 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Flatter Loss for Bias Mitigation in Cross-dataset Facial Age Estimation
Oct 20, 2020

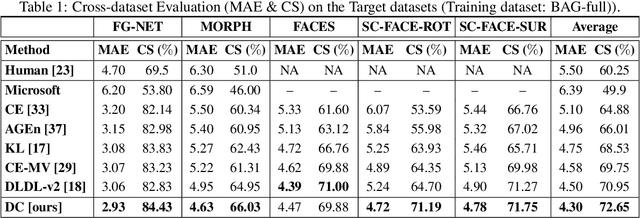
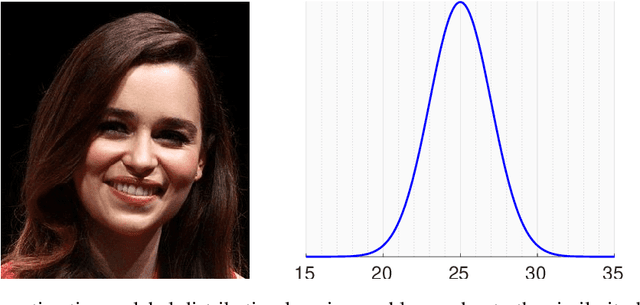
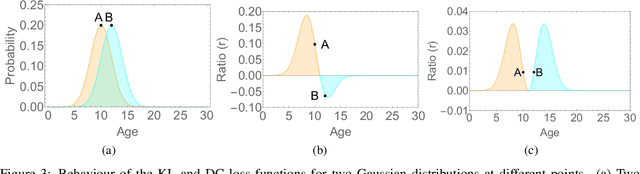
Existing studies in facial age estimation have mostly focused on intra-dataset protocols that assume training and test images captured under similar conditions. However, this is rarely valid in practical applications, where training and test sets usually have different characteristics. In this paper, we advocate a cross-dataset protocol for age estimation benchmarking. In order to improve the cross-dataset age estimation performance, we mitigate the inherent bias caused by the learning algorithm itself. To this end, we propose a novel loss function that is more effective for neural network training. The relative smoothness of the proposed loss function is its advantage with regards to the optimisation process performed by stochastic gradient descent. Its lower gradient, compared with existing loss functions, facilitates the discovery of and convergence to a better optimum, and consequently a better generalisation. The cross-dataset experimental results demonstrate the superiority of the proposed method over the state-of-the-art algorithms in terms of accuracy and generalisation capability.
SchiNet: Automatic Estimation of Symptoms of Schizophrenia from Facial Behaviour Analysis
Aug 07, 2018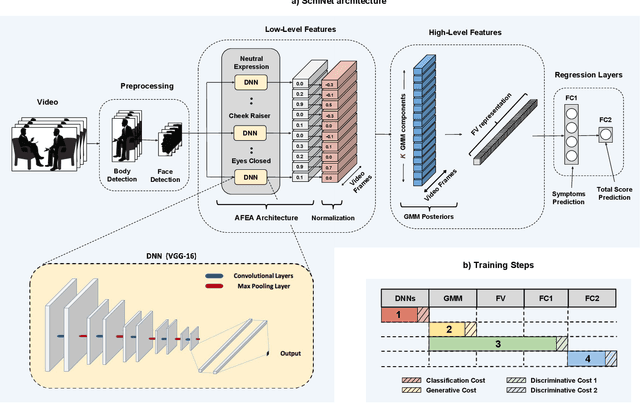
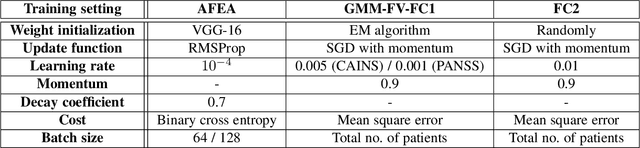
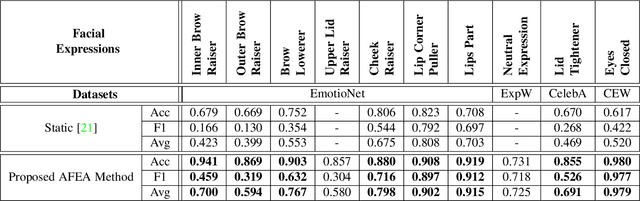
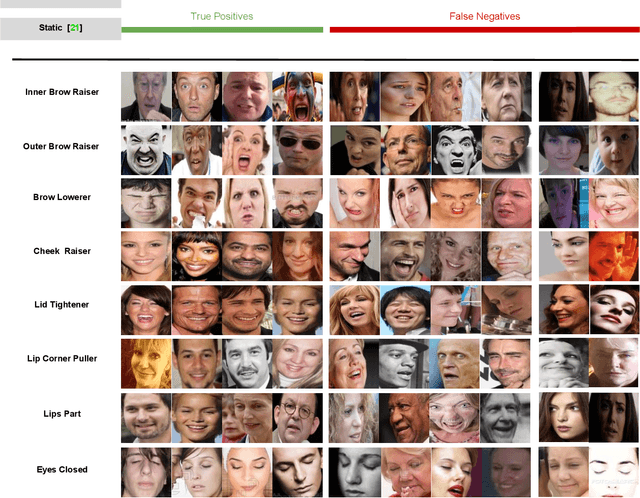
