 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Unsupervised Facial Geometry Learning for Sketch to Photo Synthesis
Oct 12, 2018
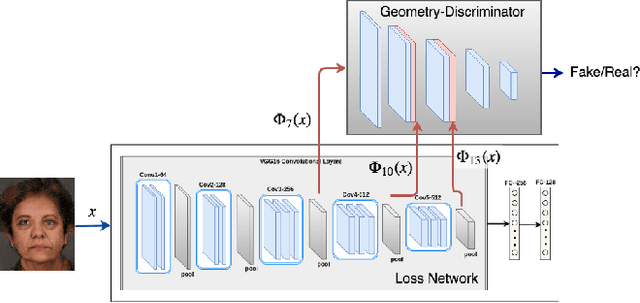
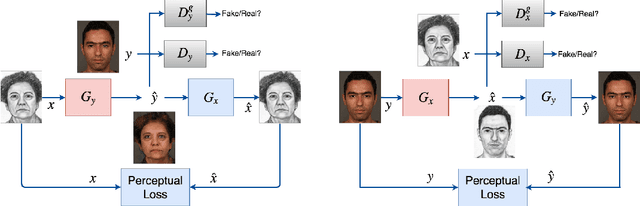

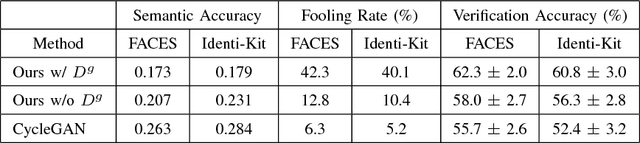
Face sketch-photo synthesis is a critical application in law enforcement and digital entertainment industry where the goal is to learn the mapping between a face sketch image and its corresponding photo-realistic image. However, the limited number of paired sketch-photo training data usually prevents the current frameworks to learn a robust mapping between the geometry of sketches and their matching photo-realistic images. Consequently, in this work, we present an approach for learning to synthesize a photo-realistic image from a face sketch in an unsupervised fashion. In contrast to current unsupervised image-to-image translation techniques, our framework leverages a novel perceptual discriminator to learn the geometry of human face. Learning facial prior information empowers the network to remove the geometrical artifacts in the face sketch. We demonstrate that a simultaneous optimization of the face photo generator network, employing the proposed perceptual discriminator in combination with a texture-wise discriminator, results in a significant improvement in quality and recognition rate of the synthesized photos. We evaluate the proposed network by conducting extensive experiments on multiple baseline sketch-photo datasets.
Adversarially Perturbed Wavelet-based Morphed Face Generation
Nov 03, 2021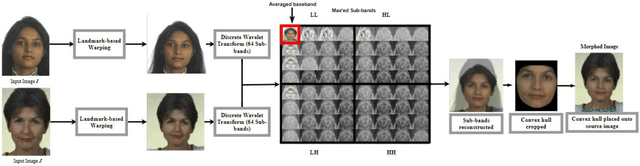
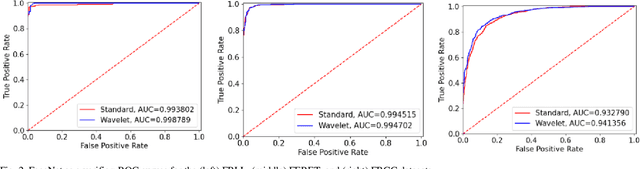
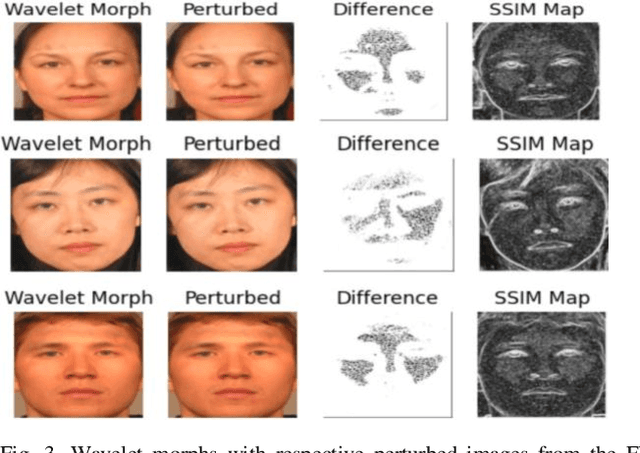
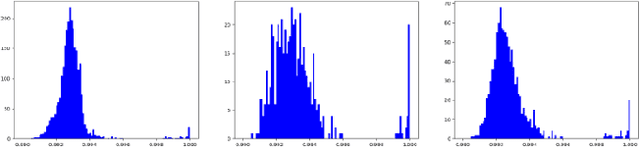
Morphing is the process of combining two or more subjects in an image in order to create a new identity which contains features of both individuals. Morphed images can fool Facial Recognition Systems (FRS) into falsely accepting multiple people, leading to failures in national security. As morphed image synthesis becomes easier, it is vital to expand the research community's available data to help combat this dilemma. In this paper, we explore combination of two methods for morphed image generation, those of geometric transformation (warping and blending to create morphed images) and photometric perturbation. We leverage both methods to generate high-quality adversarially perturbed morphs from the FERET, FRGC, and FRLL datasets. The final images retain high similarity to both input subjects while resulting in minimal artifacts in the visual domain. Images are synthesized by fusing the wavelet sub-bands from the two look-alike subjects, and then adversarially perturbed to create highly convincing imagery to deceive both humans and deep morph detectors.
