 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
An Enhanced Adversarial Network with Combined Latent Features for Spatio-Temporal Facial Affect Estimation in the Wild
Feb 18, 2021
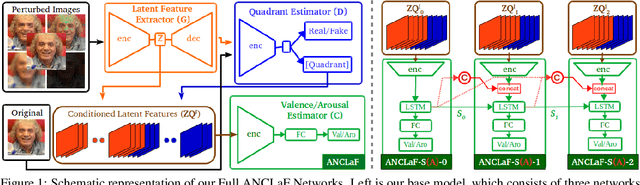
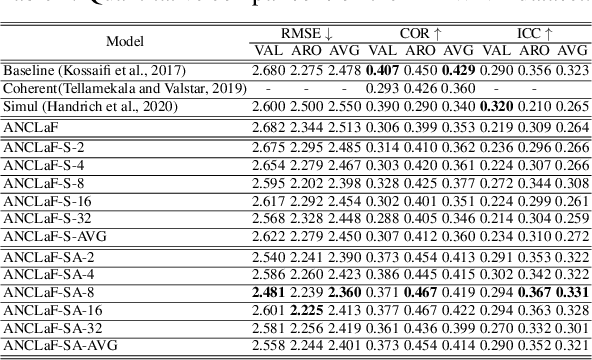
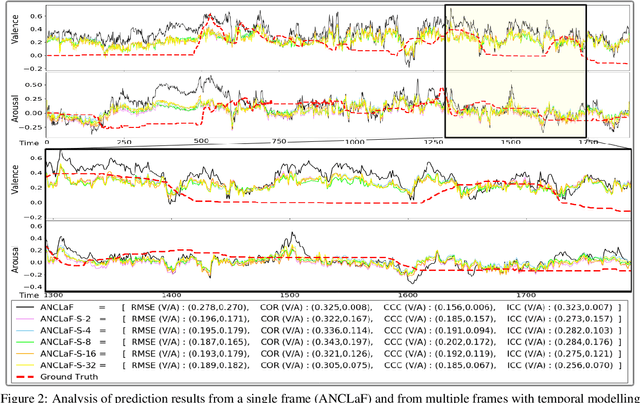
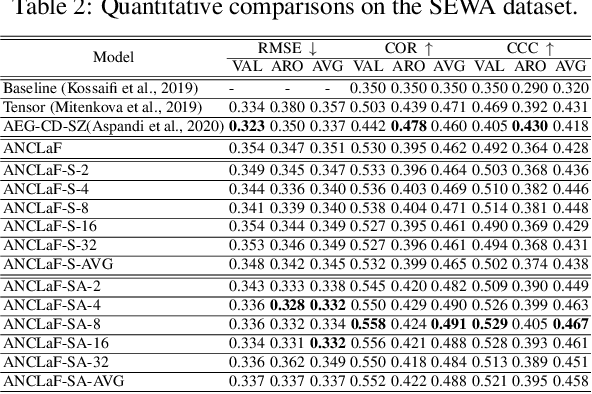
Affective Computing has recently attracted the attention of the research community, due to its numerous applications in diverse areas. In this context, the emergence of video-based data allows to enrich the widely used spatial features with the inclusion of temporal information. However, such spatio-temporal modelling often results in very high-dimensional feature spaces and large volumes of data, making training difficult and time consuming. This paper addresses these shortcomings by proposing a novel model that efficiently extracts both spatial and temporal features of the data by means of its enhanced temporal modelling based on latent features. Our proposed model consists of three major networks, coined Generator, Discriminator, and Combiner, which are trained in an adversarial setting combined with curriculum learning to enable our adaptive attention modules. In our experiments, we show the effectiveness of our approach by reporting our competitive results on both the AFEW-VA and SEWA datasets, suggesting that temporal modelling improves the affect estimates both in qualitative and quantitative terms. Furthermore, we find that the inclusion of attention mechanisms leads to the highest accuracy improvements, as its weights seem to correlate well with the appearance of facial movements, both in terms of temporal localisation and intensity. Finally, we observe the sequence length of around 160\,ms to be the optimum one for temporal modelling, which is consistent with other relevant findings utilising similar lengths.
