 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Smile Like You Mean It: Driving Animatronic Robotic Face with Learned Models
May 26, 2021
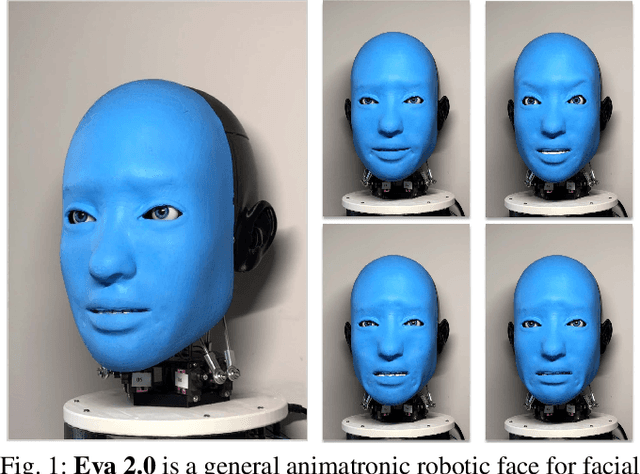



Ability to generate intelligent and generalizable facial expressions is essential for building human-like social robots. At present, progress in this field is hindered by the fact that each facial expression needs to be programmed by humans. In order to adapt robot behavior in real time to different situations that arise when interacting with human subjects, robots need to be able to train themselves without requiring human labels, as well as make fast action decisions and generalize the acquired knowledge to diverse and new contexts. We addressed this challenge by designing a physical animatronic robotic face with soft skin and by developing a vision-based self-supervised learning framework for facial mimicry. Our algorithm does not require any knowledge of the robot's kinematic model, camera calibration or predefined expression set. By decomposing the learning process into a generative model and an inverse model, our framework can be trained using a single motor babbling dataset. Comprehensive evaluations show that our method enables accurate and diverse face mimicry across diverse human subjects. The project website is at http://www.cs.columbia.edu/~bchen/aiface/
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation
Sep 24, 2021
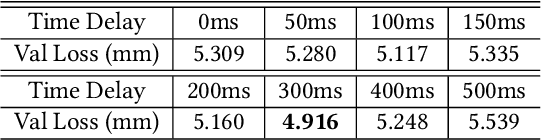
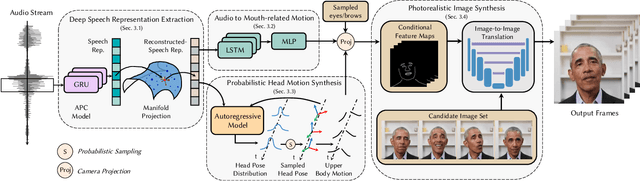
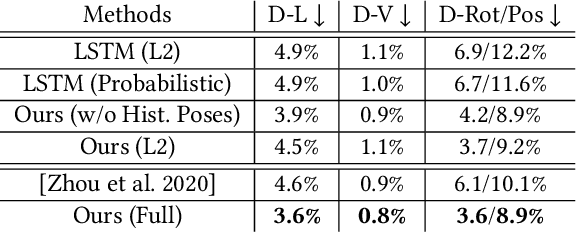
To the best of our knowledge, we first present a live system that generates personalized photorealistic talking-head animation only driven by audio signals at over 30 fps. Our system contains three stages. The first stage is a deep neural network that extracts deep audio features along with a manifold projection to project the features to the target person's speech space. In the second stage, we learn facial dynamics and motions from the projected audio features. The predicted motions include head poses and upper body motions, where the former is generated by an autoregressive probabilistic model which models the head pose distribution of the target person. Upper body motions are deduced from head poses. In the final stage, we generate conditional feature maps from previous predictions and send them with a candidate image set to an image-to-image translation network to synthesize photorealistic renderings. Our method generalizes well to wild audio and successfully synthesizes high-fidelity personalized facial details, e.g., wrinkles, teeth. Our method also allows explicit control of head poses. Extensive qualitative and quantitative evaluations, along with user studies, demonstrate the superiority of our method over state-of-the-art techniques.
