 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Noisy Student Training using Body Language Dataset Improves Facial Expression Recognition
Aug 06, 2020
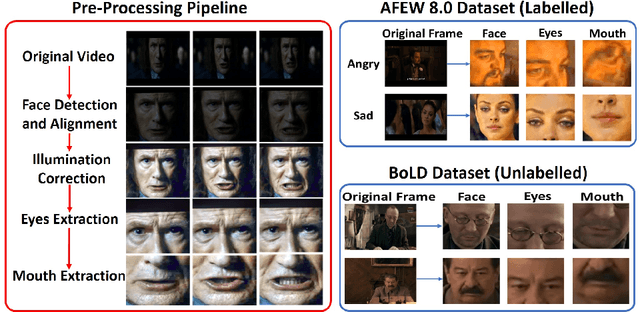
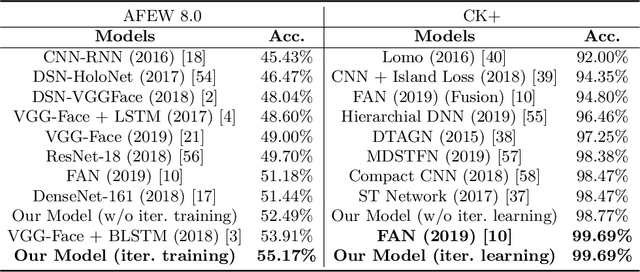
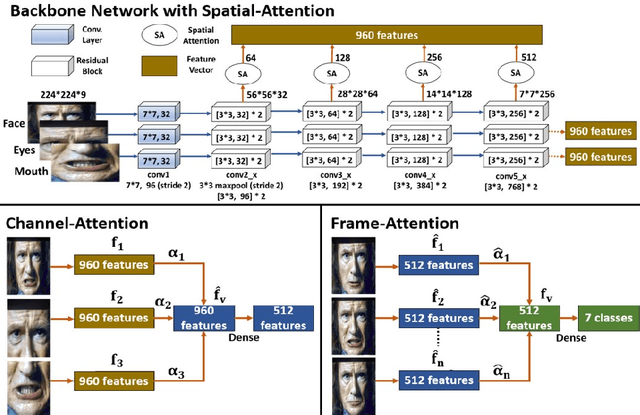
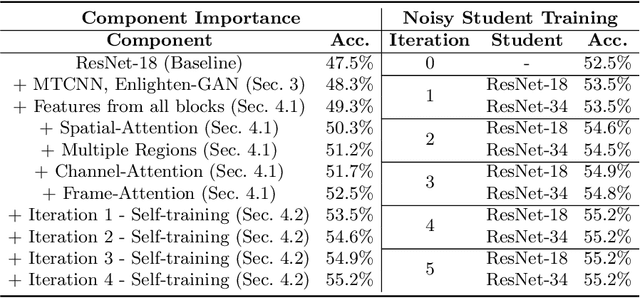
Facial expression recognition from videos in the wild is a challenging task due to the lack of abundant labelled training data. Large DNN (deep neural network) architectures and ensemble methods have resulted in better performance, but soon reach saturation at some point due to data inadequacy. In this paper, we use a self-training method that utilizes a combination of a labelled dataset and an unlabelled dataset (Body Language Dataset - BoLD). Experimental analysis shows that training a noisy student network iteratively helps in achieving significantly better results. Additionally, our model isolates different regions of the face and processes them independently using a multi-level attention mechanism which further boosts the performance. Our results show that the proposed method achieves state-of-the-art performance on benchmark datasets CK+ and AFEW 8.0 when compared to other single models.
