 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
An Ensemble Approach for Facial Expression Analysis in Video
Mar 24, 2022
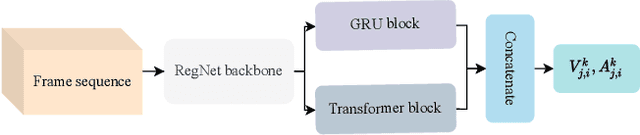
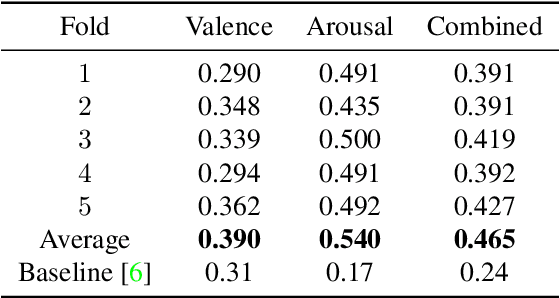
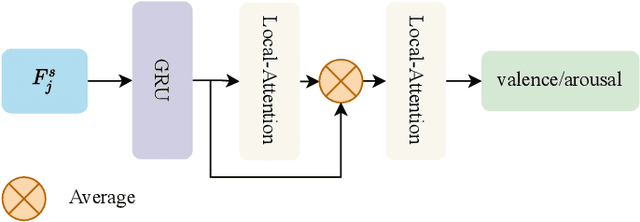
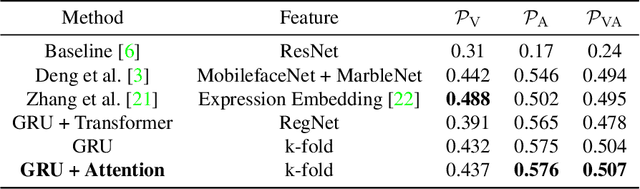
Human emotions recognization contributes to the development of human-computer interaction. The machines understanding human emotions in the real world will significantly contribute to life in the future. This paper will introduce the Affective Behavior Analysis in-the-wild (ABAW3) 2022 challenge. The paper focuses on solving the problem of the valence-arousal estimation and action unit detection. For valence-arousal estimation, we conducted two stages: creating new features from multimodel and temporal learning to predict valence-arousal. First, we make new features; the Gated Recurrent Unit (GRU) and Transformer are combined using a Regular Networks (RegNet) feature, which is extracted from the image. The next step is the GRU combined with Local Attention to predict valence-arousal. The Concordance Correlation Coefficient (CCC) was used to evaluate the model.
Multi-Level Adaptive Region of Interest and Graph Learning for Facial Action Unit Recognition
Feb 24, 2021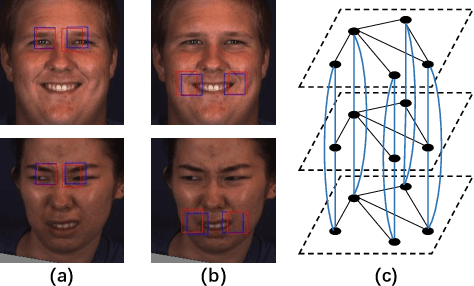

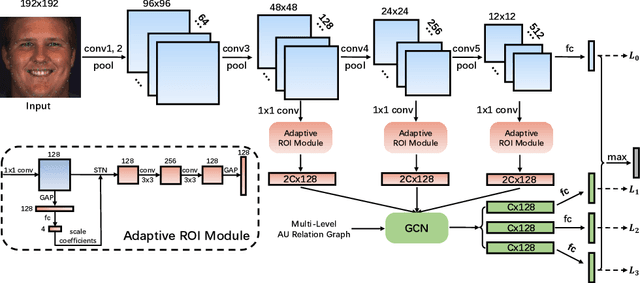
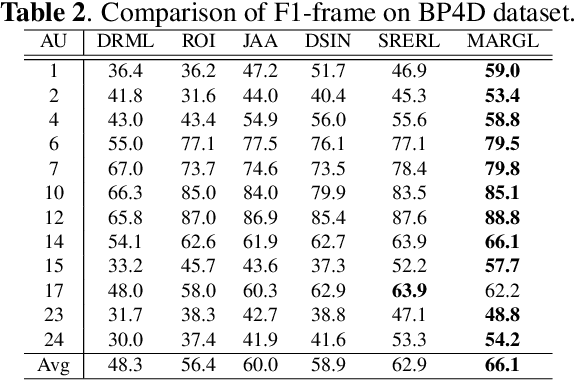
In facial action unit (AU) recognition tasks, regional feature learning and AU relation modeling are two effective aspects which are worth exploring. However, the limited representation capacity of regional features makes it difficult for relation models to embed AU relationship knowledge. In this paper, we propose a novel multi-level adaptive ROI and graph learning (MARGL) framework to tackle this problem. Specifically, an adaptive ROI learning module is designed to automatically adjust the location and size of the predefined AU regions. Meanwhile, besides relationship between AUs, there exists strong relevance between regional features across multiple levels of the backbone network as level-wise features focus on different aspects of representation. In order to incorporate the intra-level AU relation and inter-level AU regional relevance simultaneously, a multi-level AU relation graph is constructed and graph convolution is performed to further enhance AU regional features of each level. Experiments on BP4D and DISFA demonstrate the proposed MARGL significantly outperforms the previous state-of-the-art methods.
Correcting Face Distortion in Wide-Angle Videos
