 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Multibias-mitigated and Sentiment Knowledge Enriched Transformer for Debiasing in Multimodal Conversational Emotion Recognition
Jul 17, 2022
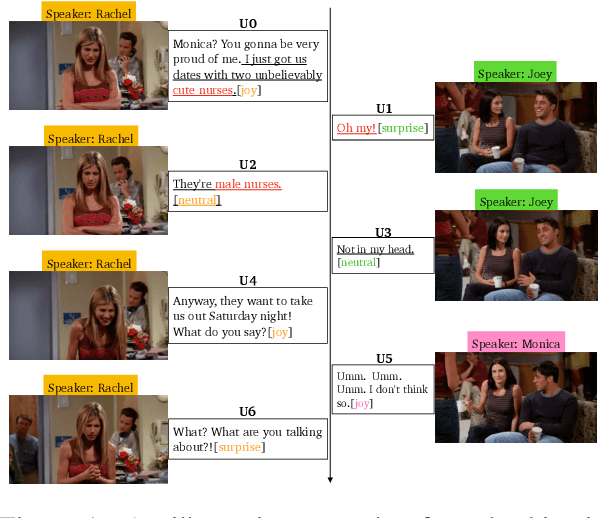

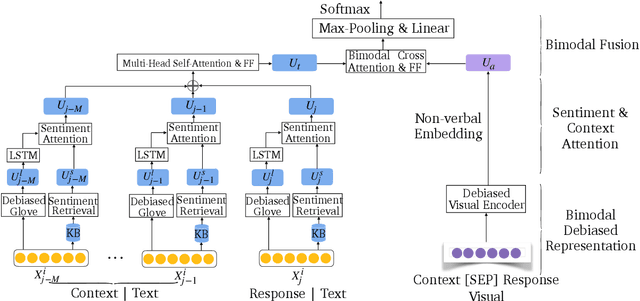
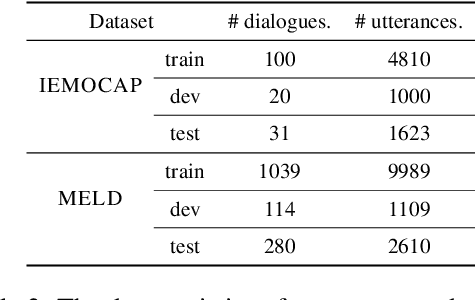
Multimodal emotion recognition in conversations (mERC) is an active research topic in natural language processing (NLP), which aims to predict human's emotional states in communications of multiple modalities, e,g., natural language and facial gestures. Innumerable implicit prejudices and preconceptions fill human language and conversations, leading to the question of whether the current data-driven mERC approaches produce a biased error. For example, such approaches may offer higher emotional scores on the utterances by females than males. In addition, the existing debias models mainly focus on gender or race, where multibias mitigation is still an unexplored task in mERC. In this work, we take the first step to solve these issues by proposing a series of approaches to mitigate five typical kinds of bias in textual utterances (i.e., gender, age, race, religion and LGBTQ+) and visual representations (i.e, gender and age), followed by a Multibias-Mitigated and sentiment Knowledge Enriched bi-modal Transformer (MMKET). Comprehensive experimental results show the effectiveness of the proposed model and prove that the debias operation has a great impact on the classification performance for mERC. We hope our study will benefit the development of bias mitigation in mERC and related emotion studies.
