 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation
Sep 15, 2017
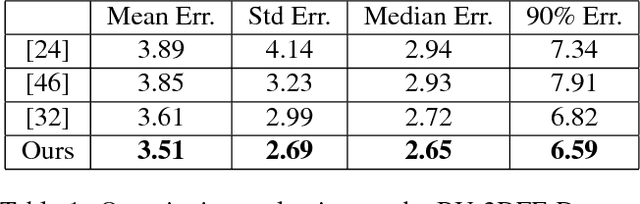

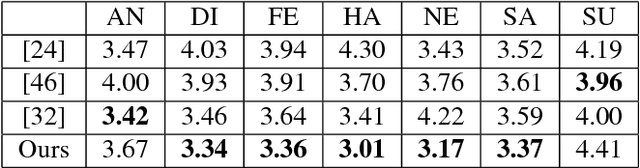
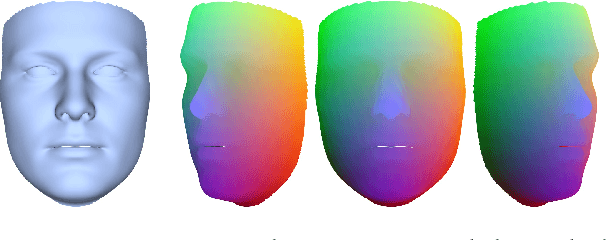
It has been recently shown that neural networks can recover the geometric structure of a face from a single given image. A common denominator of most existing face geometry reconstruction methods is the restriction of the solution space to some low-dimensional subspace. While such a model significantly simplifies the reconstruction problem, it is inherently limited in its expressiveness. As an alternative, we propose an Image-to-Image translation network that jointly maps the input image to a depth image and a facial correspondence map. This explicit pixel-based mapping can then be utilized to provide high quality reconstructions of diverse faces under extreme expressions, using a purely geometric refinement process. In the spirit of recent approaches, the network is trained only with synthetic data, and is then evaluated on in-the-wild facial images. Both qualitative and quantitative analyses demonstrate the accuracy and the robustness of our approach.
GMFIM: A Generative Mask-guided Facial Image Manipulation Model for Privacy Preservation
Jan 10, 2022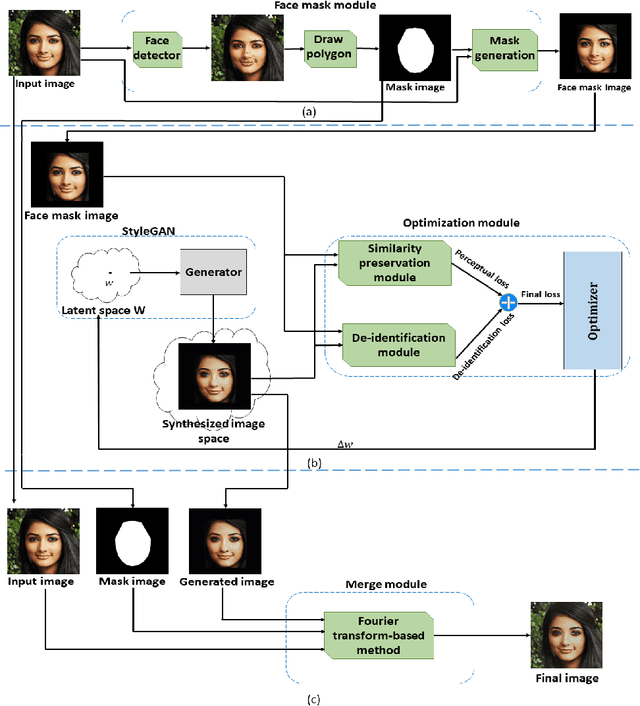



The use of social media websites and applications has become very popular and people share their photos on these networks. Automatic recognition and tagging of people's photos on these networks has raised privacy preservation issues and users seek methods for hiding their identities from these algorithms. Generative adversarial networks (GANs) are shown to be very powerful in generating face images in high diversity and also in editing face images. In this paper, we propose a Generative Mask-guided Face Image Manipulation (GMFIM) model based on GANs to apply imperceptible editing to the input face image to preserve the privacy of the person in the image. Our model consists of three main components: a) the face mask module to cut the face area out of the input image and omit the background, b) the GAN-based optimization module for manipulating the face image and hiding the identity and, c) the merge module for combining the background of the input image and the manipulated de-identified face image. Different criteria are considered in the loss function of the optimization step to produce high-quality images that are as similar as possible to the input image while they cannot be recognized by AFR systems. The results of the experiments on different datasets show that our model can achieve better performance against automated face recognition systems in comparison to the state-of-the-art methods and it catches a higher attack success rate in most experiments from a total of 18. Moreover, the generated images of our proposed model have the highest quality and are more pleasing to human eyes.
