 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Aggregation via Separation: Boosting Facial Landmark Detector with Semi-Supervised Style Translation
Aug 18, 2019

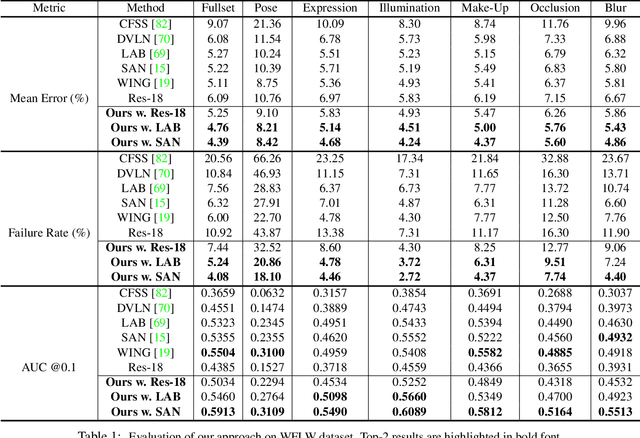
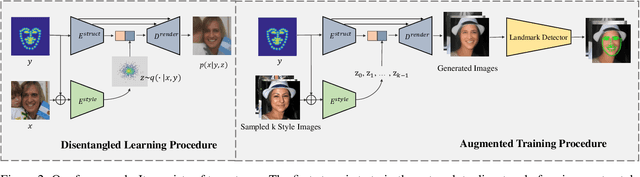
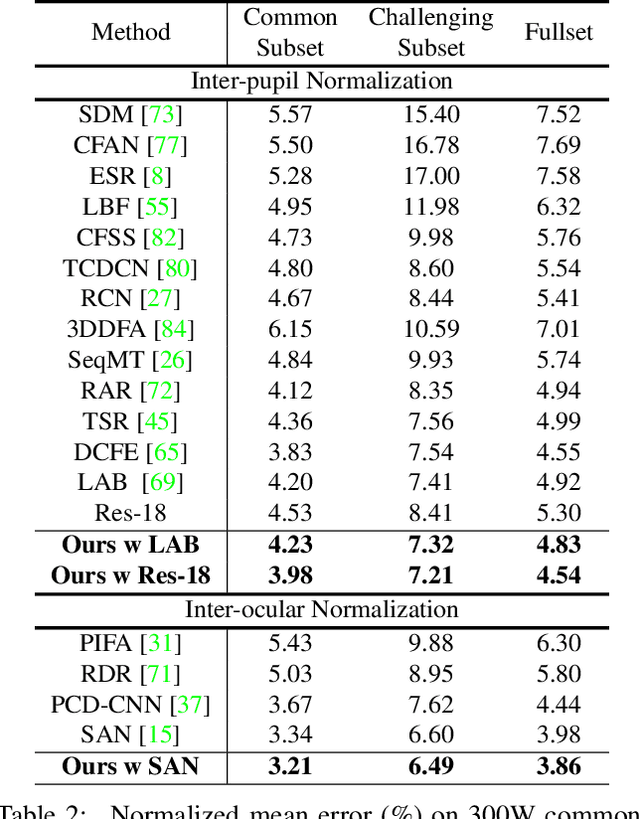
Facial landmark detection, or face alignment, is a fundamental task that has been extensively studied. In this paper, we investigate a new perspective of facial landmark detection and demonstrate it leads to further notable improvement. Given that any face images can be factored into space of style that captures lighting, texture and image environment, and a style-invariant structure space, our key idea is to leverage disentangled style and shape space of each individual to augment existing structures via style translation. With these augmented synthetic samples, our semi-supervised model surprisingly outperforms the fully-supervised one by a large margin. Extensive experiments verify the effectiveness of our idea with state-of-the-art results on WFLW, 300W, COFW, and AFLW datasets. Our proposed structure is general and could be assembled into any face alignment frameworks. The code is made publicly available at https://github.com/thesouthfrog/stylealign.
