 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
DeepFakes: Detecting Forged and Synthetic Media Content Using Machine Learning
Sep 07, 2021
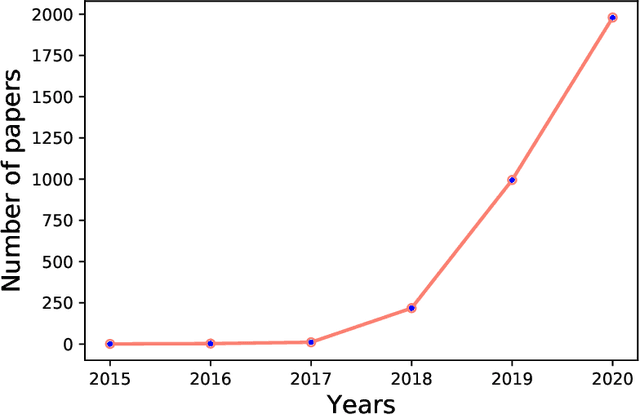
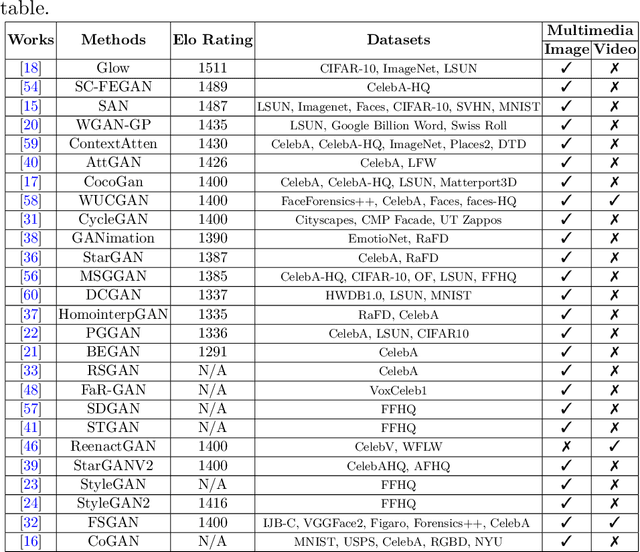
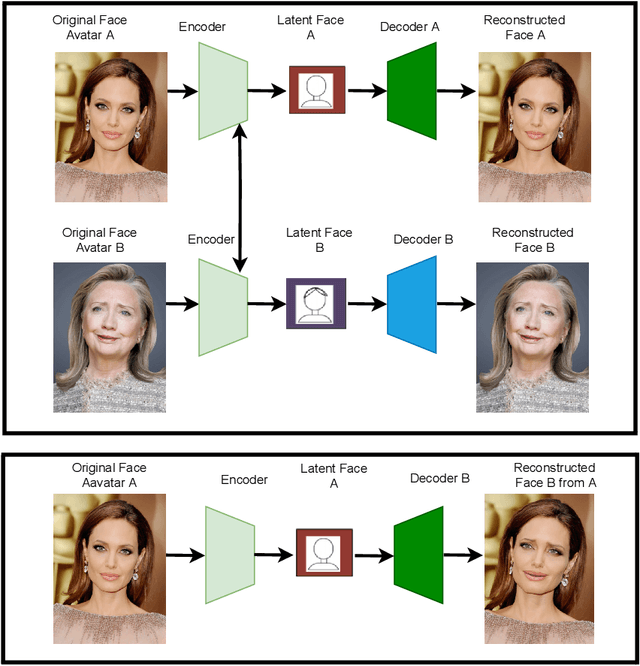
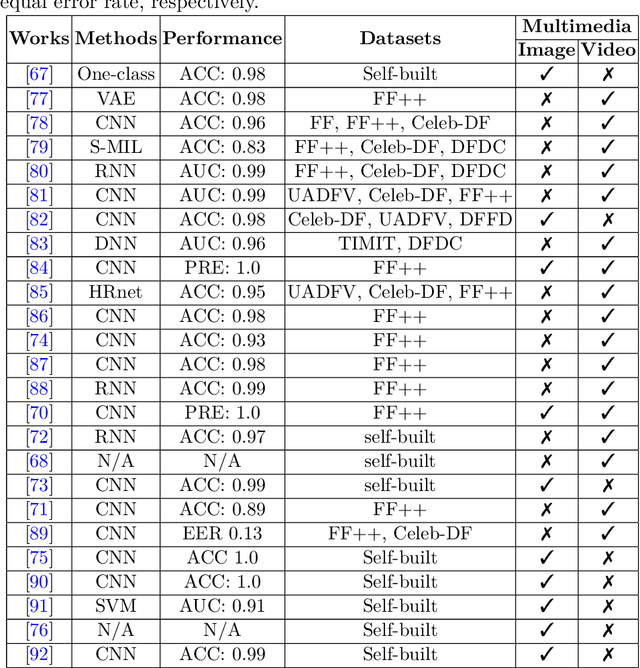
The rapid advancement in deep learning makes the differentiation of authentic and manipulated facial images and video clips unprecedentedly harder. The underlying technology of manipulating facial appearances through deep generative approaches, enunciated as DeepFake that have emerged recently by promoting a vast number of malicious face manipulation applications. Subsequently, the need of other sort of techniques that can assess the integrity of digital visual content is indisputable to reduce the impact of the creations of DeepFake. A large body of research that are performed on DeepFake creation and detection create a scope of pushing each other beyond the current status. This study presents challenges, research trends, and directions related to DeepFake creation and detection techniques by reviewing the notable research in the DeepFake domain to facilitate the development of more robust approaches that could deal with the more advance DeepFake in the future.
EMOPAIN Challenge 2020: Multimodal Pain Evaluation from Facial and Bodily Expressions
