 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Comparing Human and Machine Bias in Face Recognition
Oct 25, 2021

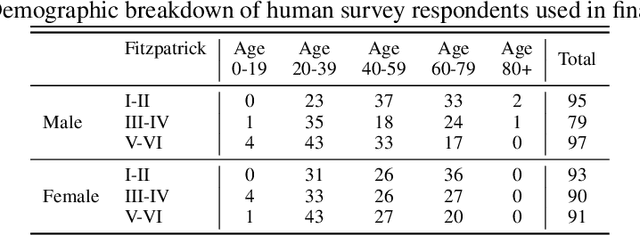

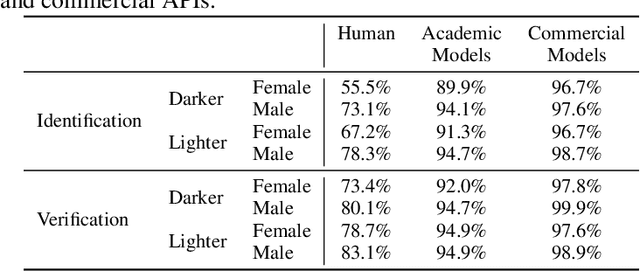
Much recent research has uncovered and discussed serious concerns of bias in facial analysis technologies, finding performance disparities between groups of people based on perceived gender, skin type, lighting condition, etc. These audits are immensely important and successful at measuring algorithmic bias but have two major challenges: the audits (1) use facial recognition datasets which lack quality metadata, like LFW and CelebA, and (2) do not compare their observed algorithmic bias to the biases of their human alternatives. In this paper, we release improvements to the LFW and CelebA datasets which will enable future researchers to obtain measurements of algorithmic bias that are not tainted by major flaws in the dataset (e.g. identical images appearing in both the gallery and test set). We also use these new data to develop a series of challenging facial identification and verification questions that we administered to various algorithms and a large, balanced sample of human reviewers. We find that both computer models and human survey participants perform significantly better at the verification task, generally obtain lower accuracy rates on dark-skinned or female subjects for both tasks, and obtain higher accuracy rates when their demographics match that of the question. Computer models are observed to achieve a higher level of accuracy than the survey participants on both tasks and exhibit bias to similar degrees as the human survey participants.
EyeNeRF: A Hybrid Representation for Photorealistic Synthesis, Animation and Relighting of Human Eyes
Jun 16, 2022
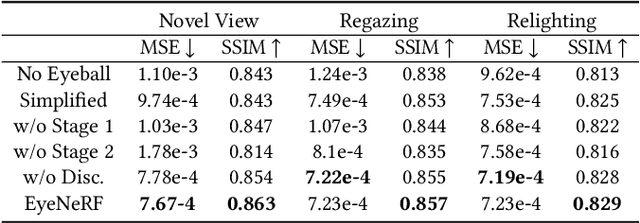
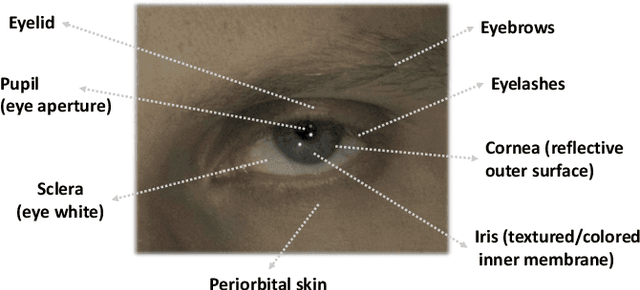
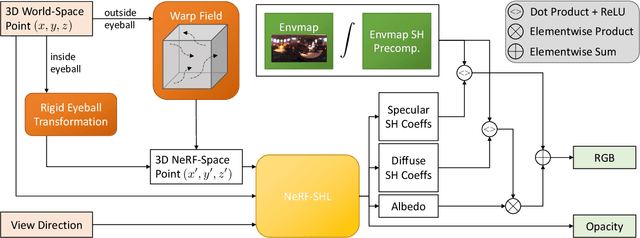
A unique challenge in creating high-quality animatable and relightable 3D avatars of people is modeling human eyes. The challenge of synthesizing eyes is multifold as it requires 1) appropriate representations for the various components of the eye and the periocular region for coherent viewpoint synthesis, capable of representing diffuse, refractive and highly reflective surfaces, 2) disentangling skin and eye appearance from environmental illumination such that it may be rendered under novel lighting conditions, and 3) capturing eyeball motion and the deformation of the surrounding skin to enable re-gazing. These challenges have traditionally necessitated the use of expensive and cumbersome capture setups to obtain high-quality results, and even then, modeling of the eye region holistically has remained elusive. We present a novel geometry and appearance representation that enables high-fidelity capture and photorealistic animation, view synthesis and relighting of the eye region using only a sparse set of lights and cameras. Our hybrid representation combines an explicit parametric surface model for the eyeball with implicit deformable volumetric representations for the periocular