 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
M2FPA: A Multi-Yaw Multi-Pitch High-Quality Database and Benchmark for Facial Pose Analysis
Mar 30, 2019

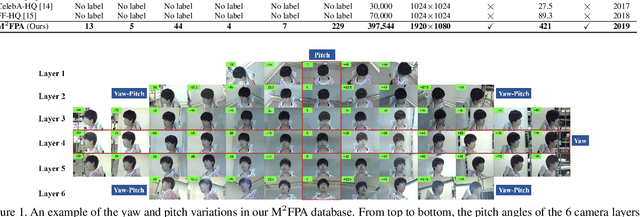


Facial images in surveillance or mobile scenarios often have large view-point variations in terms of pitch and yaw angles. These jointly occurred angle variations make face recognition challenging. Current public face databases mainly consider the case of yaw variations. In this paper, a new large-scale Multi-yaw Multi-pitch high-quality database is proposed for Facial Pose Analysis (M2FPA), including face frontalization, face rotation, facial pose estimation and pose-invariant face recognition. It contains 397,544 images of 229 subjects with yaw, pitch, attribute, illumination and accessory. M2FPA is the most comprehensive multi-view face database for facial pose analysis. Further, we provide an effective benchmark for face frontalization and pose-invariant face recognition on M2FPA with several state-of-the-art methods, including DR-GAN, TP-GAN and CAPG-GAN. We believe that the new database and benchmark can significantly push forward the advance of facial pose analysis in real-world applications. Moreover, a simple yet effective parsing guided discriminator is introduced to capture the local consistency during GAN optimization. Extensive quantitative and qualitative results on M2FPA and Multi-PIE demonstrate the superiority of our face frontalization method. Baseline results for both face synthesis and face recognition from state-of-theart methods demonstrate the challenge offered by this new database.
Proposing a System Level Machine Learning Hybrid Architecture and Approach for a Comprehensive Autism Spectrum Disorder Diagnosis
