 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Adversarial Graph Representation Adaptation for Cross-Domain Facial Expression Recognition
Aug 04, 2020
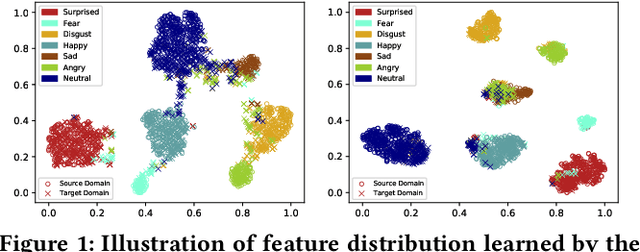
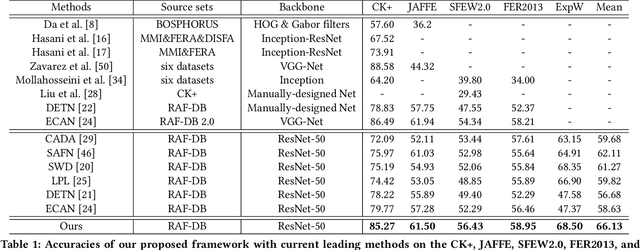
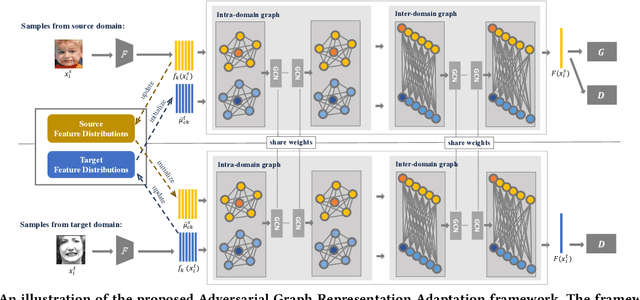
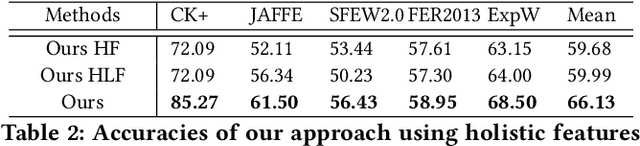
Data inconsistency and bias are inevitable among different facial expression recognition (FER) datasets due to subjective annotating process and different collecting conditions. Recent works resort to adversarial mechanisms that learn domain-invariant features to mitigate domain shift. However, most of these works focus on holistic feature adaptation, and they ignore local features that are more transferable across different datasets. Moreover, local features carry more detailed and discriminative content for expression recognition, and thus integrating local features may enable fine-grained adaptation. In this work, we propose a novel Adversarial Graph Representation Adaptation (AGRA) framework that unifies graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation. To achieve this, we first build a graph to correlate holistic and local regions within each domain and another graph to correlate these regions across different domains. Then, we learn the per-class statistical distribution of each domain and extract holistic-local features from the input image to initialize the corresponding graph nodes. Finally, we introduce two stacked graph convolution networks to propagate holistic-local feature within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. In this way, the AGRA framework can adaptively learn fine-grained domain-invariant features and thus facilitate cross-domain expression recognition. We conduct extensive and fair experiments on several popular benchmarks and show that the proposed AGRA framework achieves superior performance over previous state-of-the-art methods.
