 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Emotion recognition techniques with rule based and machine learning approaches
Feb 28, 2021

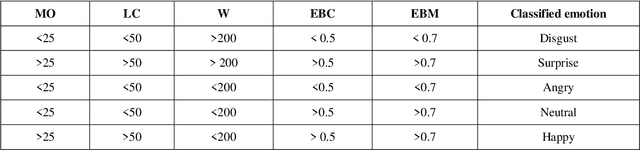
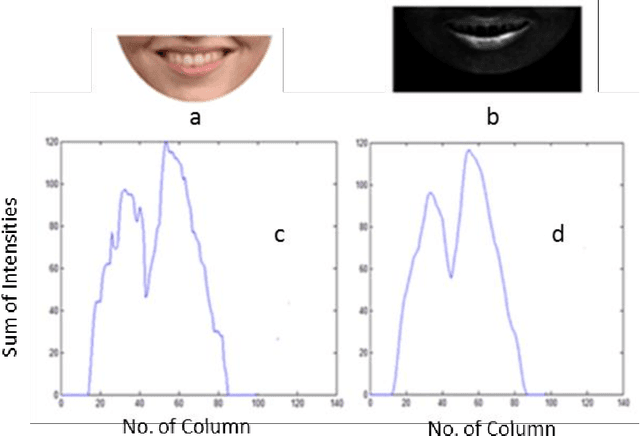
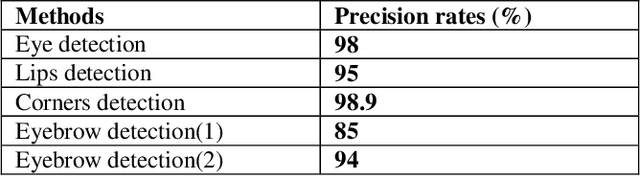
Emotion recognition using digital image processing is a multifarious task because facial emotions depend on warped facial features as well as on gender, age, and culture. Furthermore, there are several factors such as varied illumination and intricate settings that increase complexity in facial emotion recognition. In this paper, we used four salient facial features, Eyebrows, Mouth opening, Mouth corners, and Forehead wrinkles to identifying emotions from normal, occluded and partially-occluded images. We have employed rule-based approach and developed new methods to extract aforementioned facial features similar to local bit patterns using novel techniques. We propose new methods to detect eye location, eyebrow contraction, and mouth corners. For eye detection, the proposed methods are Enhancement of Cr Red (ECrR) and Suppression of Cr Blue (SCrB) which results in 98% accuracy. Additionally, for eyebrow contraction detection, we propose two techniques (1) Morphological Gradient Image Intensity (MGII) and (2) Degree of Curvature Line (DCL). Additionally, we present a new method for mouth corners detection. For classification purpose, we use an individual classifier, majority voting (MV) and weighted majority voting (WMV) methods which mimic Human Emotions Sensitivity (HES). These methods are straightforward to implement, improve the accuracy of results, and work best for emotion recognition using partially occluded images. It is ascertained from the results that our method outperforms previous approaches. Overall accuracy rates are around 94%. The processing time on one image using processor core i5 is ~0.12 sec.
A Fusion-based Gender Recognition Method Using Facial Images
Nov 17, 2017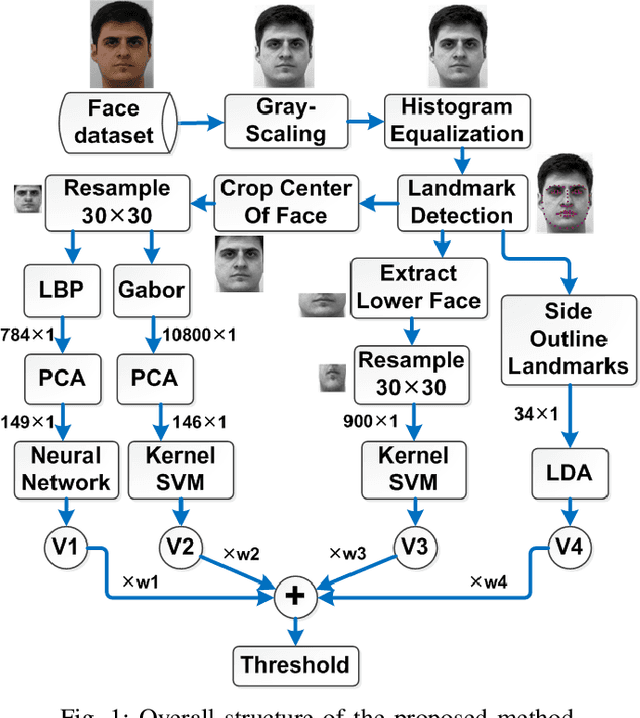


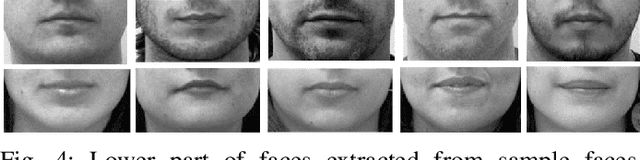
