 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Advanced local motion patterns for macro and micro facial expression recognition
May 04, 2018
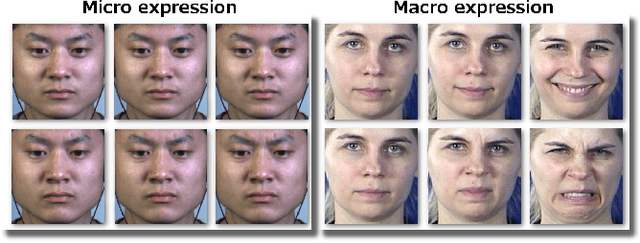
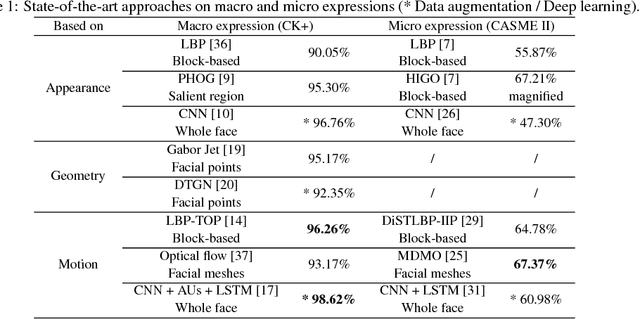
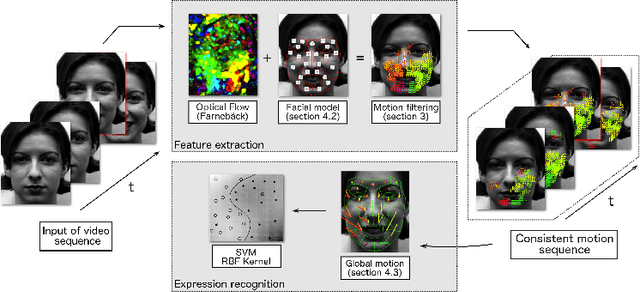
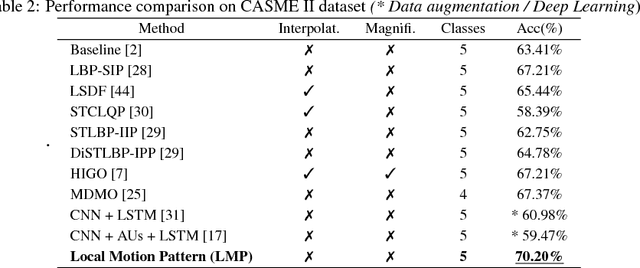
In this paper, we develop a new method that recognizes facial expressions, on the basis of an innovative local motion patterns feature, with three main contributions. The first one is the analysis of the face skin temporal elasticity and face deformations during expression. The second one is a unified approach for both macro and micro expression recognition. And, the third one is the step forward towards in-the-wild expression recognition, dealing with challenges such as various intensity and various expression activation patterns, illumination variation and small head pose variations. Our method outperforms state-of-the-art methods for micro expression recognition and positions itself among top-rank state-of-the-art methods for macro expression recognition.
