 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Deep Learning Framework to Reconstruct Face under Mask
Mar 23, 2022

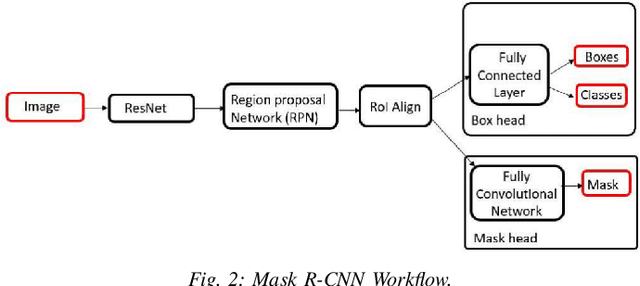
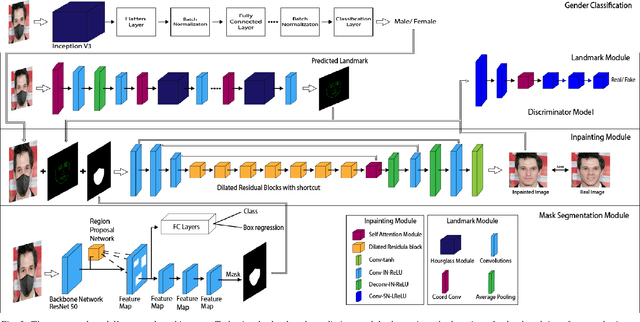
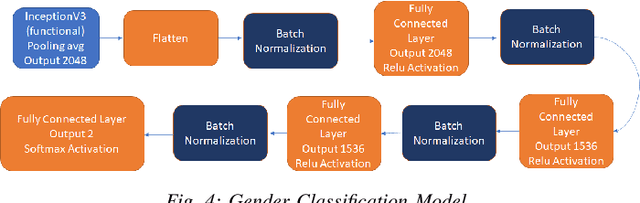
While deep learning-based image reconstruction methods have shown significant success in removing objects from pictures, they have yet to achieve acceptable results for attributing consistency to gender, ethnicity, expression, and other characteristics like the topological structure of the face. The purpose of this work is to extract the mask region from a masked image and rebuild the area that has been detected. This problem is complex because (i) it is difficult to determine the gender of an image hidden behind a mask, which causes the network to become confused and reconstruct the male face as a female or vice versa; (ii) we may receive images from multiple angles, making it extremely difficult to maintain the actual shape, topological structure of the face and a natural image; and (iii) there are problems with various mask forms because, in some cases, the area of the mask cannot be anticipated precisely; certain parts of the mask remain on the face after completion. To solve this complex task, we split the problem into three phases: landmark detection, object detection for the targeted mask area, and inpainting the addressed mask region. To begin, to solve the first problem, we have used gender classification, which detects the actual gender behind a mask, then we detect the landmark of the masked facial image. Second, we identified the non-face item, i.e., the mask, and used the Mask R-CNN network to create the binary mask of the observed mask area. Thirdly, we developed an inpainting network that uses anticipated landmarks to create realistic images. To segment the mask, this article uses a mask R-CNN and offers a binary segmentation map for identifying the mask area. Additionally, we generated the image utilizing landmarks as structural guidance through a GAN-based network. The studies presented in this paper use the FFHQ and CelebA datasets.
