 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Walk and Learn: Facial Attribute Representation Learning from Egocentric Video and Contextual Data
Jun 22, 2016

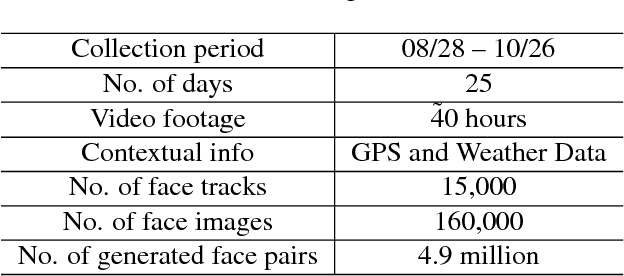
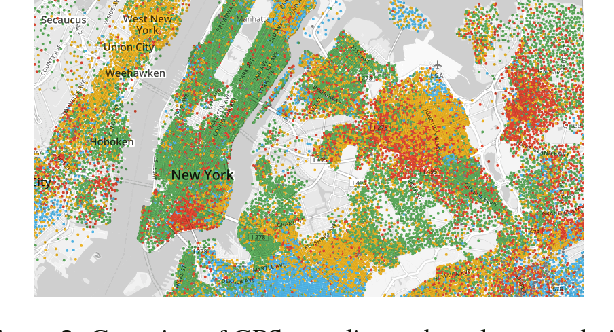
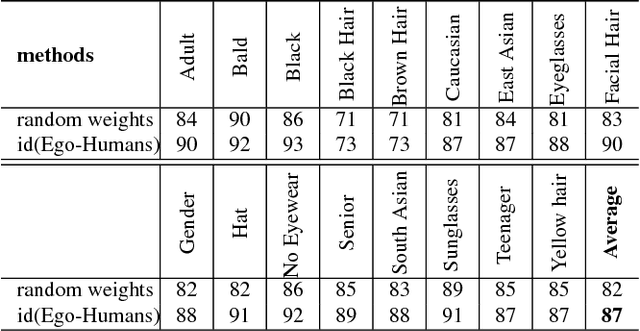
The way people look in terms of facial attributes (ethnicity, hair color, facial hair, etc.) and the clothes or accessories they wear (sunglasses, hat, hoodies, etc.) is highly dependent on geo-location and weather condition, respectively. This work explores, for the first time, the use of this contextual information, as people with wearable cameras walk across different neighborhoods of a city, in order to learn a rich feature representation for facial attribute classification, without the costly manual annotation required by previous methods. By tracking the faces of casual walkers on more than 40 hours of egocentric video, we are able to cover tens of thousands of different identities and automatically extract nearly 5 million pairs of images connected by or from different face tracks, along with their weather and location context, under pose and lighting variations. These image pairs are then fed into a deep network that preserves similarity of images connected by the same track, in order to capture identity-related attribute features, and optimizes for location and weather prediction to capture additional facial attribute features. Finally, the network is fine-tuned with manually annotated samples. We perform an extensive experimental analysis on wearable data and two standard benchmark datasets based on web images (LFWA and CelebA). Our method outperforms by a large margin a network trained from scratch. Moreover, even without using manually annotated identity labels for pre-training as in previous methods, our approach achieves results that are better than the state of the art.
