 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Unconstrained Face Recognition using ASURF and Cloud-Forest Classifier optimized with VLAD
Apr 02, 2021




The paper posits a computationally-efficient algorithm for multi-class facial image classification in which images are constrained with translation, rotation, scale, color, illumination and affine distortion. The proposed method is divided into five main building blocks including Haar-Cascade for face detection, Bilateral Filter for image preprocessing to remove unwanted noise, Affine Speeded-Up Robust Features (ASURF) for keypoint detection and description, Vector of Locally Aggregated Descriptors (VLAD) for feature quantization and Cloud Forest for image classification. The proposed method aims at improving the accuracy and the time taken for face recognition systems. The usage of the Cloud Forest algorithm as a classifier on three benchmark datasets, namely the FACES95, FACES96 and ORL facial datasets, showed promising results. The proposed methodology using Cloud Forest algorithm successfully improves the recognition model by 2-12\% when differentiated against other ensemble techniques like the Random Forest classifier depending upon the dataset used.
* 8 Pages, 3 Figures
Self-Supervised Robustifying Guidance for Monocular 3D Face Reconstruction
Dec 29, 2021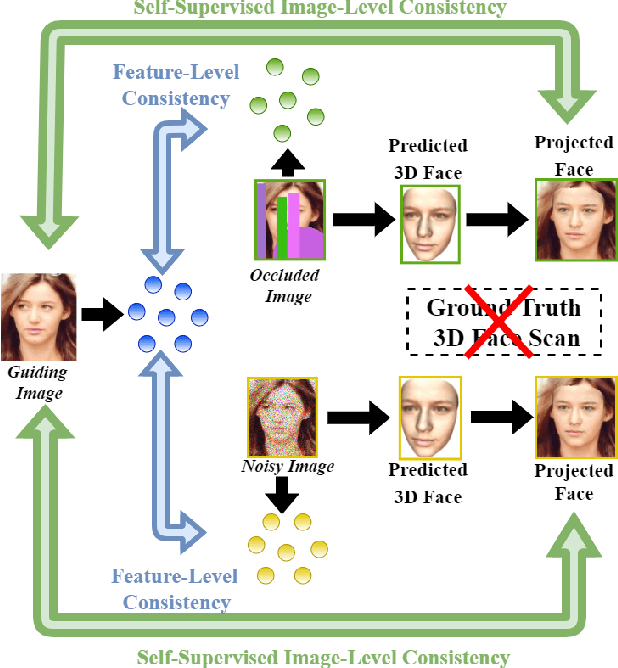
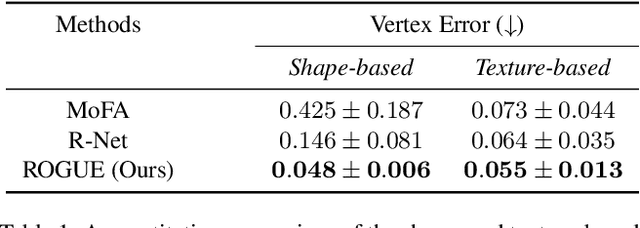
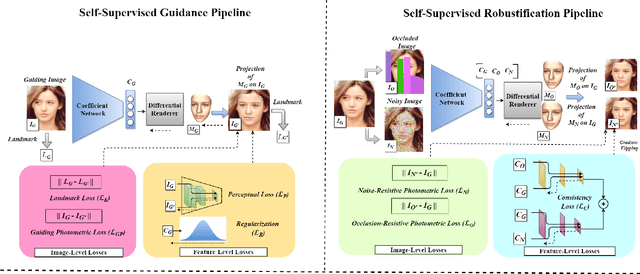
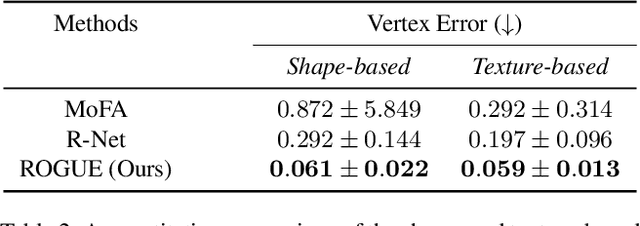
Despite the recent developments in 3D Face Reconstruction from occluded and noisy face images, the performance is still unsatisfactory. One of the main challenges is to handle moderate to heavy occlusions in the face images. In addition, the noise in the face images inhibits the correct capture of facial attributes, thus needing to be reliably addressed. Moreover, most existing methods rely on additional dependencies, posing numerous constraints over the training procedure. Therefore, we propose a Self-Supervised RObustifying GUidancE (ROGUE) framework to obtain robustness against occlusions and noise in the face images. The proposed network contains 1) the Guidance Pipeline to obtain the 3D face coefficients for the clean faces, and 2) the Robustification Pipeline to acquire the consistency between the estimated coefficients for occluded or noisy images and the clean