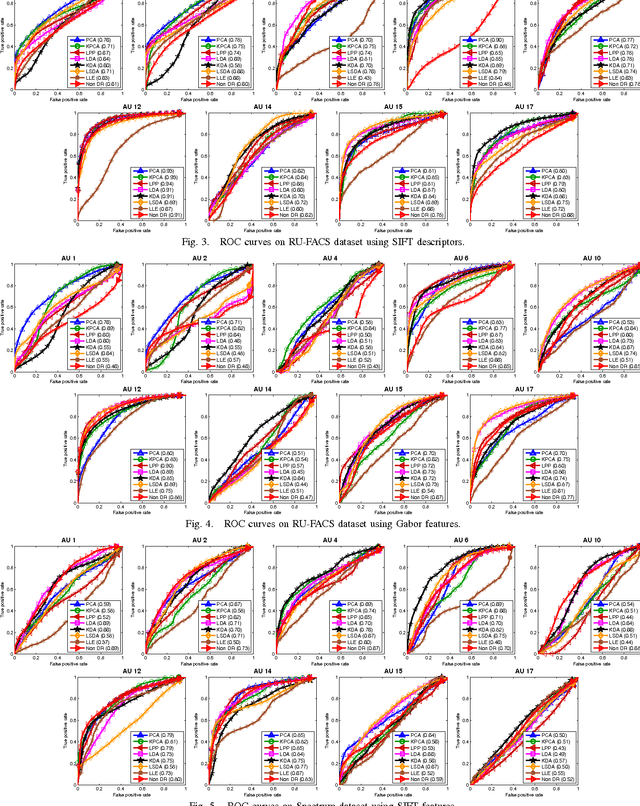
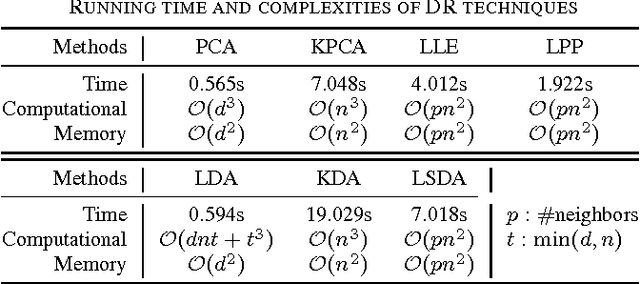
Biologically inspired features, such as Gabor filters, result in very high dimensional measurement. Does reducing the dimensionality of the feature space afford advantages beyond computational efficiency? Do some approaches to dimensionality reduction (DR) yield improved action unit detection? To answer these questions, we compared DR approaches in two relatively large databases of spontaneous facial behavior (45 participants in total with over 2 minutes of FACS-coded video per participant). Facial features were tracked and aligned using active appearance models (AAM). SIFT and Gabor features were extracted from local facial regions. We compared linear (PCA and KPCA), manifold (LPP and LLE), supervised (LDA and KDA) and hybrid approaches (LSDA) to DR with respect to AU detection. For further comparison, a no-DR control condition was included as well. Linear support vector machine classifiers with independent train and test sets were used for AU detection. AU detection was quantified using area under the ROC curve and F1. Baseline results for PCA with Gabor features were comparable with previous research. With some notable exceptions, DR improved AU detection relative to no-DR. Locality embedding approaches proved vulnerable to \emph{out-of-sample} problems. Gradient-based SIFT lead to better AU detection than the filter-based Gabor features. For area under the curve, few differences were found between linear and other DR approaches. For F1, results were mixed. For both metrics, the pattern of results varied among action units. These findings suggest that action unit detection may be optimized by using specific DR for specific action units. PCA and LDA were the most efficient approaches; KDA was the least efficient.