Emotive Response to a Hybrid-Face Robot and Translation to Consumer Social Robots
Dec 08, 2020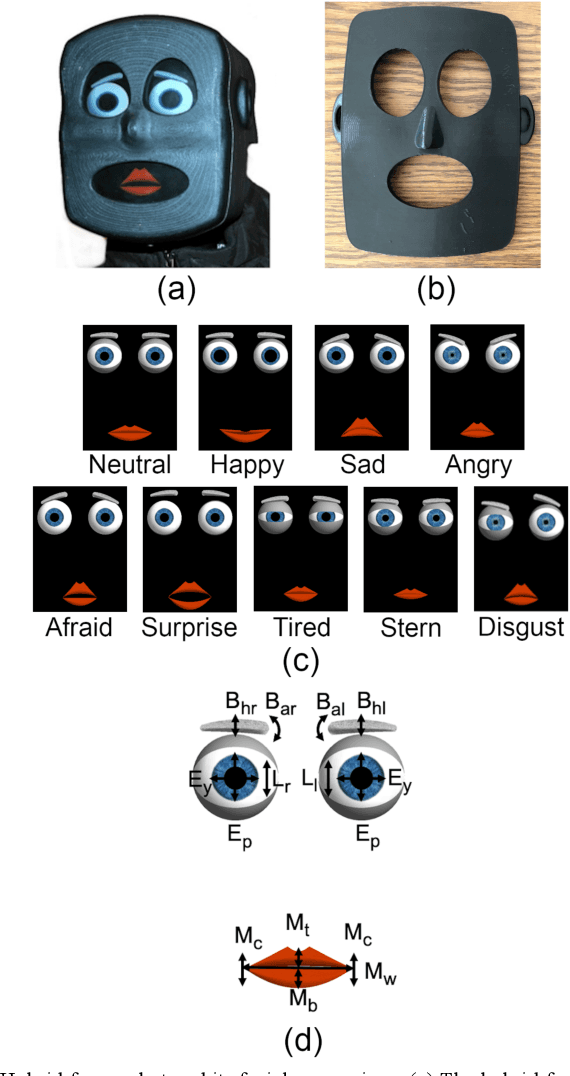
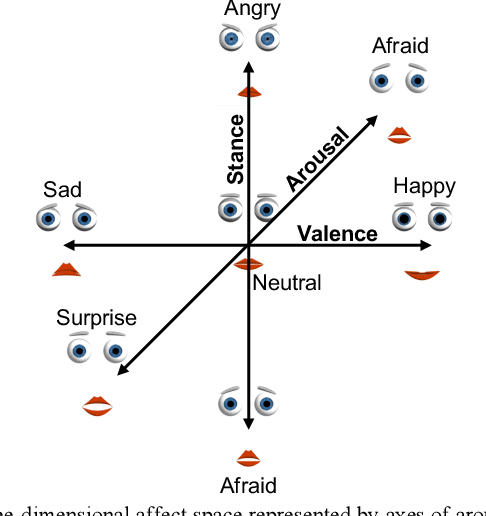

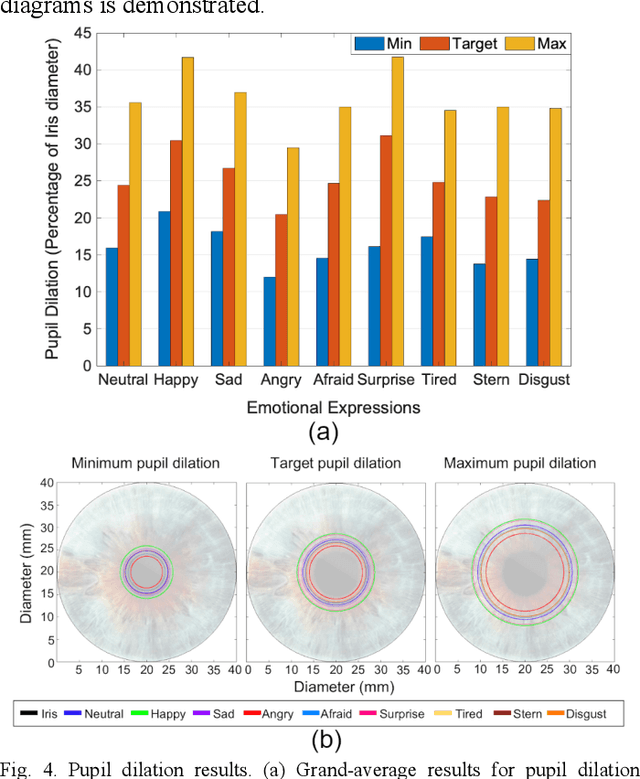
We introduce the conceptual formulation, design, fabrication, control and commercial translation with IoT connection of a hybrid-face social robot and validation of human emotional response to its affective interactions. The hybrid-face robot integrates a 3D printed faceplate and a digital display to simplify conveyance of complex facial movements while providing the impression of three-dimensional depth for natural interaction. We map the space of potential emotions of the robot to specific facial feature parameters and characterise the recognisability of the humanoid hybrid-face robot's archetypal facial expressions. We introduce pupil dilation as an additional degree of freedom for conveyance of emotive states. Human interaction experiments demonstrate the ability to effectively convey emotion from the hybrid-robot face to human observers by mapping their neurophysiological electroencephalography (EEG) response to perceived emotional information and through interviews. Results show main hybrid-face robotic expressions can be discriminated with recognition rates above 80% and invoke human emotive response similar to that of actual human faces as measured by the face-specific N170 event-related potentials in EEG. The hybrid-face robot concept has been modified, implemented, and released