 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Masked Face Recognition Challenge: The InsightFace Track Report
Aug 18, 2021
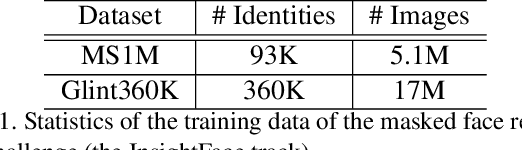

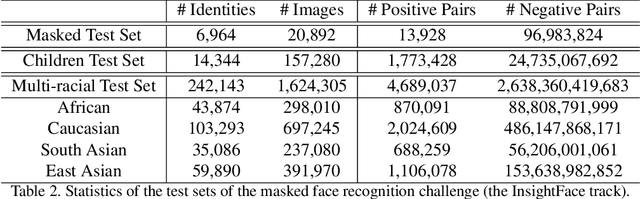
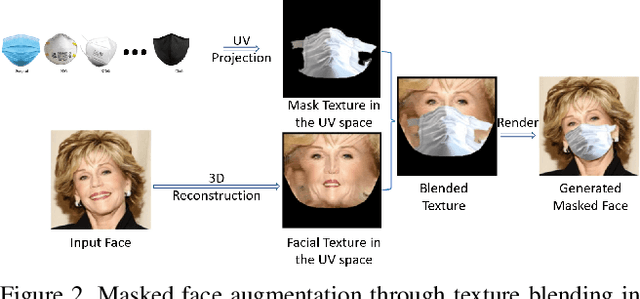
During the COVID-19 coronavirus epidemic, almost everyone wears a facial mask, which poses a huge challenge to deep face recognition. In this workshop, we organize Masked Face Recognition (MFR) challenge and focus on bench-marking deep face recognition methods under the existence of facial masks. In the MFR challenge, there are two main tracks: the InsightFace track and the WebFace260M track. For the InsightFace track, we manually collect a large-scale masked face test set with 7K identities. In addition, we also collect a children test set including 14K identities and a multi-racial test set containing 242K identities. By using these three test sets, we build up an online model testing system, which can give a comprehensive evaluation of face recognition models. To avoid data privacy problems, no test image is released to the public. As the challenge is still under-going, we will keep on updating the top-ranked solutions as well as this report on the arxiv.
Facial UV Map Completion for Pose-invariant Face Recognition: A Novel Adversarial Approach based on Coupled Attention Residual UNets
Nov 02, 2020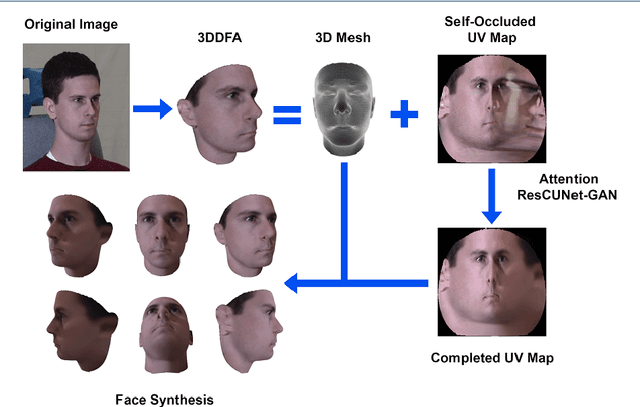

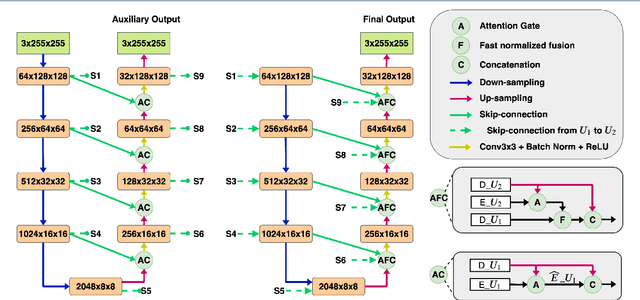
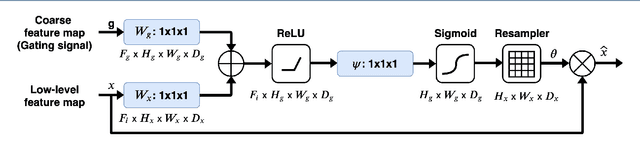
Pose-invariant face recognition refers to the problem of identifying or verifying a person by analyzing face images captured from different poses. This problem is challenging due to the large variation of pose, illumination and facial expression. A promising approach to deal with pose variation is to fulfill incomplete UV maps extracted from in-the-wild faces, then attach the completed UV map to a fitted 3D mesh and finally generate different 2D faces of arbitrary poses. The synthesized faces increase the pose variation for training deep face recognition models and reduce the pose discrepancy during the testing phase. In this paper, we propose a novel generative model called Attention ResCUNet-GAN to improve the UV map completion. We enhance the original UV-GAN by using a couple of U-Nets. Particularly, the skip connections within each U-Net are boosted by attention gates. Meanwhile, the features from two U-Nets are fused with trainable scalar weights. The experiments on the popular benchmarks, including Multi-PIE, LFW, CPLWF and CFP datasets, show that the proposed method yields superior performance compared to other existing methods.
