 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Smooth head tracking for virtual reality applications
Oct 27, 2021

In this work, we propose a new head-tracking solution for human-machine real-time interaction with virtual 3D environments. This solution leverages RGBD data to compute virtual camera pose according to the movements of the user's head. The process starts with the extraction of a set of facial features from the images delivered by the sensor. Such features are matched against their respective counterparts in a reference image for the computation of the current head pose. Afterwards, a prediction approach is used to guess the most likely next head move (final pose). Pythagorean Hodograph interpolation is then adapted to determine the path and local frames taken between the two poses. The result is a smooth head trajectory that serves as an input to set the camera in virtual scenes according to the user's gaze. The resulting motion model has the advantage of being: continuous in time, it adapts to any frame rate of rendering; it is ergonomic, as it frees the user from wearing tracking markers; it is smooth and free from rendering jerks; and it is also torsion and curvature minimizing as it produces a path with minimum bending energy.
* 8 pages, 1 figure
Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies
Aug 18, 2021
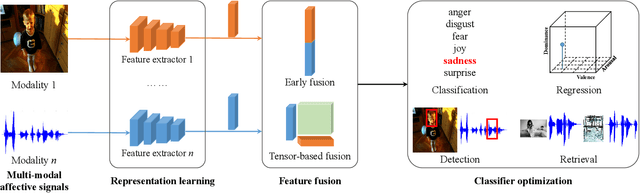
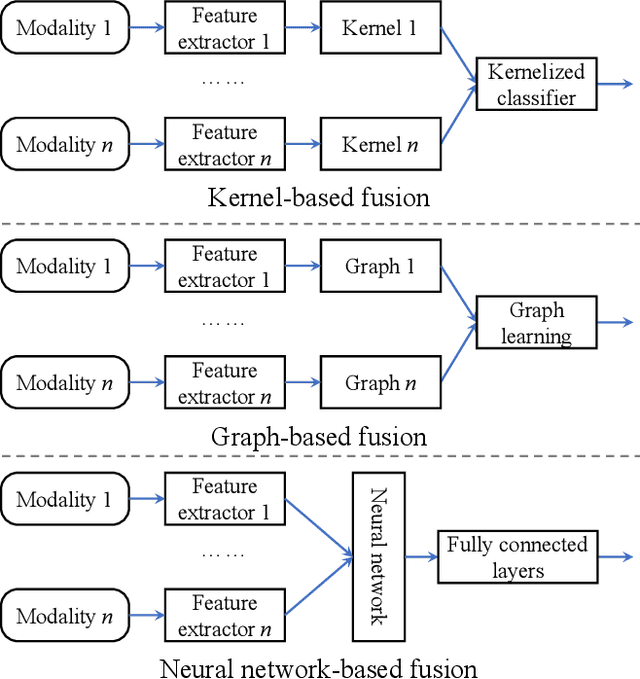
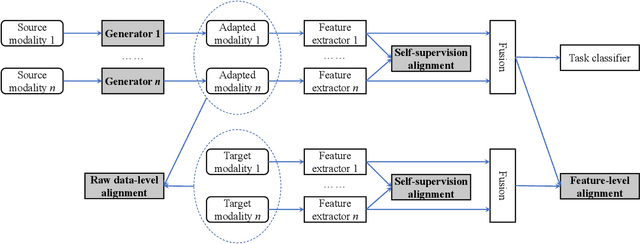
Humans are emotional creatures. Multiple modalities are often involved when we express emotions, whether we do so explicitly (e.g., facial expression, speech) or implicitly (e.g., text, image). Enabling machines to have emotional intelligence, i.e., recognizing, interpreting, processing, and simulating emotions, is becoming increasingly important. In this tutorial, we discuss several key aspects of multi-modal emotion recognition (MER). We begin with a brief introduction on widely used emotion representation models and affective modalities. We then summarize existing emotion annotation strategies and corresponding computational tasks, followed by the description of main challenges in MER. Furthermore, we present some representative approaches on representation learning of each affective modality, feature fusion of different affective modalities, classifier optimization for MER, and domain adaptation for MER. Finally, we outline several real-world applications and discuss some future directions.