Conditional De-Identification of 3D Magnetic Resonance Images
Oct 18, 2021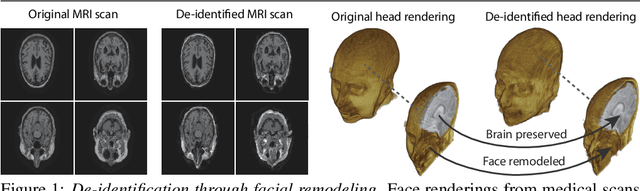
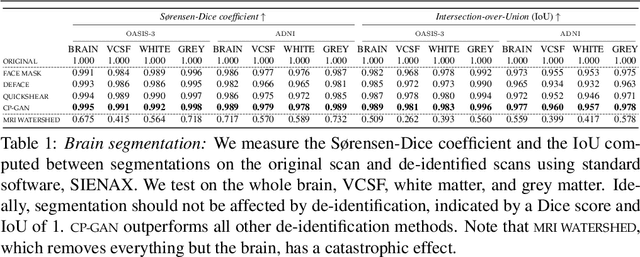
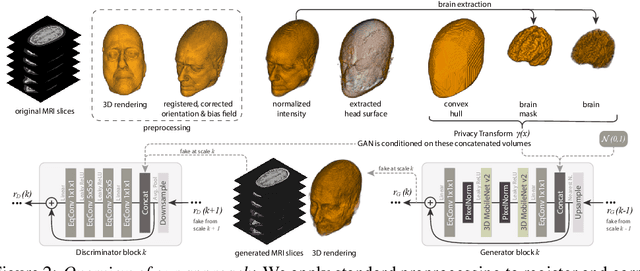
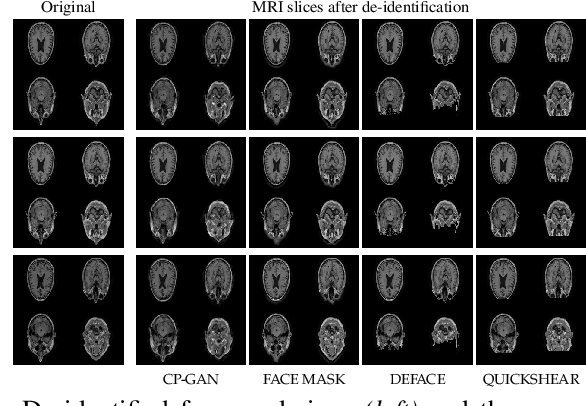
Privacy protection of medical image data is challenging. Even if metadata is removed, brain scans are vulnerable to attacks that match renderings of the face to facial image databases. Solutions have been developed to de-identify diagnostic scans by obfuscating or removing parts of the face. However, these solutions either fail to reliably hide the patient's identity or are so aggressive that they impair further analyses. We propose a new class of de-identification techniques that, instead of removing facial features, remodels them. Our solution relies on a conditional multi-scale GAN architecture. It takes a patient's MRI scan as input and generates a 3D volume conditioned on the patient's brain, which is preserved exactly, but where the face has been de-identified through remodeling. We demonstrate that our approach preserves privacy far better than existing techniques, without compromising downstream medical analyses. Analyses were run on the OASIS-3 and ADNI corpora.
Human Emotion Classification based on EEG Signals Using Recurrent Neural Network And KNN
May 10, 2022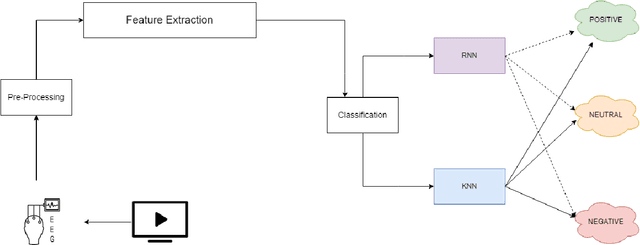
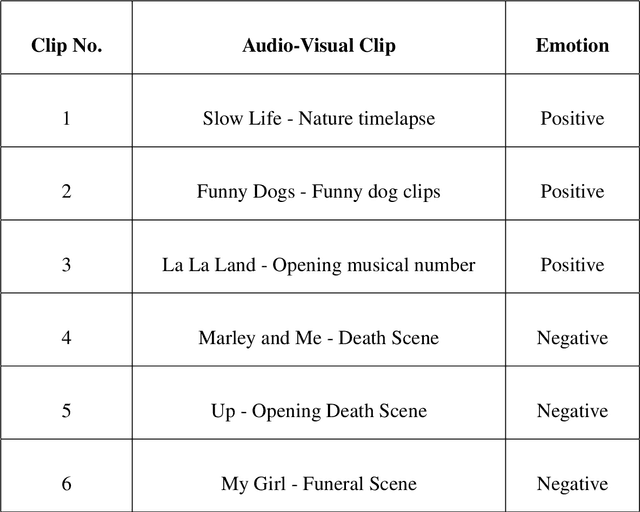
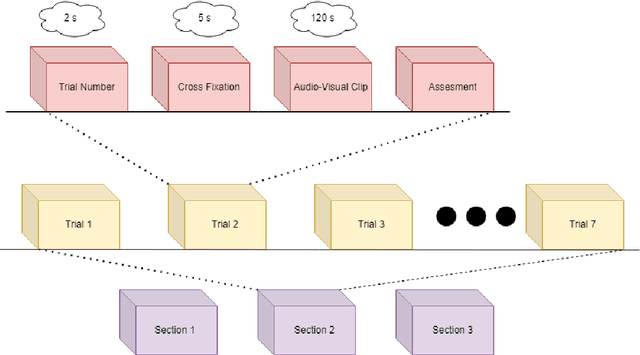
In human contact, emotion is very crucial. Attributes like words, voice intonation, facial expressions, and kinesics can all be used to portray one's feelings. However, brain-computer interface (BCI) devices have not yet reached the level required for emotion interpretation. With the rapid development of machine learning algorithms, dry electrode techniques, and different real-world applications