 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Semantic Text-to-Face GAN -ST^2FG
Jul 22, 2021

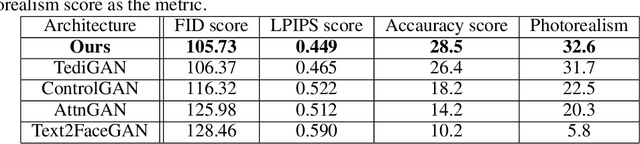
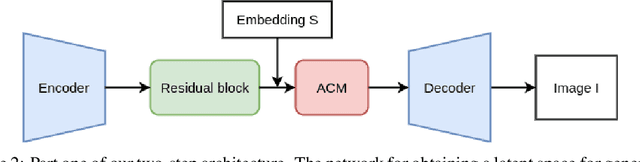

Faces generated using generative adversarial networks (GANs) have reached unprecedented realism. These faces, also known as "Deep Fakes", appear as realistic photographs with very little pixel-level distortions. While some work has enabled the training of models that lead to the generation of specific properties of the subject, generating a facial image based on a natural language description has not been fully explored. For security and criminal identification, the ability to provide a GAN-based system that works like a sketch artist would be incredibly useful. In this paper, we present a novel approach to generate facial images from semantic text descriptions. The learned model is provided with a text description and an outline of the type of face, which the model uses to sketch the features. Our models are trained using an Affine Combination Module (ACM) mechanism to combine the text embedding from BERT and the GAN latent space using a self-attention matrix. This avoids the loss of features due to inadequate "attention", which may happen if text embedding and latent vector are simply concatenated. Our approach is capable of generating images that are very accurately aligned to the exhaustive textual descriptions of faces with many fine detail features of the face and helps in generating better images. The proposed method is also capable of making incremental changes to a previously generated image if it is provided with additional textual descriptions or sentences.
Applying Artificial Intelligence for Age Estimation in Digital Forensic Investigations
Jan 09, 2022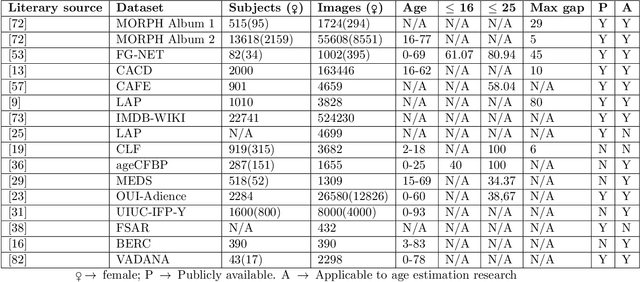
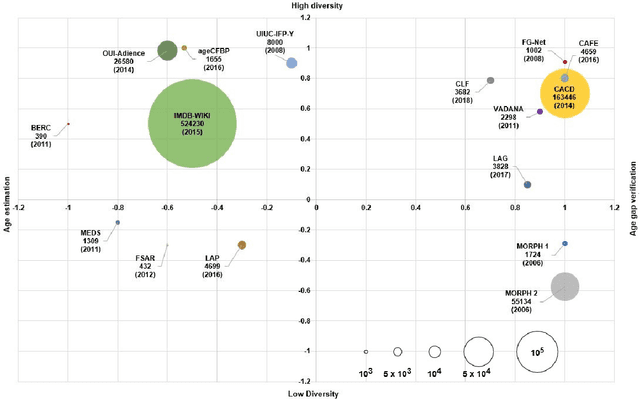

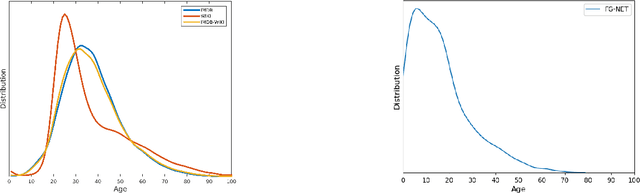
The precise age estimation of child sexual abuse and exploitation (CSAE) victims is one of the most significant digital forensic challenges. Investigators often need to determine the age of victims by looking at images and interpreting the sexual development stages and other human characteristics. The main priority - safeguarding children -- is often negatively impacted by a huge forensic backlog, cognitive bias and the immense psychological stress that this work can entail. This paper evaluates existing facial image datasets and proposes a new dataset tailored to the needs of similar digital forensic research contributions. This small, diverse dataset of 0 to 20-year-old individuals contains 245 images and is merged with 82 unique images from the FG-NET dataset, thus achieving a total of 327 images with high image diversity and low age range density. The new dataset is tested on the Deep EXpectation (DEX) algorithm pre-trained on the IMDB-WIKI dataset. The overall results for young adolescents aged 10 to 15 and older adolescents/adults aged 16 to 20 are very encouraging -- achieving MAEs as low as 1.79, but also suggest that the accuracy for children aged 0 to 10 needs further work. In order to determine the efficacy of the prototype, valuable input of four digital forensic experts, including two forensic investigators, has been taken into account to improve age estimation results. Further research is required to extend datasets both concerning image density and the equal distribution of factors such as gender and racial diversity.
