 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
3D-TalkEmo: Learning to Synthesize 3D Emotional Talking Head
Apr 25, 2021

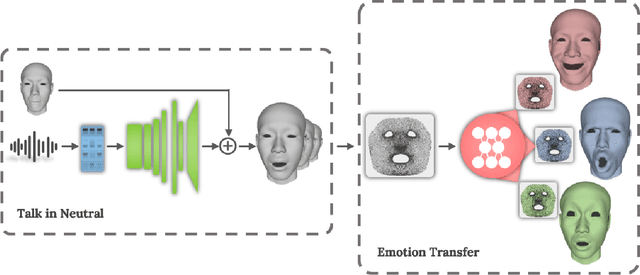

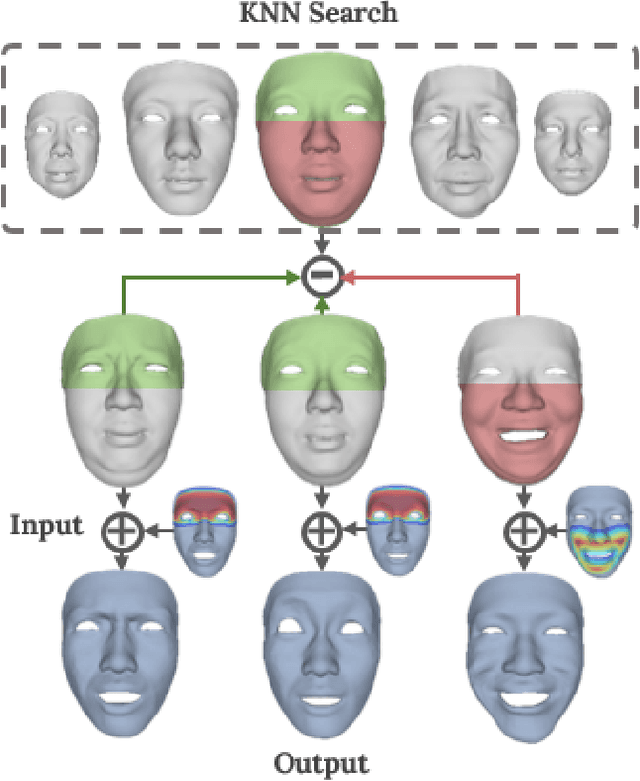
Impressive progress has been made in audio-driven 3D facial animation recently, but synthesizing 3D talking-head with rich emotion is still unsolved. This is due to the lack of 3D generative models and available 3D emotional dataset with synchronized audios. To address this, we introduce 3D-TalkEmo, a deep neural network that generates 3D talking head animation with various emotions. We also create a large 3D dataset with synchronized audios and videos, rich corpus, as well as various emotion states of different persons with the sophisticated 3D face reconstruction methods. In the emotion generation network, we propose a novel 3D face representation structure - geometry map by classical multi-dimensional scaling analysis. It maps the coordinates of vertices on a 3D face to a canonical image plane, while preserving the vertex-to-vertex geodesic distance metric in a least-square sense. This maintains the adjacency relationship of each vertex and holds the effective convolutional structure for the 3D facial surface. Taking a neutral 3D mesh and a speech signal as inputs, the 3D-TalkEmo is able to generate vivid facial animations. Moreover, it provides access to change the emotion state of the animated speaker. We present extensive quantitative and qualitative evaluation of our method, in addition to user studies, demonstrating the generated talking-heads of significantly higher quality compared to previous state-of-the-art methods.