Point Adversarial Self Mining: A Simple Method for Facial Expression Recognition in the Wild
Aug 26, 2020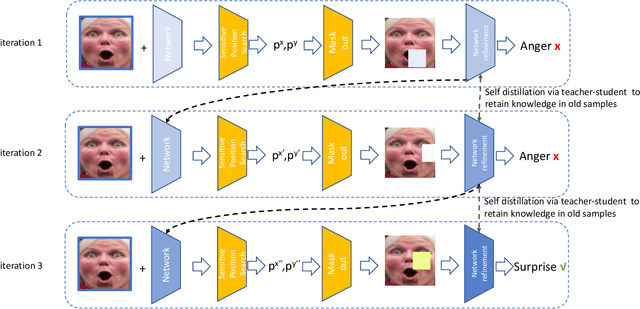
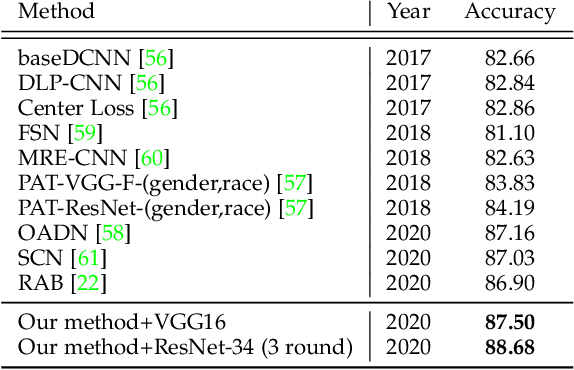
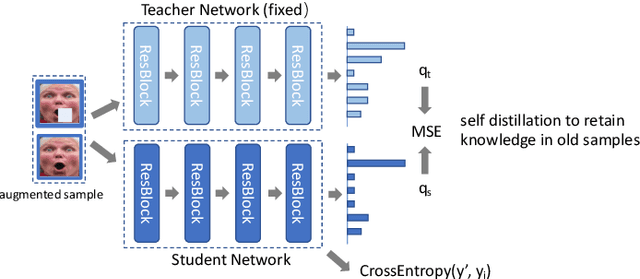

In this paper, the Point Adversarial Self Mining (PASM) approach, a simple yet effective way to progressively mine knowledge from training samples, is proposed to produce training data for CNNs to improve the performance and network generality in Facial Expression Recognition (FER) task. In order to achieve a high prediction accuracy under real-world scenarios, most of the existing works choose to manipulate the network architectures and design sophisticated loss terms. Although demonstrated to be effective in real scenarios, those aforementioned methods require extra efforts in network design. Inspired by random erasing and adversarial erasing, we propose PASM for data augmentation, simulating the data distribution in the wild. Specifically, given a sample and a pre-trained network, our proposed approach locates the informative region in the sample generated by point adversarial attack policy. The informative region is highly structured and sparse. Comparing to the regions produced by random erasing which selects the region in a purely random way and adversarial erasing which operates by attention maps, the located informative regions obtained by PASM are more adaptive and better aligned with the previous findings: not all but only a few facial regions contribute to the accurate prediction. Then, the located informative regions are masked out from the original samples to generate augmented images, which would force the network to explore additional information from other less informative regions. The augmented images are used to finetune the network to enhance its generality. In the refinement process, we take advantage of knowledge distillation, utilizing the pre-trained network to provide guidance and retain knowledge from old samples to train a new network with the same structural configuration.
A Flatter Loss for Bias Mitigation in Cross-dataset Facial Age Estimation
Oct 20, 2020
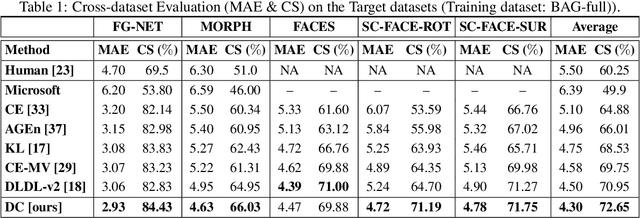
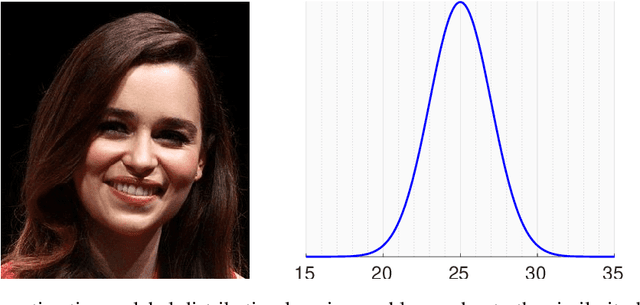
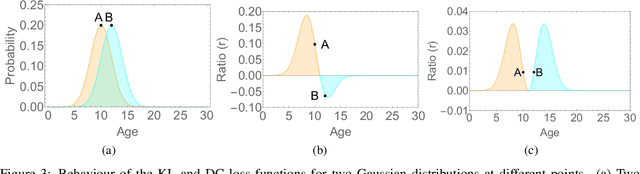
Existing studies in facial age estimation have mostly focused on intra-dataset protocols that assume training and test images captured under similar conditions. However, this is rarely valid in practical applications, where training and test sets usually have different characteristics. In this paper, we advocate a cross-dataset protocol for age estimation benchmarking. In order to improve the cross-dataset age estimation performance, we mitigate the inherent bias caused by the learning algorithm itself. To this end, we propose a novel loss function that is more effective for neural network training. The relative smoothness of the proposed loss function is its advantage with regards to the optimisation process performed by stochastic gradient descent. Its lower gradient, compared with existing loss functions, facilitates the discovery of and convergence to a better optimum, and consequently a better generalisation. The cross-dataset experimental results demonstrate the superiority of the proposed method over the state-of-the-art algorithms in terms of accuracy and generalisation capability.
