 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Are Commercial Face Detection Models as Biased as Academic Models?
Jan 25, 2022
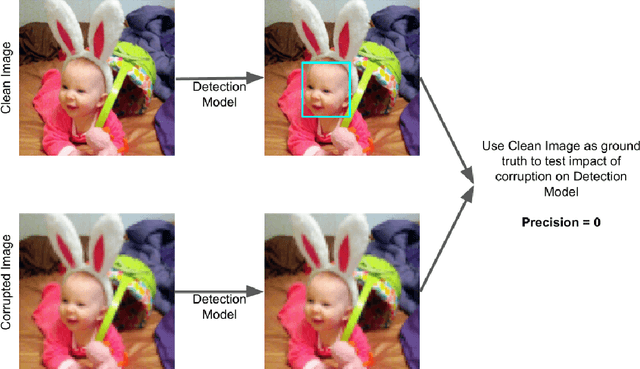
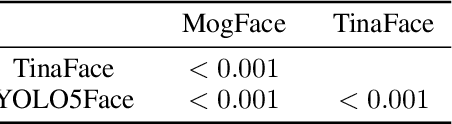
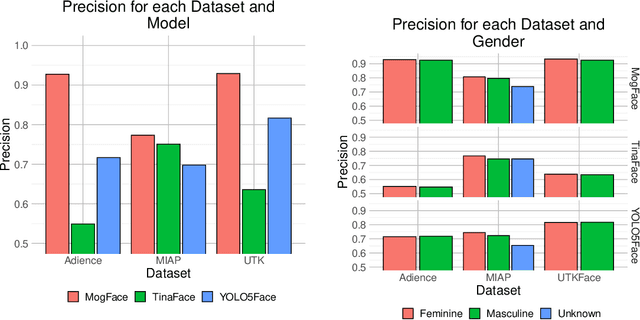
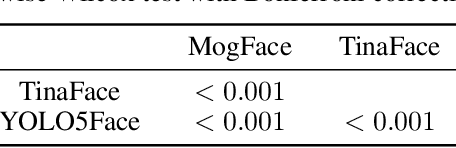
As facial recognition systems are deployed more widely, scholars and activists have studied their biases and harms. Audits are commonly used to accomplish this and compare the algorithmic facial recognition systems' performance against datasets with various metadata labels about the subjects of the images. Seminal works have found discrepancies in performance by gender expression, age, perceived race, skin type, etc. These studies and audits often examine algorithms which fall into two categories: academic models or commercial models. We present a detailed comparison between academic and commercial face detection systems, specifically examining robustness to noise. We find that state-of-the-art academic face detection models exhibit demographic disparities in their noise robustness, specifically by having statistically significant decreased performance on older individuals and those who present their gender in a masculine manner. When we compare the size of these disparities to that of commercial models, we conclude that commercial models - in contrast to their relatively larger development budget and industry-level fairness commitments - are always as biased or more biased than an academic model.
Depth-Aware Generative Adversarial Network for Talking Head Video Generation
Mar 13, 2022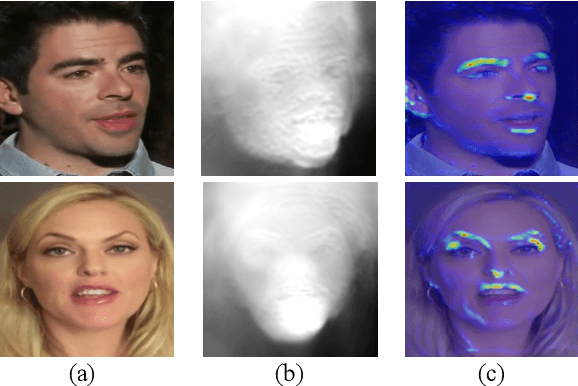
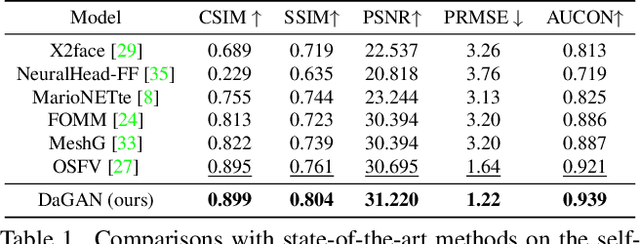
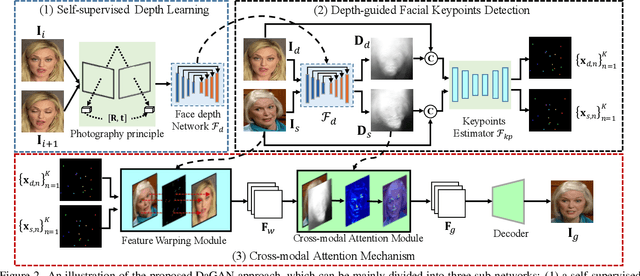
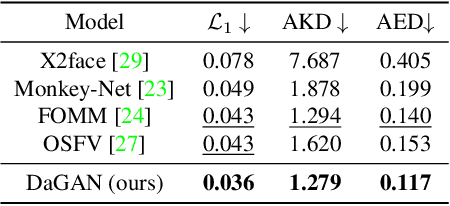