LiMuSE: Lightweight Multi-modal Speaker Extraction
Nov 07, 2021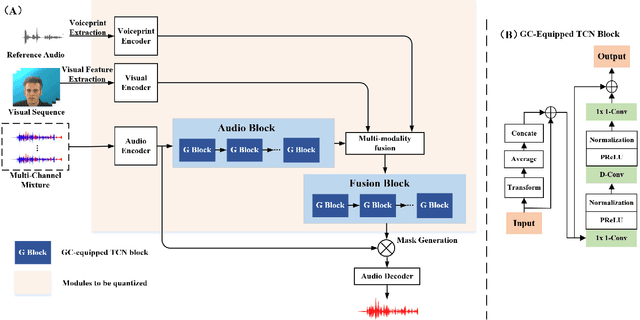

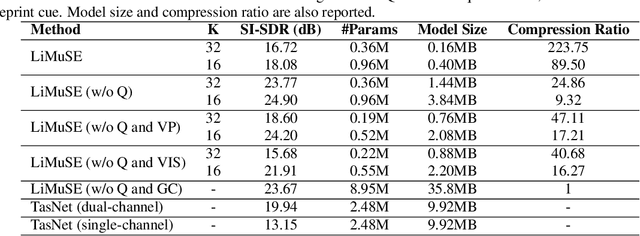
The past several years have witnessed significant progress in modeling the Cocktail Party Problem in terms of speech separation and speaker extraction. In recent years, multi-modal cues, including spatial information, facial expression and voiceprint, are introduced to speaker extraction task to serve as complementary information to each other to achieve better performance. However, the front-end model, for speaker extraction, become large and hard to deploy on a resource-constrained device. In this paper, we address the aforementioned problem with novel model architectures and model compression techniques, and propose a lightweight multi-modal framework for speaker extraction (dubbed LiMuSE), which adopts group communication (GC) to split multi-modal high-dimension features into groups of low-dimension features with smaller width which could be run in parallel, and further uses an ultra-low bit quantization strategy to achieve lower model size. The experiments on the GRID dataset show that incorporating GC into the multi-modal framework achieves on par or better performance with 24.86 times fewer parameters, and applying the quantization strategy to the GC-equipped model further obtains about 9 times compression ratio while maintaining a comparable performance compared with baselines. Our code will be available at https://github.com/aispeech-lab/LiMuSE.
Will You Ever Become Popular? Learning to Predict Virality of Dance Clips
Nov 06, 2021
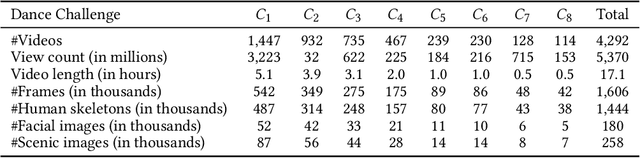
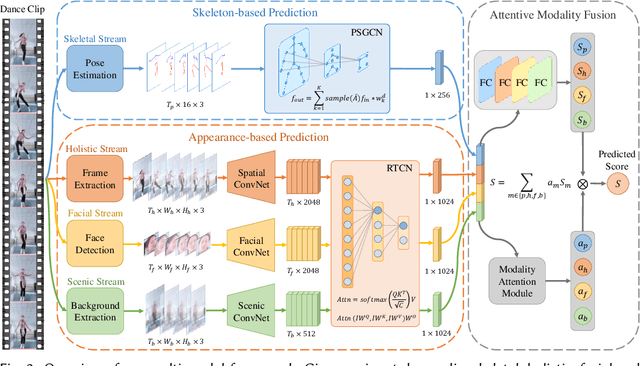
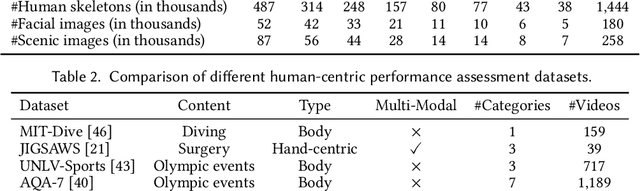
Dance challenges are going viral in video communities like TikTok nowadays. Once a challenge becomes popular, thousands of short-form videos will be uploaded in merely a couple of days. Therefore, virality prediction from dance challenges is of great commercial value and has a wide range of applications, such as smart recommendation and popularity promotion. In this paper, a novel multi-modal framework which integrates skeletal, holistic appearance, facial and scenic cues is proposed for comprehensive dance virality prediction. To model body movements, we propose a pyramidal skeleton graph convolutional network (PSGCN) which hierarchically refines spatio-temporal skeleton graphs. Meanwhile, we introduce a relational temporal convolutional network (RTCN) to exploit appearance dynamics with non-local temporal relations. An attentive fusion approach is finally proposed to adaptively aggregate predictions from different modalities. To validate our method, we introduce a large-scale viral dance video (VDV) dataset, which contains over 4,000 dance clips of eight viral dance challenges. Extensive experiments on the VDV dataset demonstrate the efficacy of our model. Extensive experiments on the VDV dataset well demonstrate the effectiveness of our approach. Furthermore, we show that short video applications like multi-dimensional recommendation and action feedback can be derived from our model.
