 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
LOMo: Latent Ordinal Model for Facial Analysis in Videos
Apr 06, 2016
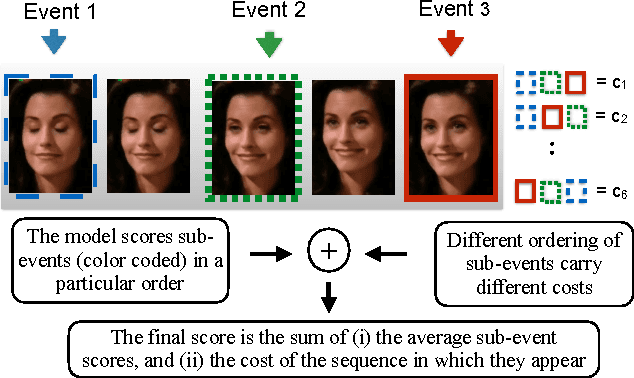
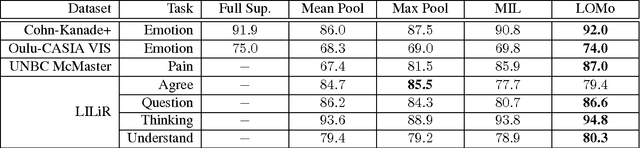
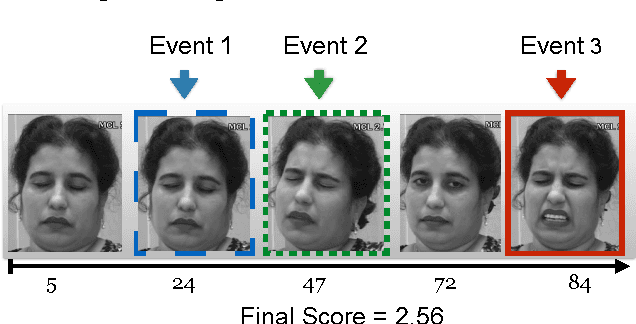
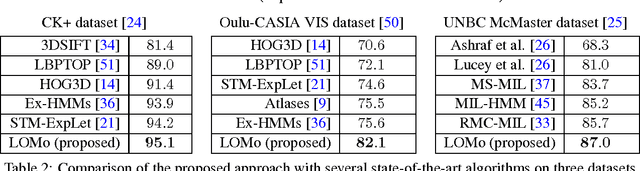
We study the problem of facial analysis in videos. We propose a novel weakly supervised learning method that models the video event (expression, pain etc.) as a sequence of automatically mined, discriminative sub-events (eg. onset and offset phase for smile, brow lower and cheek raise for pain). The proposed model is inspired by the recent works on Multiple Instance Learning and latent SVM/HCRF- it extends such frameworks to model the ordinal or temporal aspect in the videos, approximately. We obtain consistent improvements over relevant competitive baselines on four challenging and publicly available video based facial analysis datasets for prediction of expression, clinical pain and intent in dyadic conversations. In combination with complimentary features, we report state-of-the-art results on these datasets.
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Mar 04, 2022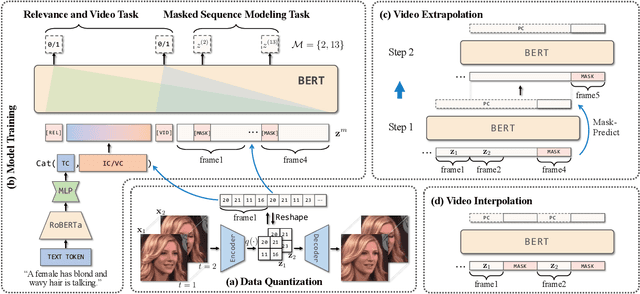
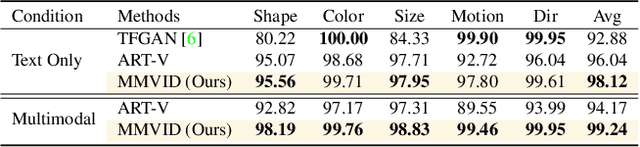


Most methods for conditional video synthesis use a single modality as the condition. This comes with major limitations. For example, it is problematic for a model conditioned on an image to generate a specific motion trajectory desired by the user since there is no means to provide motion information. Conversely, language information can describe the desired motion, while not precisely defining the content of the video. This work presents a multimodal video generation framework that benefits from text and images provided jointly or separately. We leverage the recent progress in quantized representations for videos and apply a bidirectional transformer with multiple modalities as inputs to predict a discrete video representation. To improve video quality and consistency, we propose a new video token trained with self-learning and an improved mask-prediction algorithm for sampling video tokens. We introduce text augmentation to improve the robustness of the textual representation and diversity of generated videos. Our framework can incorporate various visual modalities, such as segmentation masks, drawings, and partially occluded images. It can generate much longer sequences than the one used for training. In addition, our model can extract visual information as suggested by the text prompt, e.g., "an object in image one is moving northeast", and generate corresponding videos. We run evaluations on three public datasets and a newly collected dataset labeled with facial attributes, achieving state-of-the-art generation results on all four.
