 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Fully Automated System for Sizing Nasal PAP Masks Using Facial Photographs
Nov 09, 2018



We present a fully automated system for sizing nasal Positive Airway Pressure (PAP) masks. The system is comprised of a mix of HOG object detectors as well as multiple convolutional neural network stages for facial landmark detection. The models were trained using samples from the publicly available PUT and MUCT datasets while transfer learning was also employed to improve the performance of the models on facial photographs of actual PAP mask users. The fully automated system demonstrated an overall accuracy of 64.71% in correctly selecting the appropriate mask size and 86.1% accuracy sizing within 1 mask size.
Facial Asymmetry and Emotional Expression
Nov 20, 2011
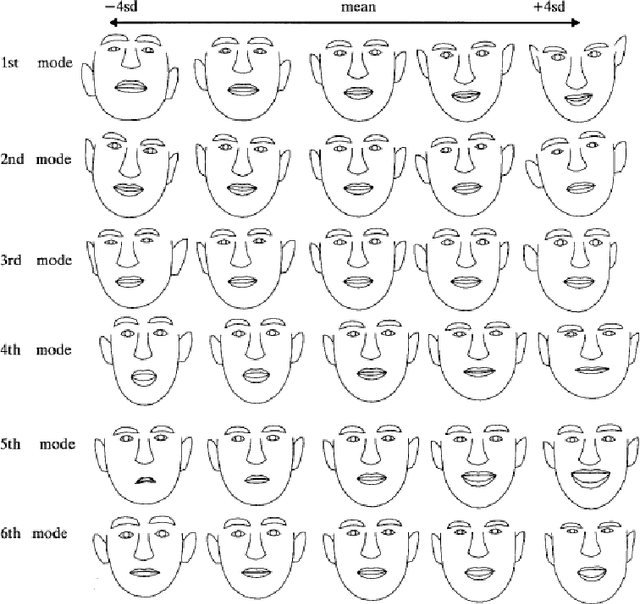
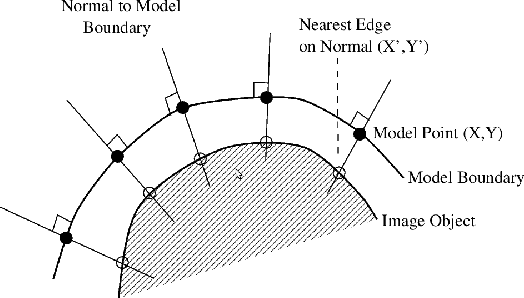
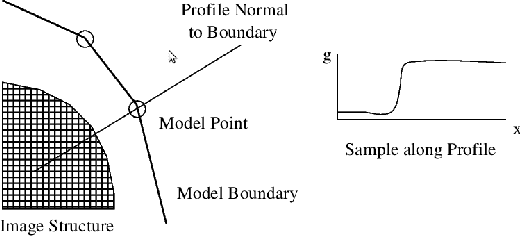
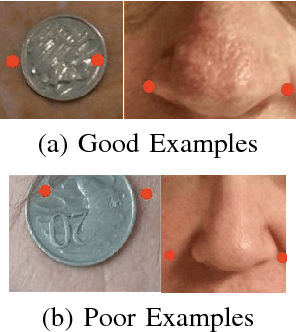
This report is about facial asymmetry, its connection to emotional expression, and methods of measuring facial asymmetry in videos of faces. The research was motivated by two factors: firstly, there was a real opportunity to develop a novel measure of asymmetry that required minimal human involvement and that improved on earlier measures in the literature; and secondly, the study of the relationship between facial asymmetry and emotional expression is both interesting in its own right, and important because it can inform neuropsychological theory and answer open questions concerning emotional processing in the brain. The two aims of the research were: first, to develop an automatic frame-by-frame measure of facial asymmetry in videos of faces that improved on previous measures; and second, to use the measure to analyse the relationship between facial asymmetry and emotional expression, and connect our findings with previous research of the relationship.
