 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Pre-Trained Convolutional Neural Network Features for Facial Expression Recognition
Dec 16, 2018


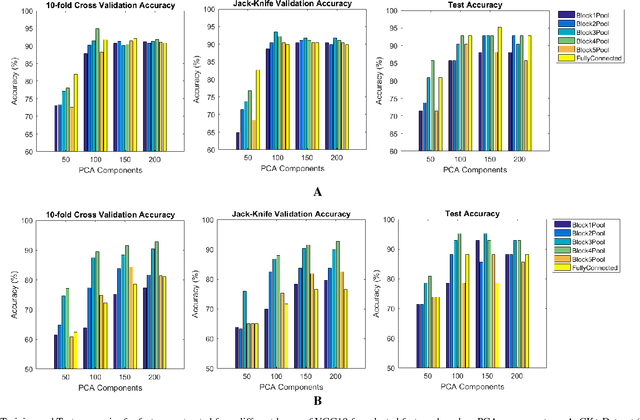
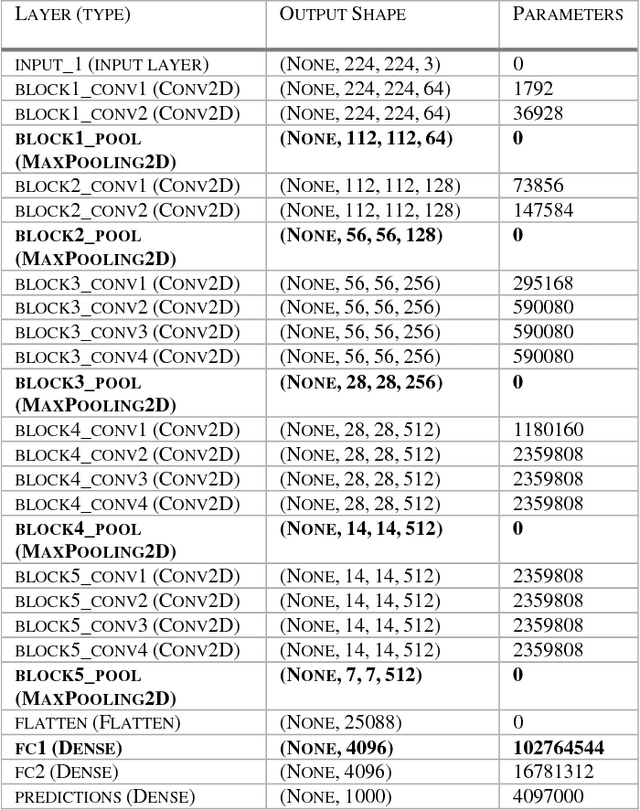
Facial expression recognition has been an active area in computer vision with application areas including animation, social robots, personalized banking, etc. In this study, we explore the problem of image classification for detecting facial expressions based on features extracted from pre-trained convolutional neural networks trained on ImageNet database. Features are extracted and transferred to a Linear Support Vector Machine for classification. All experiments are performed on two publicly available datasets such as JAFFE and CK+ database. The results show that representations learned from pre-trained networks for a task such as object recognition can be transferred, and used for facial expression recognition. Furthermore, for a small dataset, using features from earlier layers of the VGG19 network provides better classification accuracy. Accuracies of 92.26% and 92.86% were achieved for the CK+ and JAFFE datasets respectively.
