 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Recognition with Encoded Local Projections
Sep 11, 2018

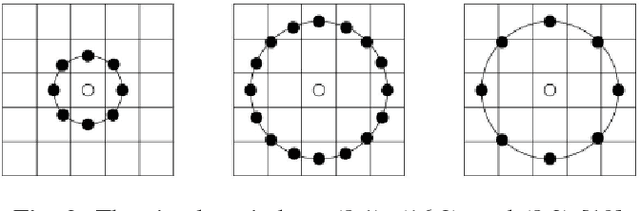

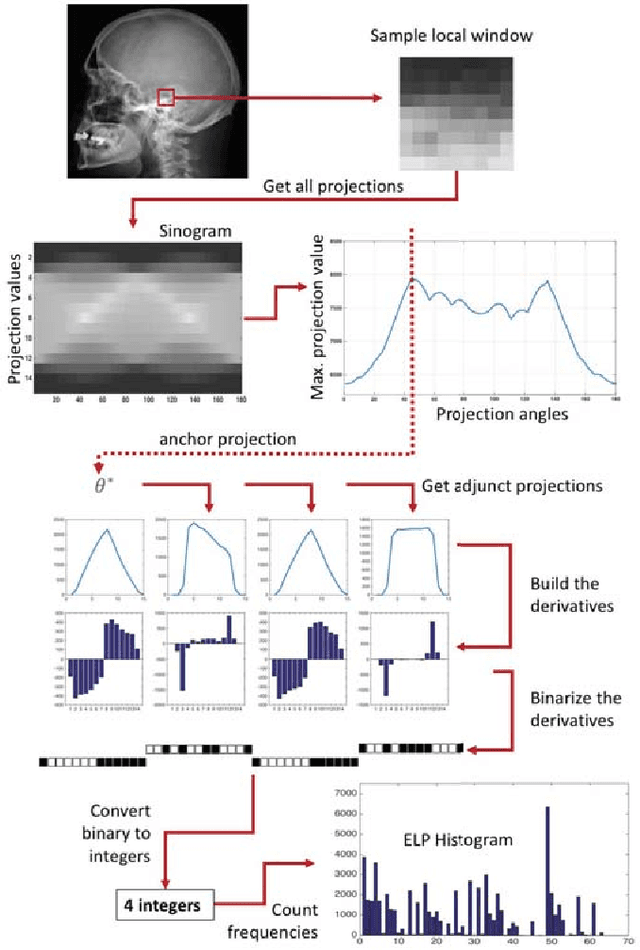
Encoded Local Projections (ELP) is a recently introduced dense sampling image descriptor which uses projections in small neighbourhoods to construct a histogram/descriptor for the entire image. ELP has shown to be as accurate as other state-of-the-art features in searching medical images while being time and resource efficient. This paper attempts for the first time to utilize ELP descriptor as primary features for facial recognition and compare the results with LBP histogram on the Labeled Faces in the Wild dataset. We have evaluated descriptors by comparing the chi-squared distance of each image descriptor versus all others as well as training Support Vector Machines (SVM) with each feature vector. In both cases, the results of ELP were better than LBP in the same sub-image configuration.
BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis
Mar 11, 2022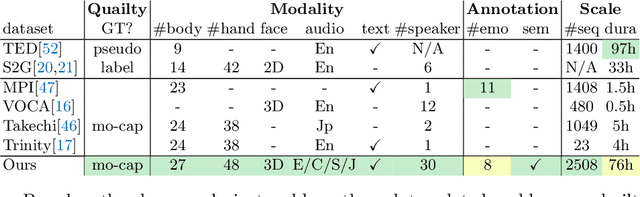
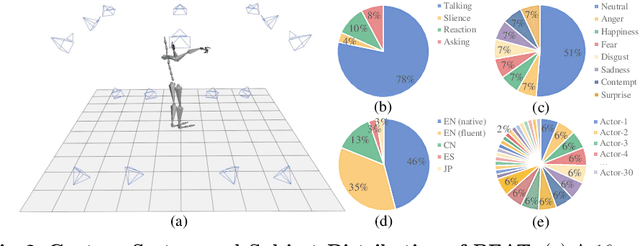

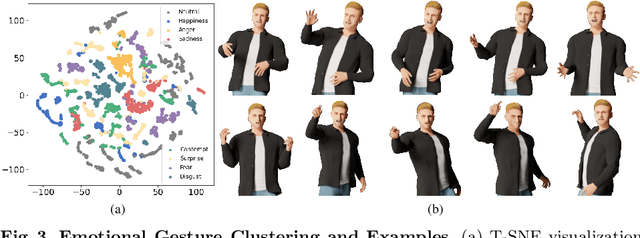
Achieving realistic, vivid, and human-like synthesized conversational gestures conditioned on multi-modal data is still an unsolved problem, due to the lack of available datasets, models and standard evaluation metrics. To address this, we build Body-Expression-Audio-Text dataset, BEAT, which has i) 76 hours, high-quality, multi-modal data captured from 30 speakers talking with eight different emotions and in four different languages, ii) 32 millions frame-level emotion and semantic relevance annotations.Our statistical analysis on BEAT demonstrates the correlation of conversational gestures with facial expressions, emotions, and semantics, in addition to the known correlation with audio, text, and speaker identity. Qualitative and quantitative experiments demonstrate metrics' validness, ground truth data quality, and baseline's state-of-the-art performance. To the best of our knowledge, BEAT is the largest motion capture dataset for investigating the human gestures, which may contribute to a number of different research fields including controllable gesture synthesis, cross-modality analysis, emotional gesture recognition. The data, code and model will be released for research.
Transformation on Computer-Generated Facial Image to Avoid Detection by Spoofing Detector
Apr 12, 2018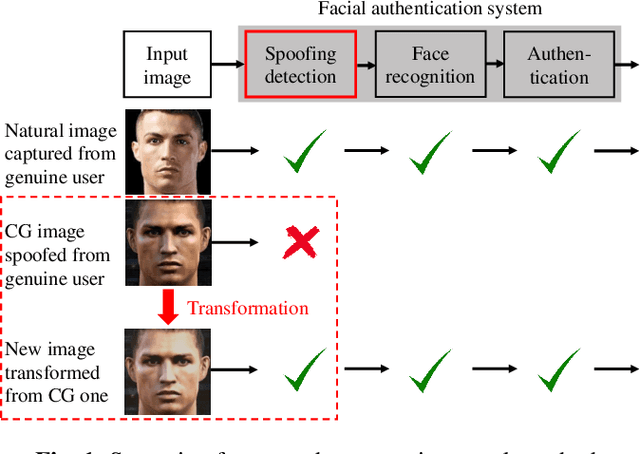
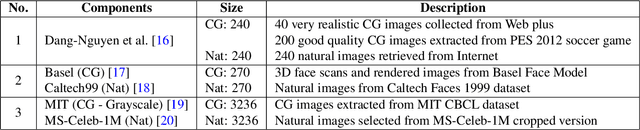
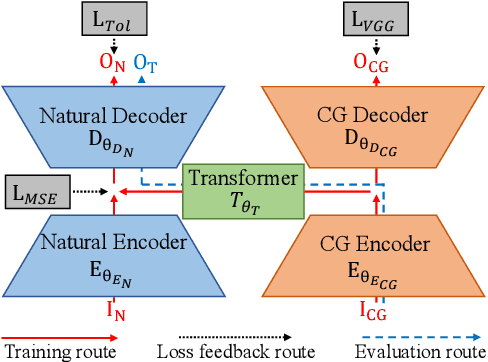

Making computer-generated (CG) images more difficult to detect is an interesting problem in computer graphics and security. While most approaches focus on the image rendering phase, this paper presents a method based on increasing the naturalness of CG facial images from the perspective of spoofing detectors. The proposed method is implemented using a convolutional neural network (CNN) comprising two autoencoders and a transformer and is trained using a black-box discriminator without gradient information. Over 50% of the transformed CG images were not detected by three state-of-the-art spoofing detectors. This capability raises an alarm regarding the reliability of facial authentication systems, which are becoming widely used in daily life.
