 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Probabilistic Regression with Huber Distributions
Nov 19, 2021
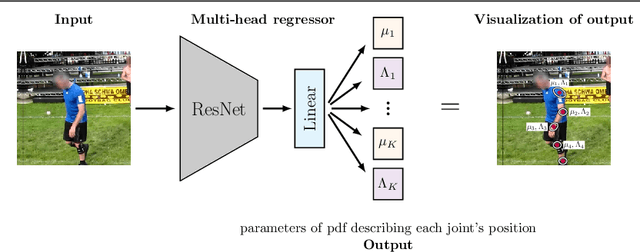
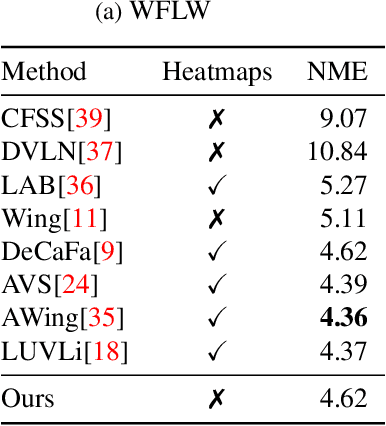
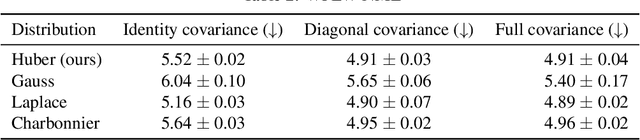

In this paper we describe a probabilistic method for estimating the position of an object along with its covariance matrix using neural networks. Our method is designed to be robust to outliers, have bounded gradients with respect to the network outputs, among other desirable properties. To achieve this we introduce a novel probability distribution inspired by the Huber loss. We also introduce a new way to parameterize positive definite matrices to ensure invariance to the choice of orientation for the coordinate system we regress over. We evaluate our method on popular body pose and facial landmark datasets and get performance on par or exceeding the performance of non-heatmap methods. Our code is available at github.com/Davmo049/Public_prob_regression_with_huber_distributions
Head2HeadFS: Video-based Head Reenactment with Few-shot Learning
Mar 30, 2021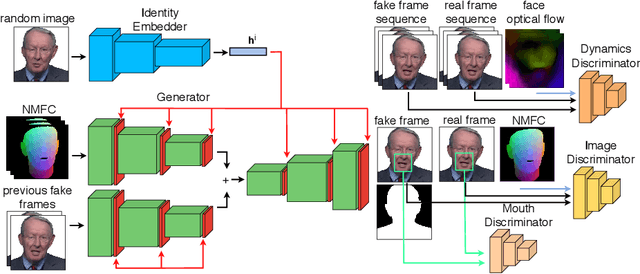
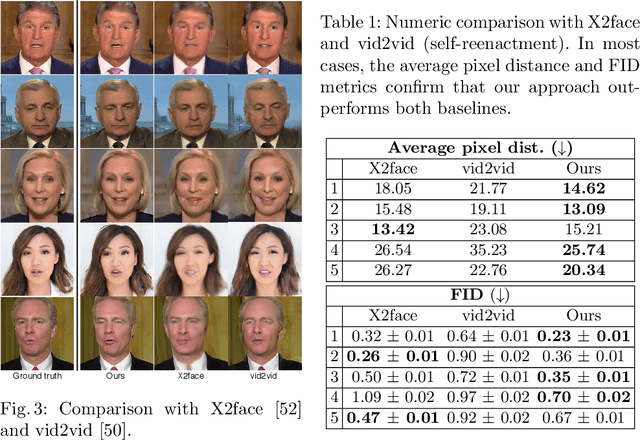


Over the past years, a substantial amount of work has been done on the problem of facial reenactment, with the solutions coming mainly from the graphics community. Head reenactment is an even more challenging task, which aims at transferring not only the facial expression, but also the entire head pose from a source person to a target. Current approaches either train person-specific systems, or use facial landmarks to model human heads, a representation that might transfer unwanted identity attributes from the source to the target. We propose head2headFS, a novel easily adaptable pipeline for head reenactment. We condition synthesis of the target person on dense 3D face shape information from the source, which enables high quality expression and pose transfer. Our video-based rendering network is fine-tuned under a few-shot learning strategy, using only a few samples. This allows for fast adaptation of a generic generator trained on a multiple-person dataset, into a person-specific one.
