 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Enhancing Facial Classification and Recognition using 3D Facial Models and Deep Learning
Dec 08, 2023
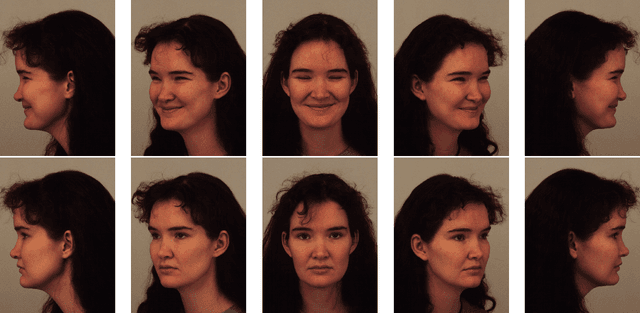



Accurate analysis and classification of facial attributes are essential in various applications, from human-computer interaction to security systems. In this work, a novel approach to enhance facial classification and recognition tasks through the integration of 3D facial models with deep learning methods was proposed. We extract the most useful information for various tasks using the 3D Facial Model, leading to improved classification accuracy. Combining 3D facial insights with ResNet architecture, our approach achieves notable results: 100% individual classification, 95.4% gender classification, and 83.5% expression classification accuracy. This method holds promise for advancing facial analysis and recognition research.
PhySU-Net: Long Temporal Context Transformer for rPPG with Self-Supervised Pre-training
Feb 19, 2024Remote photoplethysmography (rPPG) is a promising technology that consists of contactless measuring of cardiac activity from facial videos. Most recent approaches utilize convolutional networks with limited temporal modeling capability or ignore long temporal context. Supervised rPPG methods are also severely limited by scarce data availability. In this work, we propose PhySU-Net, the first long spatial-temporal map rPPG transformer network and a self-supervised pre-training strategy that exploits unlabeled data to improve our model. Our strategy leverages traditional methods and image masking to provide pseudo-labels for self-supervised pre-training. Our model is tested on two public datasets (OBF and VIPL-HR) and shows superior performance in supervised training. Furthermore, we demonstrate that our self-supervised pre-training strategy further improves our model's performance by leveraging representations learned from unlabeled data.
Efficient Expression Neutrality Estimation with Application to Face Recognition Utility Prediction
Feb 08, 2024The recognition performance of biometric systems strongly depends on the quality of the compared biometric samples. Motivated by the goal of establishing a common understanding of face image quality and enabling system interoperability, the committee draft of ISO/IEC 29794-5 introduces expression neutrality as one of many component quality elements affecting recognition performance. In this study, we train classifiers to assess facial expression neutrality using seven datasets. We conduct extensive performance benchmarking to evaluate their classification and face recognition utility prediction abilities. Our experiments reveal significant differences in how each classifier distinguishes "neutral" from "non-neutral" expressions. While Random Forests and AdaBoost classifiers are most suitable for distinguishing neutral from non-neutral facial expressions with high accuracy, they underperform compared to Support Vector Machines in predicting face recognition utility.
Maia: A Real-time Non-Verbal Chat for Human-AI Interaction
Feb 09, 2024Face-to-face communication modeling in computer vision is an area of research focusing on developing algorithms that can recognize and analyze non-verbal cues and behaviors during face-to-face interactions. We propose an alternative to text chats for Human-AI interaction, based on non-verbal visual communication only, using facial expressions and head movements that mirror, but also improvise over the human user, to efficiently engage with the users, and capture their attention in a low-cost and real-time fashion. Our goal is to track and analyze facial expressions, and other non-verbal cues in real-time, and use this information to build models that can predict and understand human behavior. We offer three different complementary approaches, based on retrieval, statistical, and deep learning techniques. We provide human as well as automatic evaluations and discuss the advantages and disadvantages of each direction.
StyleDubber: Towards Multi-Scale Style Learning for Movie Dubbing
Feb 21, 2024Given a script, the challenge in Movie Dubbing (Visual Voice Cloning, V2C) is to generate speech that aligns well with the video in both time and emotion, based on the tone of a reference audio track. Existing state-of-the-art V2C models break the phonemes in the script according to the divisions between video frames, which solves the temporal alignment problem but leads to incomplete phoneme pronunciation and poor identity stability. To address this problem, we propose StyleDubber, which switches dubbing learning from the frame level to phoneme level. It contains three main components: (1) A multimodal style adaptor operating at the phoneme level to learn pronunciation style from the reference audio, and generate intermediate representations informed by the facial emotion presented in the video; (2) An utterance-level style learning module, which guides both the mel-spectrogram decoding and the refining processes from the intermediate embeddings to improve the overall style expression; And (3) a phoneme-guided lip aligner to maintain lip sync. Extensive experiments on two of the primary benchmarks, V2C and Grid, demonstrate the favorable performance of the proposed method as compared to the current state-of-the-art. The source code and trained models will be released to the public.
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot
Feb 22, 2024We present Multi-HMR, a strong single-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e, including hands and facial expressions, using the SMPL-X parametric model and spatial location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person centers, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and spatial location using a new cross-attention module called the Human Prediction Head (HPH), with one query per detected center token, attending to the entire set of features. As direct prediction of SMPL-X parameters yields suboptimal results, we introduce CUFFS; the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating this dataset into training further enhances predictions, particularly for hands, enabling us to achieve state-of-the-art performance. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously. We train models with various backbone sizes and input resolutions. In particular, using a ViT-S backbone and $448\times448$ input images already yields a fast and competitive model with respect to state-of-the-art methods, while considering larger models and higher resolutions further improve performance.