Local Learning with Deep and Handcrafted Features for Facial Expression Recognition
Sep 25, 2018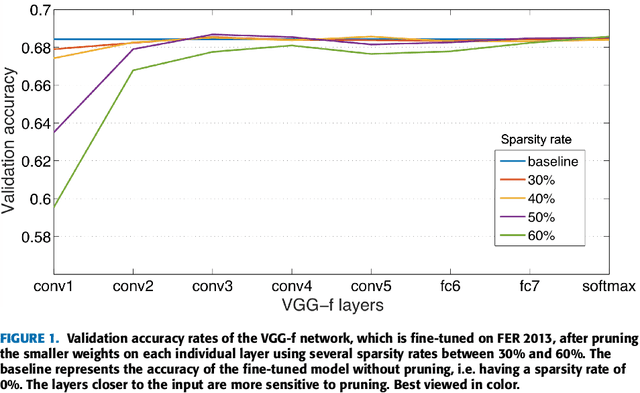
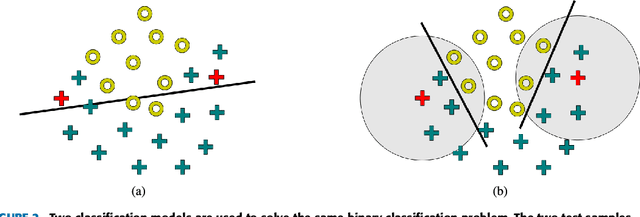
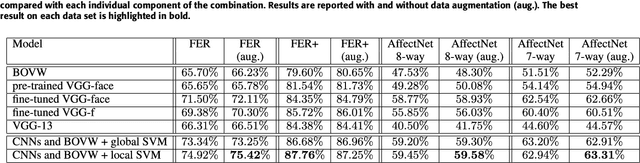
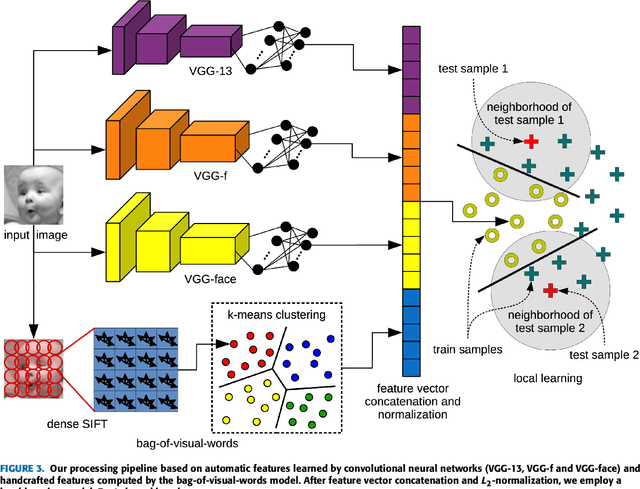
We present an approach that combines automatic features learned by convolutional neural networks (CNN) and handcrafted features computed by the bag-of-visual-words (BOVW) model in order to achieve state-of-the-art results in facial expression recognition. To obtain automatic features, we experiment with multiple CNN architectures, pre-trained models and training procedures, e.g. Dense-Sparse-Dense. After fusing the two types of features, we employ a local learning framework to predict the class label for each test image. The local learning framework is based on three steps. First, a k-nearest neighbors model is applied for selecting the nearest training samples for an input test image. Second, a one-versus-all Support Vector Machines (SVM) classifier is trained on the selected training samples. Finally, the SVM classifier is used for predicting the class label only for the test image it was trained for. Although we used local learning in combination with handcrafted features in our previous work, to the best of our knowledge, local learning has never been employed in combination with deep features. The experiments on the 2013 Facial Expression Recognition (FER) Challenge data set and the FER+ data set demonstrate that our approach achieves state-of-the-art results. With a top accuracy of 75.42% on the FER 2013 data set and 87.76% on the FER+ data set, we surpass all competition by more than 2% on both data sets.