CASIA-Face-Africa: A Large-scale African Face Image Database
May 11, 2021
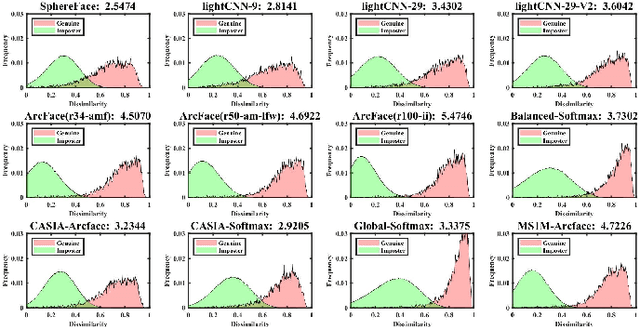
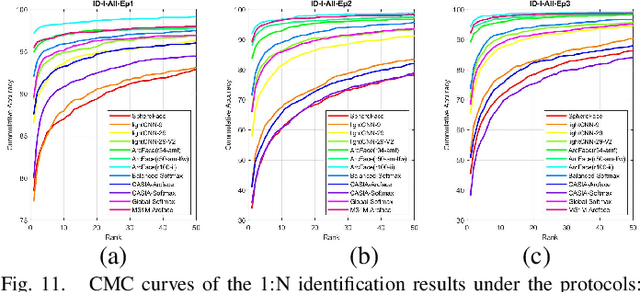

Face recognition is a popular and well-studied area with wide applications in our society. However, racial bias had been proven to be inherent in most State Of The Art (SOTA) face recognition systems. Many investigative studies on face recognition algorithms have reported higher false positive rates of African subjects cohorts than the other cohorts. Lack of large-scale African face image databases in public domain is one of the main restrictions in studying the racial bias problem of face recognition. To this end, we collect a face image database namely CASIA-Face-Africa which contains 38,546 images of 1,183 African subjects. Multi-spectral cameras are utilized to capture the face images under various illumination settings. Demographic attributes and facial expressions of the subjects are also carefully recorded. For landmark detection, each face image in the database is manually labeled with 68 facial keypoints. A group of evaluation protocols are constructed according to different applications, tasks, partitions and scenarios. The performances of SOTA face recognition algorithms without re-training are reported as baselines. The proposed database along with its face landmark annotations, evaluation protocols and preliminary results form a good benchmark to study the essential aspects of face biometrics for African subjects, especially face image preprocessing, face feature analysis and matching, facial expression recognition, sex/age estimation, ethnic classification, face image generation, etc. The database can be downloaded from our http://www.cripacsir.cn/dataset/
Label distribution based facial attractiveness computation by deep residual learning
Sep 07, 2016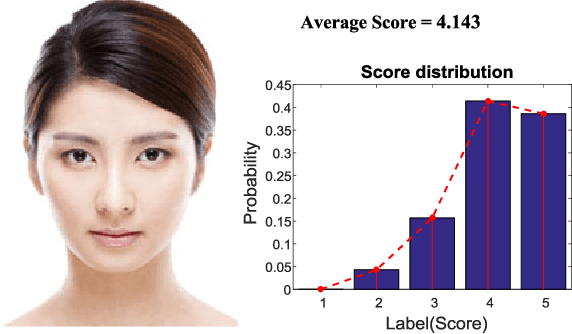
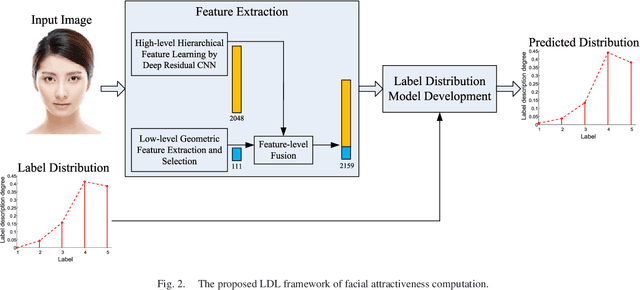
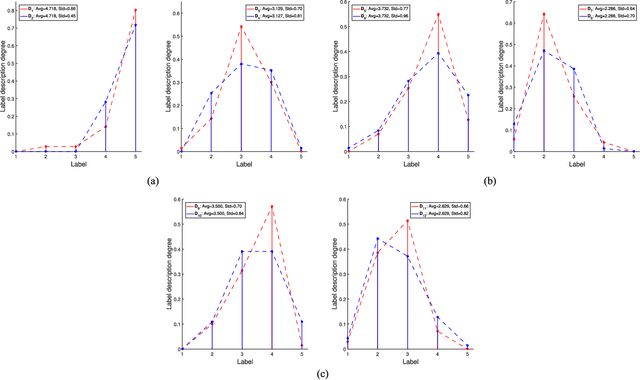
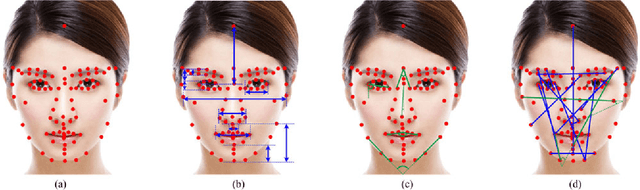
Two challenges lie in the facial attractiveness computation research: the lack of true attractiveness labels (scores), and the lack of an accurate face representation. In order to address the first challenge, this paper recasts facial attractiveness computation as a label distribution learning (LDL) problem rather than a traditional single-label supervised learning task. In this way, the negative influence of the label incomplete problem can be reduced. Inspired by the recent promising work in face recognition using deep neural networks to learn effective features, the second challenge is expected to be solved from a deep learning point of view. A very deep residual network is utilized to enable automatic learning of hierarchical aesthetics representation. Integrating these two ideas, an end-to-end deep learning framework is established. Our approach achieves the best results on a standard benchmark SCUT-FBP dataset compared with other state-of-the-art work.