This paper proposes a fusion-based gender recognition method which uses facial images as input. Firstly, this paper utilizes pre-processing and a landmark detection method in order to find the important landmarks of faces. Thereafter, four different frameworks are proposed which are inspired by state-of-the-art gender recognition systems. The first framework extracts features using Local Binary Pattern (LBP) and Principal Component Analysis (PCA) and uses back propagation neural network. The second framework uses Gabor filters, PCA, and kernel Support Vector Machine (SVM). The third framework uses lower part of faces as input and classifies them using kernel SVM. The fourth framework uses Linear Discriminant Analysis (LDA) in order to classify the side outline landmarks of faces. Finally, the four decisions of frameworks are fused using weighted voting. This paper takes advantage of both texture and geometrical information, the two dominant types of information in facial gender recognition. Experimental results show the power and effectiveness of the proposed method. This method obtains recognition rate of 94% for neutral faces of FEI face dataset, which is equal to state-of-the-art rate for this dataset.
Customized Facial Constant Positive Air Pressure (CPAP) Masks
Sep 22, 2016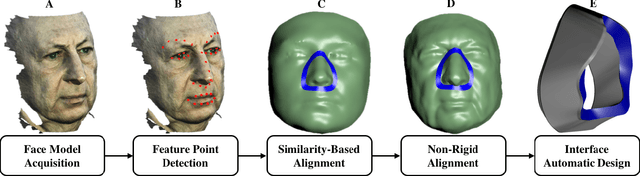
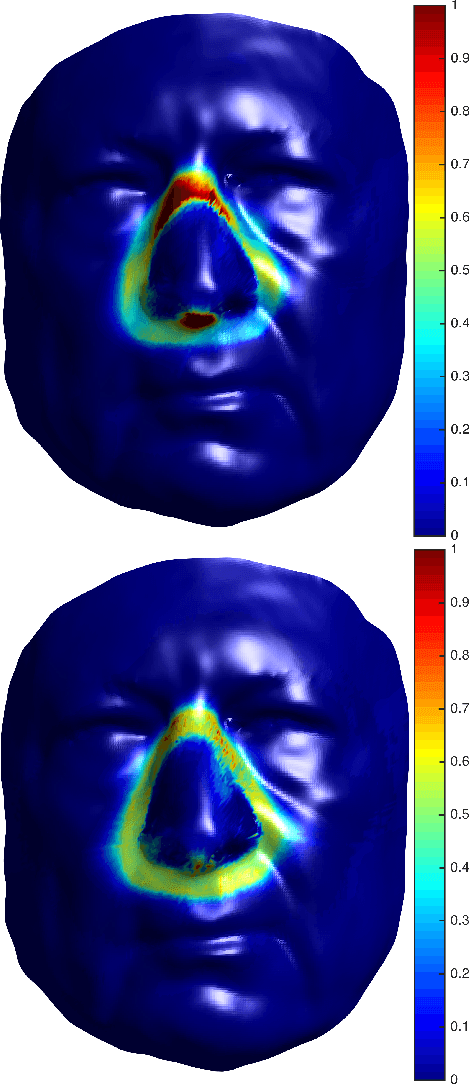
Sleep apnea is a syndrome that is characterized by sudden breathing halts while sleeping. One of the common treatments involves wearing a mask that delivers continuous air flow into the nostrils so as to maintain a steady air pressure. These masks are designed for an average facial model and are often difficult to adjust due to poor fit to the actual patient. The incompatibility is characterized by gaps between the mask and the face, which deteriorates the impermeability of the mask and leads to air leakage. We suggest a fully automatic approach for designing a personalized nasal mask interface using a facial depth scan. The interfaces generated by the proposed method accurately fit the geometry of the scanned face, and are easy to manufacture. The proposed method utilizes cheap commodity depth sensors and 3D printing technologies to efficiently design and manufacture customized masks for patients suffering from sleep apnea.
