 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
Jan 19, 2022
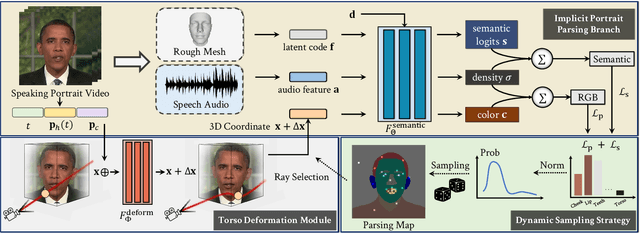
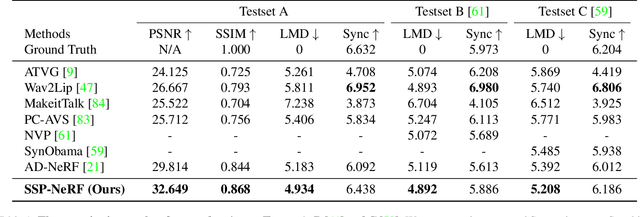
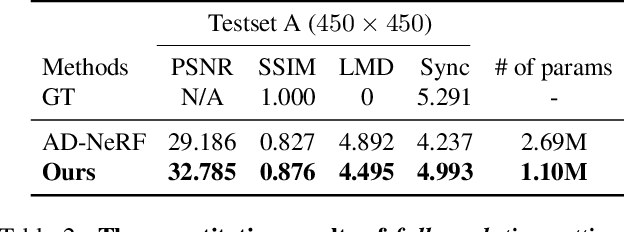

Animating high-fidelity video portrait with speech audio is crucial for virtual reality and digital entertainment. While most previous studies rely on accurate explicit structural information, recent works explore the implicit scene representation of Neural Radiance Fields (NeRF) for realistic generation. In order to capture the inconsistent motions as well as the semantic difference between human head and torso, some work models them via two individual sets of NeRF, leading to unnatural results. In this work, we propose Semantic-aware Speaking Portrait NeRF (SSP-NeRF), which creates delicate audio-driven portraits using one unified set of NeRF. The proposed model can handle the detailed local facial semantics and the global head-torso relationship through two semantic-aware modules. Specifically, we first propose a Semantic-Aware Dynamic Ray Sampling module with an additional parsing branch that facilitates audio-driven volume rendering. Moreover, to enable portrait rendering in one unified neural radiance field, a Torso Deformation module is designed to stabilize the large-scale non-rigid torso motions. Extensive evaluations demonstrate that our proposed approach renders more realistic video portraits compared to previous methods. Project page: https://alvinliu0.github.io/projects/SSP-NeRF
A Deep Learning Framework to Reconstruct Face under Mask
Mar 23, 2022
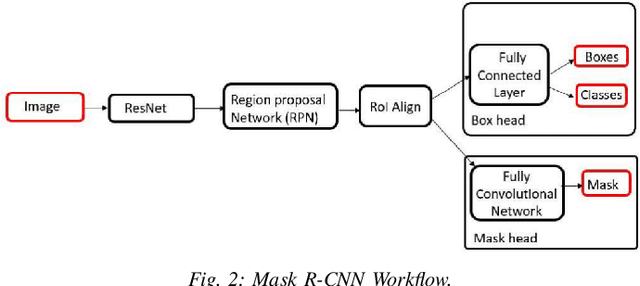
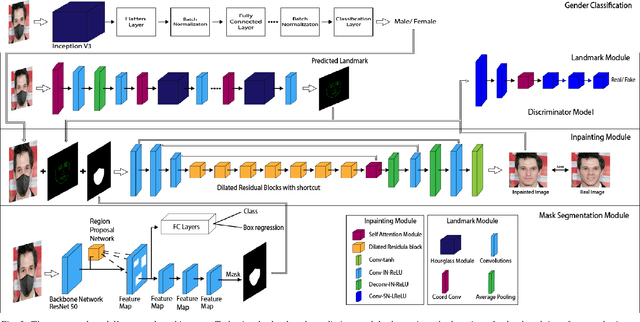
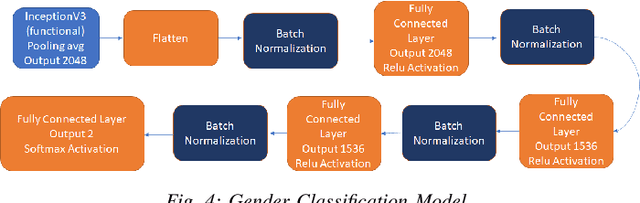
While deep learning-based image reconstruction methods have shown significant success in removing objects from pictures, they have yet to achieve acceptable results for attributing consistency to gender, ethnicity, expression, and other characteristics like the topological structure of the face. The purpose of this work is to extract the mask region from a masked image and rebuild the area that has been detected. This problem is complex because (i) it is difficult to determine the gender of an image hidden behind a mask, which causes the network to become confused and reconstruct