ResMoNet: A Residual Mobile-based Network for Facial Emotion Recognition in Resource-Limited Systems
May 15, 2020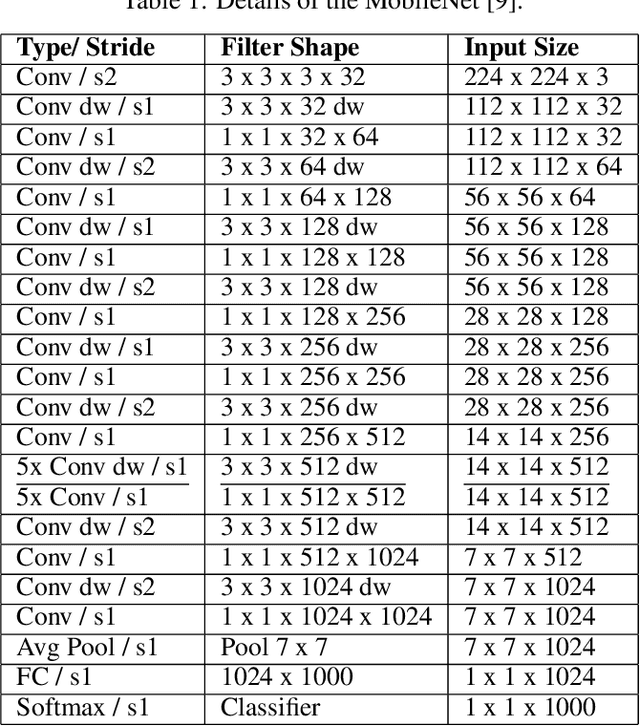
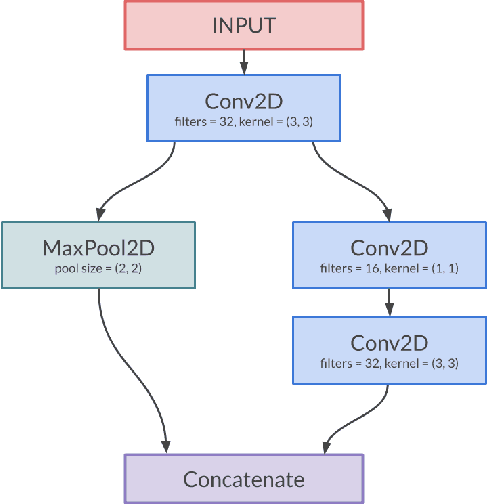
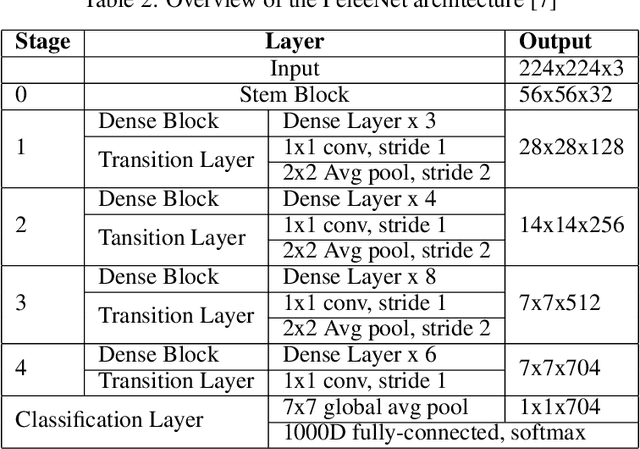
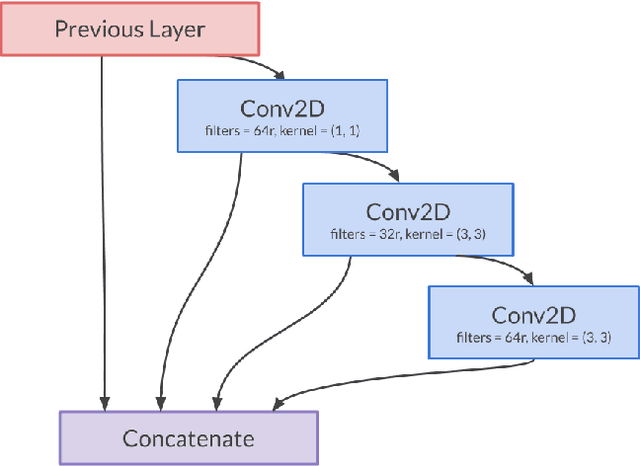
The Deep Neural Networks (DNNs) models have contributed a high accuracy for the classification of human emotional states from facial expression recognition data sets, where efficiency is an important factor for resource-limited systems as mobile devices and embedded systems. There are efficient Convolutional Neural Networks (CNN) models as MobileNet, PeleeNet, Extended Deep Neural Network (EDNN) and Inception-Based Deep Neural Network (IDNN) in terms of model architecture results: parameters, Floating-point OPerations (FLOPs) and accuracy. Although these results are satisfactory, it is necessary to evaluate other computational resources related to the trained model such as main memory utilization and response time to complete the emotion recognition. In this paper, we compare our proposed model inspired in depthwise separable convolutions and residual blocks with MobileNet, PeleeNet, EDNN and IDNN. The comparative results of the CNN architectures and the trained models --with Radboud Faces Database (RaFD)-- installed in a resource-limited device are discussed.