Multi Modal Adaptive Normalization for Audio to Video Generation
Dec 14, 2020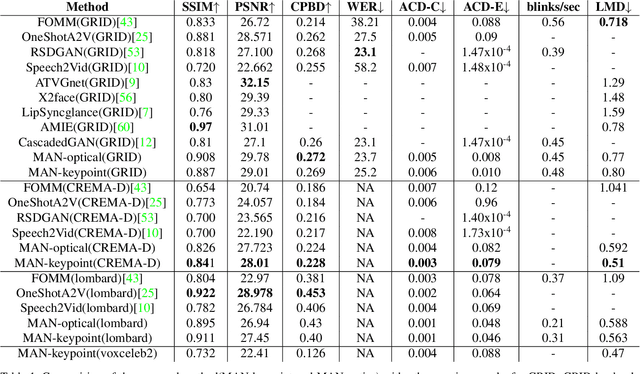

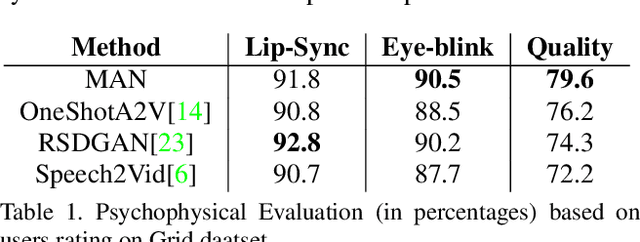
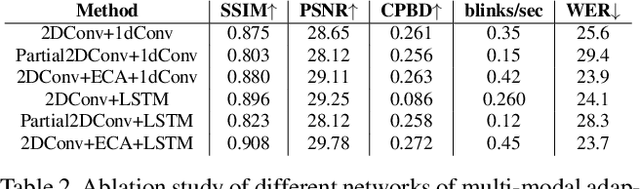
Speech-driven facial video generation has been a complex problem due to its multi-modal aspects namely audio and video domain. The audio comprises lots of underlying features such as expression, pitch, loudness, prosody(speaking style) and facial video has lots of variability in terms of head movement, eye blinks, lip synchronization and movements of various facial action units along with temporal smoothness. Synthesizing highly expressive facial videos from the audio input and static image is still a challenging task for generative adversarial networks. In this paper, we propose a multi-modal adaptive normalization(MAN) based architecture to synthesize a talking person video of arbitrary length using as input: an audio signal and a single image of a person. The architecture uses the multi-modal adaptive normalization, keypoint heatmap predictor, optical flow predictor and class activation map[58] based layers to learn movements of expressive facial components and hence generates a highly expressive talking-head video of the given person. The multi-modal adaptive normalization uses the various features of audio and video such as Mel spectrogram, pitch, energy from audio signals and predicted keypoint heatmap/optical flow and a single image to learn the respective affine parameters to generate highly expressive video. Experimental evaluation demonstrates superior performance of the proposed method as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [53], Speech2Vid [10], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio), CPBD (image sharpness), WER(word error rate), blinks/sec and LMD(landmark distance). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.
Personalized Automatic Estimation of Self-reported Pain Intensity from Facial Expressions
Jun 24, 2017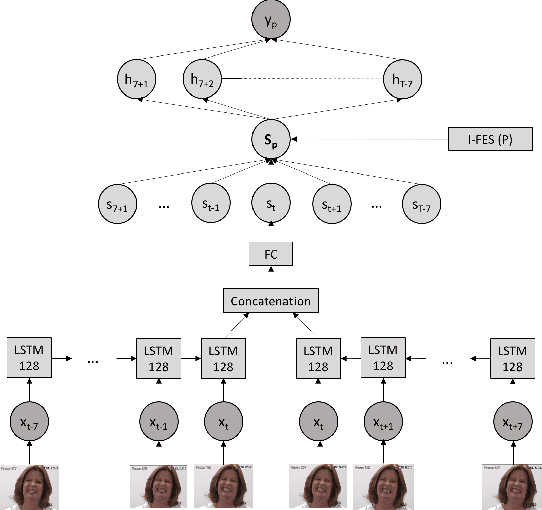

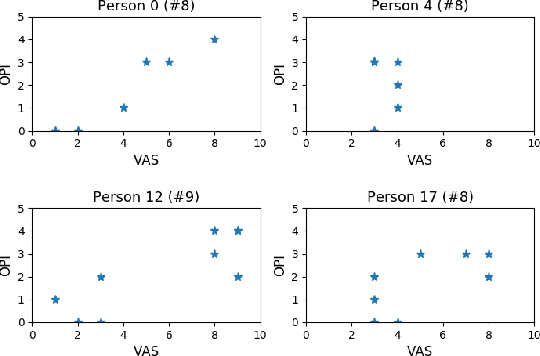
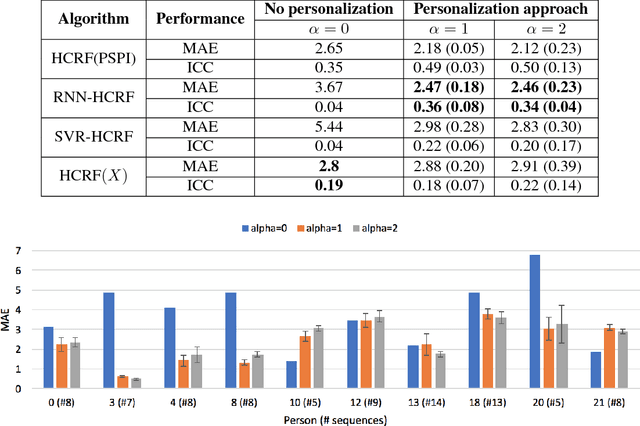
Pain is a personal, subjective experience that is commonly evaluated through visual analog scales (VAS). While this is often convenient and useful, automatic pain detection systems can reduce pain score acquisition efforts in large-scale studies by estimating it directly from the participants' facial expressions. In this paper, we propose a novel two-stage learning approach for VAS estimation: first, our algorithm employs Recurrent Neural Networks (RNNs) to automatically estimate Prkachin and Solomon Pain Intensity (PSPI) levels from face images. The estimated scores are then fed into the personalized Hidden Conditional Random Fields (HCRFs), used to estimate the VAS, provided by each person. Personalization of the model is performed using a newly introduced facial expressiveness score, unique for each person. To the best of our knowledge, this is the first approach to automatically estimate VAS from face images. We show the benefits of the proposed personalized over traditional non-personalized approach on a benchmark dataset for pain analysis from face images.
