 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Monocular Human Digitization via Implicit Re-projection Networks
May 16, 2022
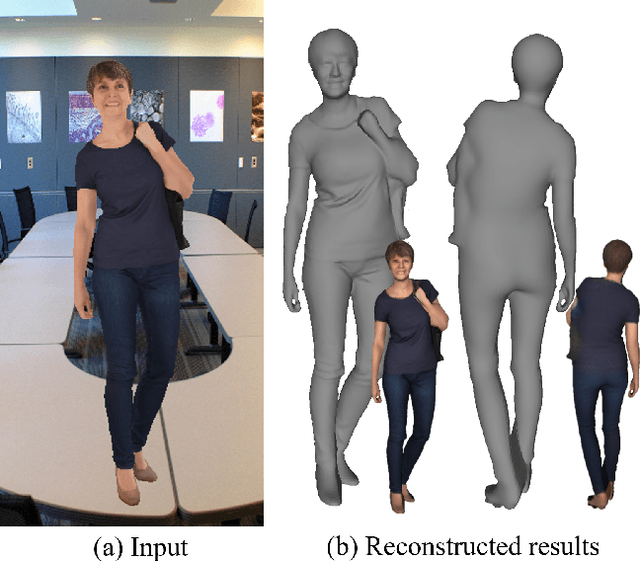
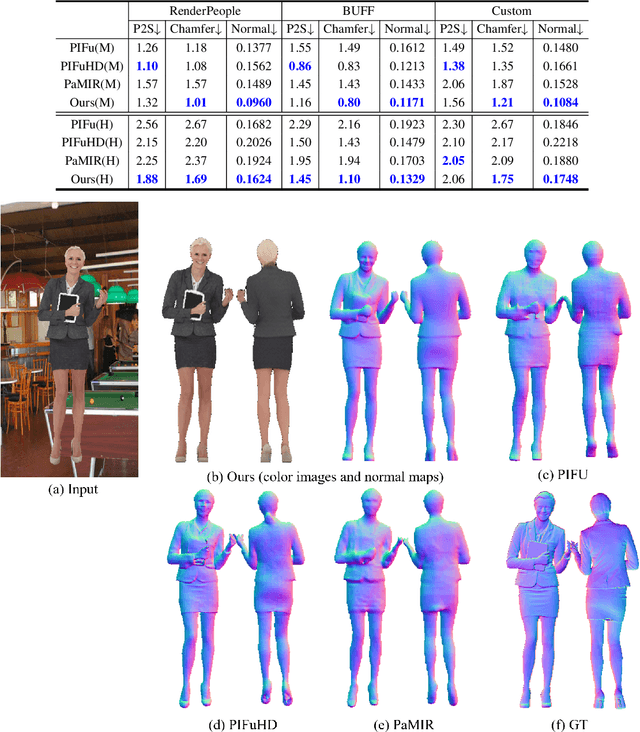
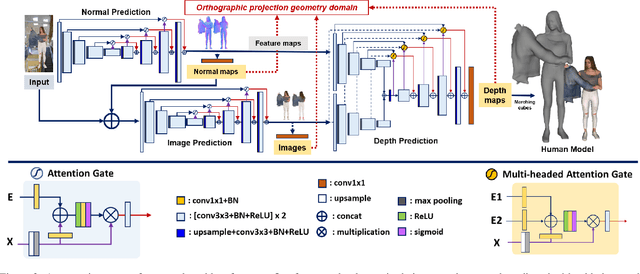
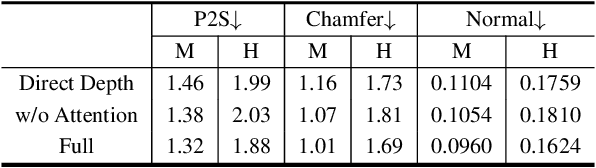
We present an approach to generating 3D human models from images. The key to our framework is that we predict double-sided orthographic depth maps and color images from a single perspective projected image. Our framework consists of three networks. The first network predicts normal maps to recover geometric details such as wrinkles in the clothes and facial regions. The second network predicts shade-removed images for the front and back views by utilizing the predicted normal maps. The last multi-headed network takes both normal maps and shade-free images and predicts depth maps while selectively fusing photometric and geometric information through multi-headed attention gates. Experimental results demonstrate that our method shows visually plausible results and competitive performance in terms of various evaluation metrics over state-of-the-art methods.