of the brain-computer interface for normal individuals, emotion categorization from EEG data has recently gotten a lot of attention. Electroencephalogram (EEG) signals are a critical resource for these systems. The primary benefit of employing EEG signals is that they reflect true emotion and are easily resolved by computer systems. In this work, EEG signals associated with good, neutral, and negative emotions were identified using channel selection preprocessing. However, researchers had a limited grasp of the specifics of the link between various emotional states until now. To identify EEG signals, we used discrete wavelet transform and machine learning techniques such as recurrent neural network (RNN) and k-nearest neighbor (kNN) algorithm. Initially, the classifier methods were utilized for channel selection. As a result, final feature vectors were created by integrating the features of EEG segments from these channels. Using the RNN and kNN algorithms, the final feature vectors with connected positive, neutral, and negative emotions were categorized independently. The classification performance of both techniques is computed and compared. Using RNN and kNN, the average overall accuracies were 94.844 % and 93.438 %, respectively.
Facial Expressions recognition Based on Principal Component Analysis (PCA)
Dec 23, 2014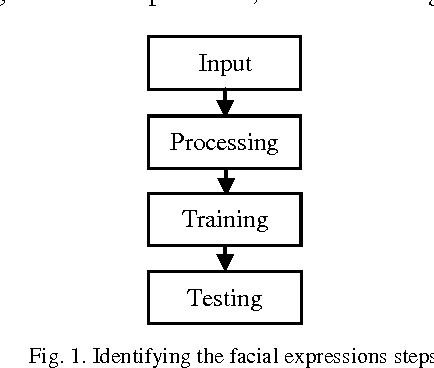

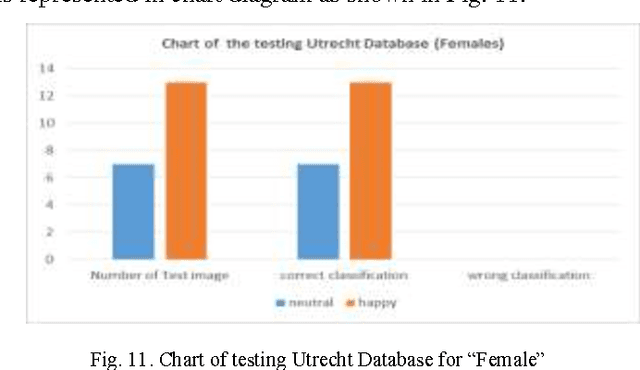
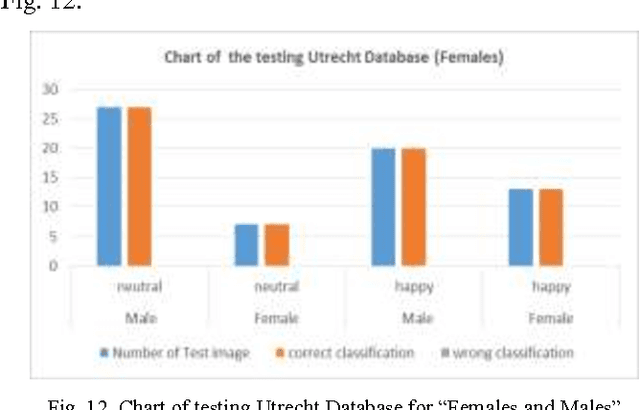
The facial expression recognition is an ocular task that can be performed without human discomfort, is really a speedily growing on the computer research field. There are many applications and programs uses facial expression to evaluate human character, judgment, feelings, and viewpoint. The process of recognizing facial expression is a hard task due to the several circumstances