in the commercial IoT robotic platform Miko (My Companion), an affective robot with facial and conversational features currently in use for human-robot interaction in children by Emotix Inc. We demonstrate that human EEG responses to Miko emotions are comparative to neurophysiological responses for actual human facial recognition. Finally, interviews show above 90% expression recognition rates in our commercial robot. We conclude that simplified hybrid-face abstraction conveys emotions effectively and enhances human-robot interaction.
Facial Gesture Recognition Using Correlation And Mahalanobis Distance
Mar 09, 2010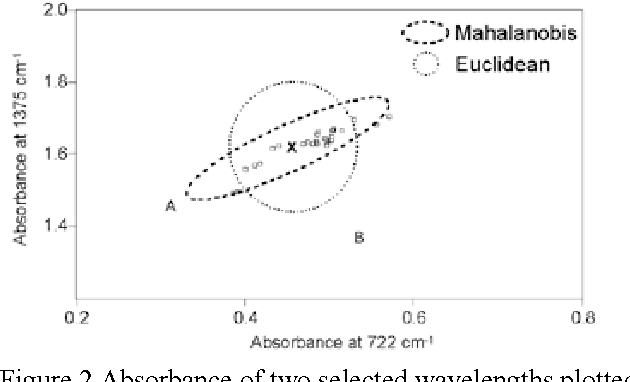
Augmenting human computer interaction with automated analysis and synthesis of facial expressions is a goal towards which much research effort has been devoted recently. Facial gesture recognition is one of the important component of natural human-machine interfaces; it may also be used in behavioural science, security systems and in clinical practice. Although humans recognise facial expressions virtually without effort or delay, reliable expression recognition by machine is still a challenge. The face expression recognition problem is challenging because different individuals display the same expression differently. This paper presents an overview of gesture recognition in real time using the concepts of correlation and Mahalanobis distance.We consider the six universal emotional categories namely joy, anger, fear, disgust, sadness and surprise.