the male face as a female or vice versa; (ii) we may receive images from multiple angles, making it extremely difficult to maintain the actual shape, topological structure of the face and a natural image; and (iii) there are problems with various mask forms because, in some cases, the area of the mask cannot be anticipated precisely; certain parts of the mask remain on the face after completion. To solve this complex task, we split the problem into three phases: landmark detection, object detection for the targeted mask area, and inpainting the addressed mask region. To begin, to solve the first problem, we have used gender classification, which detects the actual gender behind a mask, then we detect the landmark of the masked facial image. Second, we identified the non-face item, i.e., the mask, and used the Mask R-CNN network to create the binary mask of the observed mask area. Thirdly, we developed an inpainting network that uses anticipated landmarks to create realistic images. To segment the mask, this article uses a mask R-CNN and offers a binary segmentation map for identifying the mask area. Additionally, we generated the image utilizing landmarks as structural guidance through a GAN-based network. The studies presented in this paper use the FFHQ and CelebA datasets.
Multi-Order Networks for Action Unit Detection
Feb 01, 2022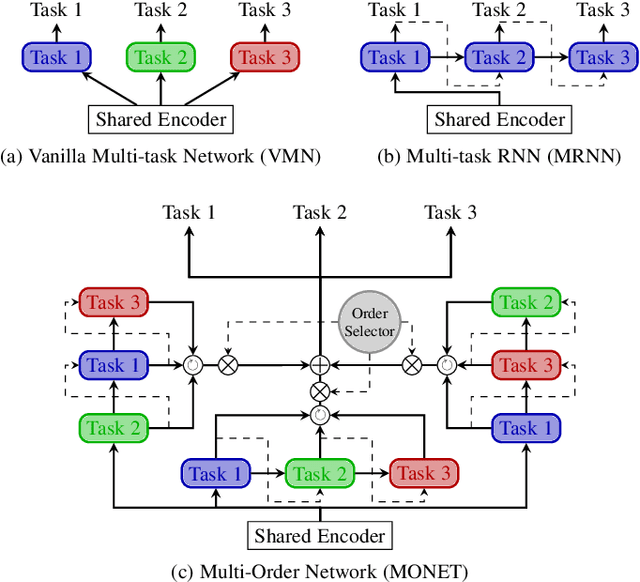
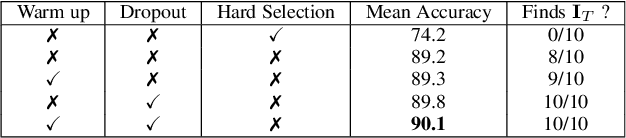
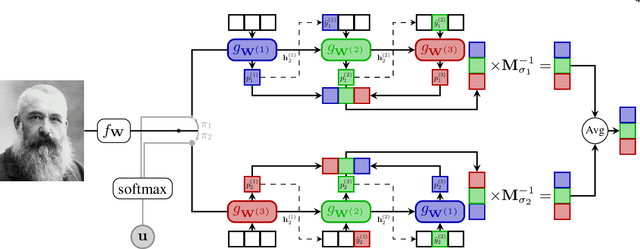
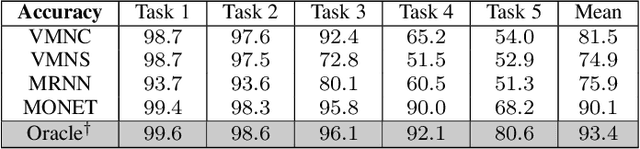
Deep multi-task methods, where several tasks are learned within a single network, have recently attracted increasing attention. Burning point of this attention is their capacity to capture inter-task relationships. Current approaches either only rely on weight sharing, or add explicit dependency modelling by decomposing the task joint distribution using Bayes chain rule. If the latter strategy yields comprehensive inter-task relationships modelling, it requires imposing an arbitrary order into an unordered task set. Most importantly, this sequence ordering choice has been identified as a critical source of performance variations. In this paper, we present Multi-Order Network (MONET), a multi-task learning method with joint task order optimization. MONET