 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
An Exploration of Active Learning for Affective Digital Phenotyping
Apr 06, 2022

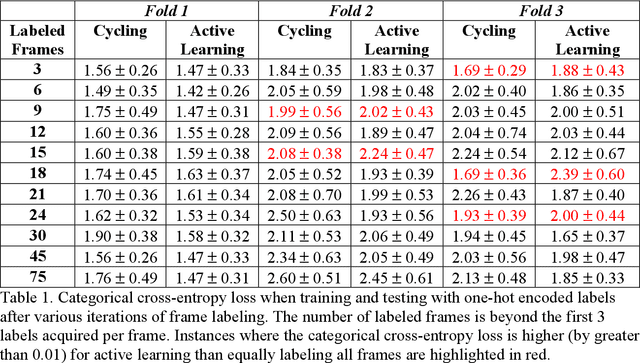
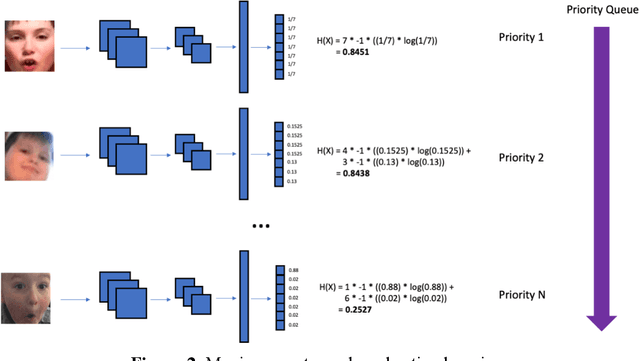
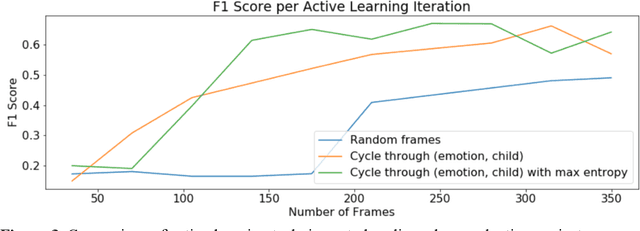
Some of the most severe bottlenecks preventing widespread development of machine learning models for human behavior include a dearth of labeled training data and difficulty of acquiring high quality labels. Active learning is a paradigm for using algorithms to computationally select a useful subset of data points to label using metrics for model uncertainty and data similarity. We explore active learning for naturalistic computer vision emotion data, a particularly heterogeneous and complex data space due to inherently subjective labels. Using frames collected from gameplay acquired from a therapeutic smartphone game for children with autism, we run a simulation of active learning using gameplay prompts as metadata to aid in the active learning process. We find that active learning using information generated during gameplay slightly outperforms random selection of the same number of labeled frames. We next investigate a method to conduct active learning with subjective data, such as in affective computing, and where multiple crowdsourced labels can be acquired for each image. Using the Child Affective Facial Expression (CAFE) dataset, we simulate an active learning process for crowdsourcing many labels and find that prioritizing frames using the entropy of the crowdsourced label distribution results in lower categorical cross-entropy loss compared to random frame selection. Collectively, these results demonstrate pilot evaluations of two novel active learning approaches for subjective affective data collected in noisy settings.