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022
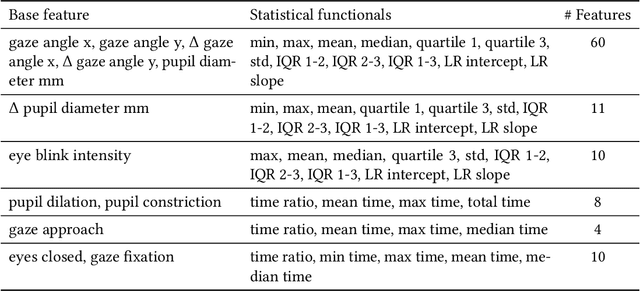

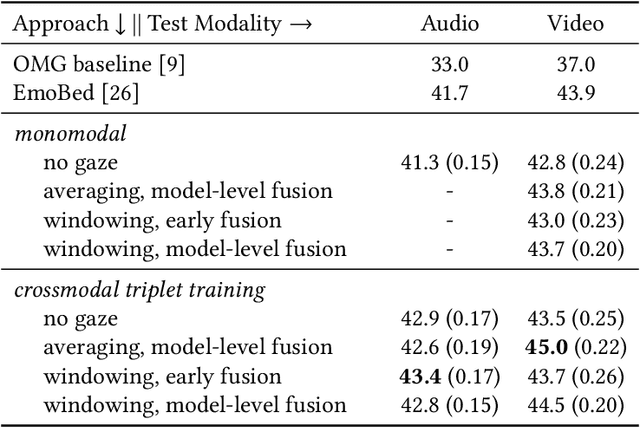
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.
On the Pitfalls of Learning with Limited Data: A Facial Expression Recognition Case Study
Apr 02, 2021
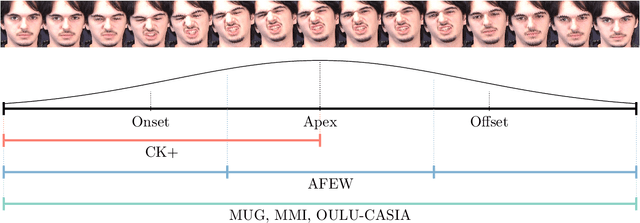
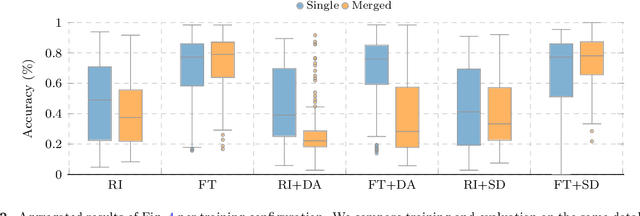
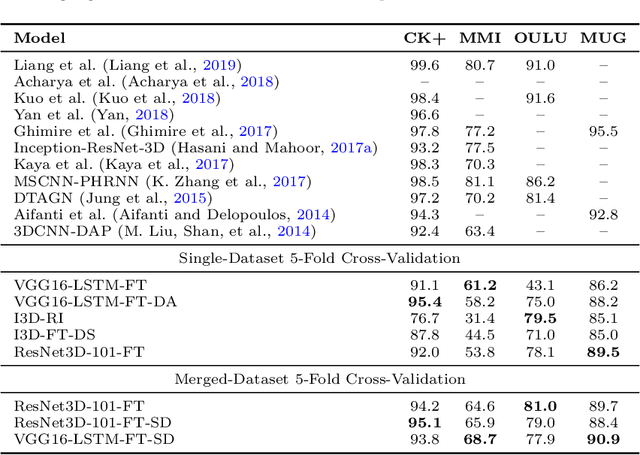
Deep learning models need large amounts of data for training. In video recognition and classification, significant advances were achieved with the introduction of new large databases. However, the creation of large-databases for training is infeasible in several scenarios. Thus, existing or small collected databases are typically joined and amplified to train these models. Nevertheless, training neural networks on limited data is not straightforward and comes with a set of problems. In this paper, we explore the effects of stacking databases, model initialization, and data amplification techniques when training with limited data on deep learning models' performance. We focused on the problem of Facial Expression Recognition from videos. We performed an extensive study with four databases at a different complexity and nine deep-learning architectures for video classification. We found that (i) complex training sets translate better to more stable test sets when trained with transfer learning and synthetically generated data, but their performance yields a high variance; (ii) training with more detailed data translates to more stable performance on novel scenarios (albeit with lower performance); (iii) merging heterogeneous data is not a straightforward improvement, as the type of augmentation and initialization is crucial; (iv) classical data augmentation cannot fill the holes created by joining largely separated datasets; and (v) inductive biases help to bridge the gap when paired with synthetic data, but this data is not enough when working with standard initialization techniques.