SchiNet: Automatic Estimation of Symptoms of Schizophrenia from Facial Behaviour Analysis
Aug 07, 2018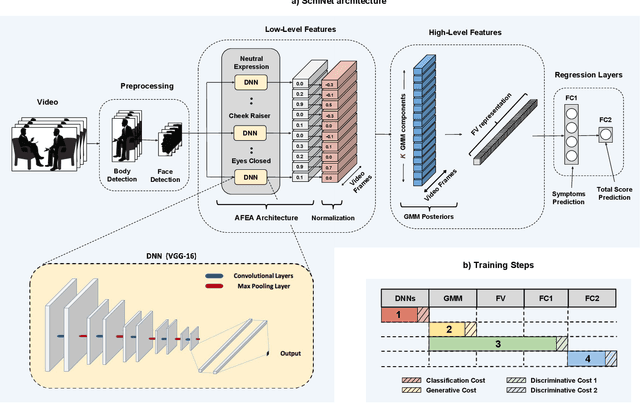
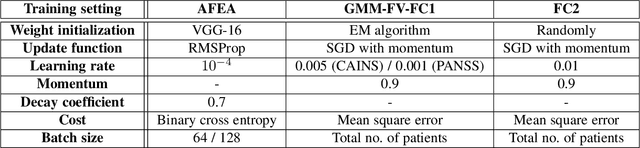
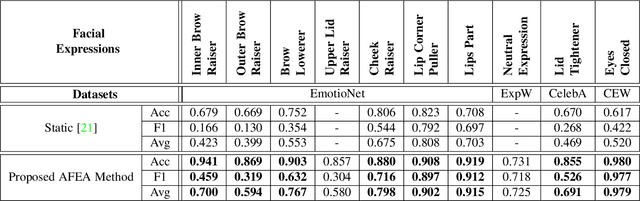
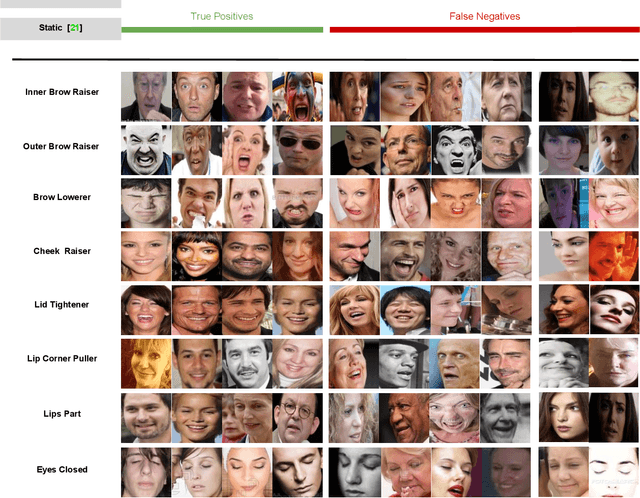
Patients with schizophrenia often display impairments in the expression of emotion and speech and those are observed in their facial behaviour. Automatic analysis of patients' facial expressions that is aimed at estimating symptoms of schizophrenia has received attention recently. However, the datasets that are typically used for training and evaluating the developed methods, contain only a small number of patients (4-34) and are recorded while the subjects were performing controlled tasks such as listening to life vignettes, or answering emotional questions. In this paper, we use videos of professional-patient interviews, in which symptoms were assessed in a standardised way as they should/may be assessed in practice, and which were recorded in realistic conditions (i.e. varying illumination levels and camera viewpoints) at the patients' homes or at mental health services. We automatically analyse the facial behaviour of 91 out-patients - this is almost 3 times the number of patients in other studies - and propose SchiNet, a novel neural network architecture that estimates expression-related symptoms in two different assessment interviews. We evaluate the proposed SchiNet for patient-independent prediction of symptoms of schizophrenia. Experimental results show that some automatically detected facial expressions are significantly correlated to symptoms of schizophrenia, and that the proposed network for estimating symptom severity delivers promising results.