Facial emotion recognition using min-max similarity classifier
Jan 01, 2018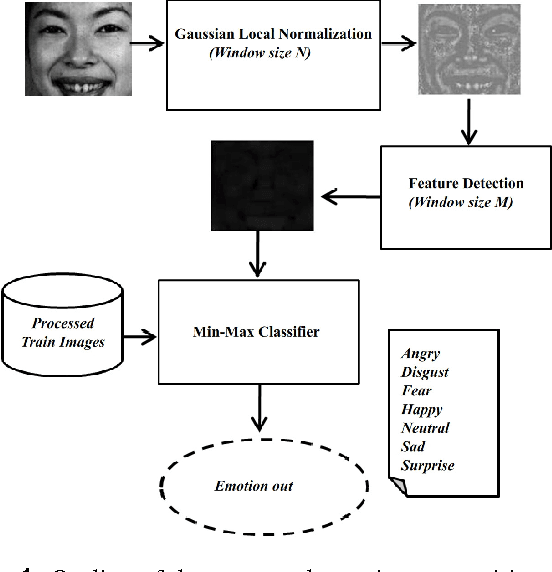


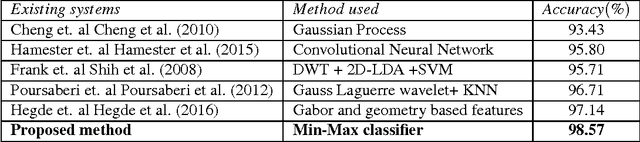
Recognition of human emotions from the imaging templates is useful in a wide variety of human-computer interaction and intelligent systems applications. However, the automatic recognition of facial expressions using image template matching techniques suffer from the natural variability with facial features and recording conditions. In spite of the progress achieved in facial emotion recognition in recent years, the effective and computationally simple feature selection and classification technique for emotion recognition is still an open problem. In this paper, we propose an efficient and straightforward facial emotion recognition algorithm to reduce the problem of inter-class pixel mismatch during classification. The proposed method includes the application of pixel normalization to remove intensity offsets followed-up with a Min-Max metric in a nearest neighbor classifier that is capable of suppressing feature outliers. The results indicate an improvement of recognition performance from 92.85% to 98.57% for the proposed Min-Max classification method when tested on JAFFE database. The proposed emotion recognition technique outperforms the existing template matching methods.
Exploring the pattern of Emotion in children with ASD as an early biomarker through Recurring-Convolution Neural Network (R-CNN)
Dec 30, 2021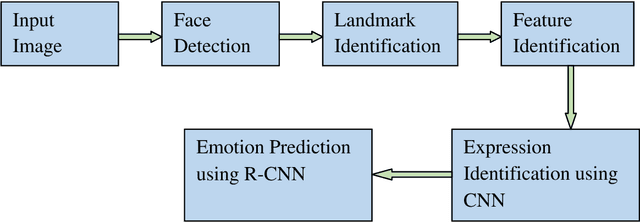
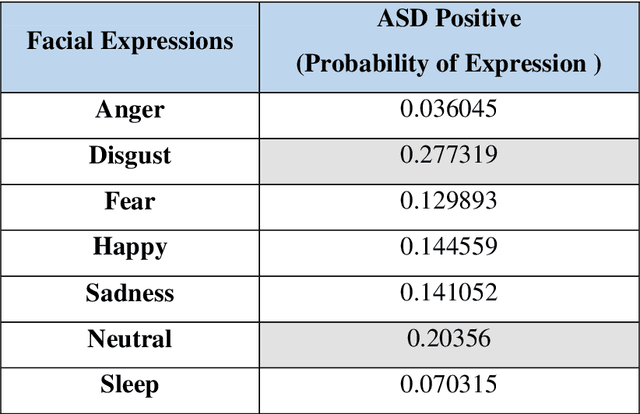
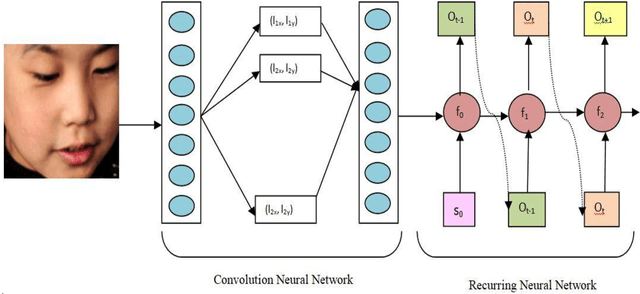
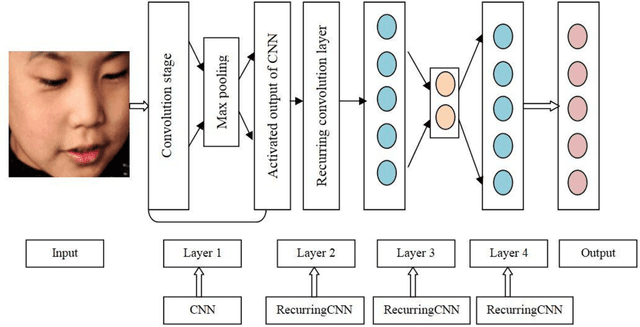
Autism Spectrum Disorder (ASD) is found to be a major concern among various occupational therapists. The foremost challenge of this neurodevelopmental disorder lies in the fact of analyzing and exploring various symptoms of the children at their early stage of development. Such early identification could prop up the therapists and clinicians to provide proper assistive support to make the children lead an independent life. Facial expressions and emotions perceived by the children could contribute to such early intervention of autism. In this regard, the paper implements in identifying basic facial expression and exploring their emotions upon a time variant factor. The emotions are analyzed by incorporating the facial expression identified through CNN using 68 landmark points plotted on the frontal face with a prediction network formed by RNN known as RCNN-FER system. The paper adopts R-CNN to take the advantage of increased accuracy and performance with decreased time complexity in predicting emotion as a textual network analysis. The papers proves better accuracy in identifying the emotion in autistic children when compared over simple machine learning models built for such identifications contributing to autistic society.
