 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
AttGAN: Facial Attribute Editing by Only Changing What You Want
Jul 25, 2018

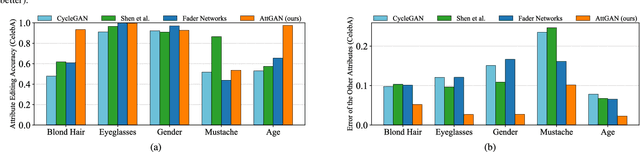
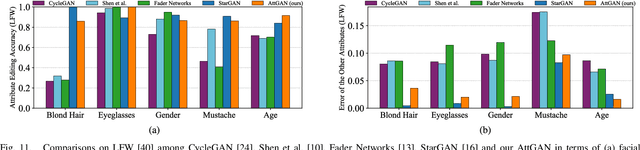

Facial attribute editing aims to manipulate single or multiple attributes of a face image, i.e., to generate a new face with desired attributes while preserving other details. Recently, generative adversarial net (GAN) and encoder-decoder architecture are usually incorporated to handle this task with promising results. Based on the encoder-decoder architecture, facial attribute editing is achieved by decoding the latent representation of the given face conditioned on the desired attributes. Some existing methods attempt to establish an attribute-independent latent representation for further attribute editing. However, such attribute-independent constraint on the latent representation is excessive because it restricts the capacity of the latent representation and may result in information loss, leading to over-smooth and distorted generation. Instead of imposing constraints on the latent representation, in this work we apply an attribute classification constraint to the generated image to just guarantee the correct change of desired attributes, i.e., to "change what you want". Meanwhile, the reconstruction learning is introduced to preserve attribute-excluding details, in other words, to "only change what you want". Besides, the adversarial learning is employed for visually realistic editing. These three components cooperate with each other forming an effective framework for high quality facial attribute editing, referred as AttGAN. Furthermore, our method is also directly applicable for attribute intensity control and can be naturally extended for attribute style manipulation. Experiments on CelebA dataset show that our method outperforms the state-of-the-arts on realistic attribute editing with facial details well preserved.
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022
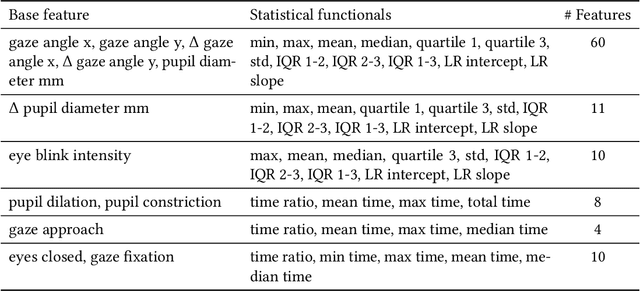

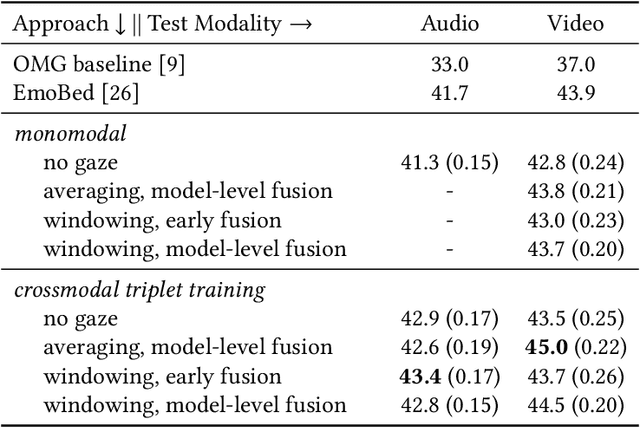
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.