Patients with schizophrenia often display impairments in the expression of emotion and speech and those are observed in their facial behaviour. Automatic analysis of patients' facial expressions that is aimed at estimating symptoms of schizophrenia has received attention recently. However, the datasets that are typically used for training and evaluating the developed methods, contain only a small number of patients (4-34) and are recorded while the subjects were performing controlled tasks such as listening to life vignettes, or answering emotional questions. In this paper, we use videos of professional-patient interviews, in which symptoms were assessed in a standardised way as they should/may be assessed in practice, and which were recorded in realistic conditions (i.e. varying illumination levels and camera viewpoints) at the patients' homes or at mental health services. We automatically analyse the facial behaviour of 91 out-patients - this is almost 3 times the number of patients in other studies - and propose SchiNet, a novel neural network architecture that estimates expression-related symptoms in two different assessment interviews. We evaluate the proposed SchiNet for patient-independent prediction of symptoms of schizophrenia. Experimental results show that some automatically detected facial expressions are significantly correlated to symptoms of schizophrenia, and that the proposed network for estimating symptom severity delivers promising results.
Multi-label Learning Based Deep Transfer Neural Network for Facial Attribute Classification
May 03, 2018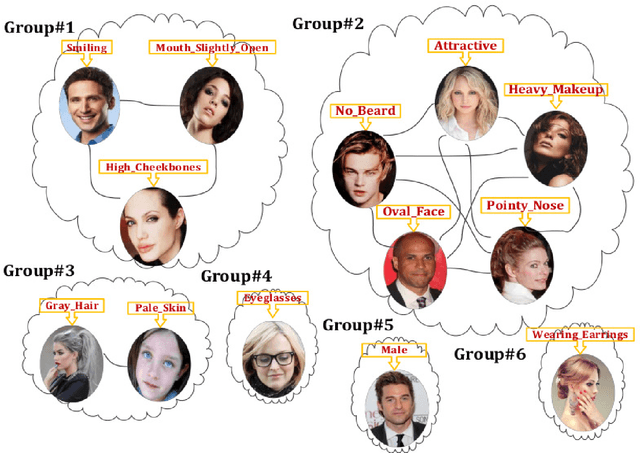
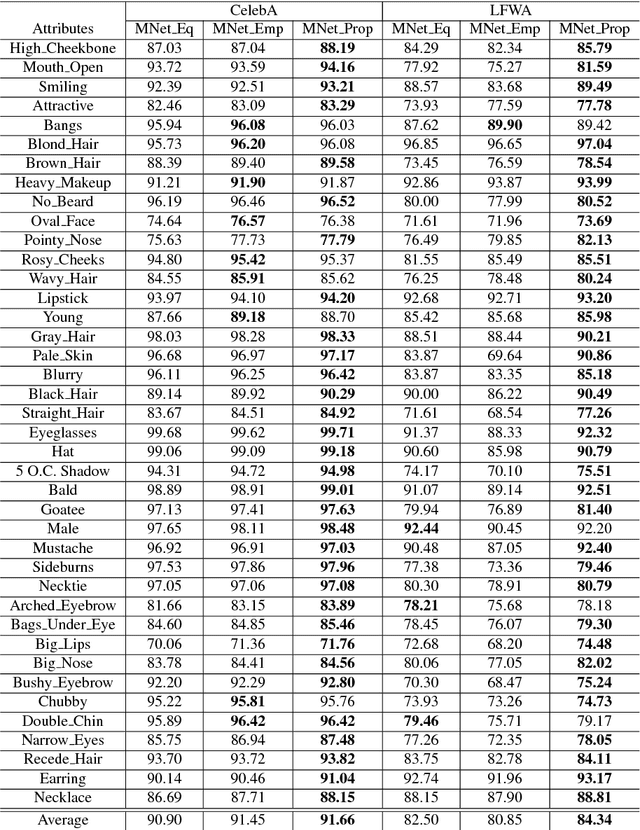
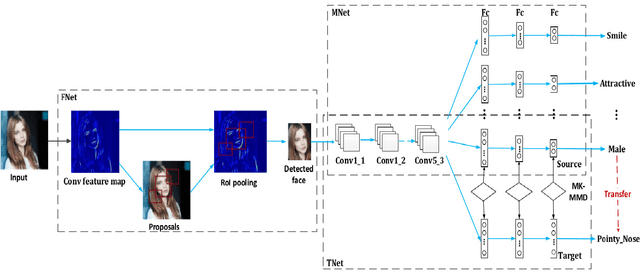
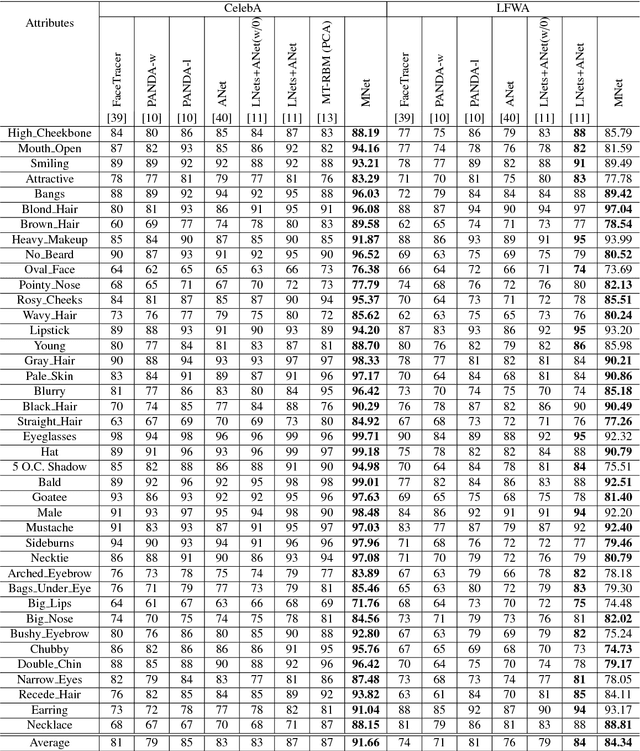
