 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
The First Vision For Vitals (V4V) Challenge for Non-Contact Video-Based Physiological Estimation
Sep 22, 2021
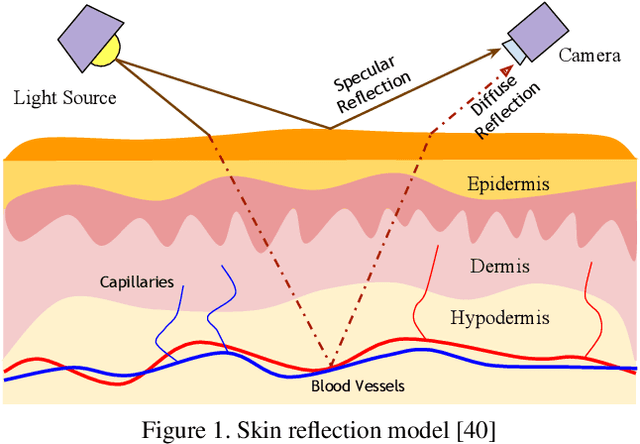
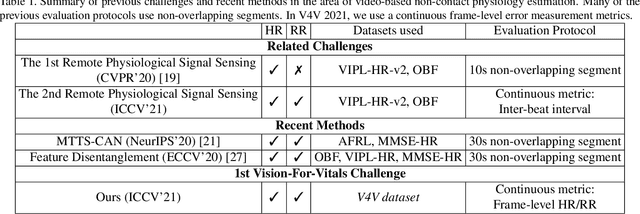
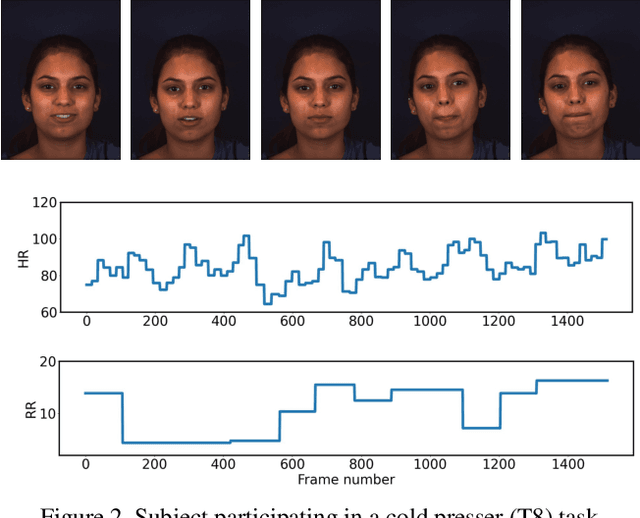
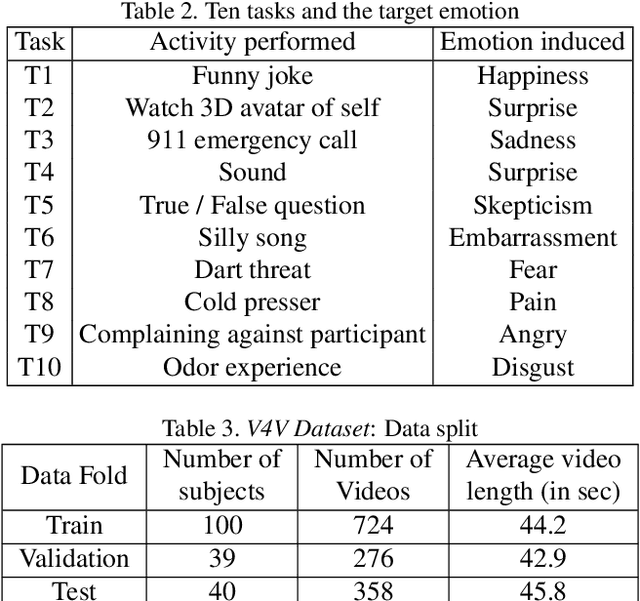
Telehealth has the potential to offset the high demand for help during public health emergencies, such as the COVID-19 pandemic. Remote Photoplethysmography (rPPG) - the problem of non-invasively estimating blood volume variations in the microvascular tissue from video - would be well suited for these situations. Over the past few years a number of research groups have made rapid advances in remote PPG methods for estimating heart rate from digital video and obtained impressive results. How these various methods compare in naturalistic conditions, where spontaneous behavior, facial expressions, and illumination changes are present, is relatively unknown. To enable comparisons among alternative methods, the 1st Vision for Vitals Challenge (V4V) presented a novel dataset containing high-resolution videos time-locked with varied physiological signals from a diverse population. In this paper, we outline the evaluation protocol, the data used, and the results. V4V is to be held in conjunction with the 2021 International Conference on Computer Vision.