Deep Representation of Facial Geometric and Photometric Attributes for Automatic 3D Facial Expression Recognition
Nov 10, 2015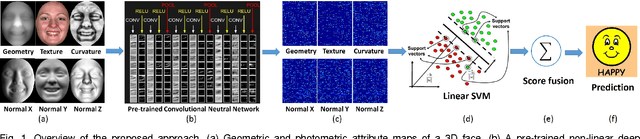
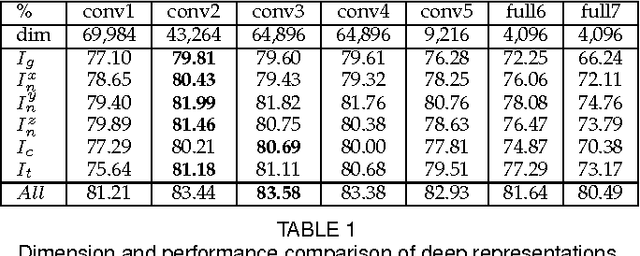
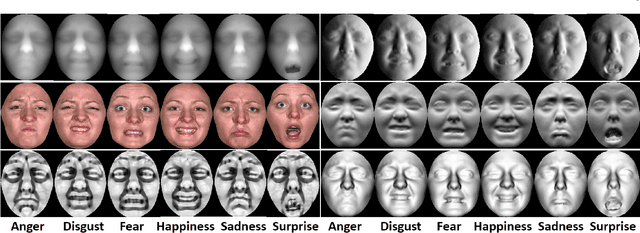
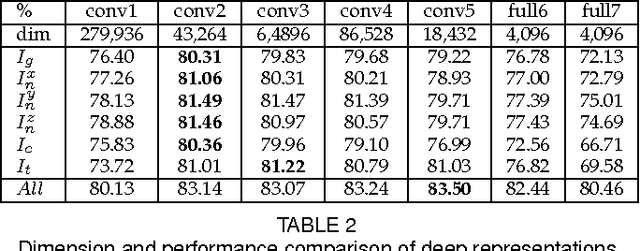
In this paper, we present a novel approach to automatic 3D Facial Expression Recognition (FER) based on deep representation of facial 3D geometric and 2D photometric attributes. A 3D face is firstly represented by its geometric and photometric attributes, including the geometry map, normal maps, normalized curvature map and texture map. These maps are then fed into a pre-trained deep convolutional neural network to generate the deep representation. Then the facial expression prediction is simplyachieved by training linear SVMs over the deep representation for different maps and fusing these SVM scores. The visualizations show that the deep representation provides a complete and highly discriminative coding scheme for 3D faces. Comprehensive experiments on the BU-3DFE database demonstrate that the proposed deep representation can outperform the widely used hand-crafted descriptors (i.e., LBP, SIFT, HOG, Gabor) and the state-of-art approaches under the same experimental protocols.
Imposing Temporal Consistency on Deep Monocular Body Shape and Pose Estimation
Feb 08, 2022Accurate and temporally consistent modeling of human bodies is essential for a wide range of applications, including character animation, understanding human social behavior and AR/VR interfaces. Capturing human motion accurately from a monocular image sequence is still challenging and the modeling quality is strongly influenced by the temporal consistency of the captured body motion. Our work presents an elegant solution for the integration of temporal constraints in the fitting process. This does not only increase temporal consistency but also robustness during the optimization. In detail, we derive parameters of a sequence of body models, representing shape and motion of a person, including jaw poses, facial expressions, and finger poses. We optimize these parameters over the complete image sequence, fitting one consistent body shape while imposing temporal consistency on the body motion, assuming linear body joint trajectories over a short time. Our approach enables the derivation of realistic 3D body models from image sequences, including facial expression and articulated hands. In extensive experiments, we show that our approach results in accurately estimated body shape and motion, also for challenging movements and poses. Further, we apply it to the special application of sign language analysis, where accurate and temporal consistent motion modelling is essential, and show that the approach is well-suited for this kind of application.