ChildPredictor: A Child Face Prediction Framework with Disentangled Learning
Apr 21, 2022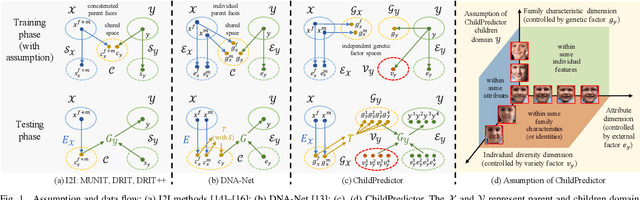

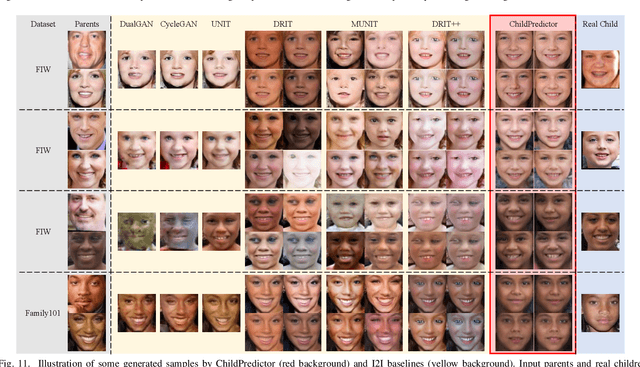

The appearances of children are inherited from their parents, which makes it feasible to predict them. Predicting realistic children's faces may help settle many social problems, such as age-invariant face recognition, kinship verification, and missing child identification. It can be regarded as an image-to-image translation task. Existing approaches usually assume domain information in the image-to-image translation can be interpreted by "style", i.e., the separation of image content and style. However, such separation is improper for the child face prediction, because the facial contours between children and parents are not the same. To address this issue, we propose a new disentangled learning strategy for children's face prediction. We assume that children's faces are determined by genetic factors (compact family features, e.g., face contour), external factors (facial attributes irrelevant to prediction, such as moustaches and glasses), and variety factors (individual properties for each child). On this basis, we formulate predictions as a mapping from parents' genetic factors to children's genetic factors, and disentangle them from external and variety factors. In order to obtain accurate genetic factors and perform the mapping, we propose a ChildPredictor framework. It transfers human faces to genetic factors by encoders and back by generators. Then, it learns the relationship between the genetic factors of parents and children through a mapping function. To ensure the generated faces are realistic, we collect a large Family Face Database to train ChildPredictor and evaluate it on the FF-Database validation set. Experimental results demonstrate that ChildPredictor is superior to other well-known image-to-image translation methods in predicting realistic and diverse child faces. Implementation codes can be found at https://github.com/zhaoyuzhi/ChildPredictor.
Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks
May 22, 2017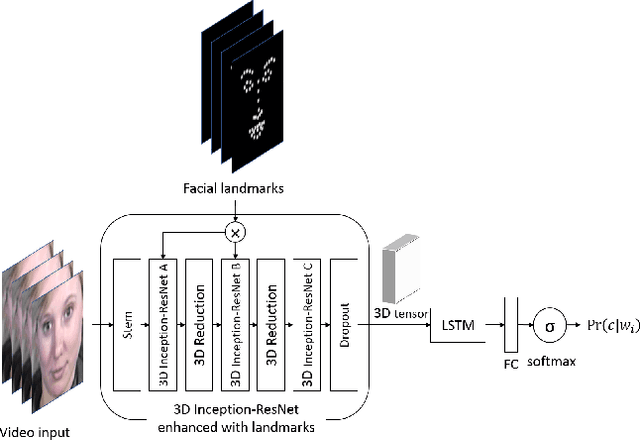
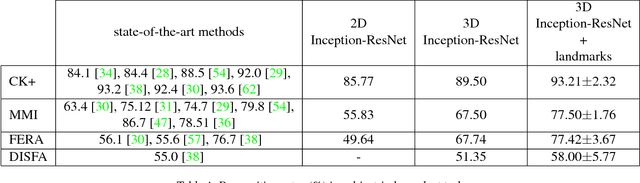
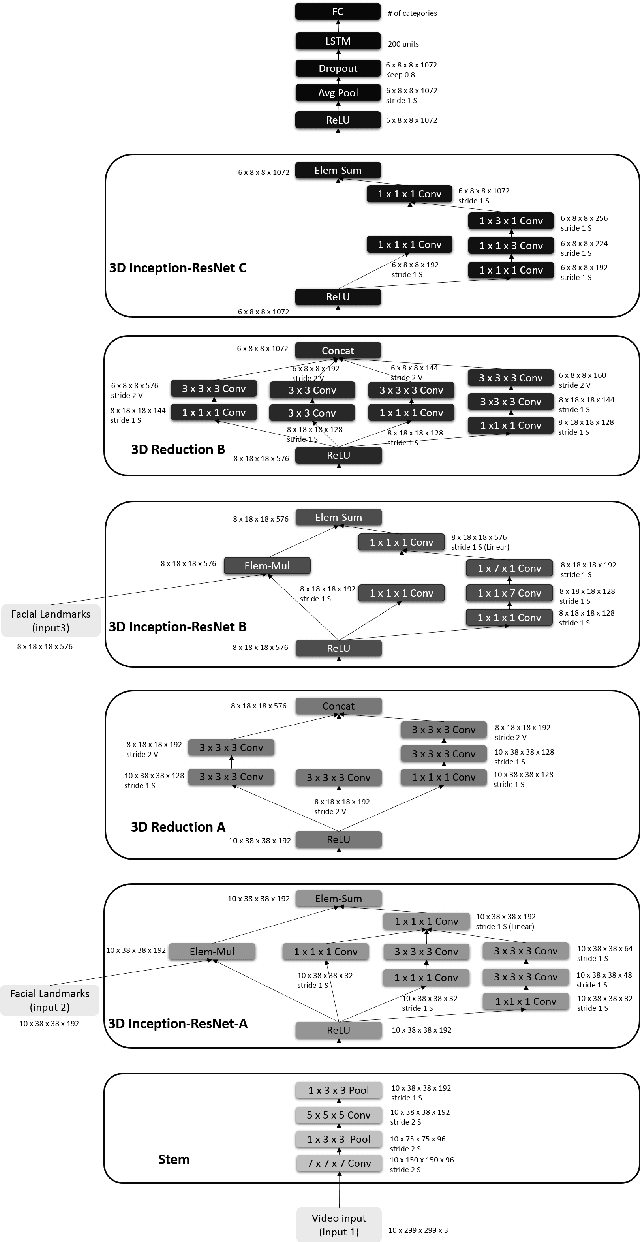
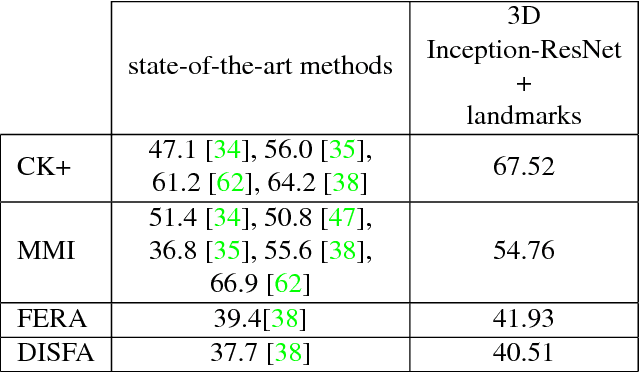
Deep Neural Networks (DNNs) have shown to outperform traditional methods in various visual recognition tasks including Facial Expression Recognition (FER). In spite of efforts made to improve the accuracy of FER systems using DNN, existing methods still are not generalizable enough in practical applications. This paper proposes a 3D Convolutional Neural Network method for FER in videos. This new network architecture consists of 3D Inception-ResNet layers followed by an LSTM unit that together extracts the spatial relations within facial images as well as the temporal relations between different frames in the video. Facial landmark points are also used as inputs to our network which emphasize on the importance of facial components rather than the facial regions that may not contribute significantly to generating facial expressions. Our proposed method is evaluated using four publicly available databases in subject-independent and cross-database tasks and outperforms state-of-the-art methods.