Sep 18, 2021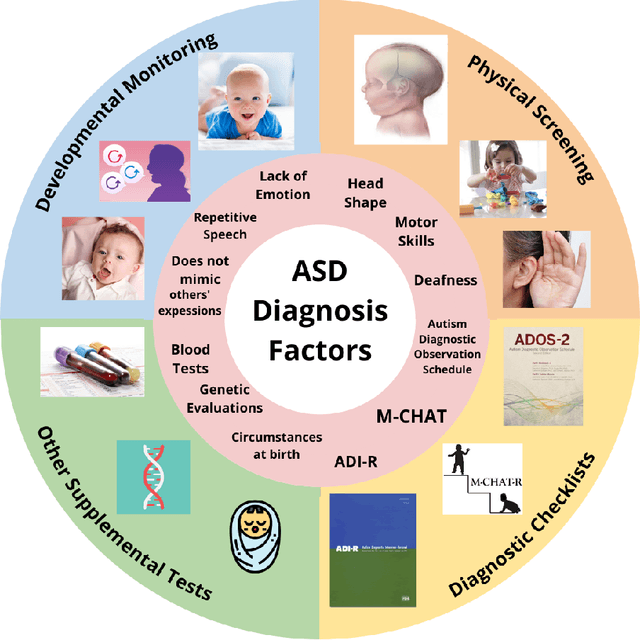
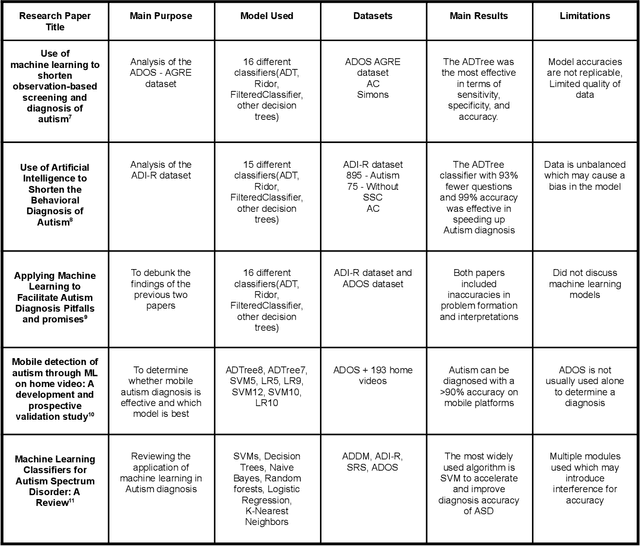
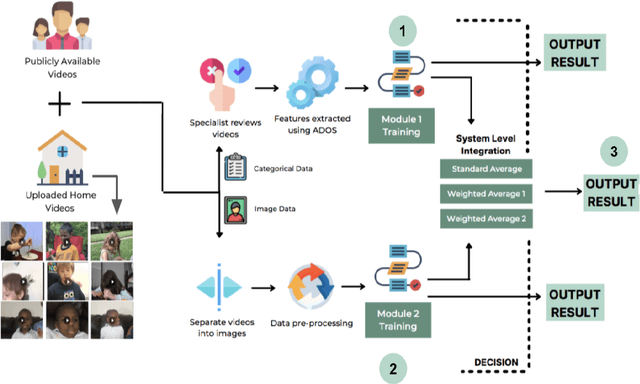
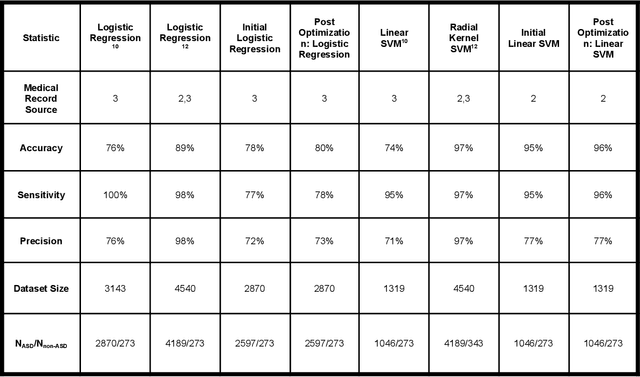
Autism Spectrum Disorder (ASD) is a severe neuropsychiatric disorder that affects intellectual development, social behavior, and facial features, and the number of cases is still significantly increasing. Due to the variety of symptoms ASD displays, the diagnosis process remains challenging, with numerous misdiagnoses as well as lengthy and expensive diagnoses. Fortunately, if ASD is diagnosed and treated early, then the patient will have a much higher chance of developing normally. For an ASD diagnosis, machine learning algorithms can analyze both social behavior and facial features accurately and efficiently, providing an ASD diagnosis in a drastically shorter amount of time than through current clinical diagnosis processes. Therefore, we propose to develop a hybrid architecture fully utilizing both social behavior and facial feature data to improve the accuracy of diagnosing ASD. We first developed a Linear Support Vector Machine for the social behavior based module, which analyzes Autism Diagnostic Observation Schedule (ADOS) social behavior data. For the facial feature based module, a DenseNet model was utilized to analyze facial feature image data. Finally, we implemented our hybrid model by incorporating different features of the Support Vector Machine and the DenseNet into one model. Our results show that the highest accuracy of 87% for ASD diagnosis has been achieved by our proposed hybrid model. The pros and cons of each module will be discussed in this paper.