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation
Jul 27, 2019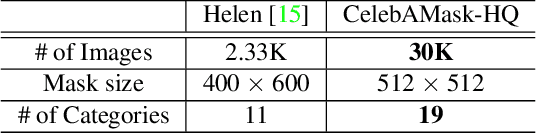
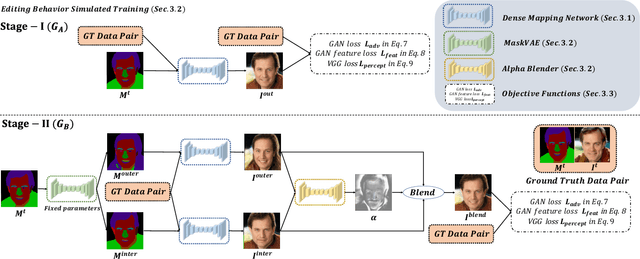
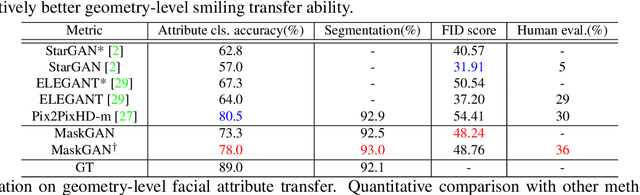
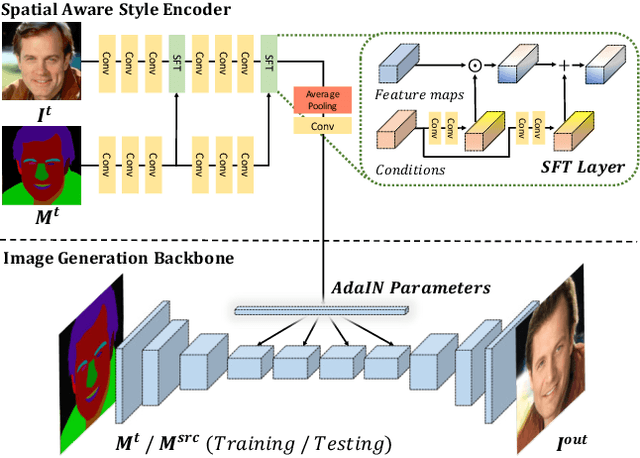
Facial image manipulation has achieved great progresses in recent years. However, previous methods either operate on a predefined set of face attributes or leave users little freedom to interactively manipulate images. To overcome these drawbacks, we propose a novel framework termed MaskGAN, enabling diverse and interactive face manipulation. Our key insight is that semantic masks serve as a suitable intermediate representation for flexible face manipulation with fidelity preservation. MaskGAN has two main components: 1) Dense Mapping Network, and 2) Editing Behavior Simulated Training. Specifically, Dense mapping network learns style mapping between a free-form user modified mask and a target image, enabling diverse generation results. Editing behavior simulated training models the user editing behavior on the source mask, making the overall framework more robust to various manipulated inputs. To facilitate extensive studies, we construct a large-scale high-resolution face dataset with fine-grained mask annotations named CelebAMask-HQ. MaskGAN is comprehensively evaluated on two challenging tasks: attribute transfer and style copy, demonstrating superior performance over other state-of-the-art methods. The code, models and dataset are available at \url{https://github.com/switchablenorms/CelebAMask-HQ}.