Multi-Modal Learning for AU Detection Based on Multi-Head Fused Transformers
Mar 22, 2022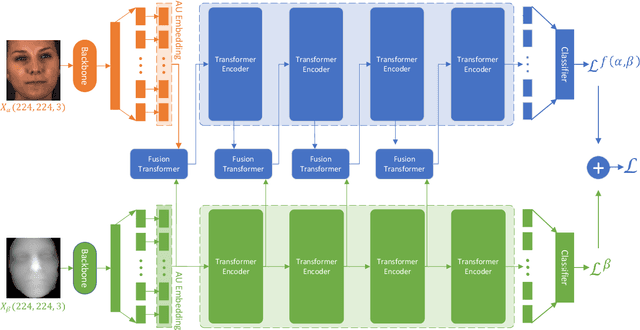
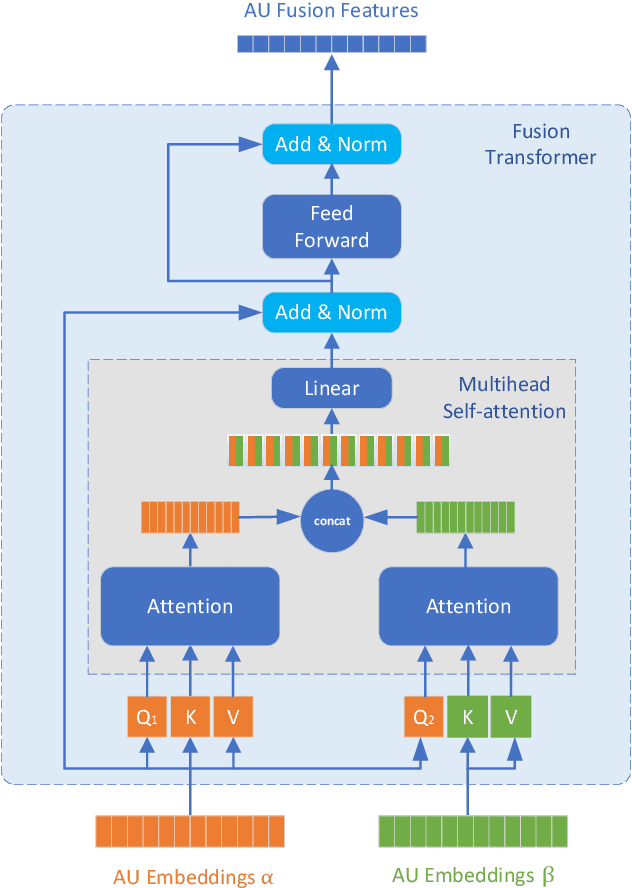
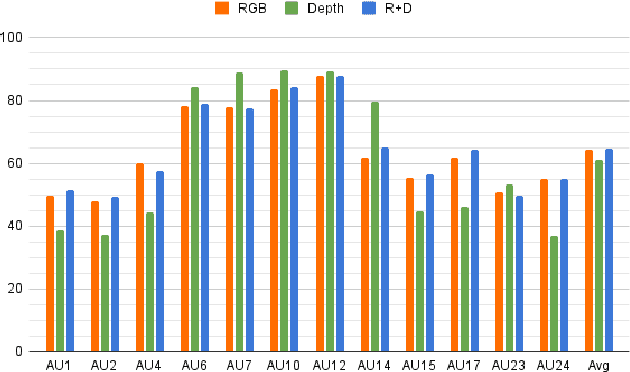
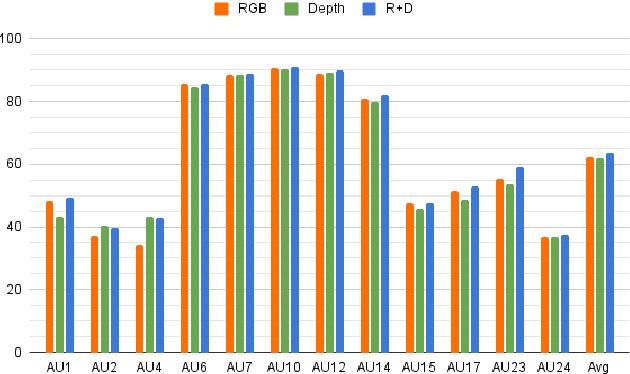
Multi-modal learning has been intensified in recent years, especially for applications in facial analysis and action unit detection whilst there still exist two main challenges in terms of 1) relevant feature learning for representation and 2) efficient fusion for multi-modalities. Recently, there are a number of works have shown the effectiveness in utilizing the attention mechanism for AU detection, however, most of them are binding the region of interest (ROI) with features but rarely apply attention between features of each AU. On the other hand, the transformer, which utilizes a more efficient self-attention mechanism, has been widely used in natural language processing and computer vision tasks but is not fully explored in AU detection tasks. In this paper, we propose a novel end-to-end Multi-Head Fused Transformer (MFT) method for AU