Exploring Biases and Prejudice of Facial Synthesis via Semantic Latent Space
Aug 23, 2021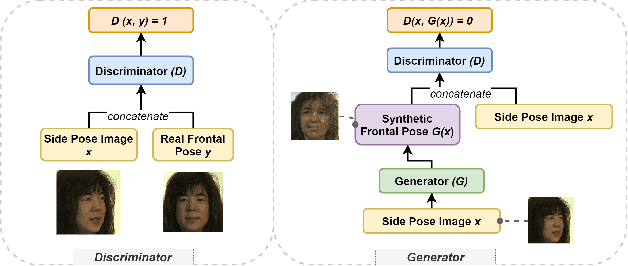
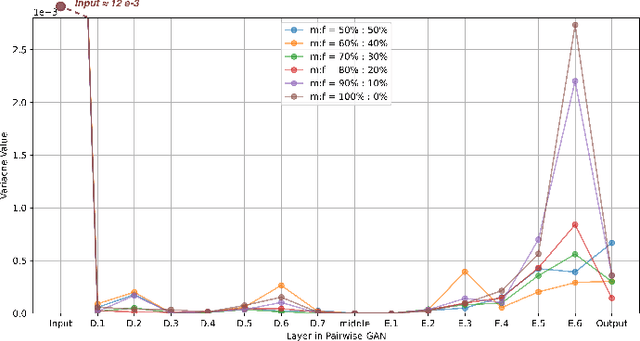
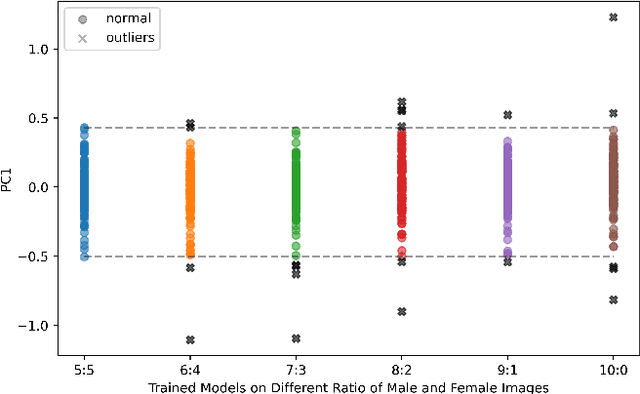
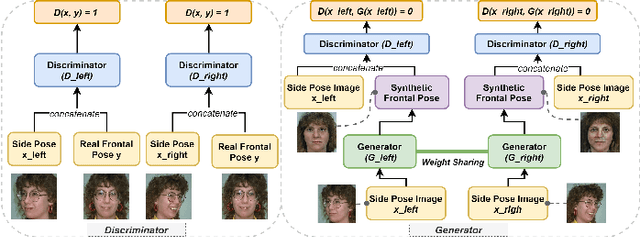
Deep learning (DL) models are widely used to provide a more convenient and smarter life. However, biased algorithms will negatively influence us. For instance, groups targeted by biased algorithms will feel unfairly treated and even fearful of negative consequences of these biases. This work targets biased generative models' behaviors, identifying the cause of the biases and eliminating them. We can (as expected) conclude that biased data causes biased predictions of face frontalization models. Varying the proportions of male and female faces in the training data can have a substantial effect on behavior on the test data: we found that the seemingly obvious choice of 50:50 proportions was not the best for this dataset to reduce biased behavior on female faces, which was 71% unbiased as compared to our top unbiased rate of 84%. Failure in generation and generating incorrect gender faces are two behaviors of these models. In addition, only some layers in face frontalization models are vulnerable to biased datasets. Optimizing the skip-connections of the generator in face frontalization models can make models less biased. We conclude that it is likely to be impossible to eliminate all training bias without an unlimited size dataset, and our experiments show that the bias can be reduced and quantified. We believe the next best to a perfect unbiased predictor is one that has minimized the remaining known bias.
Modelling Lips-State Detection Using CNN for Non-Verbal Communications
Dec 11, 2021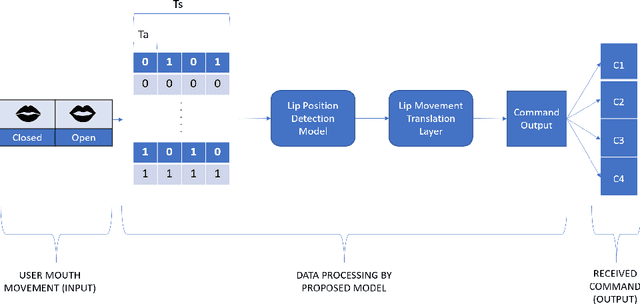
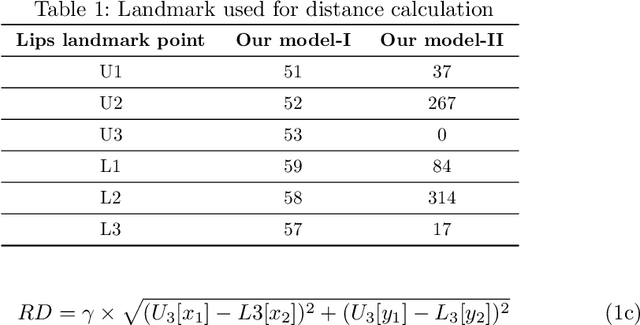
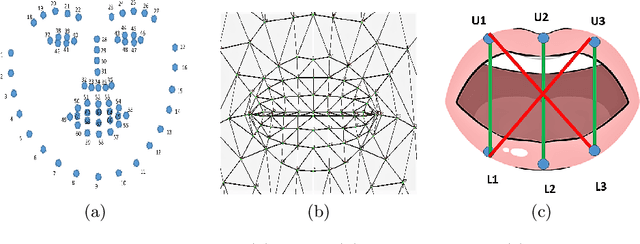
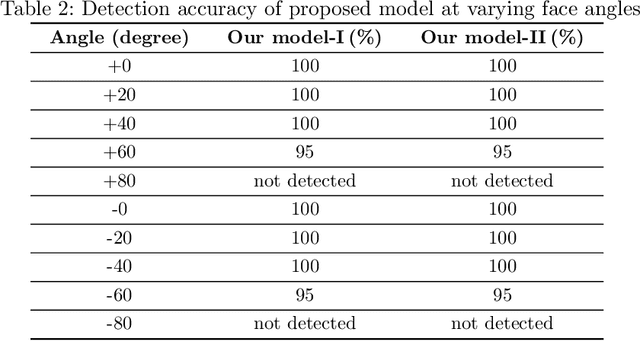