Baseline CNN structure analysis for facial expression recognition
Nov 14, 2016
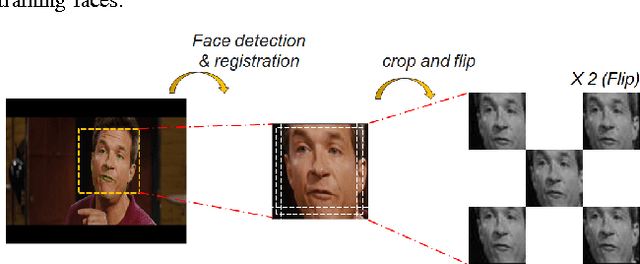
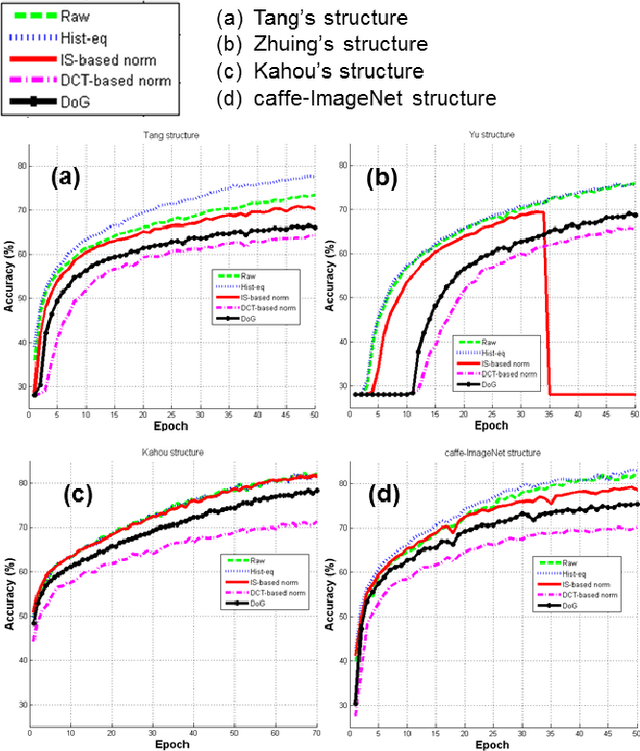
We present a baseline convolutional neural network (CNN) structure and image preprocessing methodology to improve facial expression recognition algorithm using CNN. To analyze the most efficient network structure, we investigated four network structures that are known to show good performance in facial expression recognition. Moreover, we also investigated the effect of input image preprocessing methods. Five types of data input (raw, histogram equalization, isotropic smoothing, diffusion-based normalization, difference of Gaussian) were tested, and the accuracy was compared. We trained 20 different CNN models (4 networks x 5 data input types) and verified the performance of each network with test images from five different databases. The experiment result showed that a three-layer structure consisting of a simple convolutional and a max pooling layer with histogram equalization image input was the most efficient. We describe the detailed training procedure and analyze the result of the test accuracy based on considerable observation.
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022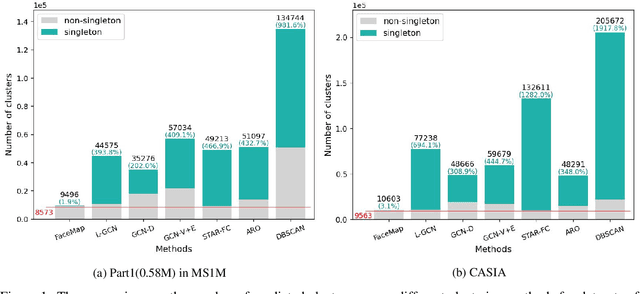
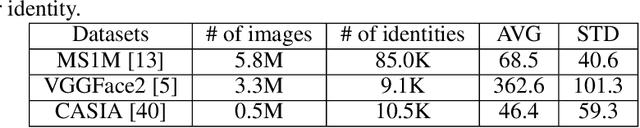
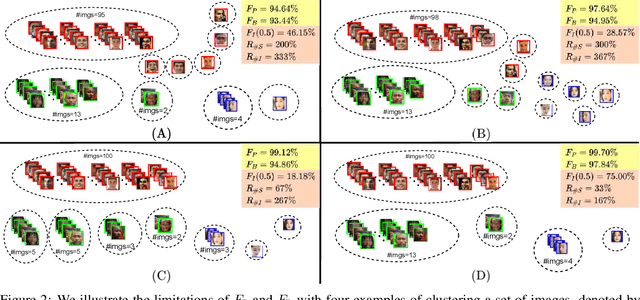

Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.
