 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Failure Detection for Facial Landmark Detectors
Aug 23, 2016


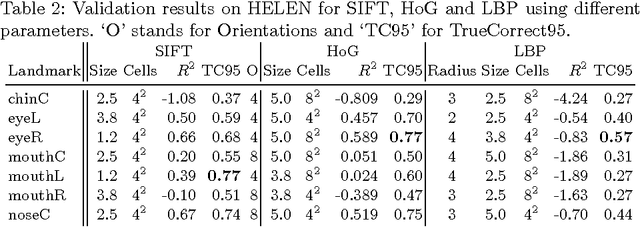
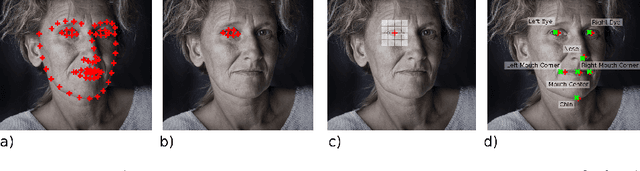
Most face applications depend heavily on the accuracy of the face and facial landmarks detectors employed. Prediction of attributes such as gender, age, and identity usually completely fail when the faces are badly aligned due to inaccurate facial landmark detection. Despite the impressive recent advances in face and facial landmark detection, little study is on the recovery from and detection of failures or inaccurate predictions. In this work we study two top recent facial landmark detectors and devise confidence models for their outputs. We validate our failure detection approaches on standard benchmarks (AFLW, HELEN) and correctly identify more than 40% of the failures in the outputs of the landmark detectors. Moreover, with our failure detection we can achieve a 12% error reduction on a gender estimation application at the cost of a small increase in computation.
RethNet: Object-by-Object Learning for Detecting Facial Skin Problems
Jan 06, 2021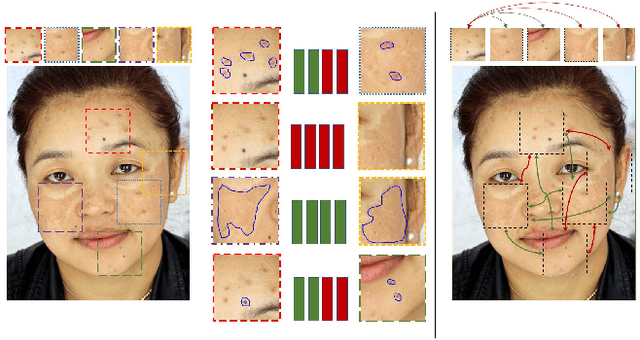

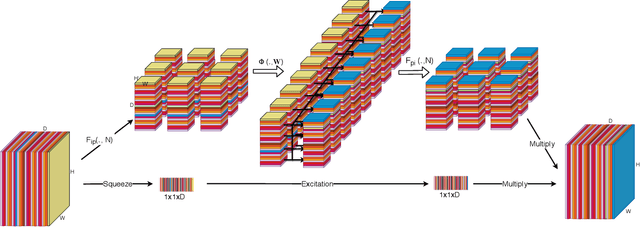
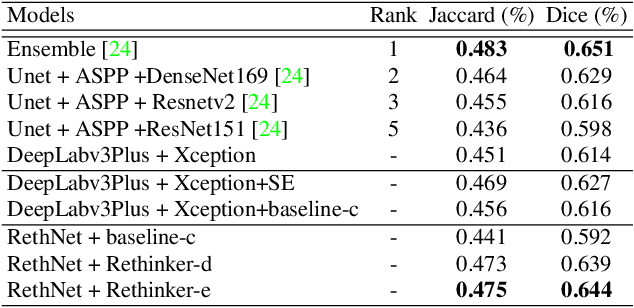
Semantic segmentation is a hot topic in computer vision where the most challenging tasks of object detection and recognition have been handling by the success of semantic segmentation approaches. We propose a concept of object-by-object learning technique to detect 11 types of facial skin lesions using semantic segmentation methods. Detecting individual skin lesion in a dense group is a challenging task, because of ambiguities in the appearance of the visual data. We observe that there exist co-occurrent visual relations between object classes (e.g., wrinkle and age spot, or papule and whitehead, etc.). In fact, rich contextual information significantly helps to handle the issue. Therefore, we propose REthinker blocks that are composed of the locally constructed convLSTM/Conv3D layers and SE module as a one-shot attention mechanism whose responsibility is to increase network's sensitivity in the local and global contextual representation that supports to capture ambiguously appeared objects and co-occurrence interactions between object classes. Experiments show that our proposed model reached MIoU of 79.46% on the test of a prepared dataset, representing a 15.34% improvement over Deeplab v3+ (MIoU of 64.12%).