An Ensemble Approach for Facial Expression Analysis in Video
Mar 24, 2022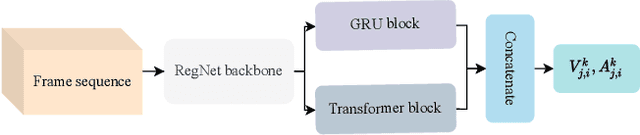
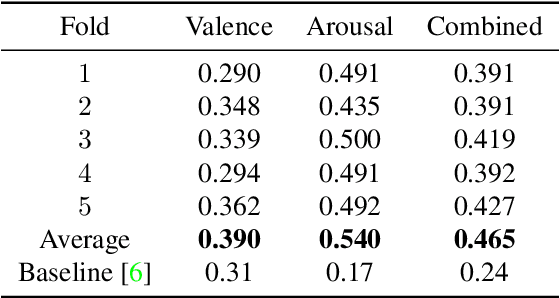
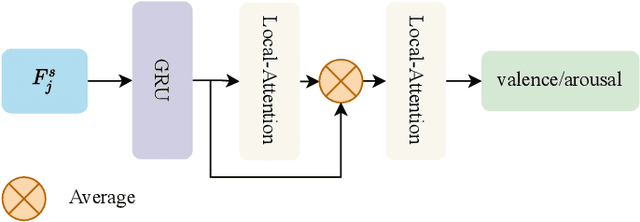
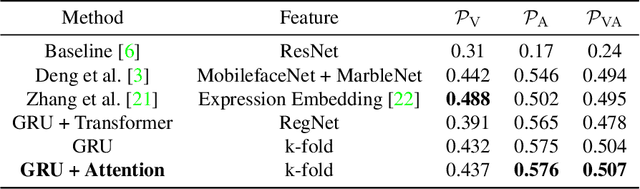
Human emotions recognization contributes to the development of human-computer interaction. The machines understanding human emotions in the real world will significantly contribute to life in the future. This paper will introduce the Affective Behavior Analysis in-the-wild (ABAW3) 2022 challenge. The paper focuses on solving the problem of the valence-arousal estimation and action unit detection. For valence-arousal estimation, we conducted two stages: creating new features from multimodel and temporal learning to predict valence-arousal. First, we make new features; the Gated Recurrent Unit (GRU) and Transformer are combined using a Regular Networks (RegNet) feature, which is extracted from the image. The next step is the GRU combined with Local Attention to predict valence-arousal. The Concordance Correlation Coefficient (CCC) was used to evaluate the model.