detection, which learns AU encoding features representation from different modalities by transformer encoder and fuses modalities by another fusion transformer module. Multi-head fusion attention is designed in the fusion transformer module for the effective fusion of multiple modalities. Our approach is evaluated on two public multi-modal AU databases, BP4D, and BP4D+, and the results are superior to the state-of-the-art algorithms and baseline models. We further analyze the performance of AU detection from different modalities.
Knowing When to Quit: Selective Cascaded Regression with Patch Attention for Real-Time Face Alignment
Aug 03, 2021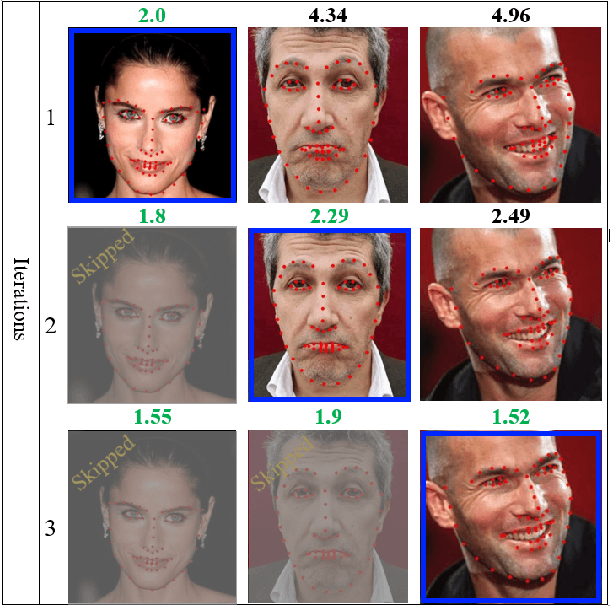
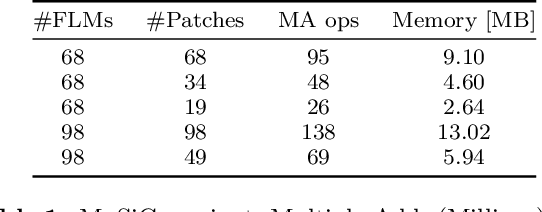
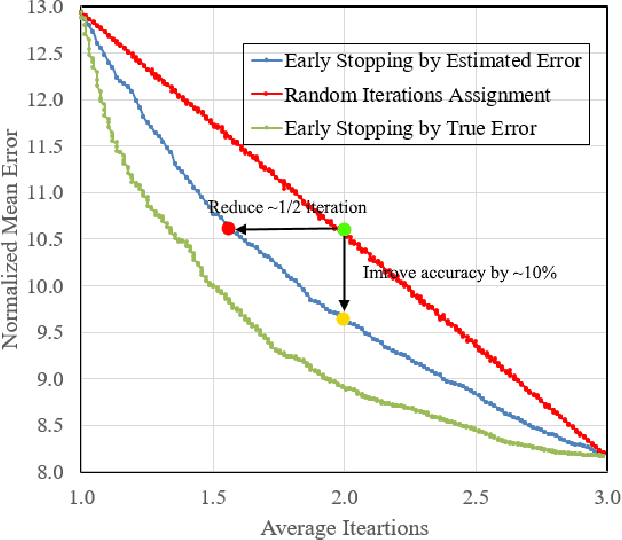
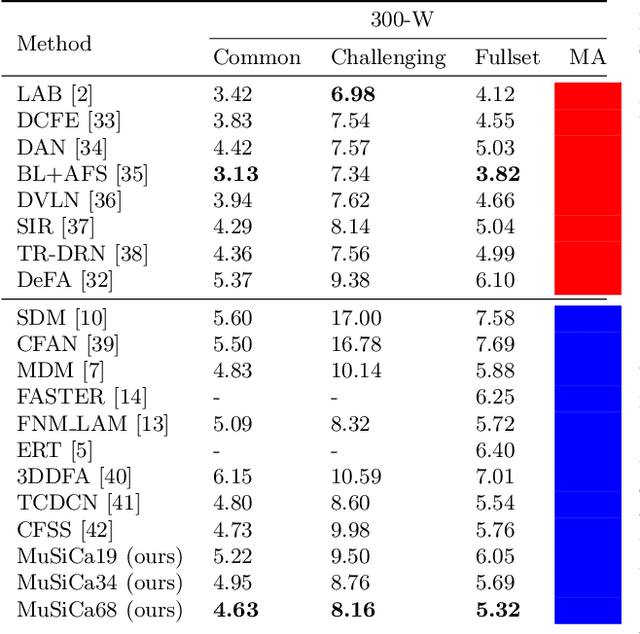
Facial landmarks (FLM) estimation is a critical component in many face-related applications. In this work, we aim to optimize for both accuracy and speed and explore the trade-off between them. Our key observation is that not all faces are created equal. Frontal faces with neutral expressions converge faster than faces with extreme poses or expressions. To differentiate among samples, we train our model to predict