 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
MeInGame: Create a Game Character Face from a Single Portrait
Feb 07, 2021
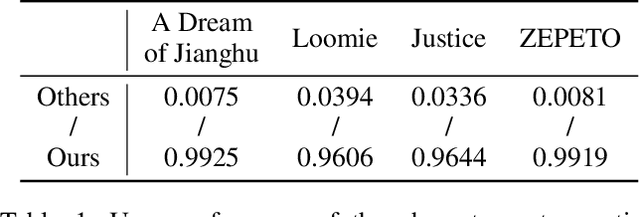
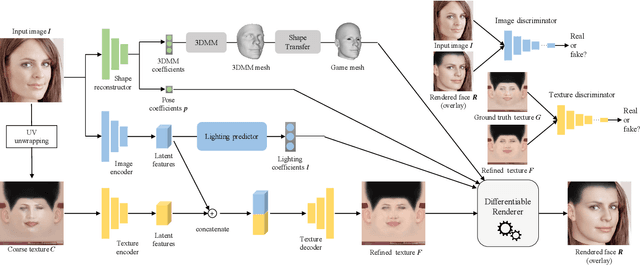
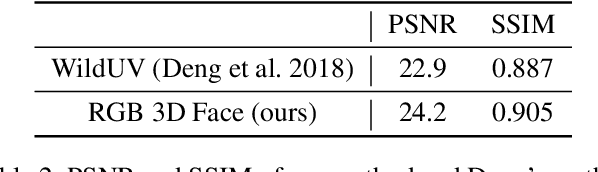

Many deep learning based 3D face reconstruction methods have been proposed recently, however, few of them have applications in games. Current game character customization systems either require players to manually adjust considerable face attributes to obtain the desired face, or have limited freedom of facial shape and texture. In this paper, we propose an automatic character face creation method that predicts both facial shape and texture from a single portrait, and it can be integrated into most existing 3D games. Although 3D Morphable Face Model (3DMM) based methods can restore accurate 3D faces from single images, the topology of 3DMM mesh is different from the meshes used in most games. To acquire fidelity texture, existing methods require a large amount of face texture data for training, while building such datasets is time-consuming and laborious. Besides, such a dataset collected under laboratory conditions may not generalized well to in-the-wild situations. To tackle these problems, we propose 1) a low-cost facial texture acquisition method, 2) a shape transfer algorithm that can transform the shape of a 3DMM mesh to games, and 3) a new pipeline for training 3D game face reconstruction networks. The proposed method not only can produce detailed and vivid game characters similar to the input portrait, but can also eliminate the influence of lighting and occlusions. Experiments show that our method outperforms state-of-the-art methods used in games.
Efficient Web-based Facial Recognition System Employing 2DHOG
Feb 11, 2012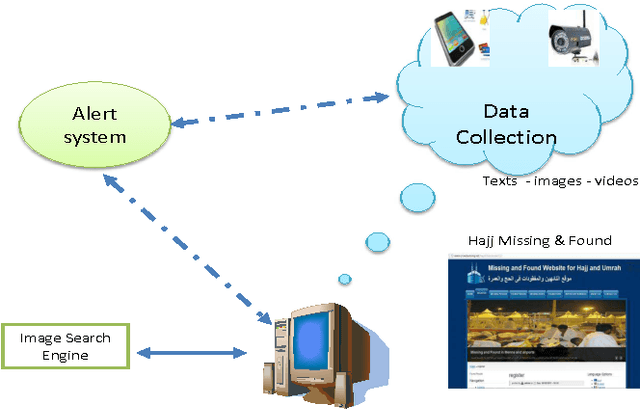
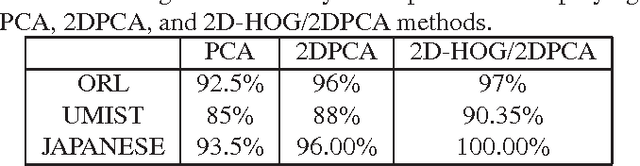
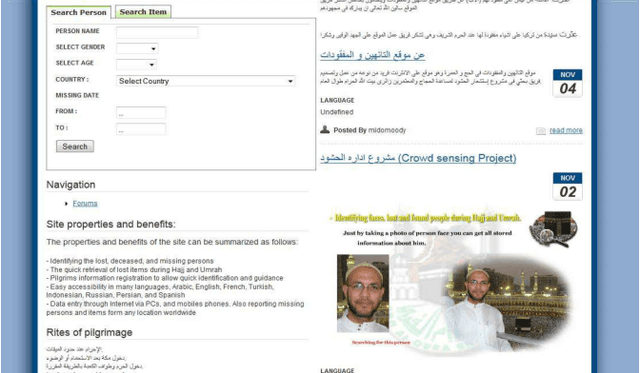
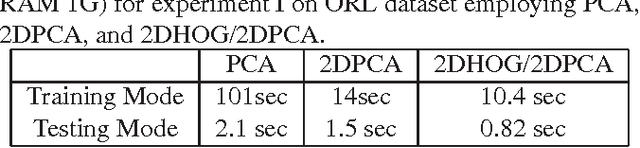