region and the interior of the eye. This novel hybrid model has been designed to address the various parts of that challenging facial area - the explicit eyeball surface allows modeling refraction and high-frequency specular reflection at the cornea, whereas the implicit representation is well suited to model lower-frequency skin reflection via spherical harmonics and can represent non-surface structures such as hair or diffuse volumetric bodies, both of which are a challenge for explicit surface models. We show that for high-resolution close-ups of the eye, our model can synthesize high-fidelity animated gaze from novel views under unseen illumination conditions.
Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
Oct 06, 2021High-fidelity face digitization solutions often combine multi-view stereo (MVS) techniques for 3D reconstruction and a non-rigid registration step to establish dense correspondence across identities and expressions. A common problem is the need for manual clean-up after the MVS step, as 3D scans are typically affected by noise and outliers and contain hairy surface regions that need to be cleaned up by artists. Furthermore, mesh registration tends to fail for extreme facial expressions. Most learning-based methods use an underlying 3D morphable model (3DMM) to ensure robustness, but this limits the output accuracy for extreme facial expressions. In addition, the global bottleneck of regression architectures cannot produce meshes that tightly fit the ground truth surfaces. We propose ToFu, Topologically consistent Face from multi-view, a geometry inference framework that can produce topologically consistent meshes across facial identities and expressions using a volumetric representation instead of an explicit underlying 3DMM. Our novel progressive mesh generation network embeds the topological structure of the face in a feature volume, sampled from geometry-aware local features. A coarse-to-fine architecture facilitates dense and accurate facial mesh predictions in a consistent mesh topology. ToFu further captures displacement maps for pore-level geometric details and facilitates high-quality rendering in the form of albedo and specular reflectance maps. These high-quality assets are readily usable by production studios for avatar creation, animation and physically-based skin rendering. We demonstrate state-of-the-art geometric and correspondence accuracy, while only taking 0.385 seconds to compute a mesh with 10K vertices, which is three orders of magnitude faster than traditional techniques. The code and the model are available for research purposes at https://tianyeli.github.io/tofu.
Style Aggregated Network for Facial Landmark Detection
Mar 22, 2018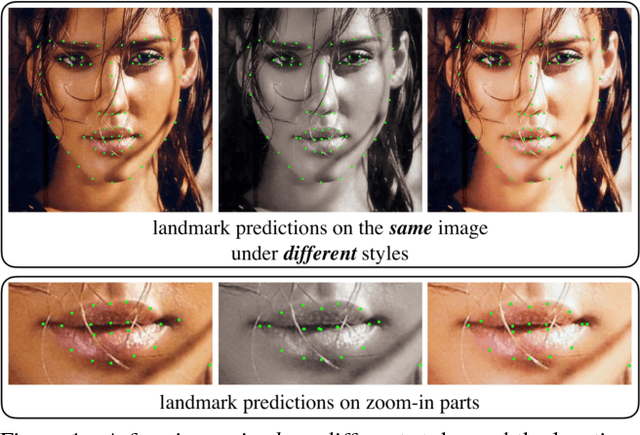
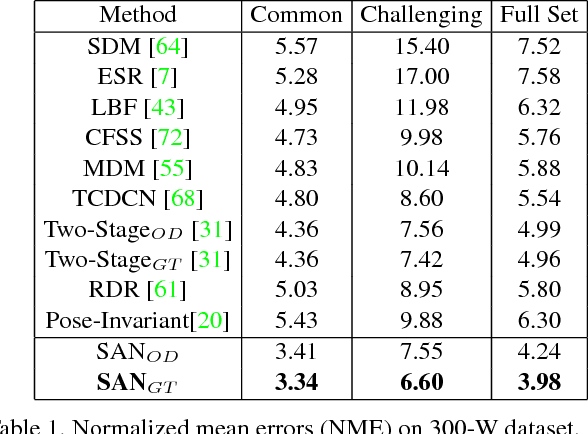