Semantic and Geometric Unfolding of StyleGAN Latent Space
Jul 09, 2021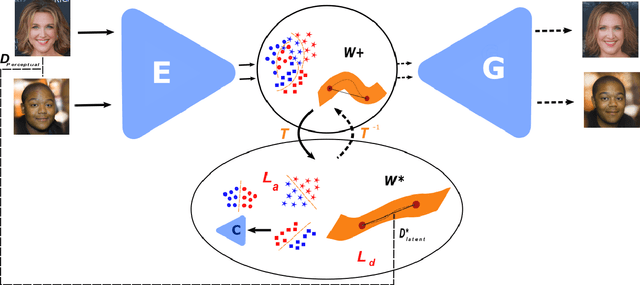
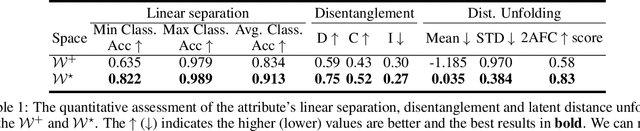

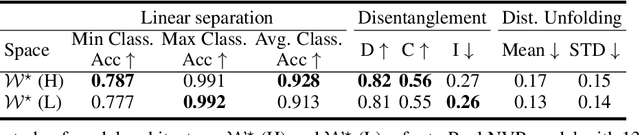
Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to a natural image. This property emerges from the disentangled nature of the latent space. In this paper, we identify two geometric limitations of such latent space: (a) euclidean distances differ from image perceptual distance, and (b) disentanglement is not optimal and facial attribute separation using linear model is a limiting hypothesis. We thus propose a new method to learn a proxy latent representation using normalizing flows to remedy these limitations, and show that this leads to a more efficient space for face image editing.
Action Unit Detection with Joint Adaptive Attention and Graph Relation
Jul 09, 2021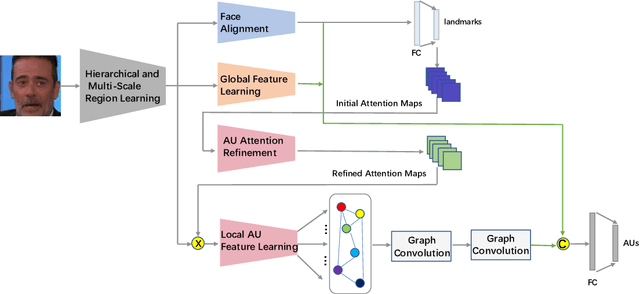
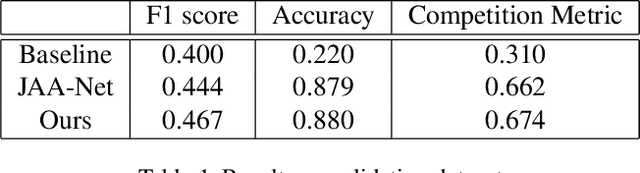
This paper describes an approach to the facial action unit (AU) detection. In this work, we present our submission to the Field Affective Behavior Analysis (ABAW) 2021 competition. The proposed method uses the pre-trained JAA model as the feature extractor, and extracts global features, face alignment features and AU local features on the basis of multi-scale features. We take the AU local features as the input of the graph convolution to further consider the correlation between AU, and finally use the fused features to classify AU. The detected accuracy was evaluated by 0.5*accuracy + 0.5*F1. Our model achieves 0.674 on the challenging Aff-Wild2 database.
