 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Super-FAN: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with GANs
Mar 27, 2018
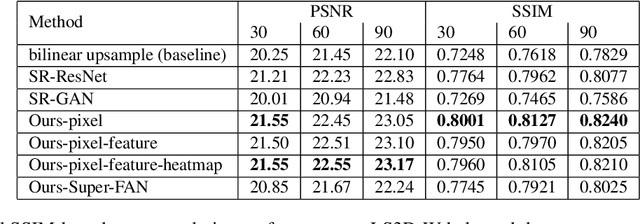
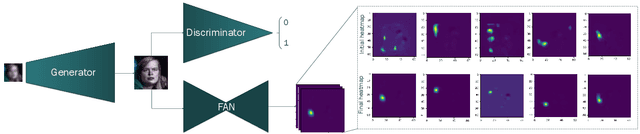
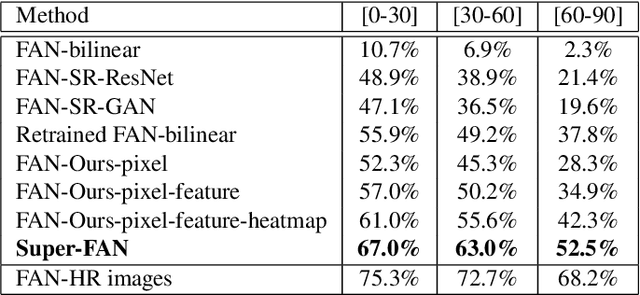
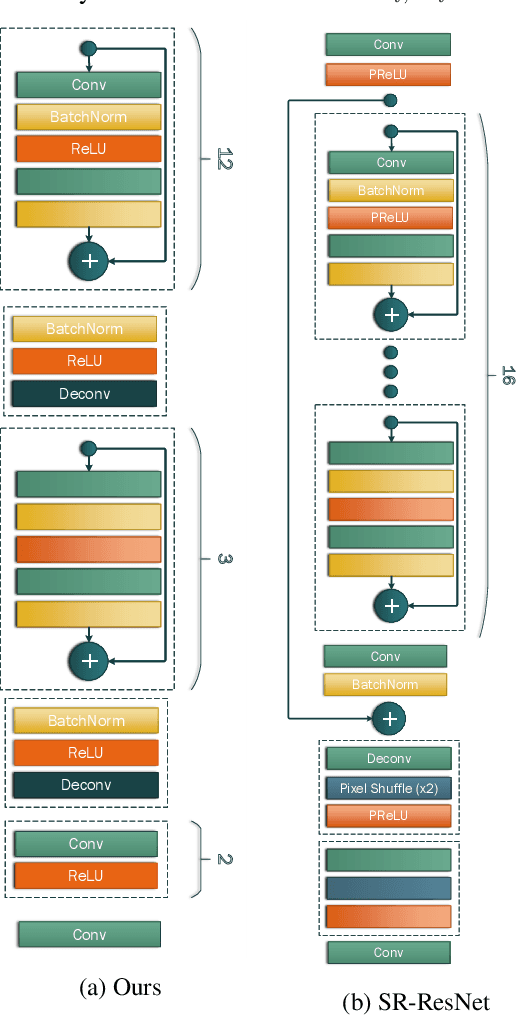
This paper addresses 2 challenging tasks: improving the quality of low resolution facial images and accurately locating the facial landmarks on such poor resolution images. To this end, we make the following 5 contributions: (a) we propose Super-FAN: the very first end-to-end system that addresses both tasks simultaneously, i.e. both improves face resolution and detects the facial landmarks. The novelty or Super-FAN lies in incorporating structural information in a GAN-based super-resolution algorithm via integrating a sub-network for face alignment through heatmap regression and optimizing a novel heatmap loss. (b) We illustrate the benefit of training the two networks jointly by reporting good results not only on frontal images (as in prior work) but on the whole spectrum of facial poses, and not only on synthetic low resolution images (as in prior work) but also on real-world images. (c) We improve upon the state-of-the-art in face super-resolution by proposing a new residual-based architecture. (d) Quantitatively, we show large improvement over the state-of-the-art for both face super-resolution and alignment. (e) Qualitatively, we show for the first time good results on real-world low resolution images.
FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
Mar 21, 2018

We propose FaceVR, a novel image-based method that enables video teleconferencing in VR based on self-reenactment. State-of-the-art face tracking methods in the VR context are focused on the animation of rigged 3d avatars. While they achieve good tracking performance the results look cartoonish and not real. In contrast to these model-based approaches, FaceVR enables VR teleconferencing using an image-based technique that results in nearly photo-realistic outputs. The key component of FaceVR is a robust algorithm to perform real-time facial motion capture of an actor who is wearing a head-mounted display (HMD), as well as a new data-driven approach for eye tracking from monocular videos. Based on reenactment of a prerecorded stereo video of the person without the HMD, FaceVR incorporates photo-realistic re-rendering in real time, thus allowing artificial modifications of face and eye appearances. For instance, we can alter facial expressions or change gaze directions in the prerecorded target video. In a live setup, we apply these newly-introduced algorithmic components.
Look into Facial Expression Domain Adaptation: Adversarial Graph Learning and A Fair Evaluation Benchmark
Aug 27, 2020

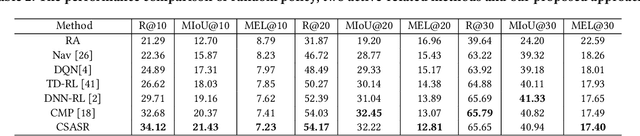
To address the problem of data inconsistencies among different facial expression recognition (FER) datasets, many cross-domain FER methods (CD-FERs) have been extensively devised in recent years. Although each declares to achieve superior performance, fair comparisons are lacking due to the inconsistent choices of the source/target datasets and feature extractors. In this work, we first analyze the performance effect caused by these inconsistent choices, and then re-implement some well-performing CD-FER and recently published domain adaptation algorithms. We ensure that all these algorithms adopt the same source datasets and feature extractors for fair CD-FER evaluations. We find that most of the current leading algorithms use adversarial learning to learn holistic domain-invariant features to mitigate domain shifts. However, these algorithms ignore local features, which are more transferable across different datasets and carry more detailed content for fine-grained adaptation. To address these issues, we integrate graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation by developing a novel adversarial graph representation adaptation (AGRA) framework. Specifically, it first builds two graphs to correlate holistic and local regions within each domain and across different domains, respectively. Then, it extracts holistic-local features from the input image and uses learnable per-class statistical distributions to initialize the corresponding graph nodes. Finally, two stacked graph convolution networks (GCNs) are adopted to propagate holistic-local features within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. We conduct extensive and fair evaluations on several popular benchmarks and show that the proposed AGRA framework outperforms previous state-of-the-art methods.
Improving Facial Emotion Recognition Systems Using Gradient and Laplacian Images
Feb 12, 2019

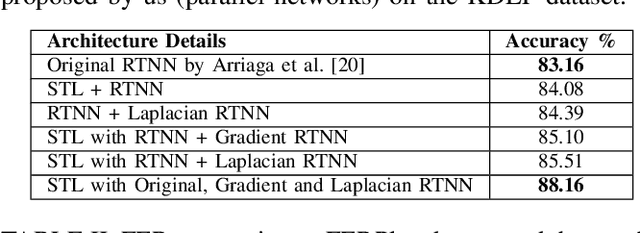
In this work, we have proposed several enhancements to improve the performance of any facial emotion recognition (FER) system. We believe that the changes in the positions of the fiducial points and the intensities capture the crucial information regarding the emotion of a face image. We propose the use of the gradient and the Laplacian of the input image together with the original input into a convolutional neural network (CNN). These modifications help the network learn additional information from the gradient and Laplacian of the images. However, the plain CNN is not able to extract this information from the raw images. We have performed a number of experiments on two well known datasets KDEF and FERplus. Our approach enhances the already high performance of state-of-the-art FER systems by 3 to 5%.