counterpart. The proposed image- and feature-level loss functions aid the ROGUE learning process without posing additional dependencies. On the three variations of the test dataset of CelebA: rational occlusions, delusional occlusions, and noisy face images, our method outperforms the current state-of-the-art method by large margins (e.g., for the shape-based 3D vertex errors, a reduction from 0.146 to 0.048 for rational occlusions, from 0.292 to 0.061 for delusional occlusions and from 0.269 to 0.053 for the noise in the face images), demonstrating the effectiveness of the proposed approach.
Applying Artificial Intelligence for Age Estimation in Digital Forensic Investigations
Jan 09, 2022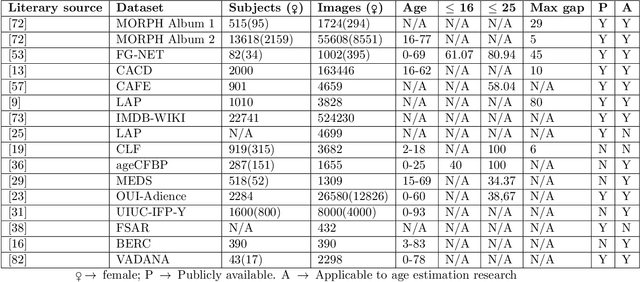
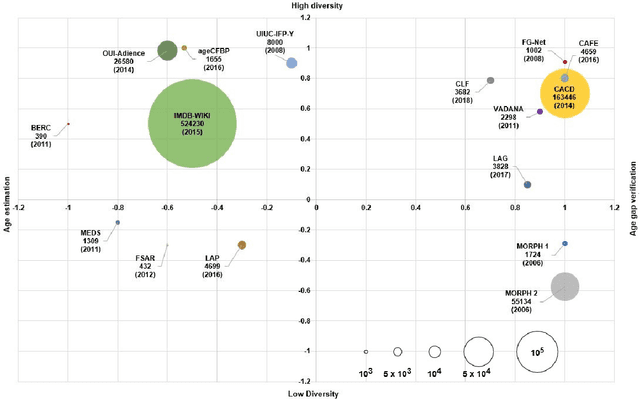

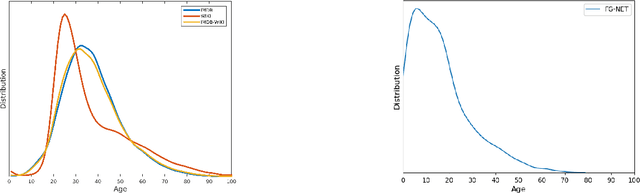
The precise age estimation of child sexual abuse and exploitation (CSAE) victims is one of the most significant digital forensic challenges. Investigators often need to determine the age of victims by looking at images and interpreting the sexual development stages and other human characteristics. The main priority - safeguarding children -- is often negatively impacted by a huge forensic backlog, cognitive bias and the immense psychological stress that this work can entail. This paper evaluates existing facial image datasets and proposes a new dataset tailored to the needs of similar digital forensic research contributions. This small, diverse dataset of 0 to 20-year-old individuals contains 245 images and is merged with 82 unique images from the FG-NET dataset, thus achieving a total of 327 images with high image diversity and low age range density. The new dataset is tested on the Deep EXpectation (DEX) algorithm pre-trained on the IMDB-WIKI dataset. The overall results for young adolescents aged 10 to 15 and older adolescents/adults aged 16 to 20 are very encouraging -- achieving MAEs as low as 1.79, but also suggest that the accuracy for children aged 0 to 10 needs further work. In order to determine the efficacy of the prototype, valuable input of four digital forensic experts, including two forensic investigators, has been taken into account to improve age estimation results. Further research is required to extend datasets both concerning image density and the equal distribution of factors such as gender and racial diversity.