Unconstrained Facial Landmark Localization with Backbone-Branches Fully-Convolutional Networks
Apr 14, 2016
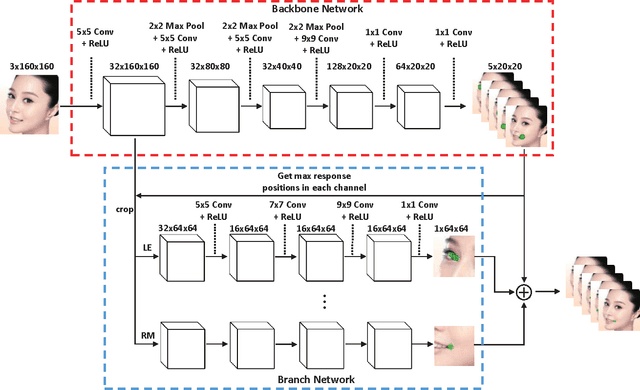
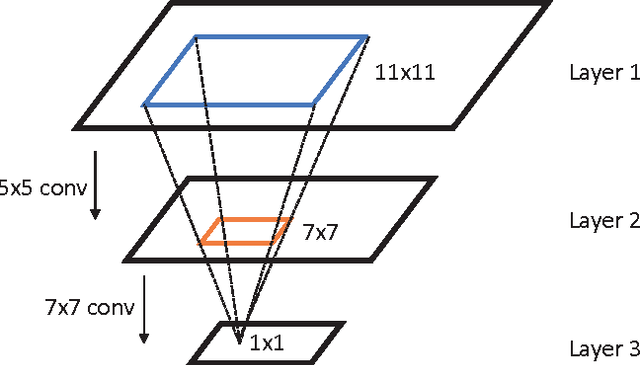

This paper investigates how to rapidly and accurately localize facial landmarks in unconstrained, cluttered environments rather than in the well segmented face images. We present a novel Backbone-Branches Fully-Convolutional Neural Network (BB-FCN), which produces facial landmark response maps directly from raw images without relying on pre-process or sliding window approaches. BB-FCN contains one backbone and a number of network branches with each corresponding to one landmark type, and it operates in a progressive manner. Specifically, the backbone roughly detects the locations of facial landmarks by taking the whole image as input, and the branches further refine the localizations based on a local observation from the backbone's intermediate feature map. Moreover, our backbone-branches architecture does not contain full-connection layers for location regression, leading to efficient learning and inference. Our extensive experiments show that our model achieves superior performances over other state-of-the-arts under both the constrained (i.e. with face regions) and the "in the wild" scenarios.