Jan 25, 2020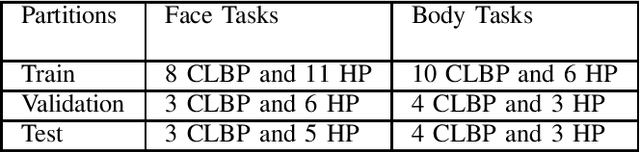
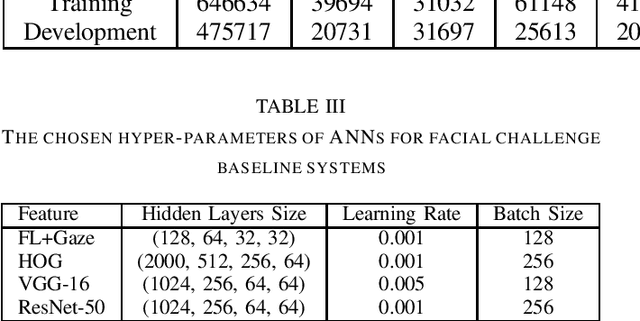
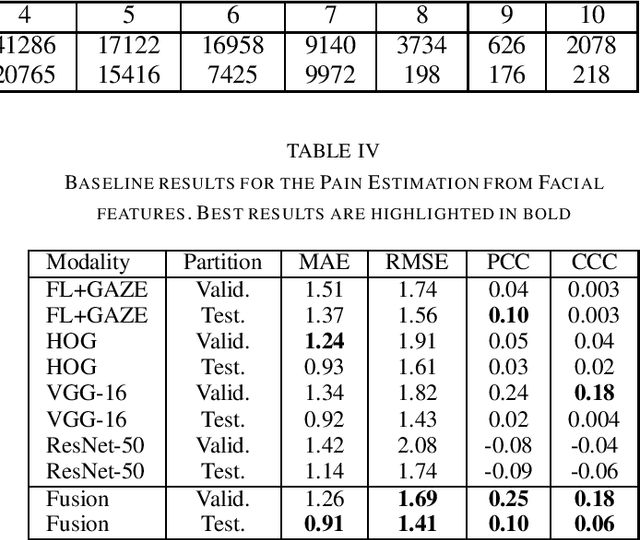
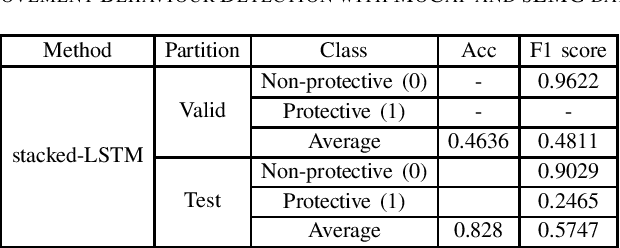
The EmoPain 2020 Challenge is the first international competition aimed at creating a uniform platform for the comparison of machine learning and multimedia processing methods of automatic chronic pain assessment from human expressive behaviour, and also the identification of pain-related behaviours. The objective of the challenge is to promote research in the development of assistive technologies that help improve the quality of life for people with chronic pain via real-time monitoring and feedback to help manage their condition and remain physically active. The challenge also aims to encourage the use of the relatively underutilised, albeit vital bodily expression signals for automatic pain and pain-related emotion recognition. This paper presents a description of the challenge, competition guidelines, bench-marking dataset, and the baseline systems' architecture and performance on the three sub-tasks: pain estimation from facial expressions, pain recognition from multimodal movement, and protective movement behaviour detection.
DeepCoder: Semi-parametric Variational Autoencoders for Automatic Facial Action Coding
Aug 05, 2017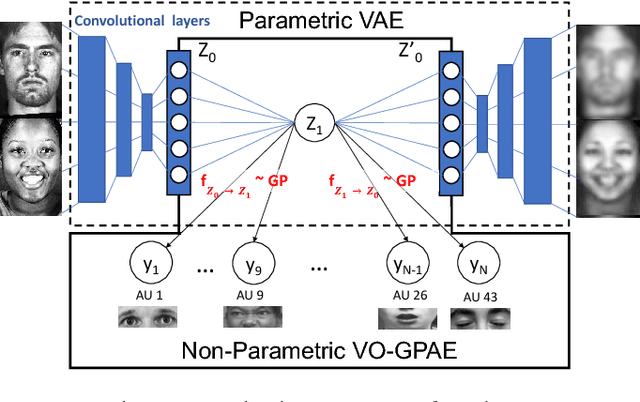
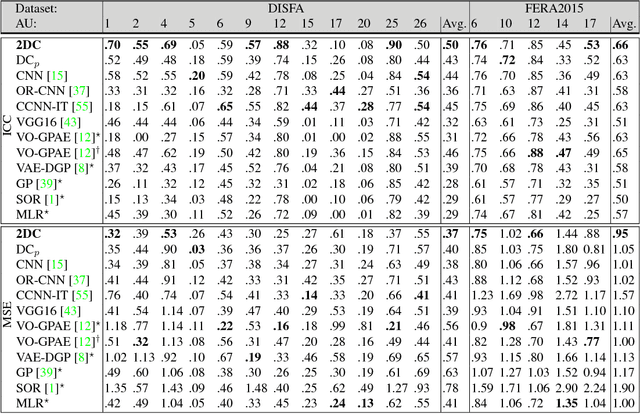