In this paper, a system for facial recognition to identify missing and found people in Hajj and Umrah is described as a web portal. Explicitly, we present a novel algorithm for recognition and classifications of facial images based on applying 2DPCA to a 2D representation of the Histogram of oriented gradients (2D-HOG) which maintains the spatial relation between pixels of the input images. This algorithm allows a compact representation of the images which reduces the computational complexity and the storage requirments, while maintaining the highest reported recognition accuracy. This promotes this method for usage with very large datasets. Large dataset was collected for people in Hajj. Experimental results employing ORL, UMIST, JAFFE, and HAJJ datasets confirm these excellent properties.
High-fidelity Face Tracking for AR/VR via Deep Lighting Adaptation
Mar 29, 2021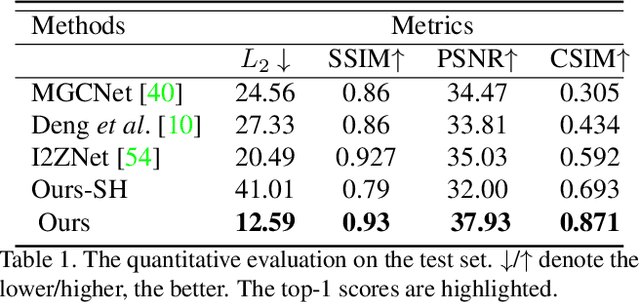
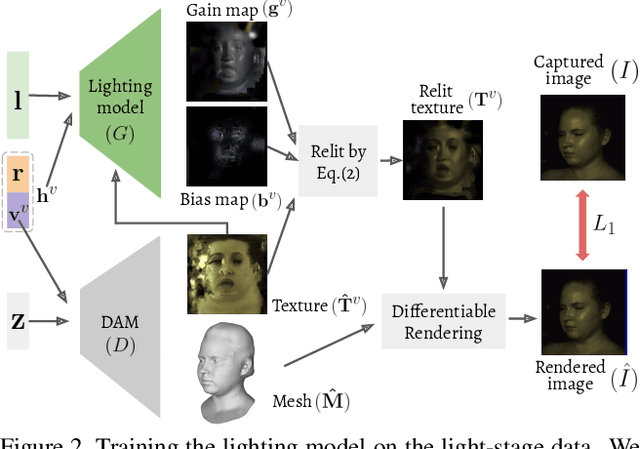

3D video avatars can empower virtual communications by providing compression, privacy, entertainment, and a sense of presence in AR/VR. Best 3D photo-realistic AR/VR avatars driven by video, that can minimize uncanny effects, rely on person-specific models. However, existing person-specific photo-realistic 3D models are not robust to lighting, hence their results typically miss subtle facial behaviors and cause artifacts in the avatar. This is a major drawback for the scalability of these models in communication systems (e.g., Messenger, Skype, FaceTime) and AR/VR. This paper addresses previous limitations by learning a deep learning lighting model, that in combination with a high-quality 3D face tracking algorithm, provides a method for subtle and robust facial motion transfer from a regular video to a 3D photo-realistic avatar. Extensive experimental validation and comparisons to other state-of-the-art methods demonstrate the effectiveness of the proposed framework in real-world scenarios with variability in pose, expression, and illumination. Please visit https://www.youtube.com/watch?v=dtz1LgZR8cc for more results. Our project page can be found at https://www.cs.rochester.edu/u/lchen63.
