 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Deep Facial Expression Recognition: A Survey
Oct 22, 2018
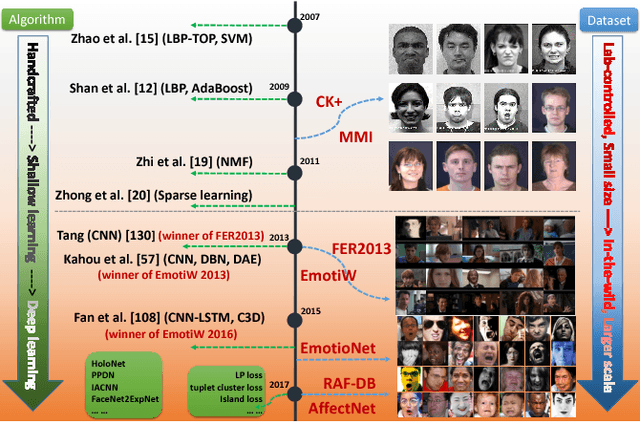
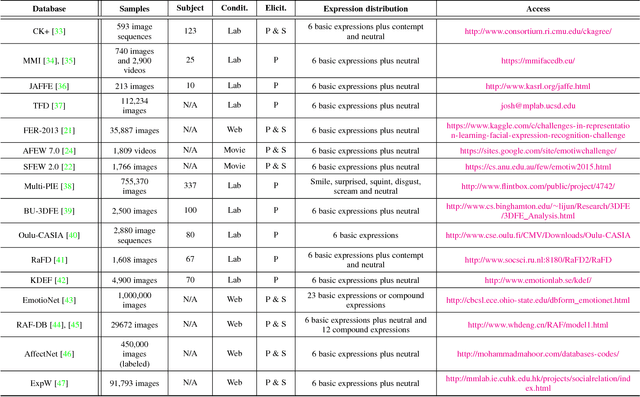
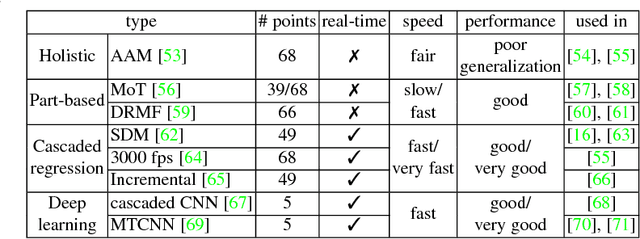
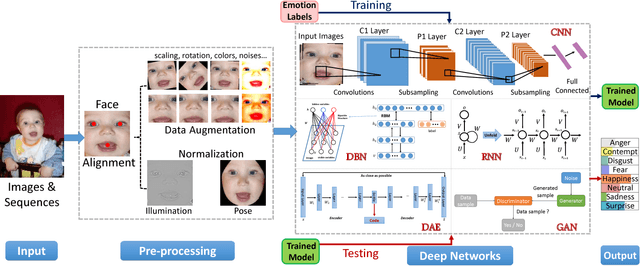
With the transition of facial expression recognition (FER) from laboratory-controlled to challenging in-the-wild conditions and the recent success of deep learning techniques in various fields, deep neural networks have increasingly been leveraged to learn discriminative representations for automatic FER. Recent deep FER systems generally focus on two important issues: overfitting caused by a lack of sufficient training data and expression-unrelated variations, such as illumination, head pose and identity bias. In this paper, we provide a comprehensive survey on deep FER, including datasets and algorithms that provide insights into these intrinsic problems. First, we describe the standard pipeline of a deep FER system with the related background knowledge and suggestions of applicable implementations for each stage. We then introduce the available datasets that are widely used in the literature and provide accepted data selection and evaluation principles for these datasets. For the state of the art in deep FER, we review existing novel deep neural networks and related training strategies that are designed for FER based on both static images and dynamic image sequences, and discuss their advantages and limitations. Competitive performances on widely used benchmarks are also summarized in this section. We then extend our survey to additional related issues and application scenarios. Finally, we review the remaining challenges and corresponding opportunities in this field as well as future directions for the design of robust deep FER systems.