Automatic Analysis of Facial Expressions Based on Deep Covariance Trajectories
Oct 25, 2018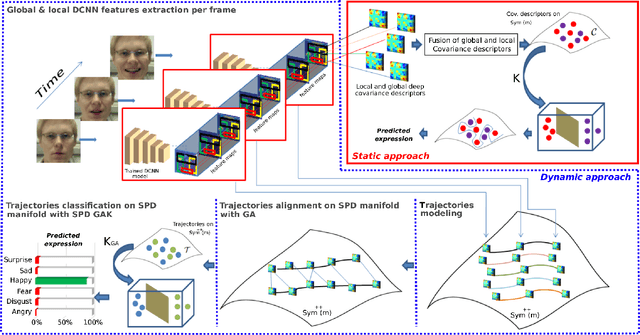
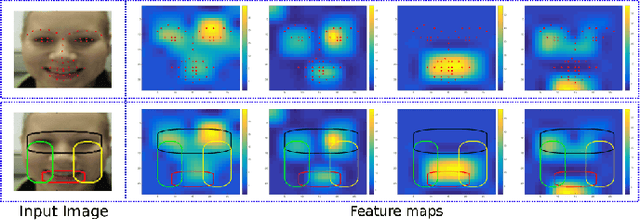
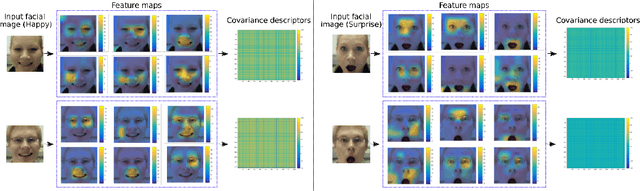

In this paper, we propose a new approach for facial expression recognition. The solution is based on the idea of encoding local and global Deep Convolutional Neural Network (DCNN) features extracted from still images, in compact local and global covariance descriptors. The space geometry of the covariance matrices is that of Symmetric Positive Definite (SPD) matrices. By performing the classification of static facial expressions using a valid Gaussian kernel on the SPD manifold and Support Vector Machine (SVM), we show that the covariance descriptors computed on DCNN features are more effective than the standard classification with fully connected layers and softmax. Besides, we propose a completely new and original solution to model the temporal dynamic of facial expressions as deep trajectories on the SPD manifold. As an extension of the classification pipeline of covariance descriptors, we apply SVM with valid positive definite kernels derived from global alignment for deep covariance trajectories classification. By conducting extensive experiments on the Oulu-CASIA, CK+, and SFEW datasets, we show that both the proposed static and dynamic approaches achieve state-of-the-art performance for facial expression recognition outperforming most recent approaches.