An Occluded Stacked Hourglass Approach to Facial Landmark Localization and Occlusion Estimation
Feb 05, 2018
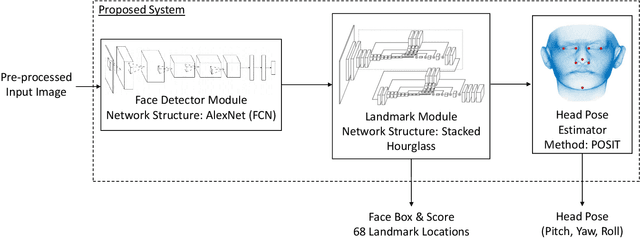
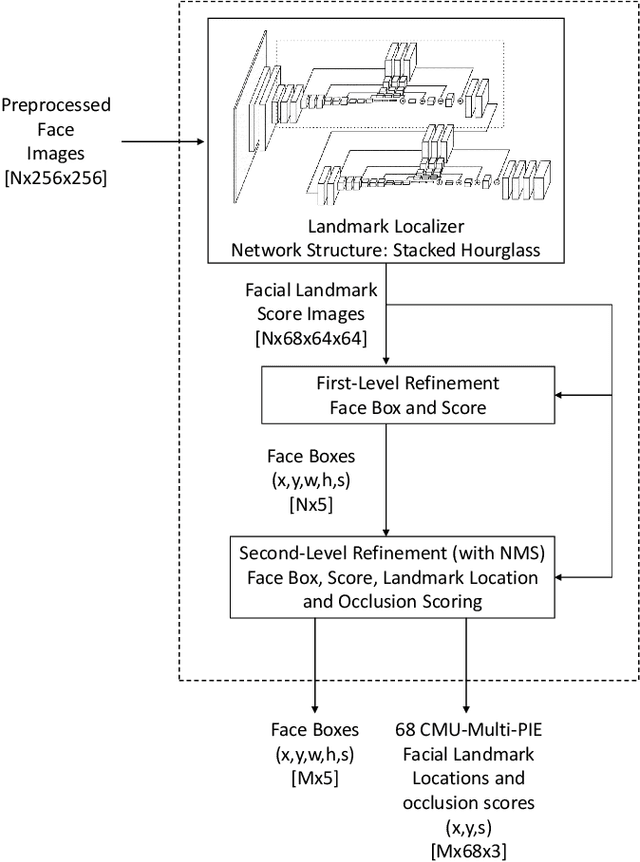
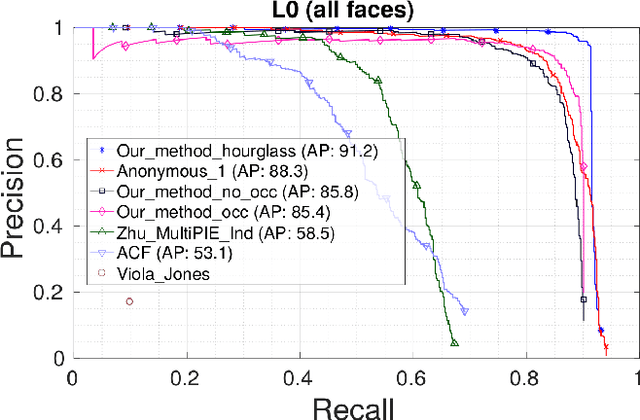
A key step to driver safety is to observe the driver's activities with the face being a key step in this process to extracting information such as head pose, blink rate, yawns, talking to passenger which can then help derive higher level information such as distraction, drowsiness, intent, and where they are looking. In the context of driving safety, it is important for the system perform robust estimation under harsh lighting and occlusion but also be able to detect when the occlusion occurs so that information predicted from occluded parts of the face can be taken into account properly. This paper introduces the Occluded Stacked Hourglass, based on the work of original Stacked Hourglass network for body pose joint estimation, which is retrained to process a detected face window and output 68 occlusion heat maps, each corresponding to a facial landmark. Landmark location, occlusion levels and a refined face detection score, to reject false positives, are extracted from these heat maps. Using the facial landmark locations, features such as head pose and eye/mouth openness can be extracted to derive driver attention and activity. The system is evaluated for face detection, head pose, and occlusion estimation on various datasets in the wild, both quantitatively and qualitatively, and shows state-of-the-art results.