Rethinking Portrait Matting with Privacy Preserving
Mar 31, 2022


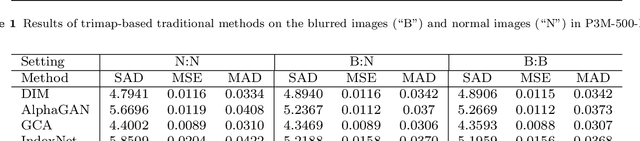
Recently, there has been an increasing concern about the privacy issue raised by using personally identifiable information in machine learning. However, previous portrait matting methods were all based on identifiable portrait images. To fill the gap, we present P3M-10k in this paper, which is the first large-scale anonymized benchmark for Privacy-Preserving Portrait Matting (P3M). P3M-10k consists of 10,000 high-resolution face-blurred portrait images along with high-quality alpha mattes. We systematically evaluate both trimap-free and trimap-based matting methods on P3M-10k and find that existing matting methods show different generalization abilities under the privacy preserving training setting, i.e., training only on face-blurred images while testing on arbitrary images. Based on the gained insights, we propose a unified matting model named P3M-Net consisting of three carefully designed integration modules that can perform privacy-insensitive semantic perception and detail-reserved matting simultaneously. We further design multiple variants of P3M-Net with different CNN and transformer backbones and identify the difference in their generalization abilities. To further mitigate this issue, we devise a simple yet effective Copy and Paste strategy (P3M-CP) that can borrow facial information from public celebrity images without privacy concerns and direct the network to reacquire the face context at both data and feature levels. P3M-CP only brings a few additional computations during training, while enabling the matting model to process both face-blurred and normal images without extra effort during inference. Extensive experiments on P3M-10k demonstrate the superiority of P3M-Net over state-of-the-art methods and the effectiveness of P3M-CP in improving the generalization ability of P3M-Net, implying a great significance of P3M for future research and real-world applications.
Towards End-to-End Neural Face Authentication in the Wild -- Quantifying and Compensating for Directional Lighting Effects
Apr 08, 2021
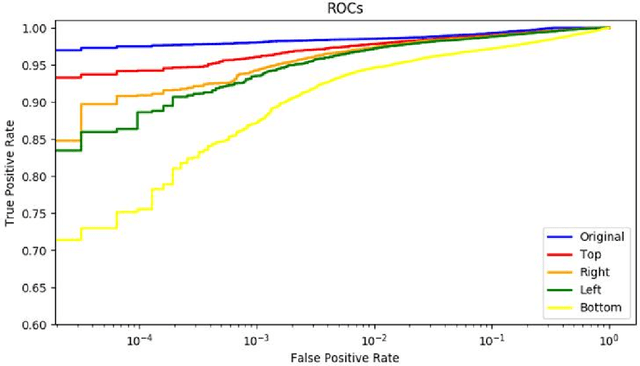

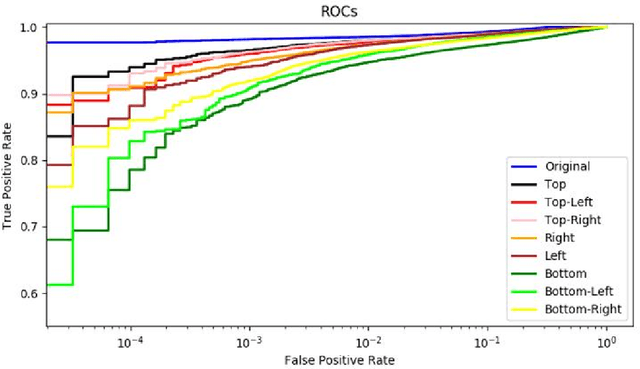
The recent availability of low-power neural accelerator hardware, combined with improvements in end-to-end neural facial recognition algorithms provides, enabling technology for on-device facial authentication. The present research work examines the effects of directional lighting on a State-of-Art(SoA) neural face recognizer. A synthetic re-lighting technique is used to augment data samples due to the lack of public data-sets with sufficient directional lighting variations. Top lighting and its variants (top-left, top-right) are found to have minimal effect on accuracy, while bottom-left or bottom-right directional lighting has the most pronounced effects. Following the fine-tuning of network weights, the face recognition model is shown to achieve close to the original Receiver Operating Characteristic curve (ROC)performance across all lighting conditions and demonstrates an ability to generalize beyond the lighting augmentations used in the fine-tuning data-set. This work shows that an SoA neural face recognition model can be tuned to compensate for directional lighting effects, removing the need for a pre-processing step before applying facial recognition.