Face sketch to photo translation using generative adversarial networks
Oct 23, 2021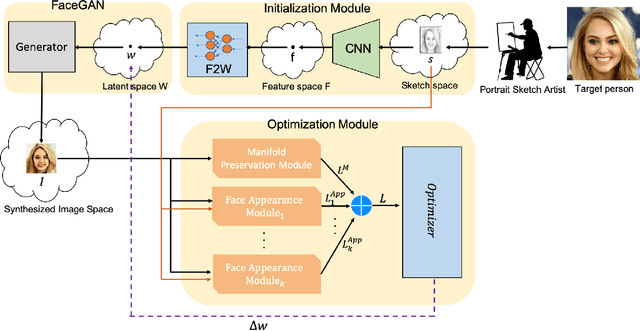
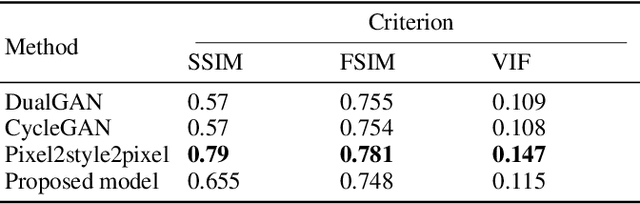
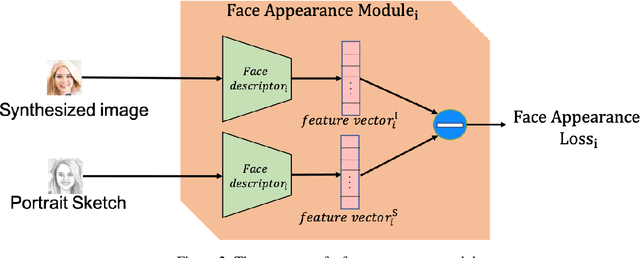
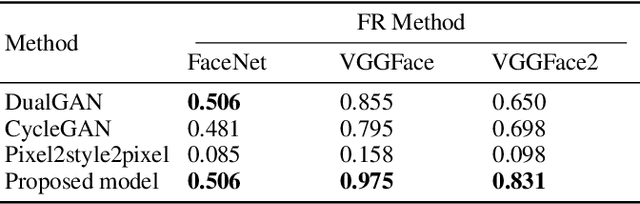
Translating face sketches to photo-realistic faces is an interesting and essential task in many applications like law enforcement and the digital entertainment industry. One of the most important challenges of this task is the inherent differences between the sketch and the real image such as the lack of color and details of the skin tissue in the sketch. With the advent of adversarial generative models, an increasing number of methods have been proposed for sketch-to-image synthesis. However, these models still suffer from limitations such as the large number of paired data required for training, the low resolution of the produced images, or the unrealistic appearance of the generated images. In this paper, we propose a method for converting an input facial sketch to a colorful photo without the need for any paired dataset. To do so, we use a pre-trained face photo generating model to synthesize high-quality natural face photos and employ an optimization procedure to keep high-fidelity to the input sketch. We train a network to map the facial features extracted from the input sketch to a vector in the latent space of the face generating model. Also, we study different optimization criteria and compare the results of the proposed model with those of the state-of-the-art models quantitatively and qualitatively. The proposed model achieved 0.655 in the SSIM index and 97.59% rank-1 face recognition rate with higher quality of the produced images.
DeepStroke: An Efficient Stroke Screening Framework for Emergency Rooms with Multimodal Adversarial Deep Learning
Sep 24, 2021
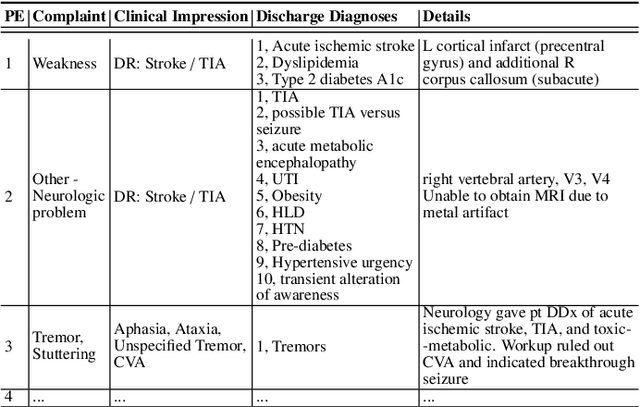
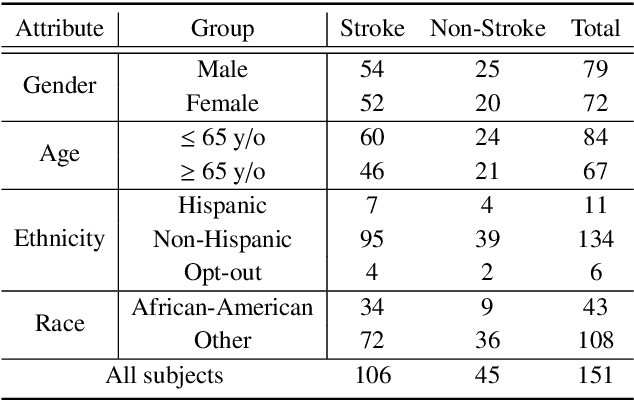
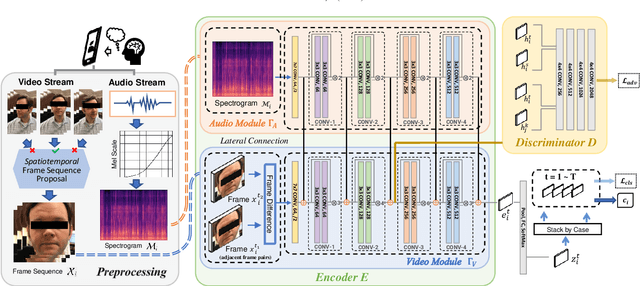
In an emergency room (ER) setting, the diagnosis of stroke is a common challenge. Due to excessive execution time and cost, an MRI scan is usually not available in the ER. Clinical tests are commonly referred to in stroke screening, but neurologists may not be immediately available. We propose a novel multimodal deep learning framework, DeepStroke, to achieve computer-aided stroke presence assessment by recognizing the patterns