Predicting Personal Traits from Facial Images using Convolutional Neural Networks Augmented with Facial Landmark Information
May 29, 2016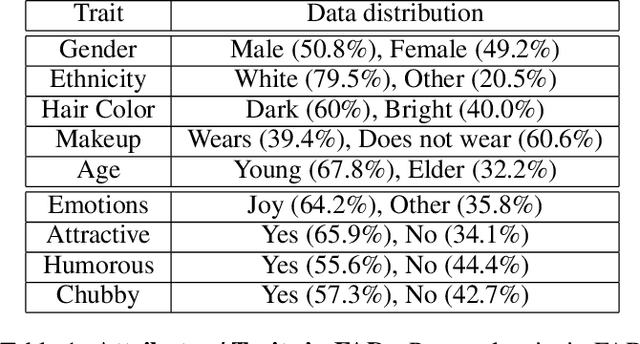
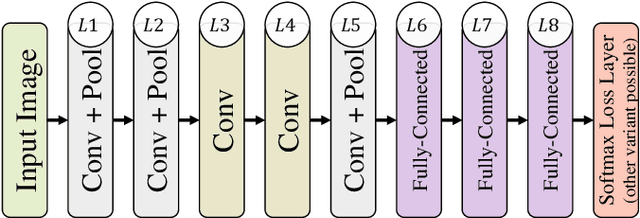
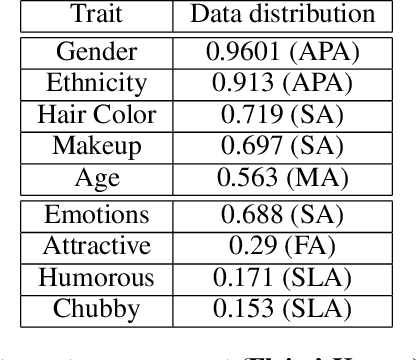

We consider the task of predicting various traits of a person given an image of their face. We estimate both objective traits, such as gender, ethnicity and hair-color; as well as subjective traits, such as the emotion a person expresses or whether he is humorous or attractive. For sizeable experimentation, we contribute a new Face Attributes Dataset (FAD), having roughly 200,000 attribute labels for the above traits, for over 10,000 facial images. Due to the recent surge of research on Deep Convolutional Neural Networks (CNNs), we begin by using a CNN architecture for estimating facial attributes and show that they indeed provide an impressive baseline performance. To further improve performance, we propose a novel approach that incorporates facial landmark information for input images as an additional channel, helping the CNN learn better attribute-specific features so that the landmarks across various training images hold correspondence. We empirically analyse the performance of our method, showing consistent improvement over the baseline across traits.
LFW-Beautified: A Dataset of Face Images with Beautification and Augmented Reality Filters
Mar 11, 2022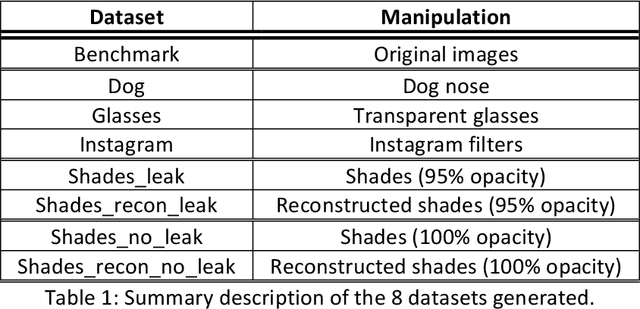
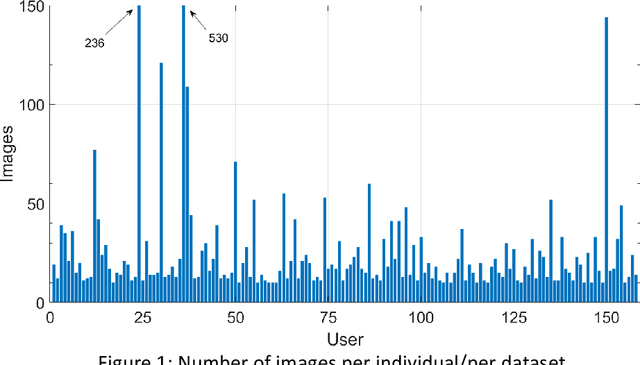


Selfie images enjoy huge popularity in social media. The same platforms centered around sharing this type of images offer filters to beautify them or incorporate augmented reality effects. Studies suggests that filtered images attract more views and engagement. Selfie images are also in increasing use in security applications due to mobiles becoming data hubs for many transactions. Also, video conference applications, boomed during the pandemic, include such filters. Such filters may destroy biometric features that would allow person recognition or even detection of the face itself, even if such commodity applications are not necessarily used to compromise facial systems. This could also affect subsequent investigations like crimes in social media, where automatic analysis is usually necessary given the amount of information posted in social sites or stored in devices or cloud