A Jointly Learned Deep Architecture for Facial Attribute Analysis and Face Detection in the Wild
Jul 27, 2017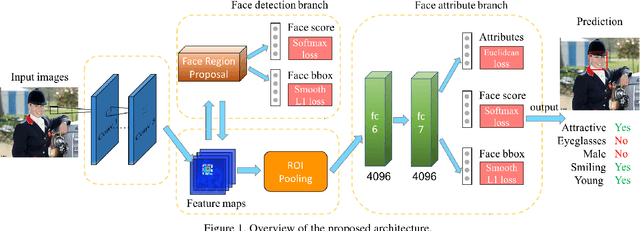
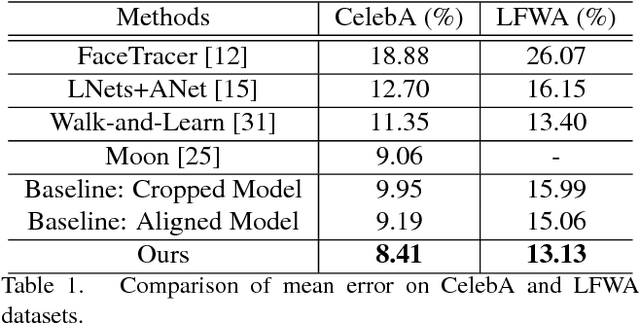
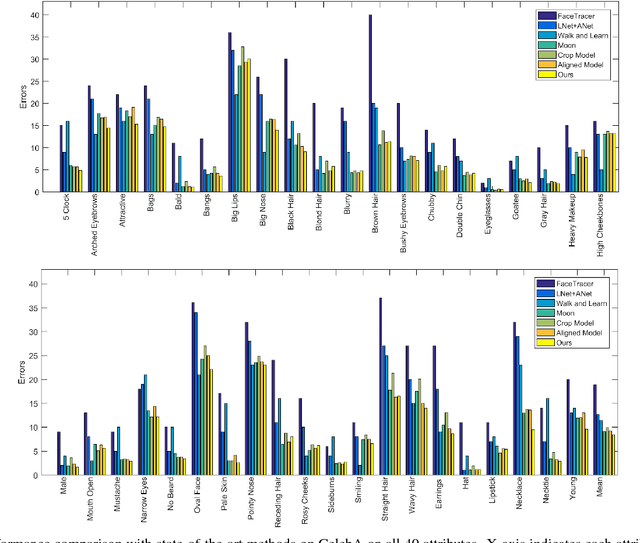
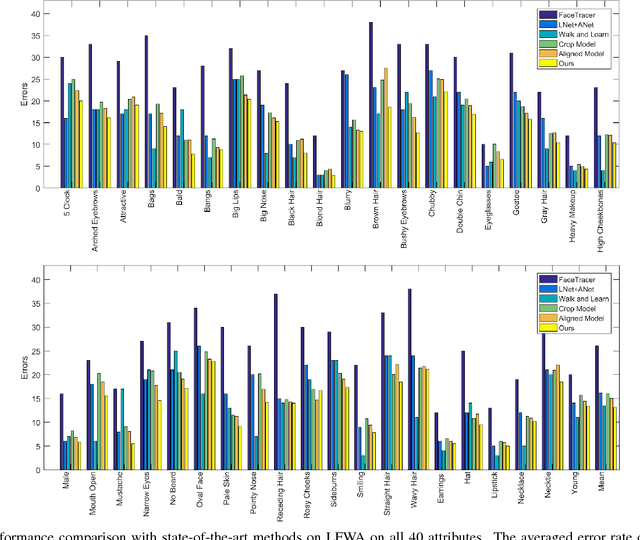
Facial attribute analysis in the real world scenario is very challenging mainly because of complex face variations. Existing works of analyzing face attributes are mostly based on the cropped and aligned face images. However, this result in the capability of attribute prediction heavily relies on the preprocessing of face detector. To address this problem, we present a novel jointly learned deep architecture for both facial attribute analysis and face detection. Our framework can process the natural images in the wild and our experiments on CelebA and LFWA datasets clearly show that the state-of-the-art performance is obtained.