Recent advances in facial landmark detection achieve success by learning discriminative features from rich deformation of face shapes and poses. Besides the variance of faces themselves, the intrinsic variance of image styles, e.g., grayscale vs. color images, light vs. dark, intense vs. dull, and so on, has constantly been overlooked. This issue becomes inevitable as increasing web images are collected from various sources for training neural networks. In this work, we propose a style-aggregated approach to deal with the large intrinsic variance of image styles for facial landmark detection. Our method transforms original face images to style-aggregated images by a generative adversarial module. The proposed scheme uses the style-aggregated image to maintain face images that are more robust to environmental changes. Then the original face images accompanying with style-aggregated ones play a duet to train a landmark detector which is complementary to each other. In this way, for each face, our method takes two images as input, i.e., one in its original style and the other in the aggregated style. In experiments, we observe that the large variance of image styles would degenerate the performance of facial landmark detectors. Moreover, we show the robustness of our method to the large variance of image styles by comparing to a variant of our approach, in which the generative adversarial module is removed, and no style-aggregated images are used. Our approach is demonstrated to perform well when compared with state-of-the-art algorithms on benchmark datasets AFLW and 300-W. Code is publicly available on GitHub: https://github.com/D-X-Y/SAN
Multi-Attribute Robust Component Analysis for Facial UV Maps
Dec 15, 2017



Recently, due to the collection of large scale 3D face models, as well as the advent of deep learning, a significant progress has been made in the field of 3D face alignment "in-the-wild". That is, many methods have been proposed that establish sparse or dense 3D correspondences between a 2D facial image and a 3D face model. The utilization of 3D face alignment introduces new challenges and research directions, especially on the analysis of facial texture images. In particular, texture does not suffer any more from warping effects (that occurred when 2D face alignment methods were used). Nevertheless, since facial images are commonly captured in arbitrary recording conditions, a considerable amount of missing information and gross outliers is observed (e.g., due to self-occlusion, or subjects wearing eye-glasses). Given that many annotated databases have been developed for face analysis tasks, it is evident that component analysis techniques need to be developed in order to alleviate issues arising from the aforementioned challenges. In this paper, we propose a novel component analysis technique that is suitable for facial UV maps containing a considerable amount of missing information and outliers, while additionally, incorporates knowledge from various attributes (such as age and identity). We evaluate the proposed Multi-Attribute Robust Component Analysis (MA-RCA) on problems such as UV completion and age progression, where the proposed method outperforms compared techniques. Finally, we demonstrate that MA-RCA method is powerful enough to provide weak annotations for training deep learning systems for various applications, such as illumination transfer.
Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet
Oct 03, 2017
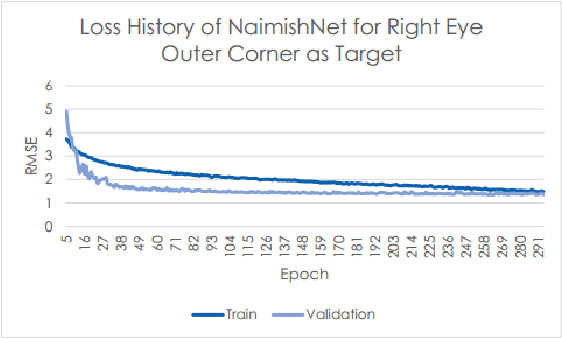
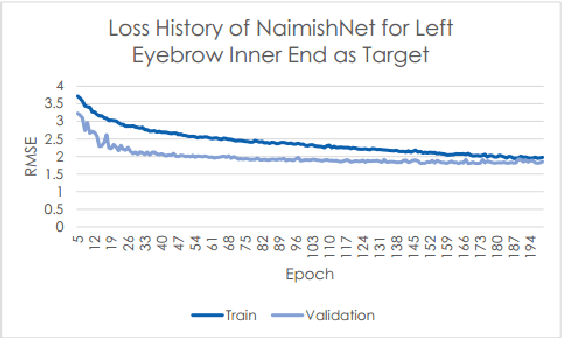
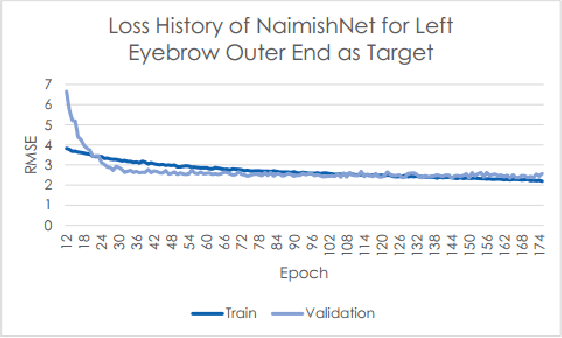
Facial Key Points (FKPs) Detection is an important and challenging problem in the fields of computer vision and machine learning. It involves predicting the co-ordinates of the FKPs, e.g. nose tip, center of eyes, etc, for a given face. In this paper, we propose a LeNet adapted Deep CNN model - NaimishNet, to operate on facial key points data and compare our model's performance against existing state of the art approaches.
UV-GAN: Adversarial Facial UV Map Completion for Pose-invariant Face Recognition
Dec 13, 2017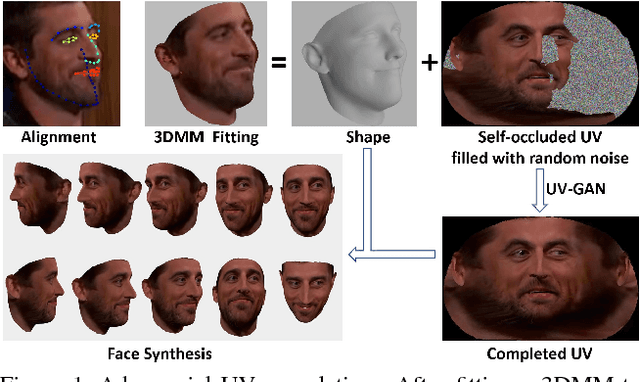
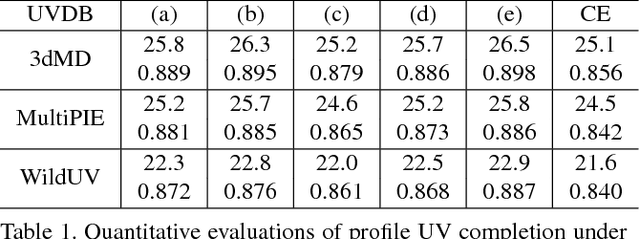

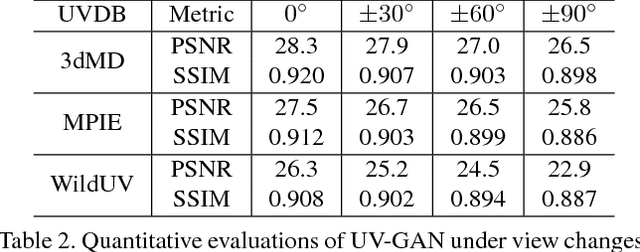
Recently proposed robust 3D face alignment methods establish either dense or sparse correspondence between a 3D face model and a 2D facial image. The use of these methods presents new challenges as well as opportunities for facial texture analysis. In particular, by sampling the image using the fitted model, a facial UV can be created. Unfortunately, due to self-occlusion, such a UV map is always incomplete. In this paper, we propose a framework for training Deep Convolutional Neural Network (DCNN) to complete the facial UV map extracted from in-the-wild images. To this end, we first gather complete UV maps by fitting a 3D Morphable Model (3DMM) to various multiview image and video datasets, as well as leveraging on a new 3D dataset with over 3,000 identities. Second, we devise a meticulously designed architecture that combines local and global adversarial DCNNs to learn an identity-preserving facial UV completion model. We demonstrate that by attaching the completed UV to the fitted mesh and generating instances of arbitrary poses, we can increase pose variations for training deep face recognition/verification models, and minimise pose discrepancy during testing, which lead to better performance. Experiments on both controlled and in-the-wild UV datasets prove the effectiveness of our adversarial UV completion model. We achieve state-of-the-art verification accuracy, $94.05\%$, under the CFP frontal-profile protocol only by combining pose augmentation during training and pose discrepancy reduction during testing. We will release the first in-the-wild UV dataset (we refer as WildUV) that comprises of complete facial UV maps from 1,892 identities for research purposes.