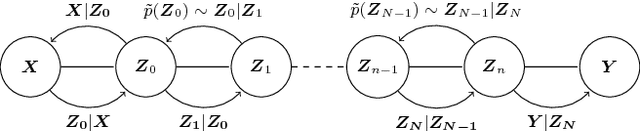
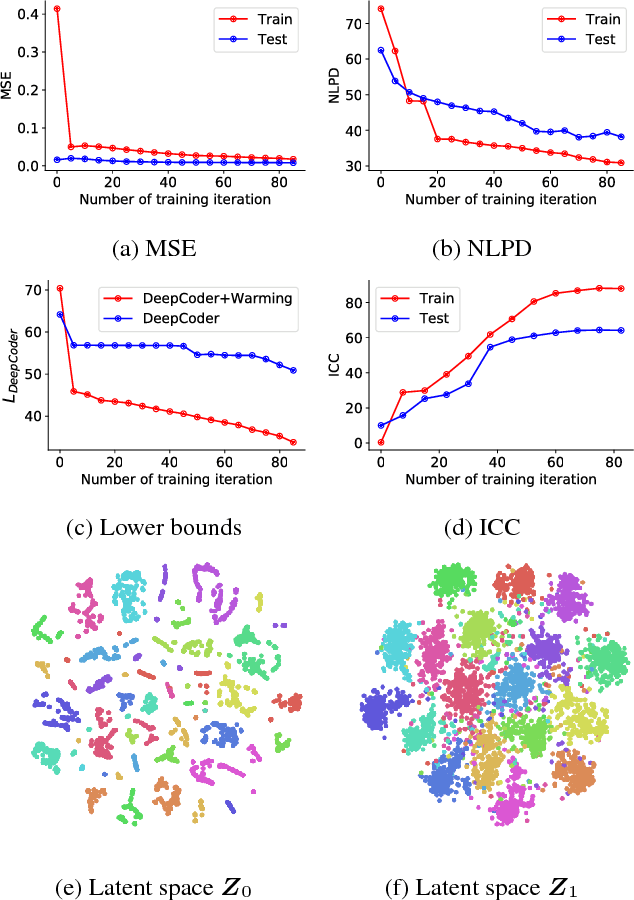
Human face exhibits an inherent hierarchy in its representations (i.e., holistic facial expressions can be encoded via a set of facial action units (AUs) and their intensity). Variational (deep) auto-encoders (VAE) have shown great results in unsupervised extraction of hierarchical latent representations from large amounts of image data, while being robust to noise and other undesired artifacts. Potentially, this makes VAEs a suitable approach for learning facial features for AU intensity estimation. Yet, most existing VAE-based methods apply classifiers learned separately from the encoded features. By contrast, the non-parametric (probabilistic) approaches, such as Gaussian Processes (GPs), typically outperform their parametric counterparts, but cannot deal easily with large amounts of data. To this end, we propose a novel VAE semi-parametric modeling framework, named DeepCoder, which combines the modeling power of parametric (convolutional) and nonparametric (ordinal GPs) VAEs, for joint learning of (1) latent representations at multiple levels in a task hierarchy1, and (2) classification of multiple ordinal outputs. We show on benchmark datasets for AU intensity estimation that the proposed DeepCoder outperforms the state-of-the-art approaches, and related VAEs and deep learning models.
BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis
Mar 10, 2022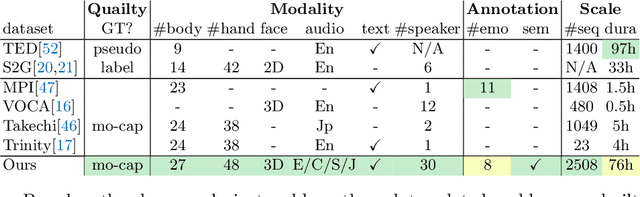
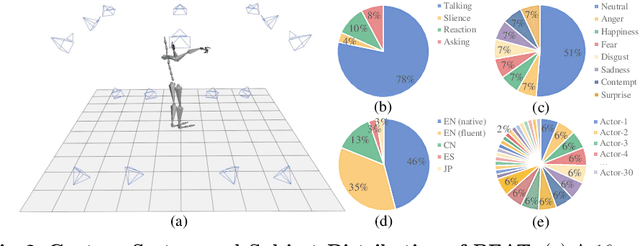

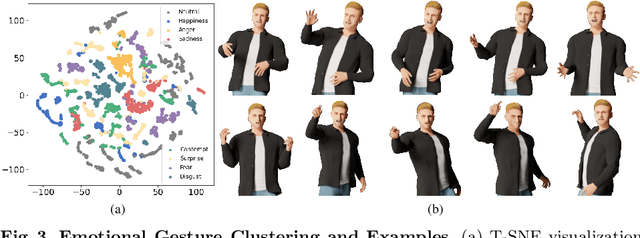
Achieving realistic, vivid, and human-like synthesized conversational gestures conditioned on multi-modal data is still an unsolved problem, due to the lack of available datasets, models and standard evaluation metrics. To address this, we build Body-Expression-Audio-Text dataset, BEAT, which has i) 76 hours, high-quality, multi-modal data captured from 30 speakers talking with eight different emotions and in four different languages, ii) 32 millions frame-level emotion and semantic relevance annotations.Our statistical analysis on BEAT demonstrates the correlation of conversational gestures with facial expressions, emotions, and semantics, in addition to the known correlation with audio, text, and speaker identity. Qualitative and quantitative experiments demonstrate metrics' validness, ground truth data quality, and baseline's state-of-the-art performance. To the best of our knowledge, BEAT is the largest motion capture dataset for investigating the human gestures, which may contribute to a number of different research fields including controllable gesture synthesis, cross-modality analysis, emotional gesture recognition. The data, code and model will be released for research.