ExprGAN: Facial Expression Editing with Controllable Expression Intensity
Sep 13, 2017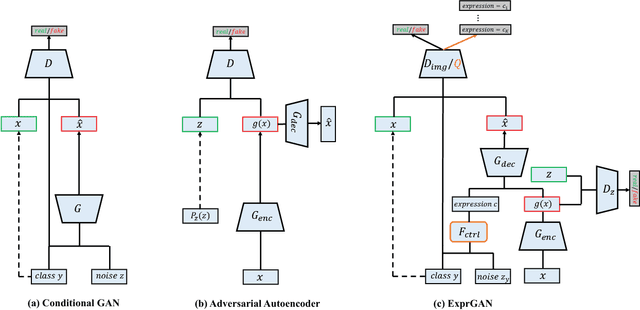



Facial expression editing is a challenging task as it needs a high-level semantic understanding of the input face image. In conventional methods, either paired training data is required or the synthetic face resolution is low. Moreover, only the categories of facial expression can be changed. To address these limitations, we propose an Expression Generative Adversarial Network (ExprGAN) for photo-realistic facial expression editing with controllable expression intensity. An expression controller module is specially designed to learn an expressive and compact expression code in addition to the encoder-decoder network. This novel architecture enables the expression intensity to be continuously adjusted from low to high. We further show that our ExprGAN can be applied for other tasks, such as expression transfer, image retrieval, and data augmentation for training improved face expression recognition models. To tackle the small size of the training database, an effective incremental learning scheme is proposed. Quantitative and qualitative evaluations on the widely used Oulu-CASIA dataset demonstrate the effectiveness of ExprGAN.
LFW-Beautified: A Dataset of Face Images with Beautification and Augmented Reality Filters
Mar 11, 2022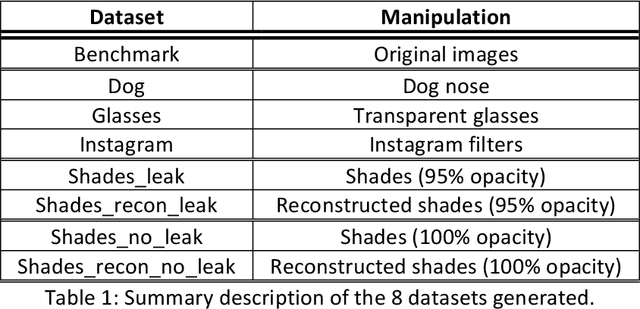
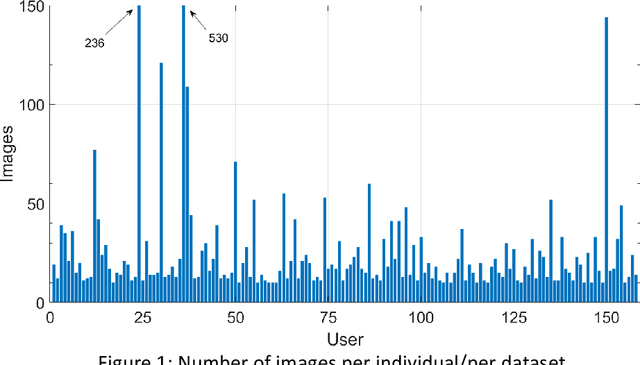


Selfie images enjoy huge popularity in social media. The same platforms centered around sharing this type of images offer filters to beautify them or incorporate augmented reality effects. Studies suggests that filtered images attract more views and engagement. Selfie images are also in increasing use in security applications due to mobiles becoming data hubs for many transactions. Also, video conference applications, boomed during the pandemic, include such filters. Such filters may destroy biometric features that would allow person recognition or even detection of the face itself, even if such commodity applications are not necessarily used to compromise facial systems. This could also affect subsequent investigations like crimes in social media, where automatic analysis is usually necessary given the amount of information posted in social sites or stored in devices or cloud repositories. To help in counteracting such issues, we contribute with a database of facial images