Do You Really Mean That? Content Driven Audio-Visual Deepfake Dataset and Multimodal Method for Temporal Forgery Localization
Apr 13, 2022

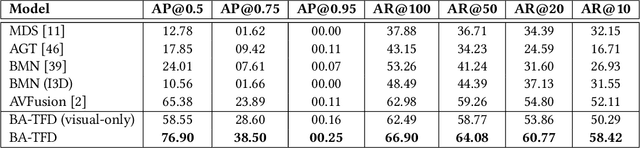
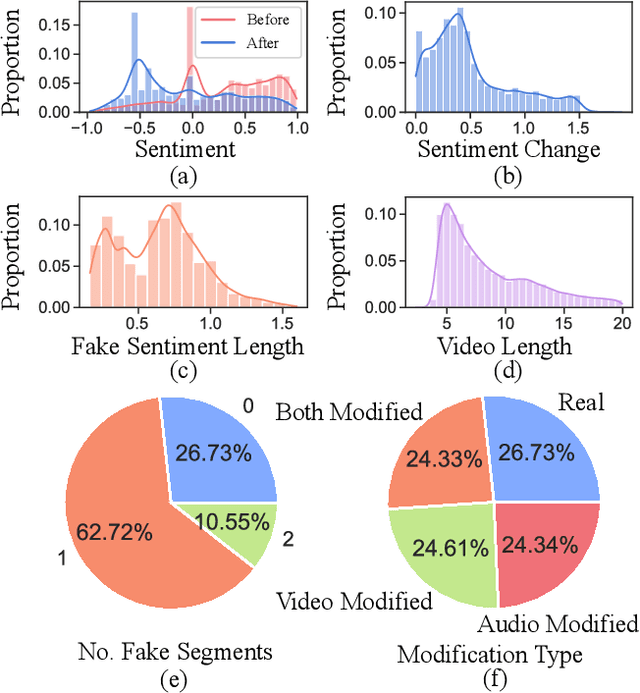
Due to its high societal impact, deepfake detection is getting active attention in the computer vision community. Most deepfake detection methods rely on identity, facial attribute and adversarial perturbation based spatio-temporal modifications at the whole video or random locations, while keeping the meaning of the content intact. However, a sophisticated deepfake may contain only a small segment of video/audio manipulation, through which the meaning of the content can be, for example, completely inverted from sentiment perspective. To address this gap, we introduce a content driven audio-visual deepfake dataset, termed as Localized Audio Visual DeepFake (LAV-DF), explicitly designed for the task of learning temporal forgery localization. Specifically, the content driven audio-visual manipulations are performed at strategic locations in order to change the sentiment polarity of the whole video. Our baseline method for benchmarking the proposed dataset is a 3DCNN model, termed as Boundary Aware Temporal Forgery Detection (BA-TFD), which is guided via contrastive, boundary matching and frame classification loss functions. Our extensive quantitative analysis demonstrates the strong performance of the proposed method for both task of temporal forgery localization and deepfake detection.