Face Anonymization by Manipulating Decoupled Identity Representation
May 24, 2021

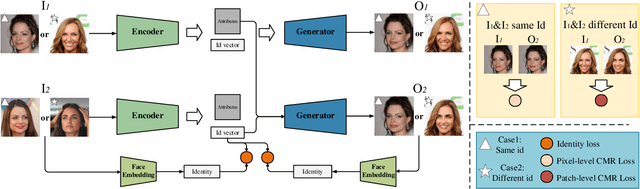

Privacy protection on human biological information has drawn increasing attention in recent years, among which face anonymization plays an importance role. We propose a novel approach which protects identity information of facial images from leakage with slightest modification. Specifically, we disentangle identity representation from other facial attributes leveraging the power of generative adversarial networks trained on a conditional multi-scale reconstruction (CMR) loss and an identity loss. We evaulate the disentangle ability of our model, and propose an effective method for identity anonymization, namely Anonymous Identity Generation (AIG), to reach the goal of face anonymization meanwhile maintaining similarity to the original image as much as possible. Quantitative and qualitative results demonstrate our method's superiority compared with the SOTAs on both visual quality and anonymization success rate.
Robust Real-time Extraction of Fiducial Facial Feature Points using Haar-like Features
May 16, 2015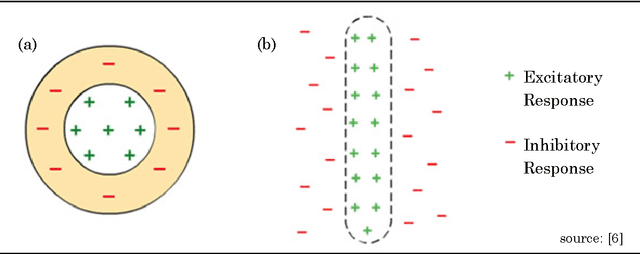
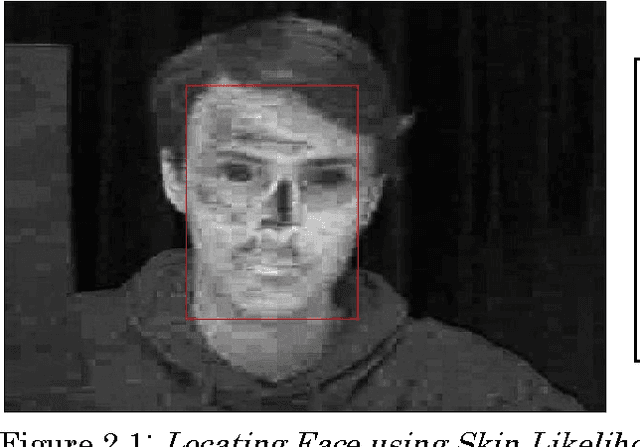


In this paper, we explore methods of robustly extracting fiducial facial feature points - an important process for numerous facial image processing tasks. We consider various methods to first detect face, then facial features and finally salient facial feature points. Colour-based models are analysed and their overall unsuitability for this task is summarised. The bulk of the report is then dedicated to proposing a learning-based method centred on the Viola-Jones algorithm. The specific difficulties and considerations relating to feature point detection are laid out in this context and a novel approach is established to address these issues. On a sequence of clear and unobstructed face images, our proposed system achieves average detection rates of over 90%. Then, using a more varied sample dataset, we identify some possible areas for future development of our system.