Deep Collaborative Multi-Modal Learning for Unsupervised Kinship Estimation
Sep 07, 2021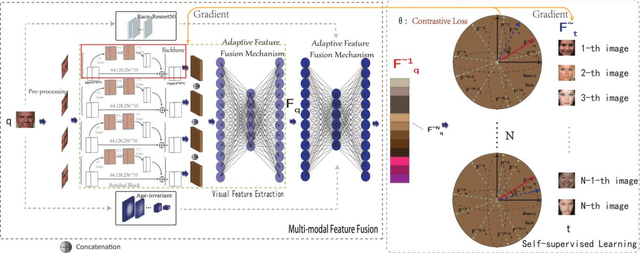
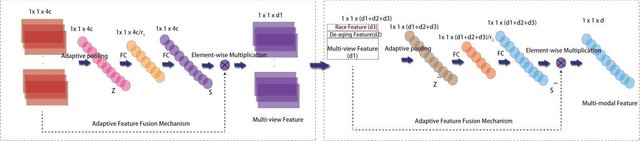
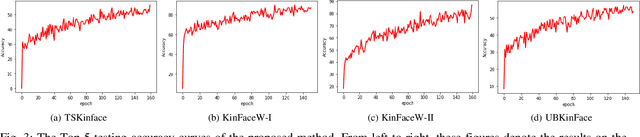
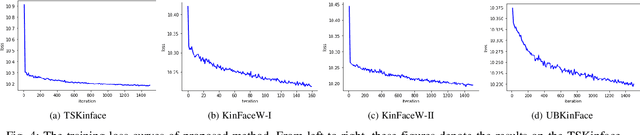
Kinship verification is a long-standing research challenge in computer vision. The visual differences presented to the face have a significant effect on the recognition capabilities of the kinship systems. We argue that aggregating multiple visual knowledge can better describe the characteristics of the subject for precise kinship identification. Typically, the age-invariant features can represent more natural facial details. Such age-related transformations are essential for face recognition due to the biological effects of aging. However, the existing methods mainly focus on employing the single-view image features for kinship identification, while more meaningful visual properties such as race and age are directly ignored in the feature learning step. To this end, we propose a novel deep collaborative multi-modal learning (DCML) to integrate the underlying information presented in facial properties in an adaptive manner to strengthen the facial details for effective unsupervised kinship verification. Specifically, we construct a well-designed adaptive feature fusion mechanism, which can jointly leverage the complementary properties from different visual perspectives to produce composite features and draw greater attention to the most informative components of spatial feature maps. Particularly, an adaptive weighting strategy is developed based on a novel attention mechanism, which can enhance the dependencies between different properties by decreasing the information redundancy in channels in a self-adaptive manner. To validate the effectiveness of the proposed method, extensive experimental evaluations conducted on four widely-used datasets show that our DCML method is always superior to some state-of-the-art kinship verification methods.
Bridging Dialogue Generation and Facial Expression Synthesis
May 28, 2019

Spoken dialogue systems that assist users to solve complex tasks such as movie ticket booking have become an emerging research topic in artificial intelligence and natural language processing areas. With a well-designed dialogue system as an intelligent personal assistant, people can accomplish certain tasks more easily via natural language interactions. Today there are several virtual intelligent assistants in the market; however, most systems only focus on single modality, such as textual or vocal interaction. A multimodal interface has various advantages: (1) allowing human to communicate with machines in a natural and concise form using the mixture of modalities that most precisely convey the intention to satisfy communication needs, and (2) providing more engaging experience by natural and human-like feedback. This paper explores a brand new research direction, which aims at bridging dialogue generation and facial expression synthesis for better multimodal interaction. The goal is to generate dialogue responses and simultaneously synthesize corresponding visual expressions on faces, which is also an ultimate step toward more human-like virtual assistants.
Audio-Visual Evaluation of Oratory Skills
Sep 30, 2021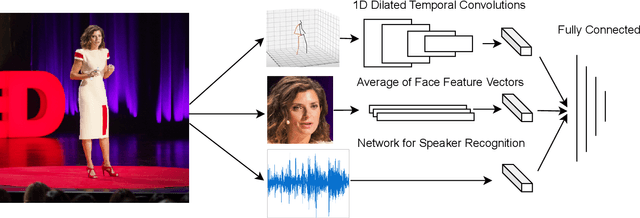
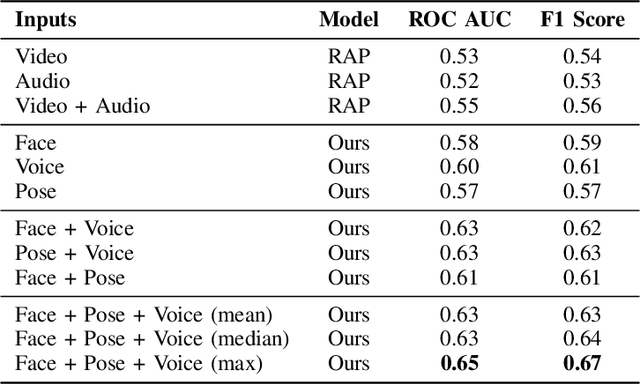
What makes a talk successful? Is it the content or the presentation? We try to estimate the contribution of the speaker's oratory skills to the talk's success, while ignoring the content of the talk. By oratory skills we refer to facial expressions, motions and gestures, as well as the vocal features. We use TED Talks as our dataset, and measure the success of each talk by its view count. Using this dataset we train a neural network to assess the oratory skills in a talk through three factors: body pose, facial expressions, and acoustic features. Most previous work on automatic evaluation of oratory skills uses hand-crafted expert annotations for both the quality of the talk and for the identification of predefined actions. Unlike prior art, we measure the quality to be equivalent to the view count of the talk as counted by TED, and allow the network to automatically learn the actions, expressions, and sounds that are relevant to the success of a talk. We find that oratory skills alone contribute substantially to the chances of a talk being successful.