Hierarchical Vectorization for Portrait Images
May 24, 2022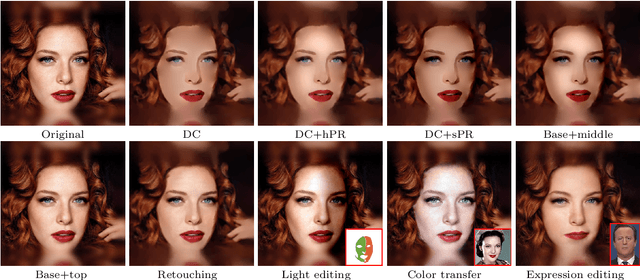
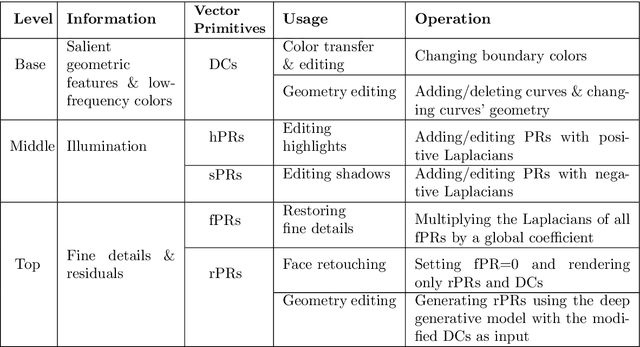
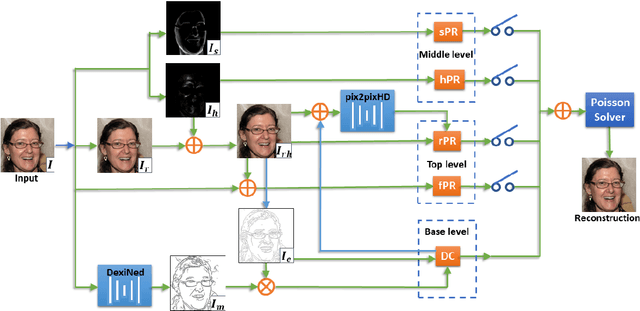
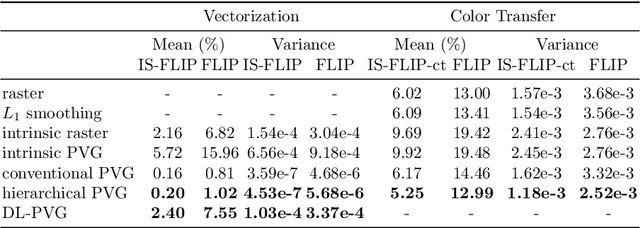
Aiming at developing intuitive and easy-to-use portrait editing tools, we propose a novel vectorization method that can automatically convert raster images into a 3-tier hierarchical representation. The base layer consists of a set of sparse diffusion curves (DC) which characterize salient geometric features and low-frequency colors and provide means for semantic color transfer and facial expression editing. The middle level encodes specular highlights and shadows to large and editable Poisson regions (PR) and allows the user to directly adjust illumination via tuning the strength and/or changing shape of PR. The top level contains two types of pixel-sized PRs for high-frequency residuals and fine details such as pimples and pigmentation. We also train a deep generative model that can produce high-frequency residuals automatically. Thanks to the meaningful organization of vector primitives, editing portraits becomes easy and intuitive. In particular, our method supports color transfer, facial expression editing, highlight and shadow editing and automatic retouching. Thanks to the linearity of the Laplace operator, we introduce alpha blending, linear dodge and linear burn to vector editing and show that they are effective in editing highlights and shadows. To quantitatively evaluate the results, we extend the commonly used FLIP metric (which measures differences between two images) by considering illumination. The new metric, called illumination-sensitive FLIP or IS-FLIP, can effectively capture the salient changes in color transfer results, and is more consistent with human perception than FLIP and other quality measures on portrait images. We evaluate our method on the FFHQR dataset and show that our method is effective for common portrait editing tasks, such as retouching, light editing, color transfer and expression editing. We will make the code and trained models publicly available.