Beholder-GAN: Generation and Beautification of Facial Images with Conditioning on Their Beauty Level
Feb 25, 2019
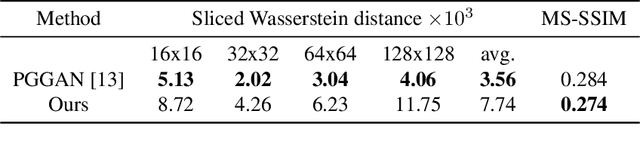

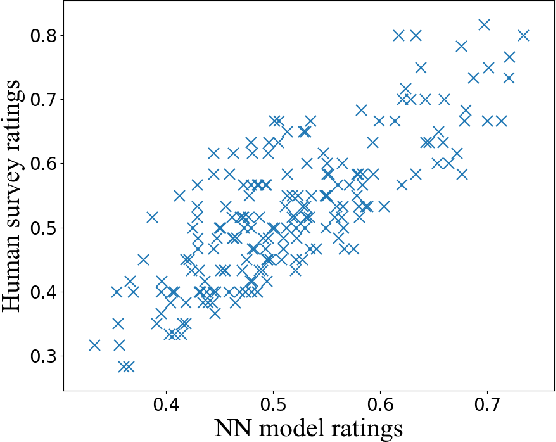
Beauty is in the eye of the beholder. This maxim, emphasizing the subjectivity of the perception of beauty, has enjoyed a wide consensus since ancient times. In the digitalera, data-driven methods have been shown to be able to predict human-assigned beauty scores for facial images. In this work, we augment this ability and train a generative model that generates faces conditioned on a requested beauty score. In addition, we show how this trained generator can be used to beautify an input face image. By doing so, we achieve an unsupervised beautification model, in the sense that it relies on no ground truth target images.
Face Sketch Synthesis via Semantic-Driven Generative Adversarial Network
Jun 29, 2021
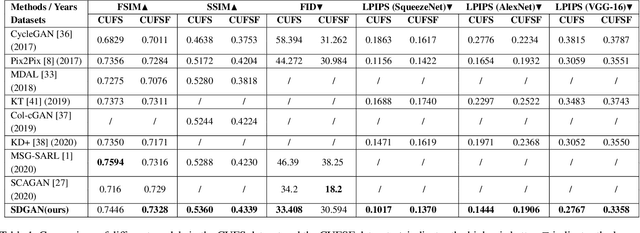
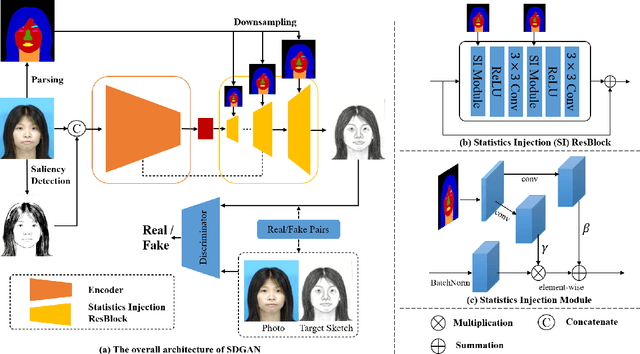
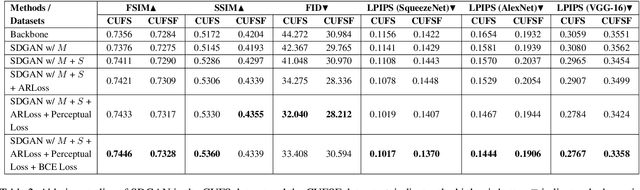
Face sketch synthesis has made significant progress with the development of deep neural networks in these years. The delicate depiction of sketch portraits facilitates a wide range of applications like digital entertainment and law enforcement. However, accurate and realistic face sketch generation is still a challenging task due to the illumination variations and complex backgrounds in the real scenes. To tackle these challenges, we propose a novel Semantic-Driven Generative Adversarial Network (SDGAN) which embeds global structure-level style injection and local class-level knowledge re-weighting. Specifically, we conduct facial saliency detection on the input face photos to provide overall facial texture structure, which could be used as a global type of prior information. In addition, we exploit face parsing layouts as the semantic-level spatial prior to enforce globally structural style injection in the generator of SDGAN. Furthermore, to enhance the realistic effect of the details, we propose a novel Adaptive Re-weighting Loss (ARLoss) which dedicates to balance the contributions of different semantic classes. Experimentally, our extensive experiments on CUFS and CUFSF datasets show that our proposed algorithm achieves state-of-the-art performance.
