 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
EmoSpeaker: One-shot Fine-grained Emotion-Controlled Talking Face Generation
Feb 02, 2024
Implementing fine-grained emotion control is crucial for emotion generation tasks because it enhances the expressive capability of the generative model, allowing it to accurately and comprehensively capture and express various nuanced emotional states, thereby improving the emotional quality and personalization of generated content. Generating fine-grained facial animations that accurately portray emotional expressions using only a portrait and an audio recording presents a challenge. In order to address this challenge, we propose a visual attribute-guided audio decoupler. This enables the obtention of content vectors solely related to the audio content, enhancing the stability of subsequent lip movement coefficient predictions. To achieve more precise emotional expression, we introduce a fine-grained emotion coefficient prediction module. Additionally, we propose an emotion intensity control method using a fine-grained emotion matrix. Through these, effective control over emotional expression in the generated videos and finer classification of emotion intensity are accomplished. Subsequently, a series of 3DMM coefficient generation networks are designed to predict 3D coefficients, followed by the utilization of a rendering network to generate the final video. Our experimental results demonstrate that our proposed method, EmoSpeaker, outperforms existing emotional talking face generation methods in terms of expression variation and lip synchronization. Project page: https://peterfanfan.github.io/EmoSpeaker/
PatchBMI-Net: Lightweight Facial Patch-based Ensemble for BMI Prediction
Nov 29, 2023Due to an alarming trend related to obesity affecting 93.3 million adults in the United States alone, body mass index (BMI) and body weight have drawn significant interest in various health monitoring applications. Consequently, several studies have proposed self-diagnostic facial image-based BMI prediction methods for healthy weight monitoring. These methods have mostly used convolutional neural network (CNN) based regression baselines, such as VGG19, ResNet50, and Efficient-NetB0, for BMI prediction from facial images. However, the high computational requirement of these heavy-weight CNN models limits their deployment to resource-constrained mobile devices, thus deterring weight monitoring using smartphones. This paper aims to develop a lightweight facial patch-based ensemble (PatchBMI-Net) for BMI prediction to facilitate the deployment and weight monitoring using smartphones. Extensive experiments on BMI-annotated facial image datasets suggest that our proposed PatchBMI-Net model can obtain Mean Absolute Error (MAE) in the range [3.58, 6.51] with a size of about 3.3 million parameters. On cross-comparison with heavyweight models, such as ResNet-50 and Xception, trained for BMI prediction from facial images, our proposed PatchBMI-Net obtains equivalent MAE along with the model size reduction of about 5.4x and the average inference time reduction of about 3x when deployed on Apple-14 smartphone. Thus, demonstrating performance efficiency as well as low latency for on-device deployment and weight monitoring using smartphone applications.
A Computer Vision Based Approach for Stalking Detection Using a CNN-LSTM-MLP Hybrid Fusion Model
Feb 05, 2024Criminal and suspicious activity detection has become a popular research topic in recent years. The rapid growth of computer vision technologies has had a crucial impact on solving this issue. However, physical stalking detection is still a less explored area despite the evolution of modern technology. Nowadays, stalking in public places has become a common occurrence with women being the most affected. Stalking is a visible action that usually occurs before any criminal activity begins as the stalker begins to follow, loiter, and stare at the victim before committing any criminal activity such as assault, kidnapping, rape, and so on. Therefore, it has become a necessity to detect stalking as all of these criminal activities can be stopped in the first place through stalking detection. In this research, we propose a novel deep learning-based hybrid fusion model to detect potential stalkers from a single video with a minimal number of frames. We extract multiple relevant features, such as facial landmarks, head pose estimation, and relative distance, as numerical values from video frames. This data is fed into a multilayer perceptron (MLP) to perform a classification task between a stalking and a non-stalking scenario. Simultaneously, the video frames are fed into a combination of convolutional and LSTM models to extract the spatio-temporal features. We use a fusion of these numerical and spatio-temporal features to build a classifier to detect stalking incidents. Additionally, we introduce a dataset consisting of stalking and non-stalking videos gathered from various feature films and television series, which is also used to train the model. The experimental results show the efficiency and dynamism of our proposed stalker detection system, achieving 89.58% testing accuracy with a significant improvement as compared to the state-of-the-art approaches.
NeRF-AD: Neural Radiance Field with Attention-based Disentanglement for Talking Face Synthesis
Jan 23, 2024Talking face synthesis driven by audio is one of the current research hotspots in the fields of multidimensional signal processing and multimedia. Neural Radiance Field (NeRF) has recently been brought to this research field in order to enhance the realism and 3D effect of the generated faces. However, most existing NeRF-based methods either burden NeRF with complex learning tasks while lacking methods for supervised multimodal feature fusion, or cannot precisely map audio to the facial region related to speech movements. These reasons ultimately result in existing methods generating inaccurate lip shapes. This paper moves a portion of NeRF learning tasks ahead and proposes a talking face synthesis method via NeRF with attention-based disentanglement (NeRF-AD). In particular, an Attention-based Disentanglement module is introduced to disentangle the face into Audio-face and Identity-face using speech-related facial action unit (AU) information. To precisely regulate how audio affects the talking face, we only fuse the Audio-face with audio feature. In addition, AU information is also utilized to supervise the fusion of these two modalities. Extensive qualitative and quantitative experiments demonstrate that our NeRF-AD outperforms state-of-the-art methods in generating realistic talking face videos, including image quality and lip synchronization. To view video results, please refer to https://xiaoxingliu02.github.io/NeRF-AD.