Vision-based deep learning models can be promising for speech-and-hearing-impaired and secret communications. While such non-verbal communications are primarily investigated with hand-gestures and facial expressions, no research endeavour is tracked so far for the lips state (i.e., open/close)-based interpretation/translation system. In support of this development, this paper reports two new Convolutional Neural Network (CNN) models for lips state detection. Building upon two prominent lips landmark detectors, DLIB and MediaPipe, we simplify lips-state model with a set of six key landmarks, and use their distances for the lips state classification. Thereby, both the models are developed to count the opening and closing of lips and thus, they can classify a symbol with the total count. Varying frame-rates, lips-movements and face-angles are investigated to determine the effectiveness of the models. Our early experimental results demonstrate that the model with DLIB is relatively slower in terms of an average of 6 frames per second (FPS) and higher average detection accuracy of 95.25%. In contrast, the model with MediaPipe offers faster landmark detection capability with an average FPS of 20 and detection accuracy of 94.4%. Both models thus could effectively interpret the lips state for non-verbal semantics into a natural language.
Towards NIR-VIS Masked Face Recognition
Apr 14, 2021
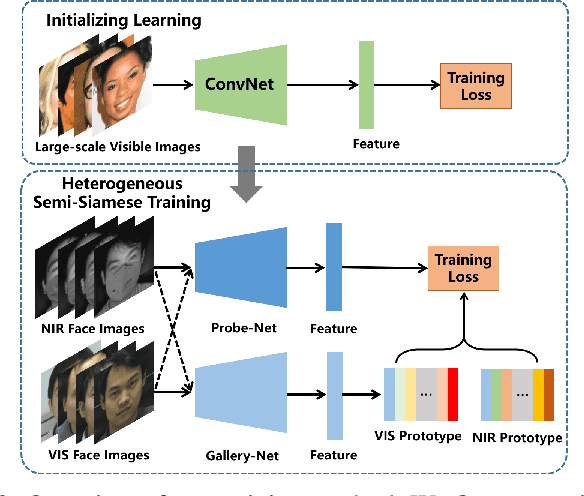
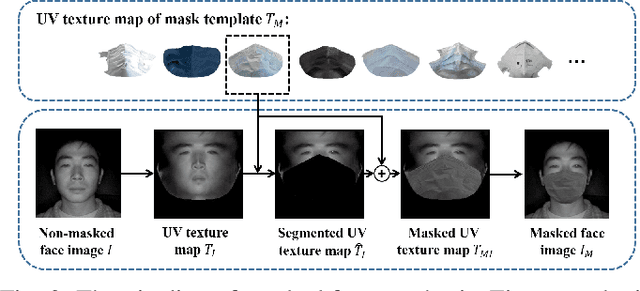

Near-infrared to visible (NIR-VIS) face recognition is the most common case in heterogeneous face recognition, which aims to match a pair of face images captured from two different modalities. Existing deep learning based methods have made remarkable progress in NIR-VIS face recognition, while it encounters certain newly-emerged difficulties during the pandemic of COVID-19, since people are supposed to wear facial masks to cut off the spread of the virus. We define this task as NIR-VIS masked face recognition, and find it problematic with the masked face in the NIR probe image. First, the lack of masked face data is a challenging issue for the network training. Second, most of the