RhythmFormer: Extracting rPPG Signals Based on Hierarchical Temporal Periodic Transformer
Feb 20, 2024Remote photoplethysmography (rPPG) is a non-contact method for detecting physiological signals based on facial videos, holding high potential in various applications such as healthcare, affective computing, anti-spoofing, etc. Due to the periodicity nature of rPPG, the long-range dependency capturing capacity of the Transformer was assumed to be advantageous for such signals. However, existing approaches have not conclusively demonstrated the superior performance of Transformer over traditional convolutional neural network methods, this gap may stem from a lack of thorough exploration of rPPG periodicity. In this paper, we propose RhythmFormer, a fully end-to-end transformer-based method for extracting rPPG signals by explicitly leveraging the quasi-periodic nature of rPPG. The core module, Hierarchical Temporal Periodic Transformer, hierarchically extracts periodic features from multiple temporal scales. It utilizes dynamic sparse attention based on periodicity in the temporal domain, allowing for fine-grained modeling of rPPG features. Furthermore, a fusion stem is proposed to guide self-attention to rPPG features effectively, and it can be easily transferred to existing methods to enhance their performance significantly. RhythmFormer achieves state-of-the-art performance with fewer parameters and reduced computational complexity in comprehensive experiments compared to previous approaches. The codes are available at https://github.com/zizheng-guo/RhythmFormer.
Optimal-Landmark-Guided Image Blending for Face Morphing Attacks
Jan 30, 2024In this paper, we propose a novel approach for conducting face morphing attacks, which utilizes optimal-landmark-guided image blending. Current face morphing attacks can be categorized into landmark-based and generation-based approaches. Landmark-based methods use geometric transformations to warp facial regions according to averaged landmarks but often produce morphed images with poor visual quality. Generation-based methods, which employ generation models to blend multiple face images, can achieve better visual quality but are often unsuccessful in generating morphed images that can effectively evade state-of-the-art face recognition systems~(FRSs). Our proposed method overcomes the limitations of previous approaches by optimizing the morphing landmarks and using Graph Convolutional Networks (GCNs) to combine landmark and appearance features. We model facial landmarks as nodes in a bipartite graph that is fully connected and utilize GCNs to simulate their spatial and structural relationships. The aim is to capture variations in facial shape and enable accurate manipulation of facial appearance features during the warping process, resulting in morphed facial images that are highly realistic and visually faithful. Experiments on two public datasets prove that our method inherits the advantages of previous landmark-based and generation-based methods and generates morphed images with higher quality, posing a more significant threat to state-of-the-art FRSs.
MIMIC: Mask Image Pre-training with Mix Contrastive Fine-tuning for Facial Expression Recognition
Jan 14, 2024Cutting-edge research in facial expression recognition (FER) currently favors the utilization of convolutional neural networks (CNNs) backbone which is supervisedly pre-trained on face recognition datasets for feature extraction. However, due to the vast scale of face recognition datasets and the high cost associated with collecting facial labels, this pre-training paradigm incurs significant expenses. Towards this end, we propose to pre-train vision Transformers (ViTs) through a self-supervised approach on a mid-scale general image dataset. In addition, when compared with the domain disparity existing between face datasets and FER datasets, the divergence between general datasets and FER datasets is more pronounced. Therefore, we propose a contrastive fine-tuning approach to effectively mitigate this domain disparity. Specifically, we introduce a novel FER training paradigm named Mask Image pre-training with MIx Contrastive fine-tuning (MIMIC). In the initial phase, we pre-train the ViT via masked image reconstruction on general images. Subsequently, in the fine-tuning stage, we introduce a mix-supervised contrastive learning process, which enhances the model with a more extensive range of positive samples by the mixing strategy. Through extensive experiments conducted on three benchmark datasets, we demonstrate that our MIMIC outperforms the previous training paradigm, showing its capability to learn better representations. Remarkably, the results indicate that the vanilla ViT can achieve impressive performance without the need for intricate, auxiliary-designed modules. Moreover, when scaling up the model size, MIMIC exhibits no performance saturation and is superior to the current state-of-the-art methods.
CamPro: Camera-based Anti-Facial Recognition
Dec 30, 2023The proliferation of images captured from millions of cameras and the advancement of facial recognition (FR) technology have made the abuse of FR a severe privacy threat. Existing works typically rely on obfuscation, synthesis, or adversarial examples to modify faces in images to achieve anti-facial recognition (AFR). However, the unmodified images captured by camera modules that contain sensitive personally identifiable information (PII) could still be leaked. In this paper, we propose a novel approach, CamPro, to capture inborn AFR images. CamPro enables well-packed commodity camera modules to produce images that contain little PII and yet still contain enough information to support other non-sensitive vision applications, such as person detection. Specifically, CamPro tunes the configuration setup inside the camera image signal processor (ISP), i.e., color correction matrix and gamma correction, to achieve AFR, and designs an image enhancer to keep the image quality for possible human viewers. We implemented and validated CamPro on a proof-of-concept camera, and our experiments demonstrate its effectiveness on ten state-of-the-art black-box FR models. The results show that CamPro images can significantly reduce face identification accuracy to 0.3\% while having little impact on the targeted non-sensitive vision application. Furthermore, we find that CamPro is resilient to adaptive attackers who have re-trained their FR models using images generated by CamPro, even with full knowledge of privacy-preserving ISP parameters.