Deep Neural Network (DNN) has recently achieved outstanding performance in a variety of computer vision tasks, including facial attribute classification. The great success of classifying facial attributes with DNN often relies on a massive amount of labelled data. However, in real-world applications, labelled data are only provided for some commonly used attributes (such as age, gender); whereas, unlabelled data are available for other attributes (such as attraction, hairline). To address the above problem, we propose a novel deep transfer neural network method based on multi-label learning for facial attribute classification, termed FMTNet, which consists of three sub-networks: the Face detection Network (FNet), the Multi-label learning Network (MNet) and the Transfer learning Network (TNet). Firstly, based on the Faster Region-based Convolutional Neural Network (Faster R-CNN), FNet is fine-tuned for face detection. Then, MNet is fine-tuned by FNet to predict multiple attributes with labelled data, where an effective loss weight scheme is developed to explicitly exploit the correlation between facial attributes based on attribute grouping. Finally, based on MNet, TNet is trained by taking advantage of unsupervised domain adaptation for unlabelled facial attribute classification. The three sub-networks are tightly coupled to perform effective facial attribute classification. A distinguishing characteristic of the proposed FMTNet method is that the three sub-networks (FNet, MNet and TNet) are constructed in a similar network structure. Extensive experimental results on challenging face datasets demonstrate the effectiveness of our proposed method compared with several state-of-the-art methods.