SELM: Siamese Extreme Learning Machine with Application to Face Biometrics
Aug 06, 2021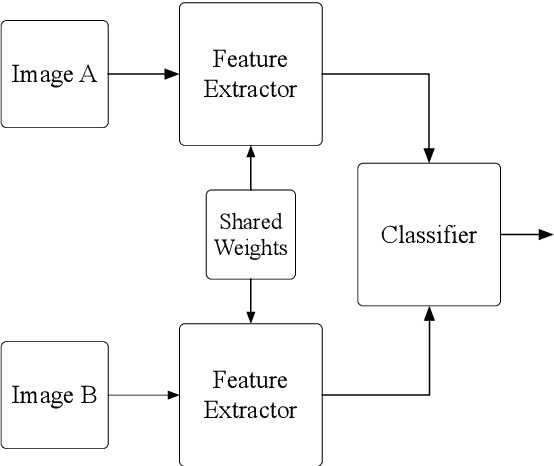
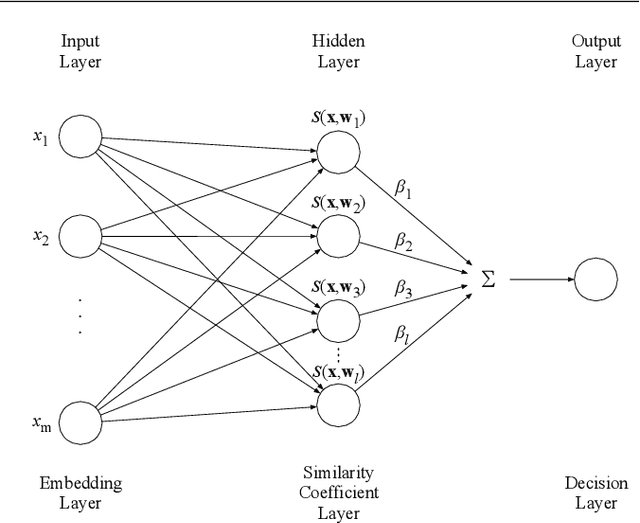
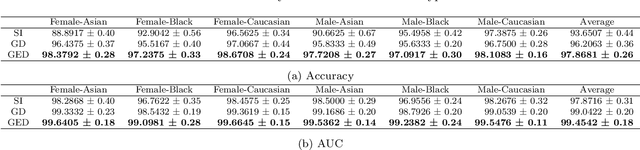
Extreme Learning Machine is a powerful classification method very competitive existing classification methods. It is extremely fast at training. Nevertheless, it cannot perform face verification tasks properly because face verification tasks require comparison of facial images of two individuals at the same time and decide whether the two faces identify the same person. The structure of Extreme Leaning Machine was not designed to feed two input data streams simultaneously, thus, in 2-input scenarios Extreme Learning Machine methods are normally applied using concatenated inputs. However, this setup consumes two times more computational resources and it is not optimized for recognition tasks where learning a separable distance metric is critical. For these reasons, we propose and develop a Siamese Extreme Learning Machine (SELM). SELM was designed to be fed with two data streams in parallel simultaneously. It utilizes a dual-stream Siamese condition in the extra Siamese layer to transform the data before passing it along to the hidden layer. Moreover, we propose a Gender-Ethnicity-Dependent triplet feature exclusively trained on a variety of specific demographic groups. This feature enables learning and extracting of useful facial features of each group. Experiments were conducted to evaluate and compare the performances of SELM, Extreme Learning Machine, and DCNN. The experimental results showed that the proposed feature was able to perform correct classification at 97.87% accuracy and 99.45% AUC. They also showed that using SELM in conjunction with the proposed feature provided 98.31% accuracy and 99.72% AUC. They outperformed the well-known DCNN and Extreme Leaning Machine methods by a wide margin.