Computational behavior recognition in child and adolescent psychiatry: A statistical and machine learning analysis plan
May 11, 2022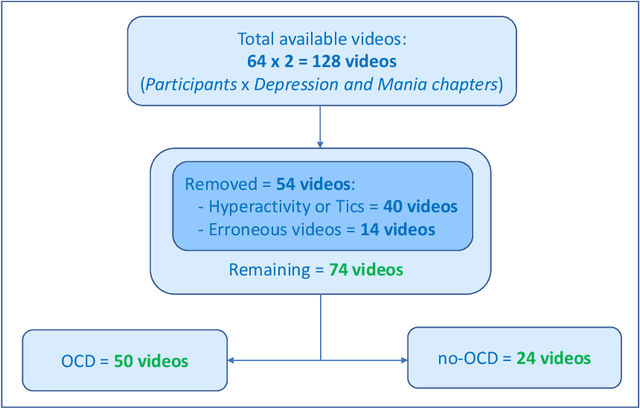
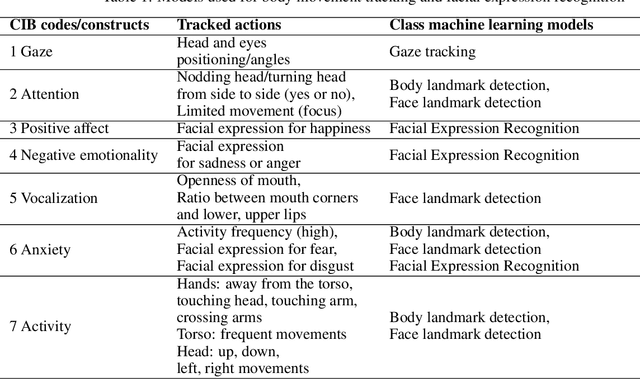
Motivation: Behavioral observations are an important resource in the study and evaluation of psychological phenomena, but it is costly, time-consuming, and susceptible to bias. Thus, we aim to automate coding of human behavior for use in psychotherapy and research with the help of artificial intelligence (AI) tools. Here, we present an analysis plan. Methods: Videos of a gold-standard semi-structured diagnostic interview of 25 youth with obsessive-compulsive disorder (OCD) and 12 youth without a psychiatric diagnosis (no-OCD) will be analyzed. Youth were between 8 and 17 years old. Features from the videos will be extracted and used to compute ratings of behavior, which will be compared to ratings of behavior produced by mental health professionals trained to use a specific behavioral coding manual. We will test the effect of OCD diagnosis on the computationally-derived behavior ratings using multivariate analysis of variance (MANOVA). Using the generated features, a binary classification model will be built and used to classify OCD/no-OCD classes. Discussion: Here, we present a pre-defined plan for how data will be pre-processed, analyzed and presented in the publication of results and their interpretation. A challenge for the proposed study is that the AI approach will attempt to derive behavioral ratings based solely on vision, whereas humans use visual, paralinguistic and linguistic cues to rate behavior. Another challenge will be using machine learning models for body and facial movement detection trained primarily on adults and not on children. If the AI tools show promising results, this pre-registered analysis plan may help reduce interpretation bias. Trial registration: ClinicalTrials.gov - H-18010607
Symmetric Skip Connection Wasserstein GAN for High-Resolution Facial Image Inpainting
Jan 11, 2020
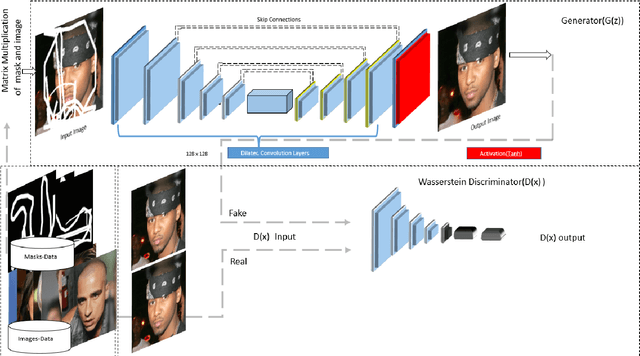
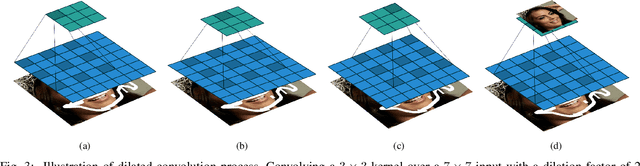