repositories. To help in counteracting such issues, we contribute with a database of facial images that includes several manipulations. It includes image enhancement filters (which mostly modify contrast and lightning) and augmented reality filters that incorporate items like animal noses or glasses. Additionally, images with sunglasses are processed with a reconstruction network trained to learn to reverse such modifications. This is because obfuscating the eye region has been observed in the literature to have the highest impact on the accuracy of face detection or recognition. We start from the popular Labeled Faces in the Wild (LFW) database, to which we apply different modifications, generating 8 datasets. Each dataset contains 4,324 images of size 64 x 64, with a total of 34,592 images. The use of a public and widely employed face dataset allows for replication and comparison. The created database is available at https://github.com/HalmstadUniversityBiometrics/LFW-Beautified
Improved Techniques for GAN based Facial Inpainting
Oct 20, 2018
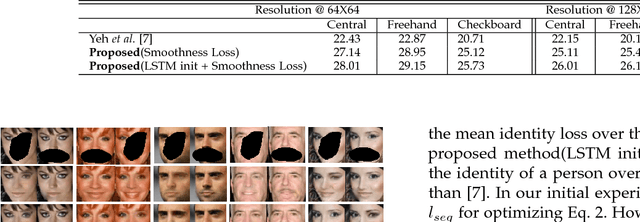

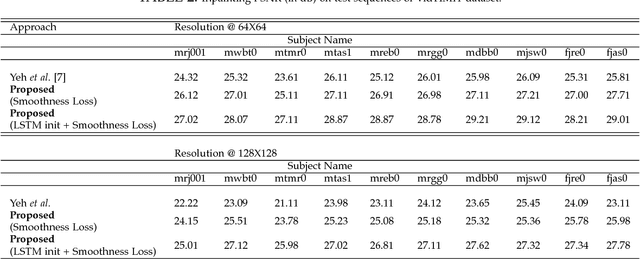
In this paper we present several architectural and optimization recipes for generative adversarial network(GAN) based facial semantic inpainting. Current benchmark models are susceptible to initial solutions of non-convex optimization criterion of GAN based inpainting. We present an end-to-end trainable parametric network to deterministically start from good initial solutions leading to more photo realistic reconstructions with significant optimization speed up. For the first time, we show how to efficiently extend GAN based single image inpainter models to sequences by a)learning to initialize a temporal window of solutions with a recurrent neural network and b)imposing a temporal smoothness loss(during iterative optimization) to respect the redundancy in temporal dimension of a sequence. We conduct comprehensive empirical evaluations on CelebA images and pseudo sequences followed by real life videos of VidTIMIT dataset. The proposed method significantly outperforms current GAN based state-of-the-art in terms of reconstruction quality with a simultaneous speedup of over 15$\times$. We also show that our proposed model is better in preserving facial identity in a sequence even without explicitly using any face recognition module during training.