Audio-Driven Emotional Video Portraits
Apr 15, 2021
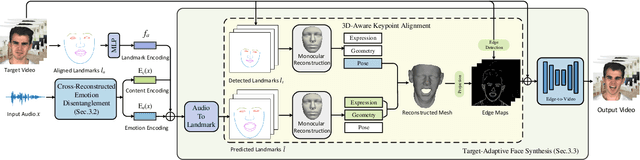
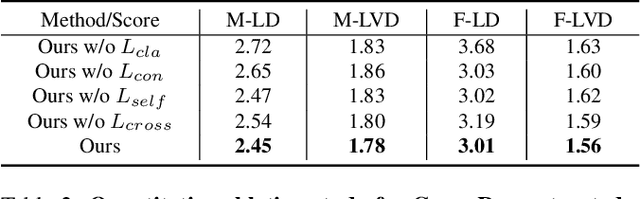
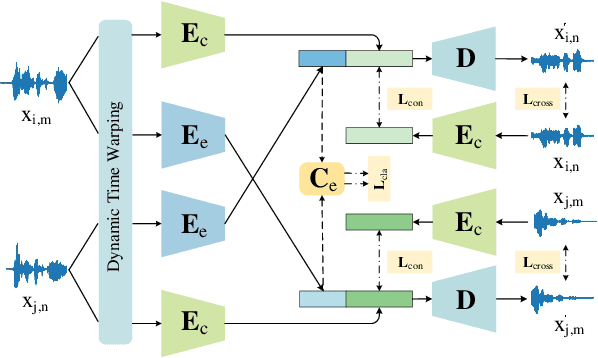
Despite previous success in generating audio-driven talking heads, most of the previous studies focus on the correlation between speech content and the mouth shape. Facial emotion, which is one of the most important features on natural human faces, is always neglected in their methods. In this work, we present Emotional Video Portraits (EVP), a system for synthesizing high-quality video portraits with vivid emotional dynamics driven by audios. Specifically, we propose the Cross-Reconstructed Emotion Disentanglement technique to decompose speech into two decoupled spaces, i.e., a duration-independent emotion space and a duration dependent content space. With the disentangled features, dynamic 2D emotional facial landmarks can be deduced. Then we propose the Target-Adaptive Face Synthesis technique to generate the final high-quality video portraits, by bridging the gap between the deduced landmarks and the natural head poses of target videos. Extensive experiments demonstrate the effectiveness of our method both qualitatively and quantitatively.