Masked Face Recognition Challenge: The WebFace260M Track Report
Aug 16, 2021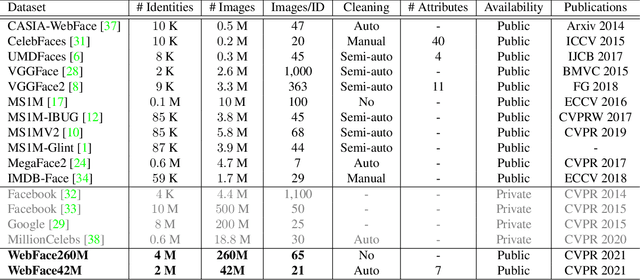
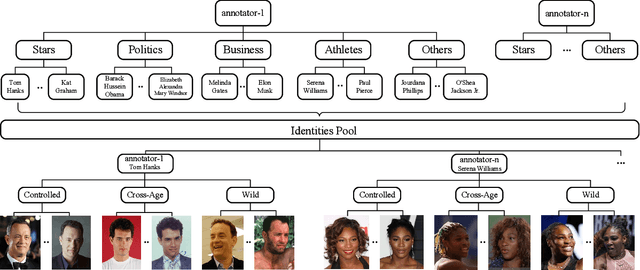
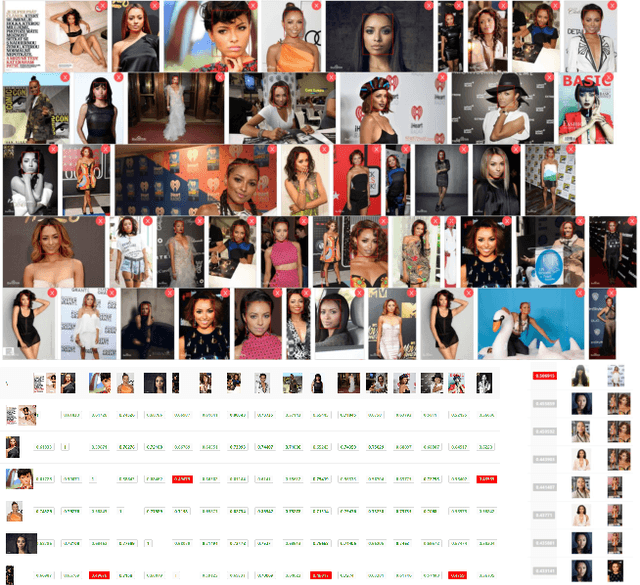
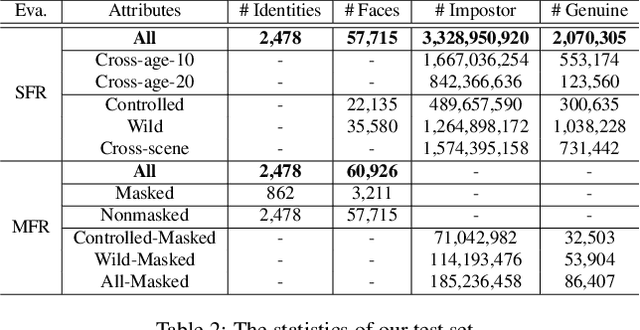
According to WHO statistics, there are more than 204,617,027 confirmed COVID-19 cases including 4,323,247 deaths worldwide till August 12, 2021. During the coronavirus epidemic, almost everyone wears a facial mask. Traditionally, face recognition approaches process mostly non-occluded faces, which include primary facial features such as the eyes, nose, and mouth. Removing the mask for authentication in airports or laboratories will increase the risk of virus infection, posing a huge challenge to current face recognition systems. Due to the sudden outbreak of the epidemic, there are yet no publicly available real-world masked face recognition (MFR) benchmark. To cope with the above-mentioned issue, we organize the Face Bio-metrics under COVID Workshop and Masked Face Recognition Challenge in ICCV 2021. Enabled by the ultra-large-scale WebFace260M benchmark and the Face Recognition Under Inference Time conStraint (FRUITS) protocol, this challenge (WebFace260M Track) aims to push the frontiers of practical MFR. Since public evaluation sets are mostly saturated or contain noise, a new test set is gathered consisting of elaborated 2,478 celebrities and 60,926 faces. Meanwhile, we collect the world-largest real-world masked test set. In the first phase of WebFace260M Track, 69 teams (total 833 solutions) participate in the challenge and 49 teams exceed the performance of our baseline. There are second phase of the challenge till October 1, 2021 and on-going leaderboard. We will actively update this report in the future.