Incept-N: A Convolutional Neural Network based Classification Approach for Predicting Nationality from Facial Features
May 18, 2018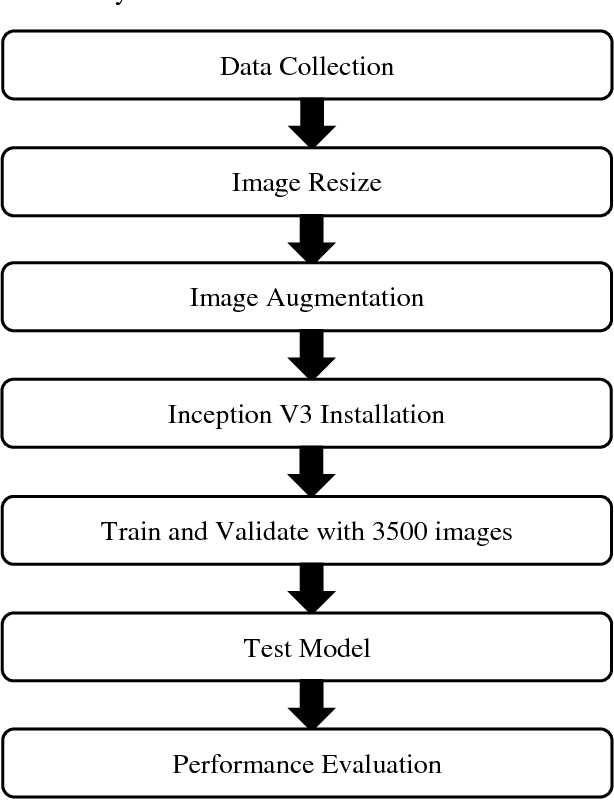

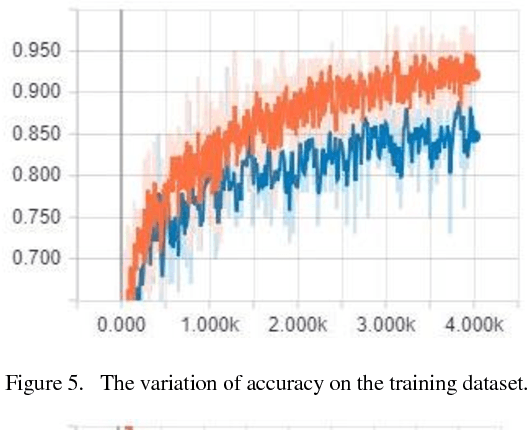
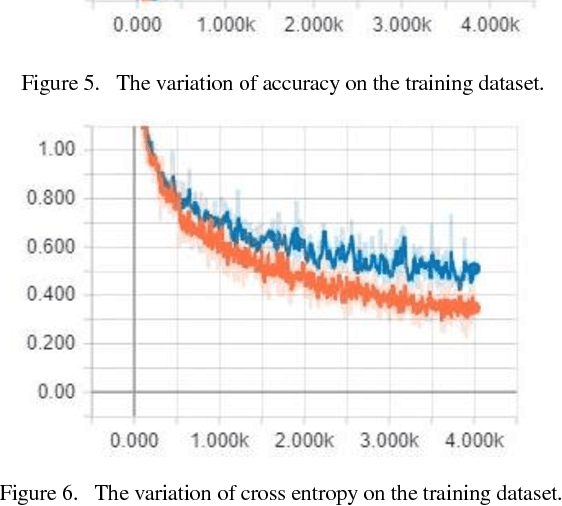
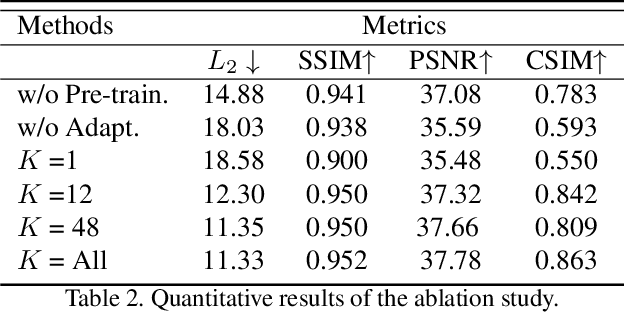
The nationality of a human being is a well-known identifying characteristic used for every major authentication purpose in every country. Albeit advances in the application of Artificial Intelligence and Computer Vision in different aspects, its contribution to this specific security procedure is yet to be cultivated. With a goal to successfully applying computer vision techniques to predict the nationality of a person based on his facial features, we have proposed this novel method and have achieved an average of 93.6% accuracy with very low misclassification rate.