Nov 18, 2021


Video blogs and selfies are popular social media formats, which are often captured by wide-angle cameras to show human subjects and expanded background. Unfortunately, due to perspective projection, faces near corners and edges exhibit apparent distortions that stretch and squish the facial features, resulting in poor video quality. In this work, we present a video warping algorithm to correct these distortions. Our key idea is to apply stereographic projection locally on the facial regions. We formulate a mesh warp problem using spatial-temporal energy minimization and minimize background deformation using a line-preservation term to maintain the straight edges in the background. To address temporal coherency, we constrain the temporal smoothness on the warping meshes and facial trajectories through the latent variables. For performance evaluation, we develop a wide-angle video dataset with a wide range of focal lengths. The user study shows that 83.9% of users prefer our algorithm over other alternatives based on perspective projection.
Facial Action Unit Intensity Estimation via Semantic Correspondence Learning with Dynamic Graph Convolution
Apr 20, 2020
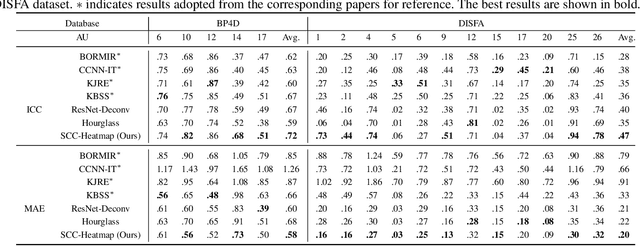
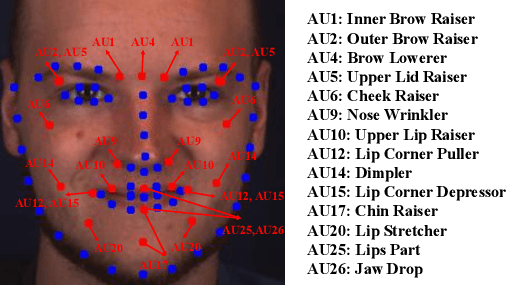
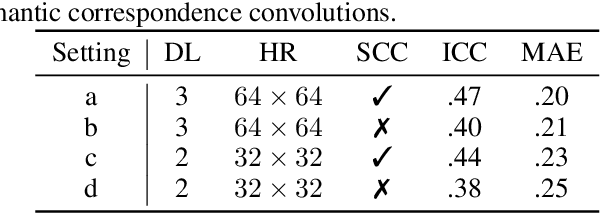
The intensity estimation of facial action units (AUs) is challenging due to subtle changes in the person's facial appearance. Previous approaches mainly rely on probabilistic models or predefined rules for modeling co-occurrence relationships among AUs, leading to limited generalization. In contrast, we present a new learning framework that automatically learns the latent relationships of AUs via establishing semantic correspondences between feature maps. In the heatmap regression-based network, feature maps preserve rich semantic information associated with AU intensities and locations. Moreover, the AU co-occurring pattern can be reflected by activating a set of feature channels, where each channel encodes a specific visual pattern of AU. This motivates us to model the correlation among feature channels, which implicitly represents the co-occurrence relationship of AU intensity levels. Specifically, we introduce a semantic correspondence convolution (SCC) module to dynamically compute the correspondences from deep and low resolution feature maps, and thus enhancing the discriminability of features. The experimental results demonstrate the effectiveness and the superior performance of our method on two benchmark datasets.