Meta Transfer Learning for Facial Emotion Recognition
May 25, 2018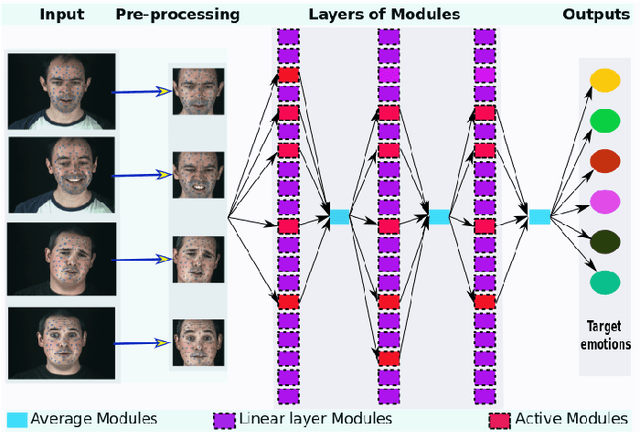
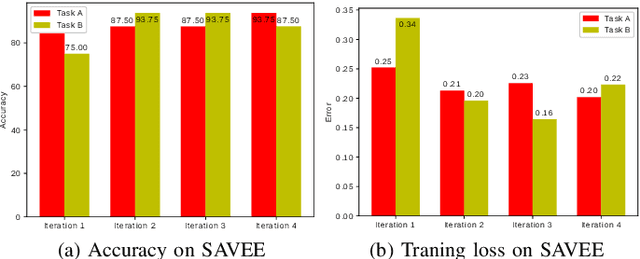
The use of deep learning techniques for automatic facial expression recognition has recently attracted great interest but developed models are still unable to generalize well due to the lack of large emotion datasets for deep learning. To overcome this problem, in this paper, we propose utilizing a novel transfer learning approach relying on PathNet and investigate how knowledge can be accumulated within a given dataset and how the knowledge captured from one emotion dataset can be transferred into another in order to improve the overall performance. To evaluate the robustness of our system, we have conducted various sets of experiments on two emotion datasets: SAVEE and eNTERFACE. The experimental results demonstrate that our proposed system leads to improvement in performance of emotion recognition and performs significantly better than the recent state-of-the-art schemes adopting fine-\ tuning/pre-trained approaches.
Look into Facial Expression Domain Adaptation: Adversarial Graph Learning and A Fair Evaluation Benchmark
Aug 27, 2020

To address the problem of data inconsistencies among different facial expression recognition (FER) datasets, many cross-domain FER methods (CD-FERs) have been extensively devised in recent years. Although each declares to achieve superior performance, fair comparisons are lacking due to the inconsistent choices of the source/target datasets and feature extractors. In this work, we first analyze the performance effect caused by these inconsistent choices, and then re-implement some well-performing CD-FER and recently published domain adaptation algorithms. We ensure that all these algorithms adopt the same source datasets and feature extractors for fair CD-FER evaluations. We find that most of the current leading algorithms use adversarial learning to learn holistic domain-invariant features to mitigate domain shifts. However, these algorithms ignore local features, which are more transferable across different datasets and carry more detailed content for fine-grained adaptation. To address these issues, we integrate graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation by developing a novel adversarial graph representation adaptation (AGRA) framework. Specifically, it first builds two graphs to correlate holistic and local regions within each domain and across different domains, respectively. Then, it extracts holistic-local features from the input image and uses learnable per-class statistical distributions to initialize the corresponding graph nodes. Finally, two stacked graph convolution networks (GCNs) are adopted to propagate holistic-local features within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. We conduct extensive and fair evaluations on several popular benchmarks and show that the proposed AGRA framework outperforms previous state-of-the-art methods.
Face Anonymization by Manipulating Decoupled Identity Representation
May 24, 2021

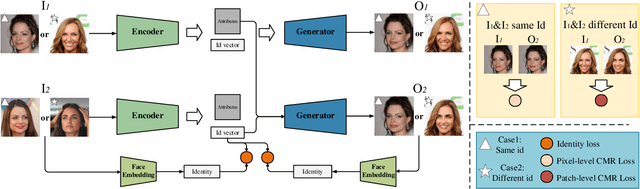

Privacy protection on human biological information has drawn increasing attention in recent years, among which face anonymization plays an importance role. We propose a novel approach which protects identity information of facial images from leakage with slightest modification. Specifically, we disentangle identity representation from other facial attributes leveraging the power of generative adversarial networks trained on a conditional multi-scale reconstruction (CMR) loss and an identity loss. We evaulate the disentangle ability of our model, and propose an effective method for identity anonymization, namely Anonymous Identity Generation (AIG), to reach the goal of face anonymization meanwhile maintaining similarity to the original image as much as possible. Quantitative and qualitative results demonstrate our method's superiority compared with the SOTAs on both visual quality and anonymization success rate.