Facial Expression Recognition using Convolutional Neural Networks: State of the Art
Dec 09, 2016
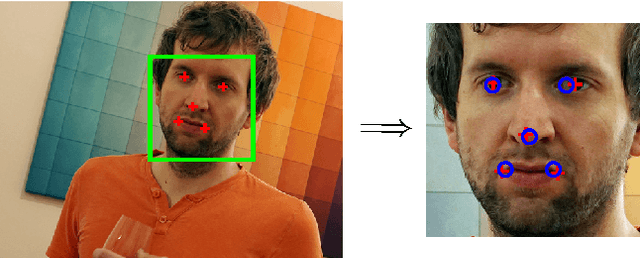
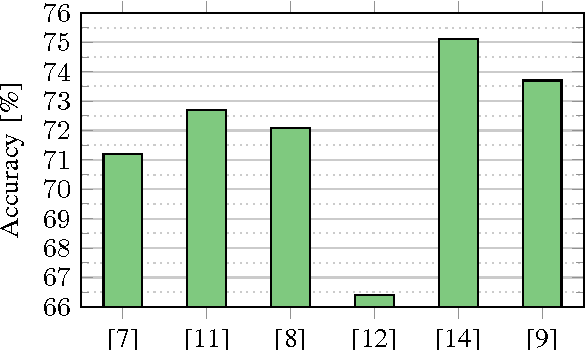
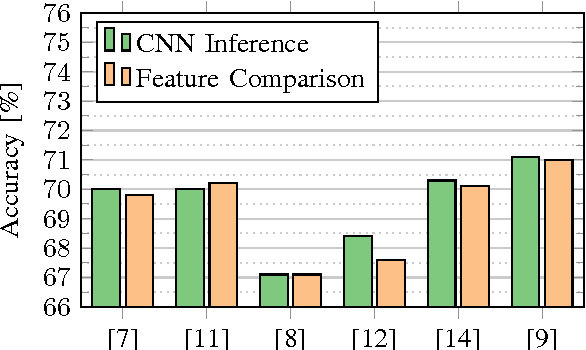
The ability to recognize facial expressions automatically enables novel applications in human-computer interaction and other areas. Consequently, there has been active research in this field, with several recent works utilizing Convolutional Neural Networks (CNNs) for feature extraction and inference. These works differ significantly in terms of CNN architectures and other factors. Based on the reported results alone, the performance impact of these factors is unclear. In this paper, we review the state of the art in image-based facial expression recognition using CNNs and highlight algorithmic differences and their performance impact. On this basis, we identify existing bottlenecks and consequently directions for advancing this research field. Furthermore, we demonstrate that overcoming one of these bottlenecks - the comparatively basic architectures of the CNNs utilized in this field - leads to a substantial performance increase. By forming an ensemble of modern deep CNNs, we obtain a FER2013 test accuracy of 75.2%, outperforming previous works without requiring auxiliary training data or face registration.