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
Apr 16, 2021
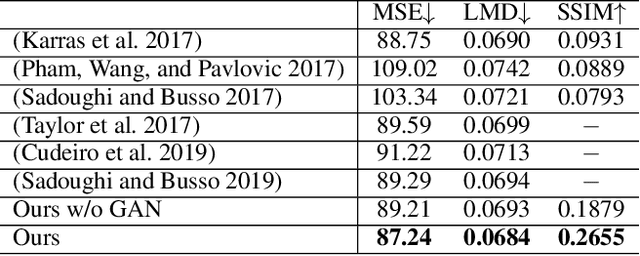
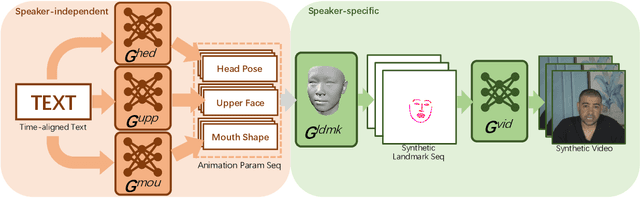
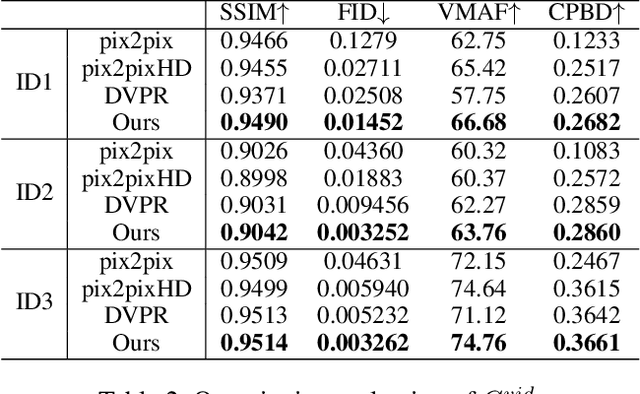
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
Oct 23, 2018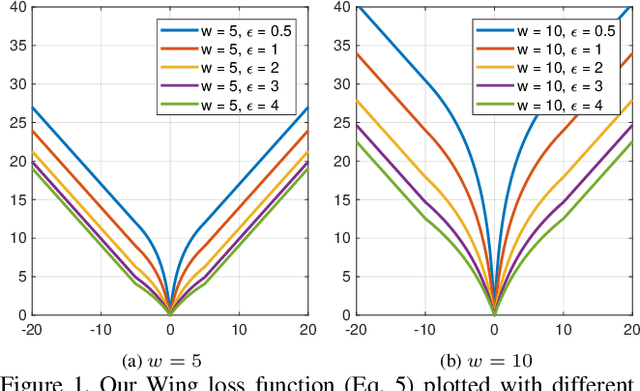
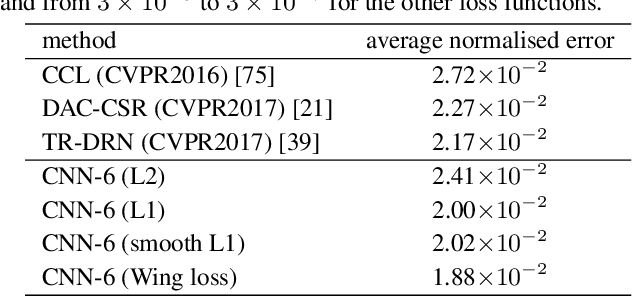
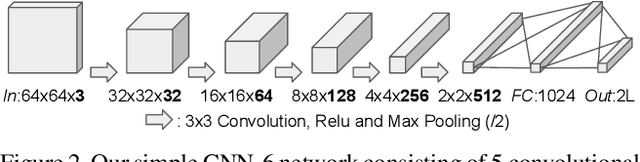
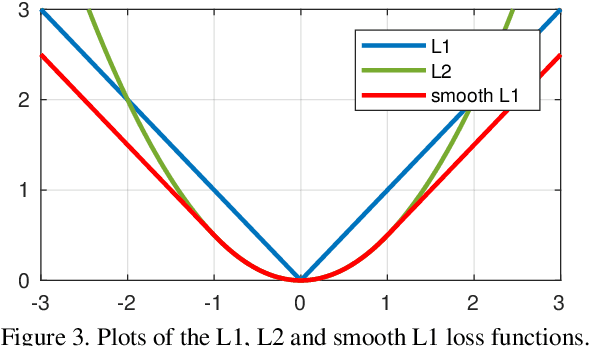
We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
AI in Pursuit of Happiness, Finding Only Sadness: Multi-Modal Facial Emotion Recognition Challenge
Oct 24, 2019
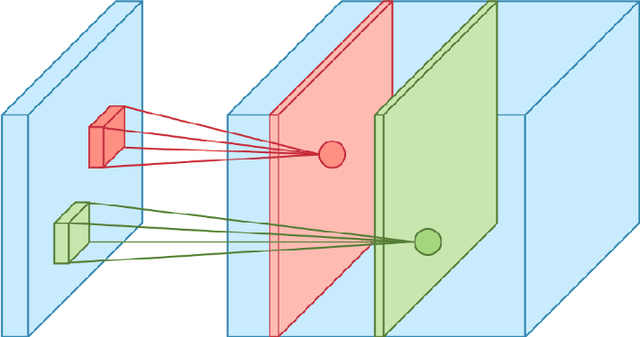
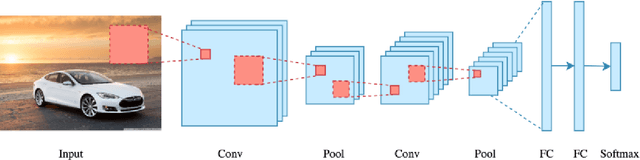
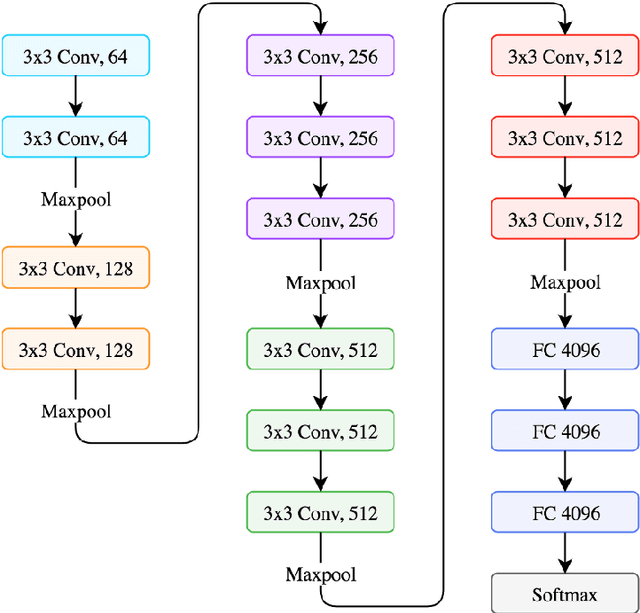
The importance of automated Facial Emotion Recognition (FER) grows the more common human-machine interactions become, which will only continue to increase dramatically with time. A common method to describe human sentiment or feeling is the categorical model the `7 basic emotions', consisting of `Angry', `Disgust', `Fear', `Happiness', `Sadness', `Surprise' and `Neutral'. The `Emotion Recognition in the Wild' (EmotiW) competition is now in its 7th year and has become the standard benchmark for measuring FER performance. The focus of this paper is the EmotiW sub-challenge of classifying videos in the `Acted Facial Expression in the Wild' (AFEW) dataset, consisting of both visual and audio modalities, into one of the above classes. Machine learning has exploded as a research topic in recent years, with advancements in `Deep Learning' a key part of this. Although Deep Learning techniques have been widely applied to the FER task by entrants in previous years, this paper has two main contributions: (i) to apply the latest `state-of-the-art' visual and temporal networks and (ii) exploring various methods of fusing features extracted from the visual and audio elements to enrich the information available to the final model making the prediction. There are a number of complex issues that arise when trying to classify emotions for `in-the-wild' video sequences, which the above two approaches attempt to directly address. There are some positive findings when comparing the results of this paper to past submissions, indicating that further research into the proposed methods and fine-tuning of the models deployed, could result in another step forwards in the field of automated FER.