Dynamic Bayesian Network Modelling of User Affect and Perceptions of a Teleoperated Robot Coach during Longitudinal Mindfulness Training
Dec 06, 2021
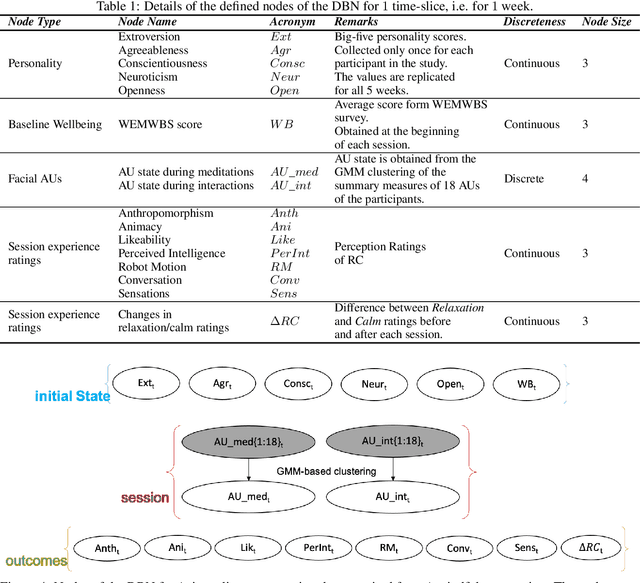

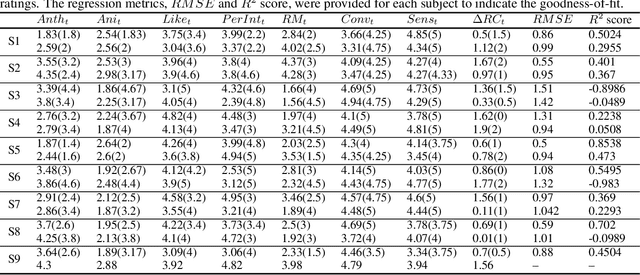
Longitudinal interaction studies with Socially Assistive Robots are crucial to ensure that the robot is relevant for long-term use and its perceptions are not prone to the novelty effect. In this paper, we present a dynamic Bayesian network (DBN) to capture the longitudinal interactions participants had with a teleoperated robot coach (RC) delivering mindfulness sessions. The DBN model is used to study complex, temporal interactions between the participants self-reported personality traits, weekly baseline wellbeing scores, session ratings, and facial AUs elicited during the sessions in a 5-week longitudinal study. DBN modelling involves learning a graphical representation that facilitates intuitive understanding of how multiple components contribute to the longitudinal changes in session ratings corresponding to the perceptions of the RC, and participants relaxation and calm levels. The learnt model captures the following within and between sessions aspects of the longitudinal interaction study: influence of the 5 personality dimensions on the facial AU states and the session ratings, influence of facial AU states on the session ratings, and the influences within the items of the session ratings. The DBN structure is learnt using first 3 time points and the obtained model is used to predict the session ratings of the last 2 time points of the 5-week longitudinal data. The predictions are quantified using subject-wise RMSE and R2 scores. We also demonstrate two applications of the model, namely, imputation of missing values in the dataset and estimation of longitudinal session ratings of a new participant with a given personality profile. The obtained DBN model thus facilitates learning of conditional dependency structure between variables in the longitudinal data and offers inferences and conceptual understanding which are not possible through other regression methodologies.