Dual Attention Network for Heart Rate and Respiratory Rate Estimation
Oct 31, 2021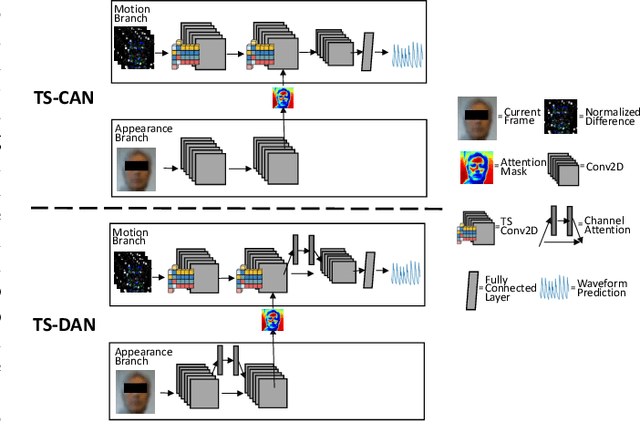
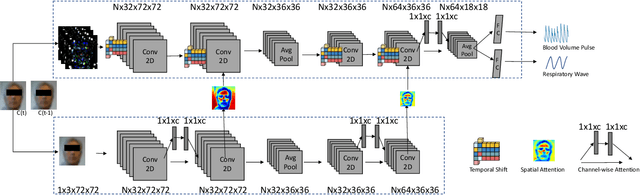
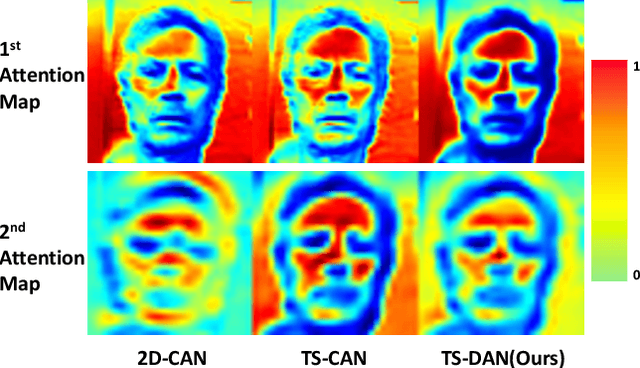

Heart rate and respiratory rate measurement is a vital step for diagnosing many diseases. Non-contact camera based physiological measurement is more accessible and convenient in Telehealth nowadays than contact instruments such as fingertip oximeters since non-contact methods reduce risk of infection. However, remote physiological signal measurement is challenging due to environment illumination variations, head motion, facial expression, etc. It's also desirable to have a unified network which could estimate both heart rate and respiratory rate to reduce system complexity and latency. We propose a convolutional neural network which leverages spatial attention and channel attention, which we call it dual attention network (DAN) to jointly estimate heart rate and respiratory rate with camera video as input. Extensive experiments demonstrate that our proposed system significantly improves heart rate and respiratory rate measurement accuracy.
Human View Synthesis using a Single Sparse RGB-D Input
Dec 30, 2021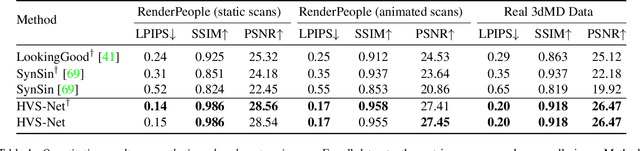

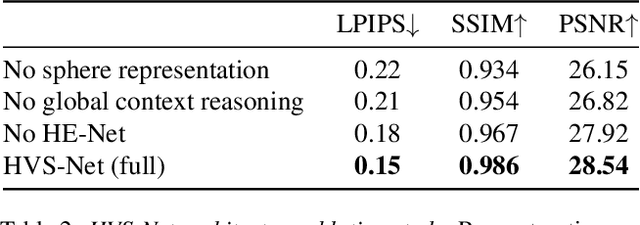
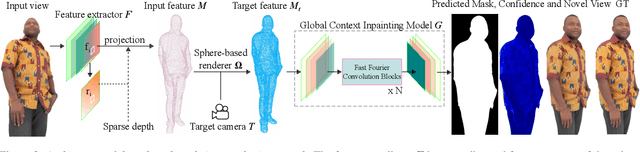
Novel view synthesis for humans in motion is a challenging computer vision problem that enables applications such as free-viewpoint video. Existing methods typically use complex setups with multiple input views, 3D supervision, or pre-trained models that do not generalize well to new identities. Aiming to address these limitations, we present a novel view synthesis framework to generate realistic renders from unseen views of any human captured from a single-view sensor with sparse RGB-D, similar to a low-cost depth camera, and without actor-specific models. We propose an architecture to learn dense features in novel views obtained by sphere-based neural rendering, and create complete renders using a global context inpainting model. Additionally, an enhancer network leverages the overall fidelity, even in occluded areas from the original view, producing crisp renders with fine details. We show our method generates high-quality novel views of synthetic and real human actors given a single sparse RGB-D input. It generalizes to unseen identities, new poses and faithfully reconstructs facial expressions. Our approach outperforms prior human view synthesis methods and is robust to different levels of input sparsity.