LAE : Long-tailed Age Estimation
Oct 25, 2021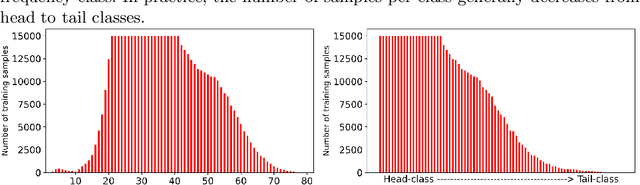


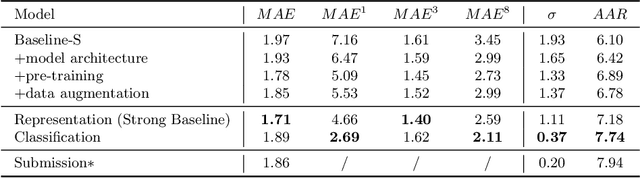
Facial age estimation is an important yet very challenging problem in computer vision. To improve the performance of facial age estimation, we first formulate a simple standard baseline and build a much strong one by collecting the tricks in pre-training, data augmentation, model architecture, and so on. Compared with the standard baseline, the proposed one significantly decreases the estimation errors. Moreover, long-tailed recognition has been an important topic in facial age datasets, where the samples often lack on the elderly and children. To train a balanced age estimator, we propose a two-stage training method named Long-tailed Age Estimation (LAE), which decouples the learning procedure into representation learning and classification. The effectiveness of our approach has been demonstrated on the dataset provided by organizers of Guess The Age Contest 2021.
Benchmarking Joint Face Spoofing and Forgery Detection with Visual and Physiological Cues
Aug 10, 2022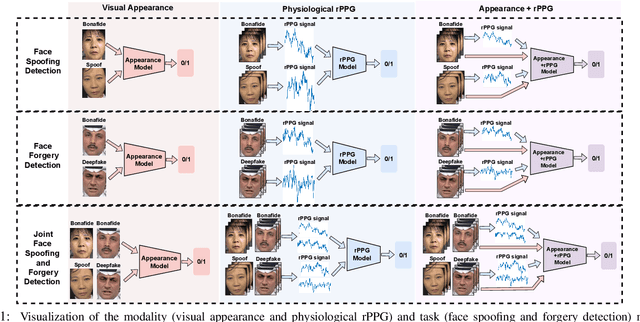
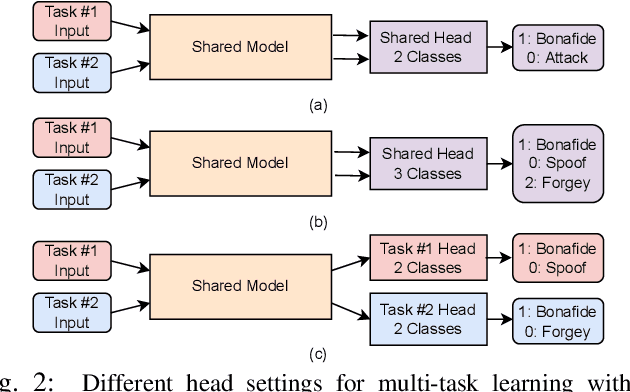
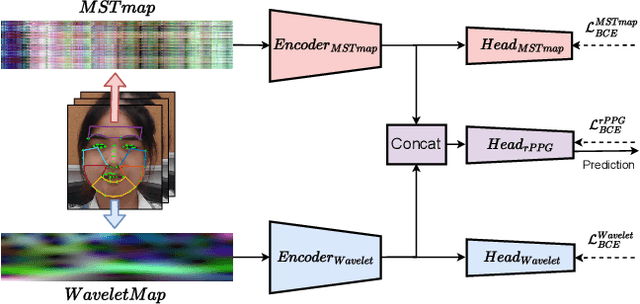
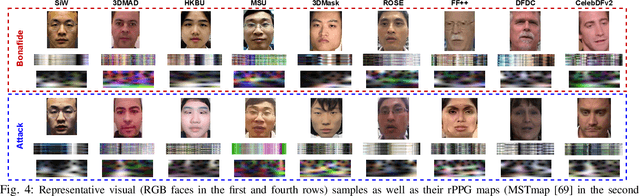
Face anti-spoofing (FAS) and face forgery detection play vital roles in securing face biometric systems from presentation attacks (PAs) and vicious digital manipulation (e.g., deepfakes). Despite promising performance upon large-scale data and powerful deep models, the generalization problem of existing approaches is still an open issue. Most of recent approaches focus on 1) unimodal visual appearance or physiological (i.e., remote photoplethysmography (rPPG)) cues; and 2) separated feature representation for FAS or face forgery detection. On one side, unimodal appearance and rPPG features are respectively vulnerable to high-fidelity face 3D mask and video replay attacks, inspiring