uses a differentiable order selection based on soft order modelling inside Birkhoff's polytope to jointly learn task-wise recurrent modules with their optimal chaining order. Furthermore, we introduce warm up and order dropout to enhance order selection by encouraging order exploration. Experimentally, we first validate MONET capacity to retrieve the optimal order in a toy environment. Second, we use an attribute detection scenario to show that MONET outperforms existing multi-task baselines on a wide range of dependency settings. Finally, we demonstrate that MONET significantly extends state-of-the-art performance in Facial Action Unit detection.
Controlling Memorability of Face Images
Feb 24, 2022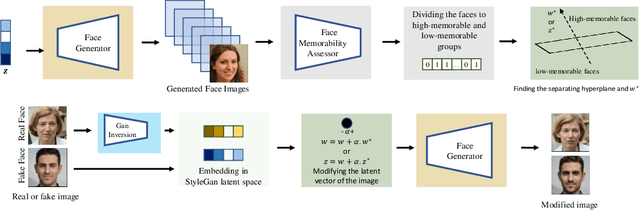


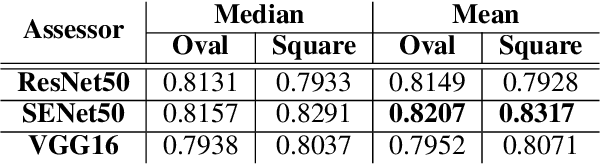
Everyday, we are bombarded with many photographs of faces, whether on social media, television, or smartphones. From an evolutionary perspective, faces are intended to be remembered, mainly due to survival and personal relevance. However, all these faces do not have the equal opportunity to stick in our minds. It has been shown that memorability is an intrinsic feature of an image but yet, it is largely unknown what attributes make an image more memorable. In this work, we aimed to address this question by proposing a fast approach to modify and control the memorability of face images. In our proposed method, we first found a hyperplane in the latent space of StyleGAN to separate high and low memorable images. We then modified the image memorability (while maintaining the identity and other facial features such as age, emotion, etc.) by moving in the positive or negative direction of this hyperplane normal vector. We further analyzed how different layers of the StyleGAN augmented latent space contribute to face memorability. These analyses showed how each individual face attribute makes an image more or less memorable. Most importantly, we evaluated our proposed method for both real and synthesized face images. The proposed method successfully modifies and controls the memorability of real human faces as well as unreal synthesized faces. Our proposed method can be employed in photograph editing applications for social media, learning aids, or advertisement purposes.