of facial motion incoordination and speech inability for patients with suspicion of stroke in an acute setting. Our proposed DeepStroke takes video data for local facial paralysis detection and audio data for global speech disorder analysis. It further leverages a multi-modal lateral fusion to combine the low- and high-level features and provides mutual regularization for joint training. A novel adversarial training loss is also introduced to obtain identity-independent and stroke-discriminative features. Experiments on our video-audio dataset with actual ER patients show that the proposed approach outperforms state-of-the-art models and achieves better performance than ER doctors, attaining a 6.60% higher sensitivity and maintaining 4.62% higher accuracy when specificity is aligned. Meanwhile, each assessment can be completed in less than 6 minutes, demonstrating the framework's great potential for clinical implementation.
Gendered Differences in Face Recognition Accuracy Explained by Hairstyles, Makeup, and Facial Morphology
Dec 29, 2021
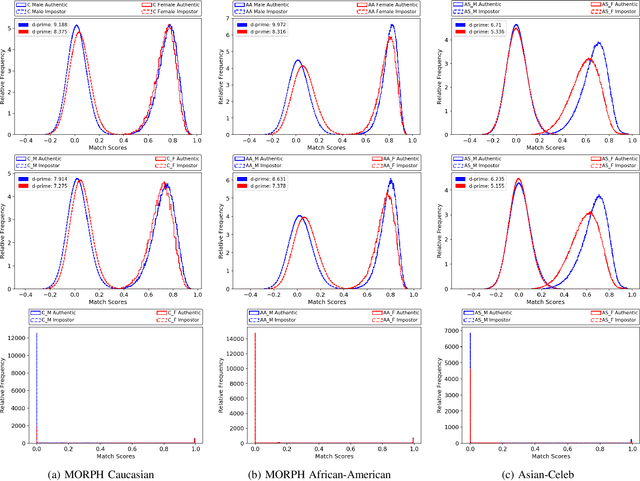
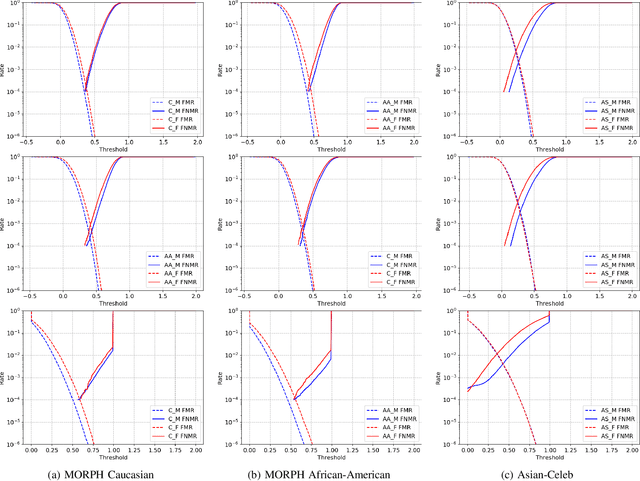
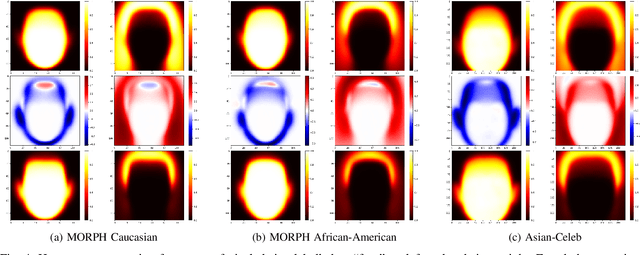
Media reports have accused face recognition of being ''biased'', ''sexist'' and ''racist''. There is consensus in the research literature that face recognition accuracy is lower for females, who often have both a higher false match rate and a higher false non-match rate. However, there is little published research aimed at identifying the cause of lower accuracy for females. For instance, the 2019 Face Recognition Vendor Test that documents lower female accuracy across a broad range of algorithms and datasets also lists ''Analyze cause and effect'' under the heading ''What we did not do''. We present the first experimental analysis to identify major causes of lower face recognition accuracy for females on datasets where previous research has observed this result. Controlling for equal amount of visible face in the test images mitigates the apparent higher false non-match rate for females. Additional analysis shows that makeup-balanced datasets further improves females to achieve lower false non-match rates. Finally, a clustering experiment suggests that images of two different females are inherently more similar than of two different males, potentially accounting for a difference in false match rates.