Generalized Visual Quality Assessment of GAN-Generated Face Images
Jan 28, 2022
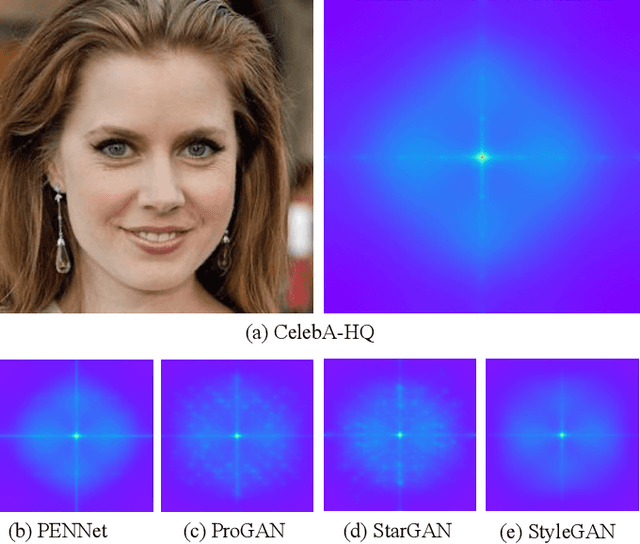
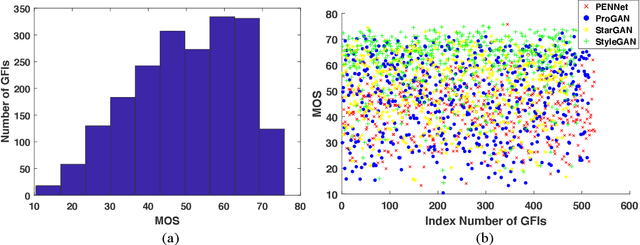
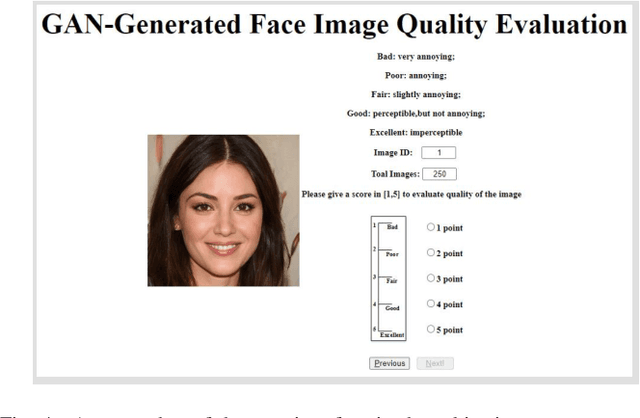
Recent years have witnessed the dramatically increased interest in face generation with generative adversarial networks (GANs). A number of successful GAN algorithms have been developed to produce vivid face images towards different application scenarios. However, little work has been dedicated to automatic quality assessment of such GAN-generated face images (GFIs), even less have been devoted to generalized and robust quality assessment of GFIs generated with unseen GAN model. Herein, we make the first attempt to study the subjective and objective quality towards generalized quality assessment of GFIs. More specifically, we establish a large-scale database consisting of GFIs from four GAN algorithms, the pseudo labels from image quality assessment (IQA) measures, as well as the human opinion scores via subjective testing. Subsequently, we develop a quality assessment model that is able to deliver accurate quality predictions for GFIs from both available and unseen GAN algorithms based on meta-learning. In particular, to learn shared knowledge from GFIs pairs that are born of limited GAN algorithms, we develop the convolutional block attention (CBA) and facial attributes-based analysis (ABA) modules, ensuring that the learned knowledge tends to be consistent with human visual perception. Extensive experiments exhibit that the proposed model achieves better performance compared with the state-of-the-art IQA models, and is capable of retaining the effectiveness when evaluating GFIs from the unseen GAN algorithms.