EmotionNet Nano: An Efficient Deep Convolutional Neural Network Design for Real-time Facial Expression Recognition
Jun 29, 2020
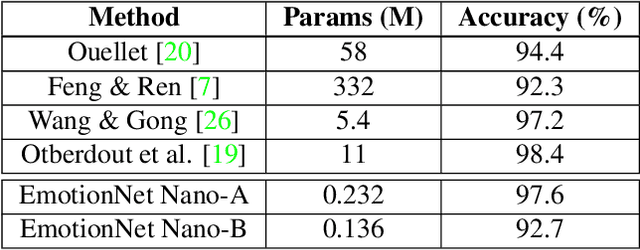
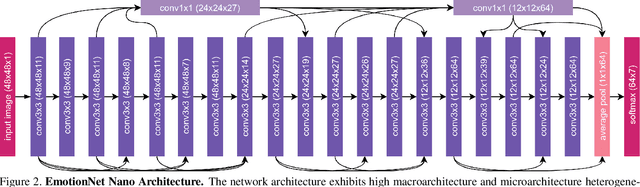
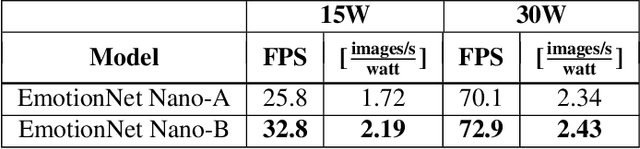
While recent advances in deep learning have led to significant improvements in facial expression classification (FEC), a major challenge that remains a bottleneck for the widespread deployment of such systems is their high architectural and computational complexities. This is especially challenging given the operational requirements of various FEC applications, such as safety, marketing, learning, and assistive living, where real-time requirements on low-cost embedded devices is desired. Motivated by this need for a compact, low latency, yet accurate system capable of performing FEC in real-time on low-cost embedded devices, this study proposes EmotionNet Nano, an efficient deep convolutional neural network created through a human-machine collaborative design strategy, where human experience is combined with machine meticulousness and speed in order to craft a deep neural network design catered towards real-time embedded usage. Two different variants of EmotionNet Nano are presented, each with a different trade-off between architectural and computational complexity and accuracy. Experimental results using the CK+ facial expression benchmark dataset demonstrate that the proposed EmotionNet Nano networks demonstrated accuracies comparable to state-of-the-art in FEC networks, while requiring significantly fewer parameters (e.g., 23$\times$ fewer at a higher accuracy). Furthermore, we demonstrate that the proposed EmotionNet Nano networks achieved real-time inference speeds (e.g. $>25$ FPS and $>70$ FPS at 15W and 30W, respectively) and high energy efficiency (e.g. $>1.7$ images/sec/watt at 15W) on an ARM embedded processor, thus further illustrating the efficacy of EmotionNet Nano for deployment on embedded devices.
Deep Recurrent Regression for Facial Landmark Detection
Oct 31, 2016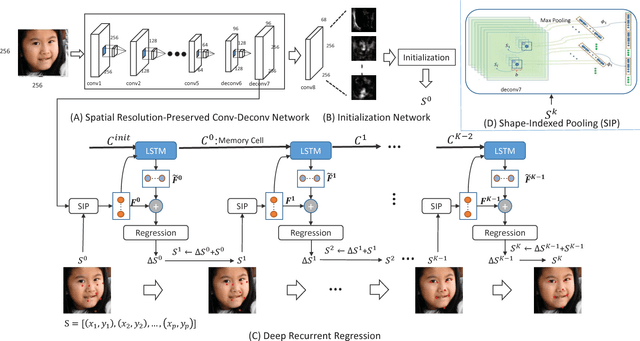
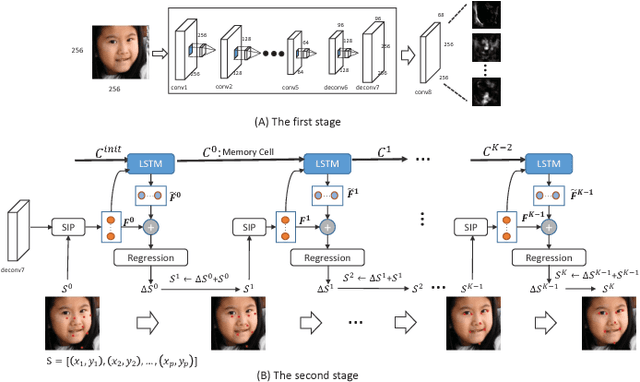
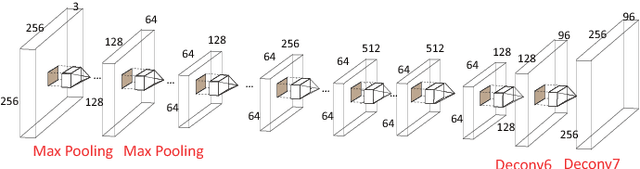
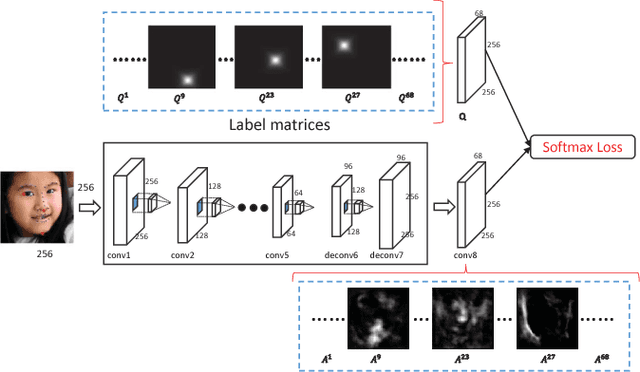