Advanced local motion patterns for macro and micro facial expression recognition
May 04, 2018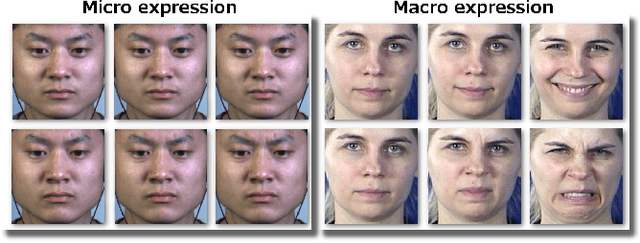
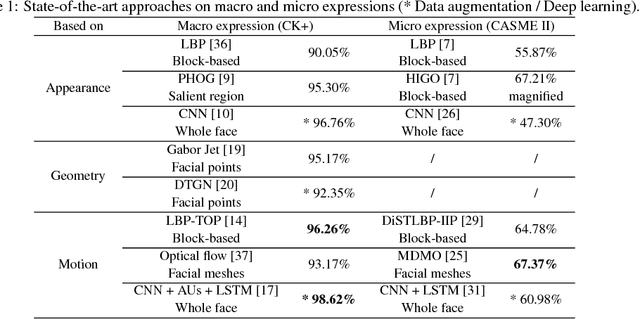
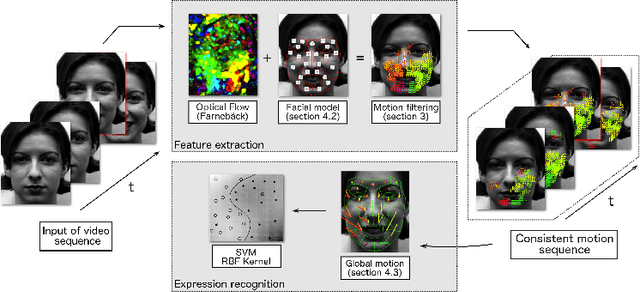
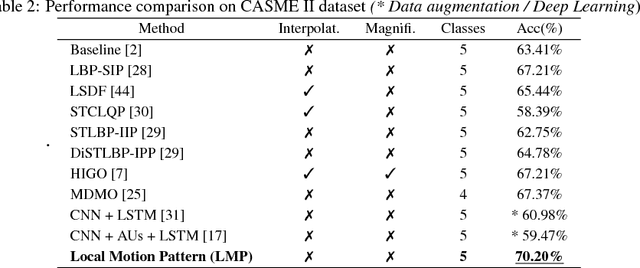
In this paper, we develop a new method that recognizes facial expressions, on the basis of an innovative local motion patterns feature, with three main contributions. The first one is the analysis of the face skin temporal elasticity and face deformations during expression. The second one is a unified approach for both macro and micro expression recognition. And, the third one is the step forward towards in-the-wild expression recognition, dealing with challenges such as various intensity and various expression activation patterns, illumination variation and small head pose variations. Our method outperforms state-of-the-art methods for micro expression recognition and positions itself among top-rank state-of-the-art methods for macro expression recognition.