Understanding Cross Domain Presentation Attack Detection for Visible Face Recognition
Nov 03, 2021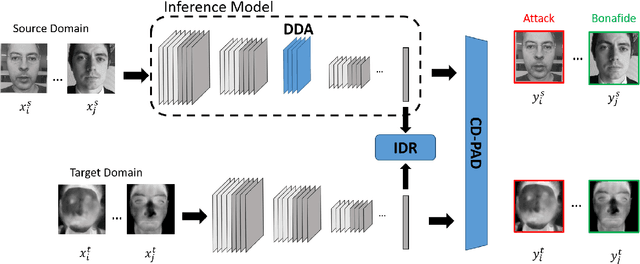
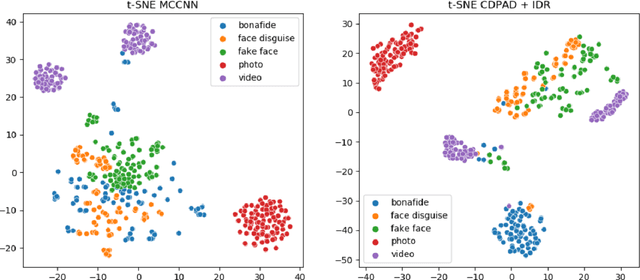
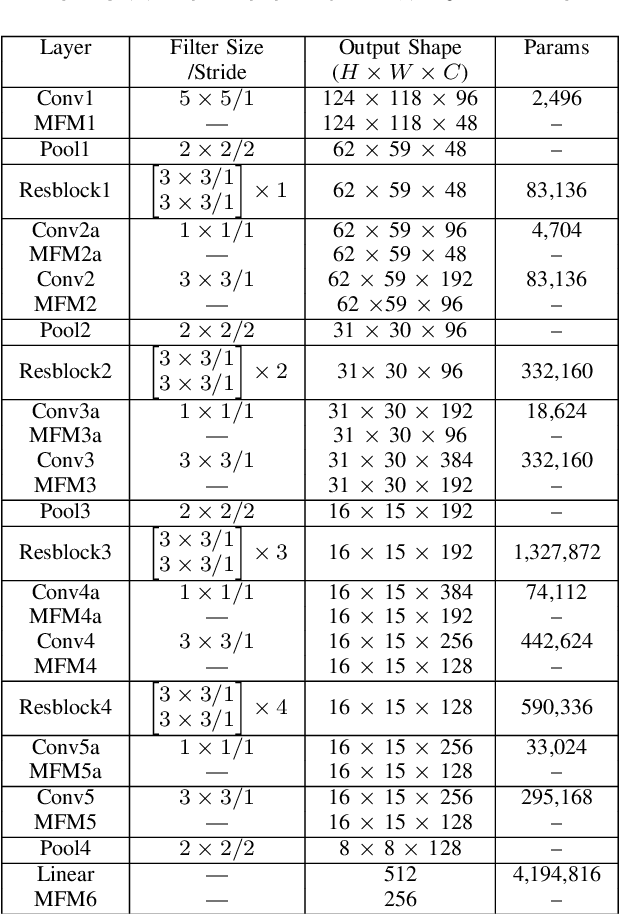

Face signatures, including size, shape, texture, skin tone, eye color, appearance, and scars/marks, are widely used as discriminative, biometric information for access control. Despite recent advancements in facial recognition systems, presentation attacks on facial recognition systems have become increasingly sophisticated. The ability to detect presentation attacks or spoofing attempts is a pressing concern for the integrity, security, and trust of facial recognition systems. Multi-spectral imaging has been previously introduced as a way to improve presentation attack detection by utilizing sensors that are sensitive to different regions of the electromagnetic spectrum (e.g., visible, near infrared, long-wave infrared). Although multi-spectral presentation attack detection systems may be discriminative, the need for additional sensors and computational resources substantially increases complexity and costs. Instead, we propose a method that exploits information from infrared imagery during training to increase the discriminability of visible-based presentation attack detection systems. We introduce (1) a new cross-domain presentation attack detection framework that increases the separability of bonafide and presentation attacks using only visible spectrum imagery, (2) an inverse domain regularization technique for added training stability when optimizing our cross-domain presentation attack detection framework, and (3) a dense domain adaptation subnetwork to transform representations between visible and non-visible domains.