Talking head video generation aims to produce a synthetic human face video that contains the identity and pose information respectively from a given source image and a driving video.Existing works for this task heavily rely on 2D representations (e.g. appearance and motion) learned from the input images. However, dense 3D facial geometry (e.g. pixel-wise depth) is extremely important for this task as it is particularly beneficial for us to essentially generate accurate 3D face structures and distinguish noisy information from the possibly cluttered background. Nevertheless, dense 3D geometry annotations are prohibitively costly for videos and are typically not available for this video generation task. In this paper, we first introduce a self-supervised geometry learning method to automatically recover the dense 3D geometry (i.e.depth) from the face videos without the requirement of any expensive 3D annotation data. Based on the learned dense depth maps, we further propose to leverage them to estimate sparse facial keypoints that capture the critical movement of the human head. In a more dense way, the depth is also utilized to learn 3D-aware cross-modal (i.e. appearance and depth) attention to guide the generation of motion fields for warping source image representations. All these contributions compose a novel depth-aware generative adversarial network (DaGAN) for talking head generation. Extensive experiments conducted demonstrate that our proposed method can generate highly realistic faces, and achieve significant results on the unseen human faces.
Audio- and Gaze-driven Facial Animation of Codec Avatars
Aug 11, 2020
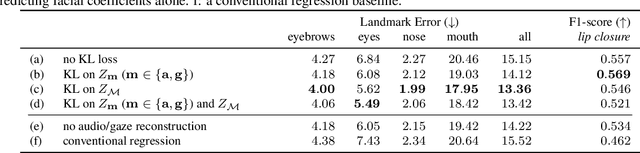
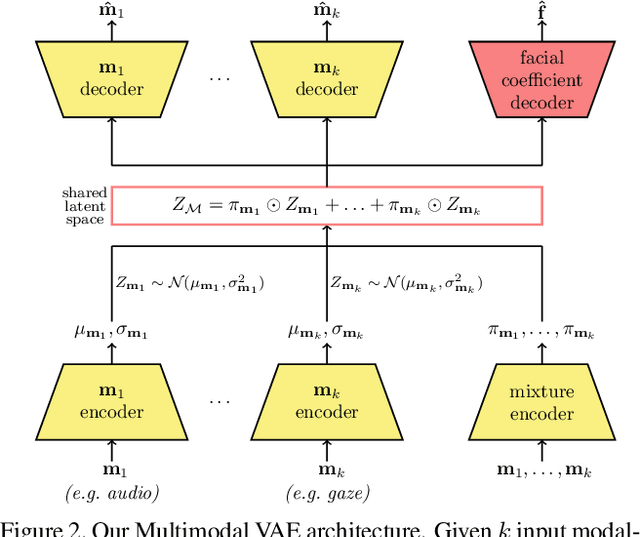
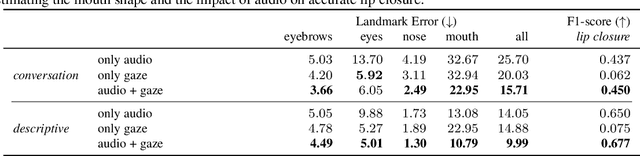
Codec Avatars are a recent class of learned, photorealistic face models that accurately represent the geometry and texture of a person in 3D (i.e., for virtual reality), and are almost indistinguishable from video. In this paper we describe the first approach to animate these parametric models in