Semantic Alignment: Finding Semantically Consistent Ground-truth for Facial Landmark Detection
Mar 26, 2019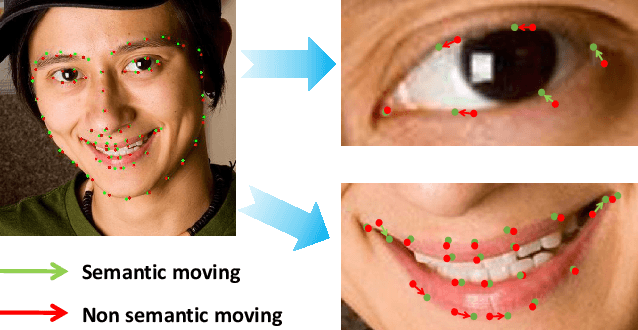
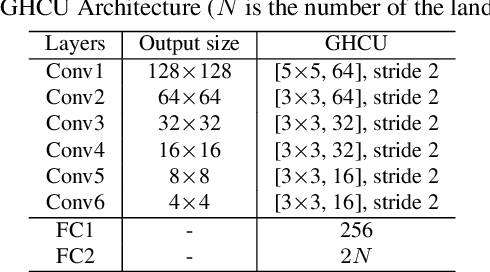
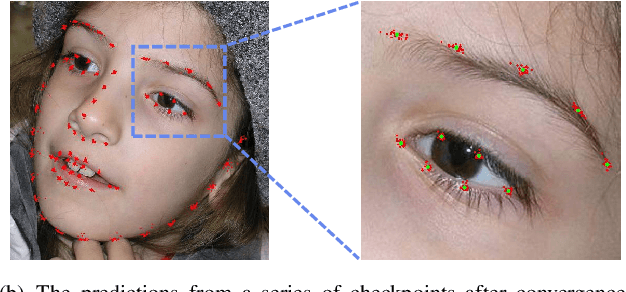
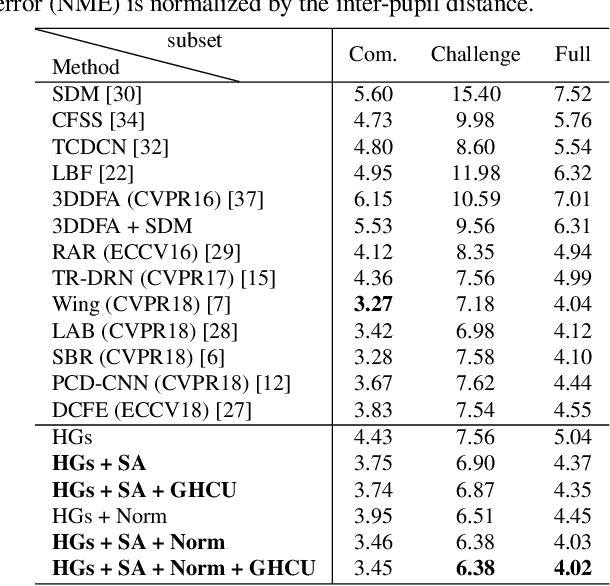
Recently, deep learning based facial landmark detection has achieved great success. Despite this, we notice that the semantic ambiguity greatly degrades the detection performance. Specifically, the semantic ambiguity means that some landmarks (e.g. those evenly distributed along the face contour) do not have clear and accurate definition, causing inconsistent annotations by annotators. Accordingly, these inconsistent annotations, which are usually provided by public databases, commonly work as the ground-truth to supervise network training, leading to the degraded accuracy. To our knowledge, little research has investigated this problem. In this paper, we propose a novel probabilistic model which introduces a latent variable, i.e. the 'real' ground-truth which is semantically consistent, to optimize. This framework couples two parts (1) training landmark detection CNN and (2) searching the 'real' ground-truth. These two parts are alternatively optimized: the searched 'real' ground-truth supervises the CNN training; and the trained CNN assists the searching of 'real' ground-truth. In addition, to recover the unconfidently predicted landmarks due to occlusion and low quality, we propose a global heatmap correction unit (GHCU) to correct outliers by considering the global face shape as a constraint. Extensive experiments on both image-based (300W and AFLW) and video-based (300-VW) databases demonstrate that our method effectively improves the landmark detection accuracy and achieves the state of the art performance.