Audio-Visual Speech Codecs: Rethinking Audio-Visual Speech Enhancement by Re-Synthesis
Mar 31, 2022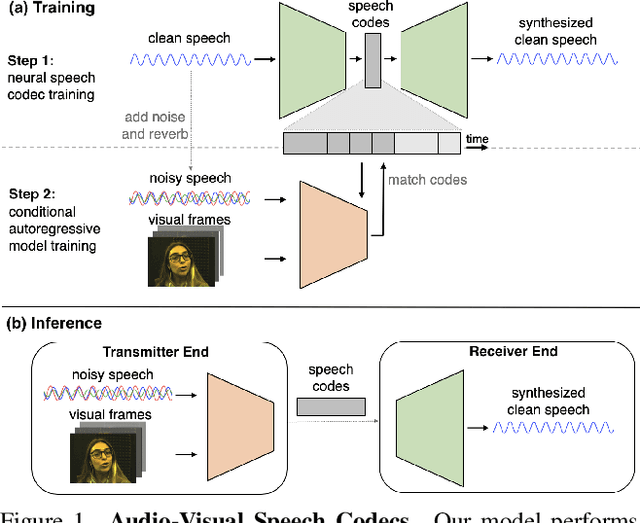
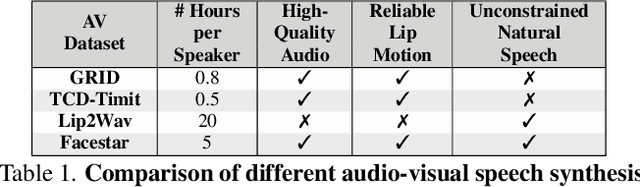
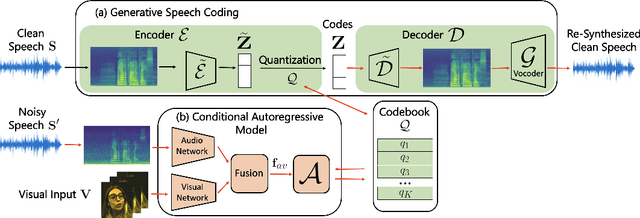

Since facial actions such as lip movements contain significant information about speech content, it is not surprising that audio-visual speech enhancement methods are more accurate than their audio-only counterparts. Yet, state-of-the-art approaches still struggle to generate clean, realistic speech without noise artifacts and unnatural distortions in challenging acoustic environments. In this paper, we propose a novel audio-visual speech enhancement framework for high-fidelity telecommunications in AR/VR. Our approach leverages audio-visual speech cues to generate the codes of a neural speech codec, enabling efficient synthesis of clean, realistic speech from noisy signals. Given the importance of speaker-specific cues in speech, we focus on developing personalized models that work well for individual speakers. We demonstrate the efficacy of our approach on a new audio-visual speech dataset collected in an unconstrained, large vocabulary setting, as well as existing audio-visual datasets, outperforming speech enhancement baselines on both quantitative metrics and human evaluation studies. Please see the supplemental video for qualitative results at https://github.com/facebookresearch/facestar/releases/download/paper_materials/video.mp4.
Reasoning Graph Networks for Kinship Verification: from Star-shaped to Hierarchical
Sep 06, 2021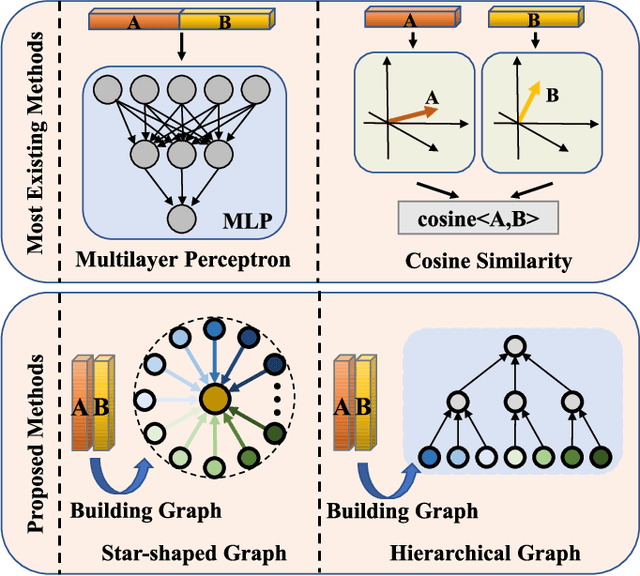
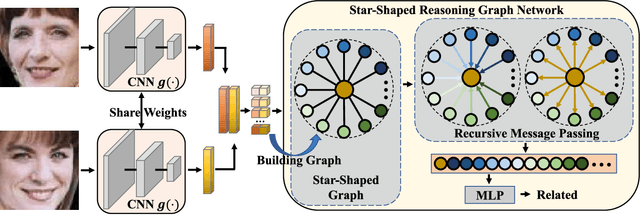

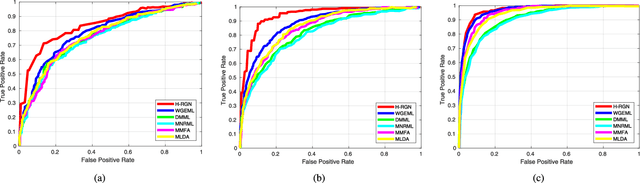