Responsible AI: Gender bias assessment in emotion recognition
Mar 21, 2021
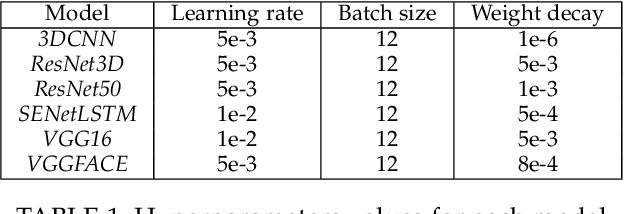

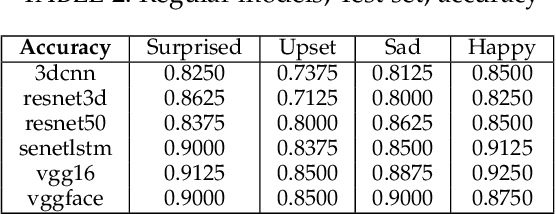
Rapid development of artificial intelligence (AI) systems amplify many concerns in society. These AI algorithms inherit different biases from humans due to mysterious operational flow and because of that it is becoming adverse in usage. As a result, researchers have started to address the issue by investigating deeper in the direction towards Responsible and Explainable AI. Among variety of applications of AI, facial expression recognition might not be the most important one, yet is considered as a valuable part of human-AI interaction. Evolution of facial expression recognition from the feature based methods to deep learning drastically improve quality of such algorithms. This research work aims to study a gender bias in deep learning methods for facial expression recognition by investigating six distinct neural networks, training them, and further analysed on the presence of bias, according to the three definition of fairness. The main outcomes show which models are gender biased, which are not and how gender of subject affects its emotion recognition. More biased neural networks show bigger accuracy gap in emotion recognition between male and female test sets. Furthermore, this trend keeps for true positive and false positive rates. In addition, due to the nature of the research, we can observe which types of emotions are better classified for men and which for women. Since the topic of biases in facial expression recognition is not well studied, a spectrum of continuation of this research is truly extensive, and may comprise detail analysis of state-of-the-art methods, as well as targeting other biases.
Controllable Image-to-Video Translation: A Case Study on Facial Expression Generation
Aug 09, 2018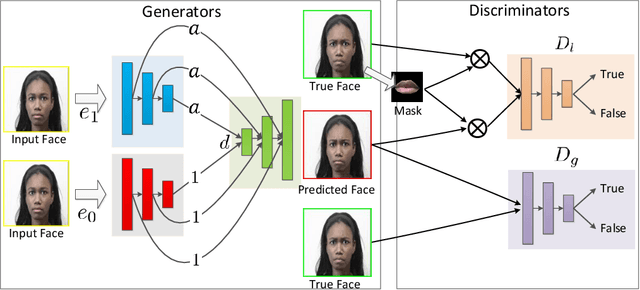


The recent advances in deep learning have made it possible to generate photo-realistic images by using neural networks and even to extrapolate video frames from an input video clip. In this paper, for the sake of both furthering this exploration and our own interest in a realistic application, we study image-to-video translation and particularly focus on the videos of facial expressions. This problem challenges the deep neural networks by another temporal dimension comparing to the image-to-image translation. Moreover, its single input image fails most existing video generation methods that rely on recurrent models. We propose a user-controllable approach so as to generate video clips of various lengths from a single face image. The lengths and types of the expressions are controlled by users. To this end, we design a novel neural network architecture that can incorporate the user input into its skip connections and propose several improvements to the adversarial training method for the neural network. Experiments and user studies verify the effectiveness of our approach. Especially, we would like to highlight that even for the face images in the wild (downloaded from the Web and the authors' own photos), our model can generate high-quality facial expression videos of which about 50\% are labeled as real by Amazon Mechanical Turk workers.