Learning to Deblur and Rotate Motion-Blurred Faces
Dec 14, 2021
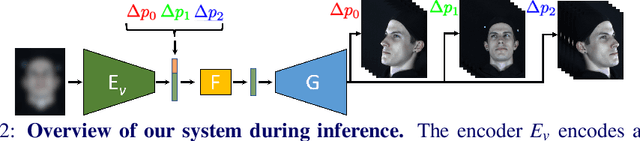
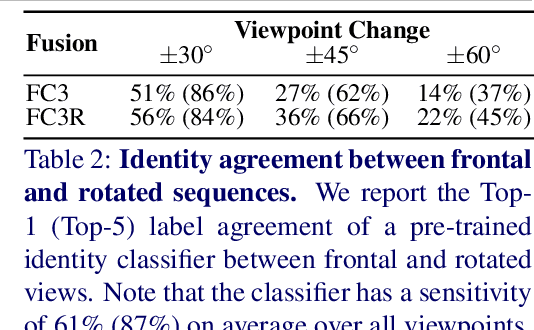
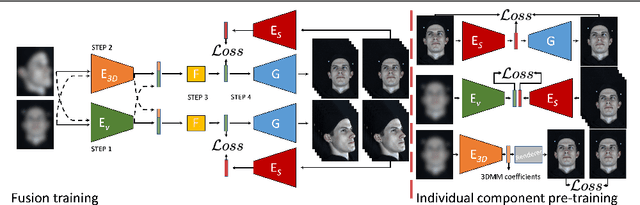
We propose a solution to the novel task of rendering sharp videos from new viewpoints from a single motion-blurred image of a face. Our method handles the complexity of face blur by implicitly learning the geometry and motion of faces through the joint training on three large datasets: FFHQ and 300VW, which are publicly available, and a new Bern Multi-View Face Dataset (BMFD) that we built. The first two datasets provide a large variety of faces and allow our model to generalize better. BMFD instead allows us to introduce multi-view constraints, which are crucial to synthesizing sharp videos from a new camera view. It consists of high frame rate synchronized videos from multiple views of several subjects displaying a wide range of facial expressions. We use the high frame rate videos to simulate realistic motion blur through averaging. Thanks to this dataset, we train a neural network to reconstruct a 3D video representation from a single image and the corresponding face gaze. We then provide a camera viewpoint relative to the estimated gaze and the blurry image as input to an encoder-decoder network to generate a video of sharp frames with a novel camera viewpoint. We demonstrate our approach on test subjects of our multi-view dataset and VIDTIMIT.
Only a Matter of Style: Age Transformation Using a Style-Based Regression Model
Feb 04, 2021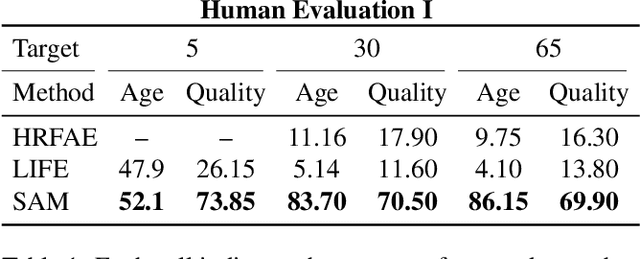
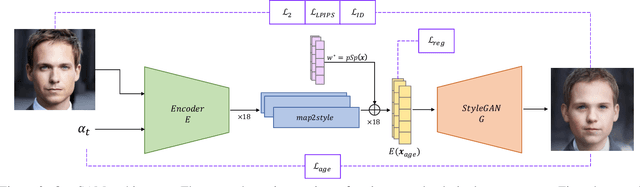

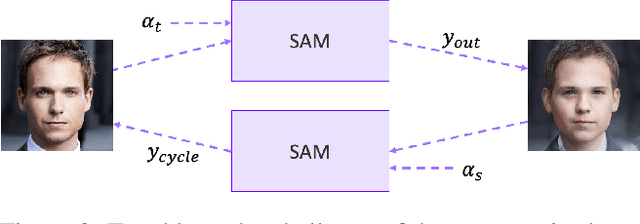
The task of age transformation illustrates the change of an individual's appearance over time. Accurately modeling this complex transformation over an input facial image is extremely challenging as it requires making convincing and possibly large changes to facial features and head shape, while still preserving the input identity. In this work, we present an image-to-image translation method that learns to directly encode real facial images into the latent space of a pre-trained unconditional GAN (e.g., StyleGAN) subject to a given aging shift. We employ a pre-trained age regression network used to explicitly guide the encoder in generating the latent codes corresponding to the desired age. In this formulation, our method approaches the continuous aging process as a regression task between the input age and desired target age, providing fine-grained control over the generated image. Moreover, unlike other approaches that operate solely in the latent space using a prior on the path controlling age, our method learns a more disentangled, non-linear path. Finally, we demonstrate that the end-to-end nature of our approach, coupled with the rich semantic latent space of StyleGAN, allows for further editing of the generated images. Qualitative and quantitative evaluations show the advantages of our method compared to state-of-the-art approaches.