Nose, eyes and ears: Head pose estimation by locating facial keypoints
Dec 03, 2018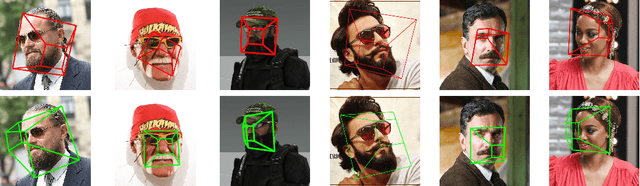
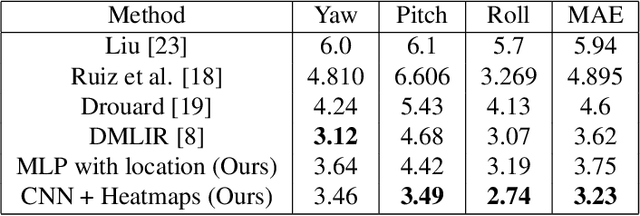

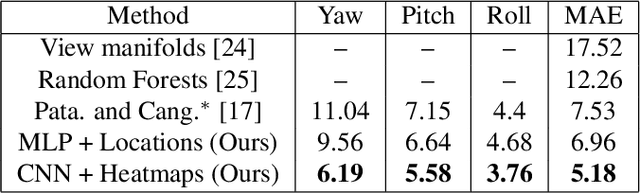
Monocular head pose estimation requires learning a model that computes the intrinsic Euler angles for pose (yaw, pitch, roll) from an input image of human face. Annotating ground truth head pose angles for images in the wild is difficult and requires ad-hoc fitting procedures (which provides only coarse and approximate annotations). This highlights the need for approaches which can train on data captured in controlled environment and generalize on the images in the wild (with varying appearance and illumination of the face). Most present day deep learning approaches which learn a regression function directly on the input images fail to do so. To this end, we propose to use a higher level representation to regress the head pose while using deep learning architectures. More specifically, we use the uncertainty maps in the form of 2D soft localization heatmap images over five facial keypoints, namely left ear, right ear, left eye, right eye and nose, and pass them through an convolutional neural network to regress the head-pose. We show head pose estimation results on two challenging benchmarks BIWI and AFLW and our approach surpasses the state of the art on both the datasets.
Learning Oracle Attention for High-fidelity Face Completion
Mar 31, 2020
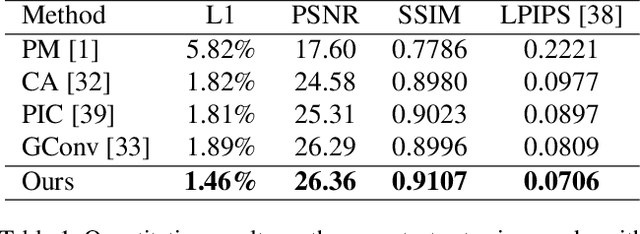
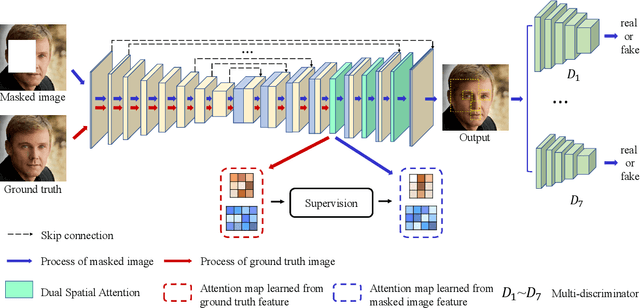

High-fidelity face completion is a challenging task due to the rich and subtle facial textures involved. What makes it more complicated is the correlations between different facial components, for example, the symmetry in texture and structure between both eyes. While recent works adopted the attention mechanism to learn the contextual relations among elements of the face, they have largely overlooked the disastrous impacts of inaccurate attention scores; in addition, they fail to pay sufficient attention to key facial components, the completion results of which largely determine the authenticity of a face image. Accordingly, in this paper, we design a comprehensive framework for face completion based on the U-Net structure. Specifically, we propose a dual spatial attention module to efficiently learn the correlations between facial textures at multiple scales; moreover, we provide an oracle supervision signal to the attention module to ensure that the obtained attention scores are reasonable. Furthermore, we take the location of the facial components as prior knowledge and impose a multi-discriminator on these regions, with which the fidelity of facial components is significantly promoted. Extensive experiments on two high-resolution face datasets including CelebA-HQ and Flickr-Faces-HQ demonstrate that the proposed approach outperforms state-of-the-art methods by large margins.