Emotion Transfer Using Vector-Valued Infinite Task Learning
Feb 09, 2021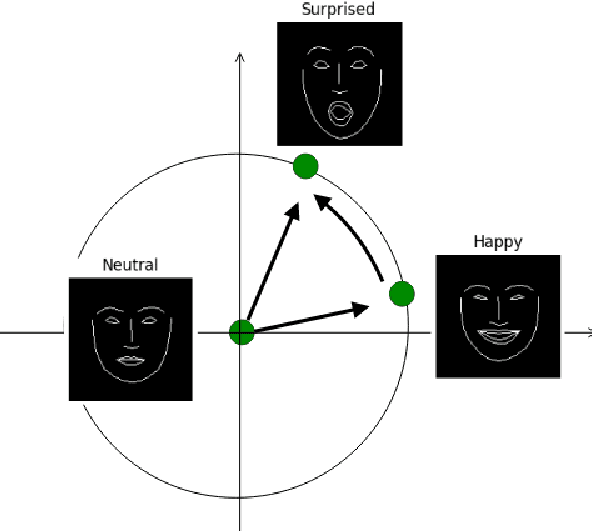
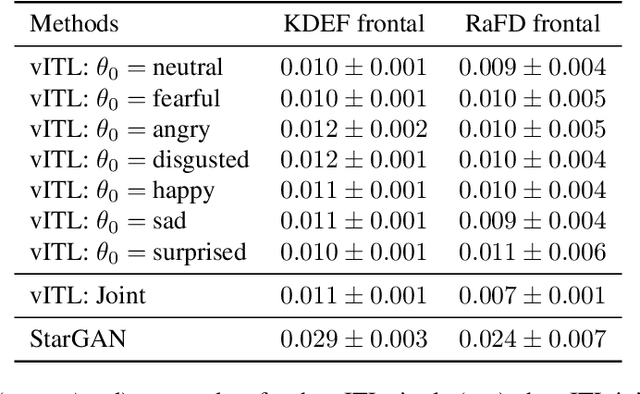
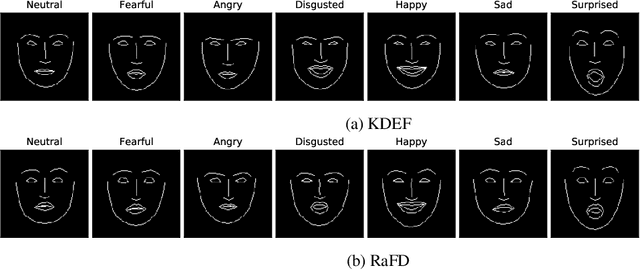
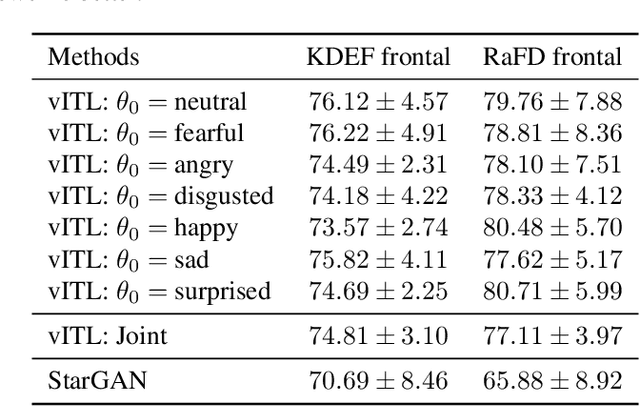
Style transfer is a significant problem of machine learning with numerous successful applications. In this work, we present a novel style transfer framework building upon infinite task learning and vector-valued reproducing kernel Hilbert spaces. We instantiate the idea in emotion transfer where the goal is to transform facial images to different target emotions. The proposed approach provides a principled way to gain explicit control over the continuous style space. We demonstrate the efficiency of the technique on popular facial emotion benchmarks, achieving low reconstruction cost and high emotion classification accuracy.