Deepfake Forensics via An Adversarial Game
Mar 25, 2021
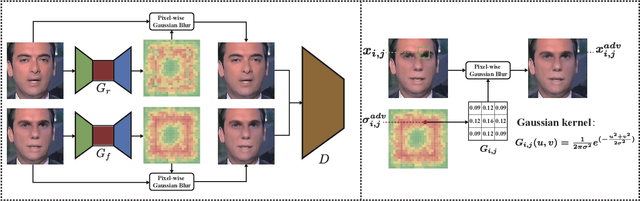

With the progress in AI-based facial forgery (i.e., deepfake), people are increasingly concerned about its abuse. Albeit effort has been made for training classification (also known as deepfake detection) models to recognize such forgeries, existing models suffer from poor generalization to unseen forgery technologies and high sensitivity to changes in image/video quality. In this paper, we advocate adversarial training for improving the generalization ability to both unseen facial forgeries and unseen image/video qualities. We believe training with samples that are adversarially crafted to attack the classification models improves the generalization ability considerably. Considering that AI-based face manipulation often leads to high-frequency artifacts that can be easily spotted by models yet difficult to generalize, we further propose a new adversarial training method that attempts to blur out these specific artifacts, by introducing pixel-wise Gaussian blurring models. With adversarial training, the classification models are forced to learn more discriminative and generalizable features, and the effectiveness of our method can be verified by plenty of empirical evidence. Our code will be made publicly available.
Morph Detection Enhanced by Structured Group Sparsity
Nov 29, 2021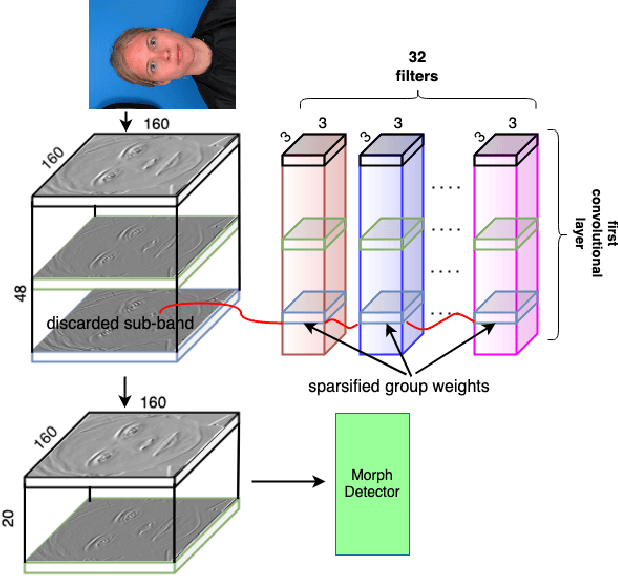
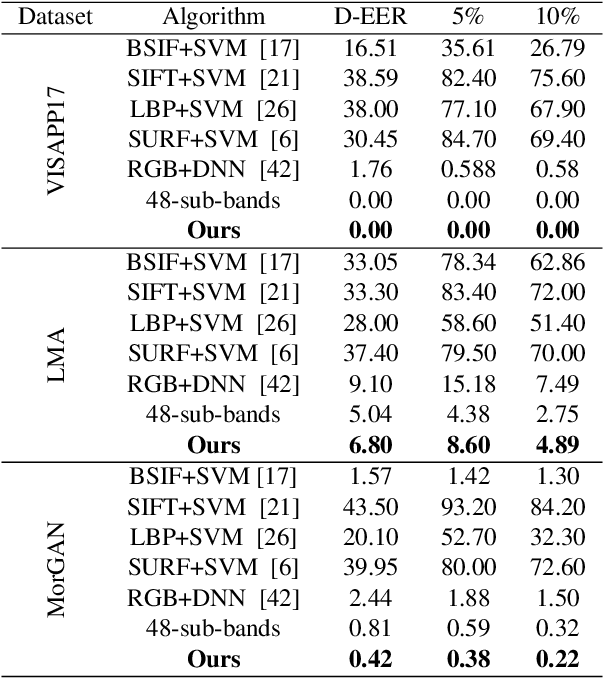