the regression error after each iteration. If the current iteration is accurate enough, we stop iterating, saving redundant iterations while keeping the accuracy in check. We also observe that as neighboring patches overlap, we can infer all facial landmarks (FLMs) with only a small number of patches without a major accuracy sacrifice. Architecturally, we offer a multi-scale, patch-based, lightweight feature extractor with a fine-grained local patch attention module, which computes a patch weighting according to the information in the patch itself and enhances the expressive power of the patch features. We analyze the patch attention data to infer where the model is attending when regressing facial landmarks and compare it to face attention in humans. Our model runs in real-time on a mobile device GPU, with 95 Mega Multiply-Add (MMA) operations, outperforming all state-of-the-art methods under 1000 MMA, with a normalized mean error of 8.16 on the 300W challenging dataset.
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
May 07, 2021
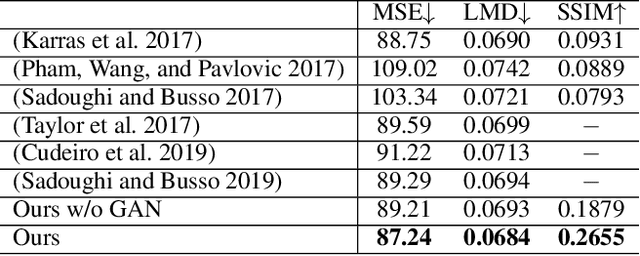
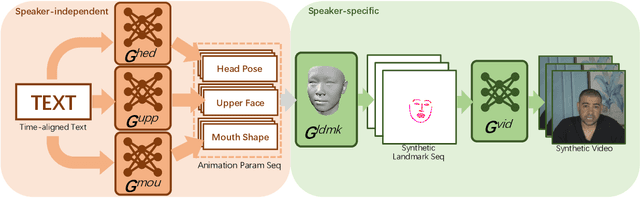
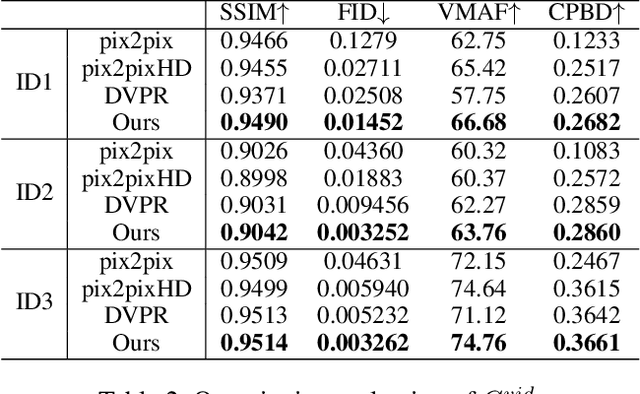
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.