A Dynamic 3D Spontaneous Micro-expression Database: Establishment and Evaluation
Aug 22, 2021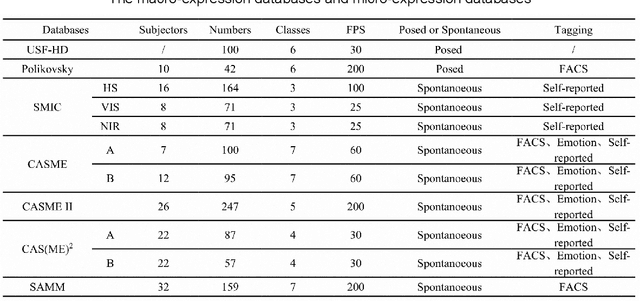
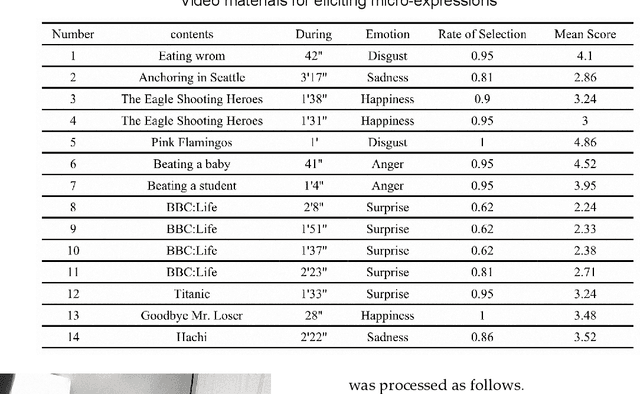


Micro-expressions are spontaneous, unconscious facial movements that show people's true inner emotions and have great potential in related fields of psychological testing. Since the face is a 3D deformation object, the occurrence of an expression can arouse spatial deformation of the face, but limited by the available databases are 2D videos, lacking the description of 3D spatial information of micro-expressions. Therefore, we proposed a new micro-expression database containing 2D video sequences and 3D point clouds sequences. The database includes 259 micro-expressions sequences, and these samples were classified using the objective method based on facial action coding system, as well as the non-objective method that combines video contents and participants' self-reports. We extracted 2D and 3D features using the local binary patterns on three orthogonal planes (LBP-TOP) and curvature algorithms, respectively, and evaluated the classification accuracies of these two features and their fusion results with leave-one-subject-out (LOSO) and 10-fold cross-validation. Further, we performed various neural network algorithms for database classification, the results show that classification accuracies are improved by fusing 3D features than using only 2D features. The database offers original and cropped micro-expression samples, which will facilitate the exploration and research on 3D Spatio-temporal features of micro-expressions.
VariTex: Variational Neural Face Textures
Apr 13, 2021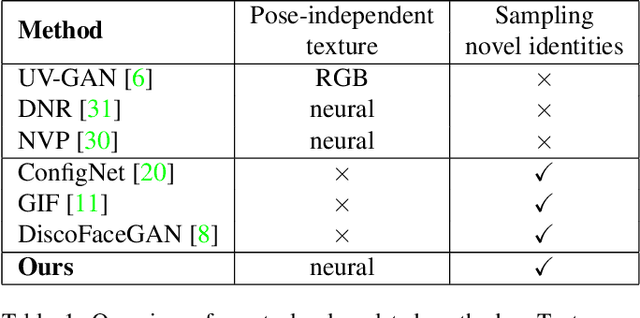
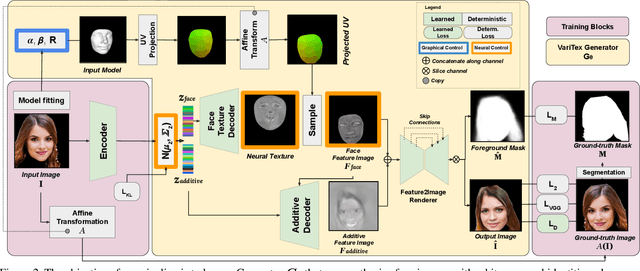


Deep generative models have recently demonstrated the ability to synthesize photorealistic images of human faces with novel identities. A key challenge to the wide applicability of such techniques is to provide independent control over semantically meaningful parameters: appearance, head pose, face shape, and facial expressions. In this paper, we propose VariTex - to the best of our knowledge the first method that learns a variational latent feature space of neural face textures, which allows sampling of novel identities. We combine this generative model with a parametric face model and gain explicit control over head pose and facial expressions. To generate images of complete human heads, we propose an additive decoder that generates plausible additional details such as hair. A novel training scheme enforces a pose independent latent space and in consequence, allows learning of a one-to-many mapping between latent codes and pose-conditioned exterior regions. The resulting method can generate geometrically consistent images of novel identities allowing fine-grained control over head pose, face shape, and facial expressions, facilitating a broad range of downstream tasks, like sampling novel identities, re-posing, expression transfer, and more.