Differentially Private Generative Adversarial Networks with Model Inversion
Jan 10, 2022

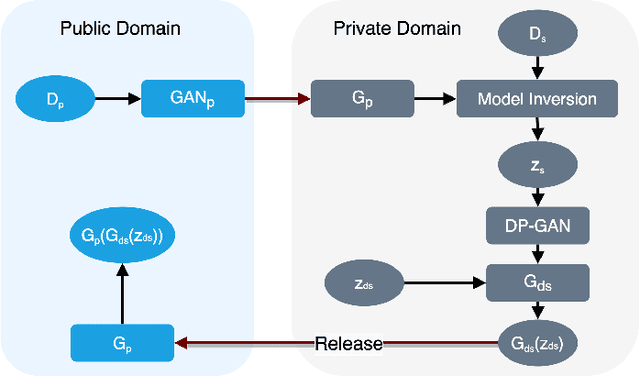
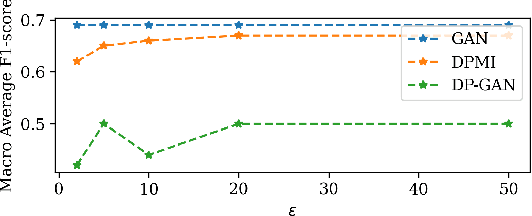
To protect sensitive data in training a Generative Adversarial Network (GAN), the standard approach is to use differentially private (DP) stochastic gradient descent method in which controlled noise is added to the gradients. The quality of the output synthetic samples can be adversely affected and the training of the network may not even converge in the presence of these noises. We propose Differentially Private Model Inversion (DPMI) method where the private data is first mapped to the latent space via a public generator, followed by a lower-dimensional DP-GAN with better convergent properties. Experimental results on standard datasets CIFAR10 and SVHN as well as on a facial landmark dataset for Autism screening show that our approach outperforms the standard DP-GAN method based on Inception Score, Fr\'echet Inception Distance, and classification accuracy under the same privacy guarantee.
RestoreFormer: High-Quality Blind Face Restoration From Undegraded Key-Value Pairs
Jan 17, 2022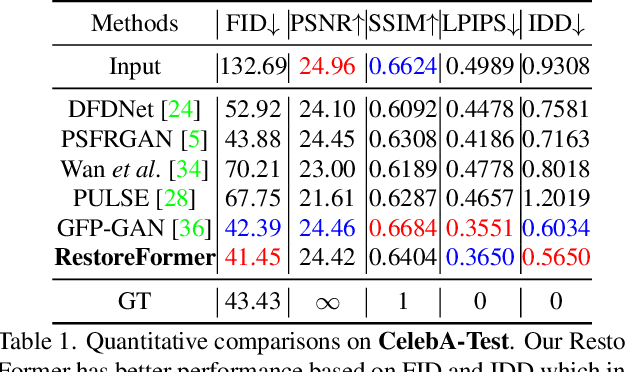
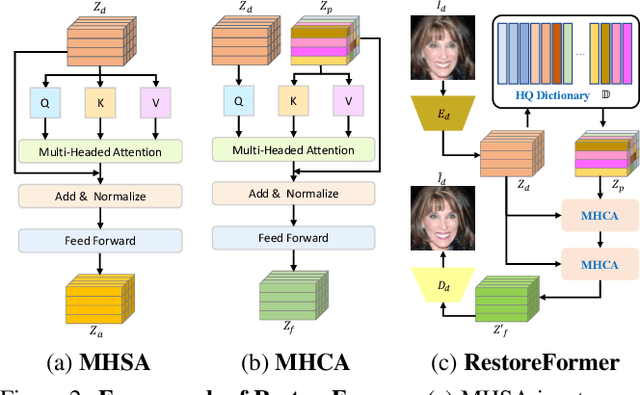
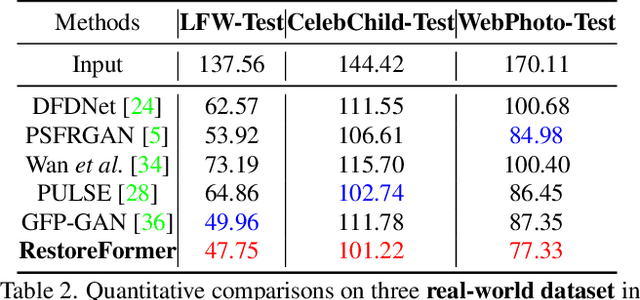
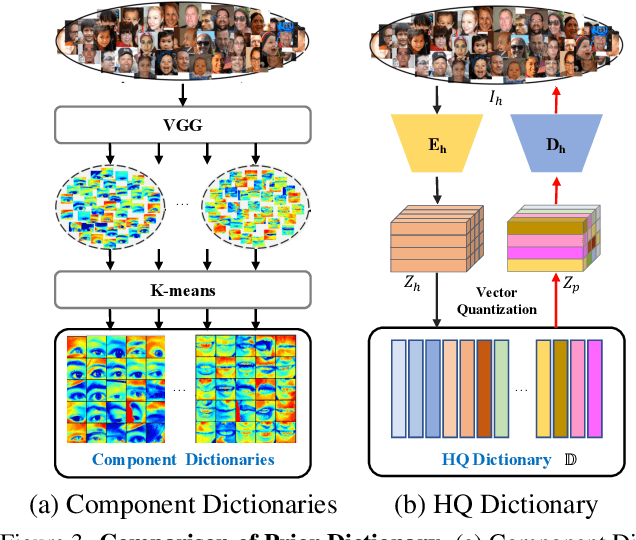