Relightable Neural Video Portrait
Jul 30, 2021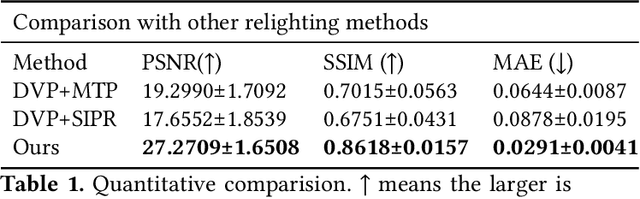
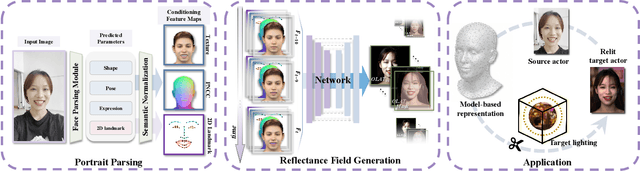

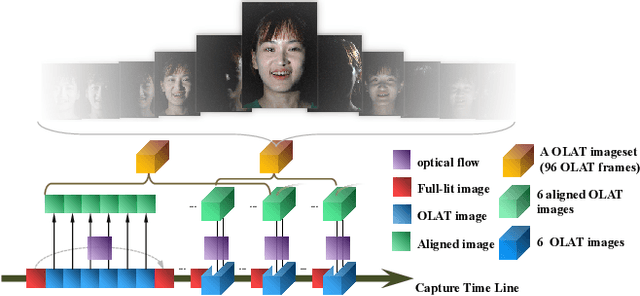
Photo-realistic facial video portrait reenactment benefits virtual production and numerous VR/AR experiences. The task remains challenging as the portrait should maintain high realism and consistency with the target environment. In this paper, we present a relightable neural video portrait, a simultaneous relighting and reenactment scheme that transfers the head pose and facial expressions from a source actor to a portrait video of a target actor with arbitrary new backgrounds and lighting conditions. Our approach combines 4D reflectance field learning, model-based facial performance capture and target-aware neural rendering. Specifically, we adopt a rendering-to-video translation network to first synthesize high-quality OLAT imagesets and alpha mattes from hybrid facial performance capture results. We then design a semantic-aware facial normalization scheme to enable reliable explicit control as well as a multi-frame multi-task learning strategy to encode content, segmentation and temporal information simultaneously for high-quality reflectance field inference. After training, our approach further enables photo-realistic and controllable video portrait editing of the target performer. Reliable face poses and expression editing is obtained by applying the same hybrid facial capture and normalization scheme to the source video input, while our explicit alpha and OLAT output enable high-quality relit and background editing. With the ability to achieve simultaneous relighting and reenactment, we are able to improve the realism in a variety of virtual production and video rewrite applications.
Age and Gender Prediction using Deep CNNs and Transfer Learning
Oct 25, 2021
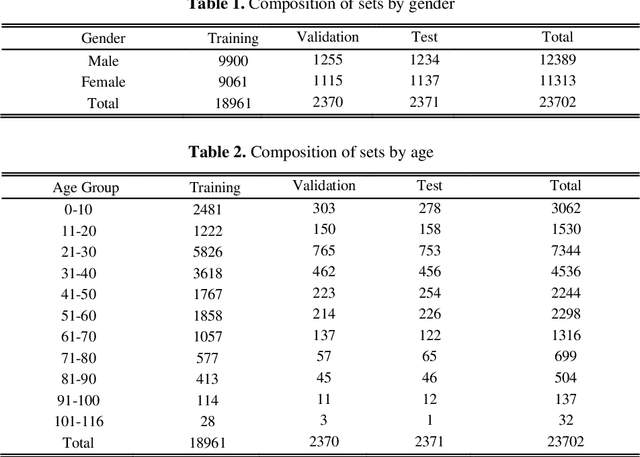
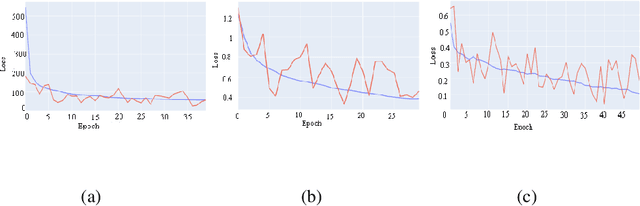

The last decade or two has witnessed a boom of images. With the increasing ubiquity of cameras and with the advent of selfies, the number of facial images available in the world has skyrocketed. Consequently, there has been a growing interest in automatic age and gender prediction of a person using facial images. We in this paper focus on this challenging problem. Specifically, this paper focuses on age estimation, age classification and gender classification from still facial images of an individual. We train different models for each problem and we also draw comparisons between building a custom CNN (Convolutional Neural Network) architecture and using various CNN architectures as feature extractors, namely VGG16 pre-trained on VGGFace, Res-Net50 and SE-ResNet50 pre-trained on VGGFace2 dataset and training over those extracted features. We also provide baseline performance of various machine learning algorithms on the feature extraction which gave us the best results. It was observed that even simple linear regression trained on such extracted features outperformed training CNN, ResNet50 and ResNeXt50 from scratch for age estimation.