Face Age Progression With Attribute Manipulation
Jun 14, 2021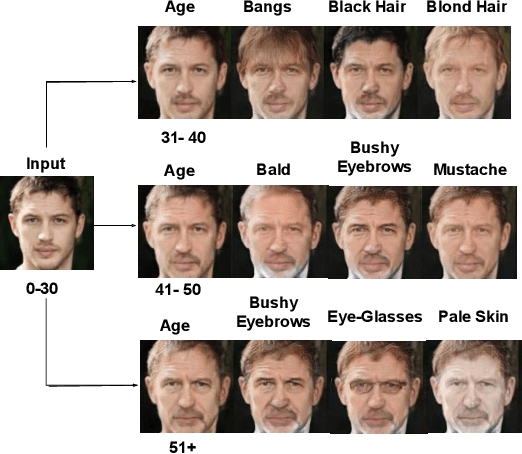
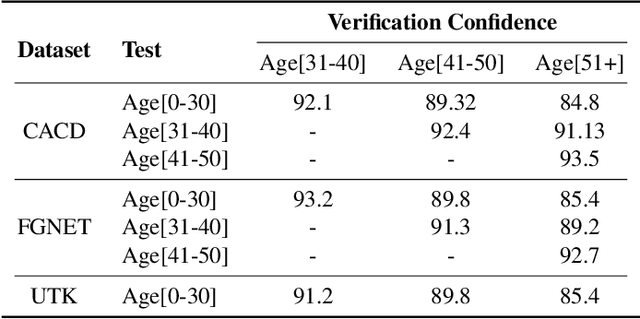
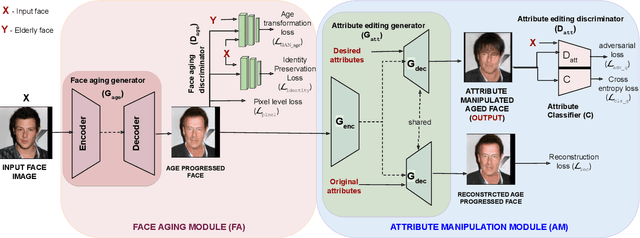
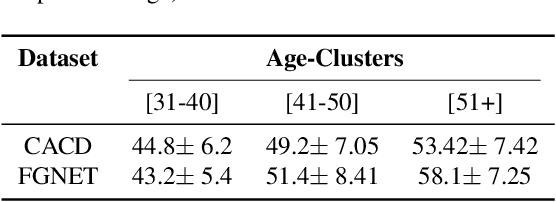
Face is one of the predominant means of person recognition. In the process of ageing, human face is prone to many factors such as time, attributes, weather and other subject specific variations. The impact of these factors were not well studied in the literature of face aging. In this paper, we propose a novel holistic model in this regard viz., ``Face Age progression With Attribute Manipulation (FAWAM)", i.e. generating face images at different ages while simultaneously varying attributes and other subject specific characteristics. We address the task in a bottom-up manner, as two submodules i.e. face age progression and face attribute manipulation. For face aging, we use an attribute-conscious face aging model with a pyramidal generative adversarial network that can model age-specific facial changes while maintaining intrinsic subject specific characteristics. For facial attribute manipulation, the age processed facial image is manipulated with desired attributes while preserving other details unchanged, leveraging an attribute generative adversarial network architecture. We conduct extensive analysis in standard large scale datasets and our model achieves significant performance both quantitatively and qualitatively.