Teacher-Student Training and Triplet Loss for Facial Expression Recognition under Occlusion
Aug 03, 2020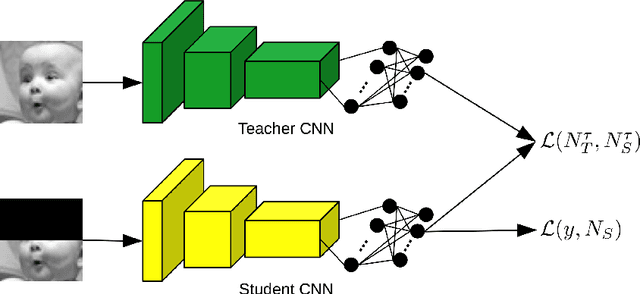
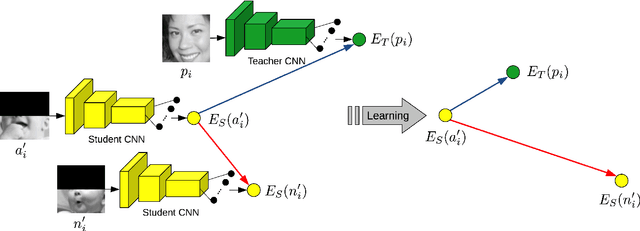
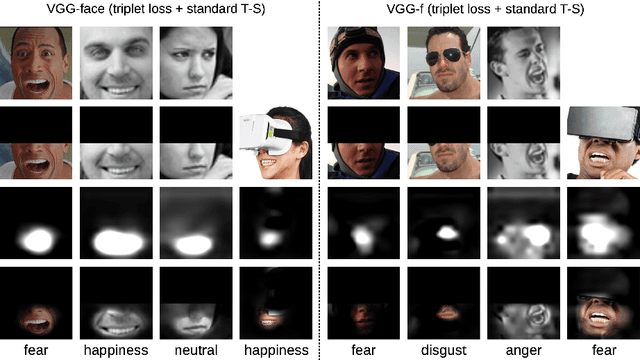
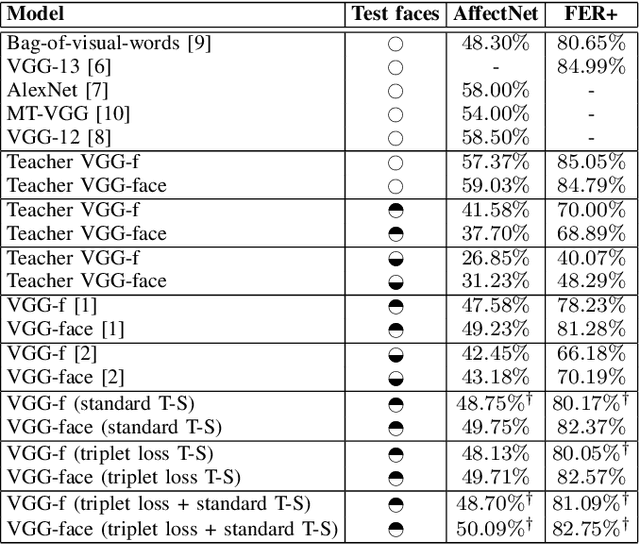
In this paper, we study the task of facial expression recognition under strong occlusion. We are particularly interested in cases where 50% of the face is occluded, e.g. when the subject wears a Virtual Reality (VR) headset. While previous studies show that pre-training convolutional neural networks (CNNs) on fully-visible (non-occluded) faces improves the accuracy, we propose to employ knowledge distillation to achieve further improvements. First of all, we employ the classic teacher-student training strategy, in which the teacher is a CNN trained on fully-visible faces and the student is a CNN trained on occluded faces. Second of all, we propose a new approach for knowledge distillation based on triplet loss. During training, the goal is to reduce the distance between an anchor embedding, produced by a student CNN that takes occluded faces as input, and a positive embedding (from the same class as the anchor), produced by a teacher CNN trained on fully-visible faces, so that it becomes smaller than the distance between the anchor and a negative embedding (from a different class than the anchor), produced by the student CNN. Third of all, we propose to combine the distilled embeddings obtained through the classic teacher-student strategy and our novel teacher-student strategy based on triplet loss into a single embedding vector. We conduct experiments on two benchmarks, FER+ and AffectNet, with two CNN architectures, VGG-f and VGG-face, showing that knowledge distillation can bring significant improvements over the state-of-the-art methods designed for occluded faces in the VR setting.