Action Units Recognition Using Improved Pairwise Deep Architecture
Jul 08, 2021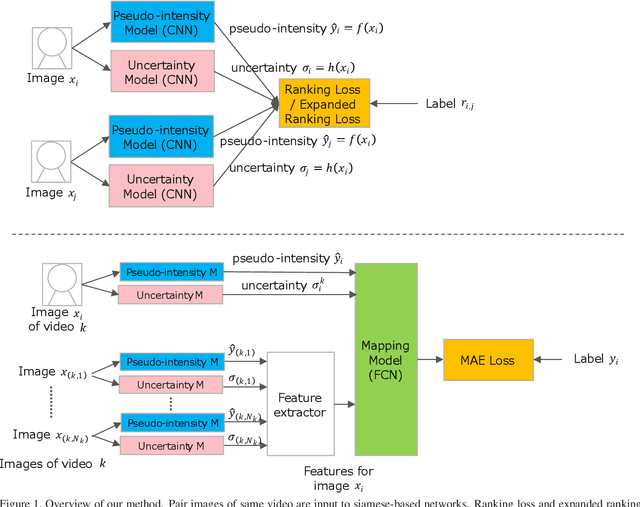
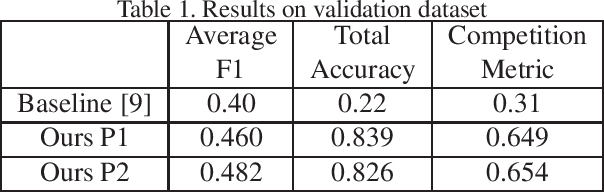
Facial Action Units (AUs) represent a set of facial muscular activities and various combinations of AUs can represent a wide range of emotions. AU recognition is often used in many applications, including marketing, healthcare, education, and so forth. Although a lot of studies have developed various methods to improve recognition accuracy, it still remains a major challenge for AU recognition. In the Affective Behavior Analysis in-the-wild (ABAW) 2020 competition, we proposed a new automatic Action Units (AUs) recognition method using a pairwise deep architecture to derive the Pseudo-Intensities of each AU and then convert them into predicted intensities. This year, we introduced a new technique to last year's framework to further reduce AU recognition errors due to temporary face occlusion such as hands on face or large face orientation. We obtained a score of 0.65 in the validation data set for this year's competition.
Real-time RGBD-based Extended Body Pose Estimation
Mar 05, 2021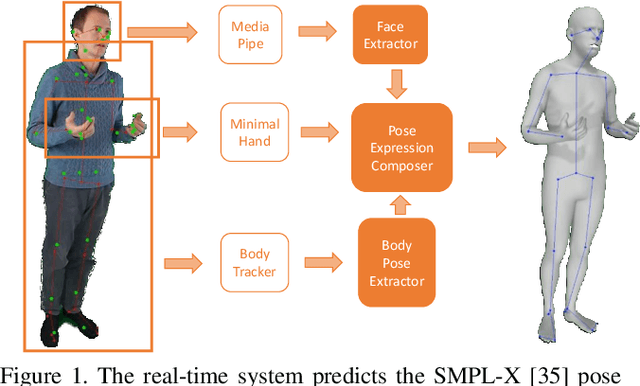
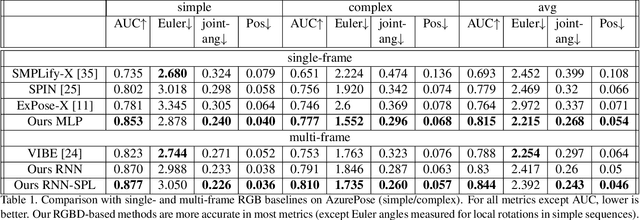
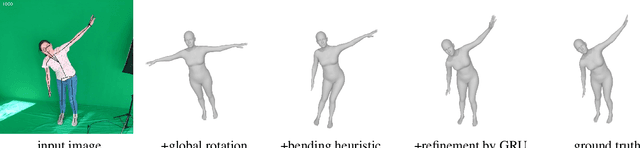
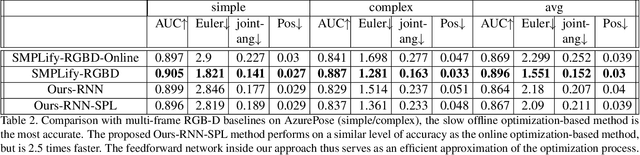
We present a system for real-time RGBD-based estimation of 3D human pose. We use parametric 3D deformable human mesh model (SMPL-X) as a representation and focus on the real-time estimation of parameters for the body pose, hands pose and facial expression from Kinect Azure RGB-D camera. We train estimators of body pose and facial expression parameters. Both estimators use previously published