that includes several manipulations. It includes image enhancement filters (which mostly modify contrast and lightning) and augmented reality filters that incorporate items like animal noses or glasses. Additionally, images with sunglasses are processed with a reconstruction network trained to learn to reverse such modifications. This is because obfuscating the eye region has been observed in the literature to have the highest impact on the accuracy of face detection or recognition. We start from the popular Labeled Faces in the Wild (LFW) database, to which we apply different modifications, generating 8 datasets. Each dataset contains 4,324 images of size 64 x 64, with a total of 34,592 images. The use of a public and widely employed face dataset allows for replication and comparison. The created database is available at https://github.com/HalmstadUniversityBiometrics/LFW-Beautified
Imposing Temporal Consistency on Deep Monocular Body Shape and Pose Estimation
Feb 08, 2022Accurate and temporally consistent modeling of human bodies is essential for a wide range of applications, including character animation, understanding human social behavior and AR/VR interfaces. Capturing human motion accurately from a monocular image sequence is still challenging and the modeling quality is strongly influenced by the temporal consistency of the captured body motion. Our work presents an elegant solution for the integration of temporal constraints in the fitting process. This does not only increase temporal consistency but also robustness during the optimization. In detail, we derive parameters of a sequence of body models, representing shape and motion of a person, including jaw poses, facial expressions, and finger poses. We optimize these parameters over the complete image sequence, fitting one consistent body shape while imposing temporal consistency on the body motion, assuming linear body joint trajectories over a short time. Our approach enables the derivation of realistic 3D body models from image sequences, including facial expression and articulated hands. In extensive experiments, we show that our approach results in accurately estimated body shape and motion, also for challenging movements and poses. Further, we apply it to the special application of sign language analysis, where accurate and temporal consistent motion modelling is essential, and show that the approach is well-suited for this kind of application.