Inferring Dynamic Representations of Facial Actions from a Still Image
Apr 04, 2019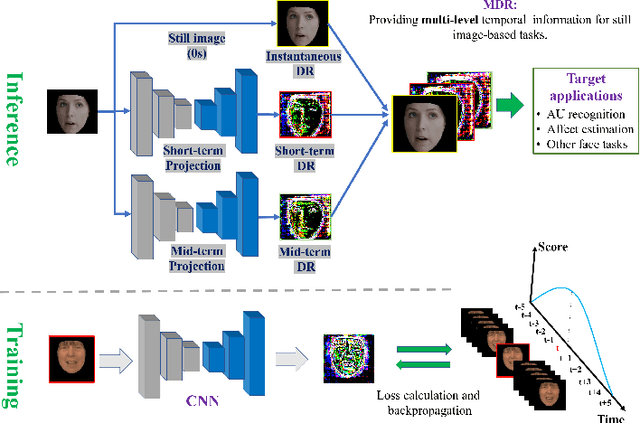
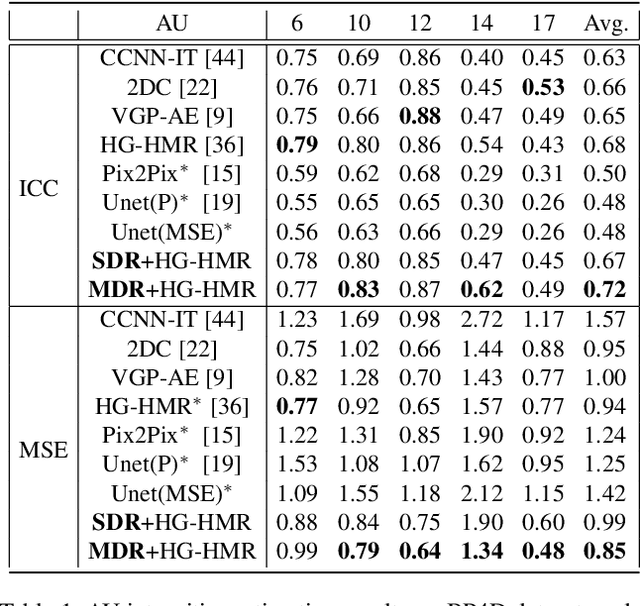
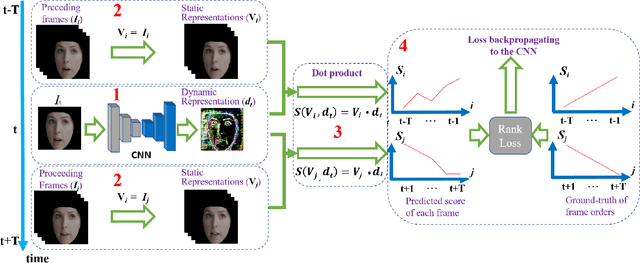
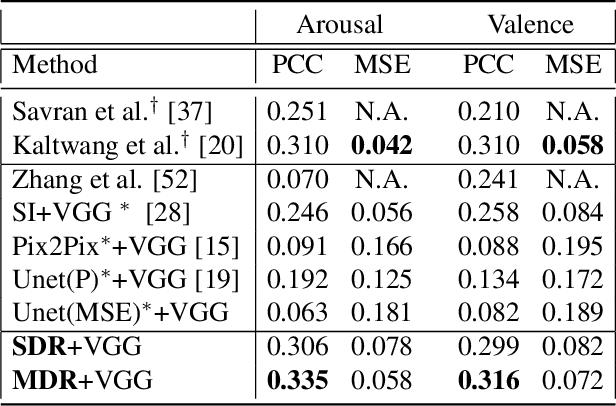
Facial actions are spatio-temporal signals by nature, and therefore their modeling is crucially dependent on the availability of temporal information. In this paper, we focus on inferring such temporal dynamics of facial actions when no explicit temporal information is available, i.e. from still images. We present a novel approach to capture multiple scales of such temporal dynamics, with an application to facial Action Unit (AU) intensity estimation and dimensional affect estimation. In particular, 1) we propose a framework that infers a dynamic representation (DR) from a still image, which captures the bi-directional flow of time within a short time-window centered at the input image; 2) we show that we can train our method without the need of explicitly generating target representations, allowing the network to represent dynamics more broadly; and 3) we propose to apply a multiple temporal scale approach that infers DRs for different window lengths (MDR) from a still image. We empirically validate the value of our approach on the task of frame ranking, and show how our proposed MDR attains state of the art results on BP4D for AU intensity estimation and on SEMAINE for dimensional affect estimation, using only still images at test time.