Efficient Facial Representations for Age, Gender and Identity Recognition in Organizing Photo Albums using Multi-output CNN
Aug 15, 2018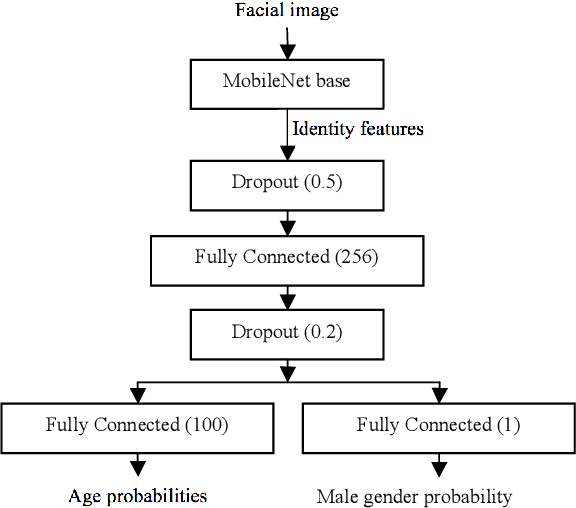
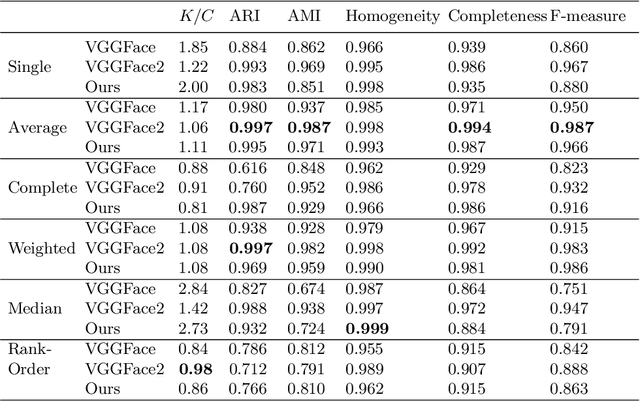
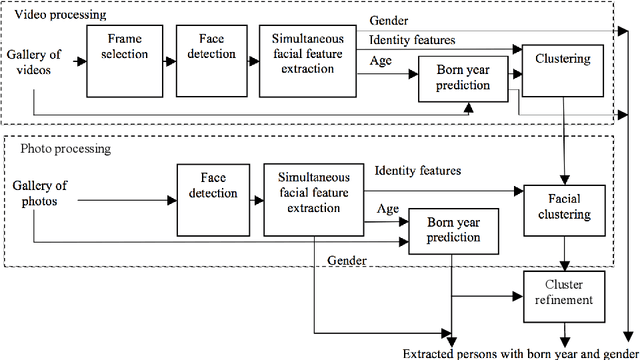
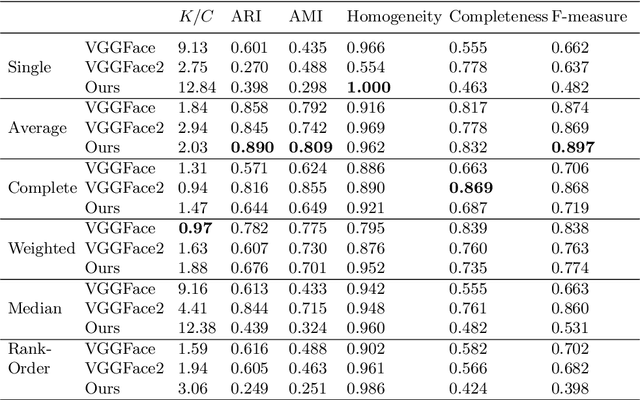
This paper is focused on the automatic extraction of persons and their attributes (gender, year of born) from album of photos and videos. We propose the two-stage approach, in which, firstly, the convolutional neural network simultaneously predicts age/gender from all photos and additionally extracts facial representations suitable for face identification. We modified the MobileNet, which is preliminarily trained to perform face recognition, in order to additionally recognize age and gender. In the second stage of our approach, extracted faces are grouped using hierarchical agglomerative clustering techniques. The born year and gender of a person in each cluster are estimated using aggregation of predictions for individual photos. We experimentally demonstrated that our facial clustering quality is competitive with the state-of-the-art neural networks, though our implementation is much computationally cheaper. Moreover, our approach is characterized by more accurate video-based age/gender recognition when compared to the publicly available models.