real-time which could be deployed on commodity virtual reality hardware using audio and/or eye tracking. Our goal is to display expressive conversations between individuals that exhibit important social signals such as laughter and excitement solely from latent cues in our lossy input signals. To this end we collected over 5 hours of high frame rate 3D face scans across three participants including traditional neutral speech as well as expressive and conversational speech. We investigate a multimodal fusion approach that dynamically identifies which sensor encoding should animate which parts of the face at any time. See the supplemental video which demonstrates our ability to generate full face motion far beyond the typically neutral lip articulations seen in competing work: https://research.fb.com/videos/audio-and-gaze-driven-facial-animation-of-codec-avatars/
Improving Facial Attribute Prediction using Semantic Segmentation
Apr 27, 2017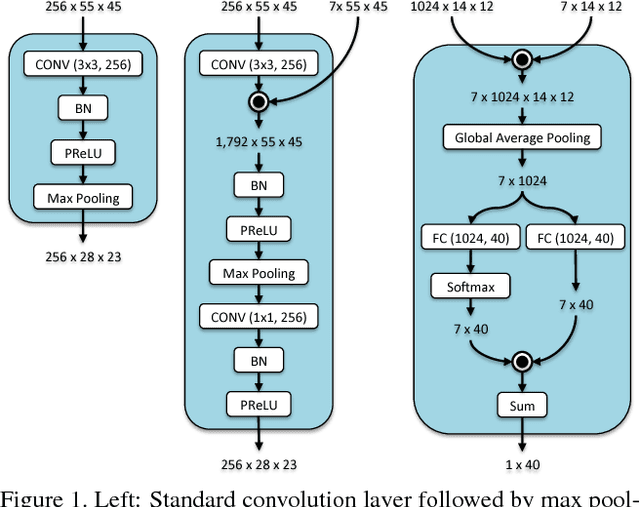
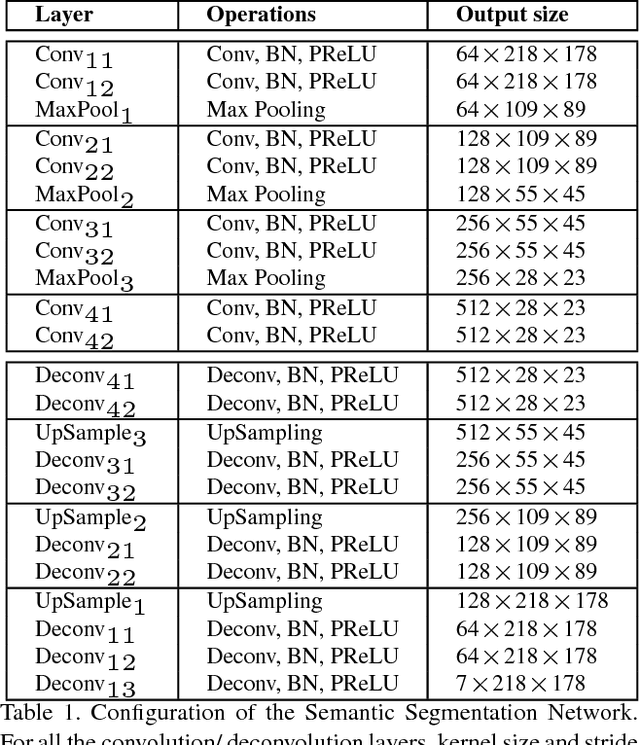

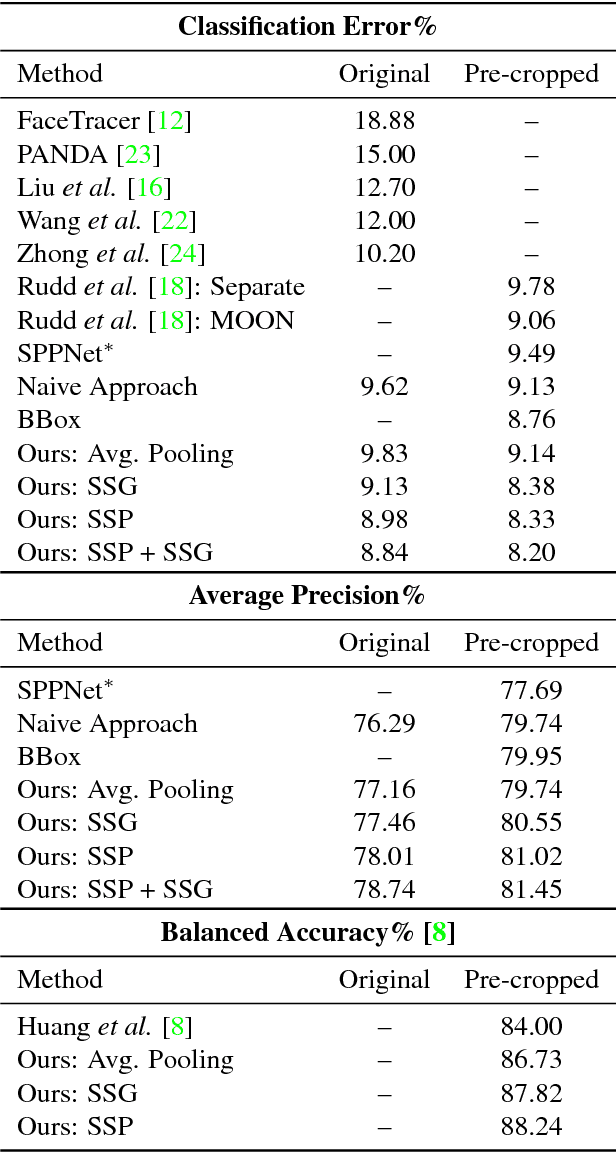
Attributes are semantically meaningful characteristics whose applicability widely crosses category boundaries. They are particularly important in describing and recognizing concepts where no explicit training example is given, \textit{e.g., zero-shot learning}. Additionally, since attributes are human describable, they can be used for efficient human-computer interaction. In this paper, we propose to employ semantic segmentation to improve facial attribute prediction. The core idea lies in the fact that many facial attributes describe local properties. In other words, the probability of an attribute to appear in a face image is far from being uniform in the spatial domain. We build our facial attribute prediction model jointly with a deep semantic segmentation network. This harnesses the localization cues learned by the semantic