us to design reliable multi-modal fusion mechanisms for generalized face attack detection. On the other side, there are rich common features across FAS and face forgery detection tasks (e.g., periodic rPPG rhythms and vanilla appearance for bonafides), providing solid evidence to design a joint FAS and face forgery detection system in a multi-task learning fashion. In this paper, we establish the first joint face spoofing and forgery detection benchmark using both visual appearance and physiological rPPG cues. To enhance the rPPG periodicity discrimination, we design a two-branch physiological network using both facial spatio-temporal rPPG signal map and its continuous wavelet transformed counterpart as inputs. To mitigate the modality bias and improve the fusion efficacy, we conduct a weighted batch and layer normalization for both appearance and rPPG features before multi-modal fusion. We find that the generalization capacities of both unimodal (appearance or rPPG) and multi-modal (appearance+rPPG) models can be obviously improved via joint training on these two tasks. We hope this new benchmark will facilitate the future research of both FAS and deepfake detection communities.
Semantic Facial Expression Editing using Autoencoded Flow
Nov 30, 2016


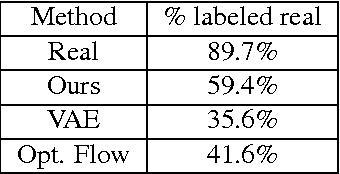
High-level manipulation of facial expressions in images --- such as changing a smile to a neutral expression --- is challenging because facial expression changes are highly non-linear, and vary depending on the appearance of the face. We present a fully automatic approach to editing faces that combines the advantages of flow-based face manipulation with the more recent generative capabilities of Variational Autoencoders (VAEs). During training, our model learns to encode the flow from one expression to another over a low-dimensional latent space. At test time, expression editing can be done simply using latent vector arithmetic. We evaluate our methods on two applications: 1) single-image facial expression editing, and 2) facial expression interpolation between two images. We demonstrate that our method generates images of higher perceptual quality than previous VAE and flow-based methods.