In this paper, we investigate the problem of facial kinship verification by learning hierarchical reasoning graph networks. Conventional methods usually focus on learning discriminative features for each facial image of a paired sample and neglect how to fuse the obtained two facial image features and reason about the relations between them. To address this, we propose a Star-shaped Reasoning Graph Network (S-RGN). Our S-RGN first constructs a star-shaped graph where each surrounding node encodes the information of comparisons in a feature dimension and the central node is employed as the bridge for the interaction of surrounding nodes. Then we perform relational reasoning on this star graph with iterative message passing. The proposed S-RGN uses only one central node to analyze and process information from all surrounding nodes, which limits its reasoning capacity. We further develop a Hierarchical Reasoning Graph Network (H-RGN) to exploit more powerful and flexible capacity. More specifically, our H-RGN introduces a set of latent reasoning nodes and constructs a hierarchical graph with them. Then bottom-up comparative information abstraction and top-down comprehensive signal propagation are iteratively performed on the hierarchical graph to update the node features. Extensive experimental results on four widely used kinship databases show that the proposed methods achieve very competitive results.
* Accepted by IEEE Transactions on Image Processing (TIP)
Facial Expression Classification using Fusion of Deep Neural Network in Video for the 3rd ABAW3 Competition
Apr 08, 2022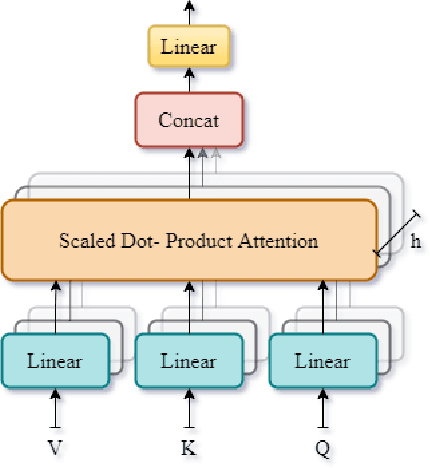


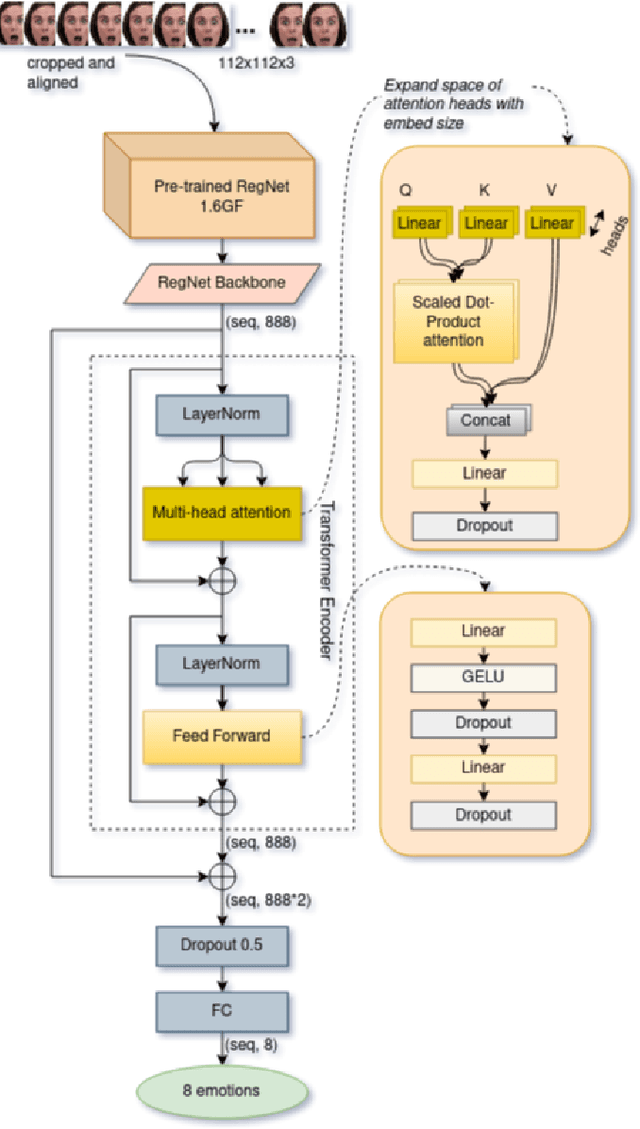
For computers to recognize human emotions, expression classification is an equally important problem in the human-computer interaction area. In the 3rd Affective Behavior Analysis In-The-Wild competition, the task of expression classification includes eight classes with six basic expressions of human faces from videos. In this paper, we employ a transformer mechanism to encode the robust representation from the backbone. Fusion of the