* 12 pages, 2 figures, 11 tables
Multi-label Learning Based Deep Transfer Neural Network for Facial Attribute Classification
May 03, 2018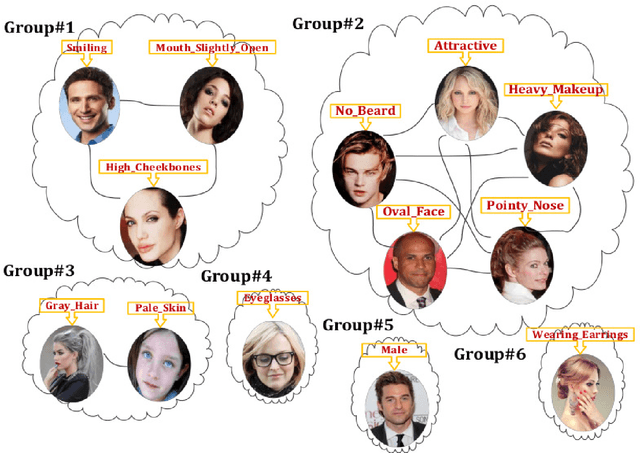
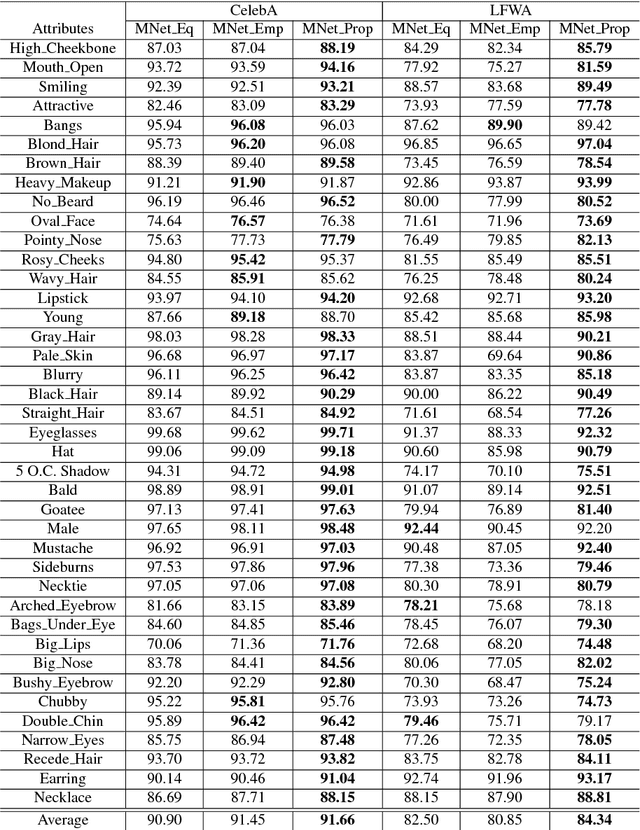
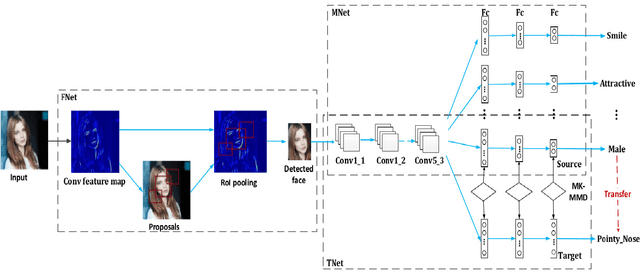
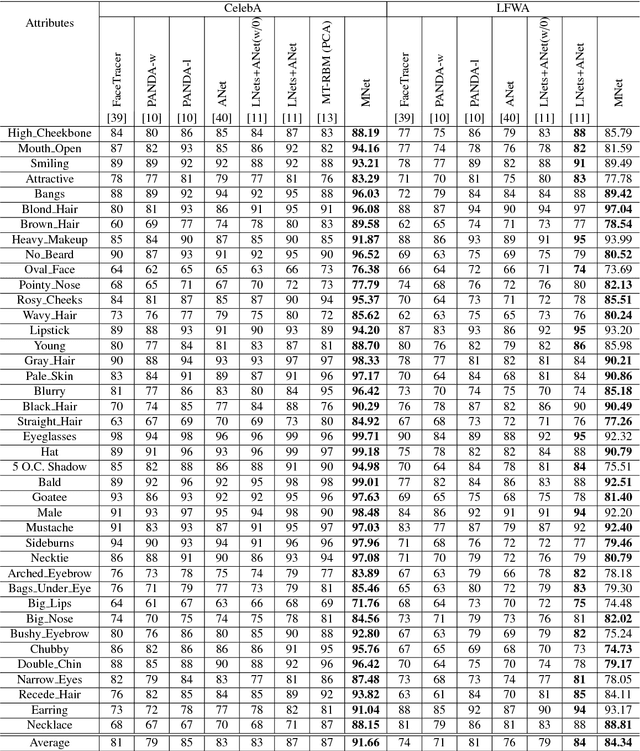
Deep Neural Network (DNN) has recently achieved outstanding performance in a variety of computer vision tasks, including facial attribute classification. The great success of classifying facial attributes with DNN often relies on a massive amount of labelled data. However, in real-world applications, labelled data are only provided for some commonly used attributes (such as age, gender); whereas, unlabelled data are available for other attributes (such as attraction, hairline). To address the above problem, we propose a novel deep transfer neural network method based on multi-label learning for facial attribute classification, termed FMTNet, which consists of three sub-networks: the Face detection Network (FNet), the Multi-label learning Network (MNet) and the Transfer learning Network (TNet). Firstly, based on the Faster Region-based Convolutional Neural Network (Faster R-CNN), FNet is fine-tuned for face detection. Then, MNet is fine-tuned by FNet to predict multiple attributes with labelled data, where an effective loss weight scheme is developed to explicitly exploit the correlation between facial attributes based on attribute grouping. Finally, based on MNet, TNet is trained by taking advantage of unsupervised domain adaptation for unlabelled facial attribute classification. The three sub-networks are tightly coupled to perform effective facial attribute classification. A distinguishing characteristic of the proposed FMTNet method is that the three sub-networks (FNet, MNet and TNet) are constructed in a similar network structure. Extensive experimental results on challenging face datasets demonstrate the effectiveness of our proposed method compared with several state-of-the-art methods.