Assessing Privacy Risks from Feature Vector Reconstruction Attacks
Feb 11, 2022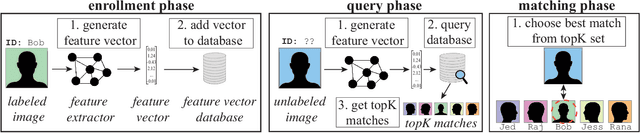
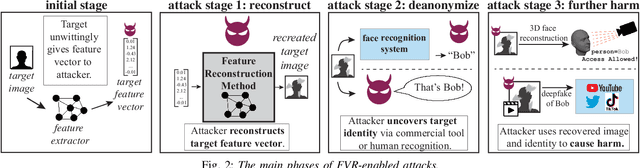

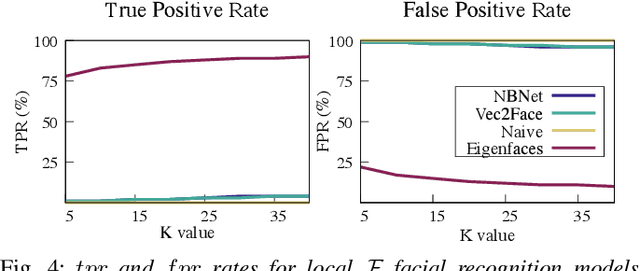
In deep neural networks for facial recognition, feature vectors are numerical representations that capture the unique features of a given face. While it is known that a version of the original face can be recovered via "feature reconstruction," we lack an understanding of the end-to-end privacy risks produced by these attacks. In this work, we address this shortcoming by developing metrics that meaningfully capture the threat of reconstructed face images. Using end-to-end experiments and user studies, we show that reconstructed face images enable re-identification by both commercial facial recognition systems and humans, at a rate that is at worst, a factor of four times higher than randomized baselines. Our results confirm that feature vectors should be recognized as Personal Identifiable Information (PII) in order to protect user privacy.
AnyFace: Free-style Text-to-Face Synthesis and Manipulation
Mar 29, 2022
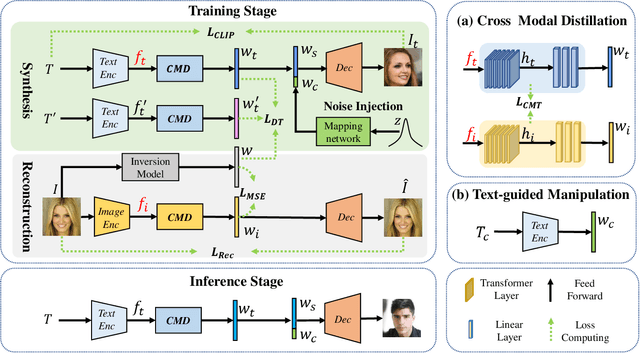
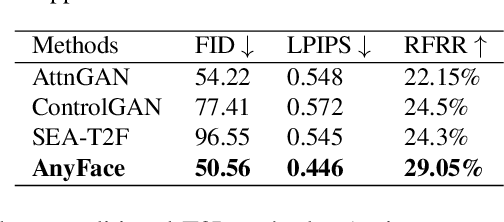
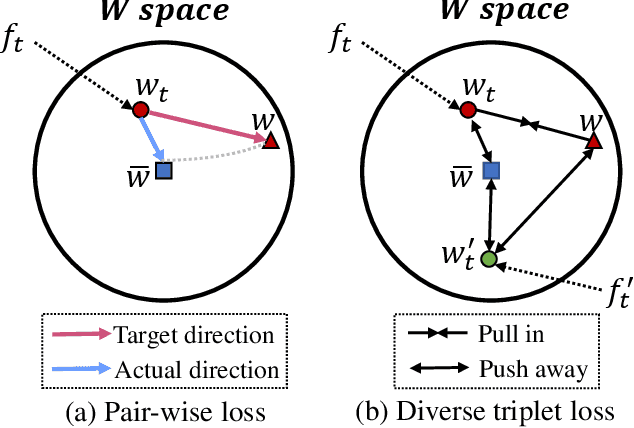
Existing text-to-image synthesis methods generally are only applicable to words in the training dataset. However, human faces are so variable to be described with limited words. So this paper proposes the first free-style text-to-face method namely AnyFace enabling much wider open world applications such as metaverse, social media, cosmetics, forensics, etc. AnyFace has a novel two-stream framework for face image synthesis and manipulation given arbitrary descriptions of the human face. Specifically, one stream performs text-to-face generation and the other conducts face image reconstruction. Facial text and image features are extracted using the CLIP (Contrastive Language-Image Pre-training) encoders. And a collaborative Cross Modal Distillation (CMD) module is designed to align the linguistic and visual features across these two streams. Furthermore, a Diverse Triplet Loss (DT loss) is developed to model fine-grained features and improve facial diversity. Extensive experiments on Multi-modal CelebA-HQ and CelebAText-HQ demonstrate significant advantages of AnyFace over state-of-the-art methods. AnyFace can achieve high-quality, high-resolution, and high-diversity face synthesis and manipulation results without any constraints on the number and content of input captions.