We propose a novel end-to-end deep architecture for face landmark detection, based on a deep convolutional and deconvolutional network followed by carefully designed recurrent network structures. The pipeline of this architecture consists of three parts. Through the first part, we encode an input face image to resolution-preserved deconvolutional feature maps via a deep network with stacked convolutional and deconvolutional layers. Then, in the second part, we estimate the initial coordinates of the facial key points by an additional convolutional layer on top of these deconvolutional feature maps. In the last part, by using the deconvolutional feature maps and the initial facial key points as input, we refine the coordinates of the facial key points by a recurrent network that consists of multiple Long-Short Term Memory (LSTM) components. Extensive evaluations on several benchmark datasets show that the proposed deep architecture has superior performance against the state-of-the-art methods.
Facial Keypoints Detection
Oct 15, 2017

Detect facial keypoints is a critical element in face recognition. However, there is difficulty to catch keypoints on the face due to complex influences from original images, and there is no guidance to suitable algorithms. In this paper, we study different algorithms that can be applied to locate keyponits. Specifically: our framework (1)prepare the data for further investigation (2)Using PCA and LBP to process the data (3) Apply different algorithms to analysis data, including linear regression models, tree based model, neural network and convolutional neural network, etc. Finally we will give our conclusion and further research topic. A comprehensive set of experiments on dataset demonstrates the effectiveness of our framework.
SCUT-FBP: A Benchmark Dataset for Facial Beauty Perception
Nov 08, 2015
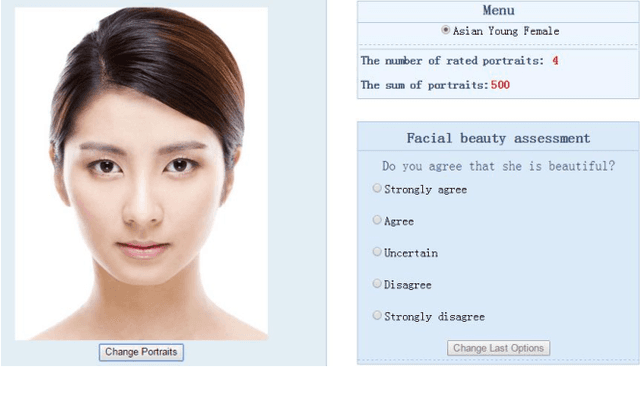
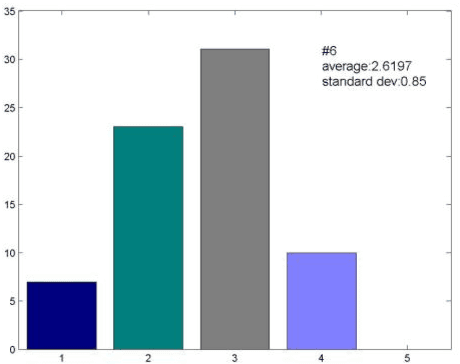
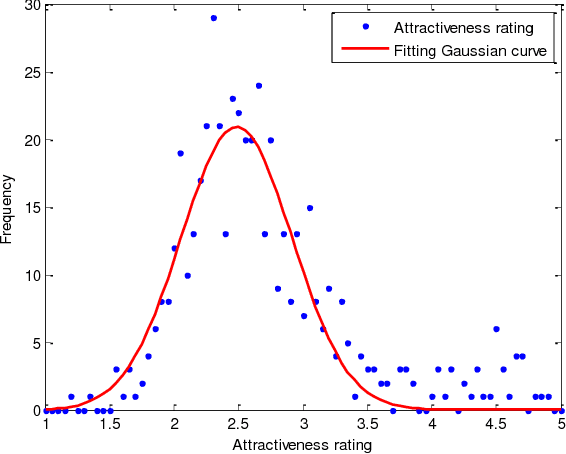