Learning to Deblur and Rotate Motion-Blurred Faces
Dec 14, 2021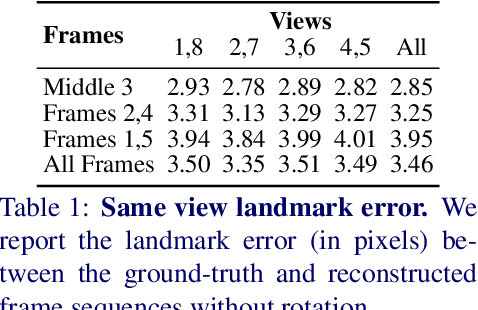
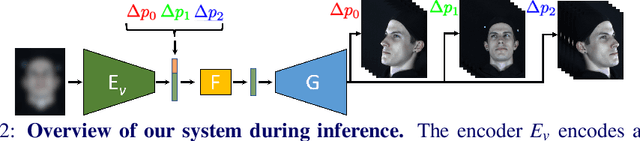
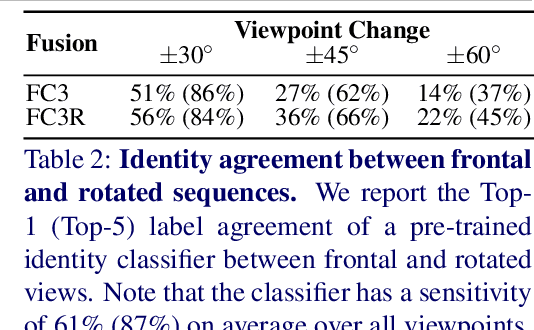
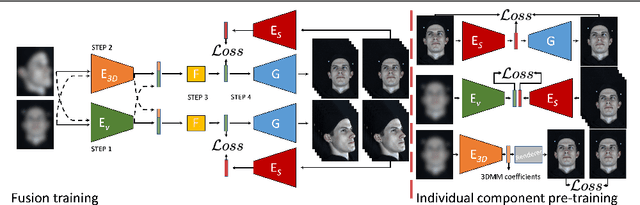
We propose a solution to the novel task of rendering sharp videos from new viewpoints from a single motion-blurred image of a face. Our method handles the complexity of face blur by implicitly learning the geometry and motion of faces through the joint training on three large datasets: FFHQ and 300VW, which are publicly available, and a new Bern Multi-View Face Dataset (BMFD) that we built. The first two datasets provide a large variety of faces and allow our model to generalize better. BMFD instead allows us to introduce multi-view constraints, which are crucial to synthesizing sharp videos from a new camera view. It consists of high frame rate synchronized videos from multiple views of several subjects displaying a wide range of facial expressions. We use the high frame rate videos to simulate realistic motion blur through averaging. Thanks to this dataset, we train a neural network to reconstruct a 3D video representation from a single image and the corresponding face gaze. We then provide a camera viewpoint relative to the estimated gaze and the blurry image as input to an encoder-decoder network to generate a video of sharp frames with a novel camera viewpoint. We demonstrate our approach on test subjects of our multi-view dataset and VIDTIMIT.
Facial Expression Detection using Patch-based Eigen-face Isomap Networks
Nov 11, 2015
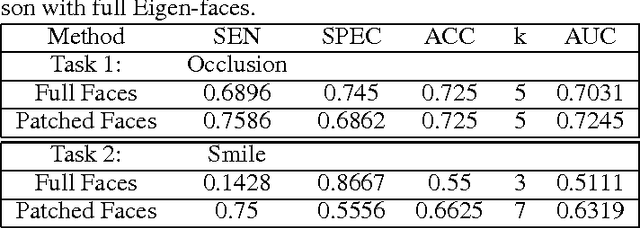
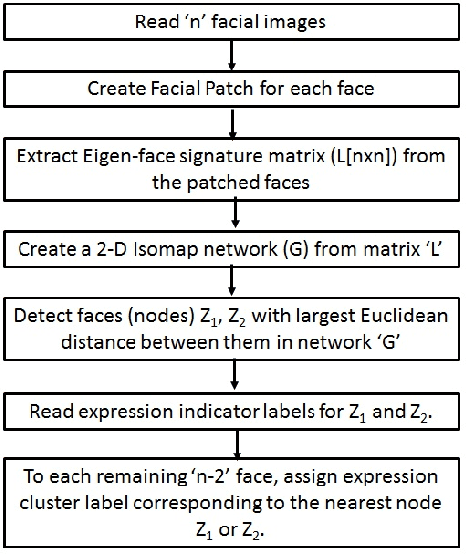
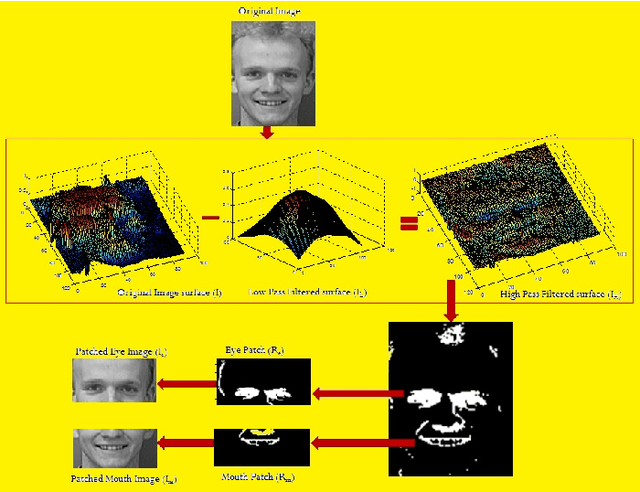
Automated facial expression detection problem pose two primary challenges that include variations in expression and facial occlusions (glasses, beard, mustache or face covers). In this paper we introduce a novel automated patch creation technique that masks a particular region of interest in the face, followed by Eigen-value decomposition of the patched faces and generation of Isomaps to detect underlying clustering patterns among faces. The proposed masked Eigen-face based Isomap clustering technique achieves 75% sensitivity and 66-73% accuracy in classification of faces with occlusions and smiling faces in around 1 second per image. Also, betweenness centrality, Eigen centrality and maximum information flow can be used as network-based measures to identify the most significant training faces for expression classification tasks. The proposed method can be used in combination with feature-based expression classification methods in large data sets for improving expression classification accuracies.