End-to-End Facial Deep Learning Feature Compression with Teacher-Student Enhancement
Feb 10, 2020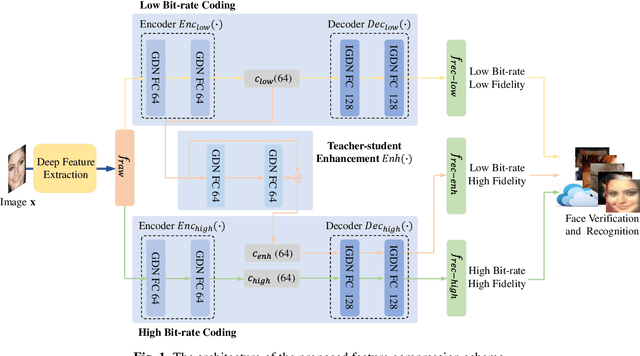

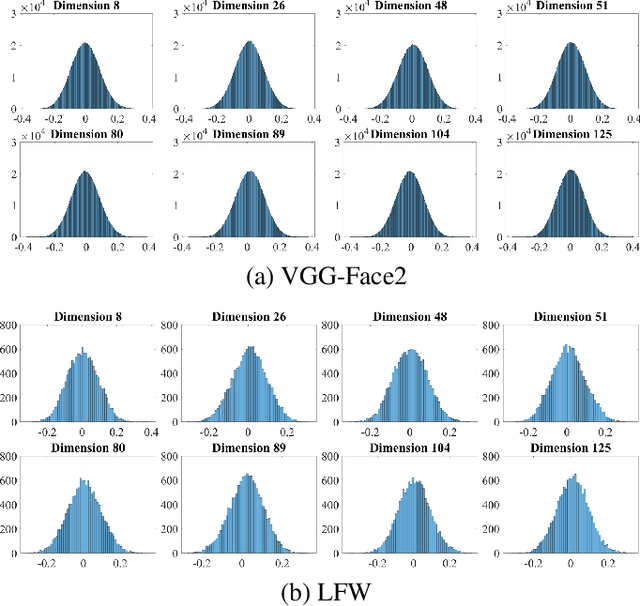
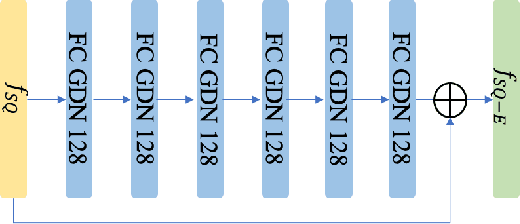
In this paper, we propose a novel end-to-end feature compression scheme by leveraging the representation and learning capability of deep neural networks, towards intelligent front-end equipped analysis with promising accuracy and efficiency. In particular, the extracted features are compactly coded in an end-to-end manner by optimizing the rate-distortion cost to achieve feature-in-feature representation. In order to further improve the compression performance, we present a latent code level teacher-student enhancement model, which could efficiently transfer the low bit-rate representation into a high bit rate one. Such a strategy further allows us to adaptively shift the representation cost to decoding computations, leading to more flexible feature compression with enhanced decoding capability. We verify the effectiveness of the proposed model with the facial feature, and experimental results reveal better compression performance in terms of rate-accuracy compared with existing models.