facial parts (cheeks, mouth, nose etc.) are fully occluded by the mask, which leads to a large amount of loss of information. Third, the domain gap still exists in the remaining facial parts. In such scenario, the existing methods suffer from significant performance degradation caused by the above issues. In this paper, we aim to address the challenge of NIR-VIS masked face recognition from the perspectives of training data and training method. Specifically, we propose a novel heterogeneous training method to maximize the mutual information shared by the face representation of two domains with the help of semi-siamese networks. In addition, a 3D face reconstruction based approach is employed to synthesize masked face from the existing NIR image. Resorting to these practices, our solution provides the domain-invariant face representation which is also robust to the mask occlusion. Extensive experiments on three NIR-VIS face datasets demonstrate the effectiveness and cross-dataset-generalization capacity of our method.
Technical Challenges for Training Fair Neural Networks
Feb 12, 2021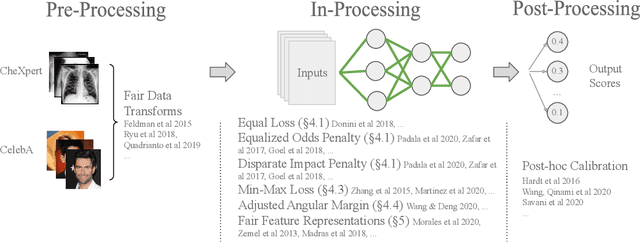
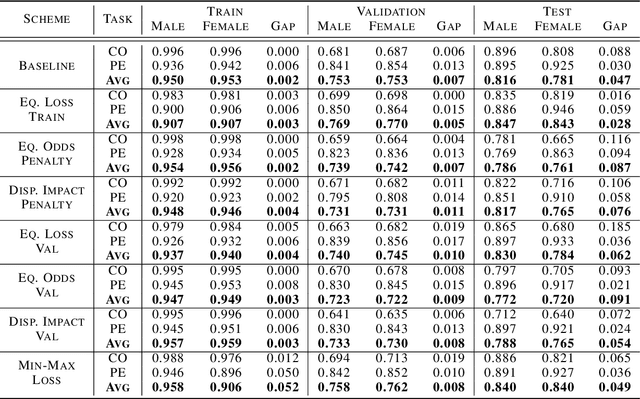

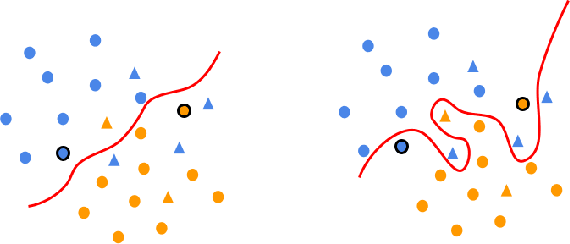
As machine learning algorithms have been widely deployed across applications, many concerns have been raised over the fairness of their predictions, especially in high stakes settings (such as facial recognition and medical imaging). To respond to these concerns, the community has proposed and formalized various notions of fairness as well as methods for rectifying unfair behavior. While fairness constraints have been studied extensively for classical models, the effectiveness of methods for imposing fairness on deep neural networks is unclear. In this paper, we observe that these large models overfit to fairness objectives, and produce a range of unintended and undesirable consequences. We conduct our experiments on both facial recognition and automated medical diagnosis datasets using state-of-the-art architectures.