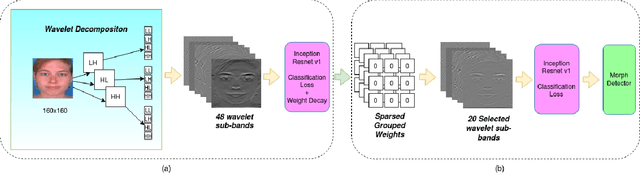
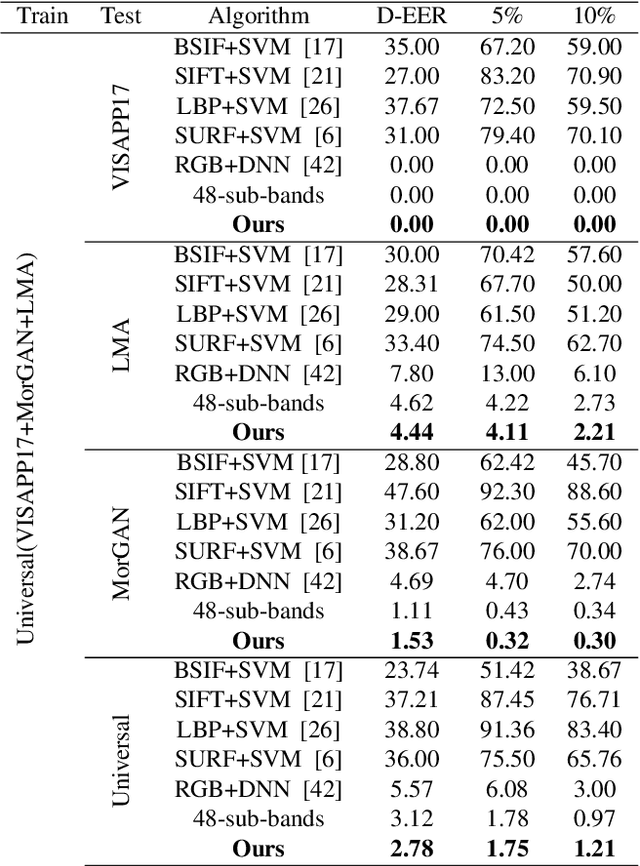
In this paper, we consider the challenge of face morphing attacks, which substantially undermine the integrity of face recognition systems such as those adopted for use in border protection agencies. Morph detection can be formulated as extracting fine-grained representations, where local discriminative features are harnessed for learning a hypothesis. To acquire discriminative features at different granularity as well as a decoupled spectral information, we leverage wavelet domain analysis to gain insight into the spatial-frequency content of a morphed face. As such, instead of using images in the RGB domain, we decompose every image into its wavelet sub-bands using 2D wavelet decomposition and a deep supervised feature selection scheme is employed to find the most discriminative wavelet sub-bands of input images. To this end, we train a Deep Neural Network (DNN) morph detector using the decomposed wavelet sub-bands of the morphed and bona fide images. In the training phase, our structured group sparsity-constrained DNN picks the most discriminative wavelet sub-bands out of all the sub-bands, with which we retrain our DNN, resulting in a precise detection of morphed images when inference is achieved on a probe image. The efficacy of our deep morph detector which is enhanced by structured group lasso is validated through experiments on three facial morph image databases, i.e., VISAPP17, LMA, and MorGAN.