Real-time Segmentation and Facial Skin Tones Grading
Dec 30, 2019
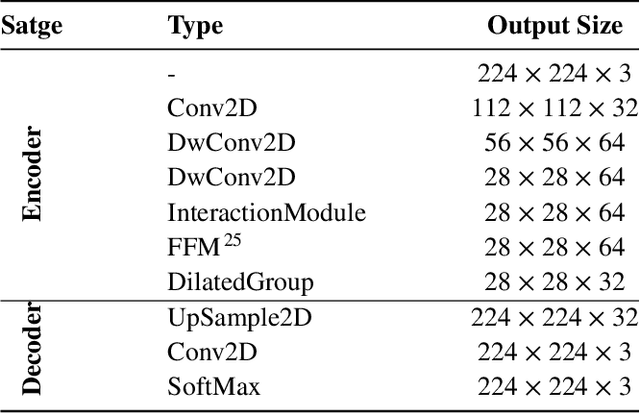
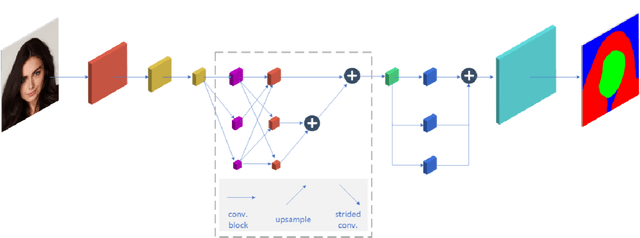
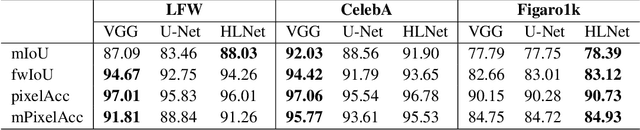
Modern approaches for semantic segmention usually pay too much attention to the accuracy of the model, and therefore it is strongly recommended to introduce cumbersome backbones, which brings heavy computation burden and memory footprint. To alleviate this problem, we propose an efficient segmentation method based on deep convolutional neural networks (DCNNs) for the task of hair and facial skin segmentation, which achieving remarkable trade-off between speed and performance on three benchmark datasets. As far as we know, the accuracy of skin tones classification is usually unsatisfactory due to the influence of external environmental factors such as illumination and background noise. Therefore, we use the segmentated face to obtain a specific face area, and further exploit the color moment algorithm to extract its color features. Specifically, for a 224 x 224 standard input, using our high-resolution spatial detail information and low-resolution contextual information fusion network (HLNet), we achieve 90.73% Pixel Accuracy on Figaro1k dataset at over 16 FPS in the case of CPU environment. Additional experiments on CamVid dataset further confirm the universality of the proposed model. We further use masked color moment for skin tones grade evaluation and approximate 80% classification accuracy demonstrate the feasibility of the proposed scheme.Code is available at https://github.com/JACKYLUO1991/Face-skin-hair-segmentaiton-and-skin-color-evaluation.
A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition
Apr 04, 2022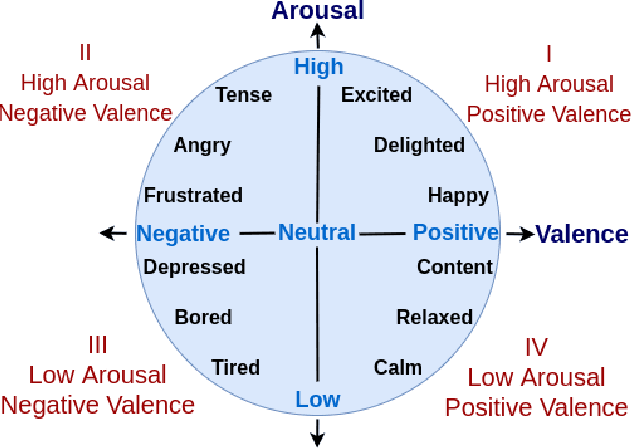
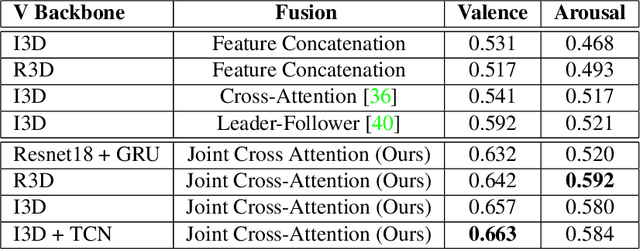
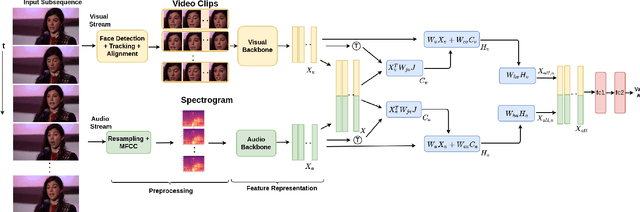
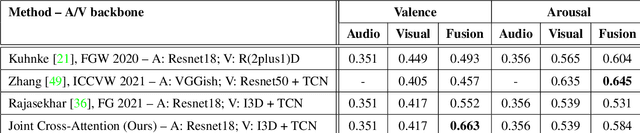
Multimodal emotion recognition has recently gained much attention since it can leverage diverse and complementary relationships over multiple modalities (e.g., audio, visual, biosignals, etc.), and can provide some robustness to noisy modalities. Most state-of-the-art methods for audio-visual (A-V) fusion rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos. Specifically, we propose a