In this paper, a novel face dataset with attractiveness ratings, namely, the SCUT-FBP dataset, is developed for automatic facial beauty perception. This dataset provides a benchmark to evaluate the performance of different methods for facial attractiveness prediction, including the state-of-the-art deep learning method. The SCUT-FBP dataset contains face portraits of 500 Asian female subjects with attractiveness ratings, all of which have been verified in terms of rating distribution, standard deviation, consistency, and self-consistency. Benchmark evaluations for facial attractiveness prediction were performed with different combinations of facial geometrical features and texture features using classical statistical learning methods and the deep learning method. The best Pearson correlation (0.8187) was achieved by the CNN model. Thus, the results of our experiments indicate that the SCUT-FBP dataset provides a reliable benchmark for facial beauty perception.
Analysis of Co-Laughter Gesture Relationship on RGB videos in Dyadic Conversation Contex
May 20, 2022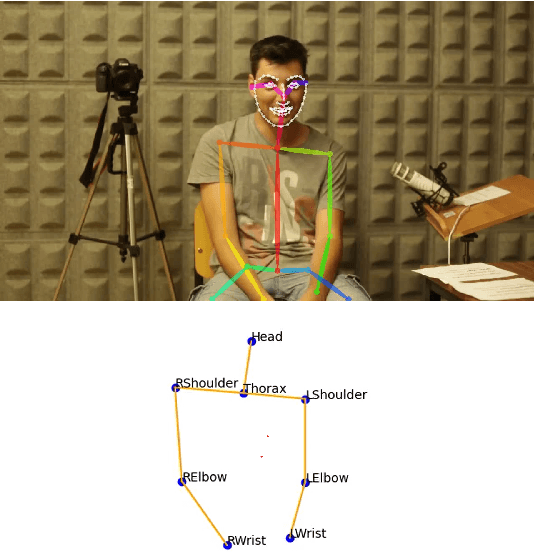

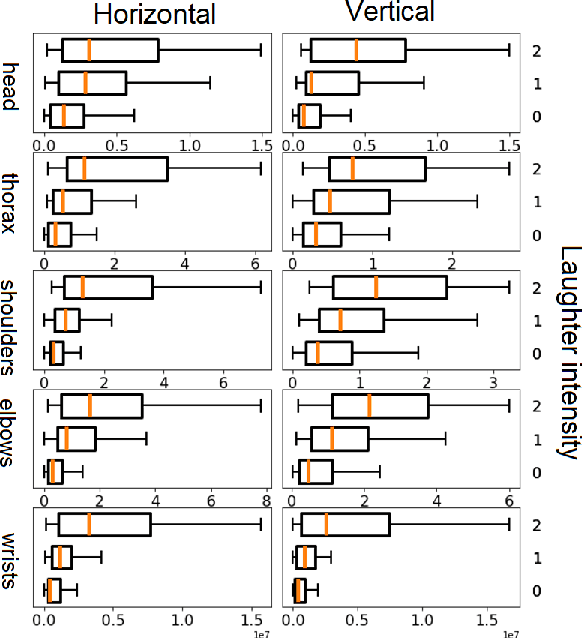
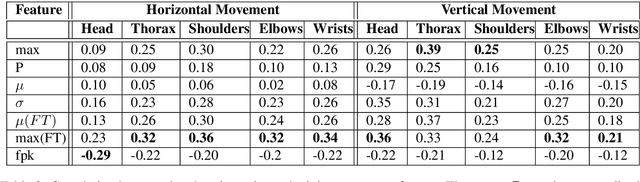
The development of virtual agents has enabled human-avatar interactions to become increasingly rich and varied. Moreover, an expressive virtual agent i.e. that mimics the natural expression of emotions, enhances social interaction between a user (human) and an agent (intelligent machine). The set of non-verbal behaviors of a virtual character is, therefore, an important component in the context of human-machine interaction. Laughter is not just an audio signal, but an intrinsic relationship of multimodal non-verbal communication, in addition to audio, it includes facial expressions and body movements. Motion analysis often relies on a relevant motion capture dataset, but the main issue is that the acquisition of such a dataset is expensive and time-consuming. This work studies the relationship between laughter and body movements in dyadic conversations. The body movements were extracted from videos using deep learning based pose estimator model. We found that, in the explored NDC-ME dataset, a single statistical feature (i.e, the maximum value, or the maximum of Fourier transform) of a joint movement weakly correlates with laughter intensity by 30%. However, we did not find a direct correlation between audio features and body movements. We discuss about the challenges to use such dataset for the audio-driven co-laughter motion synthesis task.