Face2Face: Real-time Face Capture and Reenactment of RGB Videos
Jul 29, 2020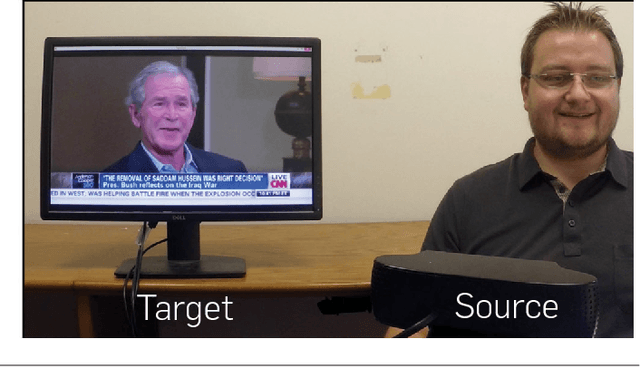
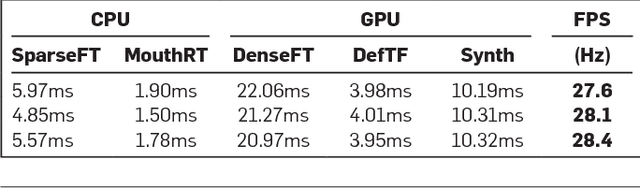
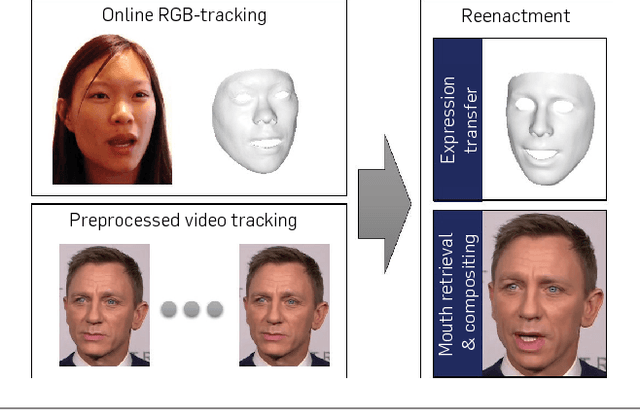

We present Face2Face, a novel approach for real-time facial reenactment of a monocular target video sequence (e.g., Youtube video). The source sequence is also a monocular video stream, captured live with a commodity webcam. Our goal is to animate the facial expressions of the target video by a source actor and re-render the manipulated output video in a photo-realistic fashion. To this end, we first address the under-constrained problem of facial identity recovery from monocular video by non-rigid model-based bundling. At run time, we track facial expressions of both source and target video using a dense photometric consistency measure. Reenactment is then achieved by fast and efficient deformation transfer between source and target. The mouth interior that best matches the re-targeted expression is retrieved from the target sequence and warped to produce an accurate fit. Finally, we convincingly re-render the synthesized target face on top of the corresponding video stream such that it seamlessly blends with the real-world illumination. We demonstrate our method in a live setup, where Youtube videos are reenacted in real time.