joint cross-attention model that relies on the complementary relationships to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. The proposed fusion model efficiently leverages the inter-modal relationships, while reducing the heterogeneity between the features. In particular, it computes the cross-attention weights based on correlation between the combined feature representation and individual modalities. By deploying the combined A-V feature representation into the cross-attention module, the performance of our fusion module improves significantly over the vanilla cross-attention module. Experimental results on validation-set videos from the AffWild2 dataset indicate that our proposed A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches. The code is available on GitHub: https://github.com/praveena2j/JointCrossAttentional-AV-Fusion.
Self-supervised CNN for Unconstrained 3D Facial Performance Capture from an RGB-D Camera
Aug 17, 2018
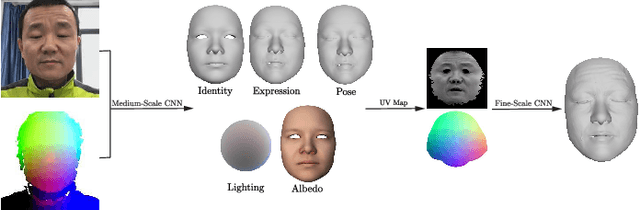


We present a novel method for real-time 3D facial performance capture with consumer-level RGB-D sensors. Our capturing system is targeted at robust and stable 3D face capturing in the wild, in which the RGB-D facial data contain noise, imperfection and occlusion, and often exhibit high variability in motion, pose, expression and lighting conditions, thus posing great challenges. The technical contribution is a self-supervised deep learning framework, which is trained directly from raw RGB-D data. The key novelties include: (1) learning both the core tensor and the parameters for refining our parametric face model; (2) using vertex displacement and UV map for learning surface detail; (3) designing the loss function by incorporating temporal coherence and same identity constraints based on pairs of RGB-D images and utilizing sparse norms, in addition to the conventional terms for photo-consistency, feature similarity, regularization as well as geometry consistency; and (4) augmenting the training data set in new ways. The method is demonstrated in a live setup that runs in real-time on a smartphone and an RGB-D sensor. Extensive experiments show that our method is robust to severe occlusion, fast motion, large rotation, exaggerated facial expressions and diverse lighting.