robust representations plays an important role in the expression classification task. Our approach achieves 30.35\% and 28.60\% for the $F_1$ score on the validation set and the test set, respectively. This result shows the effectiveness of the proposed architecture based on the Aff-Wild2 dataset.
Copy Motion From One to Another: Fake Motion Video Generation
May 03, 2022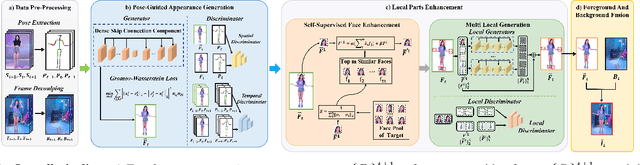
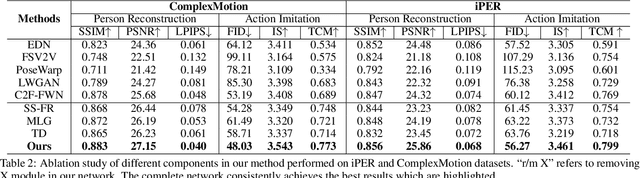
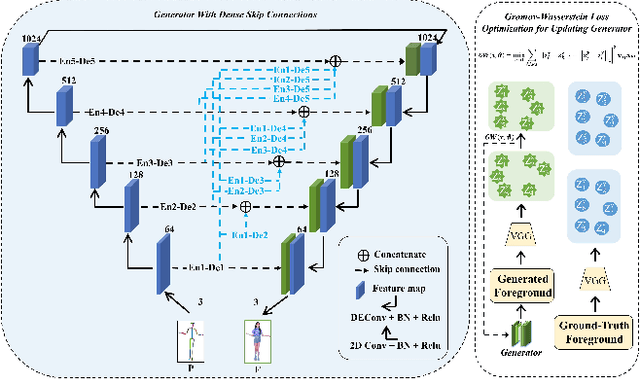
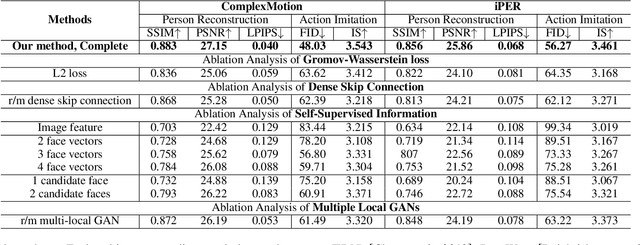
One compelling application of artificial intelligence is to generate a video of a target person performing arbitrary desired motion (from a source person). While the state-of-the-art methods are able to synthesize a video demonstrating similar broad stroke motion details, they are generally lacking in texture details. A pertinent manifestation appears as distorted face, feet, and hands, and such flaws are very sensitively perceived by human observers. Furthermore, current methods typically employ GANs with a L2 loss to assess the authenticity of the generated videos, inherently requiring a large amount of training samples to learn the texture details for adequate video generation. In this work, we tackle these challenges from three aspects: 1) We disentangle each video frame into foreground (the person) and background, focusing on generating the foreground to reduce the underlying dimension of the network output. 2) We propose a theoretically motivated Gromov-Wasserstein loss that facilitates learning the mapping from a pose to a foreground image. 3) To enhance texture details, we encode facial features with geometric guidance and employ local GANs to refine the face, feet, and hands. Extensive experiments show that our method is able to generate realistic target person videos, faithfully copying complex motions from a source person. Our code and datasets are released at https://github.com/Sifann/FakeMotion