Convolutional Experts Constrained Local Model for Facial Landmark Detection
Jul 26, 2017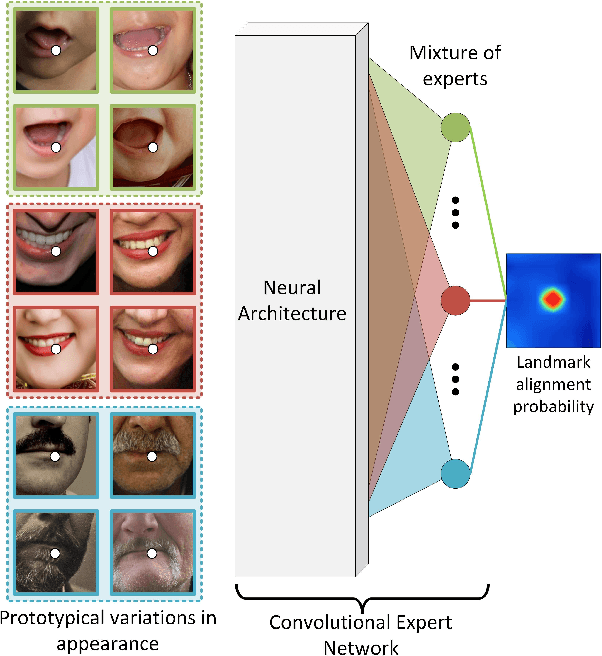
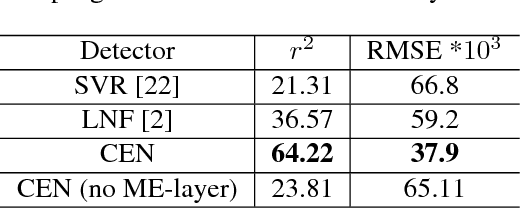
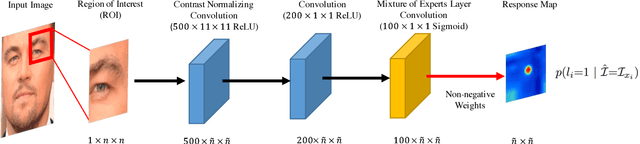
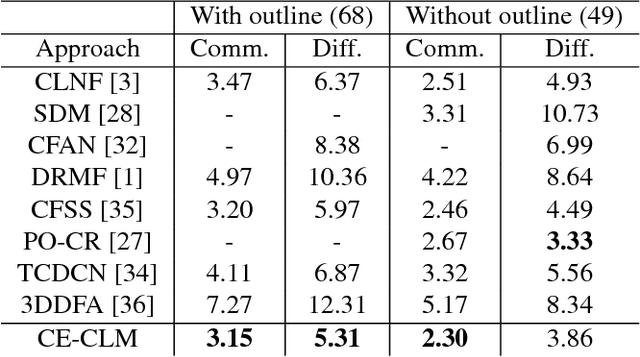
Constrained Local Models (CLMs) are a well-established family of methods for facial landmark detection. However, they have recently fallen out of favor to cascaded regression-based approaches. This is in part due to the inability of existing CLM local detectors to model the very complex individual landmark appearance that is affected by expression, illumination, facial hair, makeup, and accessories. In our work, we present a novel local detector -- Convolutional Experts Network (CEN) -- that brings together the advantages of neural architectures and mixtures of experts in an end-to-end framework. We further propose a Convolutional Experts Constrained Local Model (CE-CLM) algorithm that uses CEN as local detectors. We demonstrate that our proposed CE-CLM algorithm outperforms competitive state-of-the-art baselines for facial landmark detection by a large margin on four publicly-available datasets. Our approach is especially accurate and robust on challenging profile images.