Masked Face Recognition Challenge: The InsightFace Track Report
Aug 18, 2021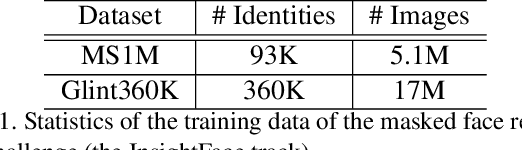

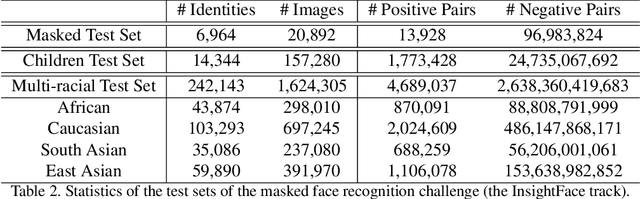
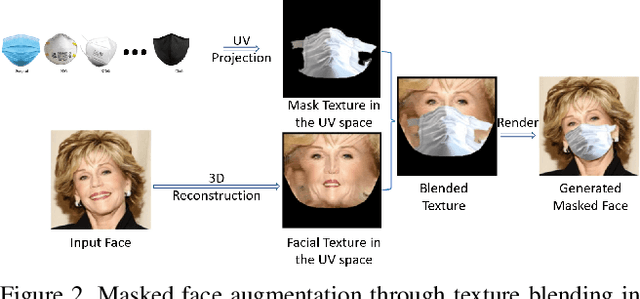
During the COVID-19 coronavirus epidemic, almost everyone wears a facial mask, which poses a huge challenge to deep face recognition. In this workshop, we organize Masked Face Recognition (MFR) challenge and focus on bench-marking deep face recognition methods under the existence of facial masks. In the MFR challenge, there are two main tracks: the InsightFace track and the WebFace260M track. For the InsightFace track, we manually collect a large-scale masked face test set with 7K identities. In addition, we also collect a children test set including 14K identities and a multi-racial test set containing 242K identities. By using these three test sets, we build up an online model testing system, which can give a comprehensive evaluation of face recognition models. To avoid data privacy problems, no test image is released to the public. As the challenge is still under-going, we will keep on updating the top-ranked solutions as well as this report on the arxiv.
Facial Descriptors for Human Interaction Recognition In Still Images
Sep 17, 2015
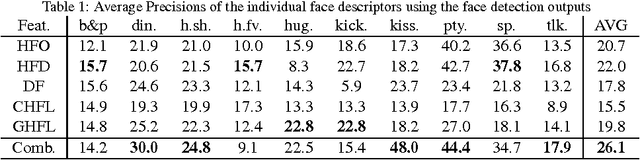
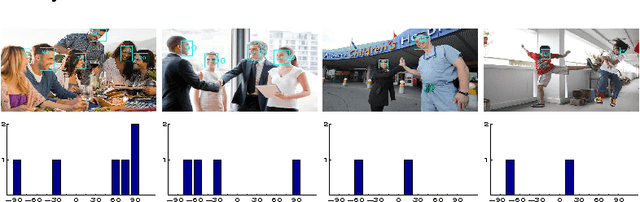
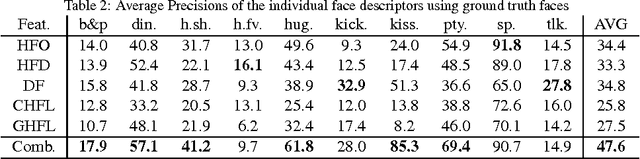
This paper presents a novel approach in a rarely studied area of computer vision: Human interaction recognition in still images. We explore whether the facial regions and their spatial configurations contribute to the recognition of interactions. In this respect, our method involves extraction of several visual features from the facial regions, as well as incorporation of scene characteristics and deep features to the recognition. Extracted multiple features are utilized within a discriminative learning framework for recognizing interactions between people. Our designed facial descriptors are based on the observation that relative positions, size and locations of the faces are likely to be important for characterizing human interactions. Since there is no available dataset in this relatively new domain, a comprehensive new dataset which includes several images of human interactions is collected. Our experimental results show that faces and scene characteristics contain important information to recognize interactions between people.