A Parallel Approach for Real-Time Face Recognition from a Large Database
Nov 01, 2020
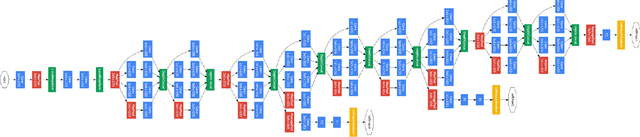

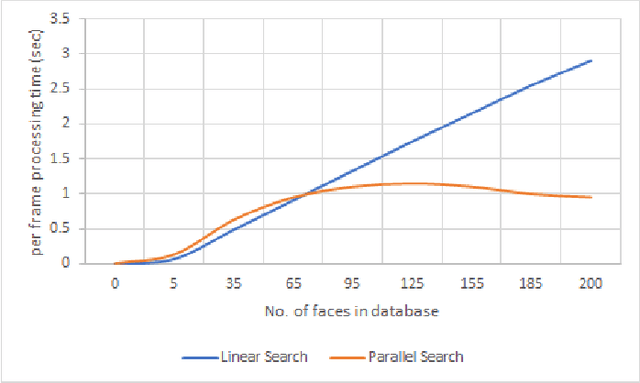
We present a new facial recognition system, capable of identifying a person, provided their likeness has been previously stored in the system, in real time. The system is based on storing and comparing facial embeddings of the subject, and identifying them later within a live video feed. This system is highly accurate, and is able to tag people with their ID in real time. It is able to do so, even when using a database containing thousands of facial embeddings, by using a parallelized searching technique. This makes the system quite fast and allows it to be highly scalable.
Going Deeper in Facial Expression Recognition using Deep Neural Networks
Nov 12, 2015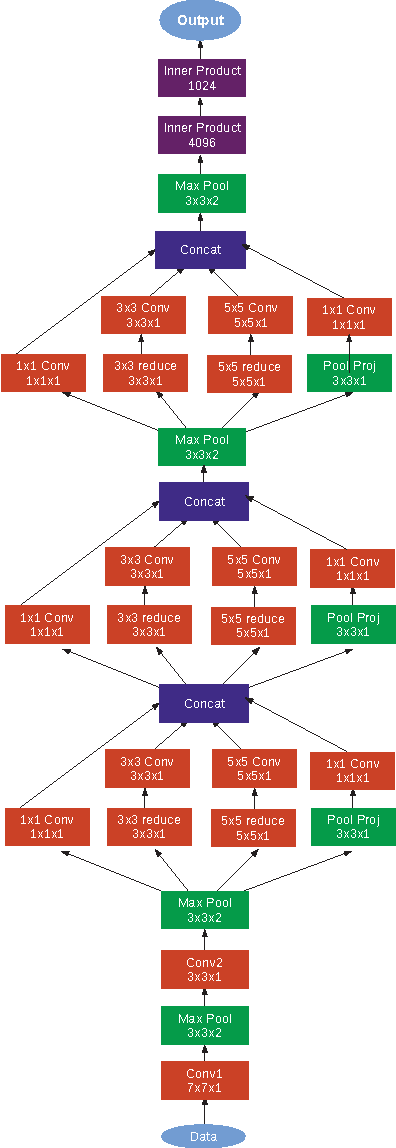
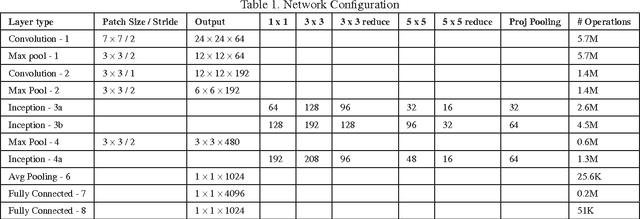

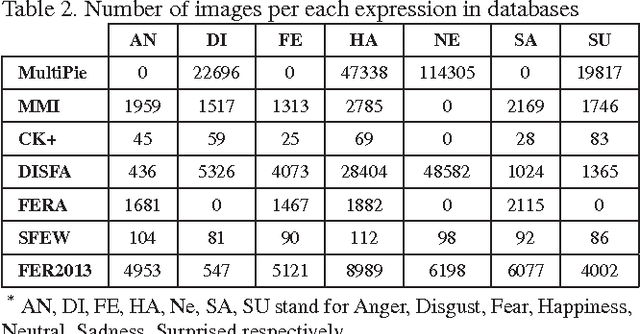
Automated Facial Expression Recognition (FER) has remained a challenging and interesting problem. Despite efforts made in developing various methods for FER, existing approaches traditionally lack generalizability when applied to unseen images or those that are captured in wild setting. Most of the existing approaches are based on engineered features (e.g. HOG, LBPH, and Gabor) where the classifier's hyperparameters are tuned to give best recognition accuracies across a single database, or a small collection of similar databases. Nevertheless, the results are not significant when they are applied to novel data. This paper proposes a deep neural network architecture to address the FER problem across multiple well-known standard face datasets. Specifically, our network consists of two convolutional layers each followed by max pooling and then four Inception layers. The network is a single