Deep Active Shape Model for Face Alignment and Pose Estimation in Mobile Environment
Mar 11, 2021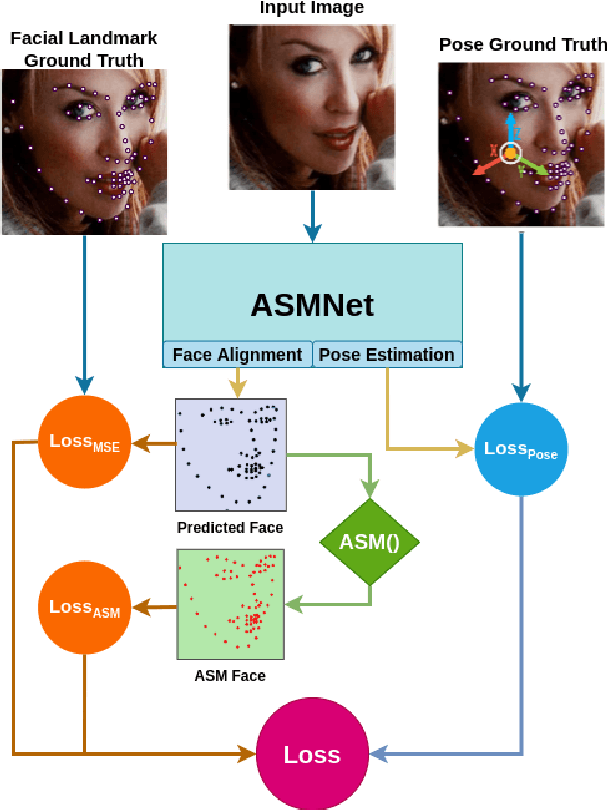
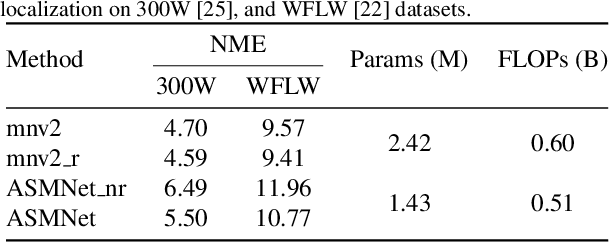
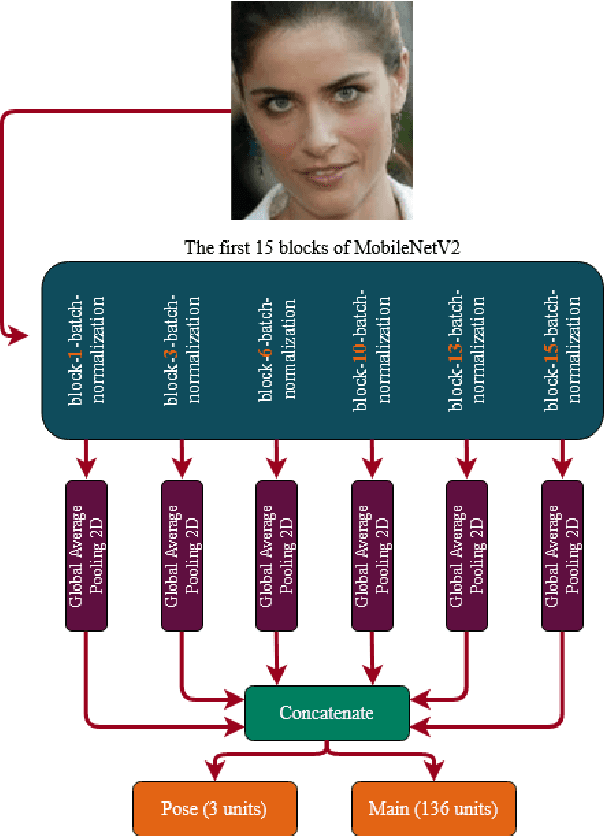
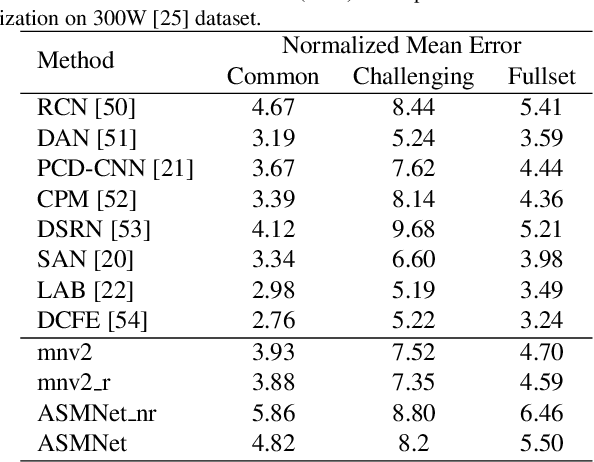
Active Shape Model (ASM) is a statistical model of object shapes that represents a target structure. ASM can guide machine learning algorithms to fit a set of points representing an object (e.g., face) onto an image. This paper presents a lightweight Convolutional Neural Network (CNN) architecture with a loss function being assisted by ASM for face alignment and estimating head pose in the wild. We use ASM to first guide the network towards learning the smoother distribution of the facial landmark points. Then, during the training process, inspired by the transfer learning, we gradually harden the regression problem and lead the network towards learning the original landmark points distribution. We define multi-tasks in our loss function that are responsible for detecting facial landmark points, as well as estimating face pose. Learning multiple correlated tasks simultaneously builds synergy and improves the performance of individual tasks. We compare the performance of our proposed CNN, ASMNet with MobileNetV2 (which is about 2 times bigger ASMNet) in both face alignment and pose estimation tasks. Experimental results on challenging datasets show that by using the proposed ASM assisted loss function, ASMNet performance is comparable with MobileNetV2 in face alignment task. Besides, for face pose estimation, ASMNet performs much better than MobileNetV2. Moreover, overall ASMNet achieves an acceptable performance for facial landmark points detection and pose estimation while having a significantly smaller number of parameters and floating-point operations comparing to many CNN-based proposed models.