Bounded Residual Gradient Networks (BReG-Net) for Facial Affect Computing
Mar 05, 2019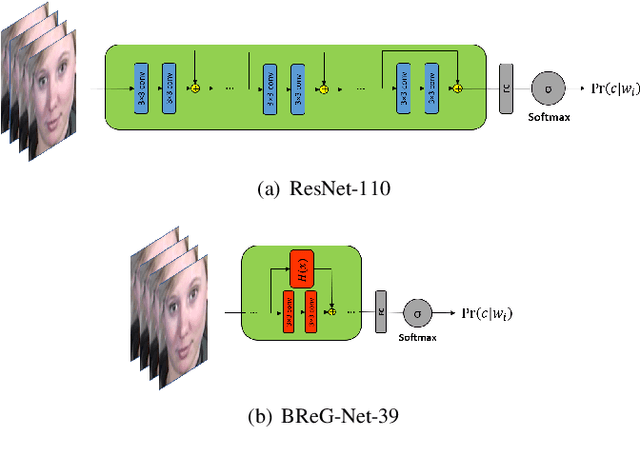
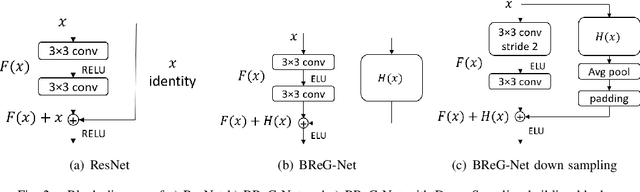
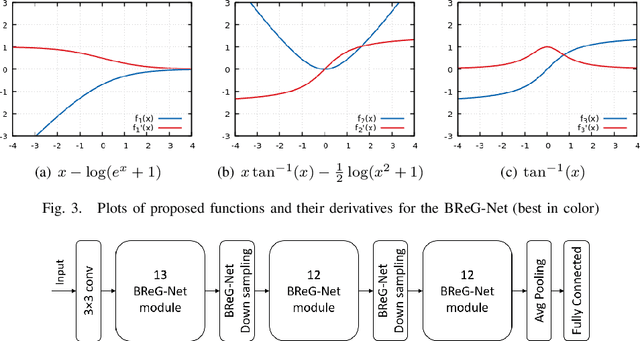
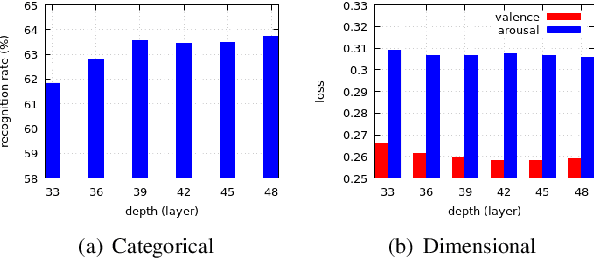
Residual-based neural networks have shown remarkable results in various visual recognition tasks including Facial Expression Recognition (FER). Despite the tremendous efforts have been made to improve the performance of FER systems using DNNs, existing methods are not generalizable enough for practical applications. This paper introduces Bounded Residual Gradient Networks (BReG-Net) for facial expression recognition, in which the shortcut connection between the input and the output of the ResNet module is replaced with a differentiable function with a bounded gradient. This configuration prevents the network from facing the vanishing or exploding gradient problem. We show that utilizing such non-linear units will result in shallower networks with better performance. Further, by using a weighted loss function which gives a higher priority to less represented categories, we can achieve an overall better recognition rate. The results of our experiments show that BReG-Nets outperform state-of-the-art methods on three publicly available facial databases in the wild, on both the categorical and dimensional models of affect.