JAA-Net: Joint Facial Action Unit Detection and Face Alignment via Adaptive Attention
Mar 18, 2020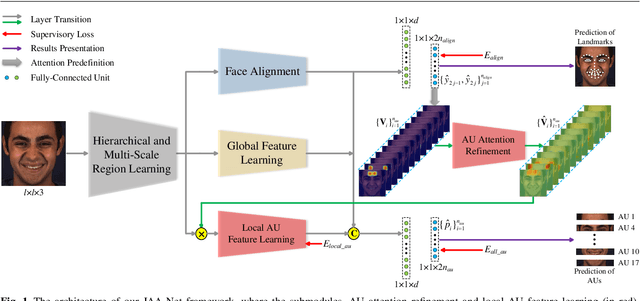
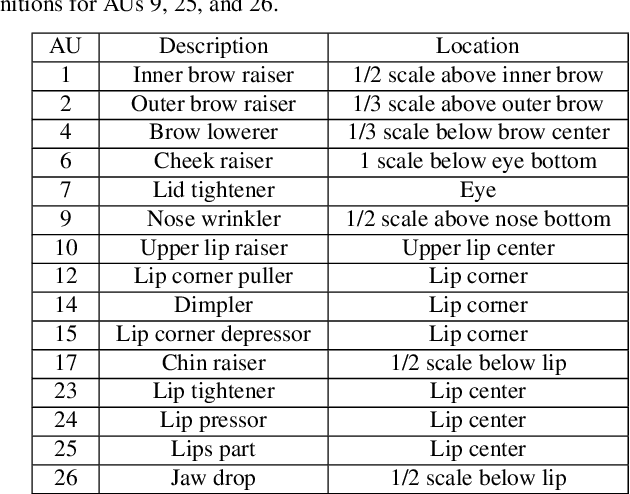
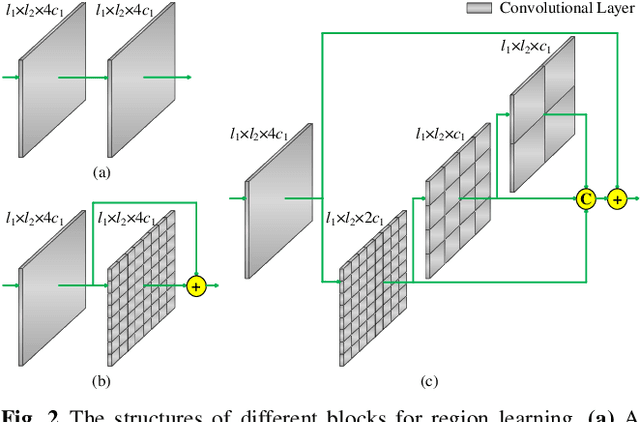
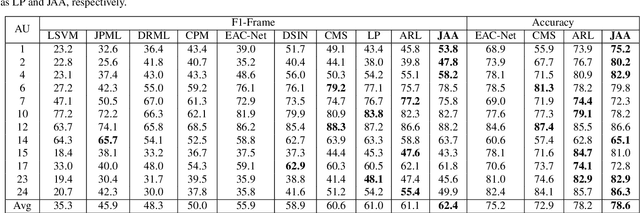
Facial action unit (AU) detection and face alignment are two highly correlated tasks, since facial landmarks can provide precise AU locations to facilitate the extraction of meaningful local features for AU detection. However, most existing AU detection works handle the two tasks independently by treating face alignment as a preprocessing, and often use landmarks to predefine a fixed region or attention for each AU. In this paper, we propose a novel end-to-end deep learning framework for joint AU detection and face alignment, which has not been explored before. In particular, multi-scale shared feature is learned firstly, and high-level feature of face alignment is fed into AU detection. Moreover, to extract precise local features, we propose an adaptive attention learning module to refine the attention map of each AU adaptively. Finally, the assembled local features are integrated with face alignment feature and global feature for AU detection. Extensive experiments demonstrate that our framework (i) significantly outperforms the state-of-the-art AU detection methods on the challenging BP4D, DISFA, GFT and BP4D+ benchmarks, (ii) can adaptively capture the irregular region of each AU, (iii) achieves competitive performance for face alignment, and (iv) also works well under partial occlusions and non-frontal poses. The code for our method is available at https://github.com/ZhiwenShao/PyTorch-JAANet.