Differential 3D Facial Recognition: Adding 3D to Your State-of-the-Art 2D Method
Apr 03, 2020
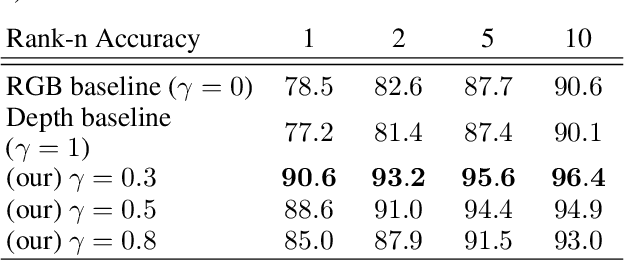
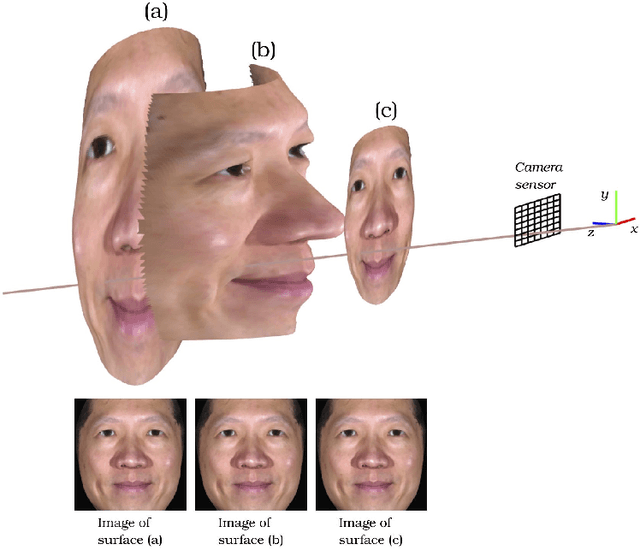
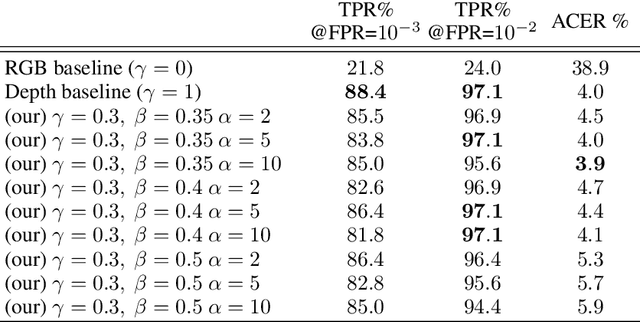
Active illumination is a prominent complement to enhance 2D face recognition and make it more robust, e.g., to spoofing attacks and low-light conditions. In the present work we show that it is possible to adopt active illumination to enhance state-of-the-art 2D face recognition approaches with 3D features, while bypassing the complicated task of 3D reconstruction. The key idea is to project over the test face a high spatial frequency pattern, which allows us to simultaneously recover real 3D information plus a standard 2D facial image. Therefore, state-of-the-art 2D face recognition solution can be transparently applied, while from the high frequency component of the input image, complementary 3D facial features are extracted. Experimental results on ND-2006 dataset show that the proposed ideas can significantly boost face recognition performance and dramatically improve the robustness to spoofing attacks.
Are Facial Attributes Adversarially Robust?
Sep 16, 2016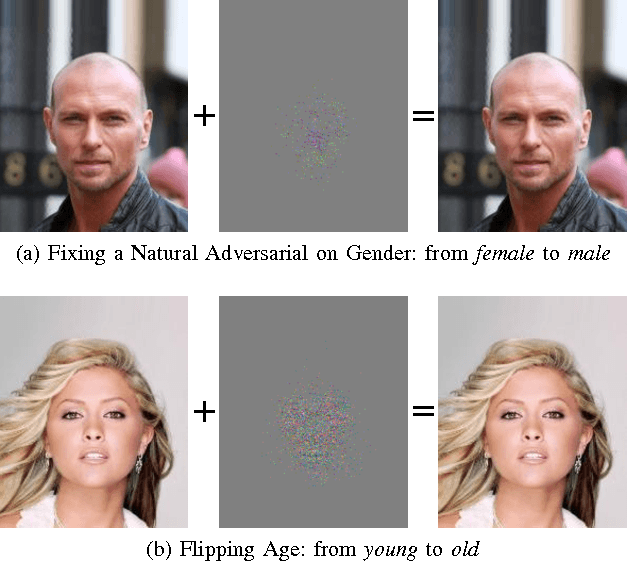
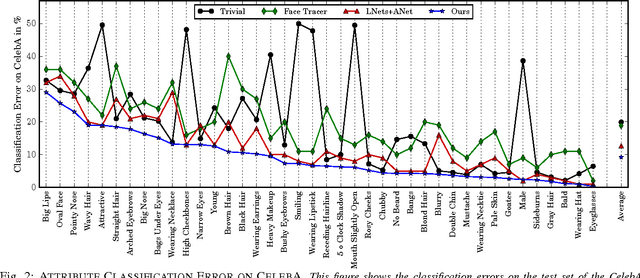
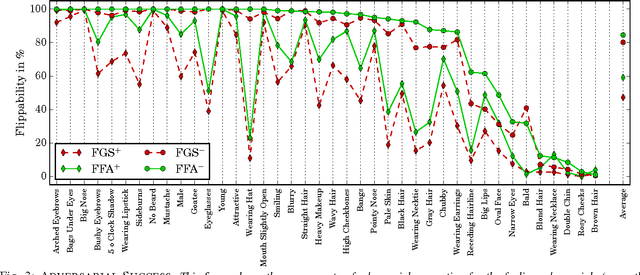
Facial attributes are emerging soft biometrics that have the potential to reject non-matches, for example, based on mismatching gender. To be usable in stand-alone systems, facial attributes must be extracted from images automatically and reliably. In this paper, we propose a simple yet effective solution for automatic facial attribute extraction by training a deep convolutional neural network (DCNN) for each facial attribute separately, without using any pre-training or dataset augmentation, and we obtain new state-of-the-art facial attribute classification results on the CelebA benchmark. To test the stability of the networks, we generated adversarial images -- formed by adding imperceptible non-random perturbations to original inputs which result in classification errors -- via a novel fast