The EMPATHIC Framework for Task Learning from Implicit Human Feedback
Sep 28, 2020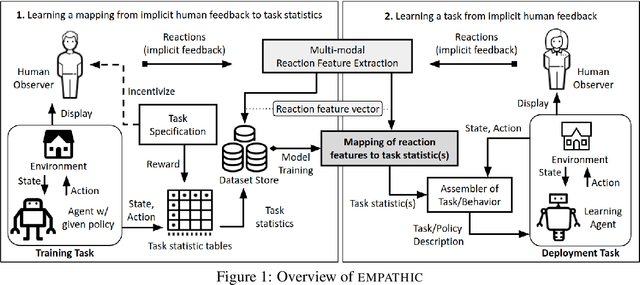



Reactions such as gestures, facial expressions, and vocalizations are an abundant, naturally occurring channel of information that humans provide during interactions. A robot or other agent could leverage an understanding of such implicit human feedback to improve its task performance at no cost to the human. This approach contrasts with common agent teaching methods based on demonstrations, critiques, or other guidance that need to be attentively and intentionally provided. In this paper, we first define the general problem of learning from implicit human feedback and then propose to address this problem through a novel data-driven framework, EMPATHIC. This two-stage method consists of (1) mapping implicit human feedback to relevant task statistics such as rewards, optimality, and advantage; and (2) using such a mapping to learn a task. We instantiate the first stage and three second-stage evaluations of the learned mapping. To do so, we collect a dataset of human facial reactions while participants observe an agent execute a sub-optimal policy for a prescribed training task. We train a deep neural network on this data and demonstrate its ability to (1) infer relative reward ranking of events in the training task from prerecorded human facial reactions; (2) improve the policy of an agent in the training task using live human facial reactions; and (3) transfer to a novel domain in which it evaluates robot manipulation trajectories.
Smooth head tracking for virtual reality applications
Oct 27, 2021
In this work, we propose a new head-tracking solution for human-machine real-time interaction with virtual 3D environments. This solution leverages RGBD data to compute virtual camera pose according to the movements of the user's head. The process starts with the extraction of a set of facial features from the images delivered by the sensor. Such features are matched against their respective counterparts in a reference image for the computation of the current head pose. Afterwards, a prediction approach is used to guess the most likely next head move (final pose). Pythagorean Hodograph interpolation is then adapted to determine the path and local frames taken between the two poses. The result is a smooth head trajectory that serves as an input to set the camera in virtual scenes according to the user's gaze. The resulting motion model has the advantage of being: continuous in time, it adapts to any frame rate of rendering; it is ergonomic, as it frees the user from wearing tracking markers; it is smooth and free from rendering jerks; and it is also torsion and curvature minimizing as it produces a path with minimum bending energy.