Blind face restoration is to recover a high-quality face image from unknown degradations. As face image contains abundant contextual information, we propose a method, RestoreFormer, which explores fully-spatial attentions to model contextual information and surpasses existing works that use local operators. RestoreFormer has several benefits compared to prior arts. First, unlike the conventional multi-head self-attention in previous Vision Transformers (ViTs), RestoreFormer incorporates a multi-head cross-attention layer to learn fully-spatial interactions between corrupted queries and high-quality key-value pairs. Second, the key-value pairs in ResotreFormer are sampled from a reconstruction-oriented high-quality dictionary, whose elements are rich in high-quality facial features specifically aimed for face reconstruction, leading to superior restoration results. Third, RestoreFormer outperforms advanced state-of-the-art methods on one synthetic dataset and three real-world datasets, as well as produces images with better visual quality.
Resurrecting Trust in Facial Recognition: Mitigating Backdoor Attacks in Face Recognition to Prevent Potential Privacy Breaches
Feb 18, 2022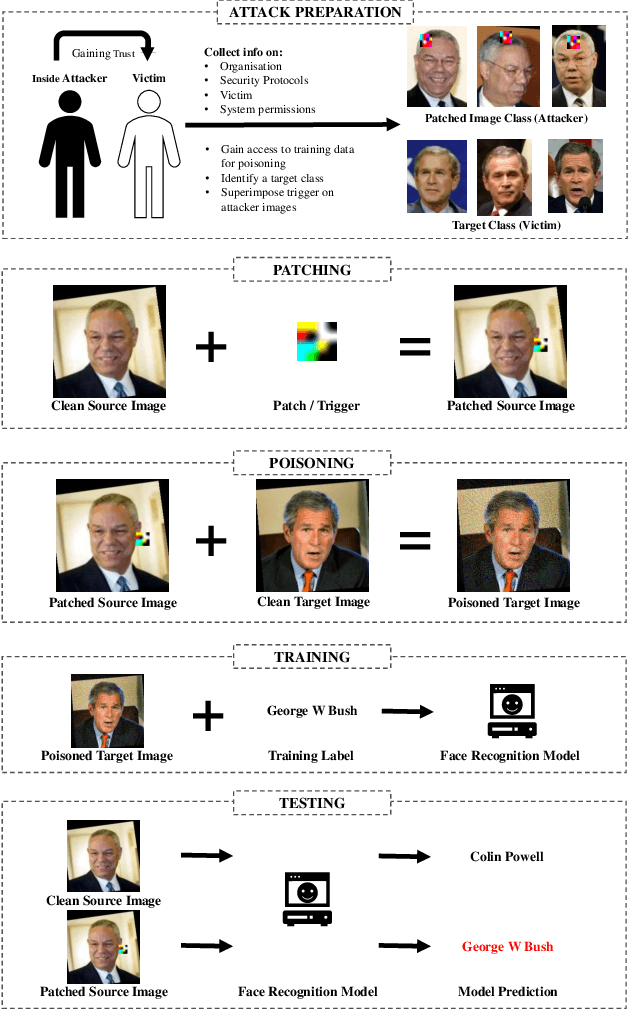
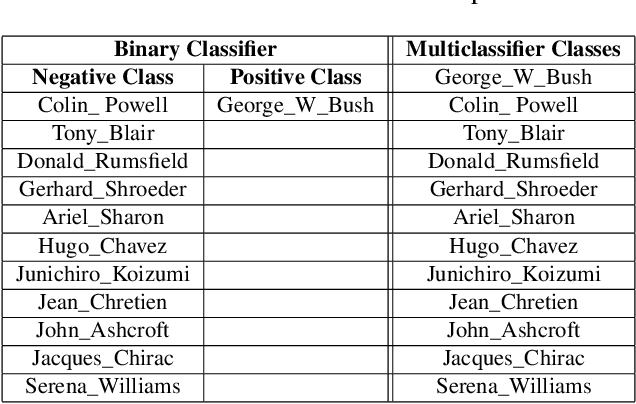
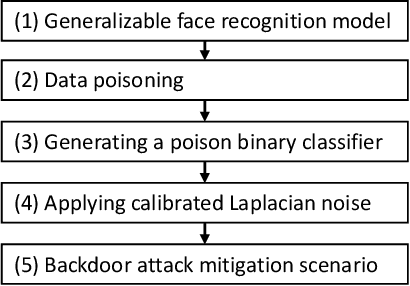
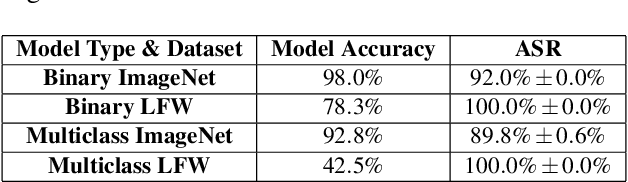
Biometric data, such as face images, are often associated with sensitive information (e.g medical, financial, personal government records). Hence, a data breach in a system storing such information can have devastating consequences. Deep learning is widely utilized for face recognition (FR); however, such models are vulnerable to backdoor attacks executed by malicious parties. Backdoor attacks cause a model to misclassify a particular class as a target class during recognition. This vulnerability can allow adversaries to gain access to highly sensitive data protected by biometric authentication measures or allow the malicious party to masquerade as an individual with higher system permissions. Such breaches pose a serious privacy threat. Previous methods integrate noise addition mechanisms into face recognition models to mitigate this issue and improve the robustness of classification against backdoor attacks. However, this can drastically affect model accuracy. We propose a novel and generalizable approach (named BA-BAM: Biometric Authentication - Backdoor Attack Mitigation), that aims to prevent backdoor attacks on face authentication deep learning models through transfer learning and selective image perturbation. The empirical evidence shows that BA-BAM is highly robust and incurs a maximal accuracy drop of 2.4%, while reducing the attack success rate to a maximum of 20%. Comparisons with existing approaches show that BA-BAM provides a more practical backdoor mitigation approach for face recognition.
Spatio-Temporal Facial Expression Recognition Using Convolutional Neural Networks and Conditional Random Fields
Apr 24, 2017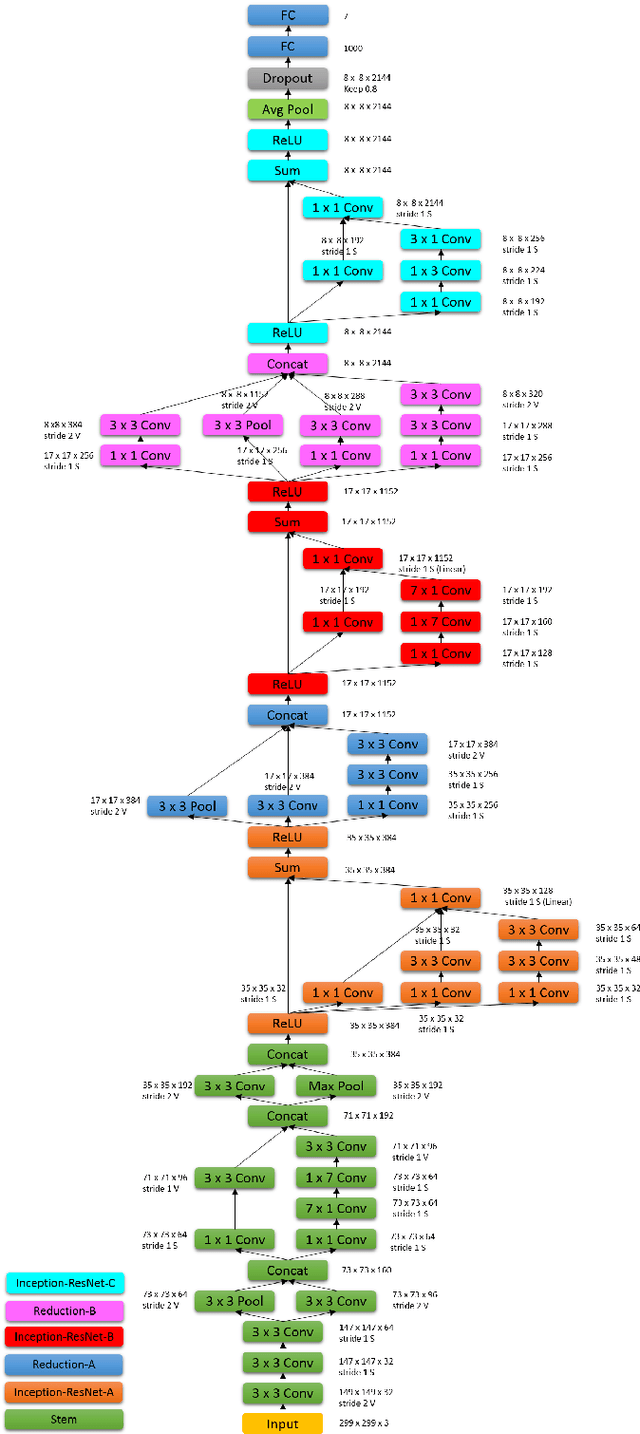
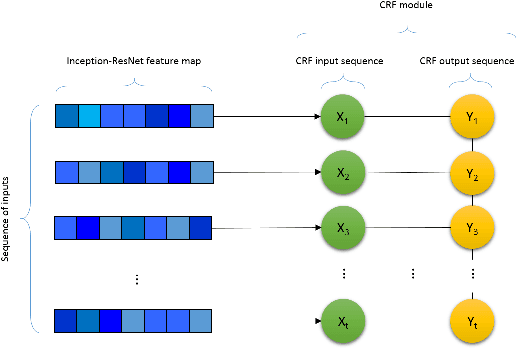
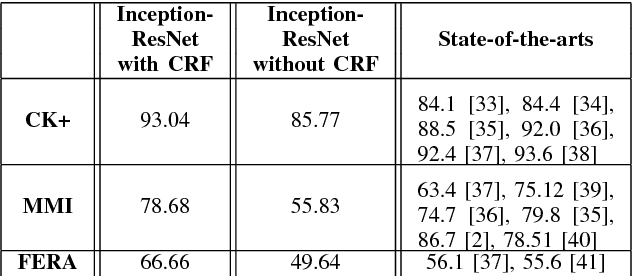