Exploring Biases and Prejudice of Facial Synthesis via Semantic Latent Space
Aug 23, 2021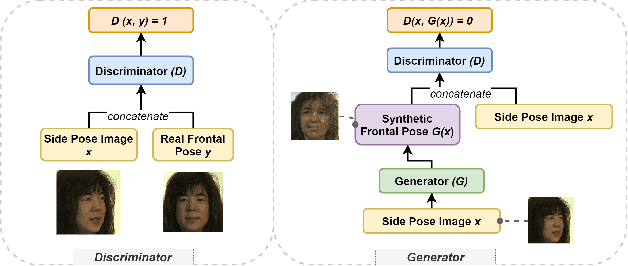
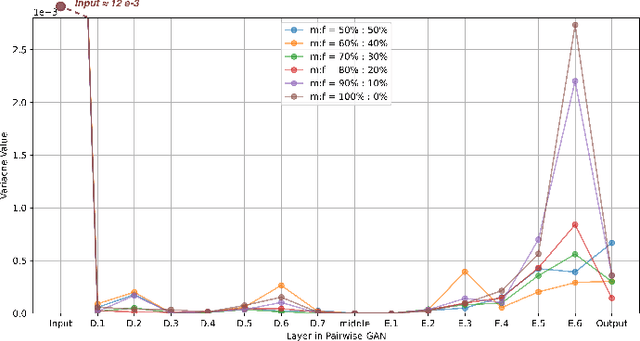
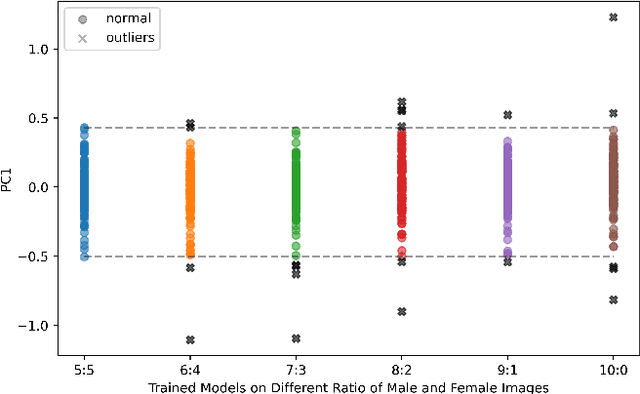
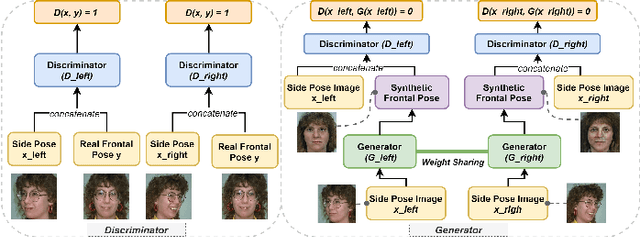
Deep learning (DL) models are widely used to provide a more convenient and smarter life. However, biased algorithms will negatively influence us. For instance, groups targeted by biased algorithms will feel unfairly treated and even fearful of negative consequences of these biases. This work targets biased generative models' behaviors, identifying the cause of the biases and eliminating them. We can (as expected) conclude that biased data causes biased predictions of face frontalization models. Varying the proportions of male and female faces in the training data can have a substantial effect on behavior on the test data: we found that the seemingly obvious choice of 50:50 proportions was not the best for this dataset to reduce biased behavior on female faces, which was 71% unbiased as compared to our top unbiased rate of 84%. Failure in generation and generating incorrect gender faces are two behaviors of these models. In addition, only some layers in face frontalization models are vulnerable to biased datasets. Optimizing the skip-connections of the generator in face frontalization models can make models less biased. We conclude that it is likely to be impossible to eliminate all training bias without an unlimited size dataset, and our experiments show that the bias can be reduced and quantified. We believe the next best to a perfect unbiased predictor is one that has minimized the remaining known bias.