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022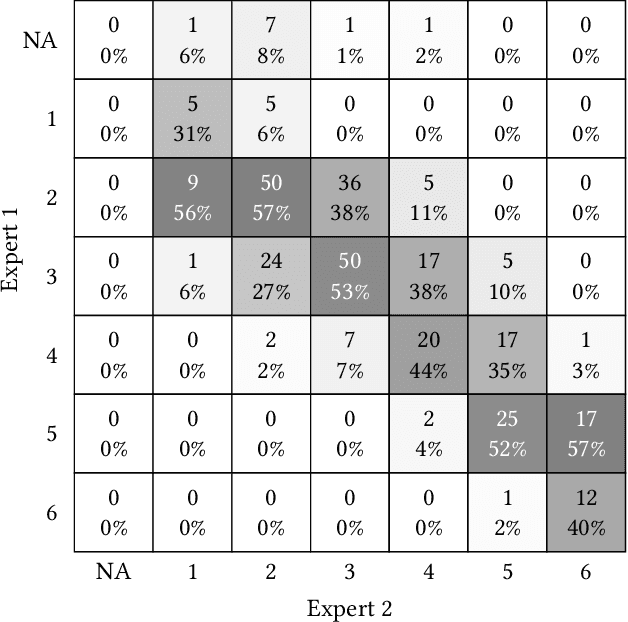
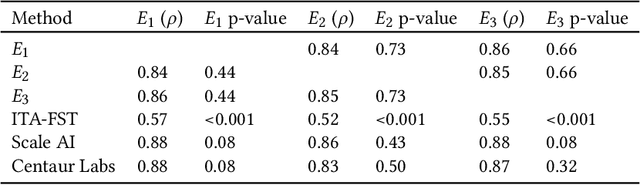
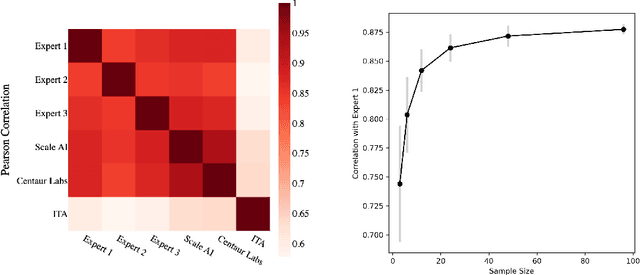
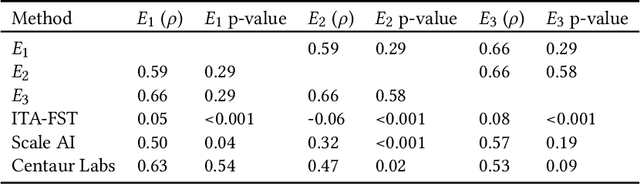
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.
Artificial Emotional Intelligence in Socially Assistive Robots for Older Adults: A Pilot Study
Jan 26, 2022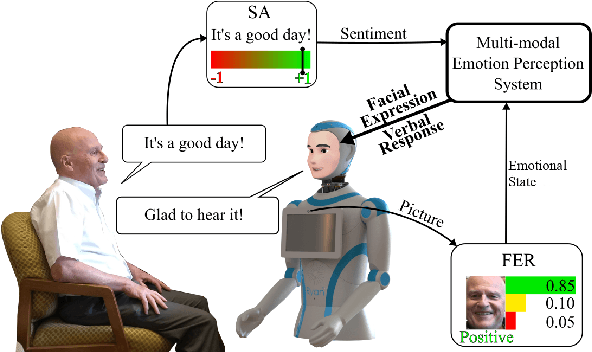
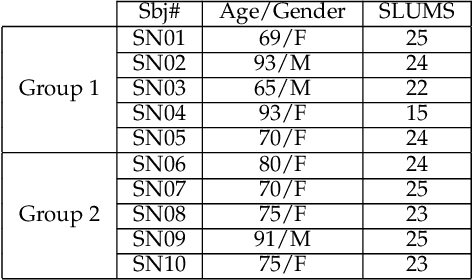

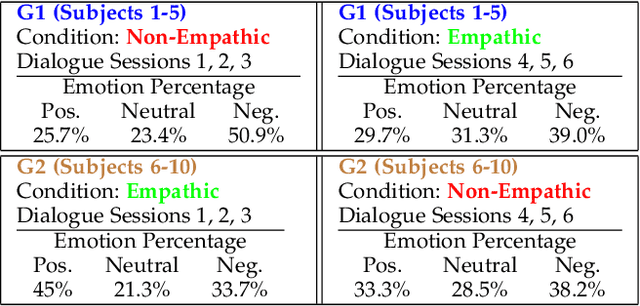
This paper presents our recent research on integrating artificial emotional intelligence in a social robot (Ryan) and studies the robot's effectiveness in engaging older adults. Ryan is a socially assistive robot designed to provide companionship for older adults with depression and dementia through conversation. We used two versions of Ryan for our study, empathic and non-empathic. The empathic Ryan utilizes a multimodal emotion recognition algorithm and a multimodal emotion expression system. Using different input modalities for emotion, i.e. facial expression and speech sentiment, the empathic Ryan detects users' emotional state and utilizes an affective dialogue manager to generate a response. On the other hand, the non-empathic Ryan lacks facial expression and uses scripted dialogues that do not factor in the users' emotional state. We studied these two versions of Ryan with 10 older adults living in a senior care facility. The statistically significant improvement in the users' reported face-scale mood measurement indicates an overall positive effect from the interaction with both the empathic and non-empathic versions of Ryan. However, the number of spoken words measurement and the exit survey analysis suggest that the users perceive the empathic Ryan as more engaging and likable.