Pixel-In-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild
Mar 08, 2020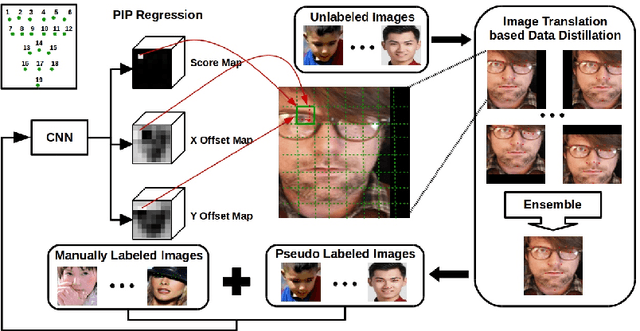

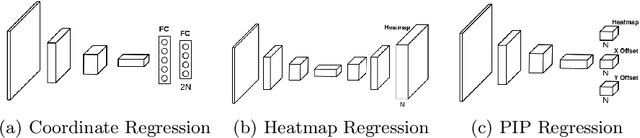

Recently, heatmap regression based models become popular because of their superior performance on locating facial landmarks. However, high-resolution feature maps have to be either generated repeatedly or maintained through the network for such models, which is computationally inefficient for practical applications. Moreover, their generalization capabilities across domains are rarely explored. To address these two problems, we propose Pixel-In-Pixel (PIP) Net for facial landmark detection. The proposed model is equipped with a novel detection head based on heatmap regression. Different from conventional heatmap regression, the new detection head conducts score prediction on low-resolution feature maps. To localize landmarks more precisely, it also conduct offset predictions within each heatmap pixel. By doing this, the inference time is largely reduced without losing accuracy. Besides, we also propose to leverage unlabeled images to improve the generalization capbility of our model through image translation based data distillation. Extensive experiments on four benchmarks show that PIP Net is comparable to state-of-the-arts while running at $27.8$ FPS on a CPU.
Limitations and Biases in Facial Landmark Detection -- An Empirical Study on Older Adults with Dementia
May 17, 2019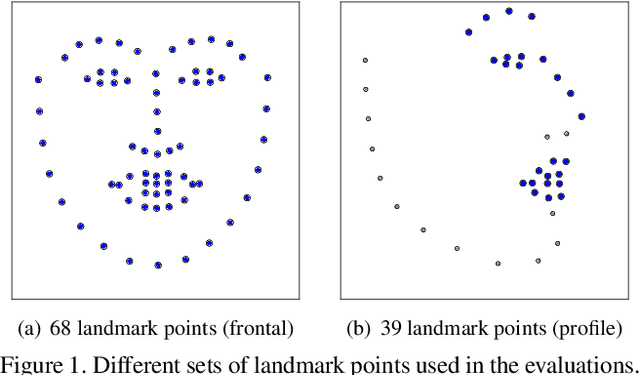
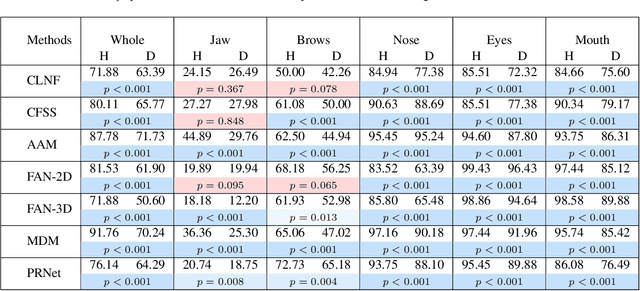
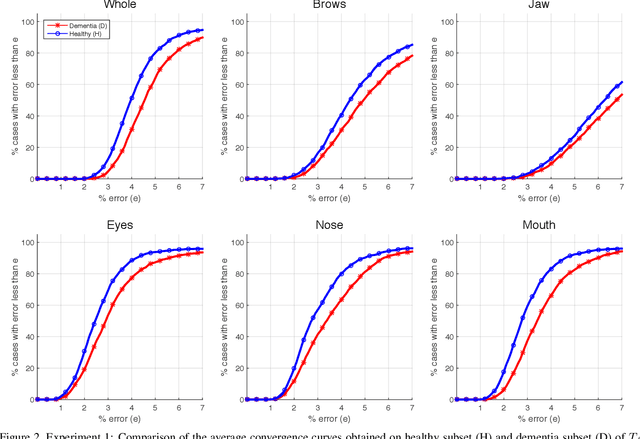
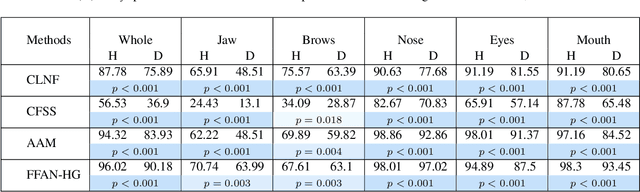