Serial-EMD: Fast Empirical Mode Decomposition Method for Multi-dimensional Signals Based on Serialization
Jun 22, 2021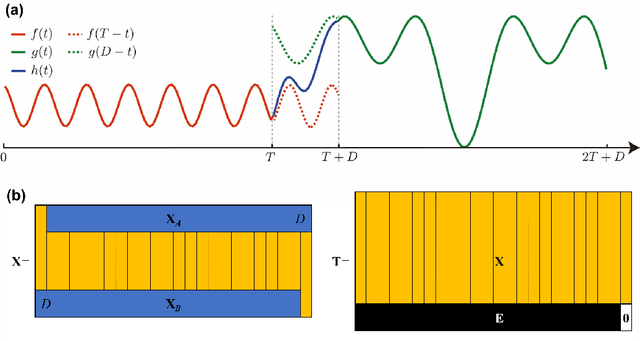


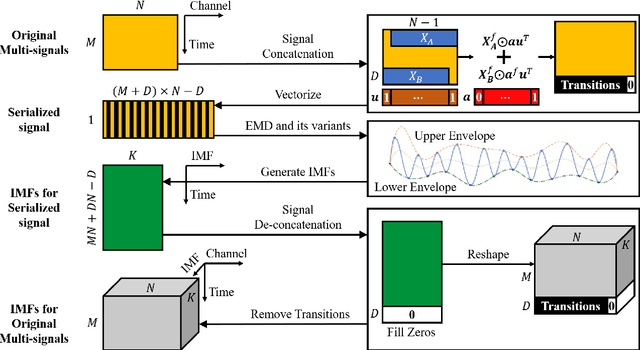
Empirical mode decomposition (EMD) has developed into a prominent tool for adaptive, scale-based signal analysis in various fields like robotics, security and biomedical engineering. Since the dramatic increase in amount of data puts forward higher requirements for the capability of real-time signal analysis, it is difficult for existing EMD and its variants to trade off the growth of data dimension and the speed of signal analysis. In order to decompose multi-dimensional signals at a faster speed, we present a novel signal-serialization method (serial-EMD), which concatenates multi-variate or multi-dimensional signals into a one-dimensional signal and uses various one-dimensional EMD algorithms to decompose it. To verify the effects of the proposed method, synthetic multi-variate time series, artificial 2D images with various textures and real-world facial images are tested. Compared with existing multi-EMD algorithms, the decomposition time becomes significantly reduced. In addition, the results of facial recognition with Intrinsic Mode Functions (IMFs) extracted using our method can achieve a higher accuracy than those obtained by existing multi-EMD algorithms, which demonstrates the superior performance of our method in terms of the quality of IMFs. Furthermore, this method can provide a new perspective to optimize the existing EMD algorithms, that is, transforming the structure of the input signal rather than being constrained by developing envelope computation techniques or signal decomposition methods. In summary, the study suggests that the serial-EMD technique is a highly competitive and fast alternative for multi-dimensional signal analysis.
An Empirical Study of Dimensional Reduction Techniques for Facial Action Units Detection
Mar 25, 2016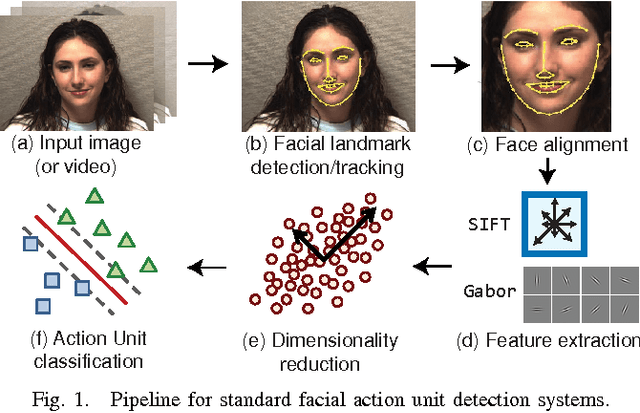

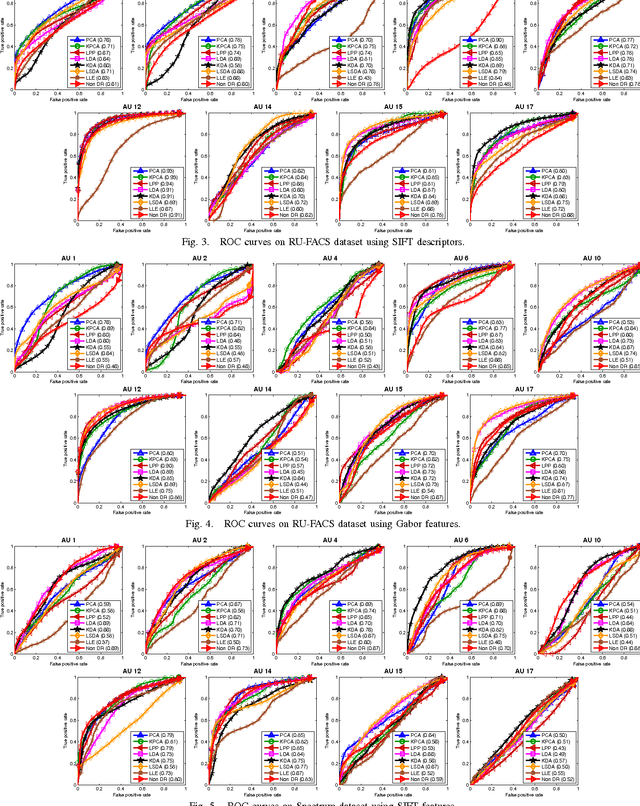
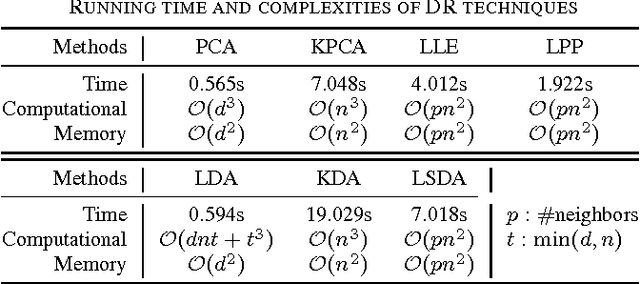
Biologically inspired features, such as Gabor filters, result in very high dimensional measurement. Does reducing the dimensionality of the feature space afford advantages beyond computational efficiency? Do some approaches to dimensionality reduction (DR) yield improved action unit detection? To answer these questions, we compared DR approaches in two relatively large databases of spontaneous facial behavior (45 participants in total with over 2 minutes of FACS-coded video per participant). Facial features were tracked and