Deepfake Detection for Facial Images with Facemasks
Feb 23, 2022
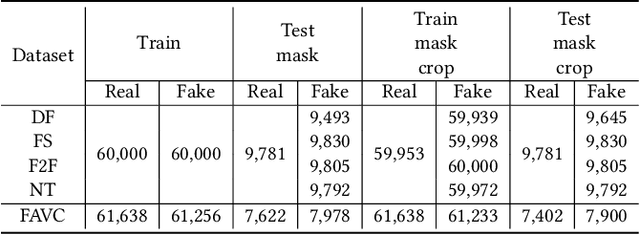
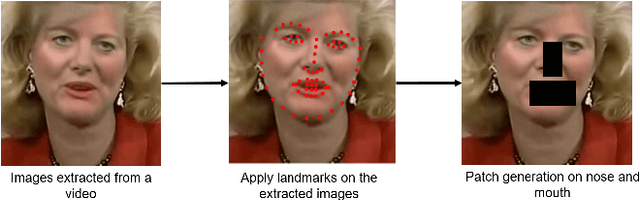
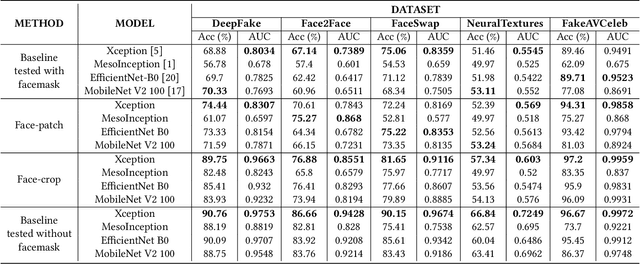
Hyper-realistic face image generation and manipulation have givenrise to numerous unethical social issues, e.g., invasion of privacy,threat of security, and malicious political maneuvering, which re-sulted in the development of recent deepfake detection methodswith the rising demands of deepfake forensics. Proposed deepfakedetection methods to date have shown remarkable detection perfor-mance and robustness. However, none of the suggested deepfakedetection methods assessed the performance of deepfakes withthe facemask during the pandemic crisis after the outbreak of theCovid-19. In this paper, we thoroughly evaluate the performance ofstate-of-the-art deepfake detection models on the deepfakes withthe facemask. Also, we propose two approaches to enhance themasked deepfakes detection:face-patchandface-crop. The experi-mental evaluations on both methods are assessed through the base-line deepfake detection models on the various deepfake datasets.Our extensive experiments show that, among the two methods,face-cropperforms better than theface-patch, and could be a trainmethod for deepfake detection models to detect fake faces withfacemask in real world.
Learning to Generate Facial Depth Maps
May 30, 2018
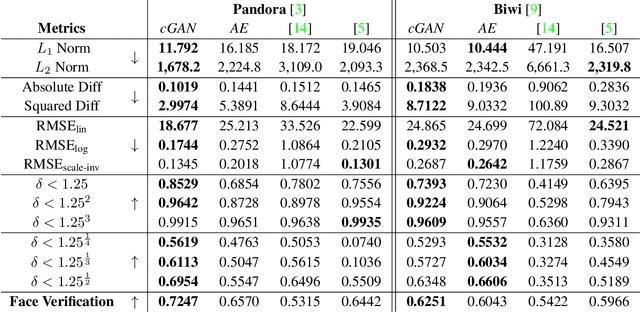
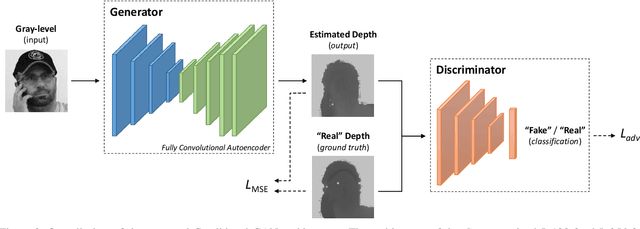

In this paper, an adversarial architecture for facial depth map estimation from monocular intensity images is presented. By following an image-to-image approach, we combine the advantages of supervised learning and adversarial training, proposing a conditional Generative Adversarial Network that effectively learns to translate intensity face images into the corresponding depth maps. Two public datasets, namely Biwi database and Pandora dataset, are exploited to demonstrate that the proposed model generates high-quality synthetic depth images, both in terms of visual appearance and informative content. Furthermore, we show that the model is capable of predicting distinctive facial details by testing the generated depth maps through a deep model trained on authentic depth maps for the face verification task.