Personalized Face Modeling for Improved Face Reconstruction and Motion Retargeting
Jul 17, 2020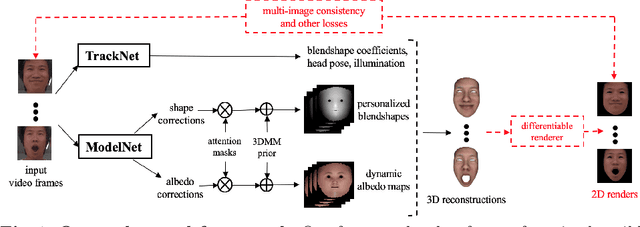
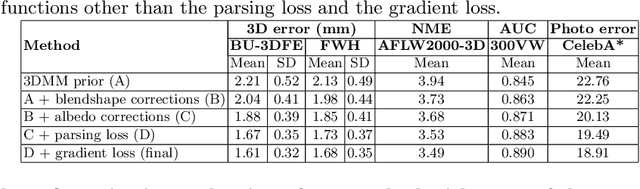


Traditional methods for image-based 3D face reconstruction and facial motion retargeting fit a 3D morphable model (3DMM) to the face, which has limited modeling capacity and fail to generalize well to in-the-wild data. Use of deformation transfer or multilinear tensor as a personalized 3DMM for blendshape interpolation does not address the fact that facial expressions result in different local and global skin deformations in different persons. Moreover, existing methods learn a single albedo per user which is not enough to capture the expression-specific skin reflectance variations. We propose an end-to-end framework that jointly learns a personalized face model per user and per-frame facial motion parameters from a large corpus of in-the-wild videos of user expressions. Specifically, we learn user-specific expression blendshapes and dynamic (expression-specific) albedo maps by predicting personalized corrections on top of a 3DMM prior. We introduce novel constraints to ensure that the corrected blendshapes retain their semantic meanings and the reconstructed geometry is disentangled from the albedo. Experimental results show that our personalization accurately captures fine-grained facial dynamics in a wide range of conditions and efficiently decouples the learned face model from facial motion, resulting in more accurate face reconstruction and facial motion retargeting compared to state-of-the-art methods.
MOST-GAN: 3D Morphable StyleGAN for Disentangled Face Image Manipulation
Nov 01, 2021

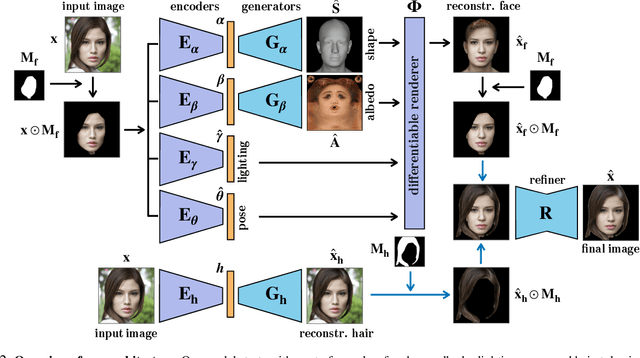

Recent advances in generative adversarial networks (GANs) have led to remarkable achievements in face image synthesis. While methods that use style-based GANs can generate strikingly photorealistic face images, it is often difficult to control the characteristics of the generated faces in a meaningful and disentangled way. Prior approaches aim to achieve such semantic control and disentanglement within the latent space of a previously trained GAN. In contrast, we propose a framework that a priori models physical attributes of the face such as 3D shape, albedo, pose, and lighting explicitly, thus providing disentanglement by design. Our method, MOST-GAN, integrates the expressive power and photorealism of style-based GANs with the physical disentanglement and flexibility of nonlinear 3D morphable models, which we couple with a state-of-the-art 2D hair manipulation network. MOST-GAN achieves photorealistic manipulation of portrait images with fully disentangled 3D control over their physical attributes, enabling extreme manipulation of lighting, facial expression, and pose variations up to full profile view.