segmentation to guide the attention of the attribute prediction to the regions where different attributes naturally show up. As a result of this approach, in addition to recognition, we are able to localize the attributes, despite merely having access to image level labels (weak supervision) during training. We evaluate our proposed method on CelebA and LFWA datasets and achieve superior results to the prior arts. Furthermore, we show that in the reverse problem, semantic face parsing improves when facial attributes are available. That reaffirms the need to jointly model these two interconnected tasks.
Predicting Trust Using Automated Assessment of Multivariate Interactional Synchrony
Jan 06, 2022
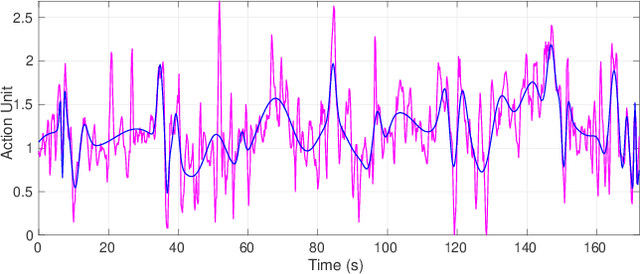
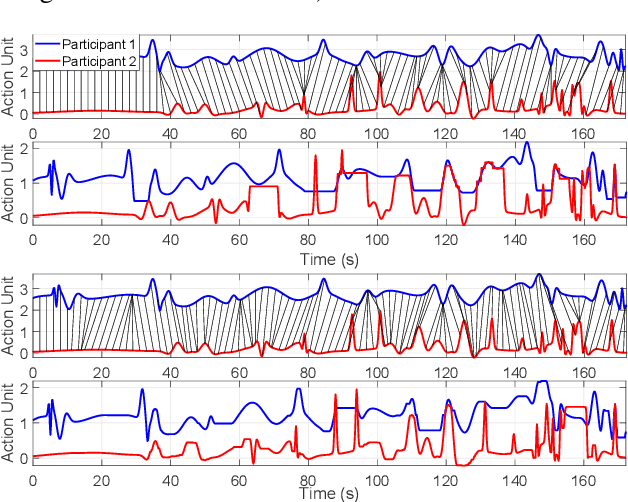
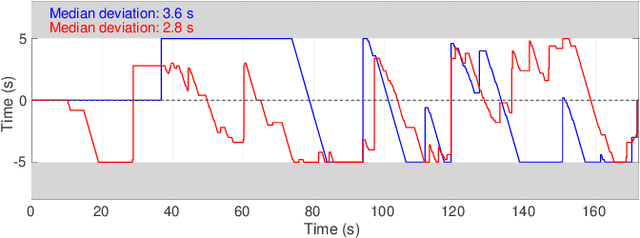
Diverse disciplines are interested in how the coordination of interacting agents' movements, emotions, and physiology over time impacts social behavior. Here, we describe a new multivariate procedure for automating the investigation of this kind of behaviorally-relevant "interactional synchrony", and introduce a novel interactional synchrony measure based on features of dynamic time warping (DTW) paths. We demonstrate that our DTW path-based measure of interactional synchrony between facial action units of two people interacting freely in a natural social interaction can be used to predict how much trust they will display in a subsequent Trust Game. We also show that our approach outperforms univariate head movement models, models that consider participants' facial action units independently, and models that use previously proposed synchrony or similarity measures. The insights of this work can be applied to any research question that aims to quantify the temporal coordination of multiple signals over time, but has immediate applications in psychology, medicine, and robotics.
Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network
May 03, 2018

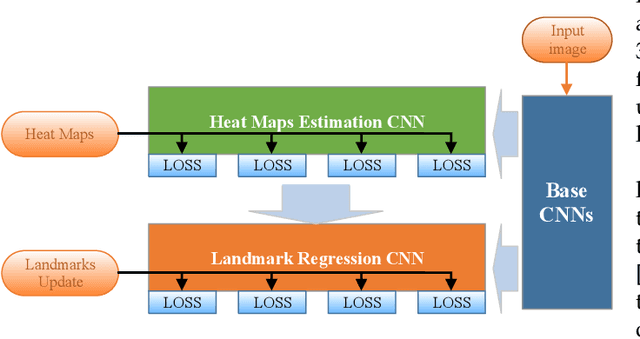
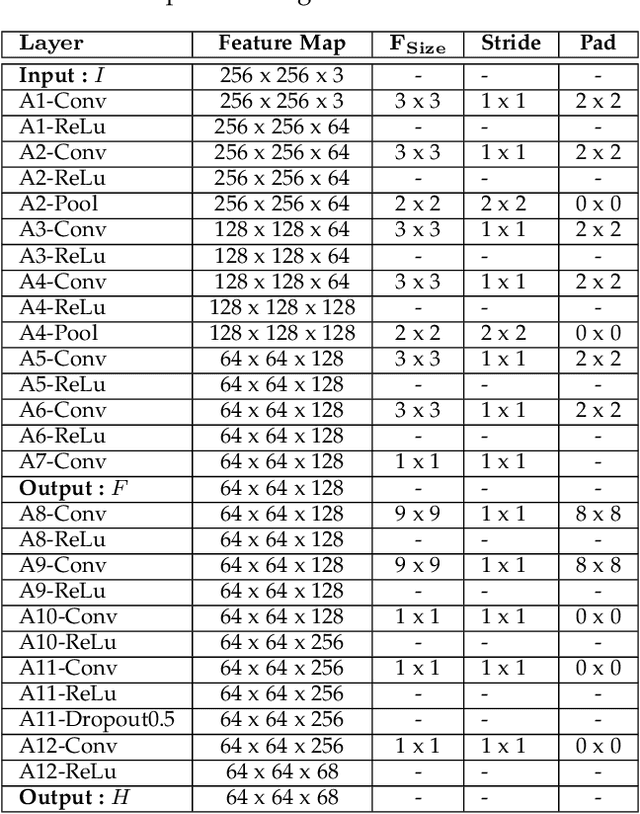
Facial landmark point localization is a typical problem in computer vision and is extensively used for increasing accuracy of face recognition, facial expression analysis, face animation etc. In recent years, substantial effort have been deployed by many researcher to design a robust facial landmark detection system. However, it still remains as one of the most challenging tasks due to the existence of extreme poses, exaggerated facial expression, unconstrained illumination, etc. In this paper, we propose a novel coarse-to-fine deep recurrent-neural-network (RNN) based framework, which uses heat-map images for facial landmark point localization. The use of heat-map images allows us using the entire face image instead of the face initialization bounding boxes or patch images around the landmark points. Performance of our proposed framework shows significant improvement in case of handling difficult face images with higher degree of occlusion, variation of pose, large yaw angles and illumination. In comparison with the best current state-of-the-art technique a reduction of 45% in failure rate and an improvement of 11.5% in area under the curve for 300-W private test set are some of the main contributions of our proposed framework.