* 8 pages, 1 figure
Deblurring Processor for Motion-Blurred Faces Based on Generative Adversarial Networks
Mar 03, 2021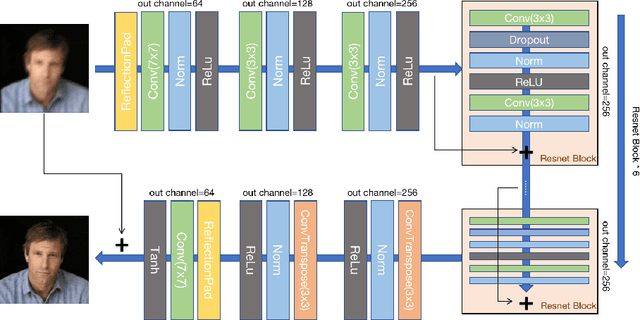
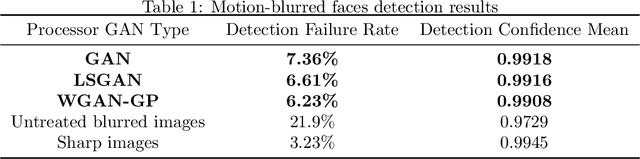
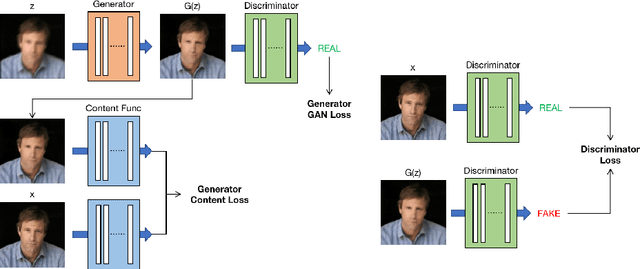

Low-quality face image restoration is a popular research direction in today's computer vision field. It can be used as a pre-work for tasks such as face detection and face recognition. At present, there is a lot of work to solve the problem of low-quality faces under various environmental conditions. This paper mainly focuses on the restoration of motion-blurred faces. In increasingly abundant mobile scenes, the fast recovery of motion-blurred faces can bring highly effective speed improvements in tasks such as face matching. In order to achieve this goal, a deblurring method for motion-blurred facial image signals based on generative adversarial networks(GANs) is proposed. It uses an end-to-end method to train a sharp image generator, i.e., a processor for motion-blurred facial images. This paper introduce the processing progress of motion-blurred images, the development and changes of GANs and some basic concepts. After that, it give the details of network structure and training optimization design of the image processor. Then we conducted a motion blur image generation experiment on some general facial data set, and used the pairs of blurred and sharp face image data to perform the training and testing experiments of the processor GAN, and gave some visual displays. Finally, MTCNN is used to detect the faces of the image generated by the deblurring processor, and compare it with the result of the blurred image. From the results, the processing effect of the deblurring processor on the motion-blurred picture has a significant improvement both in terms of intuition and evaluation indicators of face detection.
Multimedia Technology Applications and Algorithms: A Survey
Apr 03, 2021
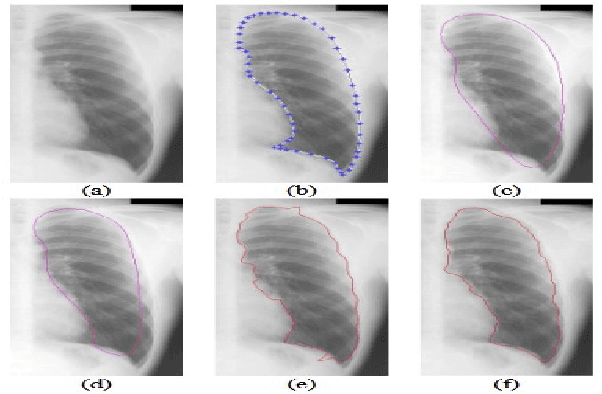
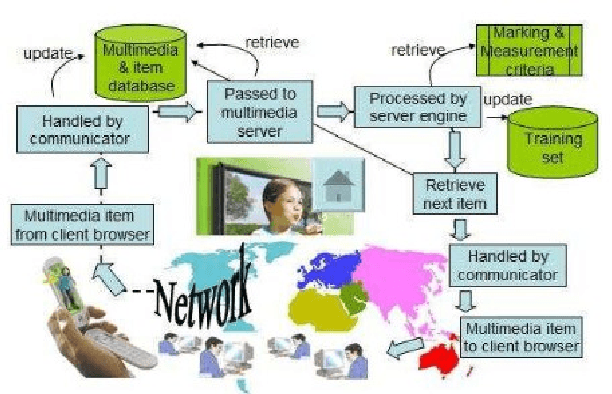
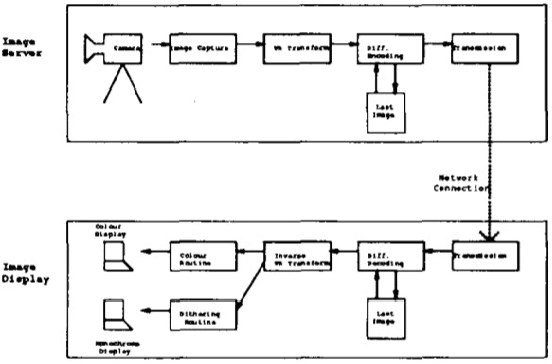
Multimedia related research and development has evolved rapidly in the last few years with advancements in hardware, software and network infrastructures. As a result, multimedia has been integrated into domains like Healthcare and Medicine, Human facial feature extraction and tracking, pose recognition, disparity estimation, etc. This survey gives an overview of the various multimedia technologies and algorithms developed in the domains mentioned.
Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies
Aug 18, 2021
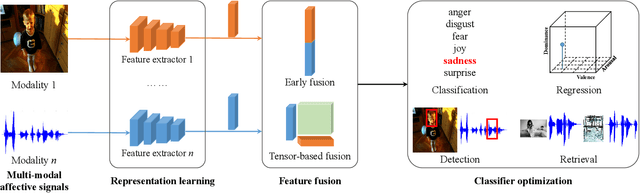
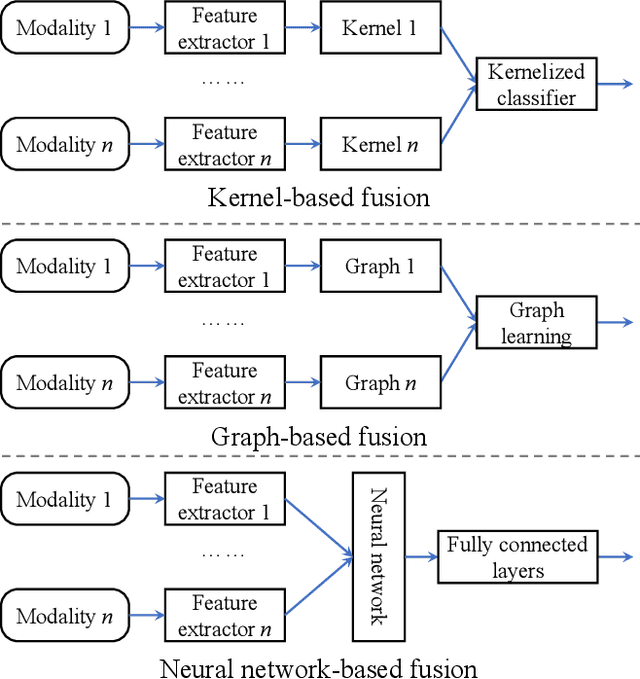
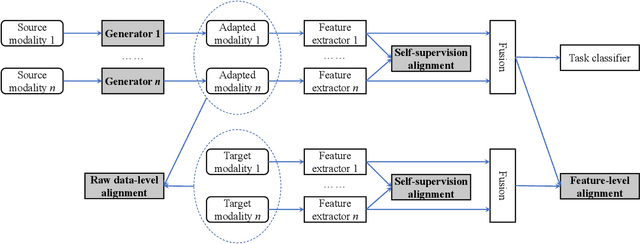
Humans are emotional creatures. Multiple modalities are often involved when we express emotions, whether we do so explicitly (e.g., facial expression, speech) or implicitly (e.g., text, image). Enabling machines to have emotional intelligence, i.e., recognizing, interpreting, processing, and simulating emotions, is becoming increasingly important. In this tutorial, we discuss several key aspects of multi-modal emotion recognition (MER). We begin with a brief introduction on widely used emotion representation models and affective modalities. We then summarize existing emotion annotation strategies and corresponding computational tasks, followed by the description of main challenges in MER. Furthermore, we present some representative approaches on representation learning of each affective modality, feature fusion of different affective modalities, classifier optimization for MER, and domain adaptation for MER. Finally, we outline several real-world applications and discuss some future directions.