Facial Landmark Detection for Manga Images
Nov 08, 2018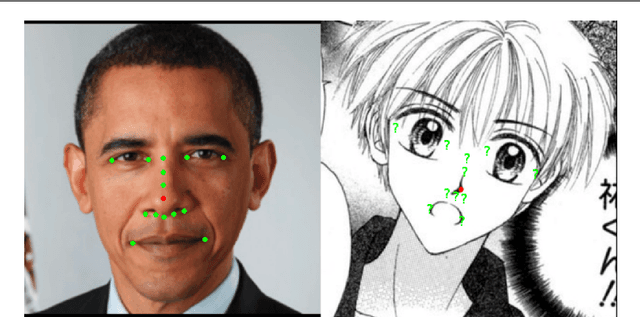



The topic of facial landmark detection has been widely covered for pictures of human faces, but it is still a challenge for drawings. Indeed, the proportions and symmetry of standard human faces are not always used for comics or mangas. The personal style of the author, the limitation of colors, etc. makes the landmark detection on faces in drawings a difficult task. Detecting the landmarks on manga images will be useful to provide new services for easily editing the character faces, estimating the character emotions, or generating automatically some animations such as lip or eye movements. This paper contains two main contributions: 1) a new landmark annotation model for manga faces, and 2) a deep learning approach to detect these landmarks. We use the "Deep Alignment Network", a multi stage architecture where the first stage makes an initial estimation which gets refined in further stages. The first results show that the proposed method succeed to accurately find the landmarks in more than 80% of the cases.
Teacher-Student Training and Triplet Loss to Reduce the Effect of Drastic Face Occlusion
Nov 20, 2021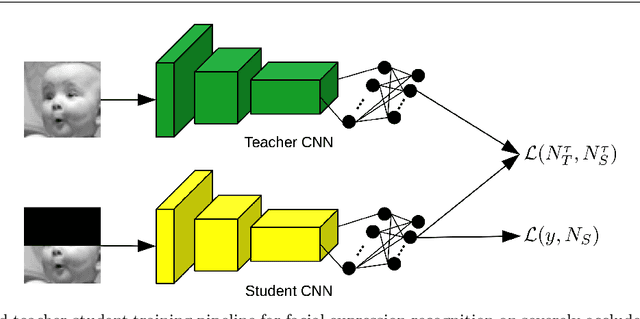
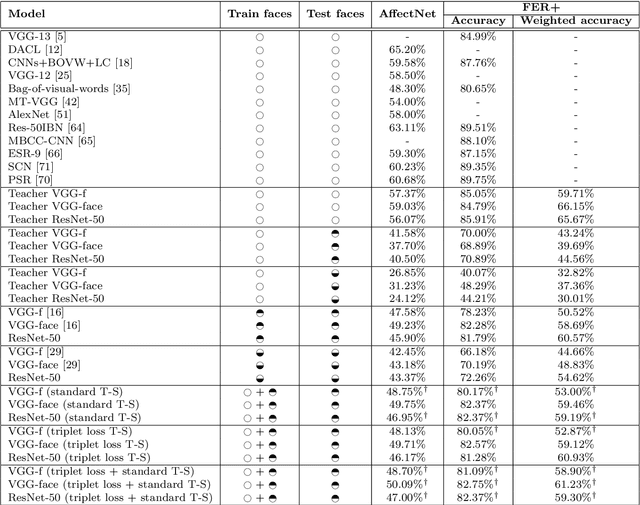
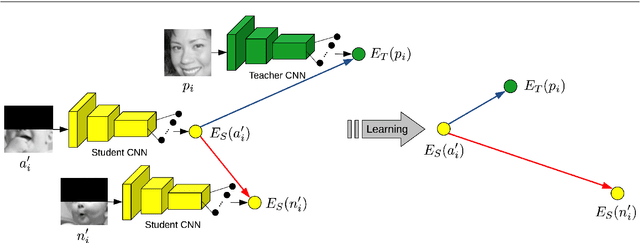
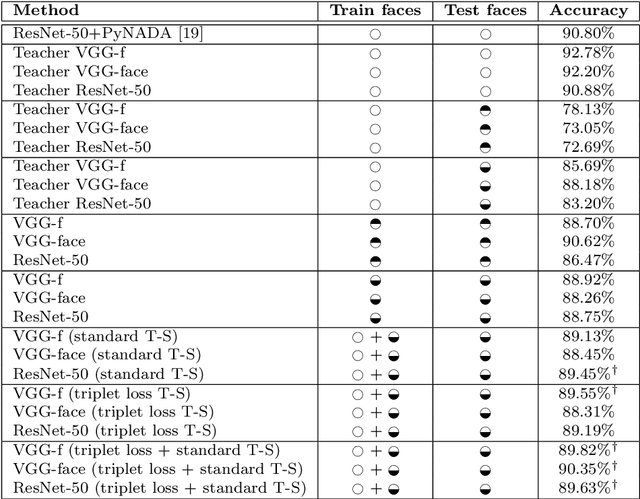
We study a series of recognition tasks in two realistic scenarios requiring the analysis of faces under strong occlusion. On the one hand, we aim to recognize facial expressions of people wearing Virtual Reality (VR) headsets. On the other hand, we aim to estimate the age and identify the gender of people wearing surgical masks. For all these tasks, the common ground is that half of the face is occluded. In this challenging setting, we show that convolutional neural networks (CNNs) trained on fully-visible faces exhibit very low performance levels. While fine-tuning the deep learning models on occluded faces is extremely useful, we show that additional performance gains can be obtained by distilling knowledge from models trained on fully-visible faces. To this end, we study two knowledge distillation methods, one based on teacher-student training and one based on triplet loss. Our main contribution consists in a novel approach for knowledge distillation based on triplet loss, which generalizes across models and tasks. Furthermore, we consider combining