Feature Super-Resolution Based Facial Expression Recognition for Multi-scale Low-Resolution Faces
Apr 05, 2020
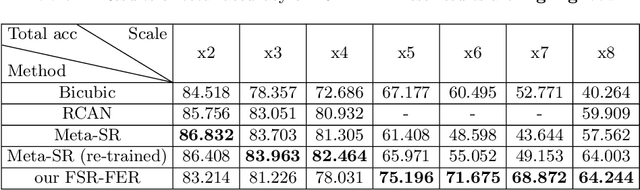
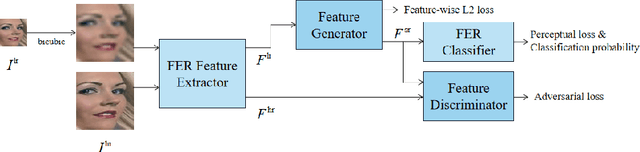
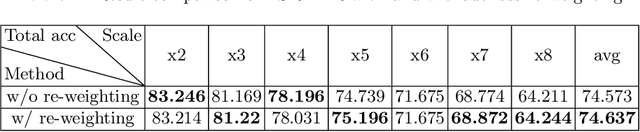
Facial Expressions Recognition(FER) on low-resolution images is necessary for applications like group expression recognition in crowd scenarios(station, classroom etc.). Classifying a small size facial image into the right expression category is still a challenging task. The main cause of this problem is the loss of discriminative feature due to reduced resolution. Super-resolution method is often used to enhance low-resolution images, but the performance on FER task is limited when on images of very low resolution. In this work, inspired by feature super-resolution methods for object detection, we proposed a novel generative adversary network-based feature level super-resolution method for robust facial expression recognition(FSR-FER). In particular, a pre-trained FER model was employed as feature extractor, and a generator network G and a discriminator network D are trained with features extracted from images of low resolution and original high resolution. Generator network G tries to transform features of low-resolution images to more discriminative ones by making them closer to the ones of corresponding high-resolution images. For better classification performance, we also proposed an effective classification-aware loss re-weighting strategy based on the classification probability calculated by a fixed FER model to make our model focus more on samples that are easily misclassified. Experiment results on Real-World Affective Faces (RAF) Database demonstrate that our method achieves satisfying results on various down-sample factors with a single model and has better performance on low-resolution images compared with methods using image super-resolution and expression recognition separately.
Efficient Facial Feature Learning with Wide Ensemble-based Convolutional Neural Networks
Jan 17, 2020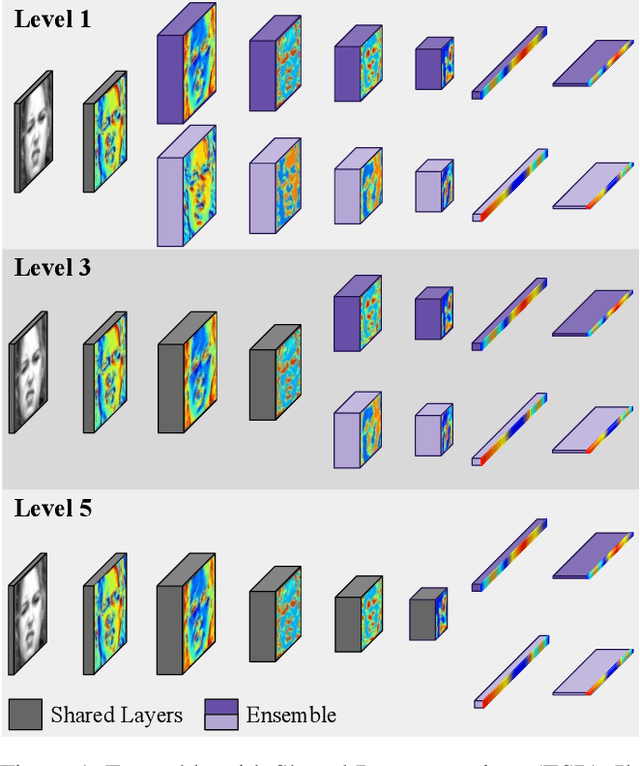
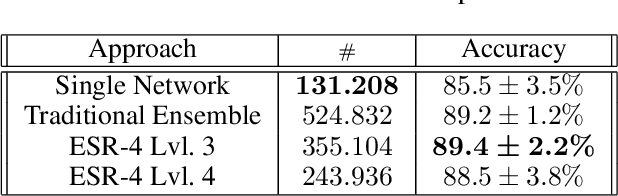