Recognition of Facial Expression Using Eigenvector Based Distributed Features and Euclidean Distance Based Decision Making Technique
Mar 04, 2013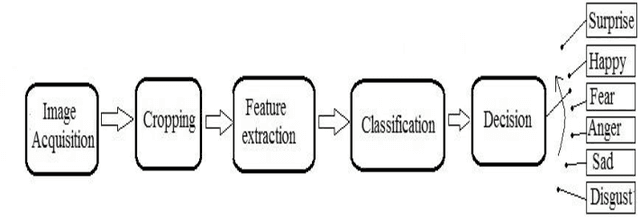
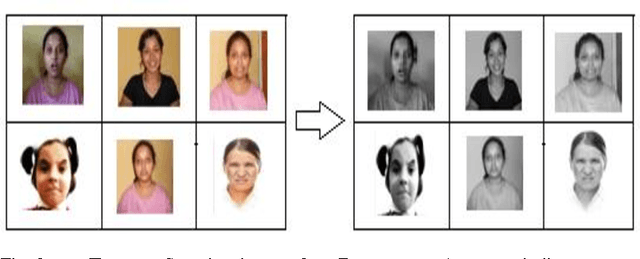
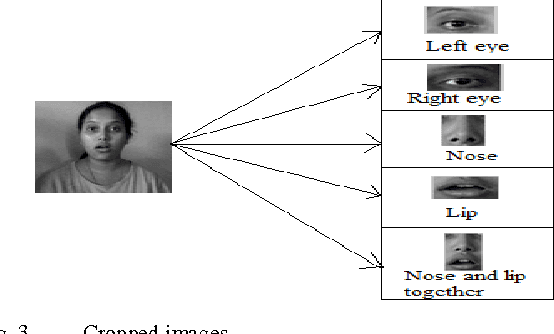
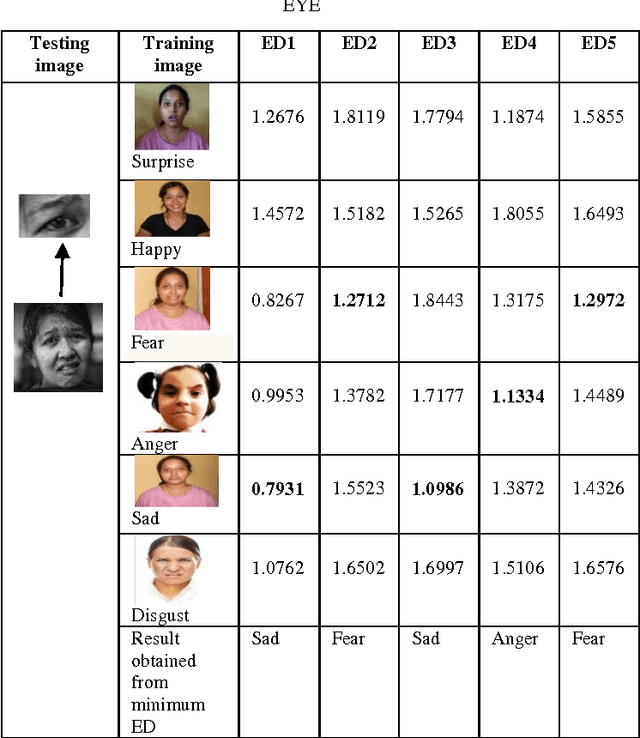
In this paper, an Eigenvector based system has been presented to recognize facial expressions from digital facial images. In the approach, firstly the images were acquired and cropping of five significant portions from the image was performed to extract and store the Eigenvectors specific to the expressions. The Eigenvectors for the test images were also computed, and finally the input facial image was recognized when similarity was obtained by calculating the minimum Euclidean distance between the test image and the different expressions.
On Recognizing Occluded Faces in the Wild
Sep 11, 2021

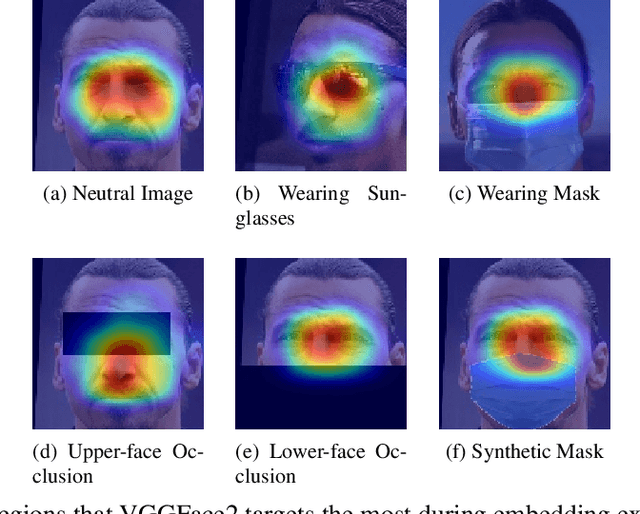
Facial appearance variations due to occlusion has been one of the main challenges for face recognition systems. To facilitate further research in this area, it is necessary and important to have occluded face datasets collected from real-world, as synthetically generated occluded faces cannot represent the nature of the problem. In this paper, we present the Real World Occluded Faces (ROF) dataset, that contains faces with both upper face occlusion, due to sunglasses, and lower face occlusion, due to masks. We propose two evaluation protocols for this dataset. Benchmark experiments on the dataset have shown that no matter how powerful the deep face representation models are, their performance degrades significantly when they are tested on real-world occluded faces. It is observed that the performance drop is far less when the models are tested on synthetically generated occluded faces. The ROF dataset and the associated evaluation protocols are publicly available at the following link https://github.com/ekremerakin/RealWorldOccludedFaces.