landmark extractors as input and custom annotated datasets for supervision, while hand pose is estimated directly by a previously published method. We combine the predictions of those estimators into a temporally-smooth human pose. We train the facial expression extractor on a large talking face dataset, which we annotate with facial expression parameters. For the body pose we collect and annotate a dataset of 56 people captured from a rig of 5 Kinect Azure RGB-D cameras and use it together with a large motion capture AMASS dataset. Our RGB-D body pose model outperforms the state-of-the-art RGB-only methods and works on the same level of accuracy compared to a slower RGB-D optimization-based solution. The combined system runs at 30 FPS on a server with a single GPU. The code will be available at https://saic-violet.github.io/rgbd-kinect-pose
Directing DNNs Attention for Facial Attribution Classification using Gradient-weighted Class Activation Mapping
May 02, 2019
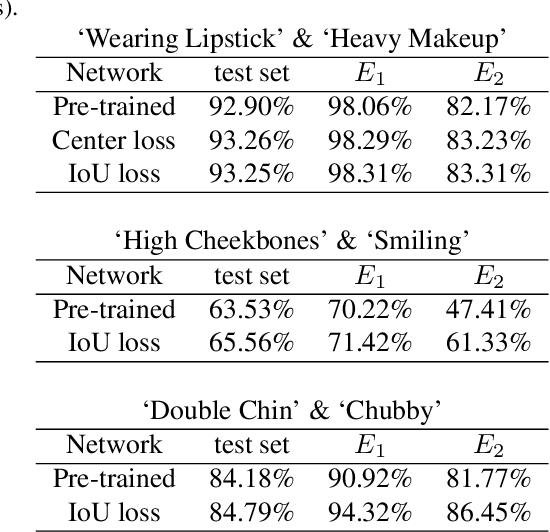
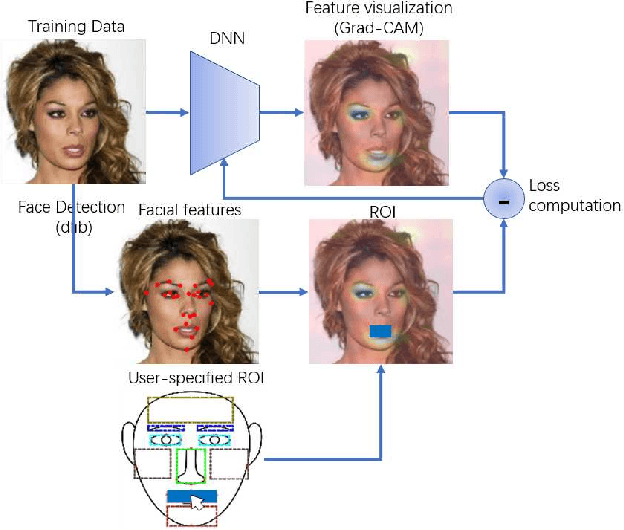
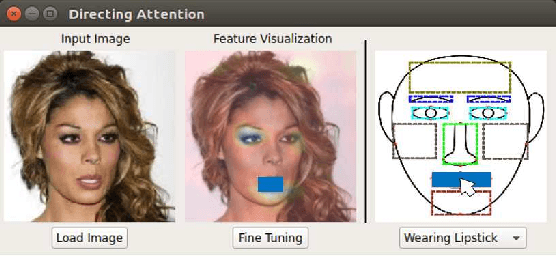
Deep neural networks (DNNs) have a high accuracy on image classification tasks. However, DNNs trained by such dataset with co-occurrence bias may rely on wrong features while making decisions for classification. It will greatly affect the transferability of pre-trained DNNs. In this paper, we propose an interactive method to direct classifiers paying attentions to the regions that are manually specified by the users, in order to mitigate the influence of co-occurrence bias. We test on CelebA dataset, the pre-trained AlexNet is fine-tuned to focus on the specific facial attributes based on the results of Grad-CAM.
StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022
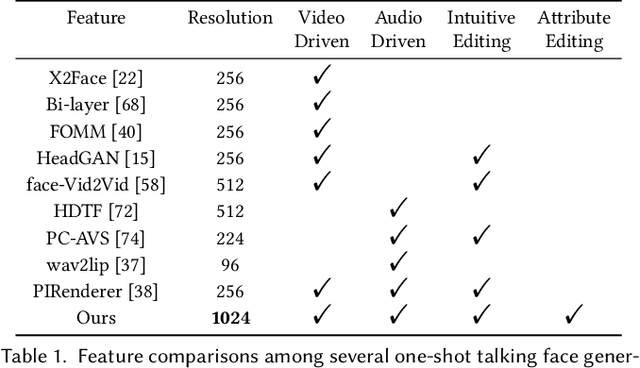

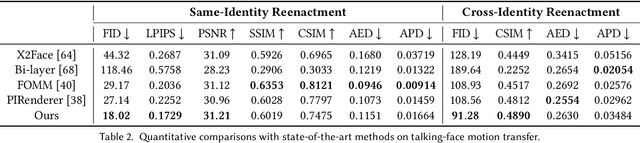
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.
FaceForensics++: Learning to Detect Manipulated Facial Images
Jan 25, 2019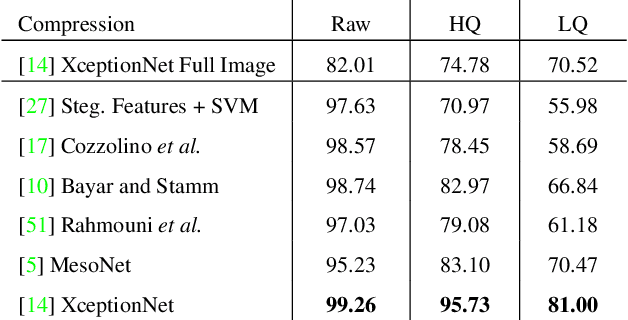

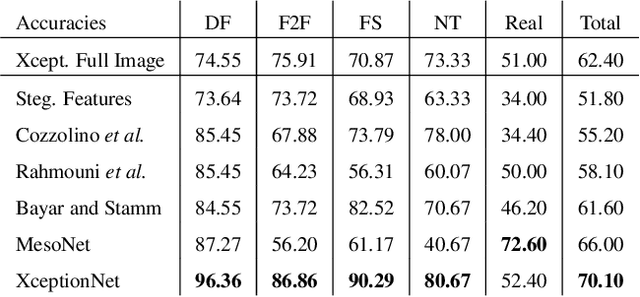
The rapid progress in synthetic image generation and manipulation has now come to a point where it raises significant concerns on the implication on the society. At best, this leads to a loss of trust in digital content, but it might even cause further harm by spreading false information and the creation of fake news. In this paper, we examine the realism of state-of-the-art image manipulations, and how difficult it is to detect them - either automatically or by humans. In particular, we focus on DeepFakes, Face2Face, and FaceSwap as prominent representatives for facial manipulations. We create more than half a million manipulated images respectively for each approach. The resulting publicly available dataset is at least an order of magnitude larger than comparable alternatives and it enables us to train data-driven forgery detectors in a supervised fashion. We show that the use of additional domain specific knowledge improves forgery detection to an unprecedented accuracy, even in the presence of strong compression. By conducting a series of thorough experiments, we quantify the differences between classical approaches, novel deep learning approaches, and the performance of human observers.
Facial Expression Recognition Using Sparse Gaussian Conditional Random Field
Nov 06, 2015

The analysis of expression and facial Action Units (AUs) detection are very important tasks in fields of computer vision and Human Computer Interaction (HCI) due to the wide range of applications in human life. Many works has been done during the past few years which has their own advantages and disadvantages. In this work we present a new model based on Gaussian Conditional Random Field. We solve our objective problem using ADMM and we show how well the proposed model works. We train and test our work on two facial expression datasets, CK+ and RU-FACS. Experimental evaluation shows that our proposed approach outperform state of the art expression recognition.