Teacher Supervises Students How to Learn From Partially Labeled Images for Facial Landmark Detection
Aug 13, 2019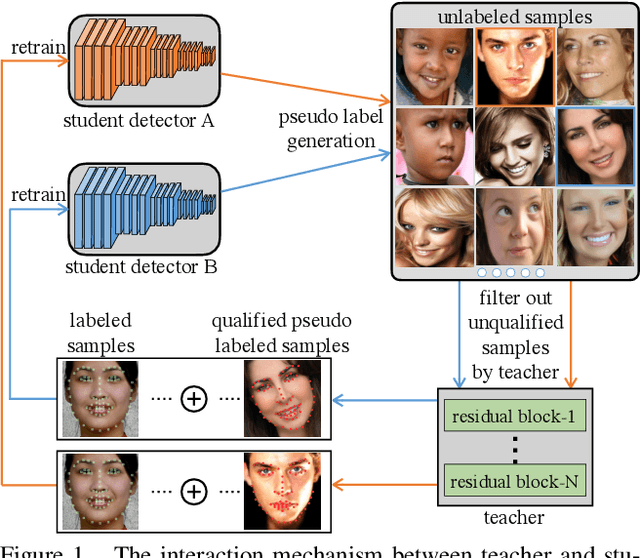
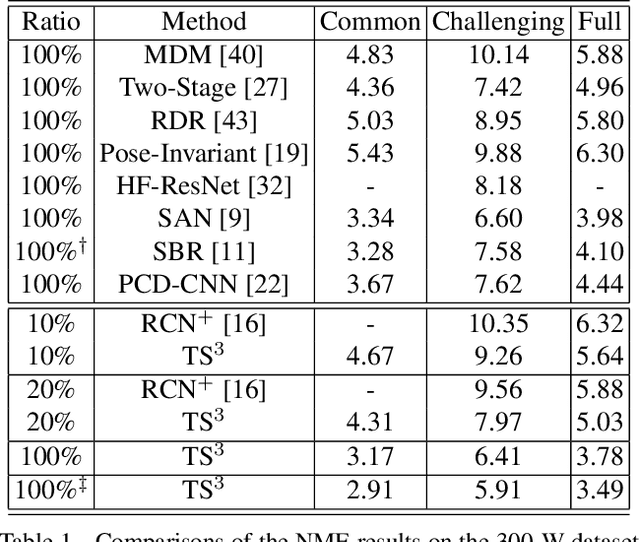
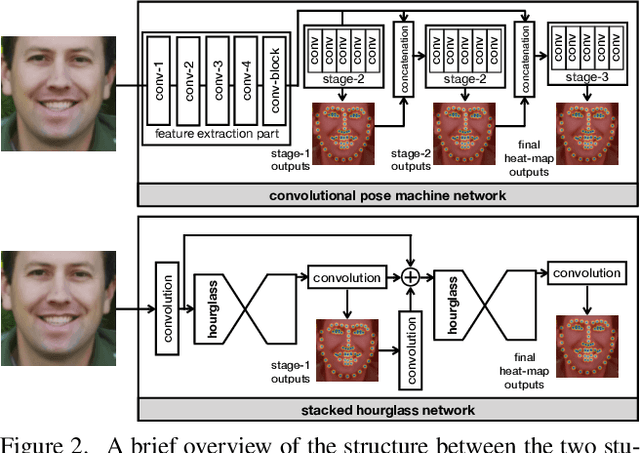

Facial landmark detection aims to localize the anatomically defined points of human faces. In this paper, we study facial landmark detection from partially labeled facial images. A typical approach is to (1) train a detector on the labeled images; (2) generate new training samples using this detector's prediction as pseudo labels of unlabeled images; (3) retrain the detector on the labeled samples and partial pseudo labeled samples. In this way, the detector can learn from both labeled and unlabeled data to become robust. In this paper, we propose an interaction mechanism between a teacher and two students to generate more reliable pseudo labels for unlabeled data, which are beneficial to semi-supervised facial landmark detection. Specifically, the two students are instantiated as dual detectors. The teacher learns to judge the quality of the pseudo labels generated by the students and filter out unqualified samples before the retraining stage. In this way, the student detectors get feedback from their teacher and are retrained by premium data generated by itself. Since the two students are trained by different samples, a combination of their predictions will be more robust as the final prediction compared to either prediction. Extensive experiments on 300-W and AFLW benchmarks show that the interactions between teacher and students contribute to better utilization of the unlabeled data and achieves state-of-the-art performance.