A Multi-resolution Approach to Expression Recognition in the Wild
Mar 09, 2021
Facial expressions play a fundamental role in human communication. Indeed, they typically reveal the real emotional status of people beyond the spoken language. Moreover, the comprehension of human affect based on visual patterns is a key ingredient for any human-machine interaction system and, for such reasons, the task of Facial Expression Recognition (FER) draws both scientific and industrial interest. In the recent years, Deep Learning techniques reached very high performance on FER by exploiting different architectures and learning paradigms. In such a context, we propose a multi-resolution approach to solve the FER task. We ground our intuition on the observation that often faces images are acquired at different resolutions. Thus, directly considering such property while training a model can help achieve higher performance on recognizing facial expressions. To our aim, we use a ResNet-like architecture, equipped with Squeeze-and-Excitation blocks, trained on the Affect-in-the-Wild 2 dataset. Not being available a test set, we conduct tests and models selection by employing the validation set only on which we achieve more than 90\% accuracy on classifying the seven expressions that the dataset comprises.
FERA 2017 - Addressing Head Pose in the Third Facial Expression Recognition and Analysis Challenge
Feb 14, 2017
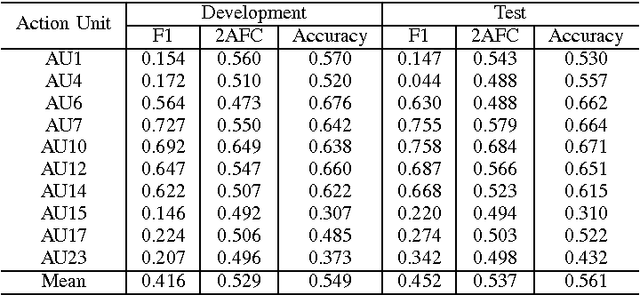
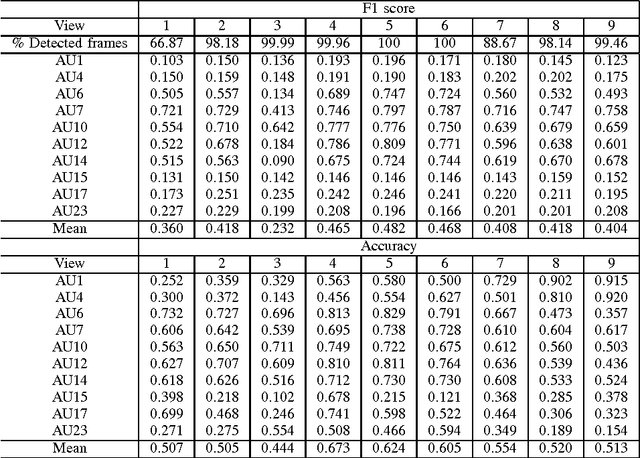
The field of Automatic Facial Expression Analysis has grown rapidly in recent years. However, despite progress in new approaches as well as benchmarking efforts, most evaluations still focus on either posed expressions, near-frontal recordings, or both. This makes it hard to tell how existing expression recognition approaches perform under conditions where faces appear in a wide range of poses (or camera views), displaying ecologically valid expressions. The main obstacle for assessing this is the availability of suitable data, and the challenge proposed here addresses this limitation. The FG 2017 Facial Expression Recognition and Analysis challenge (FERA 2017) extends FERA 2015 to the estimation of Action Units occurrence and intensity under different camera views. In this paper we present the third challenge in automatic recognition of facial expressions, to be held in conjunction with the 12th IEEE conference on Face and Gesture Recognition, May 2017, in Washington, United States. Two sub-challenges are defined: the detection of AU occurrence, and the estimation of AU intensity. In this work we outline the evaluation protocol, the data used, and the results of a baseline method for both sub-challenges.
FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors
Nov 29, 2017
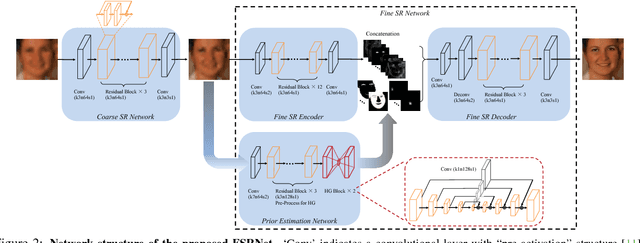

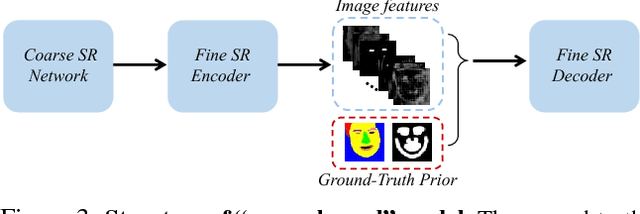
Face Super-Resolution (SR) is a domain-specific super-resolution problem. The specific facial prior knowledge could be leveraged for better super-resolving face images. We present a novel deep end-to-end trainable Face Super-Resolution Network (FSRNet), which makes full use of the geometry prior, i.e., facial landmark heatmaps and parsing maps, to super-resolve very low-resolution (LR) face images without well-aligned requirement. Specifically, we first construct a coarse SR network to recover a coarse high-resolution (HR) image. Then, the coarse HR image is sent to two branches: a fine SR encoder and a prior information estimation network, which extracts the image features, and estimates landmark heatmaps/parsing maps respectively. Both image features and prior information are sent to a fine SR decoder to recover the HR image. To further generate realistic faces, we propose the Face Super-Resolution Generative Adversarial Network (FSRGAN) to incorporate the adversarial loss into FSRNet. Moreover, we introduce two related tasks, face alignment and parsing, as the new evaluation metrics for face SR, which address the inconsistency of classic metrics w.r.t. visual perception. Extensive benchmark experiments show that FSRNet and FSRGAN significantly outperforms state of the arts for very LR face SR, both quantitatively and qualitatively. Code will be made available upon publication.
Delta-GAN-Encoder: Encoding Semantic Changes for Explicit Image Editing, using Few Synthetic Samples
Nov 17, 2021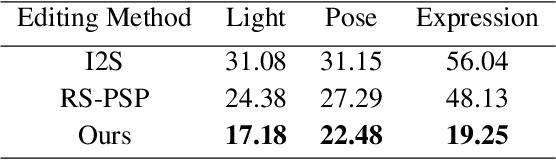

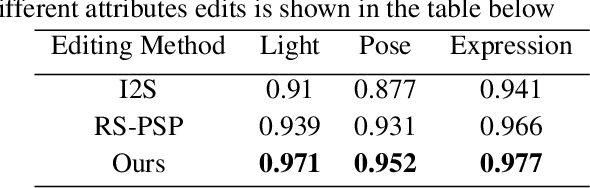
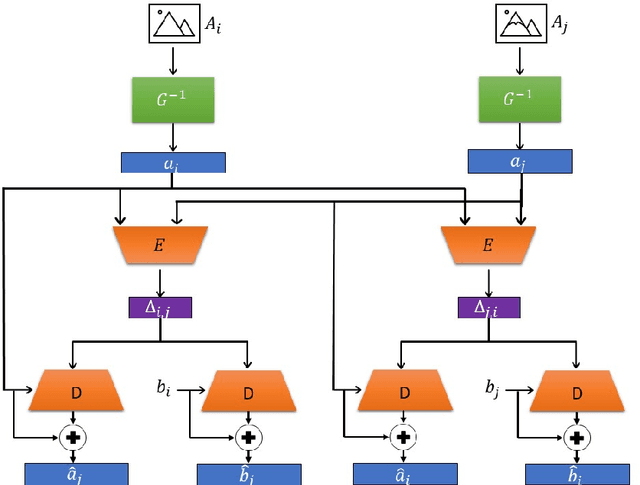
Understating and controlling generative models' latent space is a complex task. In this paper, we propose a novel method for learning to control any desired attribute in a pre-trained GAN's latent space, for the purpose of editing synthesized and real-world data samples accordingly. We perform Sim2Real learning, relying on minimal samples to achieve an unlimited amount of continuous precise edits. We present an Autoencoder-based model that learns to encode the semantics of changes between images as a basis for editing new samples later on, achieving precise desired results - example shown in Fig. 1. While previous editing methods rely on a known structure of latent spaces (e.g., linearity of some semantics in StyleGAN), our method inherently does not require any structural constraints. We demonstrate our method in the domain of facial imagery: editing different expressions, poses, and lighting attributes, achieving state-of-the-art results.