Grammatical facial expression recognition using customized deep neural network architecture
Nov 16, 2017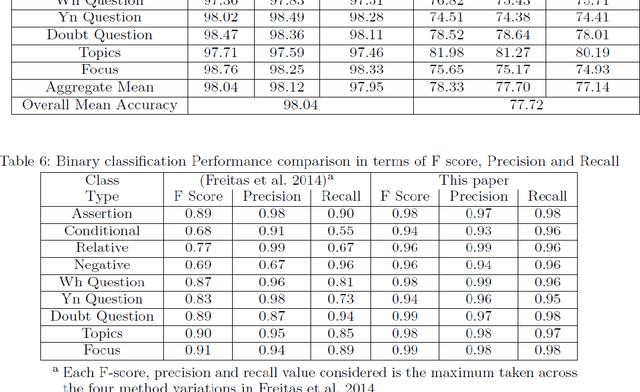
This paper proposes to expand the visual understanding capacity of computers by helping it recognize human sign language more efficiently. This is carried out through recognition of facial expressions, which accompany the hand signs used in this language. This paper specially focuses on the popular Brazilian sign language (LIBRAS). While classifying different hand signs into their respective word meanings has already seen much literature dedicated to it, the emotions or intention with which the words are expressed haven't primarily been taken into consideration. As from our normal human experience, words expressed with different emotions or mood can have completely different meanings attached to it. Lending computers the ability of classifying these facial expressions, can help add another level of deep understanding of what the deaf person exactly wants to communicate. The proposed idea is implemented through a deep neural network having a customized architecture. This helps learning specific patterns in individual expressions much better as compared to a generic approach. With an overall accuracy of 98.04%, the implemented deep network performs excellently well and thus is fit to be used in any given practical scenario.
Prior Aided Streaming Network for Multi-task Affective Recognitionat the 2nd ABAW2 Competition
Jul 08, 2021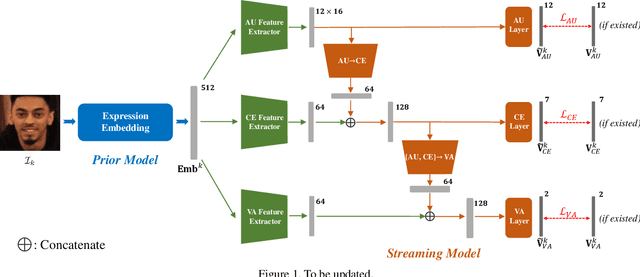
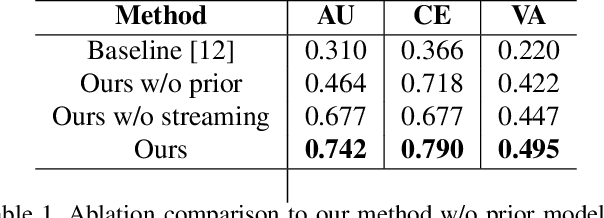
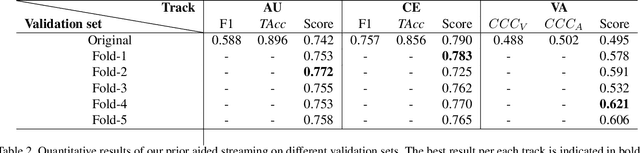
Automatic affective recognition has been an important research topic in human computer interaction (HCI) area. With recent development of deep learning techniques and large scale in-the-wild annotated datasets, the facial emotion analysis is now aimed at challenges in the real world settings. In this paper, we introduce our submission to the 2nd Affective Behavior Analysis in-the-wild (ABAW2) Competition. In dealing with different emotion representations, including Categorical Emotions (CE), Action Units (AU), and Valence Arousal (VA), we propose a multi-task streaming network by a heuristic that the three representations are intrinsically associated with each other. Besides, we leverage an advanced facial expression embedding as prior knowledge, which is capable of capturing identity-invariant expression features while preserving the expression similarities, to aid the down-streaming recognition tasks. The extensive quantitative evaluations as well as ablation studies on the Aff-Wild2 dataset prove the effectiveness of our proposed prior aided streaming network approach.