Classifying Online Dating Profiles on Tinder using FaceNet Facial Embeddings
Mar 12, 2018
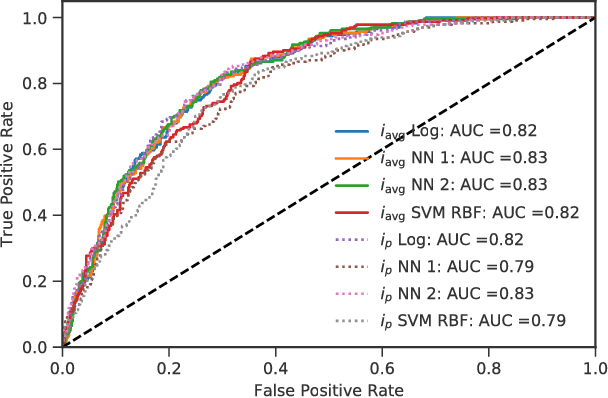
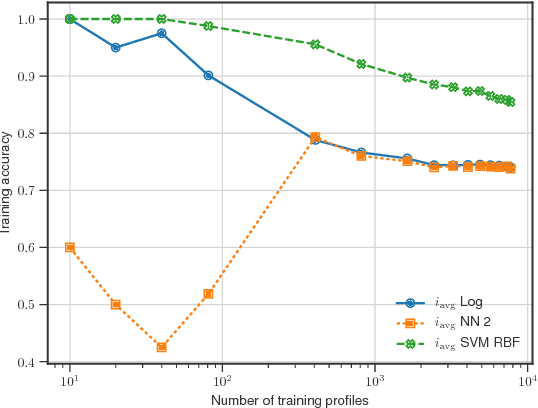
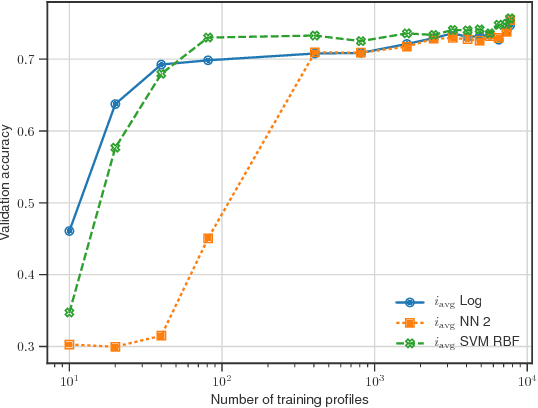
A method to produce personalized classification models to automatically review online dating profiles on Tinder is proposed, based on the user's historical preference. The method takes advantage of a FaceNet facial classification model to extract features which may be related to facial attractiveness. The embeddings from a FaceNet model were used as the features to describe an individual's face. A user reviewed 8,545 online dating profiles. For each reviewed online dating profile, a feature set was constructed from the profile images which contained just one face. Two approaches are presented to go from the set of features for each face, to a set of profile features. A simple logistic regression trained on the embeddings from just 20 profiles could obtain a 65% validation accuracy. A point of diminishing marginal returns was identified to occur around 80 profiles, at which the model accuracy of 73% would only improve marginally after reviewing a significant number of additional profiles.
Refacing: reconstructing anonymized facial features using GANs
Oct 15, 2018
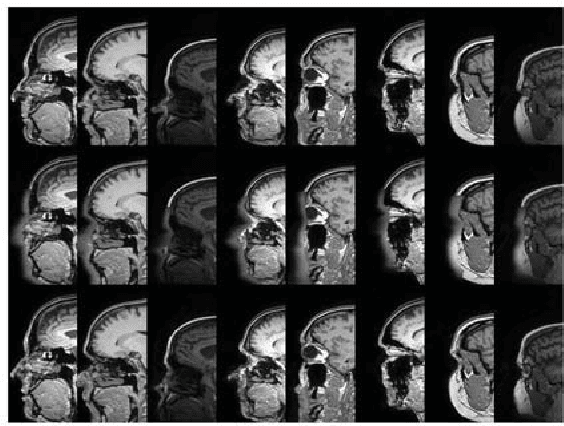
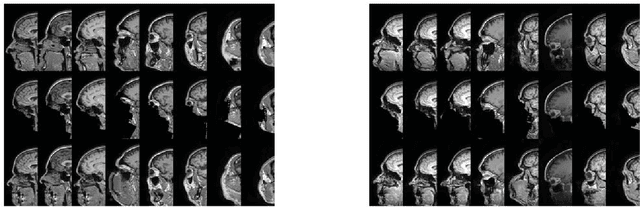
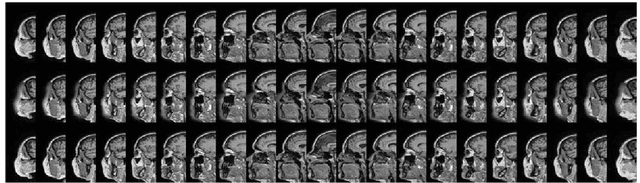
Anonymization of medical images is necessary for protecting the identity of the test subjects, and is therefore an essential step in data sharing. However, recent developments in deep learning may raise the bar on the amount of distortion that needs to be applied to guarantee anonymity. To test such possibilities, we have applied the novel CycleGAN unsupervised image-to-image translation framework on sagittal slices of T1 MR images, in order to reconstruct facial features from anonymized data. We applied the CycleGAN framework on both face-blurred and face-removed images. Our results show that face blurring may not provide adequate protection against malicious attempts at identifying the subjects, while face removal provides more robust anonymization, but is still partially reversible.