Deep Portrait Lighting Enhancement with 3D Guidance
Aug 04, 2021Despite recent breakthroughs in deep learning methods for image lighting enhancement, they are inferior when applied to portraits because 3D facial information is ignored in their models. To address this, we present a novel deep learning framework for portrait lighting enhancement based on 3D facial guidance. Our framework consists of two stages. In the first stage, corrected lighting parameters are predicted by a network from the input bad lighting image, with the assistance of a 3D morphable model and a differentiable renderer. Given the predicted lighting parameter, the differentiable renderer renders a face image with corrected shading and texture, which serves as the 3D guidance for learning image lighting enhancement in the second stage. To better exploit the long-range correlations between the input and the guidance, in the second stage, we design an image-to-image translation network with a novel transformer architecture, which automatically produces a lighting-enhanced result. Experimental results on the FFHQ dataset and in-the-wild images show that the proposed method outperforms state-of-the-art methods in terms of both quantitative metrics and visual quality. We will publish our dataset along with more results on https://cassiepython.github.io/egsr/index.html.
* {\dag} for equal conribution. Accepted to CGF. Project page: https://cassiepython.github.io/egsr/index.html
PureGaze: Purifying Gaze Feature for Generalizable Gaze Estimation
Mar 24, 2021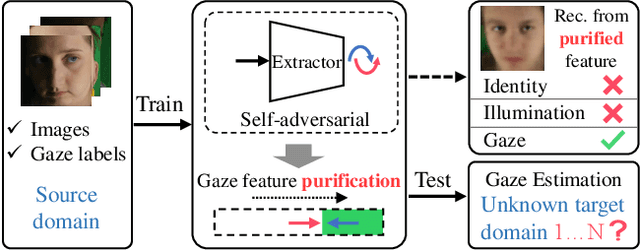
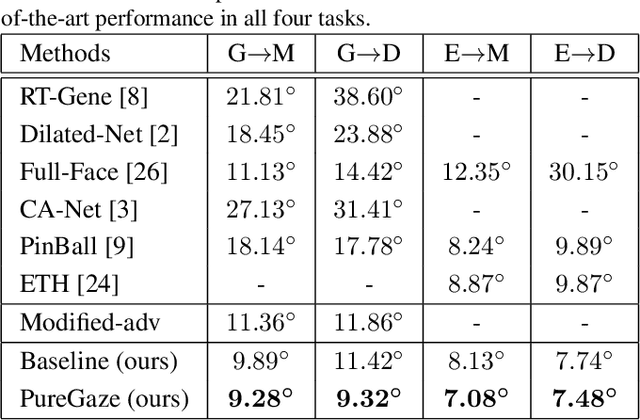
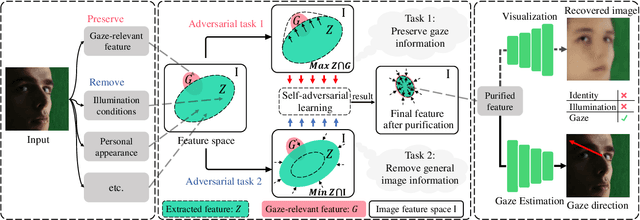
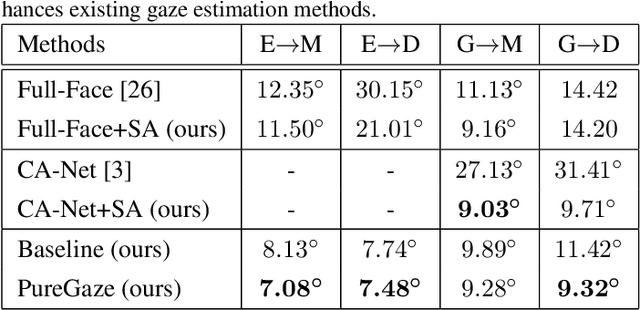
Gaze estimation methods learn eye gaze from facial features. However, among rich information in the facial image, real gaze-relevant features only correspond to subtle changes in eye region, while other gaze-irrelevant features like illumination, personal appearance and even facial expression may affect the learning in an unexpected way. This is a major reason