flipping attribute (FFA) technique. We show that FFA generates more adversarial examples than other related algorithms, and that DCNNs for certain attributes are generally robust to adversarial inputs, while DCNNs for other attributes are not. This result is surprising because no DCNNs tested to date have exhibited robustness to adversarial images without explicit augmentation in the training procedure to account for adversarial examples. Finally, we introduce the concept of natural adversarial samples, i.e., images that are misclassified but can be easily turned into correctly classified images by applying small perturbations. We demonstrate that natural adversarial samples commonly occur, even within the training set, and show that many of these images remain misclassified even with additional training epochs. This phenomenon is surprising because correcting the misclassification, particularly when guided by training data, should require only a small adjustment to the DCNN parameters.
Deep Energies for Estimating Three-Dimensional Facial Pose and Expression
Dec 07, 2018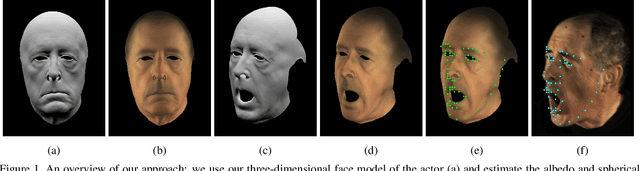


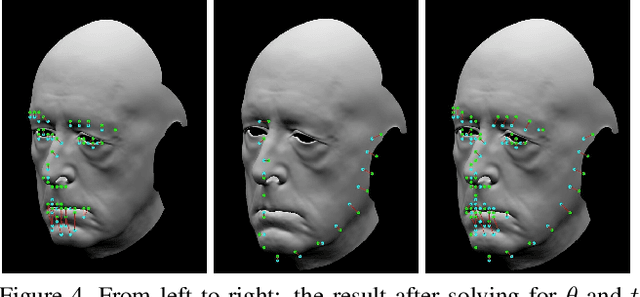
While much progress has been made in capturing high-quality facial performances using motion capture markers and shape-from-shading, high-end systems typically also rely on rotoscope curves hand-drawn on the image. These curves are subjective and difficult to draw consistently; moreover, ad-hoc procedural methods are required for generating matching rotoscope curves on synthetic renders embedded in the optimization used to determine three-dimensional facial pose and expression. We propose an alternative approach whereby these curves and other keypoints are detected automatically on both the image and the synthetic renders using trained neural networks, eliminating artist subjectivity and the ad-hoc procedures meant to mimic it. More generally, we propose using machine learning networks to implicitly define deep energies which when minimized using classical optimization techniques lead to three-dimensional facial pose and expression estimation.