Unconstrained Face Recognition using ASURF and Cloud-Forest Classifier optimized with VLAD
Apr 02, 2021



The paper posits a computationally-efficient algorithm for multi-class facial image classification in which images are constrained with translation, rotation, scale, color, illumination and affine distortion. The proposed method is divided into five main building blocks including Haar-Cascade for face detection, Bilateral Filter for image preprocessing to remove unwanted noise, Affine Speeded-Up Robust Features (ASURF) for keypoint detection and description, Vector of Locally Aggregated Descriptors (VLAD) for feature quantization and Cloud Forest for image classification. The proposed method aims at improving the accuracy and the time taken for face recognition systems. The usage of the Cloud Forest algorithm as a classifier on three benchmark datasets, namely the FACES95, FACES96 and ORL facial datasets, showed promising results. The proposed methodology using Cloud Forest algorithm successfully improves the recognition model by 2-12\% when differentiated against other ensemble techniques like the Random Forest classifier depending upon the dataset used.
* 8 Pages, 3 Figures
LEED: Label-Free Expression Editing via Disentanglement
Jul 17, 2020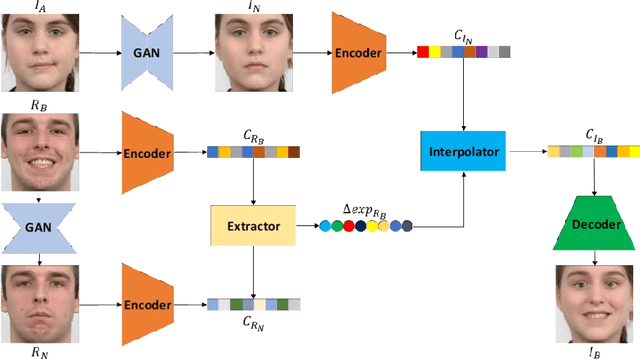


Recent studies on facial expression editing have obtained very promising progress. On the other hand, existing methods face the constraint of requiring a large amount of expression labels which are often expensive and time-consuming to collect. This paper presents an innovative label-free expression editing via disentanglement (LEED) framework that is capable of editing the expression of both frontal and profile facial images without requiring any expression label. The idea is to disentangle the identity and expression of a facial image in the expression manifold, where the neutral face captures the identity attribute and the displacement between the neutral image and the expressive image captures the expression attribute. Two novel losses are designed for optimal expression disentanglement and consistent synthesis, including a mutual expression information loss that aims to extract pure expression-related features and a siamese loss that aims to enhance the expression similarity between the synthesized image and the reference image. Extensive experiments over two public facial expression datasets show that LEED achieves superior facial expression editing qualitatively and quantitatively.