Multi Visual Modality Fall Detection Dataset
Jun 25, 2022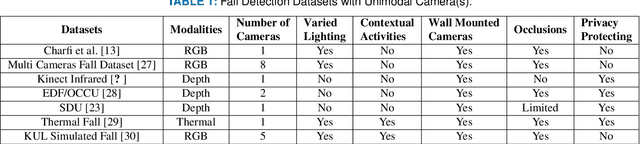

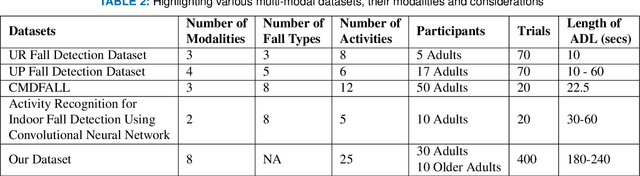
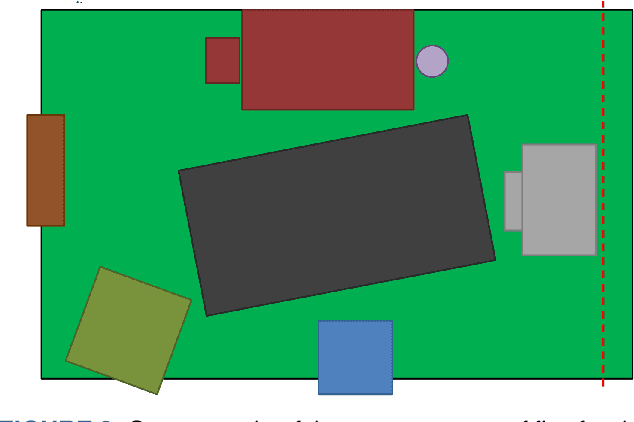
Falls are one of the leading cause of injury-related deaths among the elderly worldwide. Effective detection of falls can reduce the risk of complications and injuries. Fall detection can be performed using wearable devices or ambient sensors; these methods may struggle with user compliance issues or false alarms. Video cameras provide a passive alternative; however, regular RGB cameras are impacted by changing lighting conditions and privacy concerns. From a machine learning perspective, developing an effective fall detection system is challenging because of the rarity and variability of falls. Many existing fall detection datasets lack important real-world considerations, such as varied lighting, continuous activities of daily living (ADLs), and camera placement. The lack of these considerations makes it difficult to develop predictive models that can operate effectively in the real world. To address these limitations, we introduce a novel multi-modality dataset (MUVIM) that contains four visual modalities: infra-red, depth, RGB and thermal cameras. These modalities offer benefits such as obfuscated facial features and improved performance in low-light conditions. We formulated fall detection as an anomaly detection problem, in which a customized spatio-temporal convolutional autoencoder was trained only on ADLs so that a fall would increase the reconstruction error. Our results showed that infra-red cameras provided