AEGIS: A real-time multimodal augmented reality computer vision based system to assist facial expression recognition for individuals with autism spectrum disorder
Oct 22, 2020The ability to interpret social cues comes naturally for most people, but for those living with Autism Spectrum Disorder (ASD), some experience a deficiency in this area. This paper presents the development of a multimodal augmented reality (AR) system which combines the use of computer vision and deep convolutional neural networks (CNN) in order to assist individuals with the detection and interpretation of facial expressions in social settings. The proposed system, which we call AEGIS (Augmented-reality Expression Guided Interpretation System), is an assistive technology deployable on a variety of user devices including tablets, smartphones, video conference systems, or smartglasses, showcasing its extreme flexibility and wide range of use cases, to allow integration into daily life with ease. Given a streaming video camera source, each real-world frame is passed into AEGIS, processed for facial bounding boxes, and then fed into our novel deep convolutional time windowed neural network (TimeConvNet). We leverage both spatial and temporal information in order to provide an accurate expression prediction, which is then converted into its corresponding visualization and drawn on top of the original video frame. The system runs in real-time, requires minimal set up and is simple to use. With the use of AEGIS, we can assist individuals living with ASD to learn to better identify expressions and thus improve their social experiences.
Single-Image 3D Face Reconstruction under Perspective Projection
May 09, 2022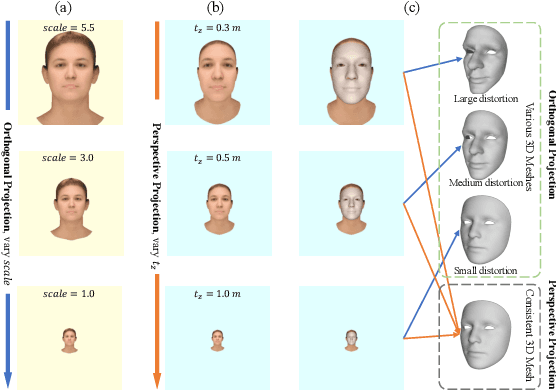
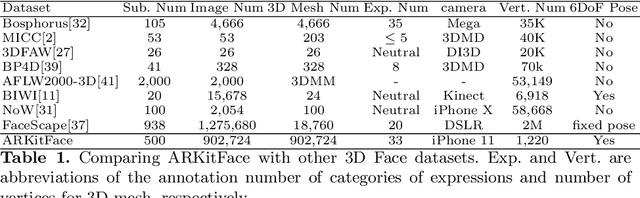
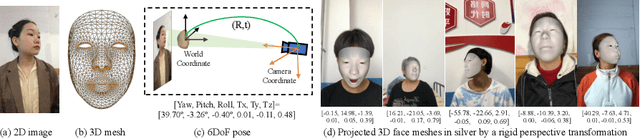

In 3D face reconstruction, orthogonal projection has been widely employed to substitute perspective projection to simplify the fitting process. This approximation performs well when the distance between camera and face is far enough. However, in some scenarios that the face is very close to camera or moving along the camera axis, the methods suffer from the inaccurate reconstruction and unstable temporal fitting due to the distortion under the perspective projection. In this paper, we aim to address the problem of single-image 3D face reconstruction under perspective projection. Specifically, a deep neural network, Perspective Network (PerspNet), is proposed to simultaneously reconstruct 3D face shape in canonical space and learn the correspondence between 2D pixels and 3D points, by which the 6DoF (6 Degrees of Freedom) face pose can be estimated to represent perspective projection. Besides, we contribute a large ARKitFace dataset to enable the training and evaluation of 3D face reconstruction solutions under the scenarios of perspective projection, which has 902,724 2D facial images with ground-truth 3D face mesh and annotated 6DoF pose parameters. Experimental results show that our approach outperforms current state-of-the-art methods by a significant margin.
Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet
Oct 03, 2017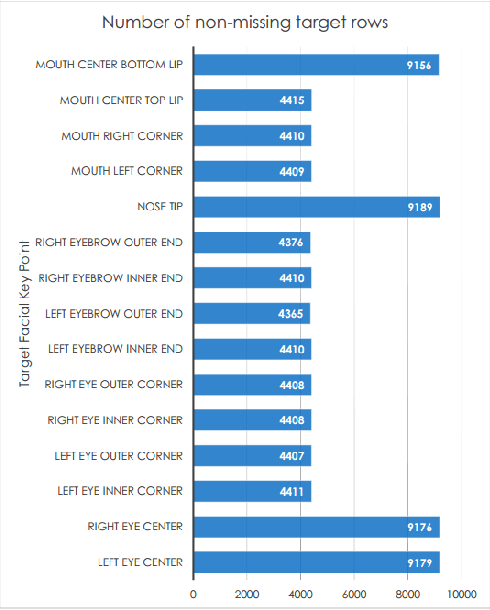
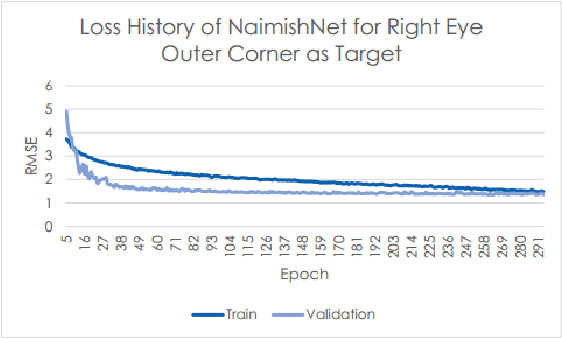
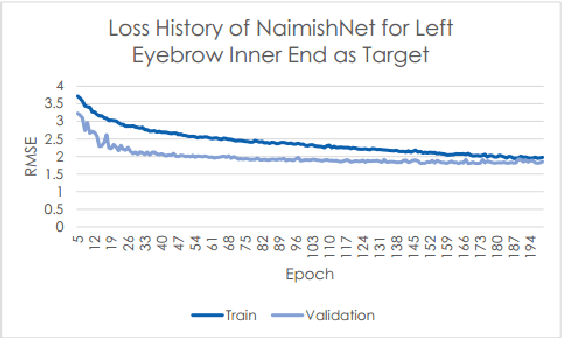
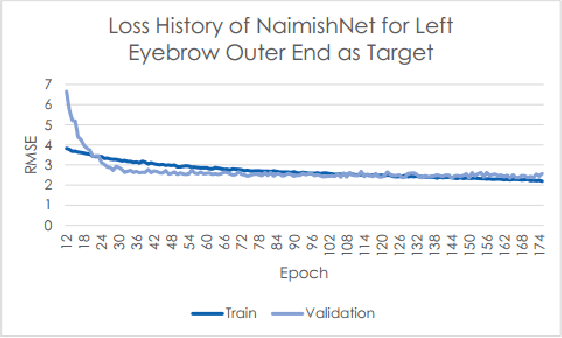
Facial Key Points (FKPs) Detection is an important and challenging problem in the fields of computer vision and machine learning. It involves predicting the co-ordinates of the FKPs, e.g. nose tip, center of eyes, etc, for a given face. In this paper, we propose a LeNet adapted Deep CNN model - NaimishNet, to operate on facial key points data and compare our model's performance against existing state of the art approaches.