distilled models learned through conventional teacher-student training or through our novel teacher-student training based on triplet loss. We provide empirical evidence showing that, in most cases, both individual and combined knowledge distillation methods bring statistically significant performance improvements. We conduct experiments with three different neural models (VGG-f, VGG-face, ResNet-50) on various tasks (facial expression recognition, gender recognition, age estimation), showing consistent improvements regardless of the model or task.
The Influence of the Other-Race Effect on Susceptibility to Face Morphing Attacks
Apr 26, 2022
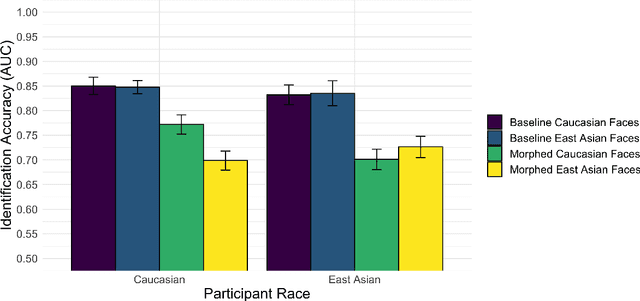
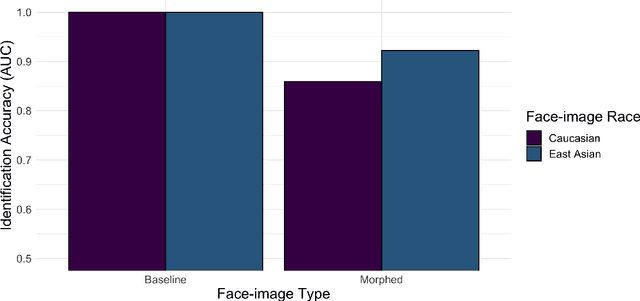
Facial morphs created between two identities resemble both of the faces used to create the morph. Consequently, humans and machines are prone to mistake morphs made from two identities for either of the faces used to create the morph. This vulnerability has been exploited in "morph attacks" in security scenarios. Here, we asked whether the "other-race effect" (ORE) -- the human advantage for identifying own- vs. other-race faces -- exacerbates morph attack susceptibility for humans. We also asked whether face-identification performance in a deep convolutional neural network (DCNN) is affected by the race of morphed faces. Caucasian (CA) and East-Asian (EA) participants performed a face-identity matching task on pairs of CA and EA face images in two conditions. In the morph condition, different-identity pairs consisted of an image of identity "A" and a 50/50 morph between images of identity "A" and "B". In the baseline condition, morphs of different identities never appeared. As expected, morphs were identified mistakenly more often than original face images. Moreover, CA participants showed an advantage for CA faces in comparison to EA faces (a partial ORE). Of primary interest, morph identification was substantially worse for cross-race faces than for own-race faces. Similar to humans, the DCNN performed more accurately for original face images than for morphed image pairs. Notably, the deep network proved substantially more accurate than humans in both cases. The results point to the possibility that DCNNs might be useful for improving face identification accuracy when morphed faces are presented. They also indicate the significance of the ORE in morph attack susceptibility in applied settings.