Information-Theoretic Bias Assessment Of Learned Representations Of Pretrained Face Recognition
Nov 09, 2021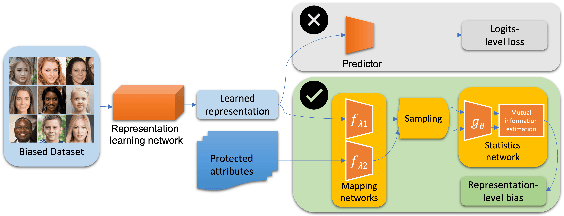
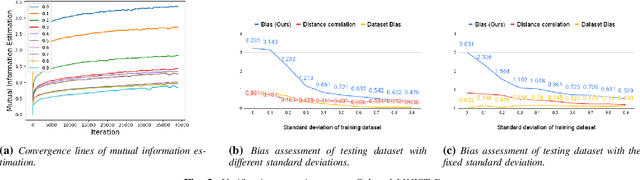
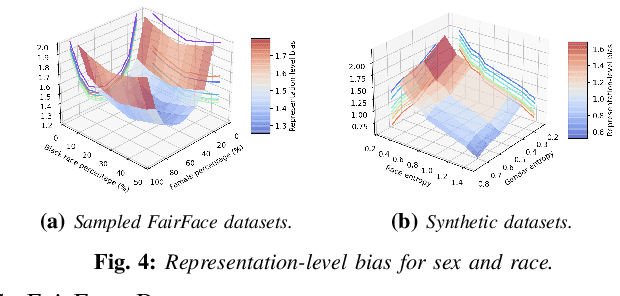

As equality issues in the use of face recognition have garnered a lot of attention lately, greater efforts have been made to debiased deep learning models to improve fairness to minorities. However, there is still no clear definition nor sufficient analysis for bias assessment metrics. We propose an information-theoretic, independent bias assessment metric to identify degree of bias against protected demographic attributes from learned representations of pretrained facial recognition systems. Our metric differs from other methods that rely on classification accuracy or examine the differences between ground truth and predicted labels of protected attributes predicted using a shallow network. Also, we argue, theoretically and experimentally, that logits-level loss is not adequate to explain bias since predictors based on neural networks will always find correlations. Further, we present a synthetic dataset that mitigates the issue of insufficient samples in certain cohorts. Lastly, we establish a benchmark metric by presenting advantages in clear discrimination and small variation comparing with other metrics, and evaluate the performance of different debiased models with the proposed metric.