High-fidelity GAN Inversion with Padding Space
Mar 21, 2022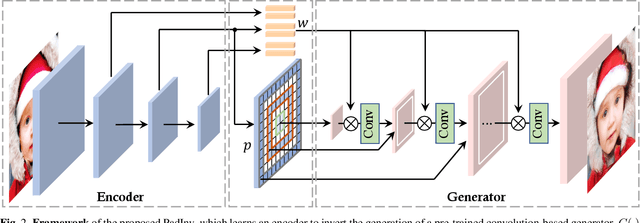



Inverting a Generative Adversarial Network (GAN) facilitates a wide range of image editing tasks using pre-trained generators. Existing methods typically employ the latent space of GANs as the inversion space yet observe the insufficient recovery of spatial details. In this work, we propose to involve the padding space of the generator to complement the latent space with spatial information. Concretely, we replace the constant padding (e.g., usually zeros) used in convolution layers with some instance-aware coefficients. In this way, the inductive bias assumed in the pre-trained model can be appropriately adapted to fit each individual image. Through learning a carefully designed encoder, we manage to improve the inversion quality both qualitatively and quantitatively, outperforming existing alternatives. We then demonstrate that such a space extension barely affects the native GAN manifold, hence we can still reuse the prior knowledge learned by GANs for various downstream applications. Beyond the editing tasks explored in prior arts, our approach allows a more flexible image manipulation, such as the separate control of face contour and facial details, and enables a novel editing manner where users can customize their own manipulations highly efficiently.
Deep Temporal Appearance-Geometry Network for Facial Expression Recognition
Mar 05, 2015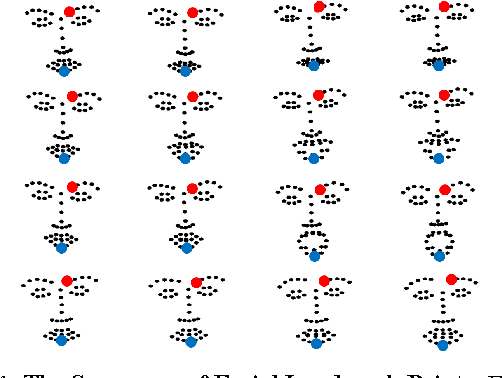

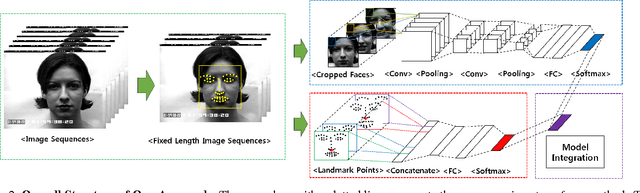

Temporal information can provide useful features for recognizing facial expressions. However, to manually design useful features requires a lot of effort. In this paper, to reduce this effort, a deep learning technique which is regarded as a tool to automatically extract useful features from raw data, is adopted. Our deep network is based on two different models. The first deep network extracts temporal geometry features from temporal facial landmark points, while the other deep network extracts temporal appearance features from image sequences . These two models are combined in order to boost the performance of the facial expression recognition. Through several experiments, we showed that the two models cooperate with each other. As a result, we achieved superior performance to other state-of-the-art methods in CK+ and Oulu-CASIA databases. Furthermore, one of the main contributions of this paper is that our deep network catches the facial action points automatically.