Assessing the Influencing Factors on the Accuracy of Underage Facial Age Estimation
Dec 02, 2020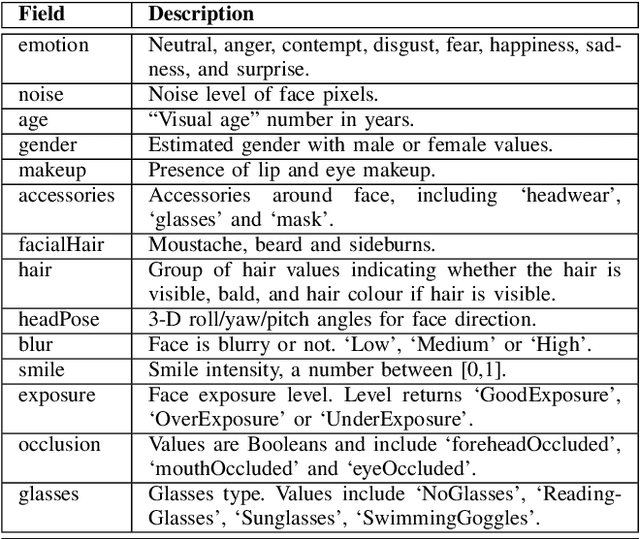
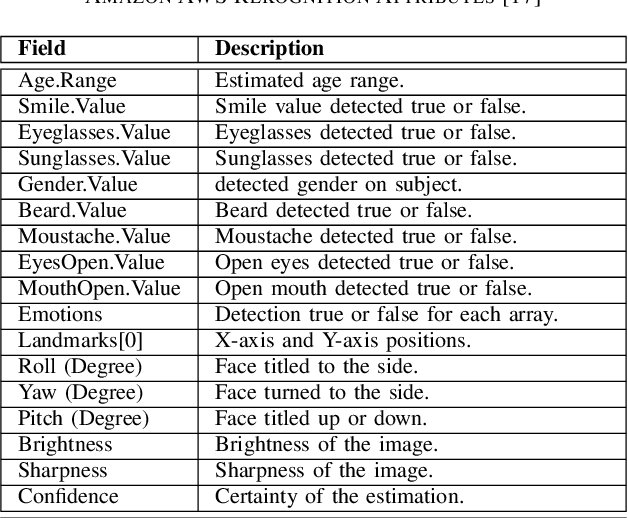
Swift response to the detection of endangered minors is an ongoing concern for law enforcement. Many child-focused investigations hinge on digital evidence discovery and analysis. Automated age estimation techniques are needed to aid in these investigations to expedite this evidence discovery process, and decrease investigator exposure to traumatic material. Automated techniques also show promise in decreasing the overflowing backlog of evidence obtained from increasing numbers of devices and online services. A lack of sufficient training data combined with natural human variance has been long hindering accurate automated age estimation -- especially for underage subjects. This paper presented a comprehensive evaluation of the performance of two cloud age estimation services (Amazon Web Service's Rekognition service and Microsoft Azure's Face API) against a dataset of over 21,800 underage subjects. The objective of this work is to evaluate the influence that certain human biometric factors, facial expressions, and image quality (i.e. blur, noise, exposure and resolution) have on the outcome of automated age estimation services. A thorough evaluation allows us to identify the most influential factors to be overcome in future age estimation systems.