3D Facial Expression Reconstruction using Cascaded Regression
Aug 17, 2018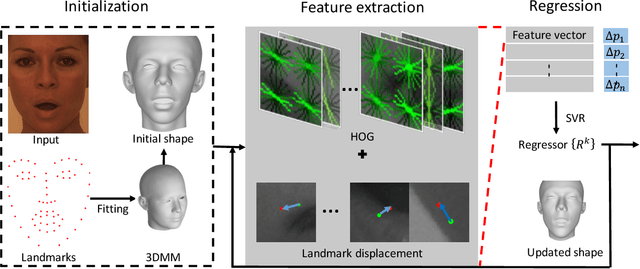
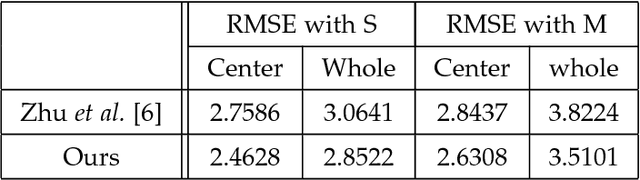
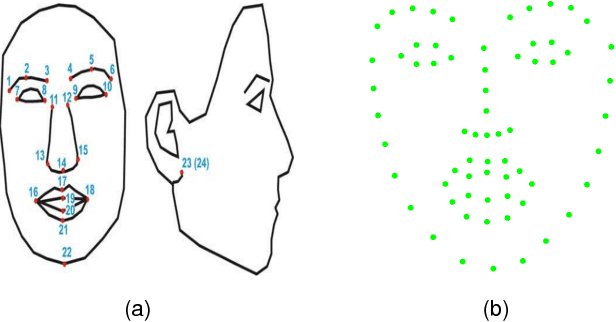
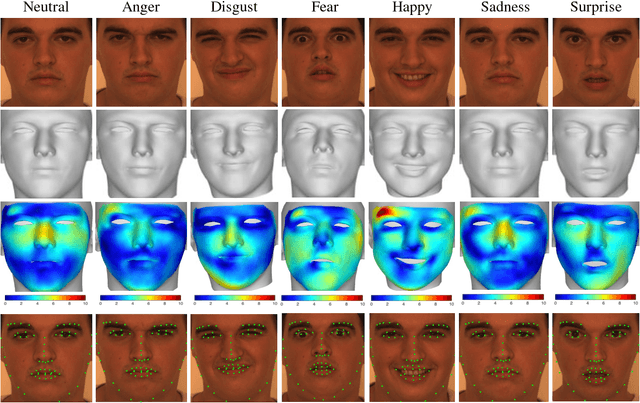
This paper proposes a novel model fitting algorithm for 3D facial expression reconstruction from a single image. Face expression reconstruction from a single image is a challenging task in computer vision. Most state-of-the-art methods fit the input image to a 3D Morphable Model (3DMM). These methods need to solve a stochastic problem and cannot deal with expression and pose variations. To solve this problem, we adopt a 3D face expression model and use a combined feature which is robust to scale, rotation and different lighting conditions. The proposed method applies a cascaded regression framework to estimate parameters for the 3DMM. 2D landmarks are detected and used to initialize the 3D shape and mapping matrices. In each iteration, residues between the current 3DMM parameters and the ground truth are estimated and then used to update the 3D shapes. The mapping matrices are also calculated based on the updated shapes and 2D landmarks. HOG features of the local patches and displacements between 3D landmark projections and 2D landmarks are exploited. Compared with existing methods, the proposed method is robust to expression and pose changes and can reconstruct higher fidelity 3D face shape.