Two-stage Temporal Modelling Framework for Video-based Depression Recognition using Graph Representation
Nov 30, 2021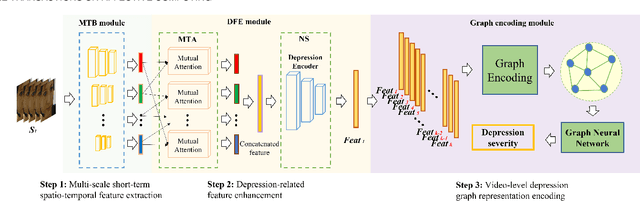
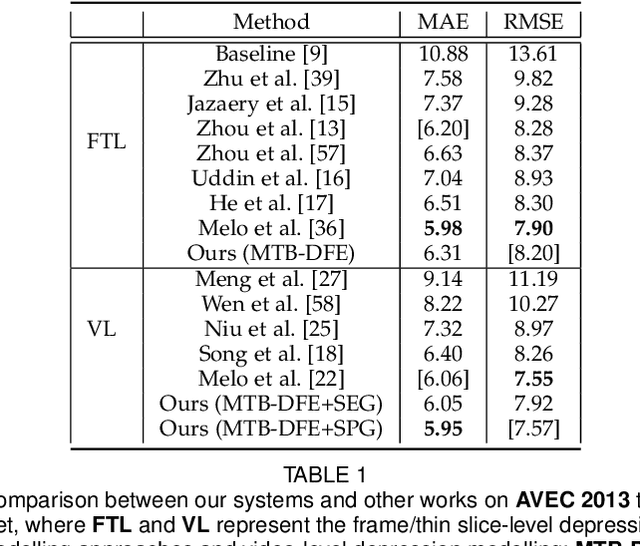
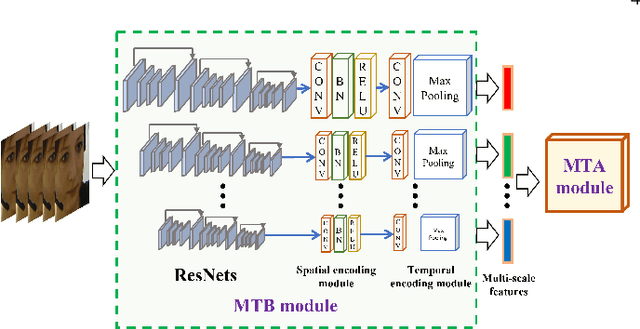
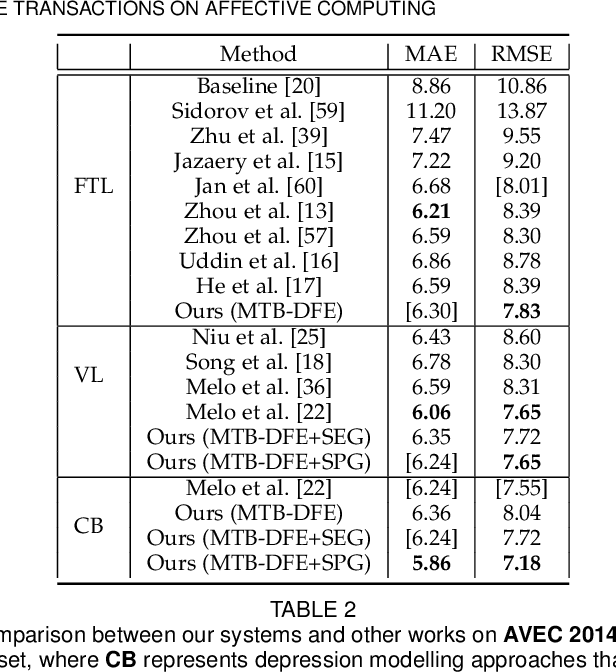
Video-based automatic depression analysis provides a fast, objective and repeatable self-assessment solution, which has been widely developed in recent years. While depression clues may be reflected by human facial behaviours of various temporal scales, most existing approaches either focused on modelling depression from short-term or video-level facial behaviours. In this sense, we propose a two-stage framework that models depression severity from multi-scale short-term and video-level facial behaviours. The short-term depressive behaviour modelling stage first deep learns depression-related facial behavioural features from multiple short temporal scales, where a Depression Feature Enhancement (DFE) module is proposed to enhance the depression-related clues for all temporal scales and remove non-depression noises. Then, the video-level depressive behaviour modelling stage proposes two novel graph encoding strategies, i.e., Sequential Graph Representation (SEG) and Spectral Graph Representation (SPG), to re-encode all short-term features of the target video into a video-level graph representation, summarizing depression-related multi-scale video-level temporal information. As a result, the produced graph representations predict depression severity using both short-term and long-term facial beahviour patterns. The experimental results on AVEC 2013 and AVEC 2014 datasets show that the proposed DFE module constantly enhanced the depression severity estimation performance for various CNN models while the SPG is superior than other video-level modelling methods. More importantly, the result achieved for the proposed two-stage framework shows its promising and solid performance compared to widely-used one-stage modelling approaches.