Fast Localization of Facial Landmark Points
Jan 20, 2015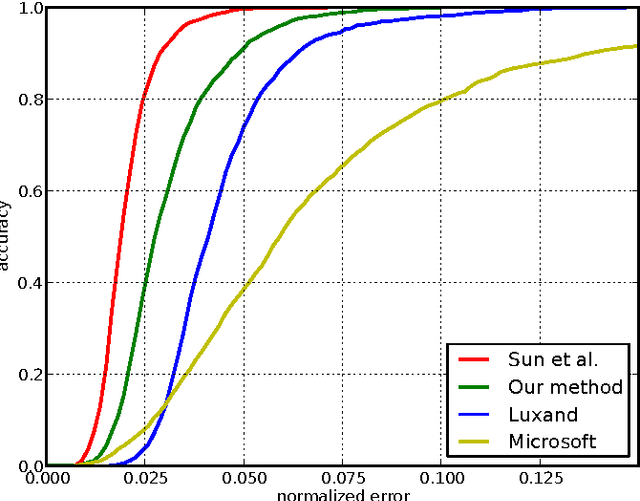
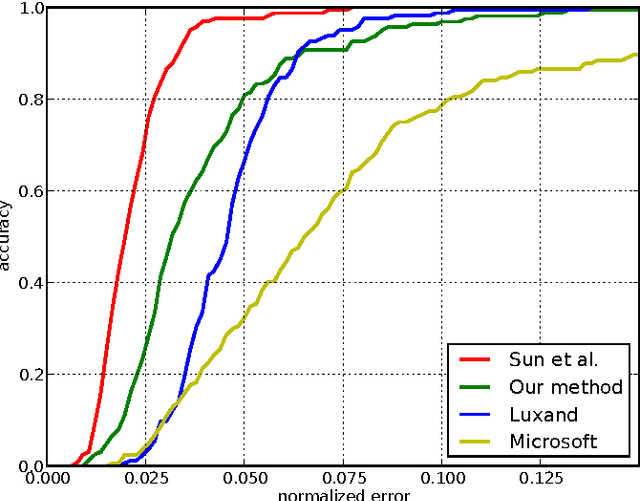
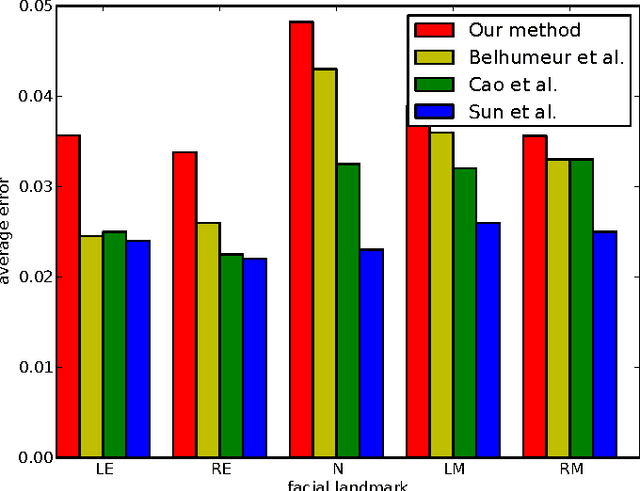
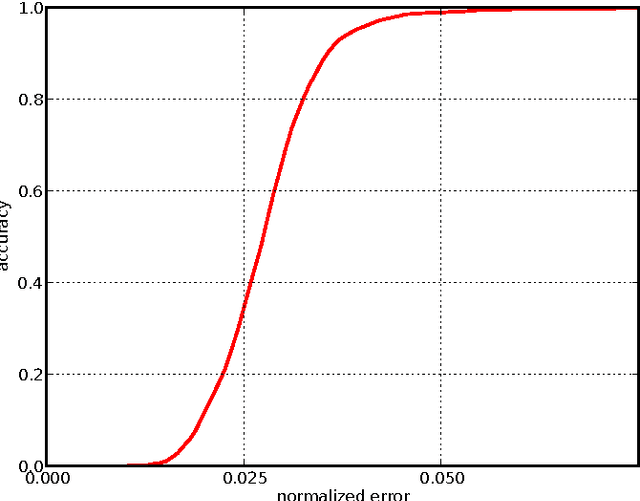
Localization of salient facial landmark points, such as eye corners or the tip of the nose, is still considered a challenging computer vision problem despite recent efforts. This is especially evident in unconstrained environments, i.e., in the presence of background clutter and large head pose variations. Most methods that achieve state-of-the-art accuracy are slow, and, thus, have limited applications. We describe a method that can accurately estimate the positions of relevant facial landmarks in real-time even on hardware with limited processing power, such as mobile devices. This is achieved with a sequence of estimators based on ensembles of regression trees. The trees use simple pixel intensity comparisons in their internal nodes and this makes them able to process image regions very fast. We test the developed system on several publicly available datasets and analyse its processing speed on various devices. Experimental results show that our method has practical value.