Deep Active Shape Model for Face Alignment and Pose Estimation
Feb 27, 2021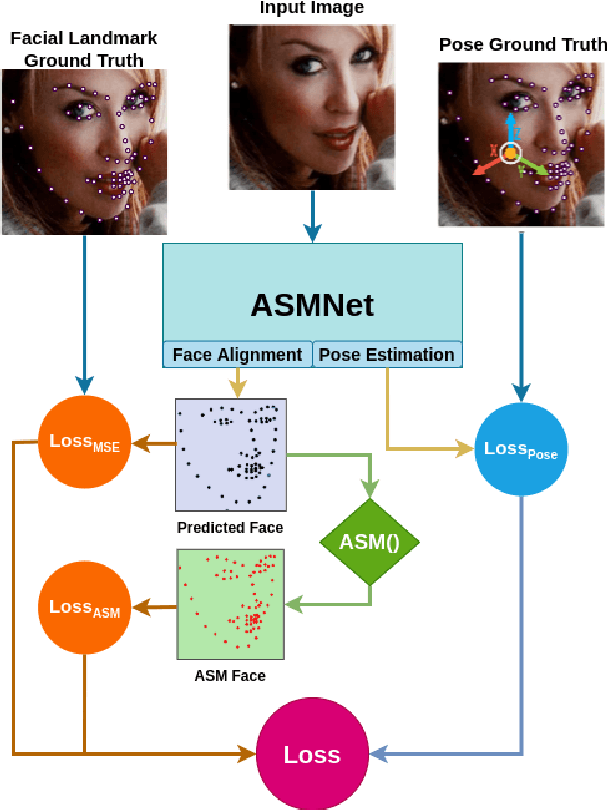
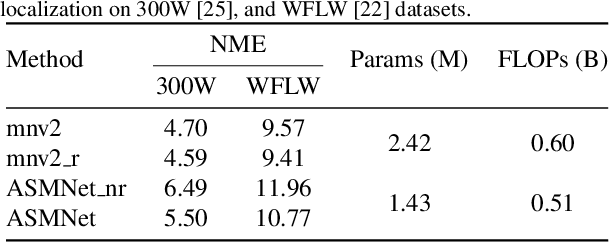
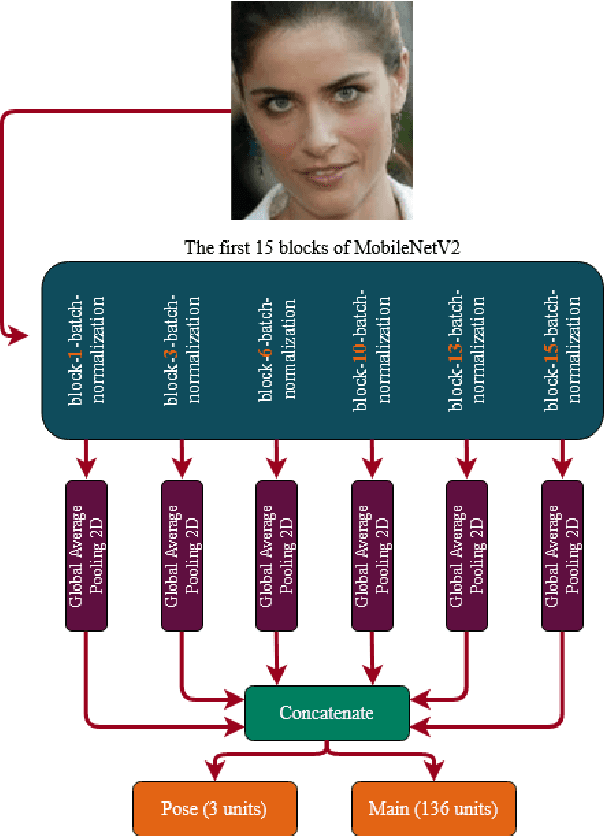
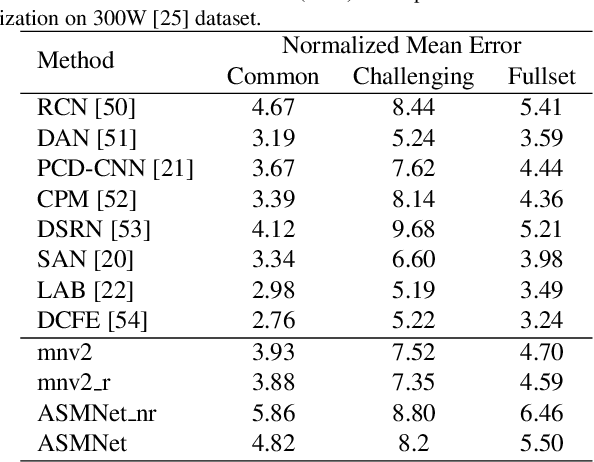
Active Shape Model (ASM) is a statistical model of object shapes that represents a target structure. ASM can guide machine learning algorithms to fit a set of points representing an object (e.g., face) onto an image. This paper presents a lightweight Convolutional Neural Network (CNN) architecture with a loss function regularized by ASM for face alignment and estimating head pose in the wild. The ASM-based regularization term in the loss function would guide the network to learn faster, generalize better, and hence handle challenging examples even with light-weight network architecture. We define multi-tasks in our loss function that are responsible for detecting facial landmark points, as well as estimating face pose. Learning multiple correlated tasks simultaneously builds synergy and improves the performance of individual tasks. Experimental results on challenging datasets show that our proposed ASM regularized loss function achieves competitive performance for facial landmark points detection and pose estimation using a very light-weight CNN architecture.