such as facial occlusions, face shape, illumination, face colors, and etc. This paper present a PCA methodology to distinguish expressions of faces under different circumstances and identifying it. Relies on Eigen faces technique using standard Data base images. So as to overcome the problem of difficulty to computers to identify the features and expressions of persons.
Using Photorealistic Face Synthesis and Domain Adaptation to Improve Facial Expression Analysis
May 17, 2019
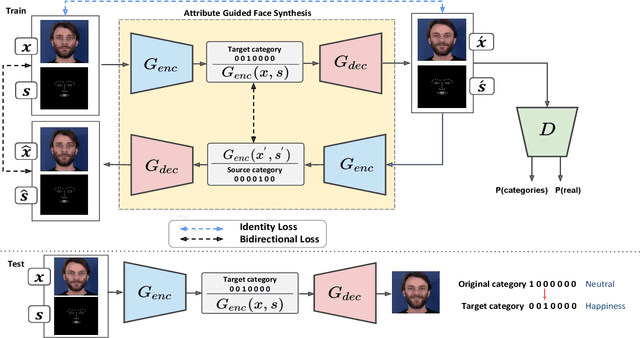

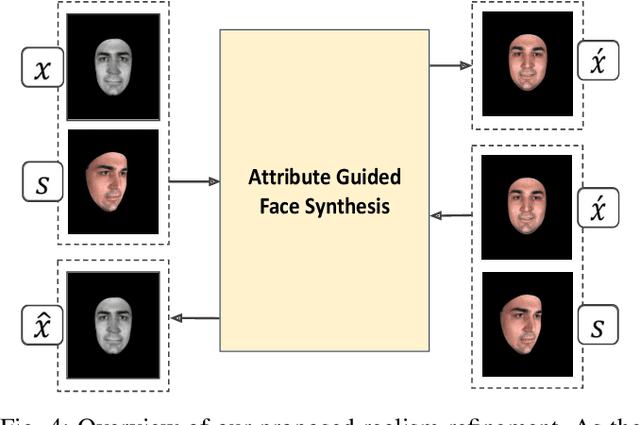
Cross-domain synthesizing realistic faces to learn deep models has attracted increasing attention for facial expression analysis as it helps to improve the performance of expression recognition accuracy despite having small number of real training images. However, learning from synthetic face images can be problematic due to the distribution discrepancy between low-quality synthetic images and real face images and may not achieve the desired performance when the learned model applies to real world scenarios. To this end, we propose a new attribute guided face image synthesis to perform a translation between multiple image domains using a single model. In addition, we adopt the proposed model to learn from synthetic faces by matching the feature distributions between different domains while preserving each domain's characteristics. We evaluate the effectiveness of the proposed approach on several face datasets on generating realistic face images. We demonstrate that the expression recognition performance can be enhanced by benefiting from our face synthesis model. Moreover, we also conduct experiments on a near-infrared dataset containing facial expression videos of drivers to assess the performance using in-the-wild data for driver emotion recognition.