3D Lip Event Detection via Interframe Motion Divergence at Multiple Temporal Resolutions
Nov 18, 2021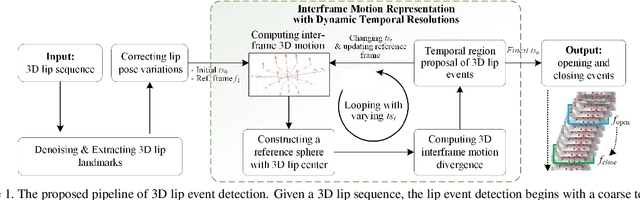
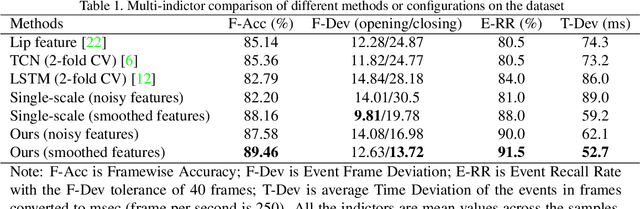
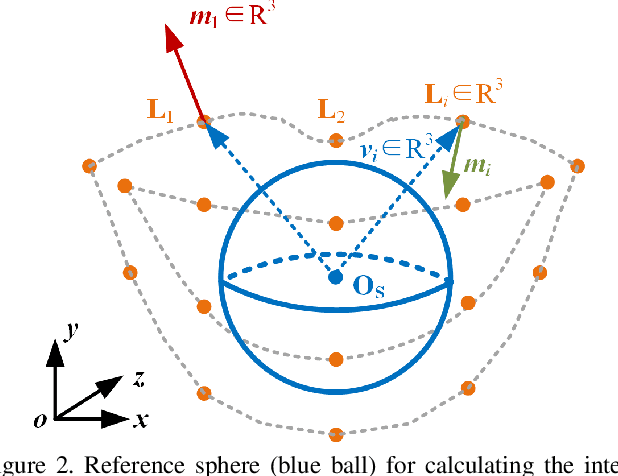
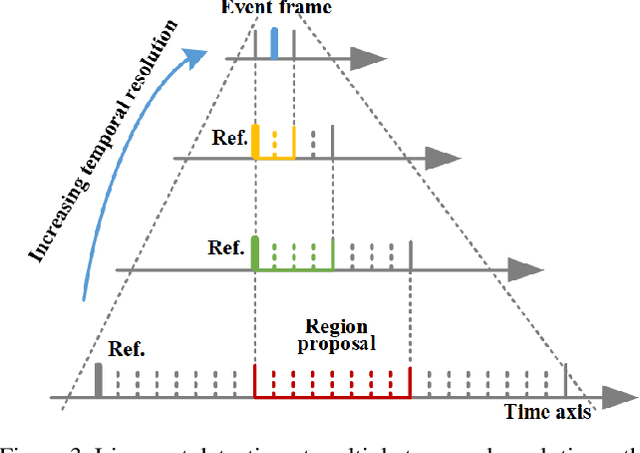
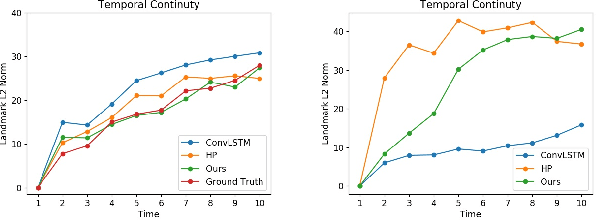
The lip is a dominant dynamic facial unit when a person is speaking. Detecting lip events is beneficial to speech analysis and support for the hearing impaired. This paper proposes a 3D lip event detection pipeline that automatically determines the lip events from a 3D speaking lip sequence. We define a motion divergence measure using 3D lip landmarks to quantify the interframe dynamics of a 3D speaking lip. Then, we cast the interframe motion detection in a multi-temporal-resolution framework that allows the detection to be applicable to different speaking speeds. The experiments on the S3DFM Dataset investigate the overall 3D lip dynamics based on the proposed motion divergence. The proposed 3D pipeline is able to detect opening and closing lip events across 100 sequences, achieving a state-of-the-art performance.