Artificial Emotional Intelligence in Socially Assistive Robots for Older Adults: A Pilot Study
Jan 26, 2022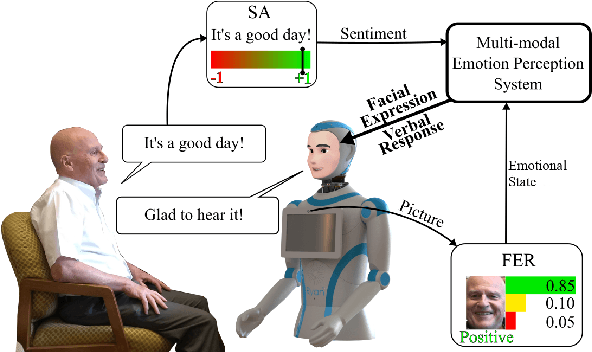
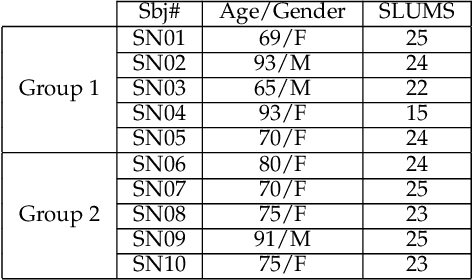

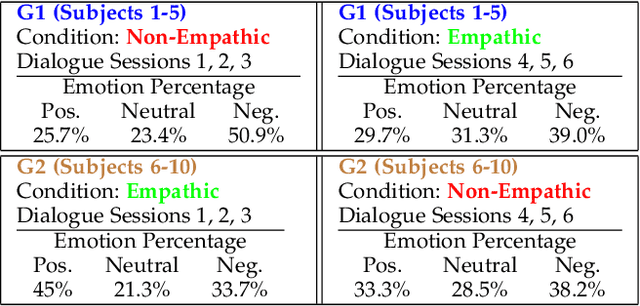
This paper presents our recent research on integrating artificial emotional intelligence in a social robot (Ryan) and studies the robot's effectiveness in engaging older adults. Ryan is a socially assistive robot designed to provide companionship for older adults with depression and dementia through conversation. We used two versions of Ryan for our study, empathic and non-empathic. The empathic Ryan utilizes a multimodal emotion recognition algorithm and a multimodal emotion expression system. Using different input modalities for emotion, i.e. facial expression and speech sentiment, the empathic Ryan detects users' emotional state and utilizes an affective dialogue manager to generate a response. On the other hand, the non-empathic Ryan lacks facial expression and uses scripted dialogues that do not factor in the users' emotional state. We studied these two versions of Ryan with 10 older adults living in a senior care facility. The statistically significant improvement in the users' reported face-scale mood measurement indicates an overall positive effect from the interaction with both the empathic and non-empathic versions of Ryan. However, the number of spoken words measurement and the exit survey analysis suggest that the users perceive the empathic Ryan as more engaging and likable.
MTGLS: Multi-Task Gaze Estimation with Limited Supervision
Oct 23, 2021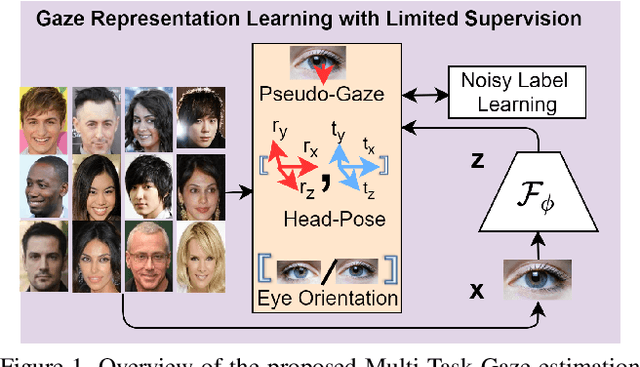
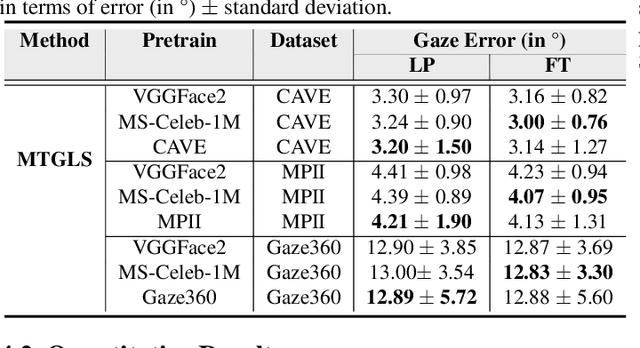
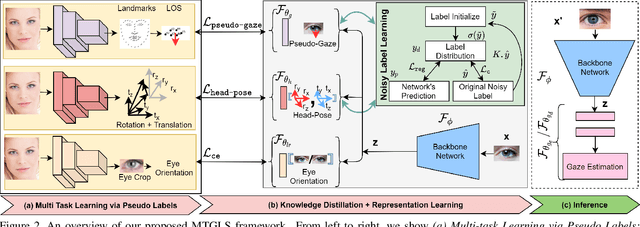
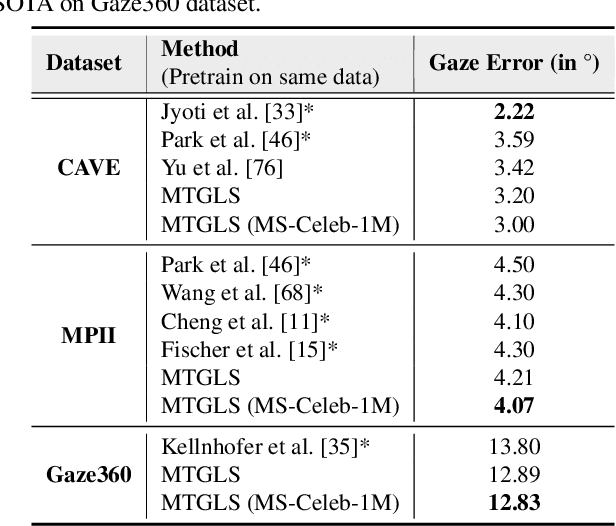
Robust gaze estimation is a challenging task, even for deep CNNs, due to the non-availability of large-scale labeled data. Moreover, gaze annotation is a time-consuming process and requires specialized hardware setups. We propose MTGLS: a Multi-Task Gaze estimation framework with Limited Supervision, which leverages abundantly available non-annotated facial image data. MTGLS distills knowledge from off-the-shelf facial image analysis models, and learns strong feature representations of human