Detection of Distracted Driver using Convolution Neural Network
Apr 07, 2022
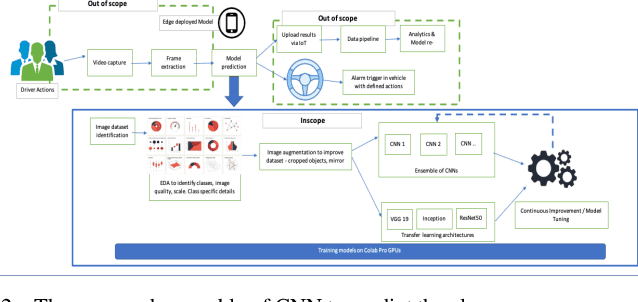
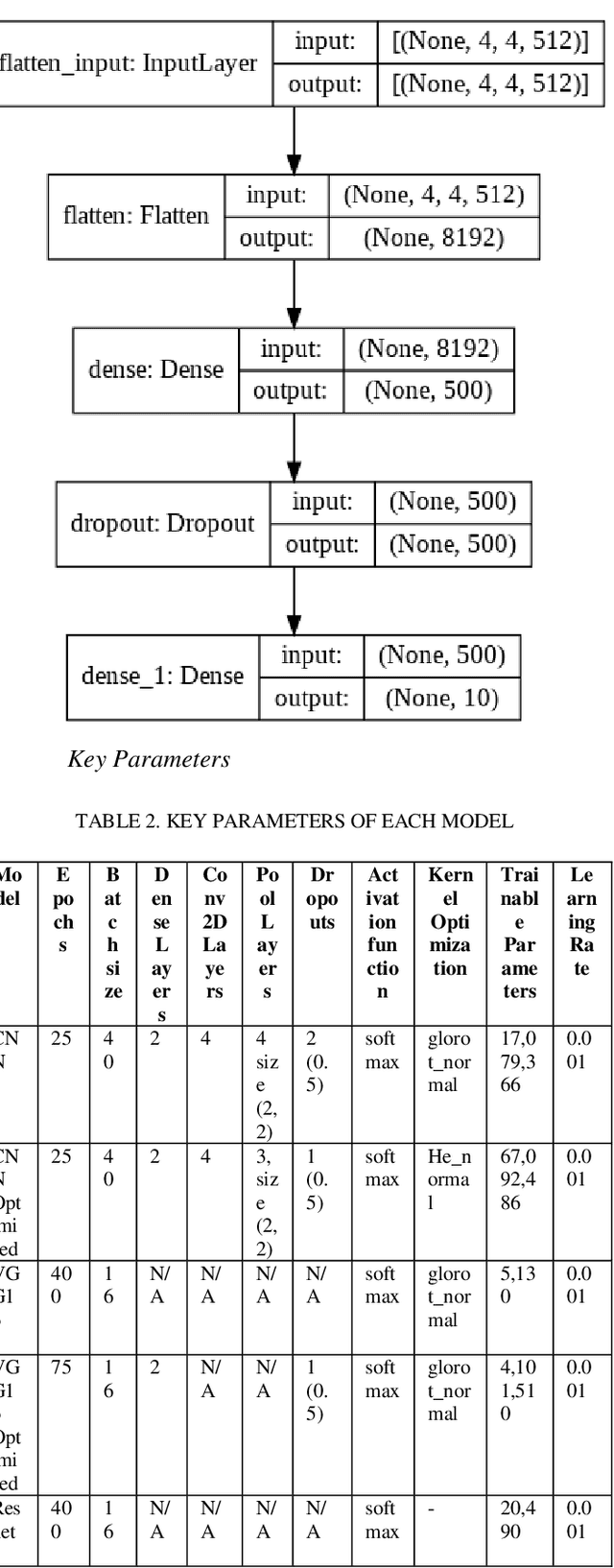

With over 50 million car sales annually and over 1.3 million deaths every year due to motor accidents we have chosen this space. India accounts for 11 per cent of global death in road accidents. Drivers are held responsible for 78% of accidents. Road safety problems in developing countries is a major concern and human behavior is ascribed as one of the main causes and accelerators of road safety problems. Driver distraction has been identified as the main reason for accidents. Distractions can be caused due to reasons such as mobile usage, drinking, operating instruments, facial makeup, social interaction. For the scope of this project, we will focus on building a highly efficient ML model to classify different driver distractions at runtime using computer vision. We would also analyze the overall speed and scalability of the model in order to be able to set it up on an edge device. We use CNN, VGG-16, RestNet50 and ensemble of CNN to predict the classes.