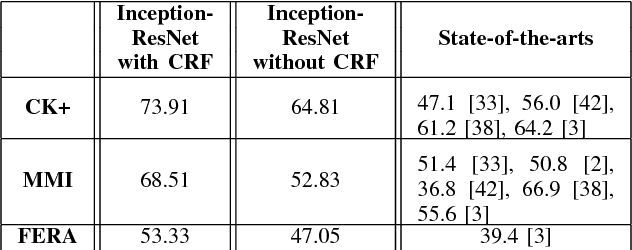
Automated Facial Expression Recognition (FER) has been a challenging task for decades. Many of the existing works use hand-crafted features such as LBP, HOG, LPQ, and Histogram of Optical Flow (HOF) combined with classifiers such as Support Vector Machines for expression recognition. These methods often require rigorous hyperparameter tuning to achieve good results. Recently Deep Neural Networks (DNN) have shown to outperform traditional methods in visual object recognition. In this paper, we propose a two-part network consisting of a DNN-based architecture followed by a Conditional Random Field (CRF) module for facial expression recognition in videos. The first part captures the spatial relation within facial images using convolutional layers followed by three Inception-ResNet modules and two fully-connected layers. To capture the temporal relation between the image frames, we use linear chain CRF in the second part of our network. We evaluate our proposed network on three publicly available databases, viz. CK+, MMI, and FERA. Experiments are performed in subject-independent and cross-database manners. Our experimental results show that cascading the deep network architecture with the CRF module considerably increases the recognition of facial expressions in videos and in particular it outperforms the state-of-the-art methods in the cross-database experiments and yields comparable results in the subject-independent experiments.