Accurate facial expression analysis is an essential step in various clinical applications that involve physical and mental health assessments of older adults (e.g. diagnosis of pain or depression). Although remarkable progress has been achieved toward developing robust facial landmark detection methods, state-of-the-art methods still face many challenges when encountering uncontrolled environments, different ranges of facial expressions, and different demographics of the population. A recent study has revealed that the health status of individuals can also affect the performance of facial landmark detection methods on front views of faces. In this work, we investigate this matter in a much greater context using seven facial landmark detection methods. We perform our evaluation not only on frontal faces but also on profile faces and in various regions of the face. Our results shed light on limitations of the existing methods and challenges of applying these methods in clinical settings by indicating: 1) a significant difference between the performance of state-of-the-art when tested on the profile or frontal faces of individuals with vs. without dementia; 2) insights on the existing bias for all regions of the face; and 3) the presence of this bias despite re-training/fine-tuning with various configurations of six datasets.
An Audio-Visual Attention Based Multimodal Network for Fake Talking Face Videos Detection
Mar 10, 2022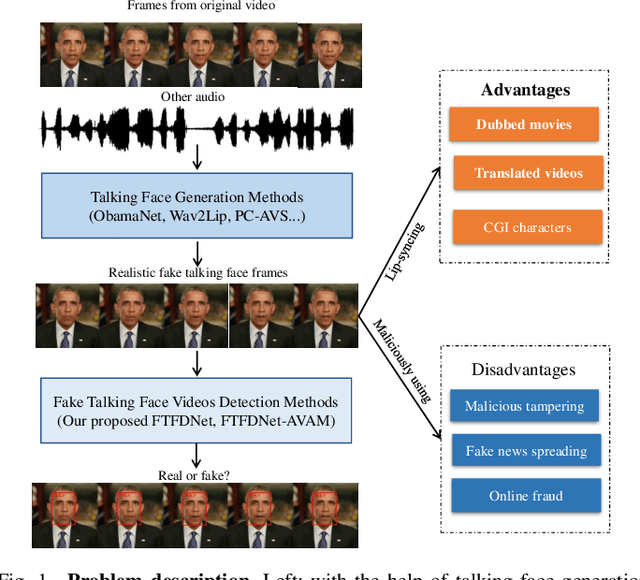

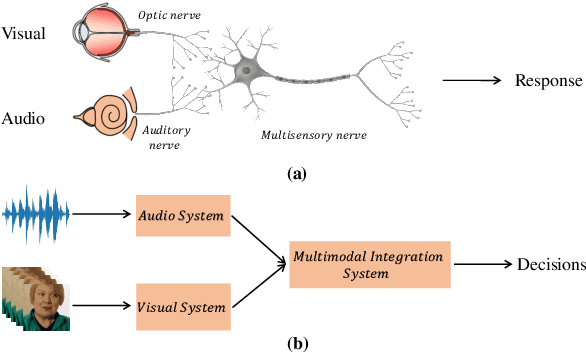
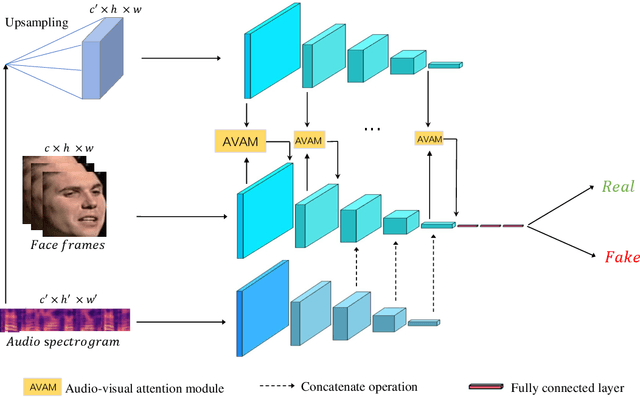
DeepFake based digital facial forgery is threatening the public media security, especially when lip manipulation has been used in talking face generation, the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity is hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face generation also becomes