A Computer Vision Application for Assessing Facial Acne Severity from Selfie Images
Jul 31, 2019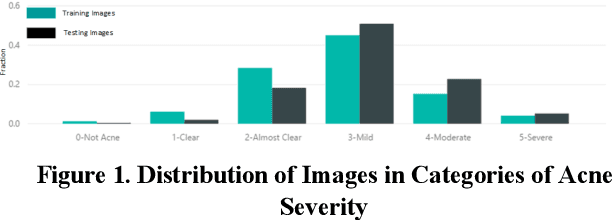
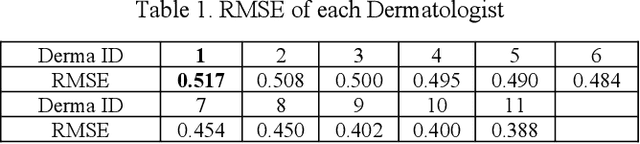
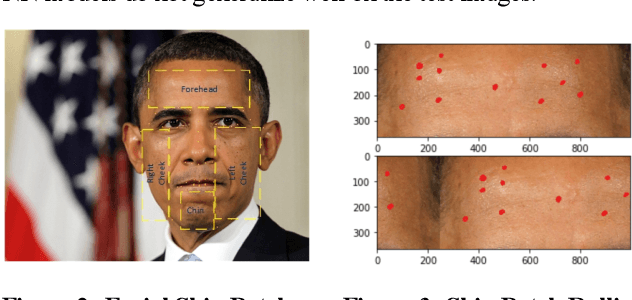
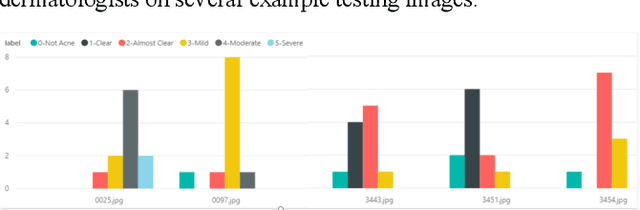
We worked with Nestle SHIELD (Skin Health, Innovation, Education, and Longevity Development, NSH) to develop a deep learning model that is able to assess acne severity from selfie images as accurate as dermatologists. The model was deployed as a mobile application, providing patients an easy way to assess and track the progress of their acne treatment. NSH acquired 4,700 selfie images for this study and recruited 11 internal dermatologists to label them in five categories: 1-Clear, 2- Almost Clear, 3-Mild, 4-Moderate, 5-Severe. Using OpenCV to detect facial landmarks we cut specific skin patches from the selfie images in order to minimize irrelevant background. We then applied a transfer learning approach by extracting features from the patches using a ResNet 152 pre-trained model, followed by a fully connected layer trained to approximate the desired severity rating. To address the problem of spatial sensitivity of CNN models, we introduce a new image rolling data augmentation approach, effectively causing acne lesions appeared in more locations in the training images. Our results demonstrate that this approach improved the generalization of the CNN model, outperforming more than half of the panel of human dermatologists on test images. To our knowledge, this is the first deep learning-based solution for acne assessment using selfie images.