MTGLS: Multi-Task Gaze Estimation with Limited Supervision
Oct 23, 2021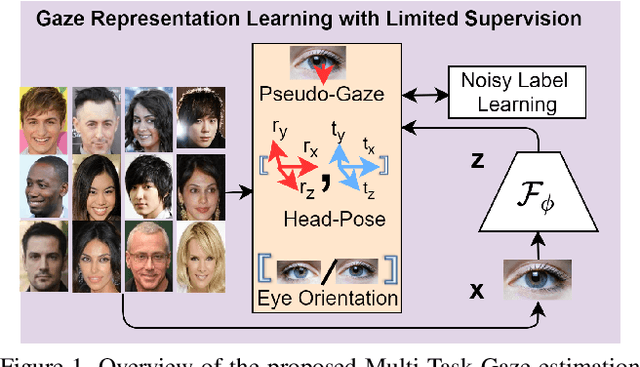
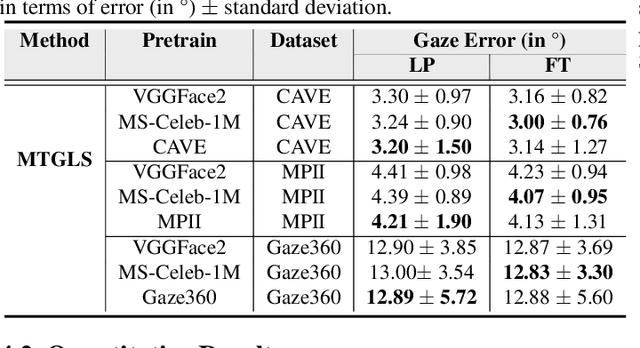
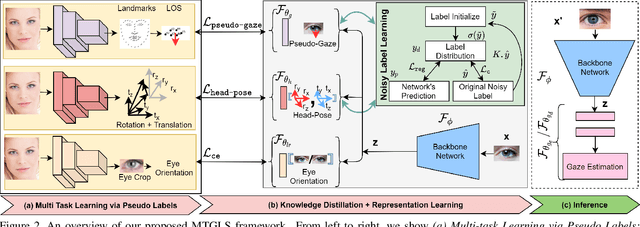
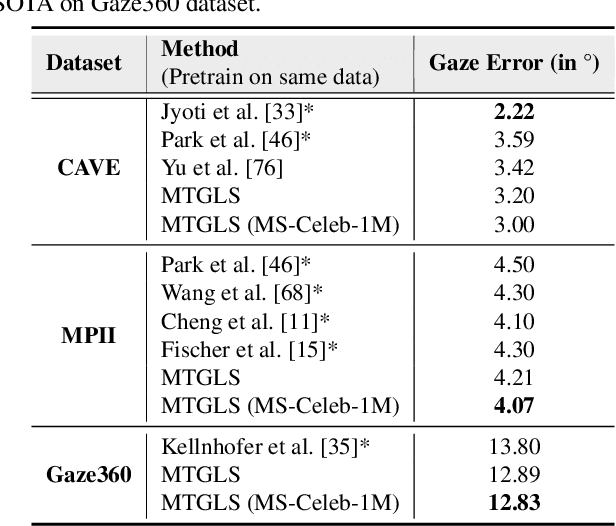
Robust gaze estimation is a challenging task, even for deep CNNs, due to the non-availability of large-scale labeled data. Moreover, gaze annotation is a time-consuming process and requires specialized hardware setups. We propose MTGLS: a Multi-Task Gaze estimation framework with Limited Supervision, which leverages abundantly available non-annotated facial image data. MTGLS distills knowledge from off-the-shelf facial image analysis models, and learns strong feature representations of human eyes, guided by three complementary auxiliary signals: (a) the line of sight of the pupil (i.e. pseudo-gaze) defined by the localized facial landmarks, (b) the head-pose given by Euler angles, and (c) the orientation of the eye patch (left/right eye). To overcome inherent noise in the supervisory signals, MTGLS further incorporates a noise distribution modelling approach. Our experimental results show that MTGLS learns highly generalized representations which consistently perform well on a range of datasets. Our proposed framework outperforms the unsupervised state-of-the-art on CAVE (by 6.43%) and even supervised state-of-the-art methods on Gaze360 (by 6.59%) datasets.