component architecture that takes registered facial images as the input and classifies them into either of the six basic or the neutral expressions. We conducted comprehensive experiments on seven publically available facial expression databases, viz. MultiPIE, MMI, CK+, DISFA, FERA, SFEW, and FER2013. The results of proposed architecture are comparable to or better than the state-of-the-art methods and better than traditional convolutional neural networks and in both accuracy and training time.
* To be appear in IEEE Winter Conference on Applications of Computer Vision (WACV), 2016 {Accepted in first round submission}
FENeRF: Face Editing in Neural Radiance Fields
Nov 30, 2021
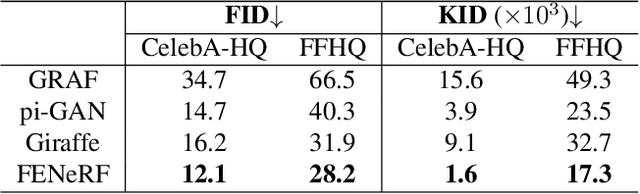
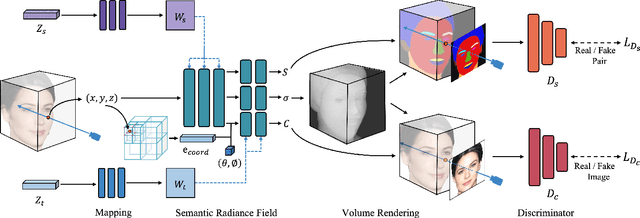

Previous portrait image generation methods roughly fall into two categories: 2D GANs and 3D-aware GANs. 2D GANs can generate high fidelity portraits but with low view consistency. 3D-aware GAN methods can maintain view consistency but their generated images are not locally editable. To overcome these limitations, we propose FENeRF, a 3D-aware generator that can produce view-consistent and locally-editable portrait images. Our method uses two decoupled latent codes to generate corresponding facial semantics and texture in a spatial aligned 3D volume with shared geometry. Benefiting from such underlying 3D representation, FENeRF can jointly render the boundary-aligned image and semantic mask and use the semantic mask to edit the 3D volume via GAN inversion. We further show such 3D representation can be learned from widely available monocular image and semantic mask pairs. Moreover, we reveal that joint learning semantics and texture helps to generate finer geometry. Our experiments demonstrate that FENeRF outperforms state-of-the-art methods in various face editing tasks.