End-to-end facial and physiological model for \\Affective Computing and applications
Dec 10, 2019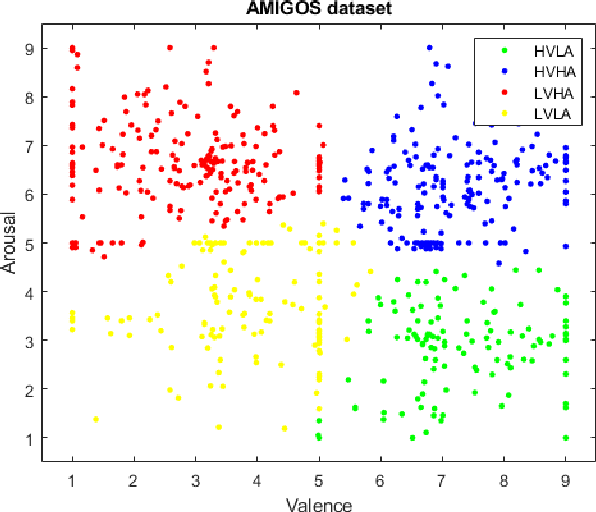
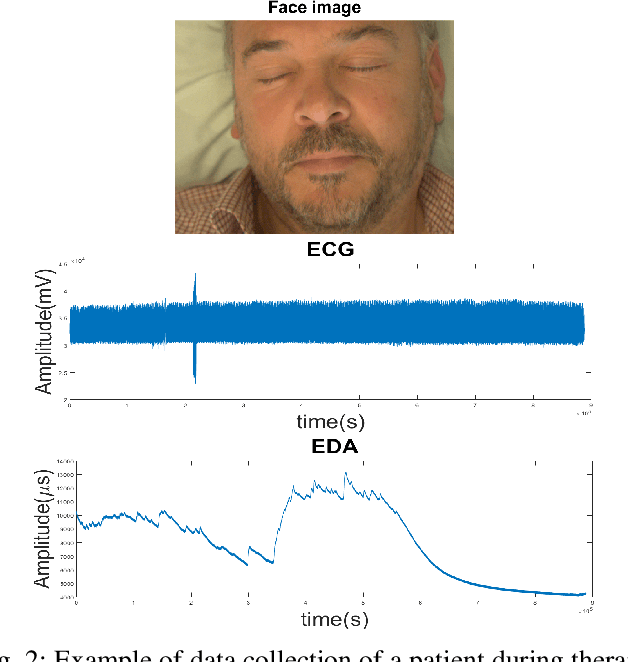
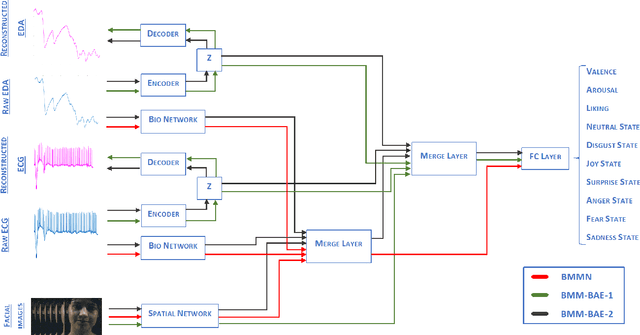
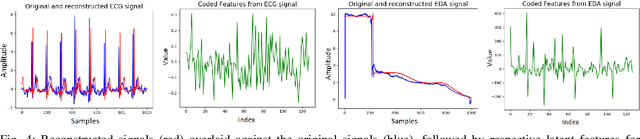
In recent years, Affective Computing and its applications have become a fast-growing research topic. Furthermore, the rise of Deep Learning has introduced significant improvements in the emotion recognition system compared to classical methods. In this work, we propose a multi-modal emotion recognition model based on deep learning techniques using the combination of peripheral physiological signals and facial expressions. Moreover, we present an improvement to proposed models by introducing latent features extracted from our internal Bio Auto-Encoder (BAE). Both models are trained and evaluated on AMIGOS datasets reporting valence, arousal, and emotion state classification. Finally, to demonstrate a possible medical application in affective computing using deep learning techniques, we applied the proposed method to the assessment of anxiety therapy. To this purpose, a reduced multi-modal database has been collected by recording facial expressions and peripheral signals such as Electrocardiogram (ECG) and Galvanic Skin Response (GSR) of each patient. Valence and arousal estimation was extracted using the proposed model from the beginning until the end of the therapy, with successful evaluation to the different emotional changes in the temporal domain.