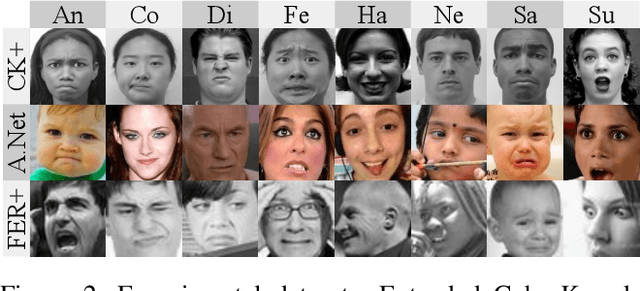
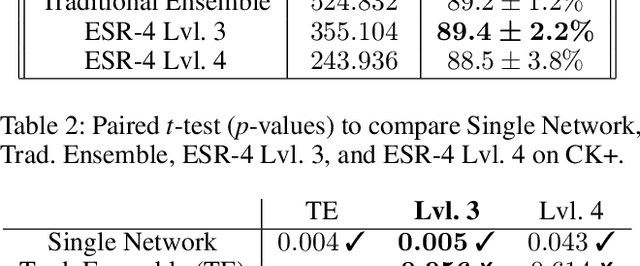
Ensemble methods, traditionally built with independently trained de-correlated models, have proven to be efficient methods for reducing the remaining residual generalization error, which results in robust and accurate methods for real-world applications. In the context of deep learning, however, training an ensemble of deep networks is costly and generates high redundancy which is inefficient. In this paper, we present experiments on Ensembles with Shared Representations (ESRs) based on convolutional networks to demonstrate, quantitatively and qualitatively, their data processing efficiency and scalability to large-scale datasets of facial expressions. We show that redundancy and computational load can be dramatically reduced by varying the branching level of the ESR without loss of diversity and generalization power, which are both important for ensemble performance. Experiments on large-scale datasets suggest that ESRs reduce the remaining residual generalization error on the AffectNet and FER+ datasets, reach human-level performance, and outperform state-of-the-art methods on facial expression recognition in the wild using emotion and affect concepts.
THIN: THrowable Information Networks and Application for Facial Expression Recognition In The Wild
Oct 15, 2020

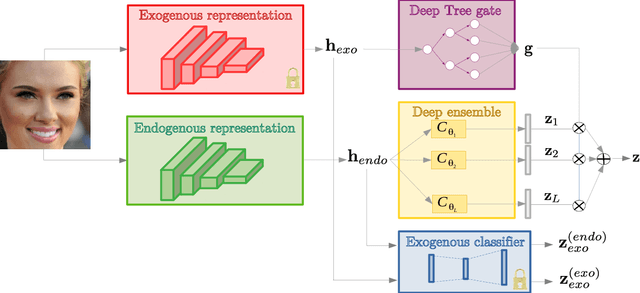
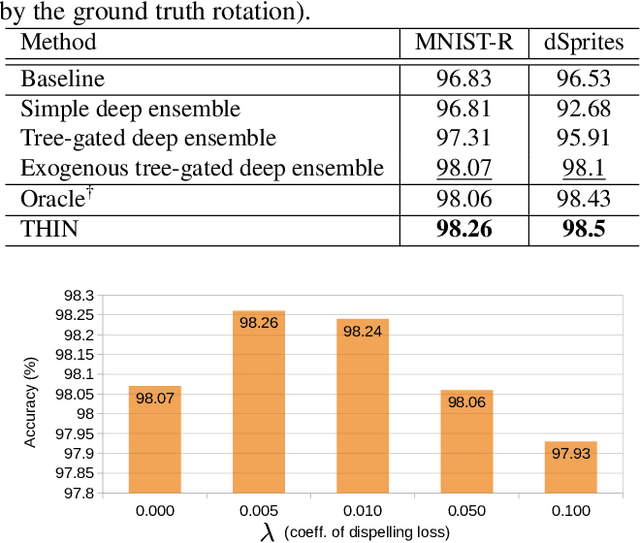
For a number of tasks solved using deep learning techniques, an exogenous variable can be identified such that (a) it heavily influences the appearance of the different classes, and (b) an ideal classifier should be invariant to this variable. An example of such exogenous variable is identity if facial expression recognition (FER) is considered. In this paper, we propose a dual exogenous/endogenous representation. The former captures the exogenous variable whereas the second one models the task at hand (e.g. facial expression). We design a prediction layer that uses a deep ensemble conditioned by the exogenous representation. It employs a differential tree gate that learns an adaptive weak predictor weighting, therefore