A Boost in Revealing Subtle Facial Expressions: A Consolidated Eulerian Framework
Jan 23, 2019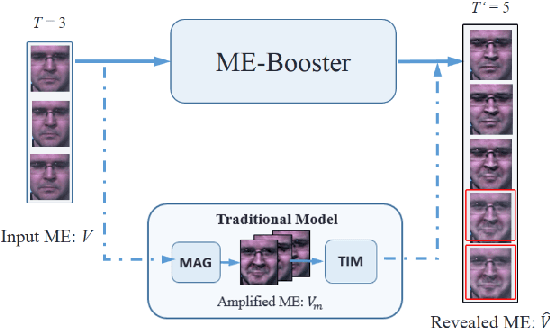
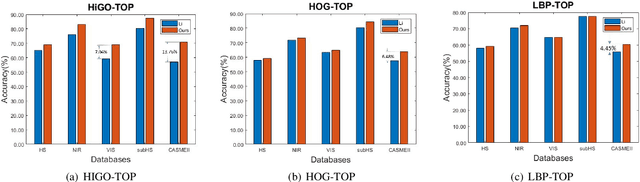
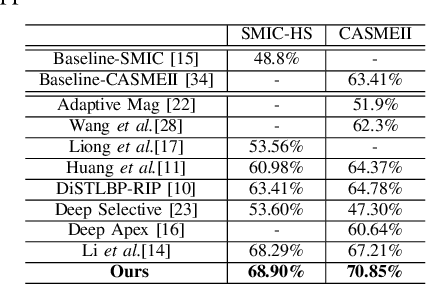
Facial Micro-expression Recognition (MER) distinguishes the underlying emotional states of spontaneous subtle facialexpressions. Automatic MER is challenging because that 1) the intensity of subtle facial muscle movement is extremely lowand 2) the duration of ME is transient.Recent works adopt motion magnification or time interpolation to resolve these issues. Nevertheless, existing works dividethem into two separate modules due to their non-linearity. Though such operation eases the difficulty in implementation, itignores their underlying connections and thus results in inevitable losses in both accuracy and speed. Instead, in this paper, weexplore their underlying joint formulations and propose a consolidated Eulerian framework to reveal the subtle facial movements.It expands the temporal duration and amplifies the muscle movements in micro-expressions simultaneously. Compared toexisting approaches, the proposed method can not only process ME clips more efficiently but also make subtle ME movementsmore distinguishable. Experiments on two public MER databases indicate that our model outperforms the state-of-the-art inboth speed and accuracy.
Pro-UIGAN: Progressive Face Hallucination from Occluded Thumbnails
Aug 05, 2021



In this paper, we study the task of hallucinating an authentic high-resolution (HR) face from an occluded thumbnail. We propose a multi-stage Progressive Upsampling and Inpainting Generative Adversarial Network, dubbed Pro-UIGAN, which exploits facial geometry priors to replenish and upsample (8*) the occluded and tiny faces (16*16 pixels). Pro-UIGAN iteratively (1) estimates facial geometry priors for low-resolution (LR) faces and (2) acquires non-occluded HR face images under the guidance of the estimated priors. Our multi-stage hallucination network super-resolves and inpaints occluded LR faces in a coarse-to-fine manner, thus reducing unwanted blurriness and artifacts significantly. Specifically, we design a novel cross-modal transformer module for facial priors estimation, in which an input face and its landmark features are formulated as queries and keys, respectively. Such a design encourages joint feature learning across the input facial and landmark features, and deep feature correspondences will be discovered by attention. Thus, facial appearance features and facial geometry priors are learned in a mutual promotion manner. Extensive experiments demonstrate that our Pro-UIGAN achieves visually pleasing HR faces, reaching superior performance in downstream tasks, i.e., face alignment, face parsing, face recognition and expression classification, compared with other state-of-the-art (SotA) methods.