Identity-Preserving Realistic Talking Face Generation
May 25, 2020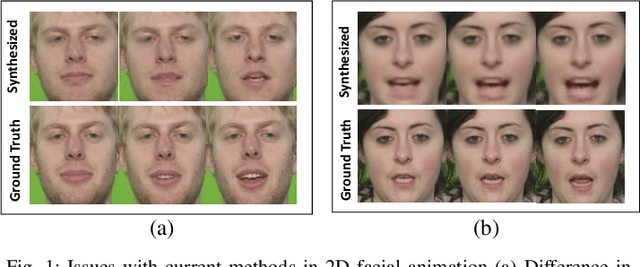

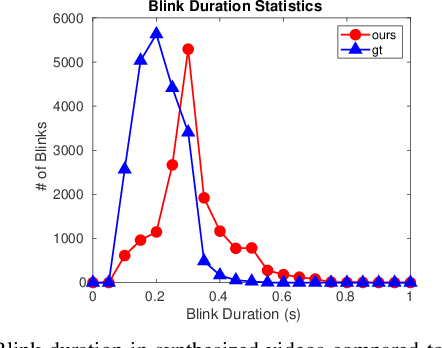
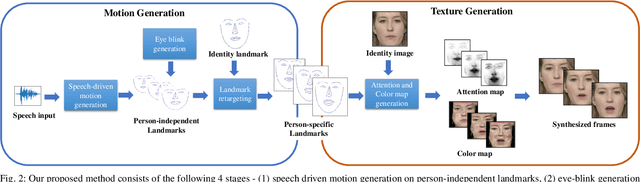
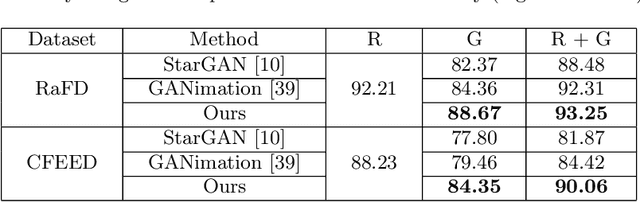
Speech-driven facial animation is useful for a variety of applications such as telepresence, chatbots, etc. The necessary attributes of having a realistic face animation are 1) audio-visual synchronization (2) identity preservation of the target individual (3) plausible mouth movements (4) presence of natural eye blinks. The existing methods mostly address the audio-visual lip synchronization, and few recent works have addressed the synthesis of natural eye blinks for overall video realism. In this paper, we propose a method for identity-preserving realistic facial animation from speech. We first generate person-independent facial landmarks from audio using DeepSpeech features for invariance to different voices, accents, etc. To add realism, we impose eye blinks on facial landmarks using unsupervised learning and retargets the person-independent landmarks to person-specific landmarks to preserve the identity-related facial structure which helps in the generation of plausible mouth shapes of the target identity. Finally, we use LSGAN to generate the facial texture from person-specific facial landmarks, using an attention mechanism that helps to preserve identity-related texture. An extensive comparison of our proposed method with the current state-of-the-art methods demonstrates a significant improvement in terms of lip synchronization accuracy, image reconstruction quality, sharpness, and identity-preservation. A user study also reveals improved realism of our animation results over the state-of-the-art methods. To the best of our knowledge, this is the first work in speech-driven 2D facial animation that simultaneously addresses all the above-mentioned attributes of a realistic speech-driven face animation.