Technical Challenges for Training Fair Neural Networks
Feb 12, 2021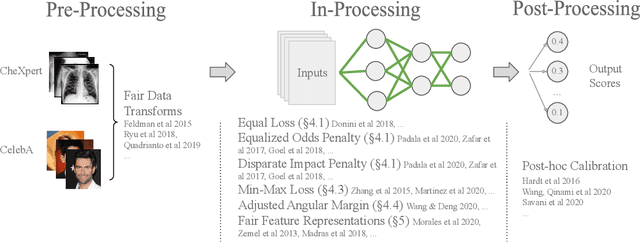
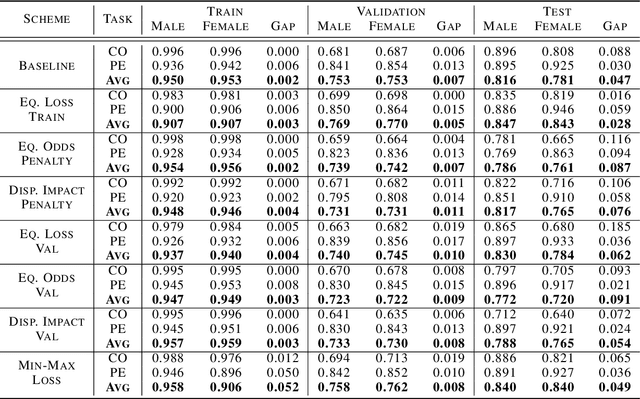

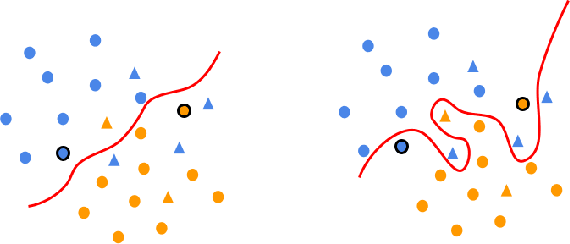
As machine learning algorithms have been widely deployed across applications, many concerns have been raised over the fairness of their predictions, especially in high stakes settings (such as facial recognition and medical imaging). To respond to these concerns, the community has proposed and formalized various notions of fairness as well as methods for rectifying unfair behavior. While fairness constraints have been studied extensively for classical models, the effectiveness of methods for imposing fairness on deep neural networks is unclear. In this paper, we observe that these large models overfit to fairness objectives, and produce a range of unintended and undesirable consequences. We conduct our experiments on both facial recognition and automated medical diagnosis datasets using state-of-the-art architectures.