Metaethical Perspectives on 'Benchmarking' AI Ethics
Apr 11, 2022Benchmarks are seen as the cornerstone for measuring technical progress in Artificial Intelligence (AI) research and have been developed for a variety of tasks ranging from question answering to facial recognition. An increasingly prominent research area in AI is ethics, which currently has no set of benchmarks nor commonly accepted way for measuring the 'ethicality' of an AI system. In this paper, drawing upon research in moral philosophy and metaethics, we argue that it is impossible to develop such a benchmark. As such, alternative mechanisms are necessary for evaluating whether an AI system is 'ethical'. This is especially pressing in light of the prevalence of applied, industrial AI research. We argue that it makes more sense to talk about 'values' (and 'value alignment') rather than 'ethics' when considering the possible actions of present and future AI systems. We further highlight that, because values are unambiguously relative, focusing on values forces us to consider explicitly what the values are and whose values they are. Shifting the emphasis from ethics to values therefore gives rise to several new ways of understanding how researchers might advance research programmes for robustly safe or beneficial AI. We conclude by highlighting a number of possible ways forward for the field as a whole, and we advocate for different approaches towards more value-aligned AI research.
Multimodal Approach for Assessing Neuromotor Coordination in Schizophrenia Using Convolutional Neural Networks
Oct 09, 2021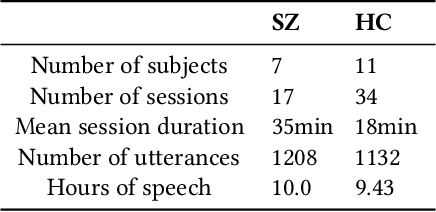
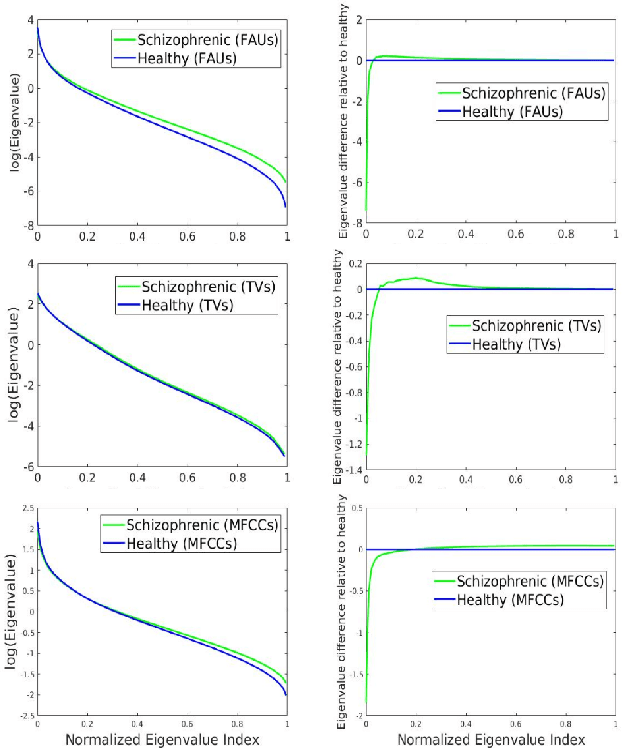

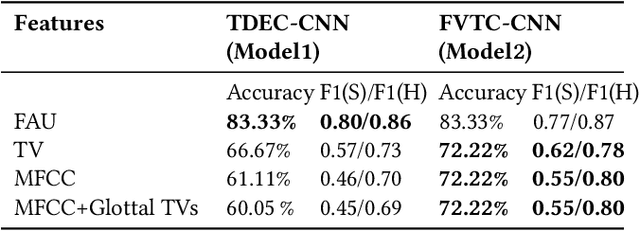
This study investigates the speech articulatory coordination in schizophrenia subjects exhibiting strong positive symptoms (e.g. hallucinations and delusions), using two distinct channel-delay correlation methods. We show that the schizophrenic subjects with strong positive symptoms and who are markedly ill pose complex articulatory coordination pattern in facial and speech gestures than what is observed in healthy subjects. This distinction in speech coordination pattern is used to train a multimodal convolutional neural network (CNN) which uses video and audio data during speech to distinguish schizophrenic patients with strong positive symptoms from healthy subjects. We also show that the vocal tract variables (TVs) which correspond to place of articulation and glottal source outperform the Mel-frequency Cepstral Coefficients (MFCCs) when fused with Facial Action Units (FAUs) in the proposed multimodal network. For the clinical dataset we collected, our best performing multimodal network improves the mean F1 score for detecting schizophrenia by around 18% with respect to the full vocal tract coordination (FVTC) baseline method implemented with fusing FAUs and MFCCs.