Improving Speech Related Facial Action Unit Recognition by Audiovisual Information Fusion
Jun 29, 2017
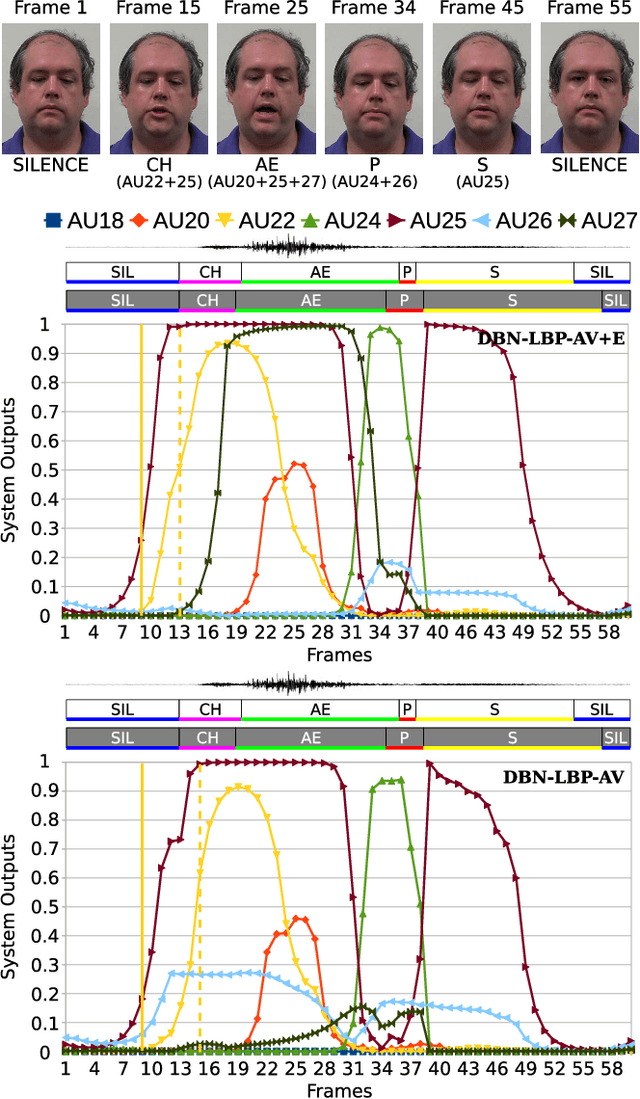
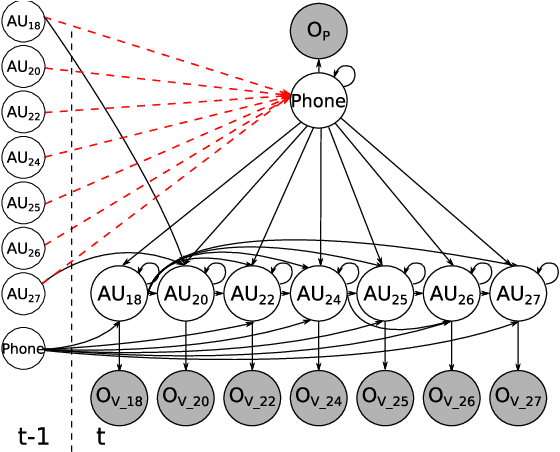
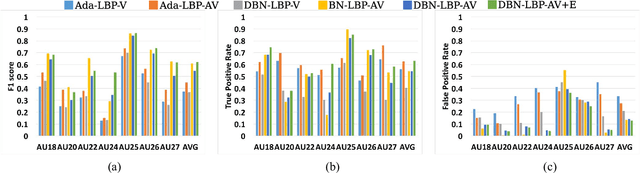
It is challenging to recognize facial action unit (AU) from spontaneous facial displays, especially when they are accompanied by speech. The major reason is that the information is extracted from a single source, i.e., the visual channel, in the current practice. However, facial activity is highly correlated with voice in natural human communications. Instead of solely improving visual observations, this paper presents a novel audiovisual fusion framework, which makes the best use of visual and acoustic cues in recognizing speech-related facial AUs. In particular, a dynamic Bayesian network (DBN) is employed to explicitly model the semantic and dynamic physiological relationships between AUs and phonemes as well as measurement uncertainty. A pilot audiovisual AU-coded database has been collected to evaluate the proposed framework, which consists of a "clean" subset containing frontal faces under well controlled circumstances and