Landmarks-assisted Collaborative Deep Framework for Automatic 4D Facial Expression Recognition
Oct 11, 2019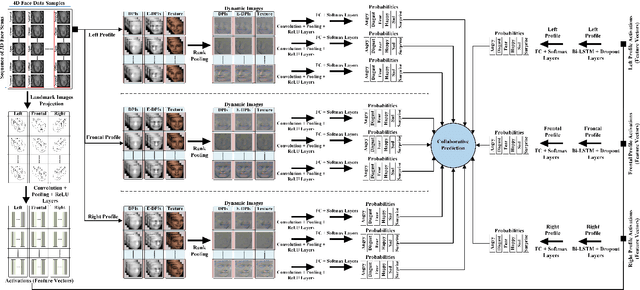
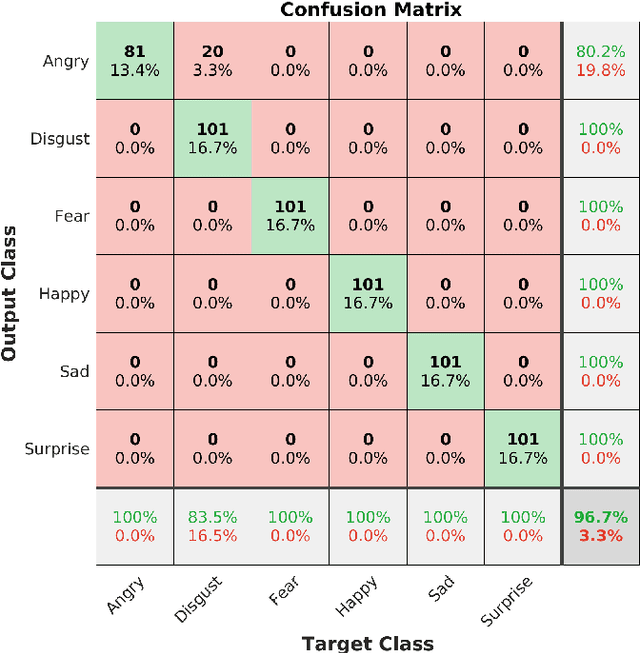
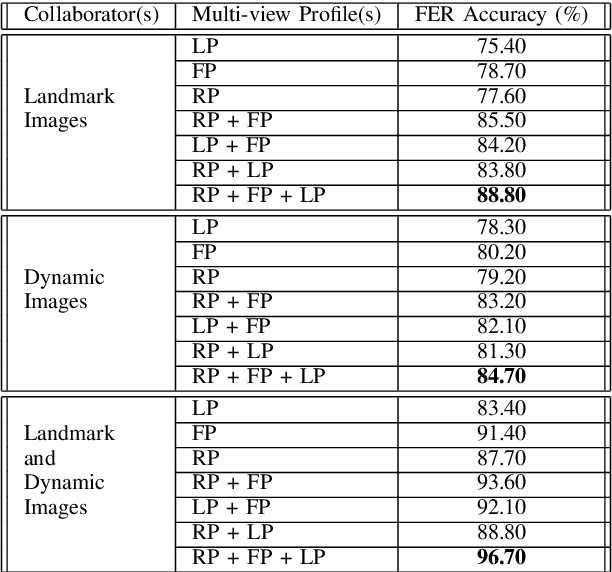
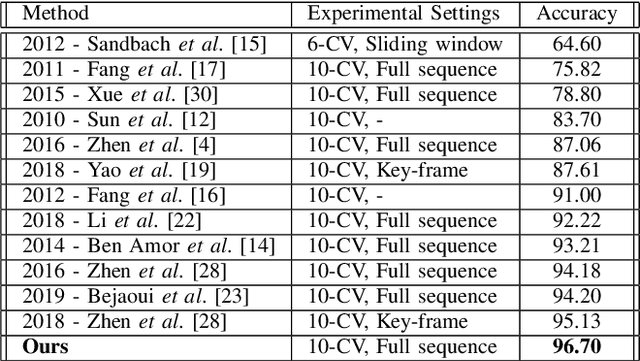
We propose a novel landmarks-assisted collaborative end-to-end deep framework for automatic 4D FER. Using 4D face scan data, we calculate its various geometrical images, and afterwards use rank pooling to generate their dynamic images encapsulating important facial muscle movements over time. As well, the given 3D landmarks are projected on a 2D plane as binary images and convolutional layers are used to extract sequences of feature vectors for every landmark video. During the training stage, the dynamic images are used to train an end-to-end deep network, while the feature vectors of landmark images are used train a long short-term memory (LSTM) network. The finally improved set of expression predictions are obtained when the dynamic and landmark images collaborate over multi-views using the proposed deep framework. Performance results obtained from extensive experimentation on the widely-adopted BU-4DFE database under globally used settings prove that our proposed collaborative framework outperforms the state-of-the-art 4D FER methods and reach a promising classification accuracy of 96.7% demonstrating its effectiveness.