Differential Generative Adversarial Networks: Synthesizing Non-linear Facial Variations with Limited Number of Training Data
Dec 29, 2017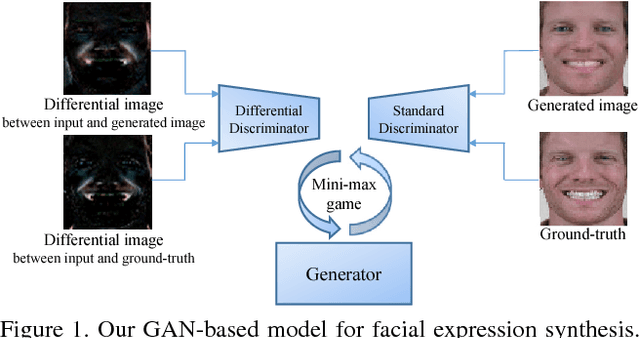
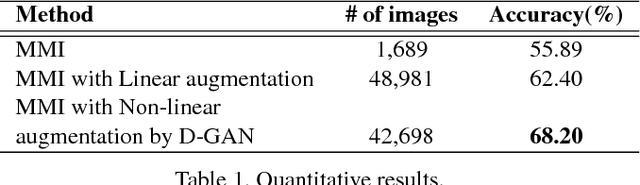
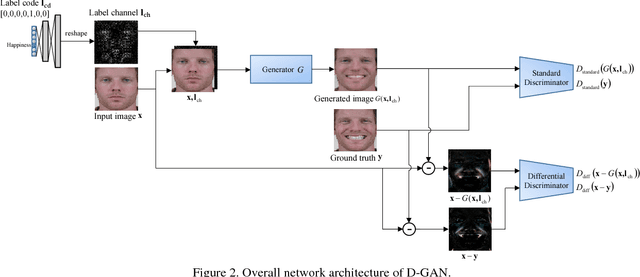

In face-related applications with a public available dataset, synthesizing non-linear facial variations (e.g., facial expression, head-pose, illumination, etc.) through a generative model is helpful in addressing the lack of training data. In reality, however, there is insufficient data to even train the generative model for face synthesis. In this paper, we propose Differential Generative Adversarial Networks (D-GAN) that can perform photo-realistic face synthesis even when training data is small. Two discriminators are devised to ensure the generator to approximate a face manifold, which can express face changes as it wants. Experimental results demonstrate that the proposed method is robust to the amount of training data and synthesized images are useful to improve the performance of a face expression classifier.
Sparse Coding of Shape Trajectories for Facial Expression and Action Recognition
Aug 08, 2019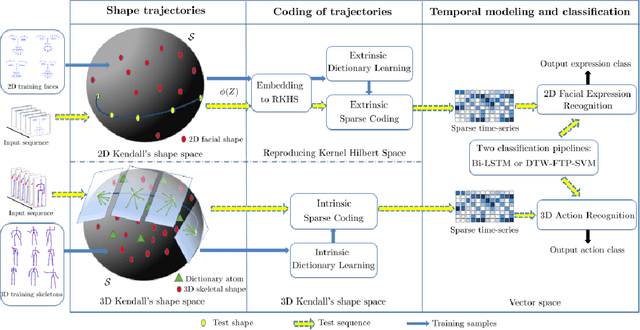
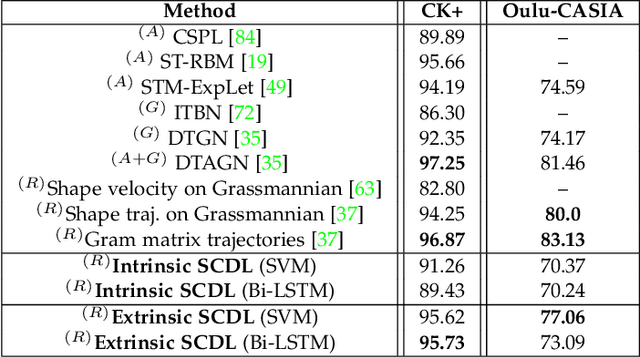
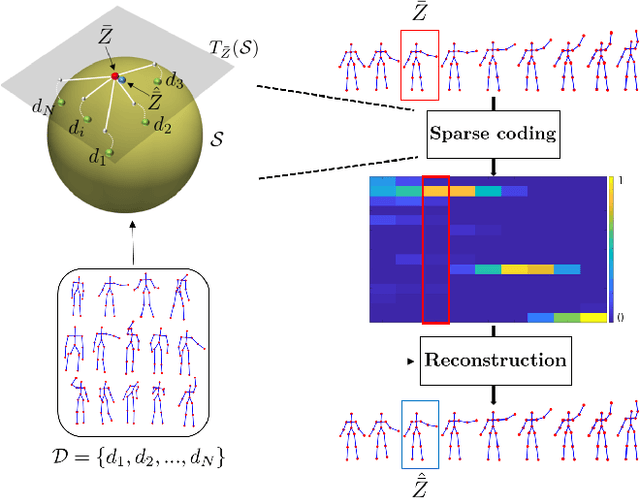
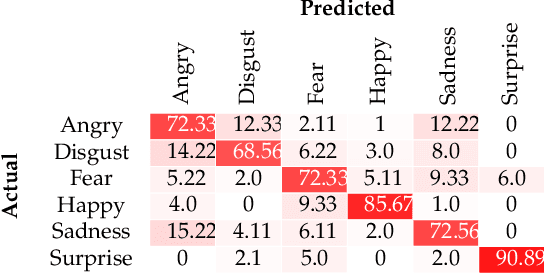
The detection and tracking of human landmarks in video streams has gained in reliability partly due to the availability of affordable RGB-D sensors. The analysis of such time-varying geometric data is playing an important role in the automatic human behavior understanding. However, suitable shape representations as well as their temporal evolution, termed trajectories, often lie to nonlinear manifolds. This puts an additional constraint (i.e., nonlinearity) in using conventional Machine Learning techniques. As a solution, this paper accommodates the well-known Sparse Coding and Dictionary Learning approach to study time-varying shapes on the Kendall shape spaces of 2D and 3D landmarks. We illustrate effective coding of 3D skeletal sequences for action recognition