Deep Metric Structured Learning For Facial Expression Recognition
Jan 18, 2020
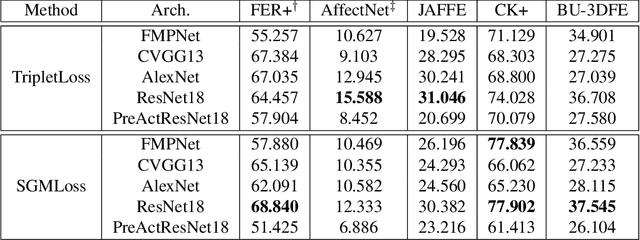
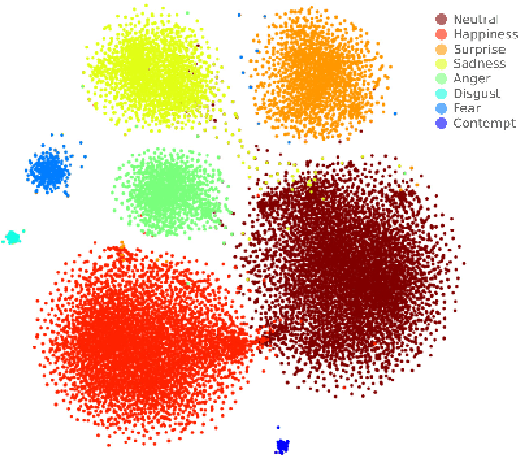
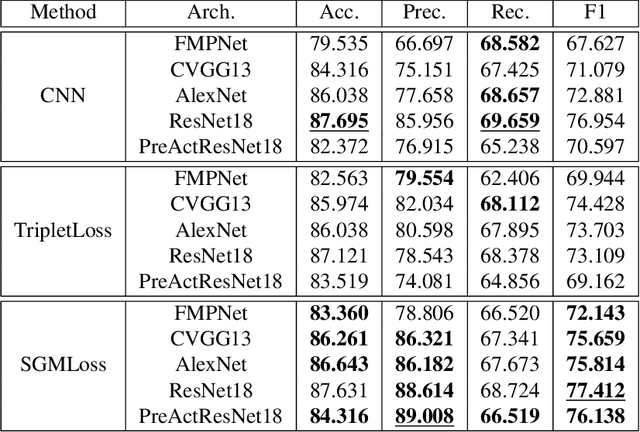
We propose a deep metric learning model to create embedded sub-spaces with a well defined structure. A new loss function that imposes Gaussian structures on the output space is introduced to create these sub-spaces thus shaping the distribution of the data. Having a mixture of Gaussians solution space is advantageous given its simplified and well established structure. It allows fast discovering of classes within classes and the identification of mean representatives at the centroids of individual classes. We also propose a new semi-supervised method to create sub-classes. We illustrate our methods on the facial expression recognition problem and validate results on the FER+, AffectNet, Extended Cohn-Kanade (CK+), BU-3DFE, and JAFFE datasets. We experimentally demonstrate that the learned embedding can be successfully used for various applications including expression retrieval and emotion recognition.