why existing methods show significant performance degradation in cross-domain/dataset evaluation. In this paper, we tackle the domain generalization problem in cross-domain gaze estimation for unknown target domains. To be specific, we realize the domain generalization by gaze feature purification. We eliminate gaze-irrelevant factors such as illumination and identity to improve the cross-dataset performance without knowing the target dataset. We design a plug-and-play self-adversarial framework for the gaze feature purification. The framework enhances not only our baseline but also existing gaze estimation methods directly and significantly. Our method achieves the state-of-the-art performance in different benchmarks. Meanwhile, the purification is easily explainable via visualization.
Controlled AutoEncoders to Generate Faces from Voices
Jul 16, 2021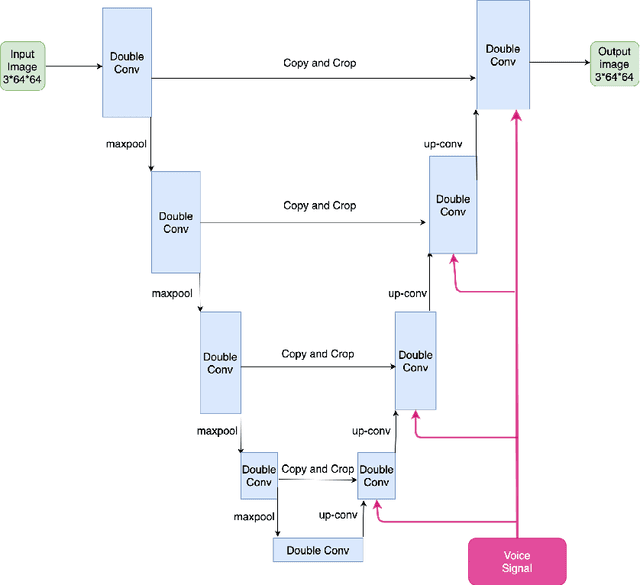
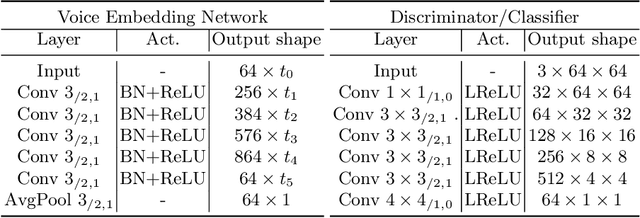
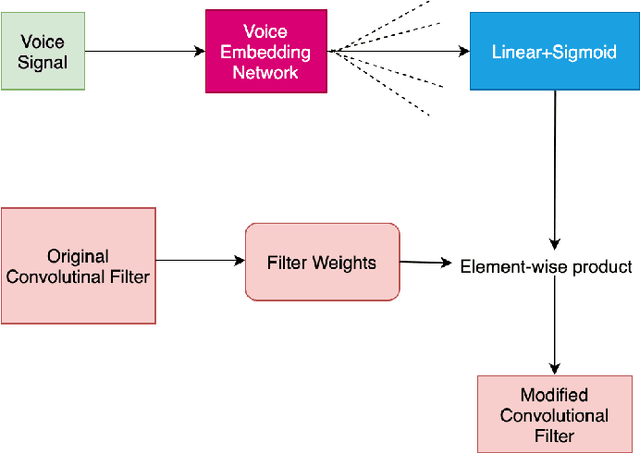

Multiple studies in the past have shown that there is a strong correlation between human vocal characteristics and facial features. However, existing approaches generate faces simply from voice, without exploring the set of features that contribute to these observed correlations. A computational methodology to explore this can be devised by rephrasing the question to: "how much would a target face have to change in order to be perceived as the originator of a source voice?" With this in perspective, we propose a framework to morph a target face in response to a given voice in a way that facial features are implicitly guided by learned voice-face correlation in this paper. Our framework includes a guided autoencoder that converts one face to another, controlled by a unique model-conditioning component called a gating controller which modifies the reconstructed face based on input voice recordings. We evaluate the framework on VoxCelab and VGGFace datasets through human subjects and face retrieval. Various experiments demonstrate the effectiveness of our proposed model.