Deep Variational Privacy Funnel: General Modeling with Applications in Face Recognition
Jan 26, 2024In this study, we harness the information-theoretic Privacy Funnel (PF) model to develop a method for privacy-preserving representation learning using an end-to-end training framework. We rigorously address the trade-off between obfuscation and utility. Both are quantified through the logarithmic loss, a measure also recognized as self-information loss. This exploration deepens the interplay between information-theoretic privacy and representation learning, offering substantive insights into data protection mechanisms for both discriminative and generative models. Importantly, we apply our model to state-of-the-art face recognition systems. The model demonstrates adaptability across diverse inputs, from raw facial images to both derived or refined embeddings, and is competent in tasks such as classification, reconstruction, and generation.
Coseparable Nonnegative Tensor Factorization With T-CUR Decomposition
Jan 30, 2024Nonnegative Matrix Factorization (NMF) is an important unsupervised learning method to extract meaningful features from data. To address the NMF problem within a polynomial time framework, researchers have introduced a separability assumption, which has recently evolved into the concept of coseparability. This advancement offers a more efficient core representation for the original data. However, in the real world, the data is more natural to be represented as a multi-dimensional array, such as images or videos. The NMF's application to high-dimensional data involves vectorization, which risks losing essential multi-dimensional correlations. To retain these inherent correlations in the data, we turn to tensors (multidimensional arrays) and leverage the tensor t-product. This approach extends the coseparable NMF to the tensor setting, creating what we term coseparable Nonnegative Tensor Factorization (NTF). In this work, we provide an alternating index selection method to select the coseparable core. Furthermore, we validate the t-CUR sampling theory and integrate it with the tensor Discrete Empirical Interpolation Method (t-DEIM) to introduce an alternative, randomized index selection process. These methods have been tested on both synthetic and facial analysis datasets. The results demonstrate the efficiency of coseparable NTF when compared to coseparable NMF.
An Evaluation of Forensic Facial Recognition
Nov 10, 2023

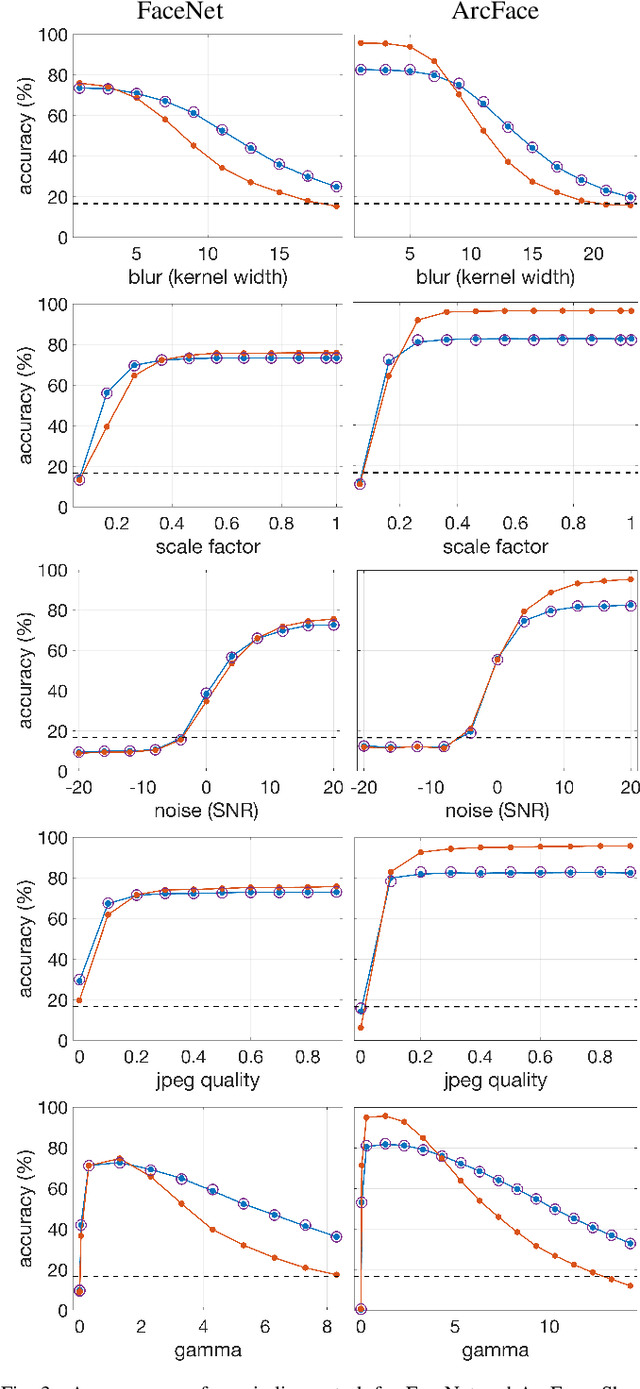
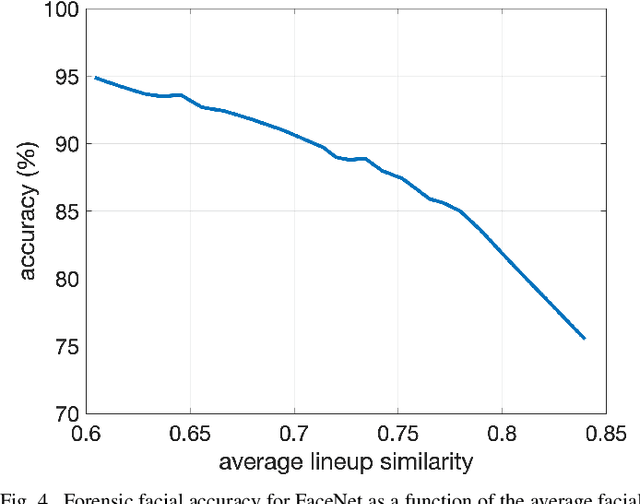
Recent advances in machine learning and computer vision have led to reported facial recognition accuracies surpassing human performance. We question if these systems will translate to real-world forensic scenarios in which a potentially low-resolution, low-quality, partially-occluded image is compared against a standard facial database. We describe the construction of a large-scale synthetic facial dataset along with a controlled facial forensic lineup, the combination of which allows for a controlled evaluation of facial recognition under a range of real-world conditions. Using this synthetic dataset, and a popular dataset of real faces, we evaluate the accuracy of two popular neural-based recognition systems. We find that previously reported face recognition accuracies of more than 95% drop to as low as 65% in this more challenging forensic scenario.
SeFi-IDE: Semantic-Fidelity Identity Embedding for Personalized Diffusion-Based Generation