Exploiting Facial Landmarks for Emotion Recognition in the Wild
Mar 30, 2016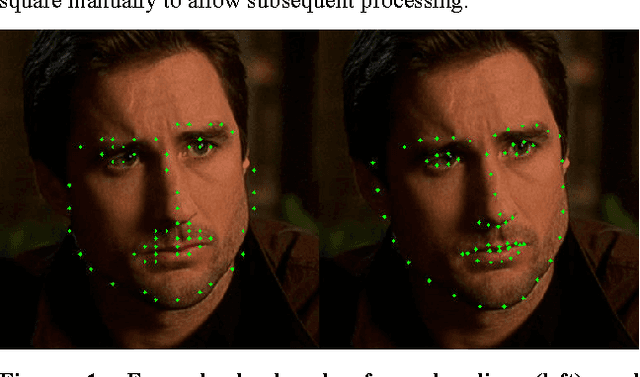
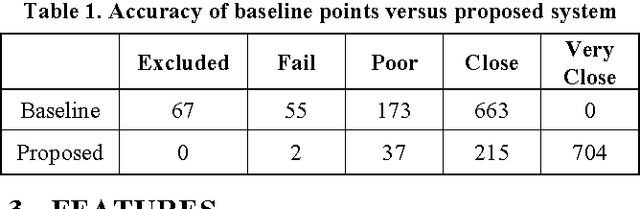
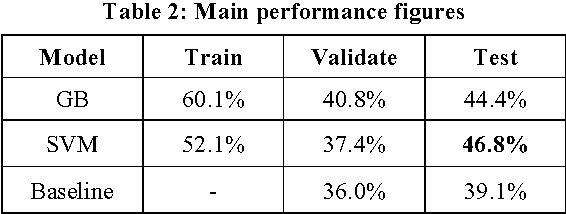

In this paper, we describe an entry to the third Emotion Recognition in the Wild Challenge, EmotiW2015. We detail the associated experiments and show that, through more accurately locating the facial landmarks, and considering only the distances between them, we can achieve a surprising level of performance. The resulting system is not only more accurate than the challenge baseline, but also much simpler.
E-Pro: Euler Angle and Probabilistic Model for Face Detection and Recognition
Nov 28, 2020
It is human nature to give prime importance to facial appearances. Often, to look good is to feel good. Also, facial features are unique to every individual on this planet, which means it is a source of vital information. This work proposes a framework named E-Pro for the detection and recognition of faces by taking facial images as inputs. E-Pro has its potential application in various domains, namely attendance, surveillance, crowd monitoring, biometric-based authentication etc. E-Pro is developed here as a mobile application that aims to aid lecturers to mark attendance in a classroom by detecting and recognizing the faces of students from a picture clicked through the app. E-Pro has been developed using Google Firebase Face Recognition APIs, which uses Euler Angles, and Probabilistic Model. E-Pro has been tested on stock images and the experimental results are promising.
Joint Face Detection and Facial Motion Retargeting for Multiple Faces
Feb 27, 2019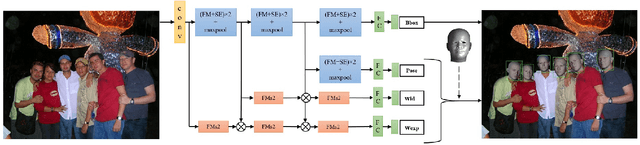

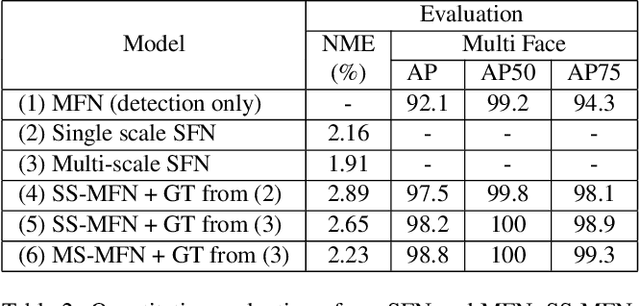
Facial motion retargeting is an important problem in both computer graphics and vision, which involves capturing the performance of a human face and transferring it to another 3D character. Learning 3D morphable model (3DMM) parameters from 2D face images using convolutional neural networks is common in 2D face alignment, 3D face reconstruction etc. However, existing methods either require an additional face detection step before retargeting or use a cascade of separate networks to perform detection followed by retargeting in a sequence. In this paper, we present a single end-to-end network to jointly predict the bounding box locations and 3DMM parameters for multiple faces. First, we design a novel multitask learning framework that learns a disentangled representation of 3DMM parameters for a single face. Then, we leverage the trained single face model to generate ground truth 3DMM parameters for multiple faces to train another network that performs joint face detection and motion retargeting for images with multiple faces. Experimental results show that our joint detection and retargeting network has high face detection accuracy and is robust to extreme expressions and poses while being faster than state-of-the-art methods.