Using Deep Autoencoders for Facial Expression Recognition
Jan 25, 2018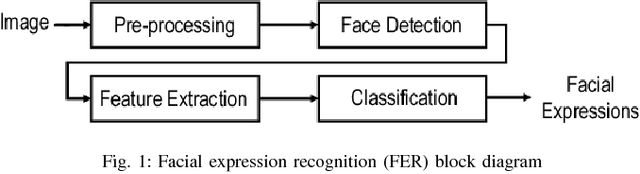
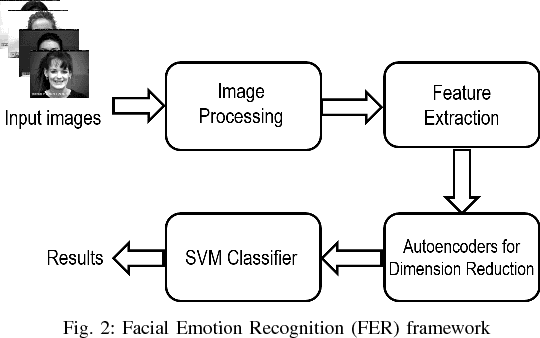

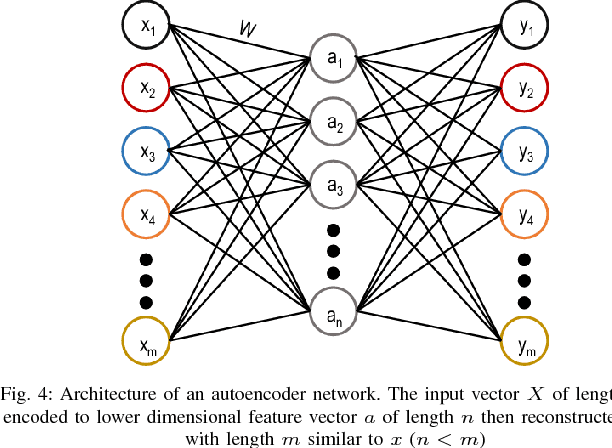
Feature descriptors involved in image processing are generally manually chosen and high dimensional in nature. Selecting the most important features is a very crucial task for systems like facial expression recognition. This paper investigates the performance of deep autoencoders for feature selection and dimension reduction for facial expression recognition on multiple levels of hidden layers. The features extracted from the stacked autoencoder outperformed when compared to other state-of-the-art feature selection and dimension reduction techniques.
Mitigating Presentation Attack using DCGAN and Deep CNN
Jun 22, 2022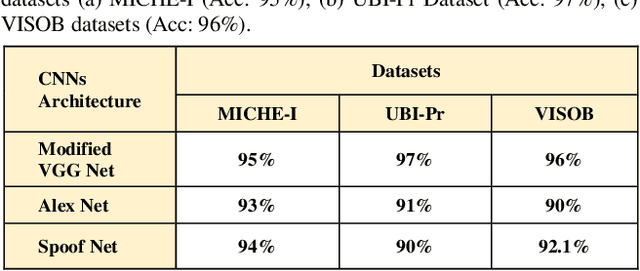
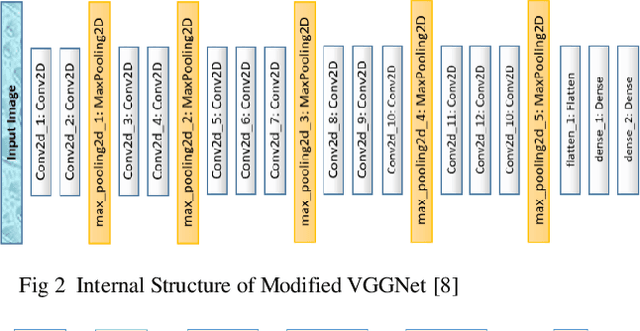
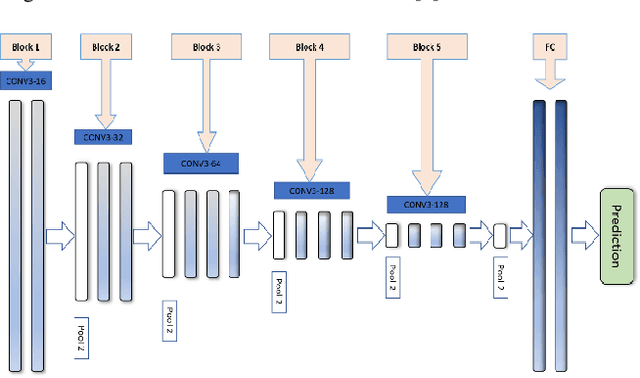
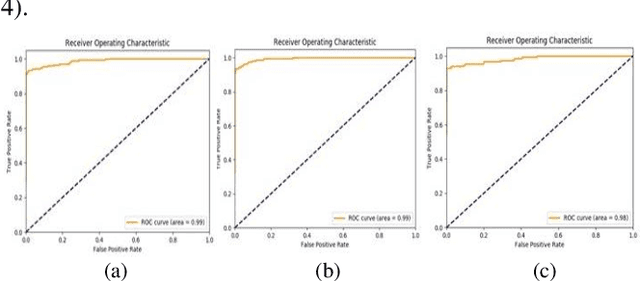
Biometric based authentication is currently playing an essential role over conventional authentication system; however, the risk of presentation attacks subsequently rising. Our research aims at identifying the areas where presentation attack can be prevented even though adequate biometric image samples of users are limited. Our work focusses on generating photorealistic synthetic images from the real image sets by implementing Deep Convolution Generative Adversarial Net (DCGAN). We have implemented the temporal and spatial augmentation during the fake image generation. Our work detects the presentation attacks on facial and iris images using our deep CNN, inspired by VGGNet [1]. We applied the deep neural net techniques on three different biometric image datasets, namely MICHE I [2], VISOB [3], and UBIPr [4]. The datasets, used in this