An Automatic Diagnosis Method of Facial Acne Vulgaris Based on Convolutional Neural Network
Nov 13, 2017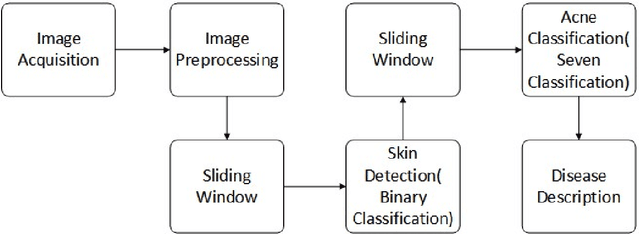



In this paper, we present a new automatic diagnosis method of facial acne vulgaris based on convolutional neural network. This method is proposed to overcome the shortcoming of classification types in previous methods. The core of our method is to extract features of images based on convolutional neural network and achieve classification by classifier. We design a binary classifier of skin-and-non-skin to detect skin area and a seven-classifier to achieve the classification of facial acne vulgaris and healthy skin. In the experiment, we compared the effectiveness of our convolutional neural network and the pre-trained VGG16 neural network on the ImageNet dataset. And we use the ROC curve and normal confusion matrix to evaluate the performance of the binary classifier and the seven-classifier. The results of our experiment show that the pre-trained VGG16 neural network is more effective in extracting image features. The classifiers based on the pre-trained VGG16 neural network achieve the skin detection and acne classification and have good robustness.
Landmark Breaker: Obstructing DeepFake By Disturbing Landmark Extraction
Feb 01, 2021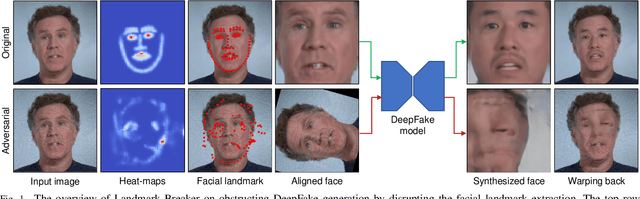

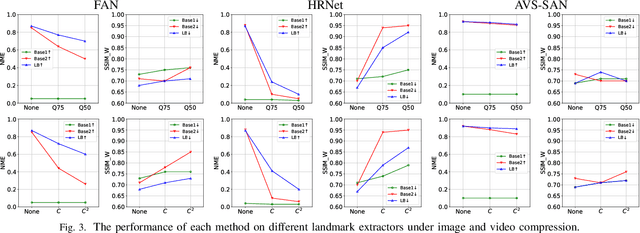
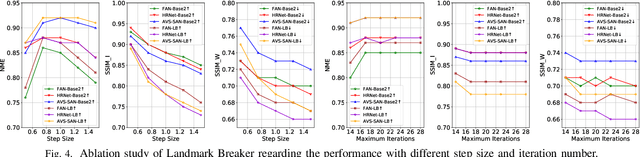
The recent development of Deep Neural Networks (DNN) has significantly increased the realism of AI-synthesized faces, with the most notable examples being the DeepFakes. The DeepFake technology can synthesize a face of target subject from a face of another subject, while retains the same face attributes. With the rapidly increased social media portals (Facebook, Instagram, etc), these realistic fake faces rapidly spread though the Internet, causing a broad negative impact to the society. In this paper, we describe Landmark Breaker, the first dedicated method to disrupt facial landmark extraction, and apply it to the obstruction of the generation of DeepFake videos.Our motivation is that disrupting the facial landmark extraction can affect the alignment of input face so as to degrade the DeepFake quality. Our method is achieved using adversarial perturbations. Compared to the detection methods that only work after DeepFake generation, Landmark Breaker goes one step ahead to prevent DeepFake generation. The experiments are conducted on three state-of-the-art facial landmark extractors using the recent Celeb-DF dataset.