the highest level of performance (AUC ROC=0.94), followed by thermal (AUC ROC=0.87), depth (AUC ROC=0.86) and RGB (AUC ROC=0.83). This research provides a unique opportunity to analyze the utility of camera modalities in detecting falls in a home setting while balancing performance, passiveness, and privacy.
Ollivier-Ricci Curvature For Head Pose Estimation From a Single Image
Apr 27, 2022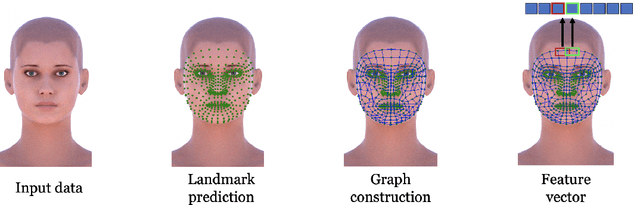
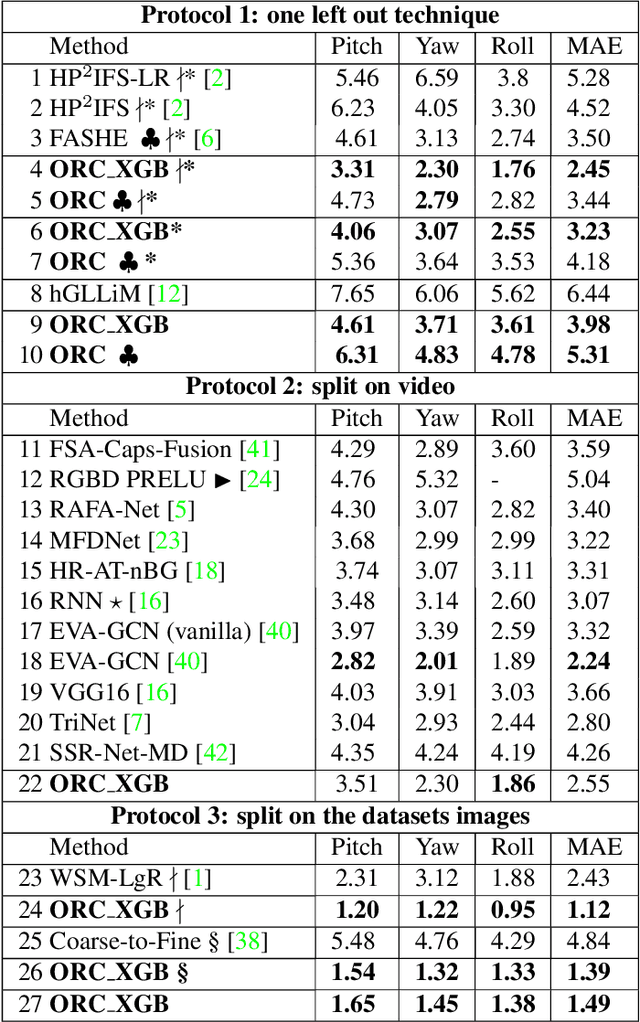
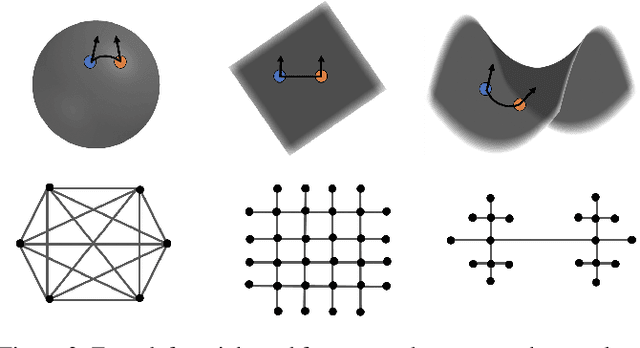
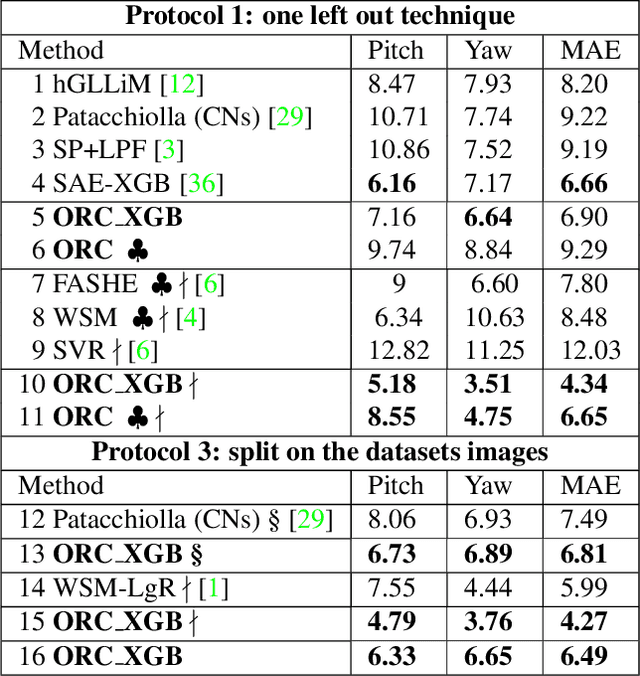
Head pose estimation is a crucial challenge for many real-world applications, such as attention and human behavior analysis. This paper aims to estimate head pose from a single image by applying notions of network curvature. In the real world, many complex networks have groups of nodes that are well connected to each other with significant functional roles. Similarly, the interactions of facial landmarks can be represented as complex dynamic systems modeled by weighted graphs. The functionalities of such systems are therefore intrinsically linked to the topology and geometry of the underlying graph. In this work, using the geometric notion of Ollivier-Ricci curvature (ORC) on weighted graphs as input to the XGBoost regression model, we show that the intrinsic geometric basis of ORC offers a natural approach to discovering underlying common structure within a pool of poses. Experiments on the BIWI, AFLW2000 and Pointing'04 datasets show that the ORC_XGB method performs well compared to state-of-the-art methods, both landmark-based and image-only.