Learning via social awareness: Improving a deep generative sketching model with facial feedback
Aug 27, 2018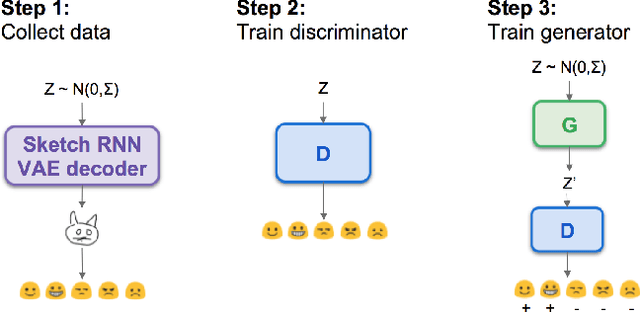
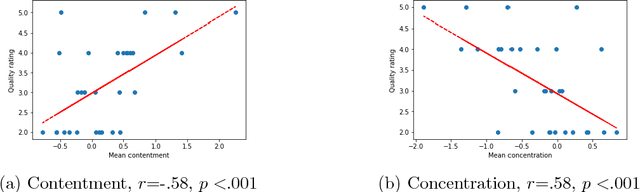
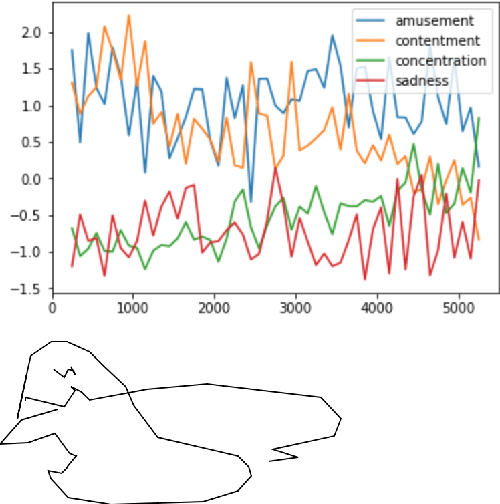
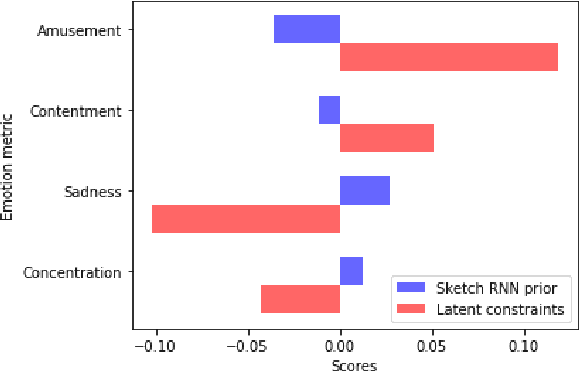
In the quest towards general artificial intelligence (AI), researchers have explored developing loss functions that act as intrinsic motivators in the absence of external rewards. This paper argues that such research has overlooked an important and useful intrinsic motivator: social interaction. We posit that making an AI agent aware of implicit social feedback from humans can allow for faster learning of more generalizable and useful representations, and could potentially impact AI safety. We collect social feedback in the form of facial expression reactions to samples from Sketch RNN, an LSTM-based variational autoencoder (VAE) designed to produce sketch drawings. We use a Latent Constraints GAN (LC-GAN) to learn from the facial feedback of a small group of viewers, by optimizing the model to produce sketches that it predicts will lead to more positive facial expressions. We show in multiple independent evaluations that the model trained with facial feedback produced sketches that are more highly rated, and induce significantly more positive facial expressions. Thus, we establish that implicit social feedback can improve the output of a deep learning model.