Canonical Saliency Maps: Decoding Deep Face Models
May 04, 2021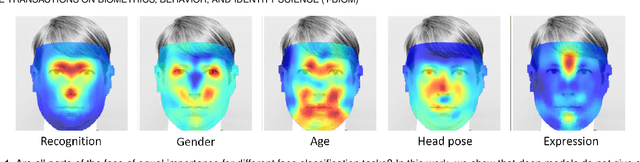

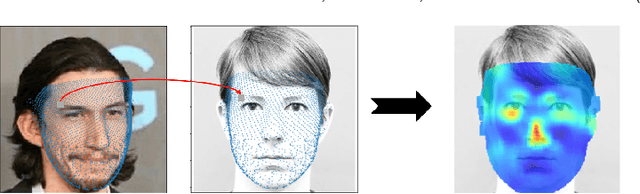

As Deep Neural Network models for face processing tasks approach human-like performance, their deployment in critical applications such as law enforcement and access control has seen an upswing, where any failure may have far-reaching consequences. We need methods to build trust in deployed systems by making their working as transparent as possible. Existing visualization algorithms are designed for object recognition and do not give insightful results when applied to the face domain. In this work, we present 'Canonical Saliency Maps', a new method that highlights relevant facial areas by projecting saliency maps onto a canonical face model. We present two kinds of Canonical Saliency Maps: image-level maps and model-level maps. Image-level maps highlight facial features responsible for the decision made by a deep face model on a given image, thus helping to understand how a DNN made a prediction on the image. Model-level maps provide an understanding of what the entire DNN model focuses on in each task and thus can be used to detect biases in the model. Our qualitative and quantitative results show the usefulness of the proposed canonical saliency maps, which can be used on any deep face model regardless of the architecture.
Facial Expression Representation and Recognition Using 2DHLDA, Gabor Wavelets, and Ensemble Learning
Jul 20, 2012In this paper, a novel method for representation and recognition of the facial expressions in two-dimensional image sequences is presented. We apply a variation of two-dimensional heteroscedastic linear discriminant analysis (2DHLDA) algorithm, as an efficient dimensionality reduction technique, to Gabor representation of the input sequence. 2DHLDA is an extension of the two-dimensional linear discriminant analysis (2DLDA) approach and it removes the equal within-class covariance. By applying 2DHLDA in two directions, we eliminate the correlations between both image columns and image rows. Then, we perform a one-dimensional LDA on the new features. This combined method can alleviate the small sample size problem and instability encountered by HLDA. Also, employing both geometric and appearance features and using an ensemble learning scheme based on data fusion, we create a classifier which can efficiently classify the facial expressions. The proposed method is robust to illumination changes and it can properly represent temporal information as well as subtle changes in facial muscles. We provide experiments on Cohn-Kanade database that show the superiority of the proposed method. KEYWORDS: two-dimensional heteroscedastic linear discriminant analysis (2DHLDA), subspace learning, facial expression analysis, Gabor wavelets, ensemble learning.