Fairness Matters -- A Data-Driven Framework Towards Fair and High Performing Facial Recognition Systems
Sep 16, 2020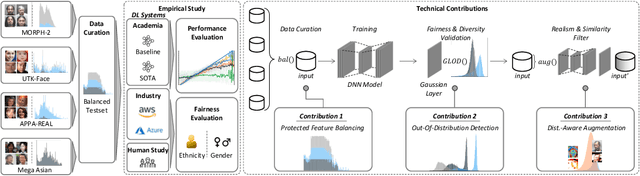


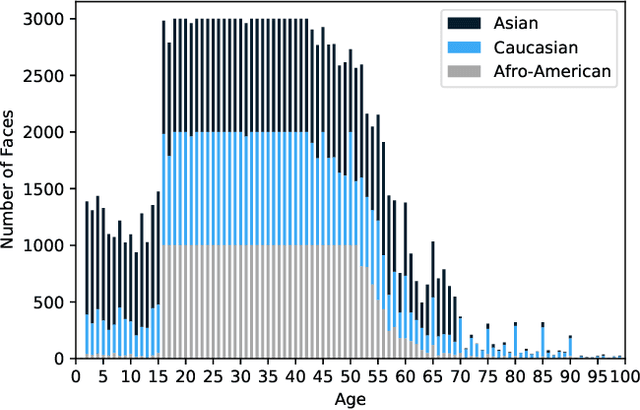
Facial recognition technologies are widely used in governmental and industrial applications. Together with the advancements in deep learning (DL), human-centric tasks such as accurate age prediction based on face images become feasible. However, the issue of fairness when predicting the age for different ethnicity and gender remains an open problem. Policing systems use age to estimate the likelihood of someone to commit a crime, where younger suspects tend to be more likely involved. Unfair age prediction may lead to unfair treatment of humans not only in crime prevention but also in marketing, identity acquisition and authentication. Therefore, this work follows two parts. First, an empirical study is conducted evaluating performance and fairness of state-of-the-art systems for age prediction including baseline and most recent works of academia and the main industrial service providers (Amazon AWS and Microsoft Azure). Building on the findings we present a novel approach to mitigate unfairness and enhance performance, using distribution-aware dataset curation and augmentation. Distribution-awareness is based on out-of-distribution detection which is utilized to validate equal and diverse DL system behavior towards e.g. ethnicity and gender. In total we train 24 DNN models and utilize one million data points to assess performance and fairness of the state-of-the-art for face recognition algorithms. We demonstrate an improvement in mean absolute age prediction error from 7.70 to 3.39 years and a 4-fold increase in fairness towards ethnicity when compared to related work. Utilizing the presented methodology we are able to outperform leading industry players such as Amazon AWS or Microsoft Azure in both fairness and age prediction accuracy and provide the necessary guidelines to assess quality and enhance face recognition systems based on DL techniques.
Leveraging Recent Advances in Deep Learning for Audio-Visual Emotion Recognition
Mar 16, 2021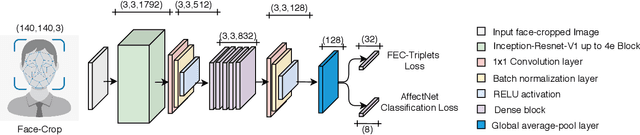
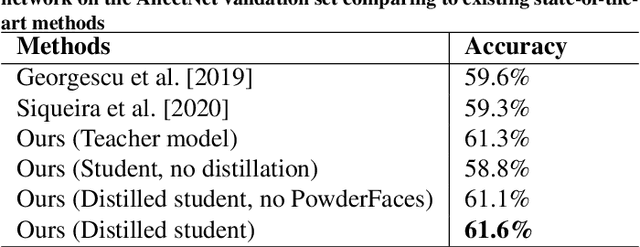
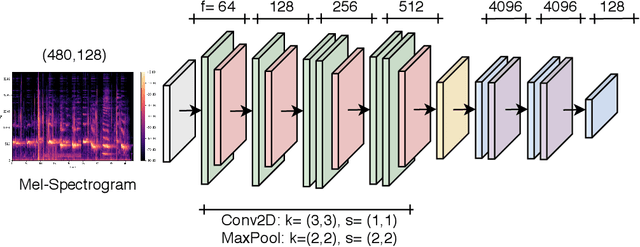
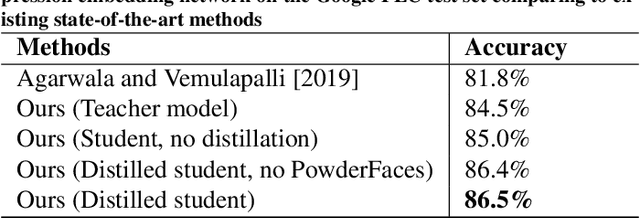