inevitable. Inspired by the decision-making mechanism of human multisensory perception system, which enables the auditory information to enhance post-sensory visual evidence for informed decisions output, in this study, a fake talking face detection framework FTFDNet is proposed by incorporating audio and visual representation to achieve more accurate fake talking face videos detection. Furthermore, an audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architectures by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance on the established dataset (FTFDD). The evaluation of the proposed work has shown an excellent performance on the detection of fake talking face videos, which is able to arrive at a detection rate above 97%.
LAE : Long-tailed Age Estimation
Oct 25, 2021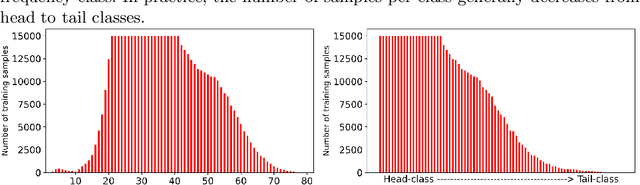


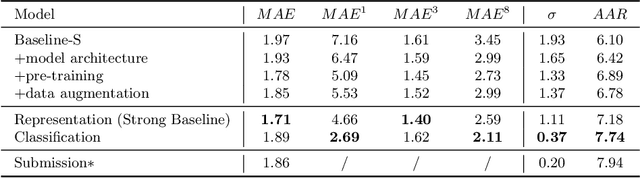
Facial age estimation is an important yet very challenging problem in computer vision. To improve the performance of facial age estimation, we first formulate a simple standard baseline and build a much strong one by collecting the tricks in pre-training, data augmentation, model architecture, and so on. Compared with the standard baseline, the proposed one significantly decreases the estimation errors. Moreover, long-tailed recognition has been an important topic in facial age datasets, where the samples often lack on the elderly and children. To train a balanced age estimator, we propose a two-stage training method named Long-tailed Age Estimation (LAE), which decouples the learning procedure into representation learning and classification. The effectiveness of our approach has been demonstrated on the dataset provided by organizers of Guess The Age Contest 2021.