We propose a Symmetric Skip Connection Wasserstein Generative Adversarial Network (S-WGAN) for high-resolution facial image inpainting. The architecture is an encoder-decoder with convolutional blocks, linked by skip connections. The encoder is a feature extractor that captures data abstractions of an input image to learn an end-to-end mapping from an input (binary masked image) to the ground-truth. The decoder uses the learned abstractions to reconstruct the image. With skip connections, S-WGAN transfers image details to the decoder. Also, we propose a Wasserstein-Perceptual loss function to preserve colour and maintain realism on a reconstructed image. We evaluate our method and the state-of-the-art methods on CelebA-HQ dataset. Our results show S-WGAN produces sharper and more realistic images when visually compared with other methods. The quantitative measures show our proposed S-WGAN achieves the best Structure Similarity Index Measure of 0.94.
Real-Time Facial Segmentation and Performance Capture from RGB Input
Apr 10, 2016

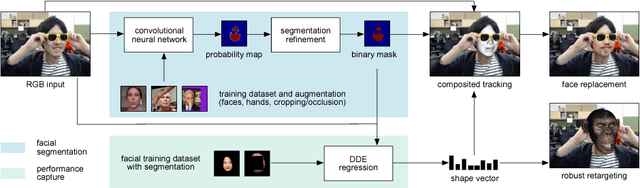
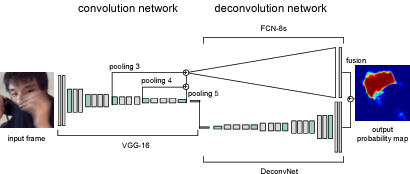
We introduce the concept of unconstrained real-time 3D facial performance capture through explicit semantic segmentation in the RGB input. To ensure robustness, cutting edge supervised learning approaches rely on large training datasets of face images captured in the wild. While impressive tracking quality has been demonstrated for faces that are largely visible, any occlusion due to hair, accessories, or hand-to-face gestures would result in significant visual artifacts and loss of tracking accuracy. The modeling of occlusions has been mostly avoided due to its immense space of appearance variability. To address this curse of high dimensionality, we perform tracking in unconstrained images assuming non-face regions can be fully masked out. Along with recent breakthroughs in deep learning, we demonstrate that pixel-level facial segmentation is possible in real-time by repurposing convolutional neural networks designed originally for general semantic segmentation. We develop an efficient architecture based on a two-stream deconvolution network with complementary characteristics, and introduce carefully designed training samples and data augmentation strategies for improved segmentation accuracy and robustness. We adopt a state-of-the-art regression-based facial tracking framework with segmented face images as training, and demonstrate accurate and uninterrupted facial performance capture in the presence of extreme occlusion and even side views. Furthermore, the resulting segmentation can be directly used to composite partial 3D face models on the input images and enable seamless facial manipulation tasks, such as virtual make-up or face replacement.