eyes, guided by three complementary auxiliary signals: (a) the line of sight of the pupil (i.e. pseudo-gaze) defined by the localized facial landmarks, (b) the head-pose given by Euler angles, and (c) the orientation of the eye patch (left/right eye). To overcome inherent noise in the supervisory signals, MTGLS further incorporates a noise distribution modelling approach. Our experimental results show that MTGLS learns highly generalized representations which consistently perform well on a range of datasets. Our proposed framework outperforms the unsupervised state-of-the-art on CAVE (by 6.43%) and even supervised state-of-the-art methods on Gaze360 (by 6.59%) datasets.
Heterogeneous Face Recognition via Face Synthesis with Identity-Attribute Disentanglement
Jun 10, 2022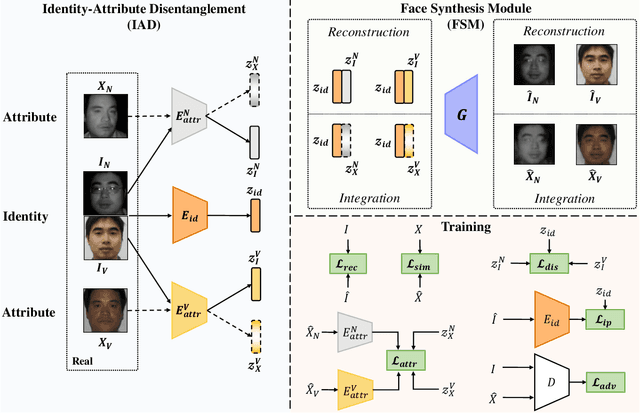


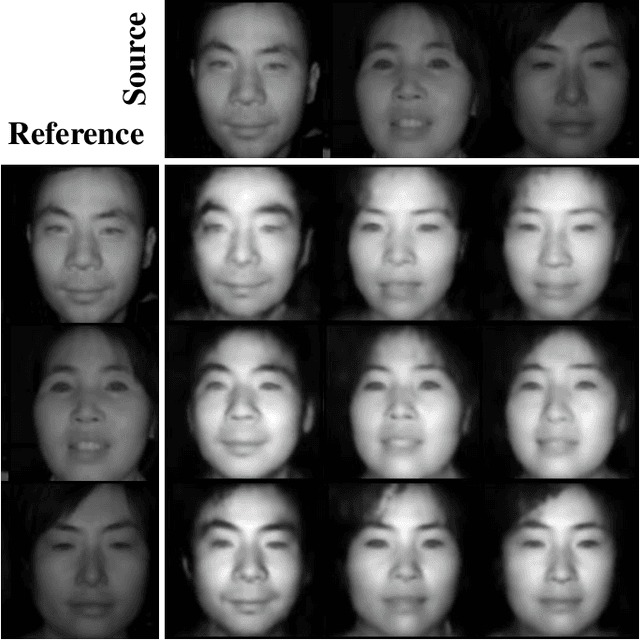
Heterogeneous Face Recognition (HFR) aims to match faces across different domains (e.g., visible to near-infrared images), which has been widely applied in authentication and forensics scenarios. However, HFR is a challenging problem because of the large cross-domain discrepancy, limited heterogeneous data pairs, and large variation of facial attributes. To address these challenges, we propose a new HFR method from the perspective of heterogeneous data augmentation, named Face Synthesis with Identity-Attribute Disentanglement (FSIAD). Firstly, the identity-attribute disentanglement (IAD) decouples face images into identity-related representations and identity-unrelated representations (called attributes), and then decreases the correlation between identities and attributes. Secondly, we devise a face synthesis module (FSM) to generate a large number of images with stochastic combinations of disentangled identities and attributes for enriching the attribute diversity of synthetic images. Both the original images and the synthetic ones are utilized to train the HFR network for tackling the challenges and improving the performance of HFR. Extensive experiments on five HFR databases validate that FSIAD obtains superior performance than previous HFR approaches. Particularly, FSIAD obtains 4.8% improvement over state of the art in terms of VR@FAR=0.01% on LAMP-HQ, the largest HFR database so far.