Transformer-S2A: Robust and Efficient Speech-to-Animation
Nov 18, 2021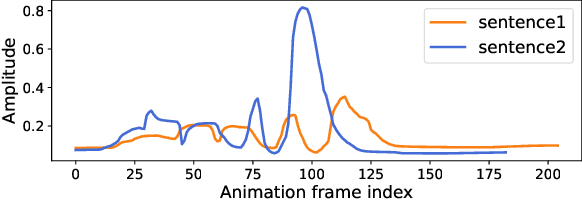
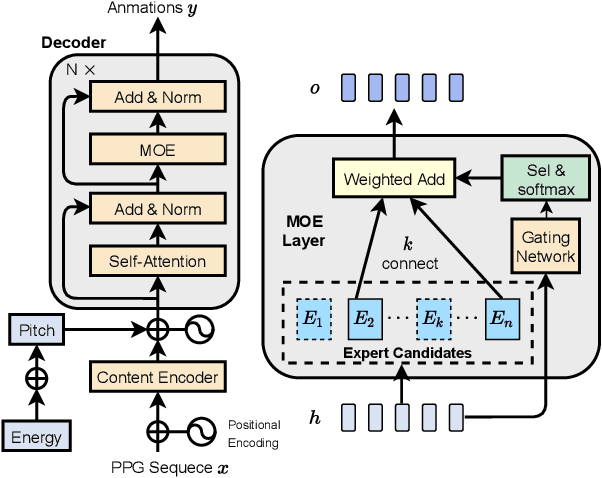
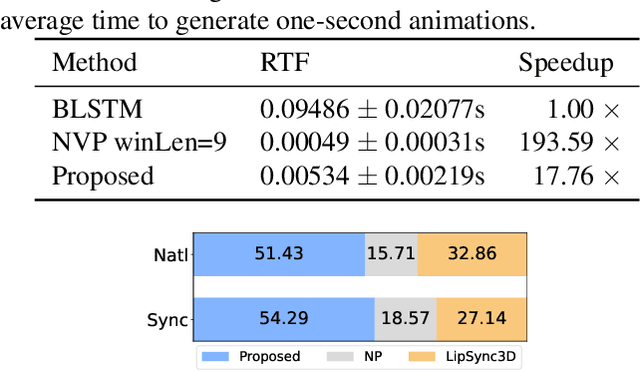

We propose a novel robust and efficient Speech-to-Animation (S2A) approach for synchronized facial animation generation in human-computer interaction. Compared with conventional approaches, the proposed approach utilize phonetic posteriorgrams (PPGs) of spoken phonemes as input to ensure the cross-language and cross-speaker ability, and introduce corresponding prosody features (i.e. pitch and energy) to further enhance the expression of generated animation. Mixtureof-experts (MOE)-based Transformer is employed to better model contextual information while provide significant optimization on computation efficiency. Experiments demonstrate the effectiveness of the proposed approach on both objective and subjective evaluation with 17x inference speedup compared with the state-of-the-art approach.
ArcFace Knows the Gender, Too!