aligned using active appearance models (AAM). SIFT and Gabor features were extracted from local facial regions. We compared linear (PCA and KPCA), manifold (LPP and LLE), supervised (LDA and KDA) and hybrid approaches (LSDA) to DR with respect to AU detection. For further comparison, a no-DR control condition was included as well. Linear support vector machine classifiers with independent train and test sets were used for AU detection. AU detection was quantified using area under the ROC curve and F1. Baseline results for PCA with Gabor features were comparable with previous research. With some notable exceptions, DR improved AU detection relative to no-DR. Locality embedding approaches proved vulnerable to \emph{out-of-sample} problems. Gradient-based SIFT lead to better AU detection than the filter-based Gabor features. For area under the curve, few differences were found between linear and other DR approaches. For F1, results were mixed. For both metrics, the pattern of results varied among action units. These findings suggest that action unit detection may be optimized by using specific DR for specific action units. PCA and LDA were the most efficient approaches; KDA was the least efficient.
Face Forgery Detection by 3D Decomposition
Nov 19, 2020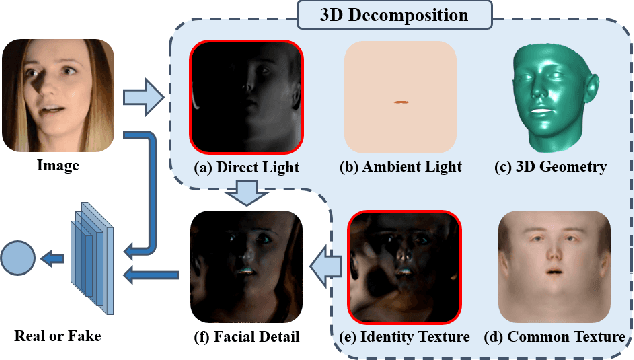


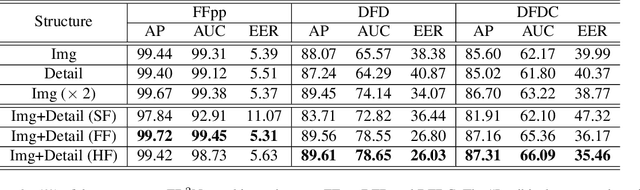
Detecting digital face manipulation has attracted extensive attention due to fake media's potential harms to the public. However, recent advances have been able to reduce the forgery signals to a low magnitude. Decomposition, which reversibly decomposes an image into several constituent elements, is a promising way to highlight the hidden forgery details. In this paper, we consider a face image as the production of the intervention of the underlying 3D geometry and the lighting environment, and decompose it in a computer graphics view. Specifically, by disentangling the face image into 3D shape, common texture, identity texture, ambient light, and direct light, we find the devil lies in the direct light and the identity texture. Based on this observation, we propose to utilize facial detail, which is the combination of direct light and identity texture, as the clue to detect the subtle forgery patterns. Besides, we highlight the manipulated region with a supervised attention mechanism and introduce a two-stream structure to exploit both face image and facial detail together as a multi-modality task. Extensive experiments indicate the effectiveness of the extra features extracted from the facial detail, and our method achieves the state-of-the-art performance.
Continuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks
Nov 18, 2020
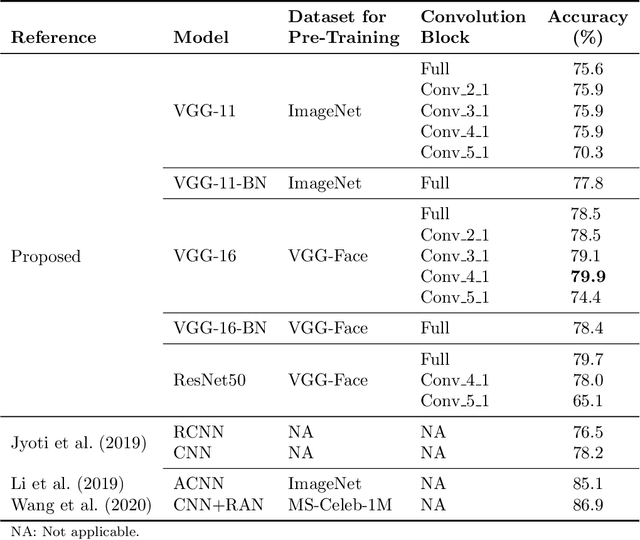
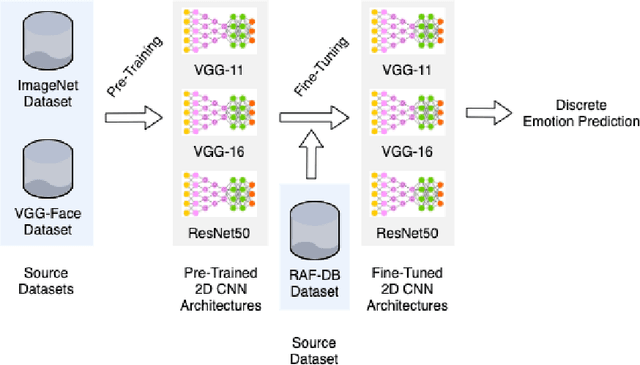
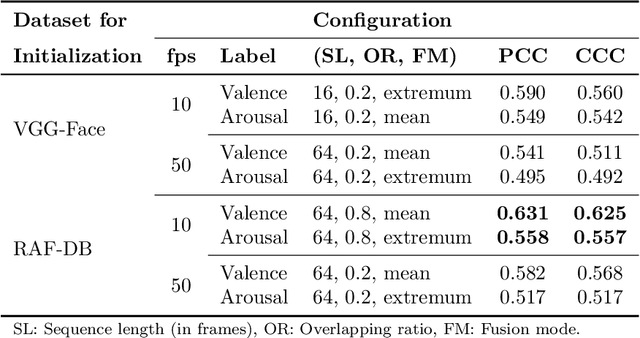
The attention in affect computing and emotion recognition has increased in the last decade. Facial expressions are one of the most powerful ways for depicting specific patterns in human behavior and describing human emotional state. Nevertheless, even for humans, identifying facial expressions is difficult, and automatic video-based systems for facial expression recognition (FER) have often suffered from variations in expressions among individuals, and from a lack of diverse and cross-culture training datasets. However, with video sequences captured in-the-wild and more complex emotion representation such as dimensional models, deep FER systems have the ability to learn more discriminative feature representations. In this paper, we present a survey of the state-of-the-art approaches based on convolutional neural networks (CNNs) for long video sequences recorded with in-the-wild settings, by considering the continuous emotion space of valence and arousal. Since few studies have used 3D-CNN for FER systems and dimensional representation of emotions, we propose an inflated 3D-CNN architecture, allowing for weight inflation of pre-trained 2D-CNN model, in order to operate the essential transfer learning for our video-based application. As a baseline, we also considered a 2D-CNN architecture cascaded network with a long short term memory network, therefore we could finally conclude with a model comparison over two approaches for spatiotemporal representation of facial features and performing the regression of valence/arousal values for emotion prediction. The experimental results on RAF-DB and SEWA-DB datasets have shown that these fine-tuned architectures allow to effectively encode the spatiotemporal information from raw pixel images, and achieved far better results than the current state-of-the-art.