Towards NIR-VIS Masked Face Recognition
Apr 14, 2021
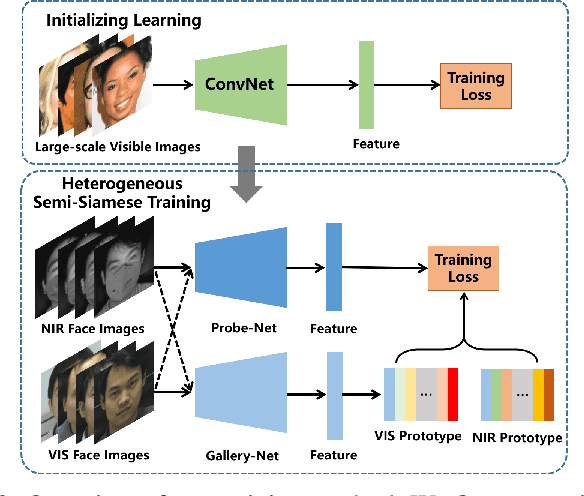
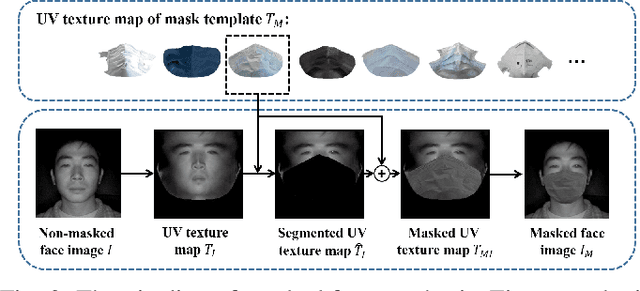

Near-infrared to visible (NIR-VIS) face recognition is the most common case in heterogeneous face recognition, which aims to match a pair of face images captured from two different modalities. Existing deep learning based methods have made remarkable progress in NIR-VIS face recognition, while it encounters certain newly-emerged difficulties during the pandemic of COVID-19, since people are supposed to wear facial masks to cut off the spread of the virus. We define this task as NIR-VIS masked face recognition, and find it problematic with the masked face in the NIR probe image. First, the lack of masked face data is a challenging issue for the network training. Second, most of the facial parts (cheeks, mouth, nose etc.) are fully occluded by the mask, which leads to a large amount of loss of information. Third, the domain gap still exists in the remaining facial parts. In such scenario, the existing methods suffer from significant performance degradation caused by the above issues. In this paper, we aim to address the challenge of NIR-VIS masked face recognition from the perspectives of training data and training method. Specifically, we propose a novel heterogeneous training method to maximize the mutual information shared by the face representation of two domains with the help of semi-siamese networks. In addition, a 3D face reconstruction based approach is employed to synthesize masked face from the existing NIR image. Resorting to these practices, our solution provides the domain-invariant face representation which is also robust to the mask occlusion. Extensive experiments on three NIR-VIS face datasets demonstrate the effectiveness and cross-dataset-generalization capacity of our method.