and 2D facial landmark sequences for macro- and micro-expression recognition. To overcome the inherent nonlinearity of the shape spaces, intrinsic and extrinsic solutions were explored. As main results, shape trajectories give rise to more discriminative time-series with suitable computational properties, including sparsity and vector space structure. Extensive experiments conducted on commonly-used datasets demonstrate the competitiveness of the proposed approaches with respect to state-of-the-art.
* 14 pages, 5 figures
MorphGAN: One-Shot Face Synthesis GAN for Detecting Recognition Bias
Dec 10, 2020
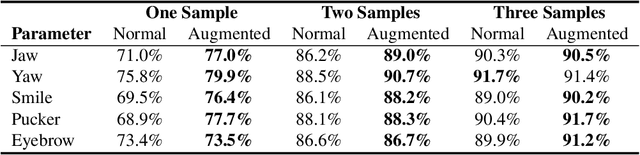
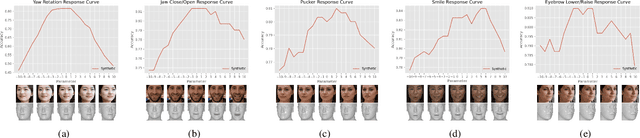

To detect bias in face recognition networks, it can be useful to probe a network under test using samples in which only specific attributes vary in some controlled way. However, capturing a sufficiently large dataset with specific control over the attributes of interest is difficult. In this work, we describe a simulator that applies specific head pose and facial expression adjustments to images of previously unseen people. The simulator first fits a 3D morphable model to a provided image, applies the desired head pose and facial expression controls, then renders the model into an image. Next, a conditional Generative Adversarial Network (GAN) conditioned on the original image and the rendered morphable model is used to produce the image of the original person with the new facial expression and head pose. We call this conditional GAN -- MorphGAN. Images generated using MorphGAN conserve the identity of the person in the original image, and the provided control over head pose and facial expression allows test sets to be created to identify robustness issues of a facial recognition deep network with respect to pose and expression. Images generated by MorphGAN can also serve as data augmentation when training data are scarce. We show that by augmenting small datasets of faces with new poses and expressions improves the recognition performance by up to 9% depending on the augmentation and data scarcity.