Cross-database non-frontal facial expression recognition based on transductive deep transfer learning
Nov 30, 2018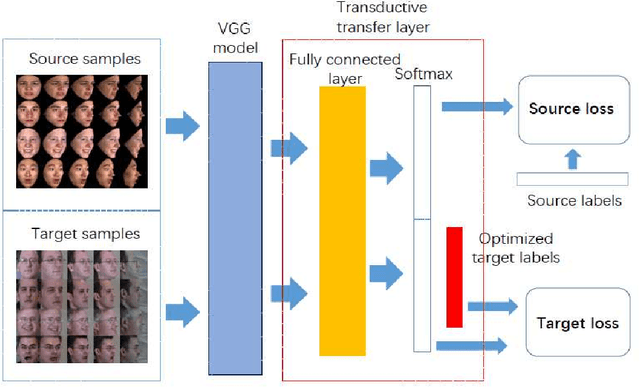


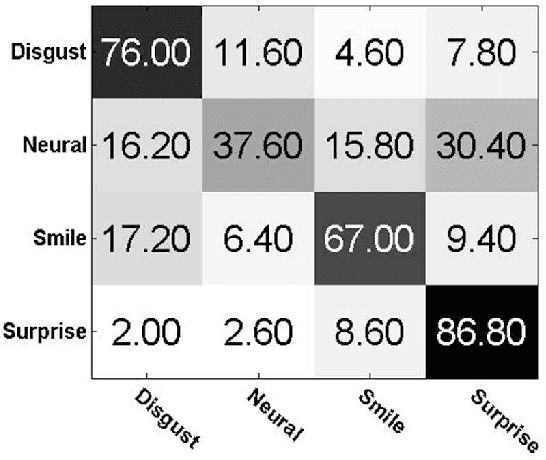
Cross-database non-frontal expression recognition is a very meaningful but rather difficult subject in the fields of computer vision and affect computing. In this paper, we proposed a novel transductive deep transfer learning architecture based on widely used VGGface16-Net for this problem. In this framework, the VGGface16-Net is used to jointly learn an common optimal nonlinear discriminative features from the non-frontal facial expression samples between the source and target databases and then we design a novel transductive transfer layer to deal with the cross-database non-frontal facial expression classification task. In order to validate the performance of the proposed transductive deep transfer learning networks, we present extensive crossdatabase experiments on two famous available facial expression databases, namely the BU-3DEF and the Multi-PIE database. The final experimental results show that our transductive deep transfer network outperforms the state-of-the-art cross-database facial expression recognition methods.
Facial Expression and Peripheral Physiology Fusion to Decode Individualized Affective Experience
Nov 18, 2018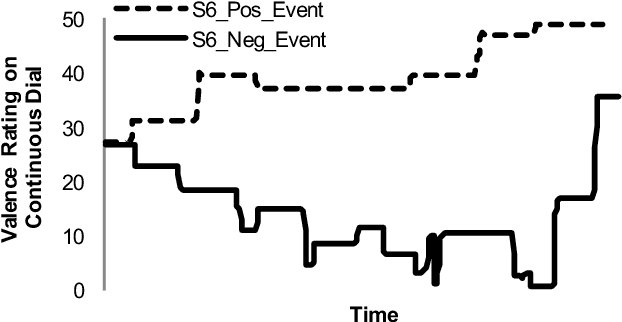
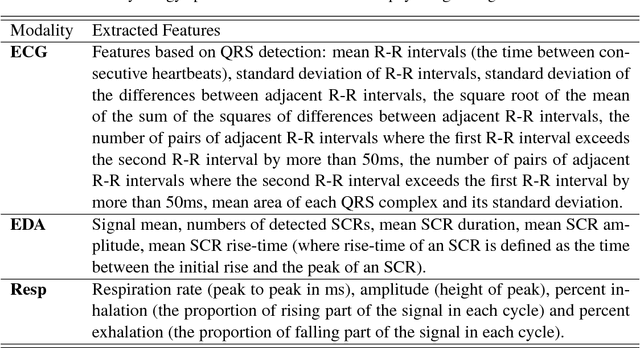
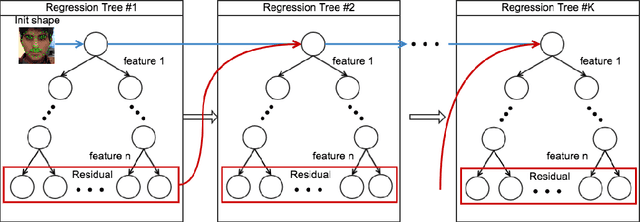
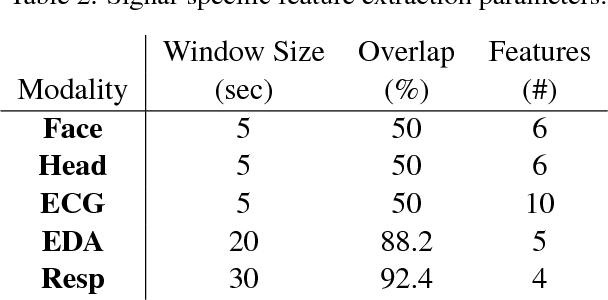
In this paper, we present a multimodal approach to simultaneously analyze facial movements and several peripheral physiological signals to decode individualized affective experiences under positive and negative emotional contexts, while considering their personalized resting dynamics. We propose a person-specific recurrence network to quantify the dynamics present in the person's facial movements and physiological data. Facial movement is represented using a robust head vs. 3D face landmark localization and tracking approach, and physiological data are processed by extracting