research, contain images that are captured both in controlled and uncontrolled environment along with different resolutions and sizes. We obtained the best test accuracy of 97% on UBI-Pr [4] Iris datasets. For MICHE-I [2] and VISOB [3] datasets, we achieved the test accuracies of 95% and 96% respectively.
Building Korean Sign Language Augmentation (KoSLA) Corpus with Data Augmentation Technique
Jul 12, 2022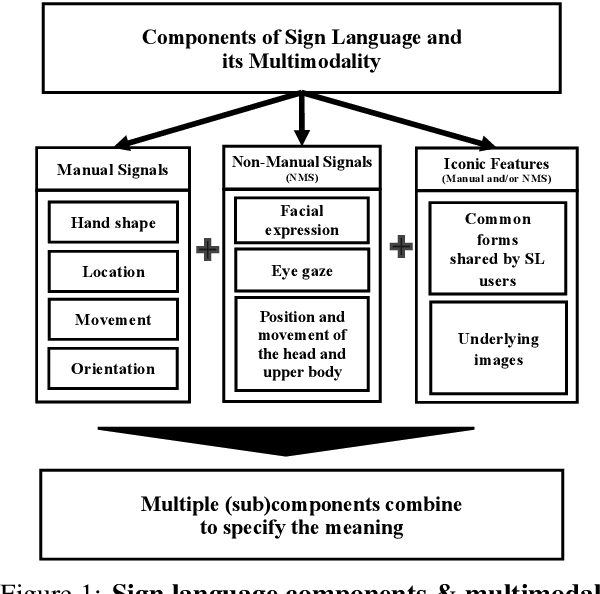

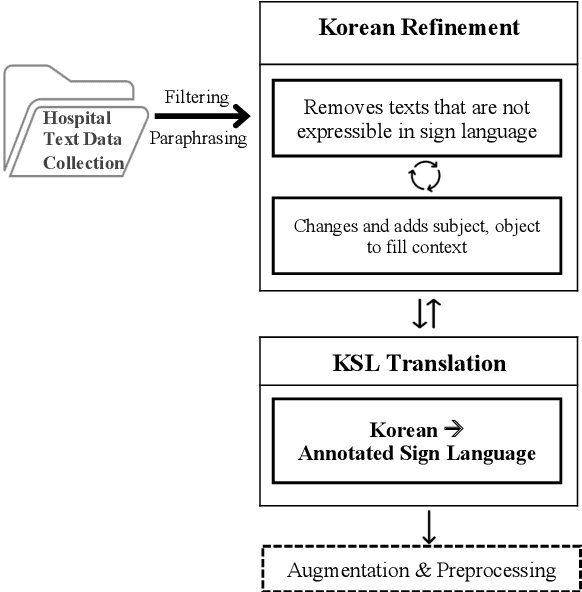
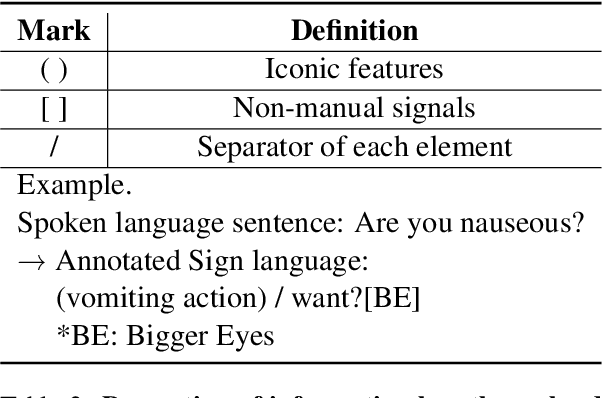
We present an efficient framework of corpus for sign language translation. Aided with a simple but dramatic data augmentation technique, our method converts text into annotated forms with minimum information loss. Sign languages are composed of manual signals, non-manual signals, and iconic features. According to professional sign language interpreters, non-manual signals such as facial expressions and gestures play an important role in conveying exact meaning. By considering the linguistic features of sign language, our proposed framework is a first and unique attempt to build a multimodal sign language augmentation corpus (hereinafter referred to as the KoSLA corpus) containing both manual and non-manual modalities. The corpus we built demonstrates confident results in the hospital context, showing improved performance with augmented datasets. To overcome data scarcity, we resorted to data augmentation techniques such as synonym replacement to boost the efficiency of our translation model and available data, while maintaining grammatical and semantic structures of sign language. For the experimental support, we verify the effectiveness of data augmentation technique and usefulness of our corpus by performing a translation task between normal sentences and sign language annotations on two tokenizers. The result was convincing, proving that the BLEU scores with the KoSLA corpus were significant.