Dec 19, 2021
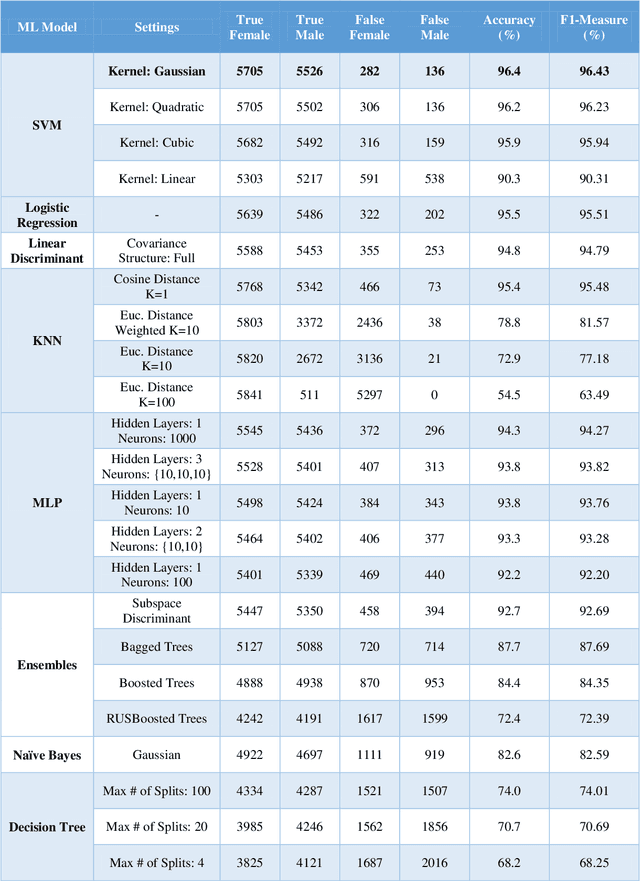
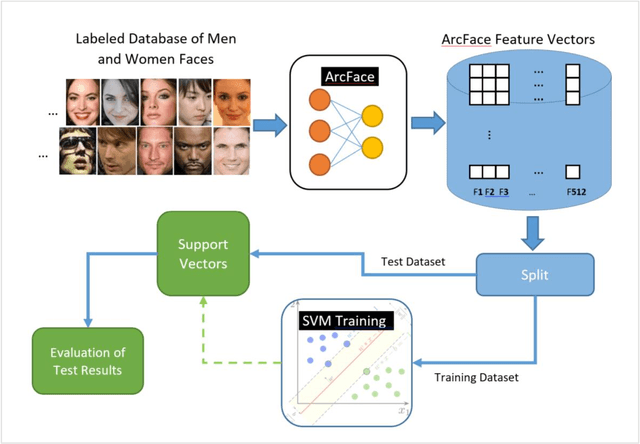
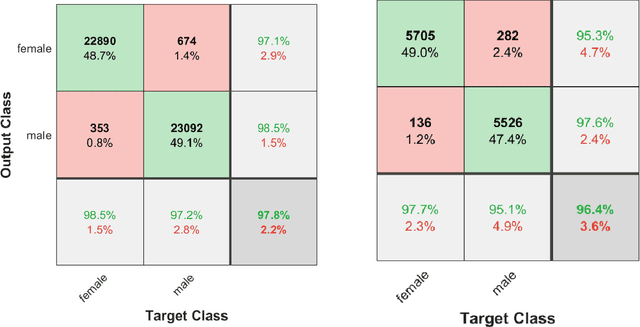
The main idea of this paper is that if a model can recognize a person, of course, it must be able to know the gender of that person, too. Therefore, instead of defining a new model for gender classification, this paper uses ArcFace features to determine gender, based on the facial features. A face image is given to ArcFace and 512 features are obtained for the face. Then, with the help of traditional machine learning models, gender is determined. Discriminative methods such as Support Vector Machine (SVM), Linear Discriminant, and Logistic Regression well demonstrate that the features extracted from the ArcFace create a remarkable distinction between the gender classes. Experiments on the Gender Classification Dataset show that SVM with Gaussian kernel is able to classify gender with an accuracy of 96.4% using ArcFace features.
Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors
Jul 04, 2018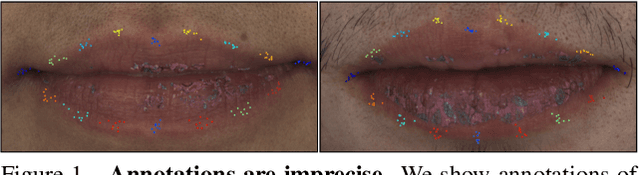
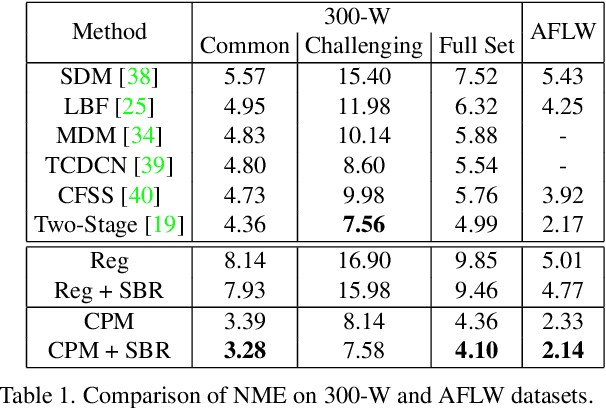
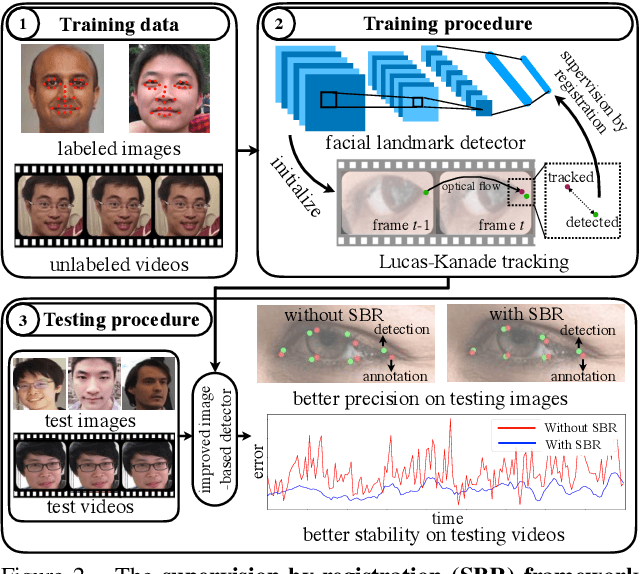
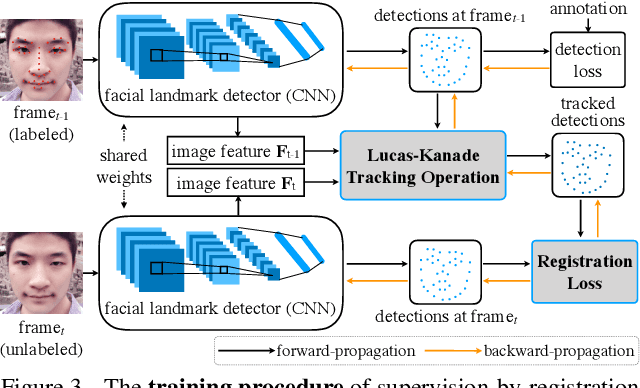
In this paper, we present supervision-by-registration, an unsupervised approach to improve the precision of facial landmark detectors on both images and video. Our key observation is that the detections of the same landmark in adjacent frames should be coherent with registration, i.e., optical flow. Interestingly, the coherency of optical flow is a source of supervision that does not require manual labeling, and can be leveraged during detector training. For example, we can enforce in the training loss function that a detected landmark at frame$_{t-1}$ followed by optical flow tracking from frame$_{t-1}$ to frame$_t$ should coincide with the location of the detection at frame$_t$. Essentially, supervision-by-registration augments the training loss function with a registration loss, thus training the detector to have output that is not only close to the annotations in labeled images, but also consistent with registration on large amounts of unlabeled videos. End-to-end training with the registration loss is made possible by a differentiable Lucas-Kanade operation, which computes optical flow registration in the forward pass, and back-propagates gradients that encourage temporal coherency in the detector. The output of our method is a more precise image-based facial landmark detector, which can be applied to single images or video. With supervision-by-registration, we demonstrate (1) improvements in facial landmark detection on both images (300W, ALFW) and video (300VW, Youtube-Celebrities), and (2) significant reduction of jittering in video detections.