known attributes related to the underlying affective experience. The dynamical coupling between different input modalities is then assessed through the extraction of several complex recurrent network metrics. Inference models are then trained using these metrics as features to predict individual's affective experience in a given context, after their resting dynamics are excluded from their response. We validated our approach using a multimodal dataset consists of (i) facial videos and (ii) several peripheral physiological signals, synchronously recorded from 12 participants while watching 4 emotion-eliciting video-based stimuli. The affective experience prediction results signified that our multimodal fusion method improves the prediction accuracy up to 19% when compared to the prediction using only one or a subset of the input modalities. Furthermore, we gained prediction improvement for affective experience by considering the effect of individualized resting dynamics.
Facial Expression Recognition using Visual Saliency and Deep Learning
Aug 26, 2017
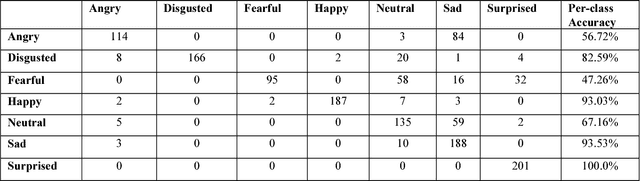
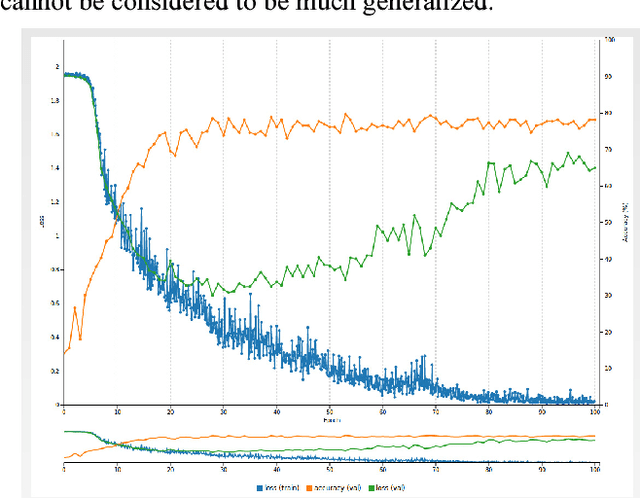
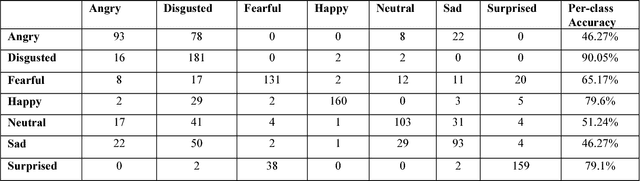
We have developed a convolutional neural network for the purpose of recognizing facial expressions in human beings. We have fine-tuned the existing convolutional neural network model trained on the visual recognition dataset used in the ILSVRC2012 to two widely used facial expression datasets - CFEE and RaFD, which when trained and tested independently yielded test accuracies of 74.79% and 95.71%, respectively. Generalization of results was evident by training on one dataset and testing on the other. Further, the image product of the cropped faces and their visual saliency maps were computed using Deep Multi-Layer Network for saliency prediction and were fed to the facial expression recognition CNN. In the most generalized experiment, we observed the top-1 accuracy in the test set to be 65.39%. General confusion trends between different facial expressions as exhibited by humans were also observed.