Using Deep Cross Modal Hashing and Error Correcting Codes for Improving the Efficiency of Attribute Guided Facial Image Retrieval
Feb 11, 2019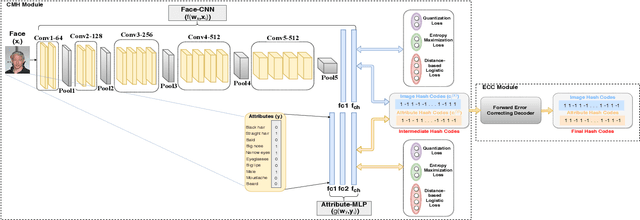

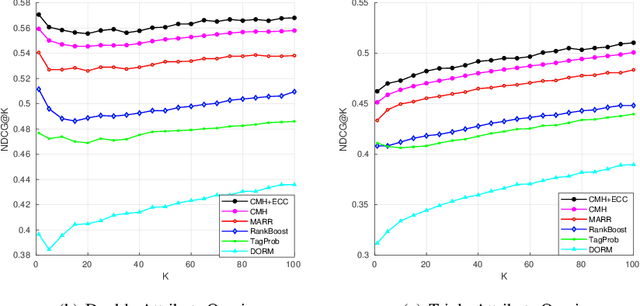
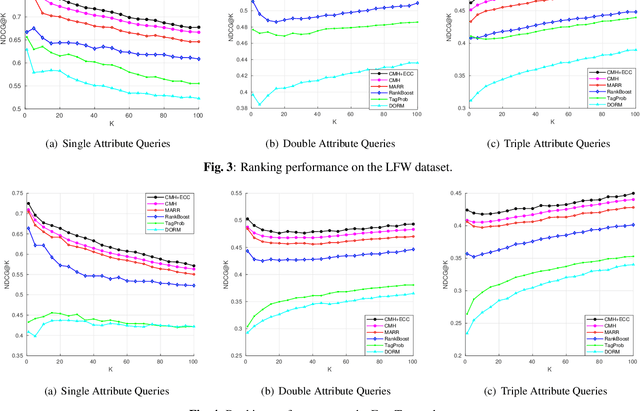
With benefits of fast query speed and low storage cost, hashing-based image retrieval approaches have garnered considerable attention from the research community. In this paper, we propose a novel Error-Corrected Deep Cross Modal Hashing (CMH-ECC) method which uses a bitmap specifying the presence of certain facial attributes as an input query to retrieve relevant face images from the database. In this architecture, we generate compact hash codes using an end-to-end deep learning module, which effectively captures the inherent relationships between the face and attribute modality. We also integrate our deep learning module with forward error correction codes to further reduce the distance between different modalities of the same subject. Specifically, the properties of deep hashing and forward error correction codes are exploited to design a cross modal hashing framework with high retrieval performance. Experimental results using two standard datasets with facial attributes-image modalities indicate that our CMH-ECC face image retrieval model outperforms most of the current attribute-based face image retrieval approaches.
Disjoint Contrastive Regression Learning for Multi-Sourced Annotations
Dec 31, 2021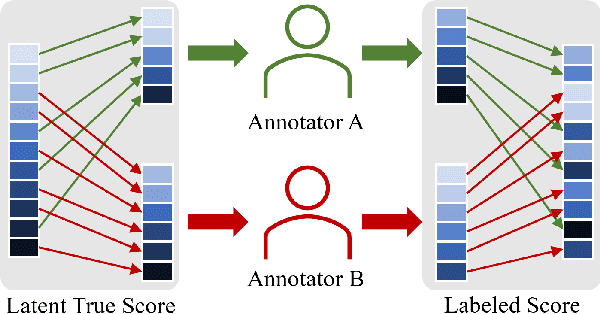
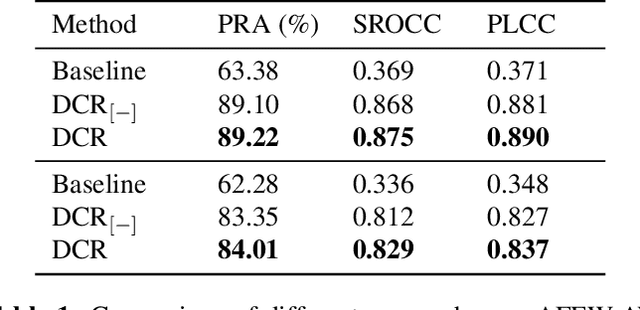
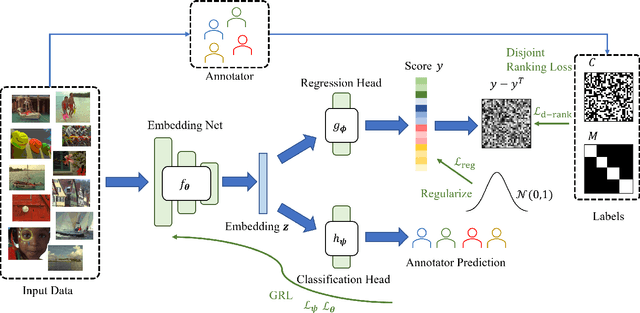
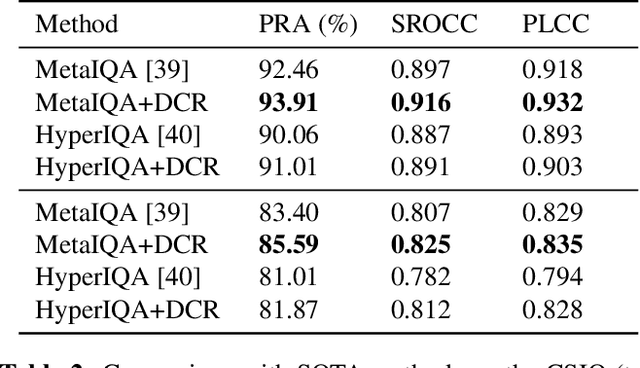
Large-scale datasets are important for the development of deep learning models. Such datasets usually require a heavy workload of annotations, which are extremely time-consuming and expensive. To accelerate the annotation procedure, multiple annotators may be employed to label different subsets of the data. However, the inconsistency and bias among different annotators are harmful to the model training, especially for qualitative and subjective tasks.To address this challenge, in this paper, we