Deep Multi-Facial patches Aggregation Network for Expression Classification from Face Images
Sep 23, 2019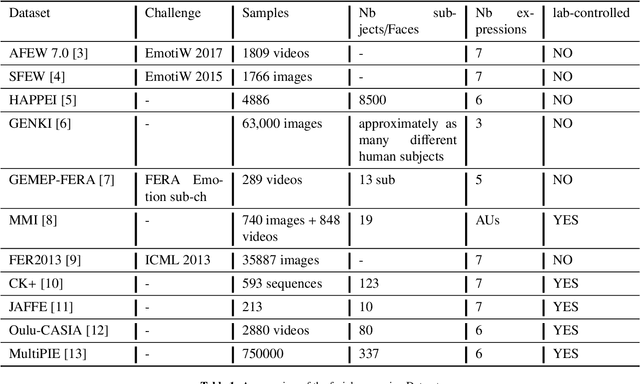
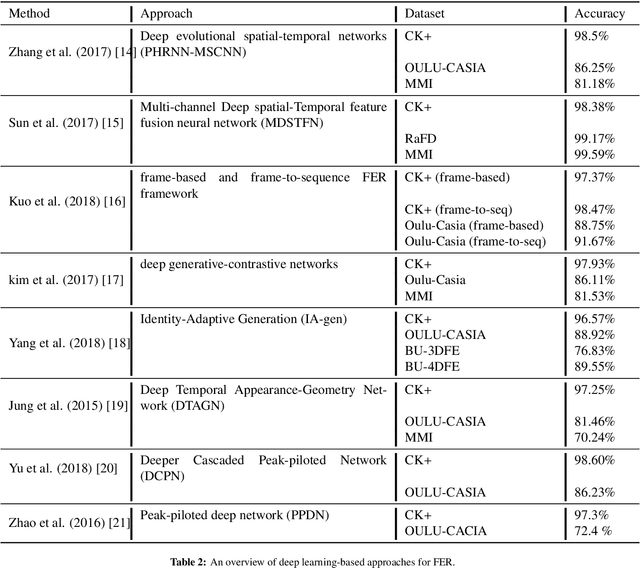
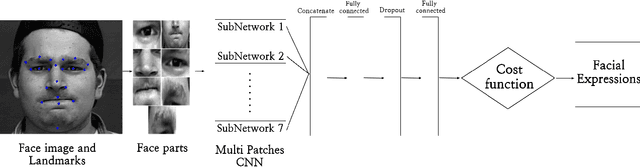
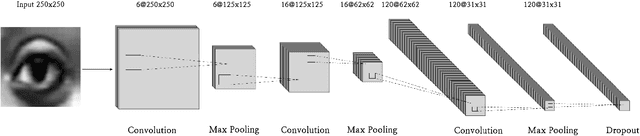
Emotional Intelligence in Human-Computer Interaction has attracted increasing attention from researchers in multidisciplinary research fields including psychology, computer vision, neuroscience, artificial intelligence, and related disciplines. Human prone to naturally interact with computers face-to-face. Human Expressions is an important key to better link human and computers. Thus, designing interfaces able to understand human expressions and emotions can improve Human-Computer Interaction (HCI) for better communication. In this paper, we investigate HCI via a deep multi-facial patches aggregation network for Face Expression Recognition (FER). Deep features are extracted from facial parts and aggregated for expression classification. Several problems may affect the performance of the proposed framework like the small size of FER datasets and the high number of parameters to learn. For That, two data augmentation techniques are proposed for facial expression generation to expand the labeled training. The proposed framework is evaluated on the extended Cohn-Konade dataset (CK+) and promising results are achieved.