Deep Active Shape Model for Face Alignment and Pose Estimation in Mobile Environment
Mar 11, 2021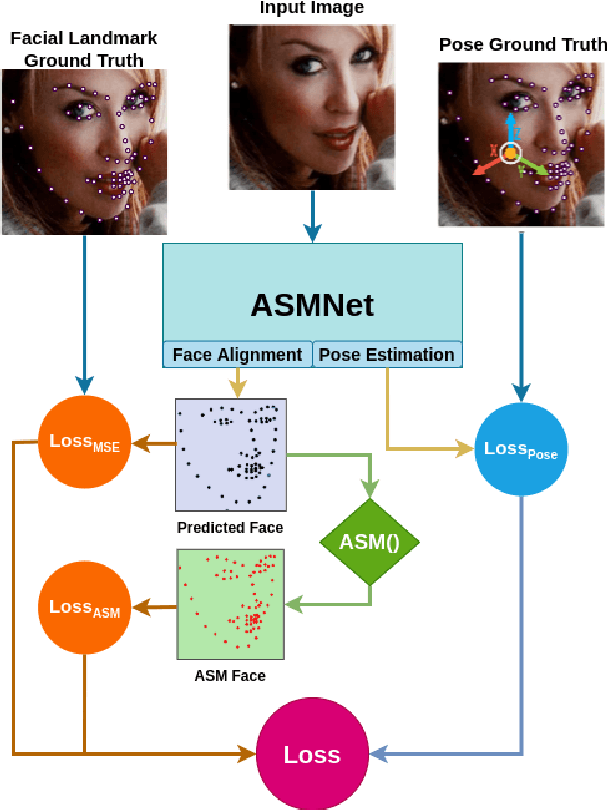
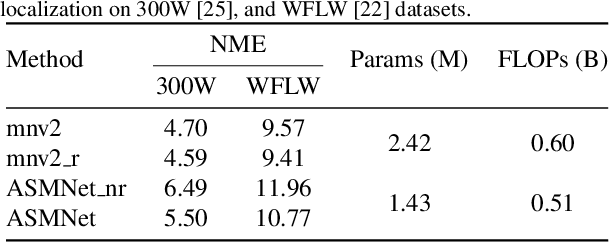
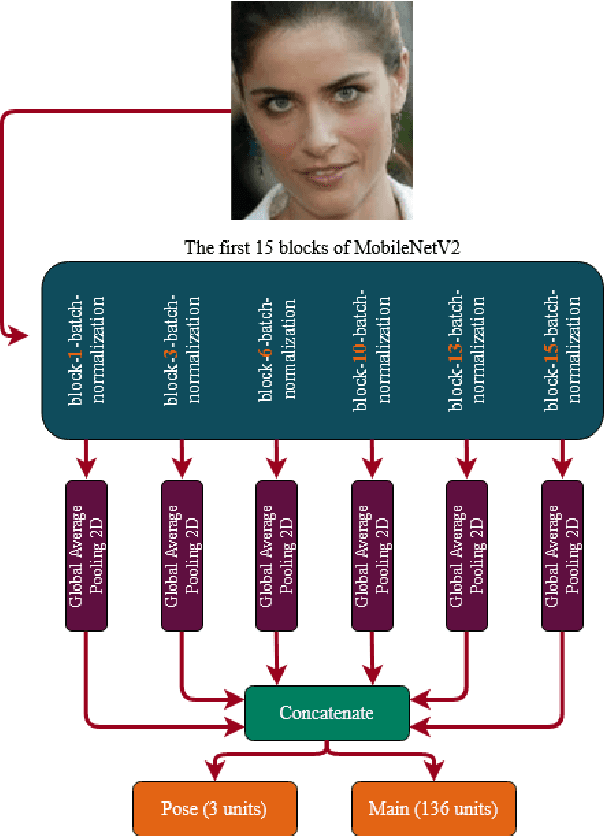
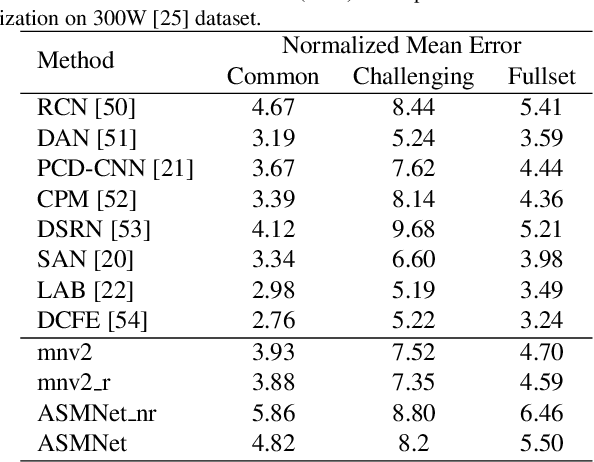
Active Shape Model (ASM) is a statistical model of object shapes that represents a target structure. ASM can guide machine learning algorithms to fit a set of points representing an object (e.g., face) onto an image. This paper presents a lightweight Convolutional Neural Network (CNN) architecture with a loss function being assisted by ASM for face alignment and estimating head pose in the wild. We use ASM to first guide the network towards learning the smoother distribution of the facial landmark points. Then, during the training process, inspired by the transfer learning, we gradually harden the regression problem and lead the network towards learning the original landmark points distribution. We define multi-tasks in our loss function that are responsible for detecting facial landmark points, as well as estimating face pose. Learning multiple correlated tasks simultaneously builds synergy and improves the performance of individual tasks. We compare the performance of our proposed CNN, ASMNet with MobileNetV2 (which is about 2 times bigger ASMNet) in both face alignment and pose estimation tasks. Experimental results on challenging datasets show that by using the proposed ASM assisted loss function, ASMNet performance is comparable with MobileNetV2 in face alignment task. Besides, for face pose estimation, ASMNet performs much better than MobileNetV2. Moreover, overall ASMNet achieves an acceptable performance for facial landmark points detection and pose estimation while having a significantly smaller number of parameters and floating-point operations comparing to many CNN-based proposed models.