Label quality in AffectNet: results of crowd-based re-annotation
Oct 09, 2021
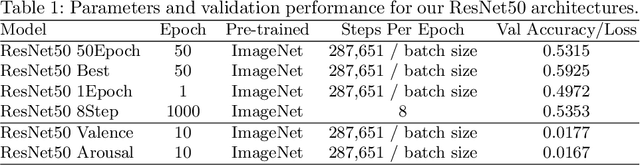
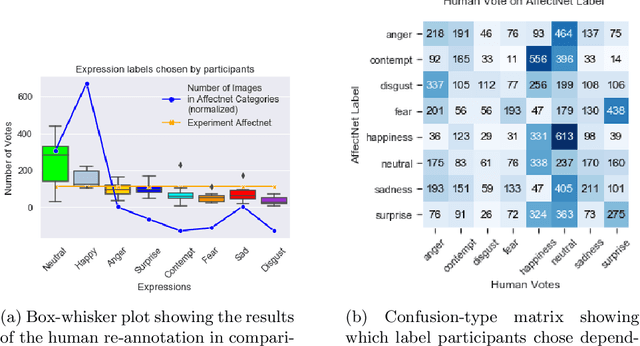
AffectNet is one of the most popular resources for facial expression recognition (FER) on relatively unconstrained in-the-wild images. Given that images were annotated by only one annotator with limited consistency checks on the data, however, label quality and consistency may be limited. Here, we take a similar approach to a study that re-labeled another, smaller dataset (FER2013) with crowd-based annotations, and report results from a re-labeling and re-annotation of a subset of difficult AffectNet faces with 13 people on both expression label, and valence and arousal ratings. Our results show that human labels overall have medium to good consistency, whereas human ratings especially for valence are in excellent agreement. Importantly, however, crowd-based labels are significantly shifting towards neutral and happy categories and crowd-based affective ratings form a consistent pattern different from the original ratings. ResNets fully trained on the original AffectNet dataset do not predict human voting patterns, but when weakly-trained do so much better, particularly for valence. Our results have important ramifications for label quality in affective computing.
Camera-Based Physiological Sensing: Challenges and Future Directions
Oct 26, 2021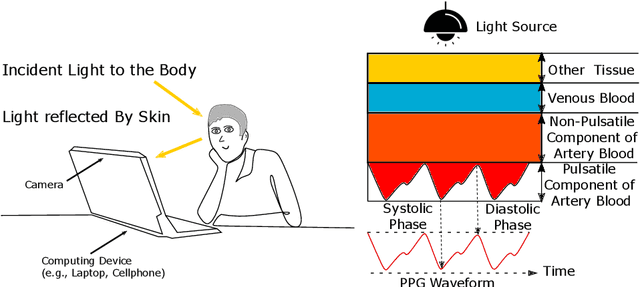
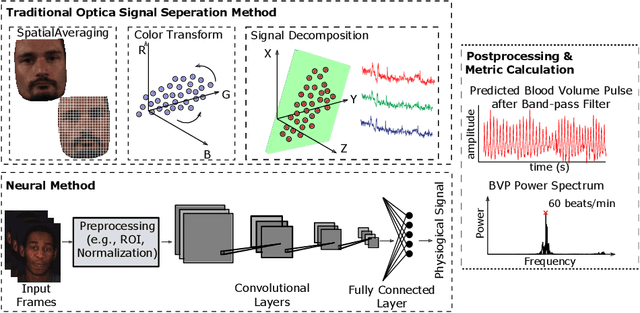
Numerous real-world applications have been driven by the recent algorithmic advancement of artificial intelligence (AI). Healthcare is no exception and AI technologies have great potential to revolutionize the industry. Non-contact camera-based physiological sensing, including remote photoplethysmography (rPPG), is a set of imaging methods that leverages ordinary RGB cameras (e.g., webcam or smartphone camera) to capture subtle changes in electromagnetic radiation (e.g., light) reflected by the body caused by physiological processes. Because of the relative ubiquity of cameras, these methods not only have the ability to measure the signals without contact with the body but also have the opportunity to capture multimodal information (e.g., facial expressions, activities and other context) from the same sensor. However, developing accessible, equitable and useful camera-based physiological sensing systems comes with various challenges. In this article, we identify four research challenges for the field of camera-based physiological sensing and broader AI driven healthcare communities and suggest future directions to tackle these. We believe solving these challenges will help deliver accurate, equitable and generalizable AI systems for healthcare that are practical in real-world and clinical contexts.