Region attention and graph embedding network for occlusion objective class-based micro-expression recognition
Jul 13, 2021
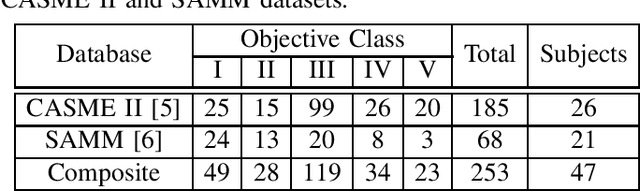
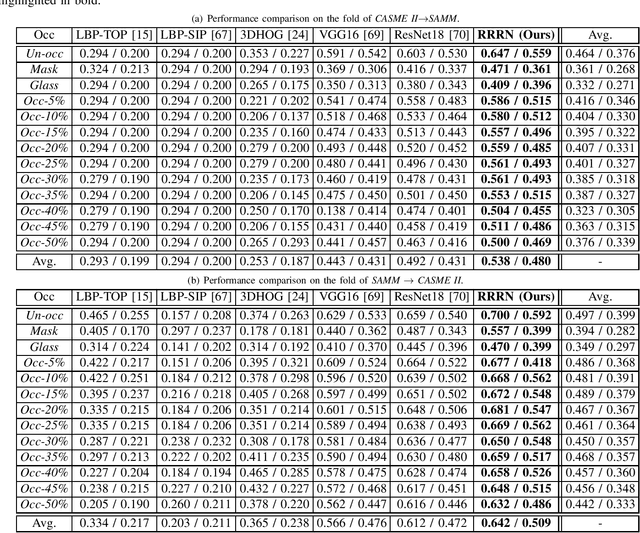
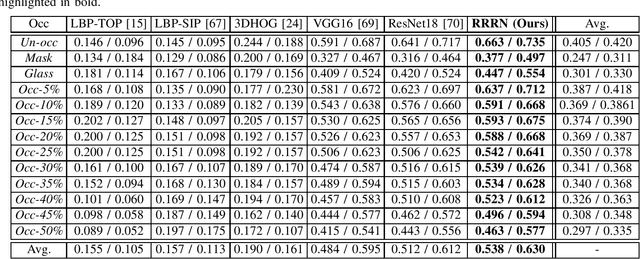
Micro-expression recognition (\textbf{MER}) has attracted lots of researchers' attention in a decade. However, occlusion will occur for MER in real-world scenarios. This paper deeply investigates an interesting but unexplored challenging issue in MER, \ie, occlusion MER. First, to research MER under real-world occlusion, synthetic occluded micro-expression databases are created by using various mask for the community. Second, to suppress the influence of occlusion, a \underline{R}egion-inspired \underline{R}elation \underline{R}easoning \underline{N}etwork (\textbf{RRRN}) is proposed to model relations between various facial regions. RRRN consists of a backbone network, the Region-Inspired (\textbf{RI}) module and Relation Reasoning (\textbf{RR}) module. More specifically, the backbone network aims at extracting feature representations from different facial regions, RI module computing an adaptive weight from the region itself based on attention mechanism with respect to the unobstructedness and importance for suppressing the influence of occlusion, and RR module exploiting the progressive interactions among these regions by performing graph convolutions. Experiments are conducted on handout-database evaluation and composite database evaluation tasks of MEGC 2018 protocol. Experimental results show that RRRN can significantly explore the importance of facial regions and capture the cooperative complementary relationship of facial regions for MER. The results also demonstrate RRRN outperforms the state-of-the-art approaches, especially on occlusion, and RRRN acts more robust to occlusion.