Modelling Lips-State Detection Using CNN for Non-Verbal Communications
Dec 11, 2021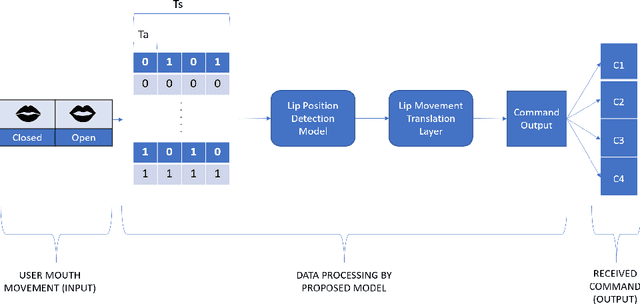
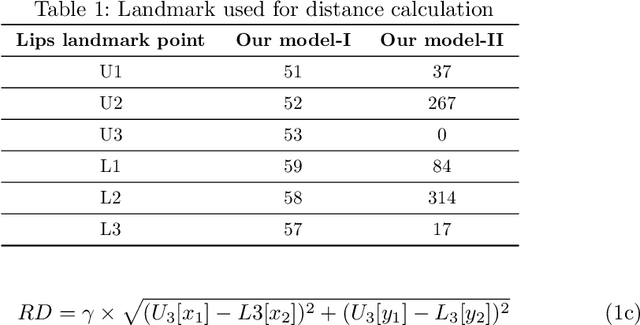
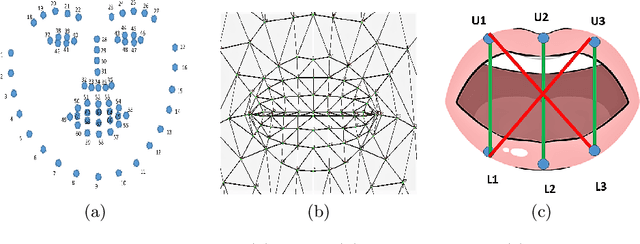
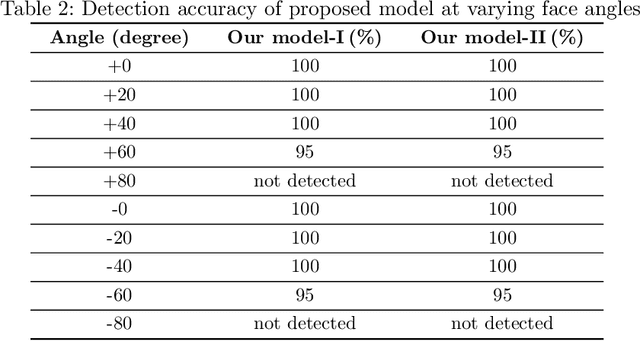
Vision-based deep learning models can be promising for speech-and-hearing-impaired and secret communications. While such non-verbal communications are primarily investigated with hand-gestures and facial expressions, no research endeavour is tracked so far for the lips state (i.e., open/close)-based interpretation/translation system. In support of this development, this paper reports two new Convolutional Neural Network (CNN) models for lips state detection. Building upon two prominent lips landmark detectors, DLIB and MediaPipe, we simplify lips-state model with a set of six key landmarks, and use their distances for the lips state classification. Thereby, both the models are developed to count the opening and closing of lips and thus, they can classify a symbol with the total count. Varying frame-rates, lips-movements and face-angles are investigated to determine the effectiveness of the models. Our early experimental results demonstrate that the model with DLIB is relatively slower in terms of an average of 6 frames per second (FPS) and higher average detection accuracy of 95.25%. In contrast, the model with MediaPipe offers faster landmark detection capability with an average FPS of 20 and detection accuracy of 94.4%. Both models thus could effectively interpret the lips state for non-verbal semantics into a natural language.