modeling a partition of the exogenous representation space, upon which the weak predictors specialize. This layer explicitly models the dependency between the exogenous variable and the predicted task (a). We also propose an exogenous dispelling loss to remove the exogenous information from the endogenous representation, enforcing (b). Thus, the exogenous information is used two times in a throwable fashion, first as a conditioning variable for the target task, and second to create invariance within the endogenous representation. We call this method THIN, standing for THrowable Information Networks. We experimentally validate THIN in several contexts where an exogenous information can be identified, such as digit recognition under large rotations and shape recognition at multiple scales. We also apply it to FER with identity as the exogenous variable. In particular, we demonstrate that THIN significantly outperforms state-of-the-art approaches on several challenging datasets.
Multi-Region Ensemble Convolutional Neural Network for Facial Expression Recognition
Jul 12, 2018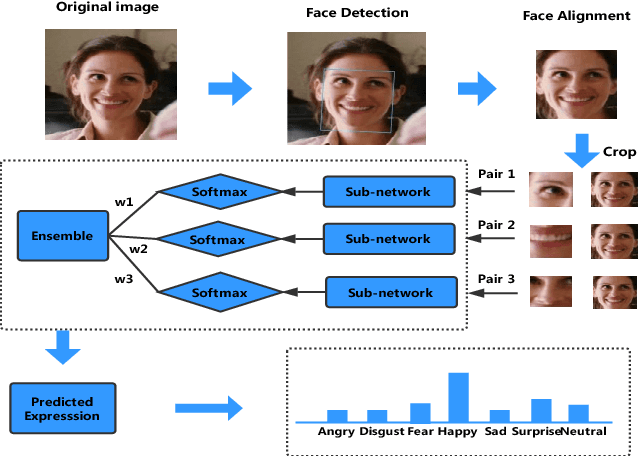
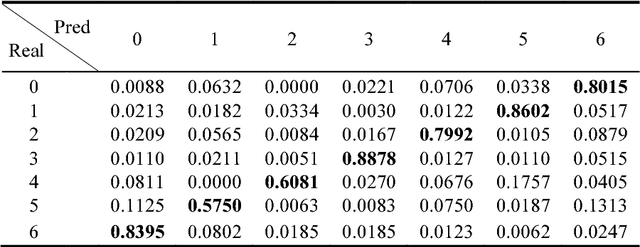

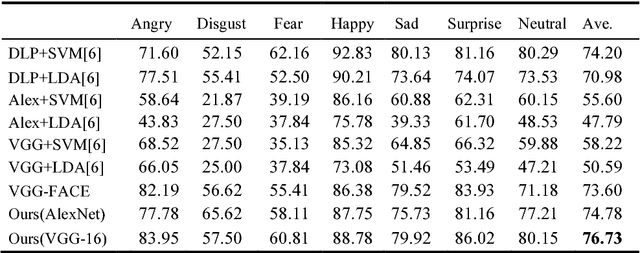
Facial expressions play an important role in conveying the emotional states of human beings. Recently, deep learning approaches have been applied to image recognition field due to the discriminative power of Convolutional Neural Network (CNN). In this paper, we first propose a novel Multi-Region Ensemble CNN (MRE-CNN) framework for facial expression recognition, which aims to enhance the learning power of CNN models by capturing both the global and the local features from multiple human face sub-regions. Second, the weighted prediction scores from each sub-network are aggregated to produce the final prediction of high accuracy. Third, we investigate the effects of different sub-regions of the whole face on facial expression recognition. Our proposed method is evaluated based on two well-known publicly available facial expression databases: AFEW 7.0 and RAF-DB, and has been shown to achieve the state-of-the-art recognition accuracy.