Facial Expression Recognition in the Wild using Rich Deep Features
Jan 11, 2016


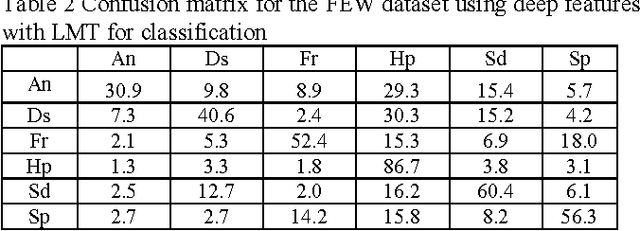
Facial Expression Recognition is an active area of research in computer vision with a wide range of applications. Several approaches have been developed to solve this problem for different benchmark datasets. However, Facial Expression Recognition in the wild remains an area where much work is still needed to serve real-world applications. To this end, in this paper we present a novel approach towards facial expression recognition. We fuse rich deep features with domain knowledge through encoding discriminant facial patches. We conduct experiments on two of the most popular benchmark datasets; CK and TFE. Moreover, we present a novel dataset that, unlike its precedents, consists of natural - not acted - expression images. Experimental results show that our approach achieves state-of-the-art results over standard benchmarks and our own dataset
Robust Facial Landmark Localization Based on Texture and Pose Correlated Initialization
May 15, 2018
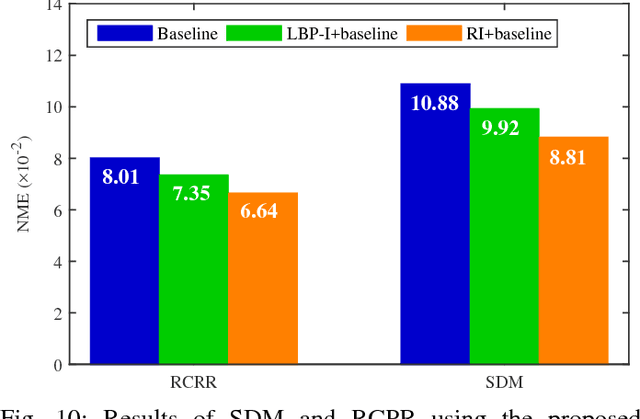

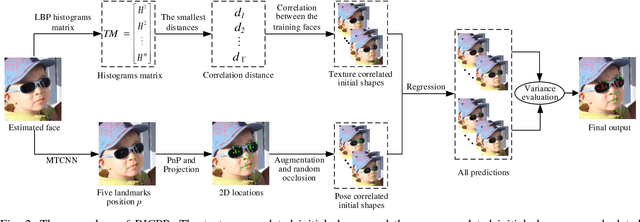
Robust facial landmark localization remains a challenging task when faces are partially occluded. Recently, the cascaded pose regression has attracted increasing attentions, due to it's superior performance in facial landmark localization and occlusion detection. However, such an approach is sensitive to initialization, where an improper initialization can severly degrade the performance. In this paper, we propose a Robust Initialization for Cascaded Pose Regression (RICPR) by providing texture and pose correlated initial shapes for the testing face. By examining the correlation of local binary patterns histograms between the testing face and the training faces, the shapes of the training faces that are most correlated with the testing face are selected as the texture correlated initialization. To make the initialization more robust to various poses, we estimate the rough pose of the testing face according to five fiducial landmarks located by multitask cascaded convolutional networks. Then the pose correlated initial shapes are constructed by the mean face's shape and the rough testing face pose. Finally, the texture correlated and the pose correlated initial shapes are joined together as the robust initialization. We evaluate RICPR on the challenging dataset of COFW. The experimental results demonstrate that the proposed scheme achieves better performances than the state-of-the-art methods in facial landmark localization and occlusion detection.