Facial age estimation by deep residual decision making
Aug 28, 2019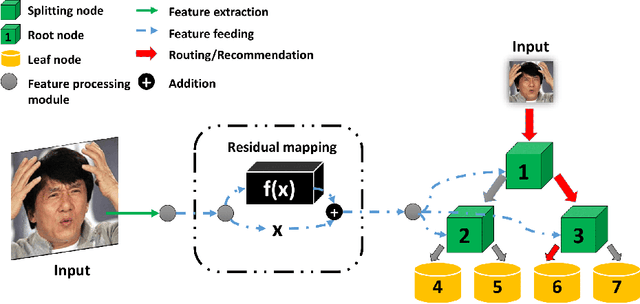
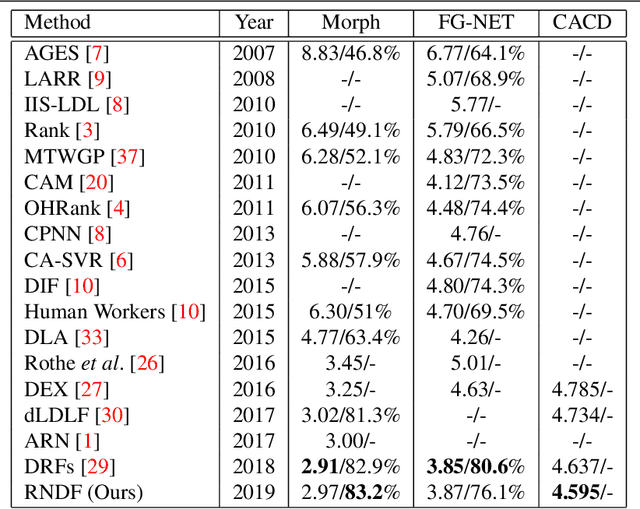

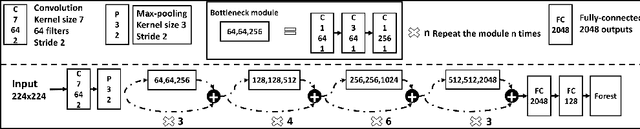
Residual representation learning simplifies the optimization problem of learning complex functions and has been widely used by traditional convolutional neural networks. However, it has not been applied to deep neural decision forest (NDF). In this paper we incorporate residual learning into NDF and the resulting model achieves state-of-the-art level accuracy on three public age estimation benchmarks while requiring less memory and computation. We further employ gradient-based technique to visualize the decision-making process of NDF and understand how it is influenced by facial image inputs. The code and pre-trained models will be available at https://github.com/Nicholasli1995/VisualizingNDF.
4DFAB: A Large Scale 4D Facial Expression Database for Biometric Applications
Jun 14, 2018
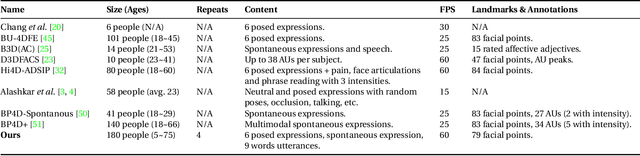


The progress we are currently witnessing in many computer vision applications, including automatic face analysis, would not be made possible without tremendous efforts in collecting and annotating large scale visual databases. To this end, we propose 4DFAB, a new large scale database of dynamic high-resolution 3D faces (over 1,800,000 3D meshes). 4DFAB contains recordings of 180 subjects captured in four different sessions spanning over a five-year period. It contains 4D videos of subjects displaying both spontaneous and posed facial behaviours. The database can be used for both face and facial expression recognition, as well as behavioural biometrics. It can also be used to learn very powerful blendshapes for parametrising facial behaviour. In this paper, we conduct several experiments and demonstrate the usefulness of the database for various applications. The database will be made publicly available for research purposes.