a challenging subset with large head movements and occlusions. Experiments on this database have demonstrated that the proposed framework yields significant improvement in recognizing speech-related AUs compared to the state-of-the-art visual-based methods especially for those AUs whose visual observations are impaired during speech, and more importantly also outperforms feature-level fusion methods by explicitly modeling and exploiting physiological relationships between AUs and phonemes.
Self-Paced Deep Regression Forests with Consideration on Ranking Fairness
Dec 28, 2021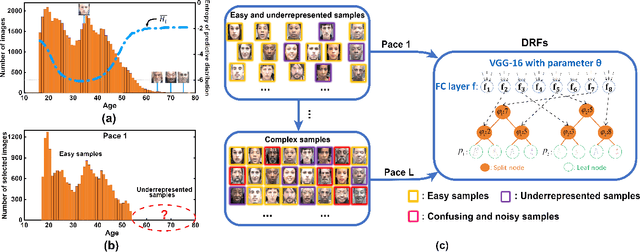
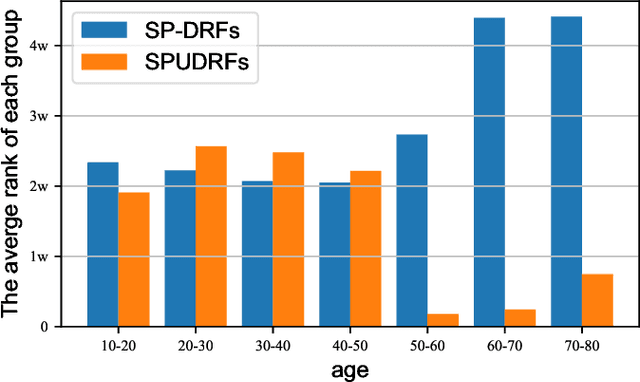
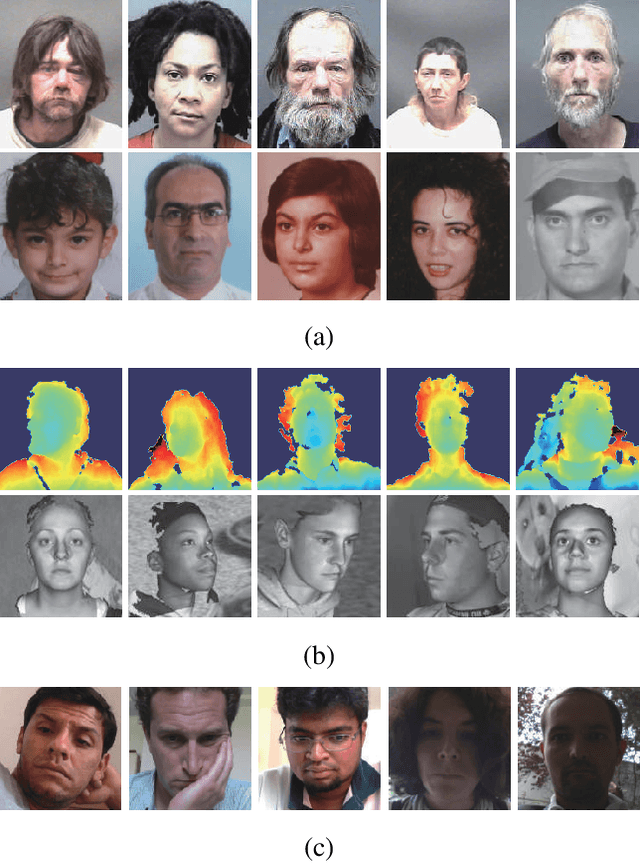
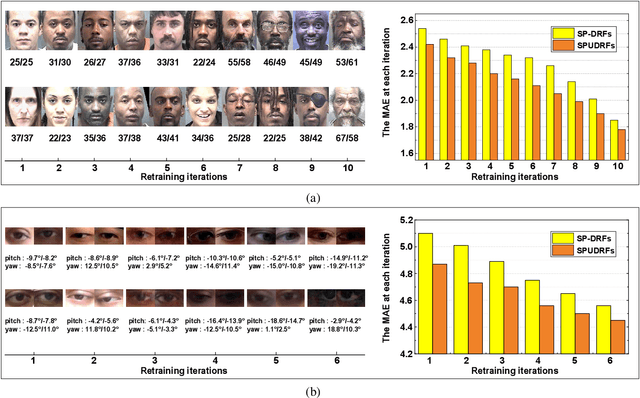
Deep discriminative models (DDMs), such as deep regression forests, deep neural decision forests, have been extensively studied recently to solve problems like facial age estimation, head pose estimation, gaze estimation and so forth. Such problems are challenging in part because a large amount of effective training data without noise and bias is often not available. While some progress has been achieved through learning more discriminative features, or reweighting samples, we argue what is more desirable is to learn gradually to discriminate like human beings. Then, we resort to self-paced learning (SPL). But a natural question arises: can self-paced regime lead DDMs to achieve more robust and less biased solutions? A serious problem with SPL, which is firstly discussed by this work, is it tends to aggravate the bias of solutions, especially for obvious imbalanced data. To this end, this paper proposes a new self-paced paradigm for deep discriminative model, which distinguishes noisy and underrepresented examples according to the output likelihood and entropy associated with each example, and tackle the fundamental ranking problem in SPL from a new perspective: fairness. This paradigm is fundamental, and could be easily combined with a variety of DDMs. Extensive experiments on three computer vision tasks, such as facial age estimation, head pose estimation and gaze estimation, demonstrate the efficacy of our paradigm. To the best of our knowledge, our work is the first paper in the literature of SPL that considers ranking fairness for self-paced regime construction.