Linear Disentangled Representation Learning for Facial Actions
Jan 11, 2017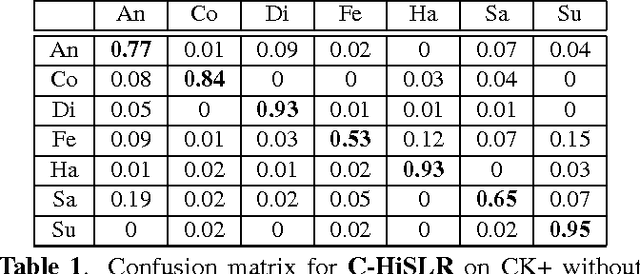

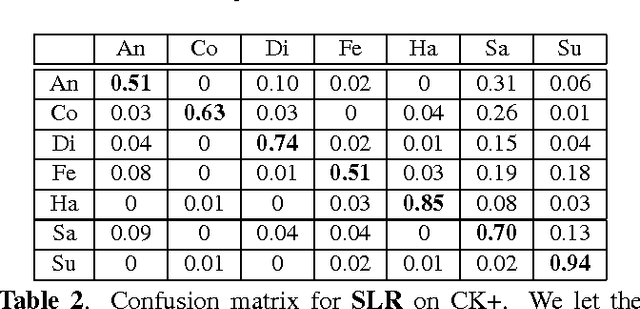
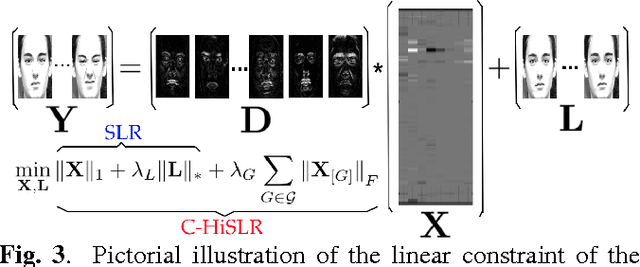
Limited annotated data available for the recognition of facial expression and action units embarrasses the training of deep networks, which can learn disentangled invariant features. However, a linear model with just several parameters normally is not demanding in terms of training data. In this paper, we propose an elegant linear model to untangle confounding factors in challenging realistic multichannel signals such as 2D face videos. The simple yet powerful model does not rely on huge training data and is natural for recognizing facial actions without explicitly disentangling the identity. Base on well-understood intuitive linear models such as Sparse Representation based Classification (SRC), previous attempts require a prepossessing of explicit decoupling which is practically inexact. Instead, we exploit the low-rank property across frames to subtract the underlying neutral faces which are modeled jointly with sparse representation on the action components with group sparsity enforced. On the extended Cohn-Kanade dataset (CK+), our one-shot automatic method on raw face videos performs as competitive as SRC applied on manually prepared action components and performs even better than SRC in terms of true positive rate. We apply the model to the even more challenging task of facial action unit recognition, verified on the MPI Face Video Database (MPI-VDB) achieving a decent performance. All the programs and data have been made publicly available.