SeCGAN: Parallel Conditional Generative Adversarial Networks for Face Editing via Semantic Consistency
Nov 24, 2021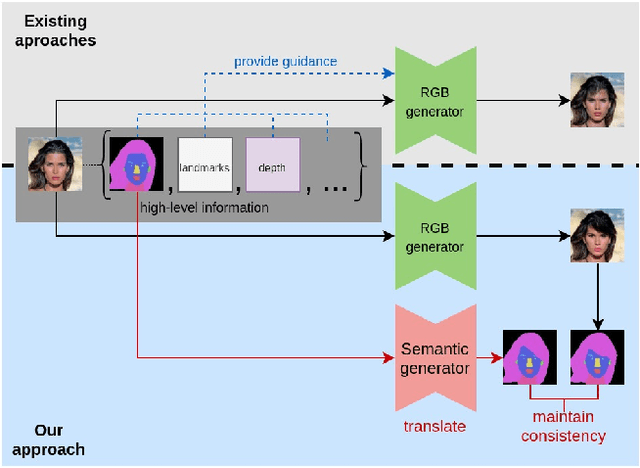
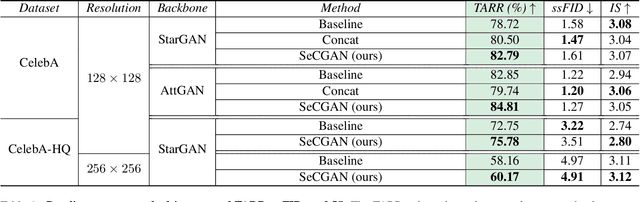
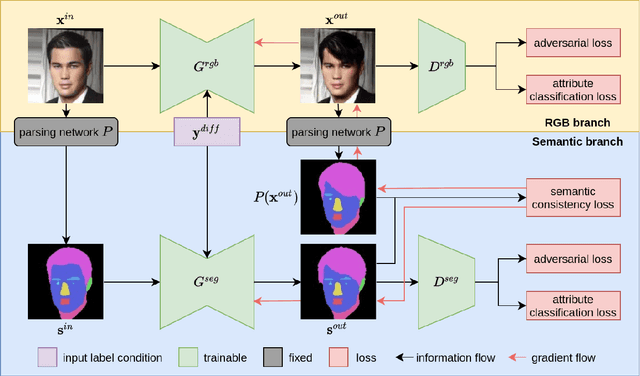
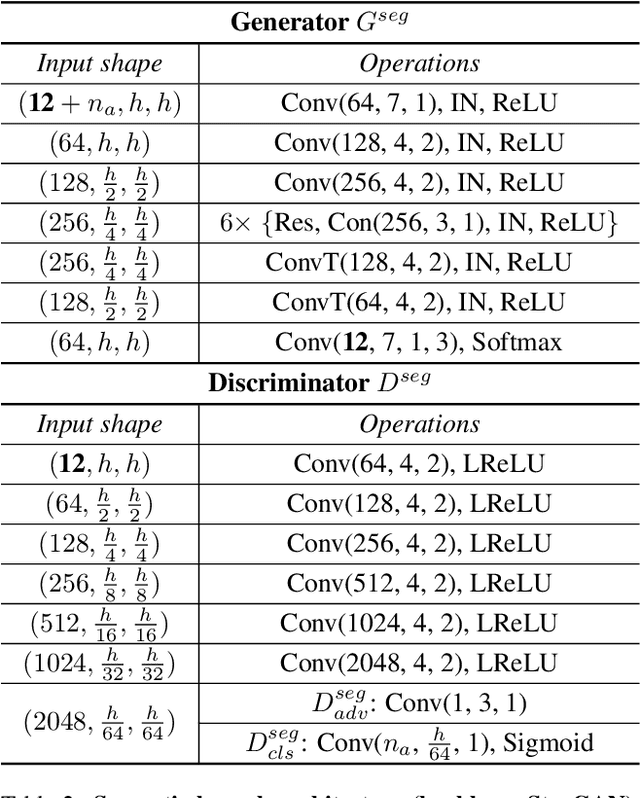
Semantically guided conditional Generative Adversarial Networks (cGANs) have become a popular approach for face editing in recent years. However, most existing methods introduce semantic masks as direct conditional inputs to the generator and often require the target masks to perform the corresponding translation in the RGB space. We propose SeCGAN, a novel label-guided cGAN for editing face images utilising semantic information without the need to specify target semantic masks. During training, SeCGAN has two branches of generators and discriminators operating in parallel, with one trained to translate RGB images and the other for semantic masks. To bridge the two branches in a mutually beneficial manner, we introduce a semantic consistency loss which constrains both branches to have consistent semantic outputs. Whilst both branches are required during training, the RGB branch is our primary network and the semantic branch is not needed for inference. Our results on CelebA and CelebA-HQ demonstrate that our approach is able to generate facial images with more accurate attributes, outperforming competitive baselines in terms of Target Attribute Recognition Rate whilst maintaining quality metrics such as self-supervised Fr\'{e}chet Inception Distance and Inception Score.