On Improving Cross-dataset Generalization of Deepfake Detectors
Apr 08, 2022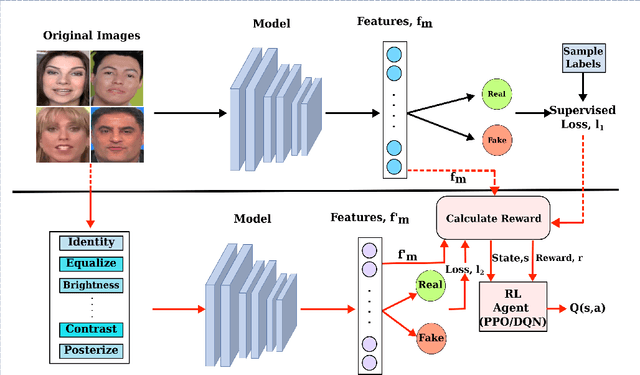
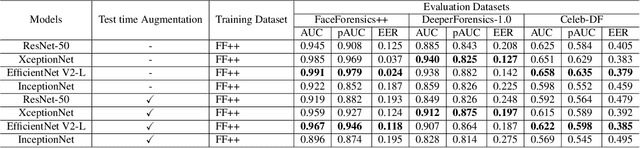
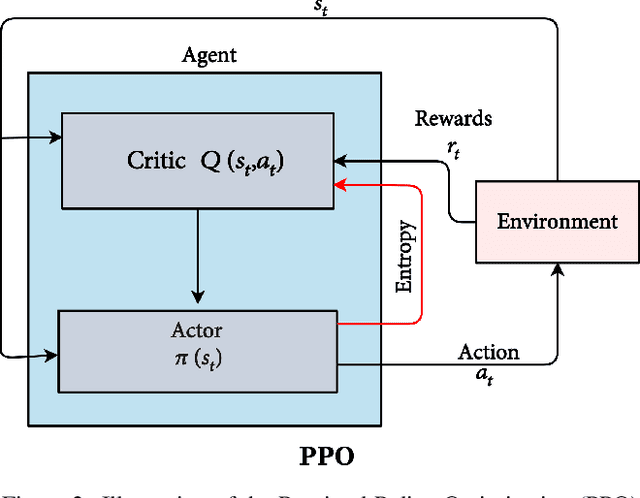
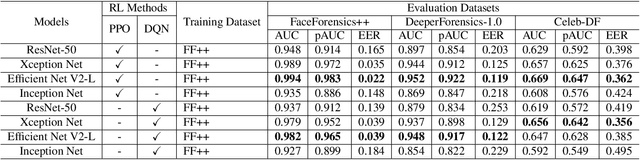
Facial manipulation by deep fake has caused major security risks and raised severe societal concerns. As a countermeasure, a number of deep fake detection methods have been proposed recently. Most of them model deep fake detection as a binary classification problem using a backbone convolutional neural network (CNN) architecture pretrained for the task. These CNN-based methods have demonstrated very high efficacy in deep fake detection with the Area under the Curve (AUC) as high as 0.99. However, the performance of these methods degrades significantly when evaluated across datasets. In this paper, we formulate deep fake detection as a hybrid combination of supervised and reinforcement learning (RL) to improve its cross-dataset generalization performance. The proposed method chooses the top-k augmentations for each test sample by an RL agent in an image-specific manner. The classification scores, obtained using CNN, of all the augmentations of each test image are averaged together for final real or fake classification. Through extensive experimental validation, we demonstrate the superiority of our method over existing published research in cross-dataset generalization of deep fake detectors, thus obtaining state-of-the-art performance.
Measuring Trustworthiness or Automating Physiognomy? A Comment on Safra, Chevallier, Grèzes, and Baumard (2020)
Feb 17, 2022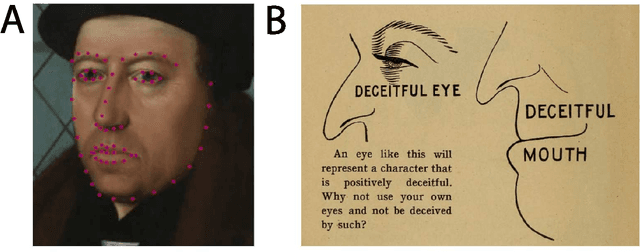
Interpersonal trust - a shared display of confidence and vulnerability toward other individuals - can be seen as instrumental in the development of human societies. Safra, Chevallier, Gr\`ezes, and Baumard (2020) studied the historical progression of interpersonal trust by training a machine learning (ML) algorithm to generate trustworthiness ratings of historical portraits, based on facial features. They reported that trustworthiness ratings of portraits dated between 1500--2000CE increased with time, claiming that this evidenced a broader increase in interpersonal trust coinciding with several metrics of societal progress. We argue that these claims are confounded by several methodological and analytical issues and highlight troubling parallels between Safra et al.'s algorithm and the pseudoscience of physiognomy. We discuss the implications and potential real-world consequences of these issues in further detail.