Robust Facial Landmark Detection under Significant Head Poses and Occlusion
Sep 23, 2017
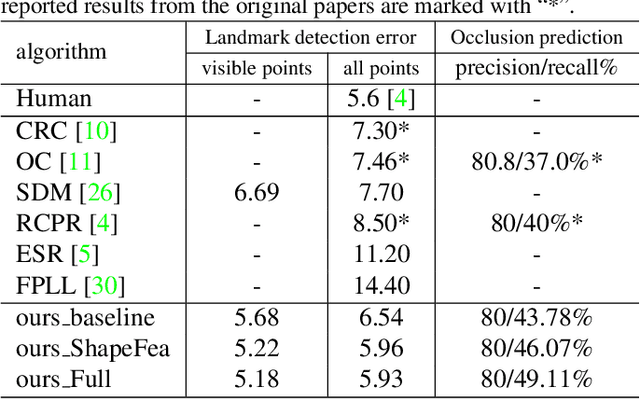

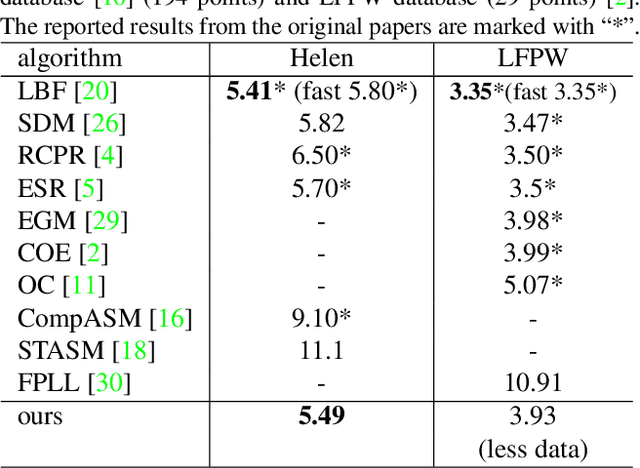
There have been tremendous improvements for facial landmark detection on general "in-the-wild" images. However, it is still challenging to detect the facial landmarks on images with severe occlusion and images with large head poses (e.g. profile face). In fact, the existing algorithms usually can only handle one of them. In this work, we propose a unified robust cascade regression framework that can handle both images with severe occlusion and images with large head poses. Specifically, the method iteratively predicts the landmark occlusions and the landmark locations. For occlusion estimation, instead of directly predicting the binary occlusion vectors, we introduce a supervised regression method that gradually updates the landmark visibility probabilities in each iteration to achieve robustness. In addition, we explicitly add occlusion pattern as a constraint to improve the performance of occlusion prediction. For landmark detection, we combine the landmark visibility probabilities, the local appearances, and the local shapes to iteratively update their positions. The experimental results show that the proposed method is significantly better than state-of-the-art works on images with severe occlusion and images with large head poses. It is also comparable to other methods on general "in-the-wild" images.