Geometric Feature-Based Facial Expression Recognition in Image Sequences Using Multi-Class AdaBoost and Support Vector Machines
Apr 12, 2016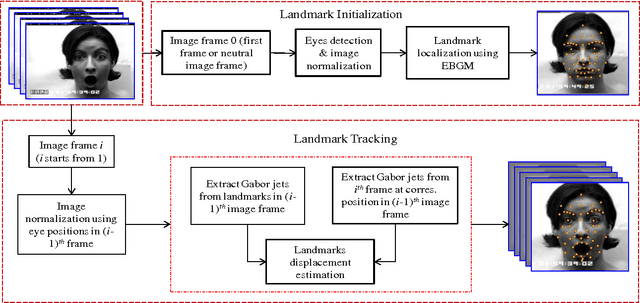

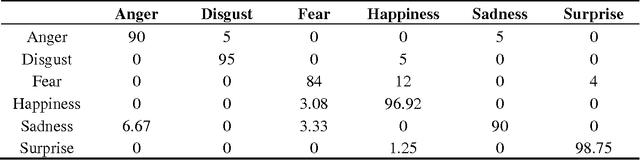

Facial expressions are widely used in the behavioral interpretation of emotions, cognitive science, and social interactions. In this paper, we present a novel method for fully automatic facial expression recognition in facial image sequences. As the facial expression evolves over time facial landmarks are automatically tracked in consecutive video frames, using displacements based on elastic bunch graph matching displacement estimation. Feature vectors from individual landmarks, as well as pairs of landmarks tracking results are extracted, and normalized, with respect to the first frame in the sequence. The prototypical expression sequence for each class of facial expression is formed, by taking the median of the landmark tracking results from the training facial expression sequences. Multi-class AdaBoost with dynamic time warping similarity distance between the feature vector of input facial expression and prototypical facial expression, is used as a weak classifier to select the subset of discriminative feature vectors. Finally, two methods for facial expression recognition are presented, either by using multi-class AdaBoost with dynamic time warping, or by using support vector machine on the boosted feature vectors. The results on the Cohn-Kanade (CK+) facial expression database show a recognition accuracy of 95.17% and 97.35% using multi-class AdaBoost and support vector machines, respectively.
* 21 pages, Sensors Journal, facial expression recognition
Multimodal Approach for Assessing Neuromotor Coordination in Schizophrenia Using Convolutional Neural Networks
Oct 09, 2021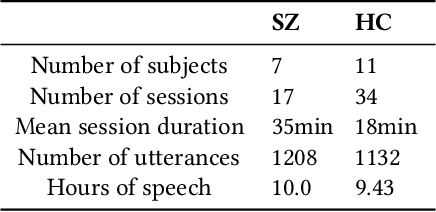
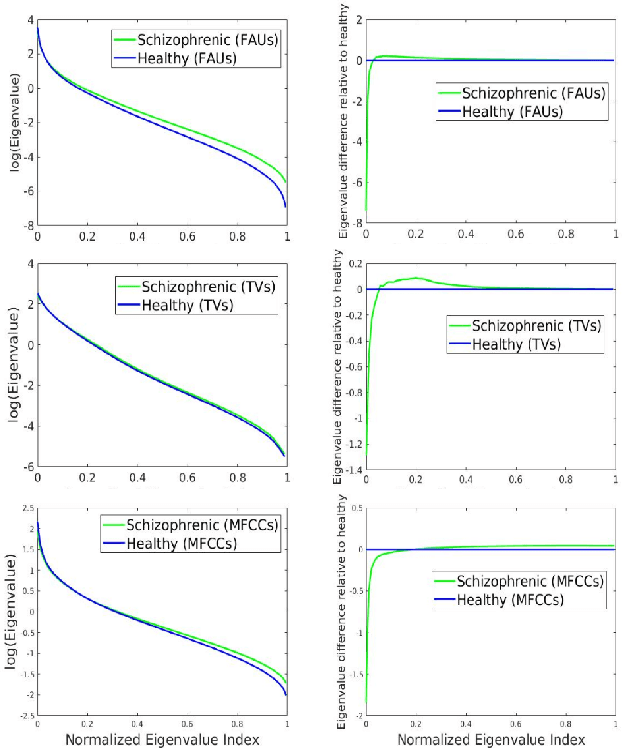

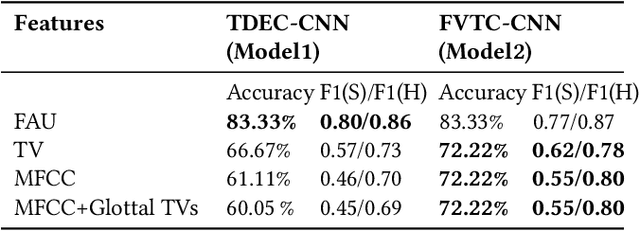
This study investigates the speech articulatory coordination in schizophrenia subjects exhibiting strong positive symptoms (e.g. hallucinations and delusions), using two distinct channel-delay correlation methods. We show that the schizophrenic subjects with strong positive symptoms and who are markedly ill pose complex articulatory coordination pattern in facial and speech gestures than what is observed in healthy