Synthesising 3D Facial Motion from "In-the-Wild" Speech
Apr 15, 2019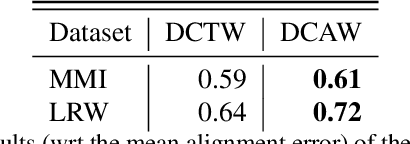
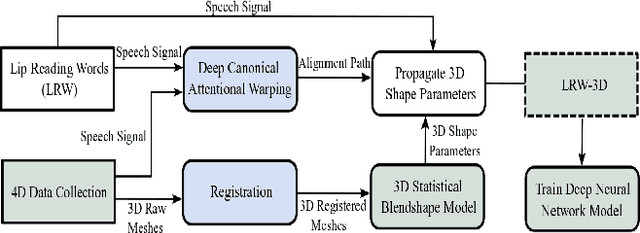

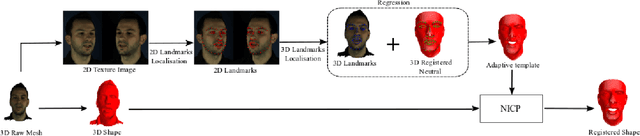
Synthesising 3D facial motion from speech is a crucial problem manifesting in a multitude of applications such as computer games and movies. Recently proposed methods tackle this problem in controlled conditions of speech. In this paper, we introduce the first methodology for 3D facial motion synthesis from speech captured in arbitrary recording conditions ("in-the-wild") and independent of the speaker. For our purposes, we captured 4D sequences of people uttering 500 words, contained in the Lip Reading Words (LRW) a publicly available large-scale in-the-wild dataset, and built a set of 3D blendshapes appropriate for speech. We correlate the 3D shape parameters of the speech blendshapes to the LRW audio samples by means of a novel time-warping technique, named Deep Canonical Attentional Warping (DCAW), that can simultaneously learn hierarchical non-linear representations and a warping path in an end-to-end manner. We thoroughly evaluate our proposed methods, and show the ability of a deep learning model to synthesise 3D facial motion in handling different speakers and continuous speech signals in uncontrolled conditions.
Revisiting Few-Shot Learning for Facial Expression Recognition