Emotional expressions are the behaviors that communicate our emotional state or attitude to others. They are expressed through verbal and non-verbal communication. Complex human behavior can be understood by studying physical features from multiple modalities; mainly facial, vocal and physical gestures. Recently, spontaneous multi-modal emotion recognition has been extensively studied for human behavior analysis. In this paper, we propose a new deep learning-based approach for audio-visual emotion recognition. Our approach leverages recent advances in deep learning like knowledge distillation and high-performing deep architectures. The deep feature representations of the audio and visual modalities are fused based on a model-level fusion strategy. A recurrent neural network is then used to capture the temporal dynamics. Our proposed approach substantially outperforms state-of-the-art approaches in predicting valence on the RECOLA dataset. Moreover, our proposed visual facial expression feature extraction network outperforms state-of-the-art results on the AffectNet and Google Facial Expression Comparison datasets.
Prior Aided Streaming Network for Multi-task Affective Recognitionat the 2nd ABAW2 Competition
Jul 08, 2021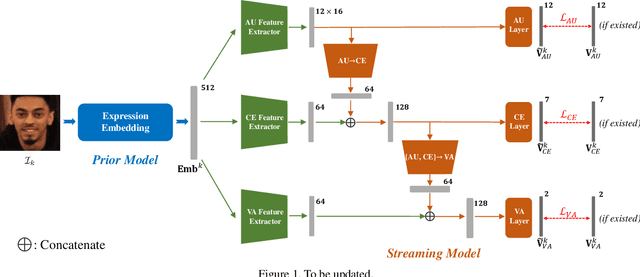
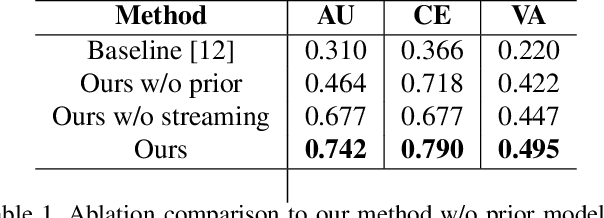
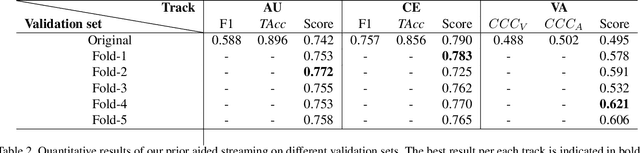
Automatic affective recognition has been an important research topic in human computer interaction (HCI) area. With recent development of deep learning techniques and large scale in-the-wild annotated datasets, the facial emotion analysis is now aimed at challenges in the real world settings. In this paper, we introduce our submission to the 2nd Affective Behavior Analysis in-the-wild (ABAW2) Competition. In dealing with different emotion representations, including Categorical Emotions (CE), Action Units (AU), and Valence Arousal (VA), we propose a multi-task streaming network by a heuristic that the three representations are intrinsically associated with each other. Besides, we leverage an advanced facial expression embedding as prior knowledge, which is capable of capturing identity-invariant expression features while preserving the expression similarities, to aid the down-streaming recognition tasks. The extensive quantitative evaluations as well as ablation studies on the Aff-Wild2 dataset prove the effectiveness of our proposed prior aided streaming network approach.