Exemplar Guided Face Image Super-Resolution without Facial Landmarks
Jun 17, 2019
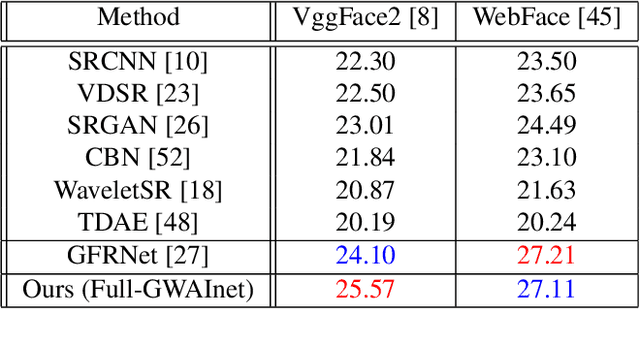
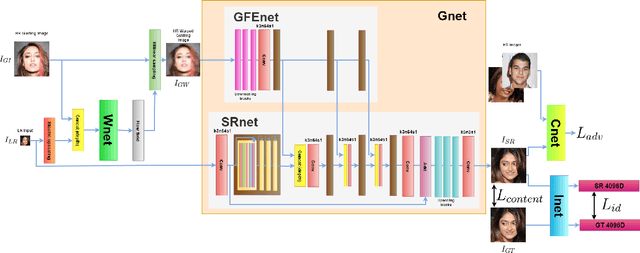
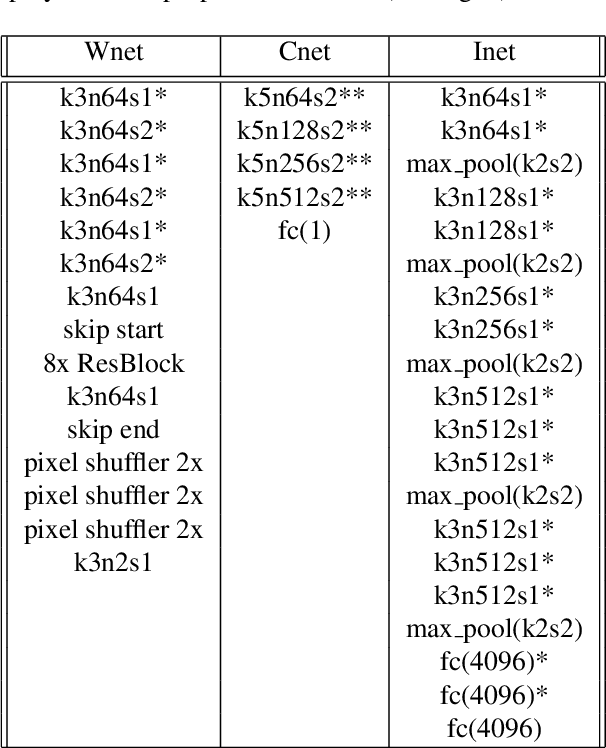
Nowadays, due to the ubiquitous visual media there are vast amounts of already available high-resolution (HR) face images. Therefore, for super-resolving a given very low-resolution (LR) face image of a person it is very likely to find another HR face image of the same person which can be used to guide the process. In this paper, we propose a convolutional neural network (CNN)-based solution, namely GWAInet, which applies super-resolution (SR) by a factor 8x on face images guided by another unconstrained HR face image of the same person with possible differences in age, expression, pose or size. GWAInet is trained in an adversarial generative manner to produce the desired high quality perceptual image results. The utilization of the HR guiding image is realized via the use of a warper subnetwork that aligns its contents to the input image and the use of a feature fusion chain for the extracted features from the warped guiding image and the input image. In training, the identity loss further helps in preserving the identity related features by minimizing the distance between the embedding vectors of SR and HR ground truth images. Contrary to the current state-of-the-art in face super-resolution, our method does not require facial landmark points for its training, which helps its robustness and allows it to produce fine details also for the surrounding face region in a uniform manner. Our method GWAInet produces photo-realistic images in upscaling factor 8x and outperforms state-of-the-art in quantitative terms and perceptual quality.