subjects. This distinction in speech coordination pattern is used to train a multimodal convolutional neural network (CNN) which uses video and audio data during speech to distinguish schizophrenic patients with strong positive symptoms from healthy subjects. We also show that the vocal tract variables (TVs) which correspond to place of articulation and glottal source outperform the Mel-frequency Cepstral Coefficients (MFCCs) when fused with Facial Action Units (FAUs) in the proposed multimodal network. For the clinical dataset we collected, our best performing multimodal network improves the mean F1 score for detecting schizophrenia by around 18% with respect to the full vocal tract coordination (FVTC) baseline method implemented with fusing FAUs and MFCCs.
Facial Aging and Rejuvenation by Conditional Multi-Adversarial Autoencoder with Ordinal Regression
Apr 08, 2018
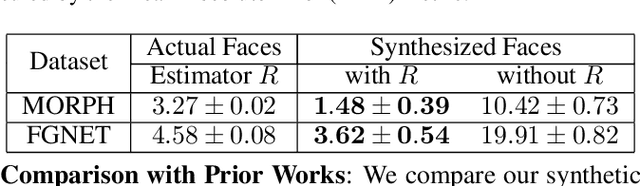
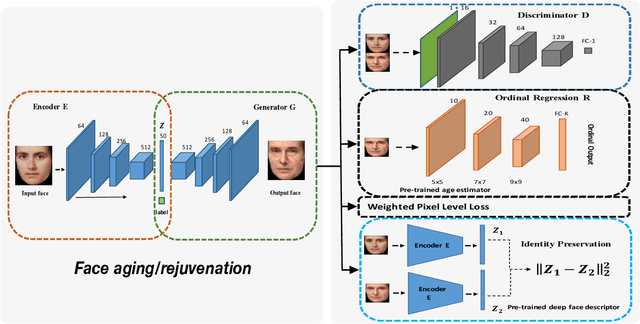

Facial aging and facial rejuvenation analyze a given face photograph to predict a future look or estimate a past look of the person. To achieve this, it is critical to preserve human identity and the corresponding aging progression and regression with high accuracy. However, existing methods cannot simultaneously handle these two objectives well. We propose a novel generative adversarial network based approach, named the Conditional Multi-Adversarial AutoEncoder with Ordinal Regression (CMAAE-OR). It utilizes an age estimation technique to control the aging accuracy and takes a high-level feature representation to preserve personalized identity. Specifically, the face is first mapped to a latent vector through a convolutional encoder. The latent vector is then projected onto the face manifold conditional on the age through a deconvolutional generator. The latent vector preserves personalized face features and the age controls facial aging and rejuvenation. A discriminator and an ordinal regression are imposed on the encoder and the generator in tandem, making the generated face images to be more photorealistic while simultaneously exhibiting desirable aging effects. Besides, a high-level feature representation is utilized to preserve personalized identity of the generated face. Experiments on two benchmark datasets demonstrate appealing performance of the proposed method over the state-of-the-art.