Towards Privacy-Preserving Affect Recognition: A Two-Level Deep Learning Architecture
Nov 14, 2021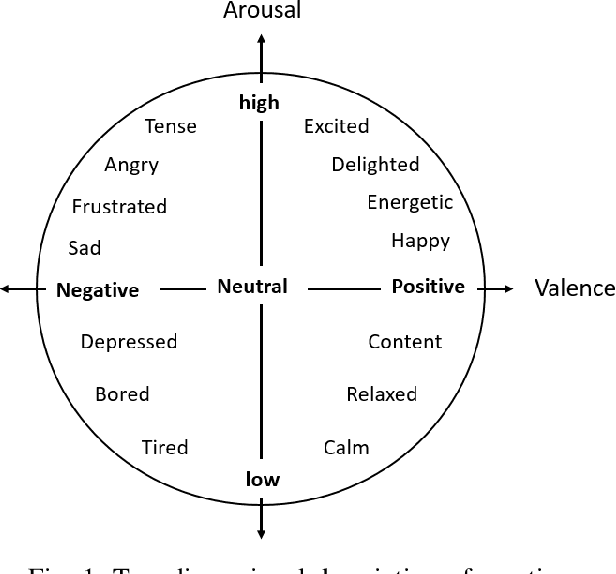
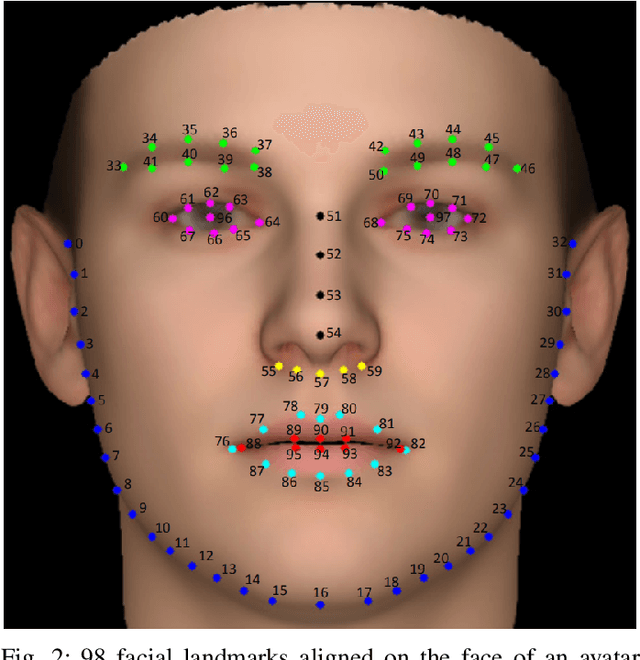
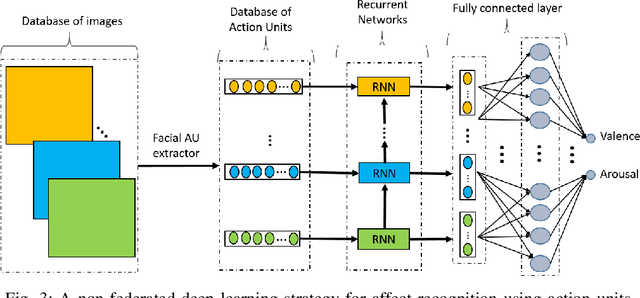
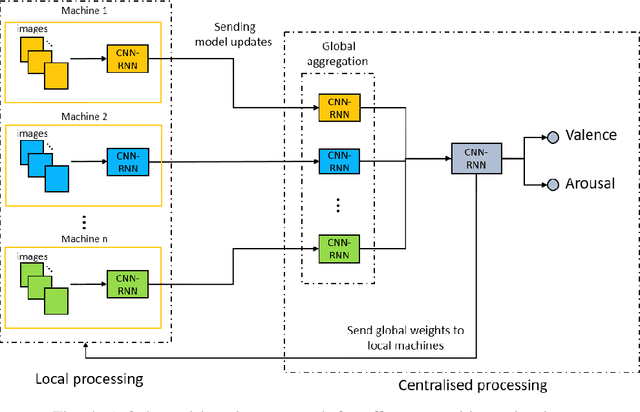
Automatically understanding and recognising human affective states using images and computer vision can improve human-computer and human-robot interaction. However, privacy has become an issue of great concern, as the identities of people used to train affective models can be exposed in the process. For instance, malicious individuals could exploit images from users and assume their identities. In addition, affect recognition using images can lead to discriminatory and algorithmic bias, as certain information such as race, gender, and age could be assumed based on facial features. Possible solutions to protect the privacy of users and avoid misuse of their identities are to: (1) extract anonymised facial features, namely action units (AU) from a database of images, discard the images and use AUs for processing and training, and (2) federated learning (FL) i.e. process raw images in users' local machines (local processing) and send the locally trained models to the main processing machine for aggregation (central processing). In this paper, we propose a two-level deep learning architecture for affect recognition that uses AUs in level 1 and FL in level 2 to protect users' identities. The architecture consists of recurrent neural networks to capture the temporal relationships amongst the features and predict valence and arousal affective states. In our experiments, we evaluate the performance of our privacy-preserving architecture using different variations of recurrent neural networks on RECOLA, a comprehensive multimodal affective database. Our results show state-of-the-art performance of $0.426$ for valence and $0.401$ for arousal using the Concordance Correlation Coefficient evaluation metric, demonstrating the feasibility of developing models for affect recognition that are both accurate and ensure privacy.