SAMM Long Videos: A Spontaneous Facial Micro- and Macro-Expressions Dataset
Nov 04, 2019

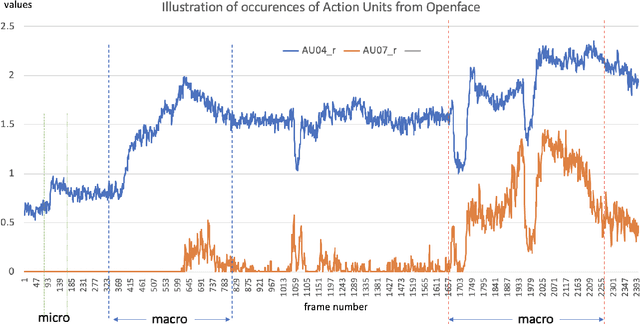
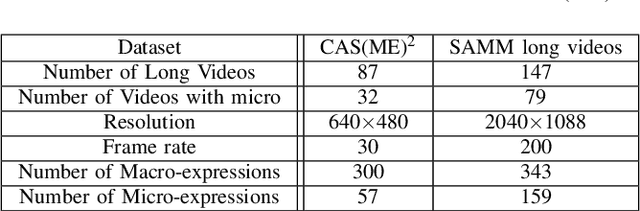
With the growth of popularity of facial microexpressions in recent years, the demand for long videos with micro- and macro-expressions is increasing. Extended from SAMM, a micro-expressions dataset released in 2016, this short report presents SAMM Long Videos dataset for spontaneous micro- and macro-expressions recognition and spotting. SAMM Long Videos dataset consists of 147 long videos with 343 macro-expressions and 159 micro-expressions. The dataset isFACS-coded with detailed Action Units (AUs). We compareour dataset with the Chinese Academy of Sciences MacroExpressions and Micro-Expressions (CAS(ME)2) dataset, which is the only available fully annotated dataset with micro- and macro-expressions. Further, we preprocess the long videos using OpenFace, which includes face alignment and detection of facial movements based on the AUs. We will release the long videos for the next micro-expressions, and macro-expressions spotting challenge and future research uses.
Neural Parameterization for Dynamic Human Head Editing
Jul 01, 2022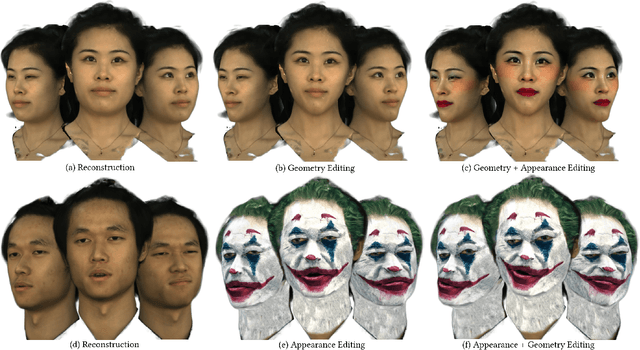

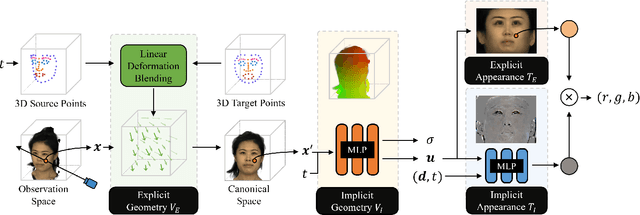

Implicit radiance functions emerged as a powerful scene representation for reconstructing and rendering photo-realistic views of a 3D scene. These representations, however, suffer from poor editability. On the other hand, explicit representations such as polygonal meshes allow easy editing but are not as suitable for reconstructing accurate details in dynamic human heads, such as fine facial features, hair, teeth, and eyes. In this work, we present Neural Parameterization (NeP), a hybrid representation that provides the advantages of both implicit and explicit methods. NeP is capable of photo-realistic rendering while allowing fine-grained editing of the scene geometry and appearance. We first disentangle the geometry and appearance by parameterizing the 3D geometry into 2D texture space. We enable geometric editability by introducing an explicit linear deformation blending layer. The deformation is controlled by a set of sparse key points, which can be explicitly and intuitively displaced to edit the geometry. For appearance, we develop a hybrid 2D texture consisting of an explicit texture map for easy editing and implicit view and time-dependent residuals to model temporal and view variations. We compare our method to several reconstruction and editing baselines. The results show that the NeP achieves almost the same level of rendering accuracy while maintaining high editability.