Objective Micro-Facial Movement Detection Using FACS-Based Regions and Baseline Evaluation
Dec 15, 2016

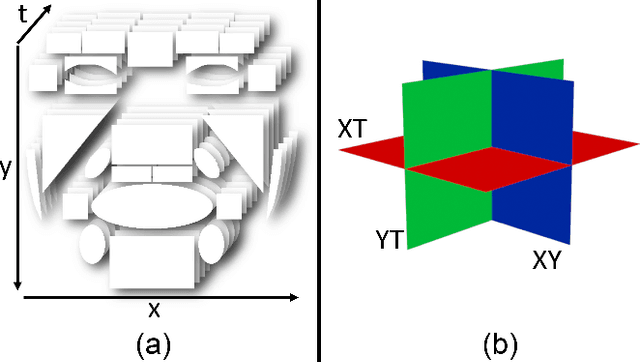
Micro-facial expressions are regarded as an important human behavioural event that can highlight emotional deception. Spotting these movements is difficult for humans and machines, however research into using computer vision to detect subtle facial expressions is growing in popularity. This paper proposes an individualised baseline micro-movement detection method using 3D Histogram of Oriented Gradients (3D HOG) temporal difference method. We define a face template consisting of 26 regions based on the Facial Action Coding System (FACS). We extract the temporal features of each region using 3D HOG. Then, we use Chi-square distance to find subtle facial motion in the local regions. Finally, an automatic peak detector is used to detect micro-movements above the newly proposed adaptive baseline threshold. The performance is validated on two FACS coded datasets: SAMM and CASME II. This objective method focuses on the movement of the 26 face regions. When comparing with the ground truth, the best result was an AUC of 0.7512 and 0.7261 on SAMM and CASME II, respectively. The results show that 3D HOG outperformed for micro-movement detection, compared to state-of-the-art feature representations: Local Binary Patterns in Three Orthogonal Planes and Histograms of Oriented Optical Flow.
Differentially Private Generative Adversarial Networks with Model Inversion
Jan 10, 2022

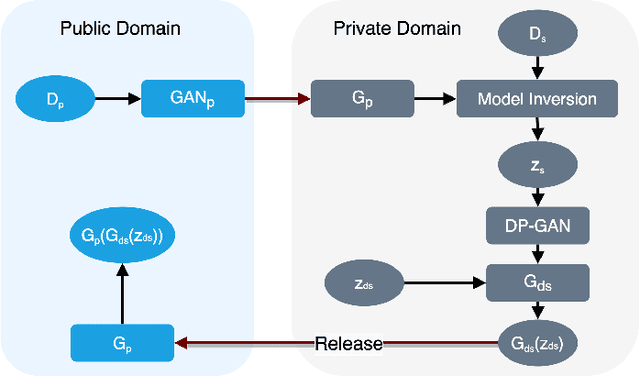
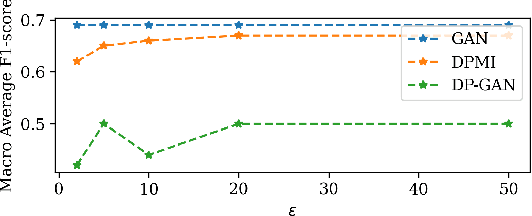
To protect sensitive data in training a Generative Adversarial Network (GAN), the standard approach is to use differentially private (DP) stochastic gradient descent method in which controlled noise is added to the gradients. The quality of the output synthetic samples can be adversely affected and the training of the network may not even converge in the presence of these noises. We propose Differentially Private Model Inversion (DPMI) method where the private data is first mapped to the latent space via a public generator, followed by a lower-dimensional DP-GAN with better convergent properties. Experimental results on standard datasets CIFAR10 and SVHN as well as on a facial landmark dataset for Autism screening show that our approach outperforms the standard DP-GAN method based on Inception Score, Fr\'echet Inception Distance, and classification accuracy under the same privacy guarantee.