propose a novel contrastive regression framework to address the disjoint annotations problem, where each sample is labeled by only one annotator and multiple annotators work on disjoint subsets of the data. To take account of both the intra-annotator consistency and inter-annotator inconsistency, two strategies are employed.Firstly, a contrastive-based loss is applied to learn the relative ranking among different samples of the same annotator, with the assumption that the ranking of samples from the same annotator is unanimous. Secondly, we apply the gradient reversal layer to learn robust representations that are invariant to different annotators. Experiments on the facial expression prediction task, as well as the image quality assessment task, verify the effectiveness of our proposed framework.
Heterogeneous Visible-Thermal and Visible-Infrared Face Recognition using Unit-Class Loss and Cross-Modality Discriminator
Nov 29, 2021
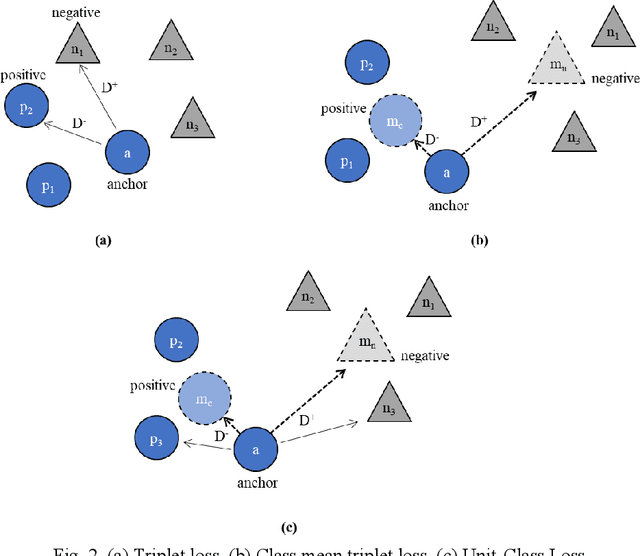
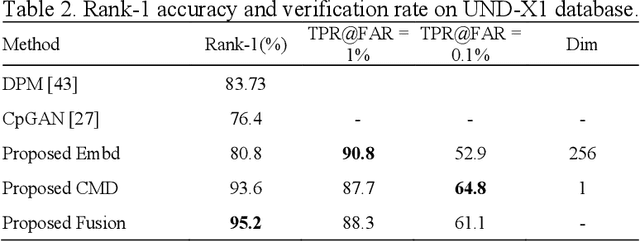
Visible-to-thermal face image matching is a challenging variate of cross-modality recognition. The challenge lies in the large modality gap and low correlation between visible and thermal modalities. Existing approaches employ image preprocessing, feature extraction, or common subspace projection, which are independent problems in themselves. In this paper, we propose an end-to-end framework for cross-modal face recognition. The proposed algorithm aims to learn identity-discriminative features from unprocessed facial images and identify cross-modal image pairs. A novel Unit-Class Loss is proposed for preserving identity information while discarding modality information. In addition, a Cross-Modality Discriminator block is proposed for integrating image-pair classification capability into the network. The proposed network can be used to extract modality-independent vector representations or a matching-pair classification for test images. Our cross-modality face recognition experiments on five independent databases demonstrate that the proposed method achieves marked improvement over existing state-of-the-art methods.