An Audio-Visual Attention Based Multimodal Network for Fake Talking Face Videos Detection
Mar 10, 2022

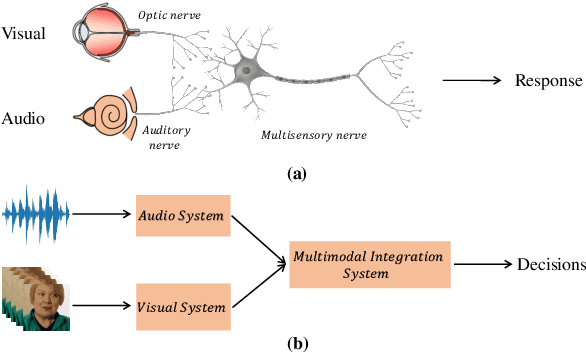
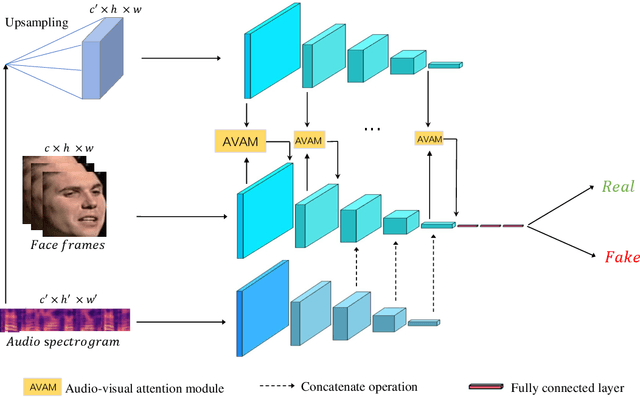
DeepFake based digital facial forgery is threatening the public media security, especially when lip manipulation has been used in talking face generation, the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity is hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face generation also becomes inevitable. Inspired by the decision-making mechanism of human multisensory perception system, which enables the auditory information to enhance post-sensory visual evidence for informed decisions output, in this study, a fake talking face detection framework FTFDNet is proposed by incorporating audio and visual representation to achieve more accurate fake talking face videos detection. Furthermore, an audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architectures by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance on the established dataset (FTFDD). The evaluation of the proposed work has shown an excellent performance on the detection of fake talking face videos, which is able to arrive at a detection rate above 97%.
Improving Borderline Adulthood Facial Age Estimation through Ensemble Learning
Jul 02, 2019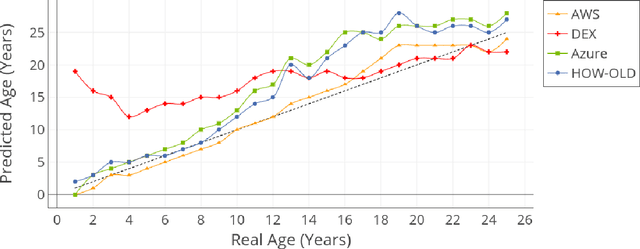
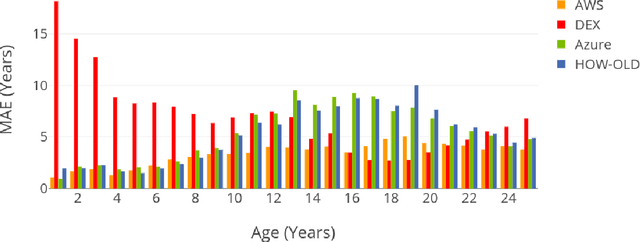
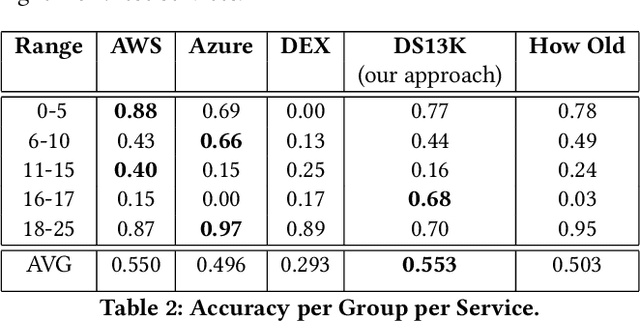

Achieving high performance for facial age estimation with subjects in the borderline between adulthood and non-adulthood has always been a challenge. Several studies have used different approaches from the age of a baby to an elder adult and different datasets have been employed to measure the mean absolute error (MAE) ranging between 1.47 to 8 years. The weakness of the algorithms specifically in the borderline has been a motivation for this paper. In our approach, we have developed an ensemble technique that improves the accuracy of underage estimation in conjunction with our deep learning model (DS13K) that has been fine-tuned on the Deep Expectation (DEX) model. We have achieved an accuracy of 68% for the age group 16 to 17 years old, which is 4 times better than the DEX accuracy for such age range. We also present an evaluation of existing cloud-based and offline facial age prediction services, such as Amazon Rekognition, Microsoft Azure Cognitive Services, How-Old.net and DEX.