Label quality in AffectNet: results of crowd-based re-annotation
Oct 09, 2021
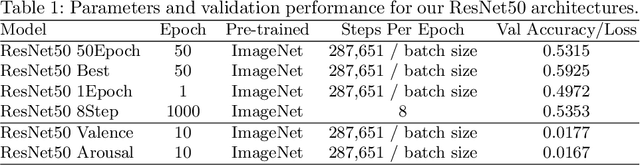
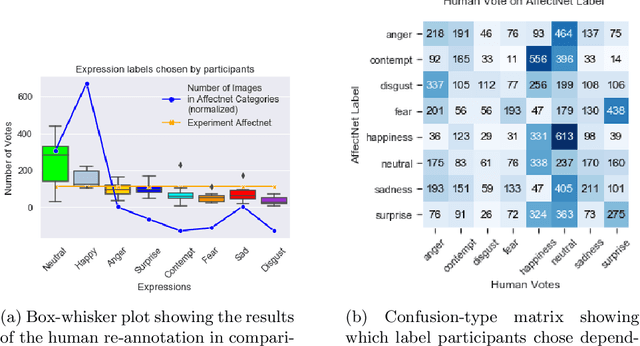
AffectNet is one of the most popular resources for facial expression recognition (FER) on relatively unconstrained in-the-wild images. Given that images were annotated by only one annotator with limited consistency checks on the data, however, label quality and consistency may be limited. Here, we take a similar approach to a study that re-labeled another, smaller dataset (FER2013) with crowd-based annotations, and report results from a re-labeling and re-annotation of a subset of difficult AffectNet faces with 13 people on both expression label, and valence and arousal ratings. Our results show that human labels overall have medium to good consistency, whereas human ratings especially for valence are in excellent agreement. Importantly, however, crowd-based labels are significantly shifting towards neutral and happy categories and crowd-based affective ratings form a consistent pattern different from the original ratings. ResNets fully trained on the original AffectNet dataset do not predict human voting patterns, but when weakly-trained do so much better, particularly for valence. Our results have important ramifications for label quality in affective computing.
Camera-Based Physiological Sensing: Challenges and Future Directions
Oct 26, 2021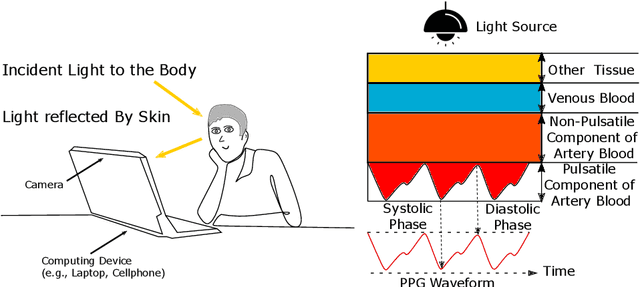
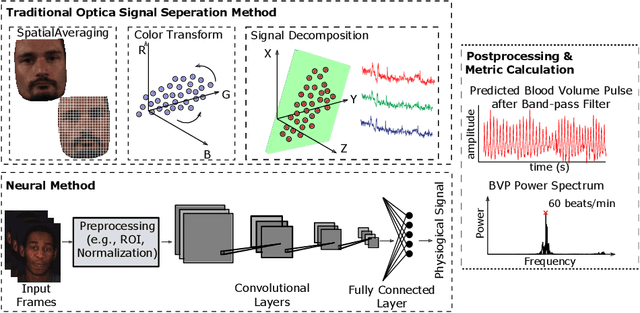
Numerous real-world applications have been driven by the recent algorithmic advancement of artificial intelligence (AI). Healthcare is no exception and AI technologies have great potential to revolutionize the industry. Non-contact camera-based physiological sensing, including remote photoplethysmography (rPPG), is a set of imaging methods that leverages ordinary RGB cameras (e.g., webcam or smartphone camera) to capture subtle changes in electromagnetic radiation (e.g., light) reflected by the body caused by physiological processes. Because of the relative ubiquity of cameras, these methods not only have the ability to measure the signals without contact with the body but also have the opportunity to capture multimodal information (e.g., facial expressions, activities and other context) from the same sensor. However, developing accessible, equitable and useful camera-based physiological sensing systems comes with various challenges. In this article, we identify four research challenges for the field of camera-based physiological sensing and broader AI driven healthcare communities and suggest future directions to tackle these. We believe solving these challenges will help deliver accurate, equitable and generalizable AI systems for healthcare that are practical in real-world and clinical contexts.