Self-Supervised Robustifying Guidance for Monocular 3D Face Reconstruction
Dec 29, 2021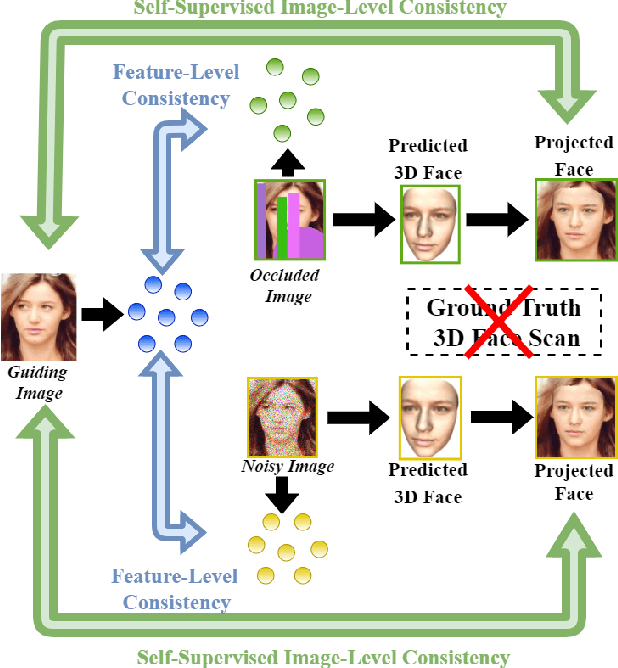
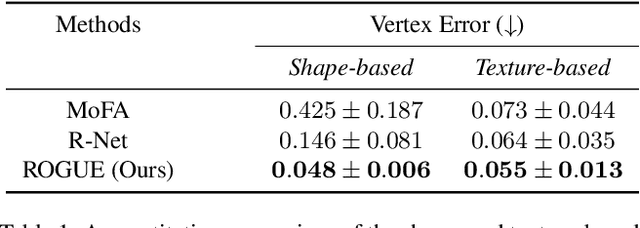
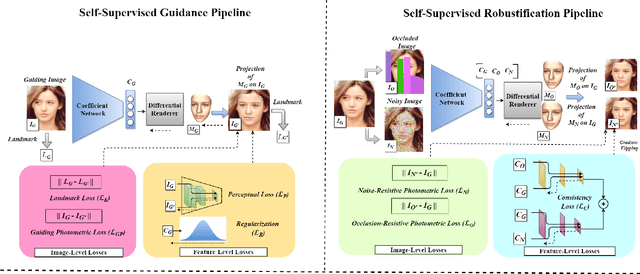
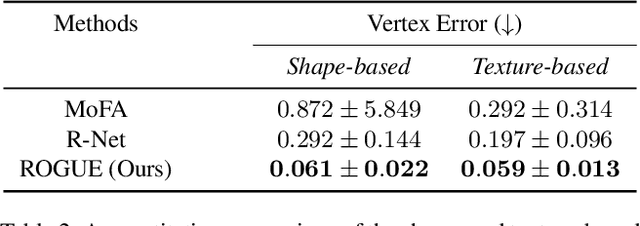
Despite the recent developments in 3D Face Reconstruction from occluded and noisy face images, the performance is still unsatisfactory. One of the main challenges is to handle moderate to heavy occlusions in the face images. In addition, the noise in the face images inhibits the correct capture of facial attributes, thus needing to be reliably addressed. Moreover, most existing methods rely on additional dependencies, posing numerous constraints over the training procedure. Therefore, we propose a Self-Supervised RObustifying GUidancE (ROGUE) framework to obtain robustness against occlusions and noise in the face images. The proposed network contains 1) the Guidance Pipeline to obtain the 3D face coefficients for the clean faces, and 2) the Robustification Pipeline to acquire the consistency between the estimated coefficients for occluded or noisy images and the clean counterpart. The proposed image- and feature-level loss functions aid the ROGUE learning process without posing additional dependencies. On the three variations of the test dataset of CelebA: rational occlusions, delusional occlusions, and noisy face images, our method outperforms the current state-of-the-art method by large margins (e.g., for the shape-based 3D vertex errors, a reduction from 0.146 to 0.048 for rational occlusions, from 0.292 to 0.061 for delusional occlusions and from 0.269 to 0.053 for the noise in the face images), demonstrating the effectiveness of the proposed approach.