Jan 31, 2024Advanced diffusion-based Text-to-Image (T2I) models, such as the Stable Diffusion Model, have made significant progress in generating diverse and high-quality images using text prompts alone. However, T2I models are unable to accurately map identities (IDs) when non-famous users require personalized image generation. The main problem is that existing T2I models do not learn the ID-image alignments of new users. The previous methods either failed to accurately fit the face region or lost the interactive generative ability with other existing concepts in T2I models (i.e., unable to generate other concepts described in given prompts such as scenes, actions, and facial attributes). In this paper, we focus on accurate and semantic-fidelity ID embedding into the Stable Diffusion Model for personalized generation. We address this challenge from two perspectives: face-wise region fitting, and semantic-fidelity token optimization. Specifically, we first visualize the attention overfit problem, and propose a face-wise attention loss to fit the face region instead of the whole target image. This key trick significantly enhances the ID accuracy and interactive generative ability with other existing concepts. Then, we optimize one ID representation as multiple per-stage tokens where each token contains two disentangled features. This expansion of the textual conditioning space enhances semantic-fidelity control. Extensive experiments validate that our results exhibit superior ID accuracy and manipulation ability compared to previous methods.
Learning Position-Aware Implicit Neural Network for Real-World Face Inpainting
Jan 19, 2024Face inpainting requires the model to have a precise global understanding of the facial position structure. Benefiting from the powerful capabilities of deep learning backbones, recent works in face inpainting have achieved decent performance in ideal setting (square shape with $512px$). However, existing methods often produce a visually unpleasant result, especially in the position-sensitive details (e.g., eyes and nose), when directly applied to arbitrary-shaped images in real-world scenarios. The visually unpleasant position-sensitive details indicate the shortcomings of existing methods in terms of position information processing capability. In this paper, we propose an \textbf{I}mplicit \textbf{N}eural \textbf{I}npainting \textbf{N}etwork (IN$^2$) to handle arbitrary-shape face images in real-world scenarios by explicit modeling for position information. Specifically, a downsample processing encoder is proposed to reduce information loss while obtaining the global semantic feature. A neighbor hybrid attention block is proposed with a hybrid attention mechanism to improve the facial understanding ability of the model without restricting the shape of the input. Finally, an implicit neural pyramid decoder is introduced to explicitly model position information and bridge the gap between low-resolution features and high-resolution output. Extensive experiments demonstrate the superiority of the proposed method in real-world face inpainting task.
PatternPortrait: Draw Me Like One of Your Scribbles
Jan 22, 2024This paper introduces a process for generating abstract portrait drawings from pictures. Their unique style is created by utilizing single freehand pattern sketches as references to generate unique patterns for shading. The method involves extracting facial and body features from images and transforming them into vector lines. A key aspect of the research is the development of a graph neural network architecture designed to learn sketch stroke representations in vector form, enabling the generation of diverse stroke variations. The combination of these two approaches creates joyful abstract drawings that are realized via a pen plotter. The presented process garnered positive feedback from an audience of approximately 280 participants.