* Accepted for publication in IEEE Transactions on Information Forensics and Security (TIFS)
Facial Feature Point Detection: A Comprehensive Survey
Oct 04, 2014
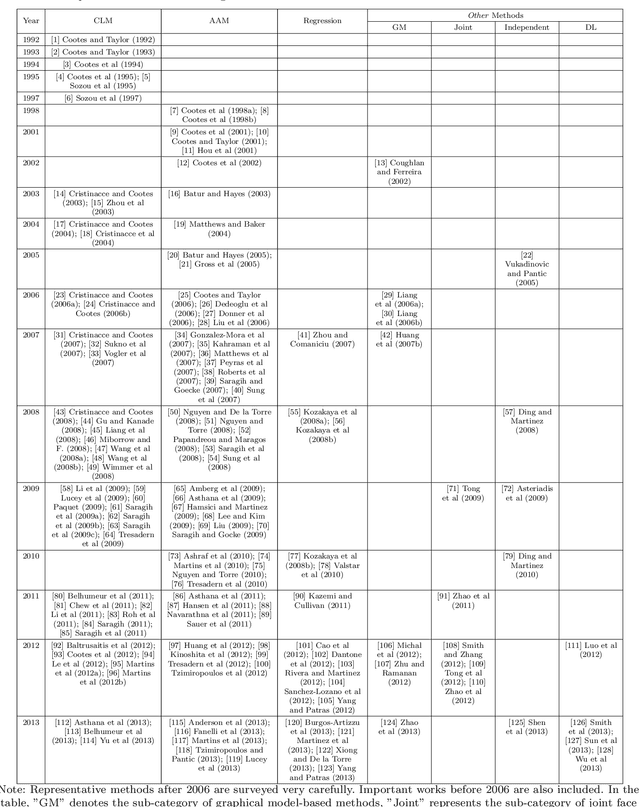
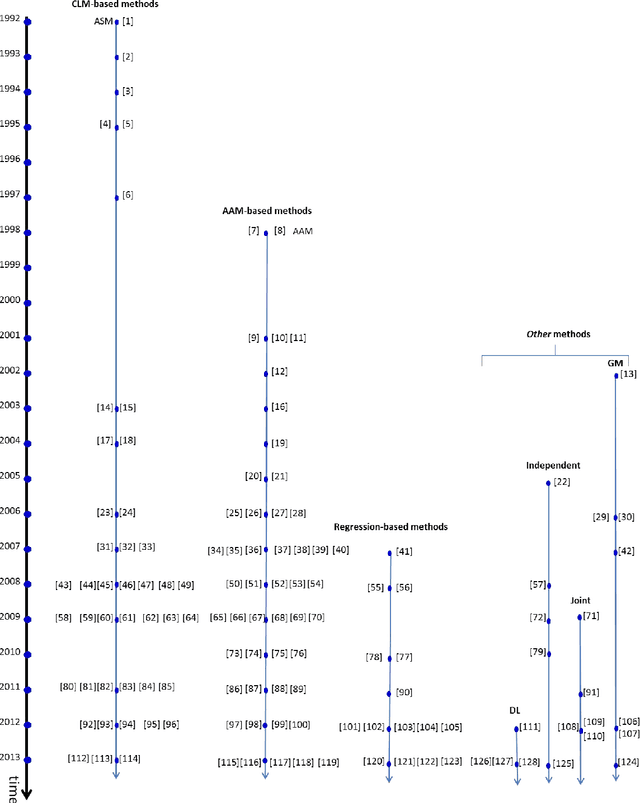
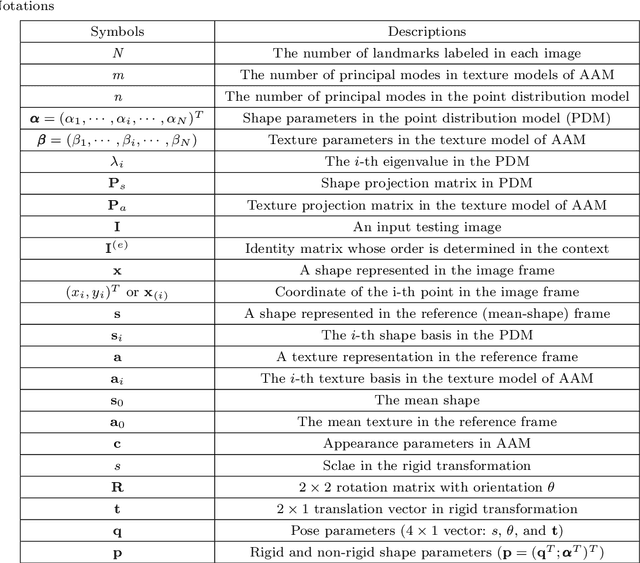
This paper presents a comprehensive survey of facial feature point detection with the assistance of abundant manually labeled images. Facial feature point detection favors many applications such as face recognition, animation, tracking, hallucination, expression analysis and 3D face modeling. Existing methods can be categorized into the following four groups: constrained local model (CLM)-based, active appearance model (AAM)-based, regression-based, and other methods. CLM-based methods consist of a shape model and a number of local experts, each of which is utilized to detect a facial feature point. AAM-based methods fit a shape model to an image by minimizing texture synthesis errors. Regression-based methods directly learn a mapping function from facial image appearance to facial feature points. Besides the above three major categories of methods, there are also minor categories of methods which we classify into other methods: graphical model-based methods, joint face alignment methods, independent facial feature point detectors, and deep learning-based methods. Though significant progress has been made, facial feature point detection is limited in its success by wild and real-world conditions: variations across poses, expressions, illuminations, and occlusions. A comparative illustration and analysis of representative methods provide us a holistic understanding and deep insight into facial feature point detection, which also motivates us to explore promising future directions.
FD-GAN: Face-demorphing generative adversarial network for restoring accomplice's facial image
Nov 19, 2018
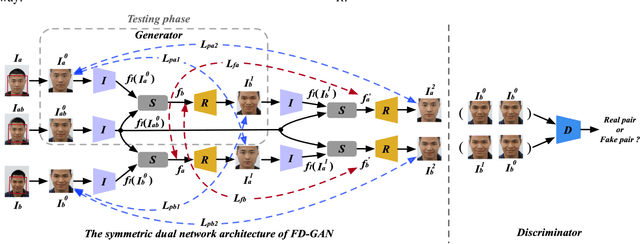
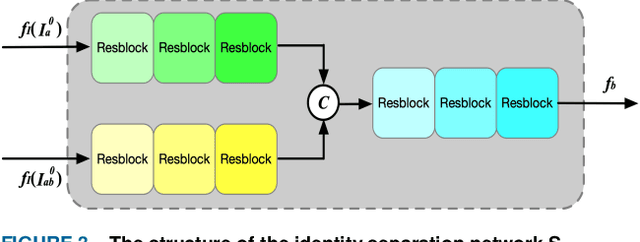

Face morphing attack is proved to be a serious threat to the existing face recognition systems. Although a few face morphing detection methods have been put forward, the face morphing accomplice's facial restoration remains a challenging problem. In this paper, a face-demorphing generative adversarial network (FD-GAN) is proposed to restore the accomplice's facial image. It utilizes a symmetric dual network architecture and two levels of restoration losses to separate the identity feature of the morphing accomplice. By exploiting the captured face image (containing the criminal's identity) from the face recognition system and the morphed image stored in the e-passport system (containing both criminal and accomplice's identities), the FD-GAN can effectively restore the accomplice's facial image. Experimental results and analysis demonstrate the effectiveness of the proposed scheme. It has great potential to be implemented for detecting the face morphing accomplice in a real identity verification scenario.