Semantic and Geometric Unfolding of StyleGAN Latent Space
Jul 09, 2021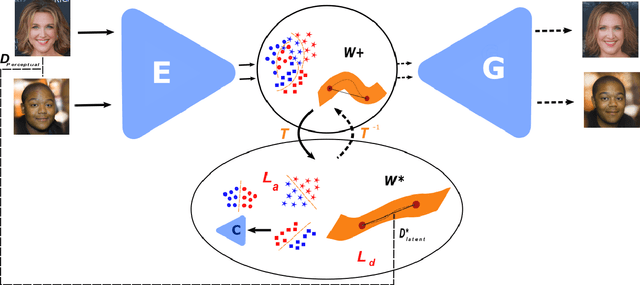
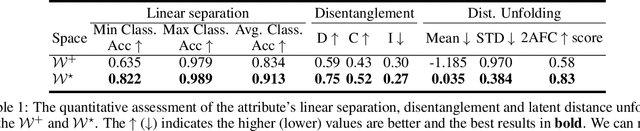

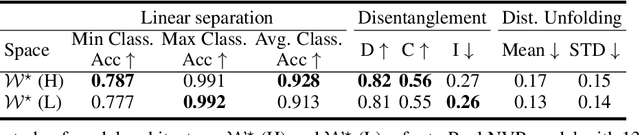
Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to a natural image. This property emerges from the disentangled nature of the latent space. In this paper, we identify two geometric limitations of such latent space: (a) euclidean distances differ from image perceptual distance, and (b) disentanglement is not optimal and facial attribute separation using linear model is a limiting hypothesis. We thus propose a new method to learn a proxy latent representation using normalizing flows to remedy these limitations, and show that this leads to a more efficient space for face image editing.
Action Unit Detection with Joint Adaptive Attention and Graph Relation
Jul 09, 2021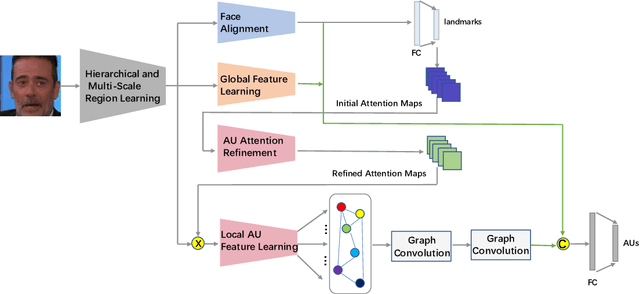
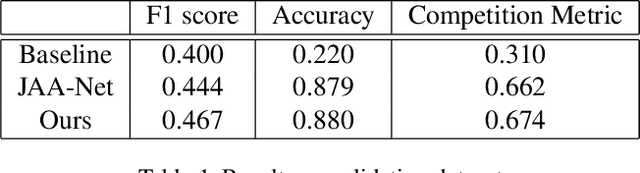
This paper describes an approach to the facial action unit (AU) detection. In this work, we present our submission to the Field Affective Behavior Analysis (ABAW) 2021 competition. The proposed method uses the pre-trained JAA model as the feature extractor, and extracts global features, face alignment features and AU local features on the basis of multi-scale features. We take the AU local features as the input of the graph convolution to further consider the correlation between AU, and finally use the fused features to classify AU. The detected accuracy was evaluated by 0.5*accuracy + 0.5*F1. Our model achieves 0.674 on the challenging Aff-Wild2 database.