TransPPG: Two-stream Transformer for Remote Heart Rate Estimate
Jan 26, 2022Non-contact facial video-based heart rate estimation using remote photoplethysmography (rPPG) has shown great potential in many applications (e.g., remote health care) and achieved creditable results in constrained scenarios. However, practical applications require results to be accurate even under complex environment with head movement and unstable illumination. Therefore, improving the performance of rPPG in complex environment has become a key challenge. In this paper, we propose a novel video embedding method that embeds each facial video sequence into a feature map referred to as Multi-scale Adaptive Spatial and Temporal Map with Overlap (MAST_Mop), which contains not only vital information but also surrounding information as reference, which acts as the mirror to figure out the homogeneous perturbations imposed on foreground and background simultaneously, such as illumination instability. Correspondingly, we propose a two-stream Transformer model to map the MAST_Mop into heart rate (HR), where one stream follows the pulse signal in the facial area while the other figures out the perturbation signal from the surrounding region such that the difference of the two channels leads to adaptive noise cancellation. Our approach significantly outperforms all current state-of-the-art methods on two public datasets MAHNOB-HCI and VIPL-HR. As far as we know, it is the first work with Transformer as backbone to capture the temporal dependencies in rPPGs and apply the two stream scheme to figure out the interference from backgrounds as mirror of the corresponding perturbation on foreground signals for noise tolerating.