SenTion: A framework for Sensing Facial Expressions
Aug 16, 2016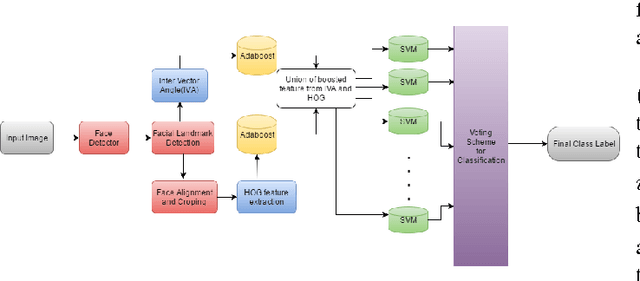
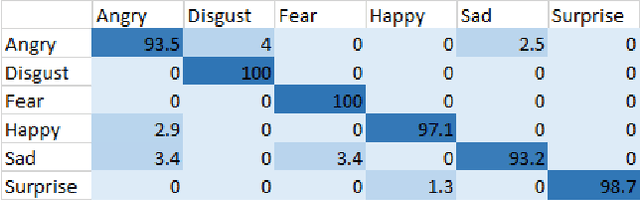
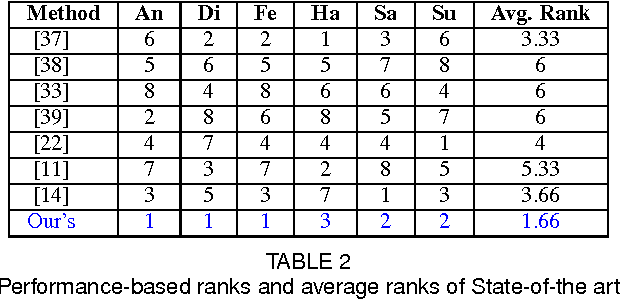
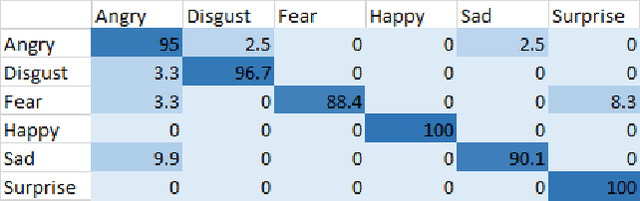
Facial expressions are an integral part of human cognition and communication, and can be applied in various real life applications. A vital precursor to accurate expression recognition is feature extraction. In this paper, we propose SenTion: A framework for sensing facial expressions. We propose a novel person independent and scale invariant method of extracting Inter Vector Angles (IVA) as geometric features, which proves to be robust and reliable across databases. SenTion employs a novel framework of combining geometric (IVA's) and appearance based features (Histogram of Gradients) to create a hybrid model, that achieves state of the art recognition accuracy. We evaluate the performance of SenTion on two famous face expression data set, namely: CK+ and JAFFE; and subsequently evaluate the viability of facial expression systems by a user study. Extensive experiments showed that SenTion framework yielded dramatic improvements in facial expression recognition and could be employed in real-world applications with low resolution imaging and minimal computational resources in real-time, achieving 15-18 fps on a 2.4 GHz CPU with no GPU.
Mechanical Chameleons: Evaluating the effects of a social robot's non-verbal behavior on social influence
Sep 02, 2021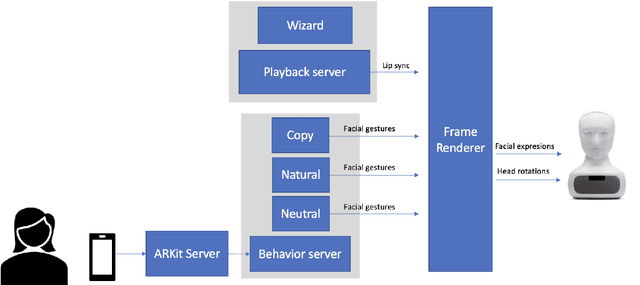

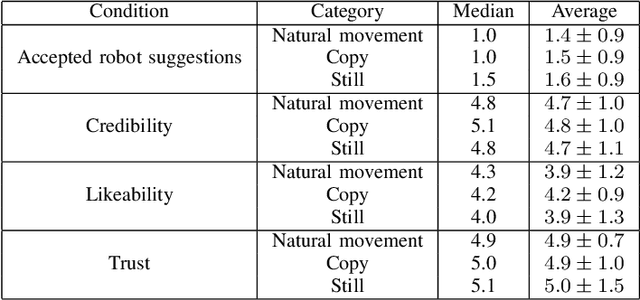
In this paper we present a pilot study which investigates how non-verbal behavior affects social influence in social robots. We also present a modular system which is capable of controlling the non-verbal behavior based on the interlocutor's facial gestures (head movements and facial expressions) in real time, and a study investigating whether three different strategies for facial gestures ("still", "natural movement", i.e. movements recorded from another conversation, and "copy", i.e. mimicking the user with a four second delay) has any affect on social influence and decision making in a "survival task". Our preliminary results show there was no significant difference between the three conditions, but this might be due to among other things a low number of study participants (12).