VGAN-Based Image Representation Learning for Privacy-Preserving Facial Expression Recognition
Sep 07, 2018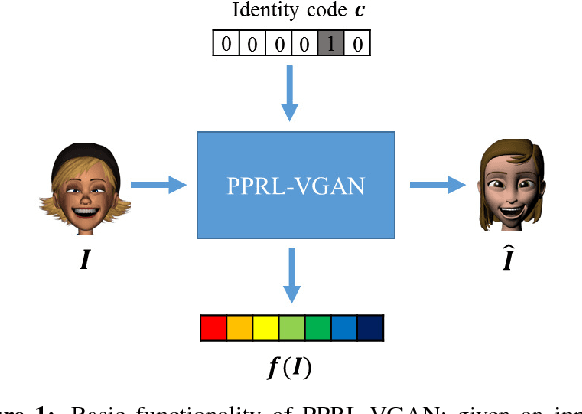

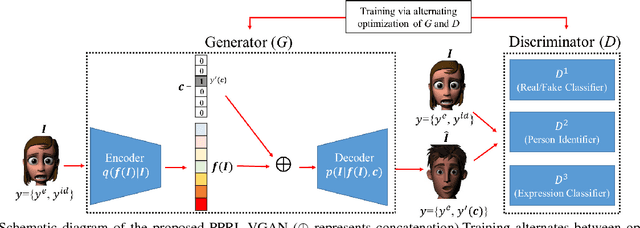
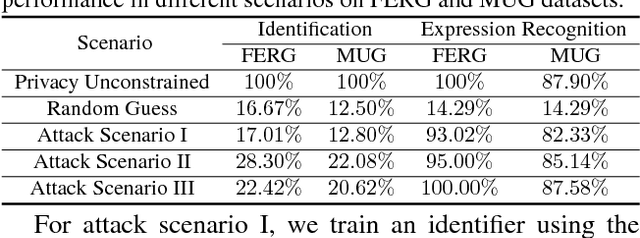
Reliable facial expression recognition plays a critical role in human-machine interactions. However, most of the facial expression analysis methodologies proposed to date pay little or no attention to the protection of a user's privacy. In this paper, we propose a Privacy-Preserving Representation-Learning Variational Generative Adversarial Network (PPRL-VGAN) to learn an image representation that is explicitly disentangled from the identity information. At the same time, this representation is discriminative from the standpoint of facial expression recognition and generative as it allows expression-equivalent face image synthesis. We evaluate the proposed model on two public datasets under various threat scenarios. Quantitative and qualitative results demonstrate that our approach strikes a balance between the preservation of privacy and data utility. We further demonstrate that our model can be effectively applied to other tasks such as expression morphing and image completion.
Facial Emotion Recognition using Convolutional Neural Networks
Oct 12, 2019
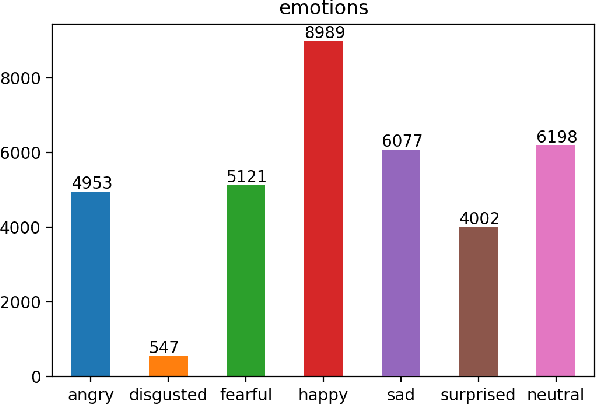
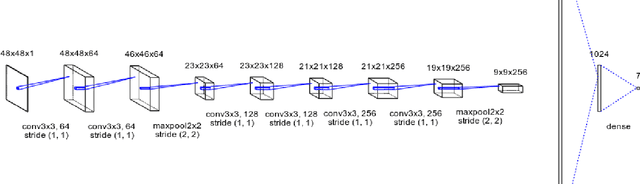
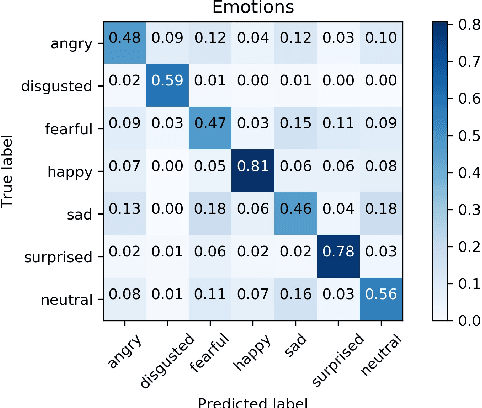
Facial expression recognition is a topic of great interest in most fields from artificial intelligence and gaming to marketing and healthcare. The goal of this paper is to classify images of human faces into one of seven basic emotions. A number of different models were experimented with, including decision trees and neural networks before arriving at a final Convolutional Neural Network (CNN) model. CNNs work better for image recognition tasks since they are able to capture spacial features of the inputs due to their large number of filters. The proposed model consists of six convolutional layers, two max pooling layers and two fully connected layers. Upon tuning of the various hyperparameters, this model achieved a final accuracy of 0.60.