Facial Expressions Tracking and Recognition: Database Protocols for Systems Validation and Evaluation
Jun 02, 2015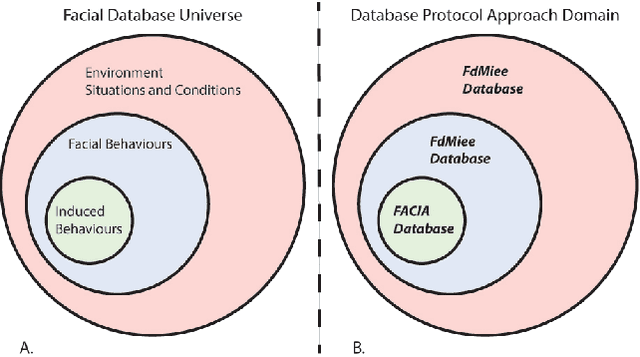
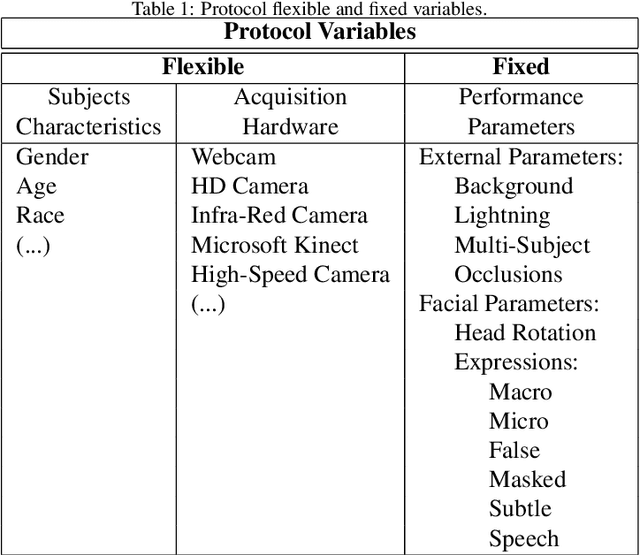

Each human face is unique. It has its own shape, topology, and distinguishing features. As such, developing and testing facial tracking systems are challenging tasks. The existing face recognition and tracking algorithms in Computer Vision mainly specify concrete situations according to particular goals and applications, requiring validation methodologies with data that fits their purposes. However, a database that covers all possible variations of external and factors does not exist, increasing researchers' work in acquiring their own data or compiling groups of databases. To address this shortcoming, we propose a methodology for facial data acquisition through definition of fundamental variables, such as subject characteristics, acquisition hardware, and performance parameters. Following this methodology, we also propose two protocols that allow the capturing of facial behaviors under uncontrolled and real-life situations. As validation, we executed both protocols which lead to creation of two sample databases: FdMiee (Facial database with Multi input, expressions, and environments) and FACIA (Facial Multimodal database driven by emotional induced acting). Using different types of hardware, FdMiee captures facial information under environmental and facial behaviors variations. FACIA is an extension of FdMiee introducing a pipeline to acquire additional facial behaviors and speech using an emotion-acting method. Therefore, this work eases the creation of adaptable database according to algorithm's requirements and applications, leading to simplified validation and testing processes.