Dec 05, 2019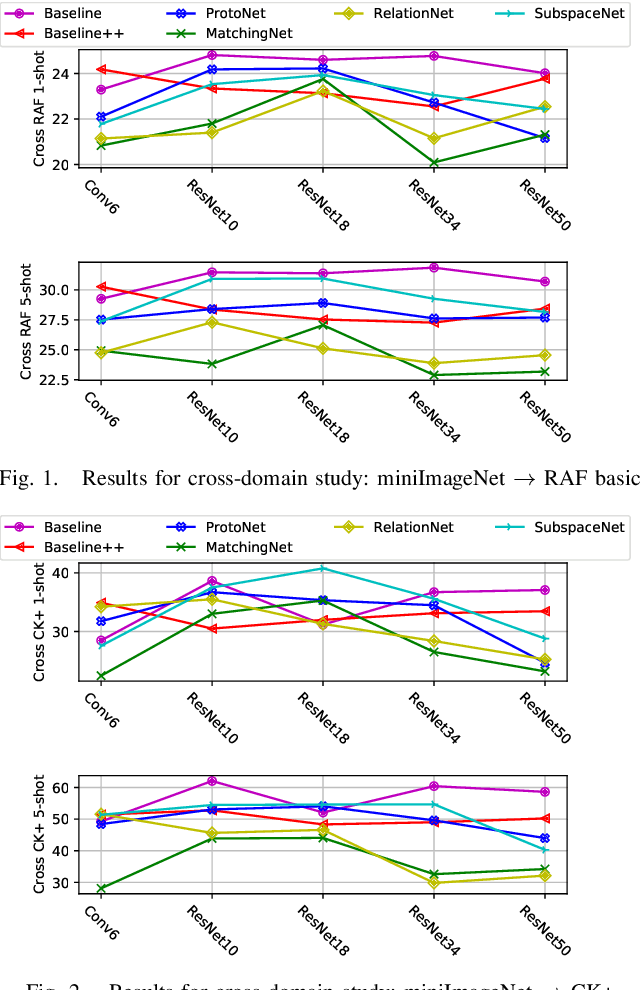
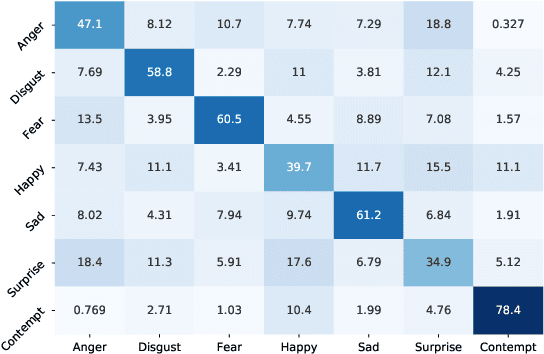
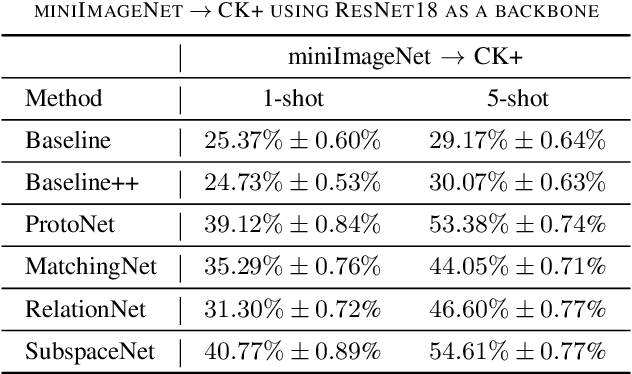
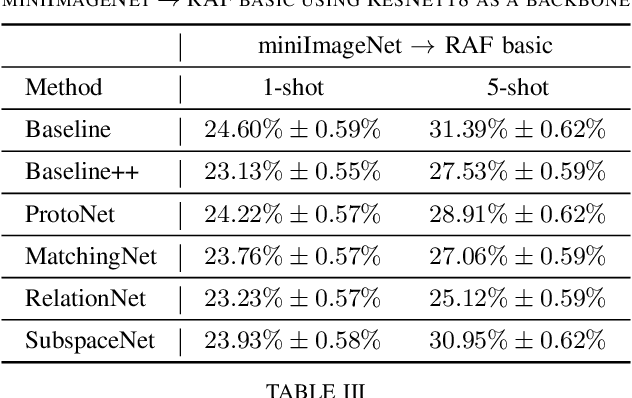
Most of the existing deep neural nets on automatic facial expression recognition focus on a set of predefined emotion classes, where the amount of training data has the biggest impact on performance. However, over-parameterised neural networks are not amenable for learning from few samples as they can quickly over-fit. In addition, these approaches do not have such a strong generalisation ability to identify a new category, where the data of each category is too limited and significant variations exist in the expression within the same semantic category. We embrace these challenges and formulate the problem as a low-shot learning, where once the base classifier is deployed, it must rapidly adapt to recognise novel classes using a few samples. In this paper, we revisit and compare existing few-shot learning methods for the low-shot facial expression recognition in terms of their generalisation ability via episode-training. In particular, we extend our analysis on the cross-domain generalisation, where training and test tasks are not drawn from the same distribution. We demonstrate the efficacy of low-shot learning methods through extensive experiments.
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 05, 2019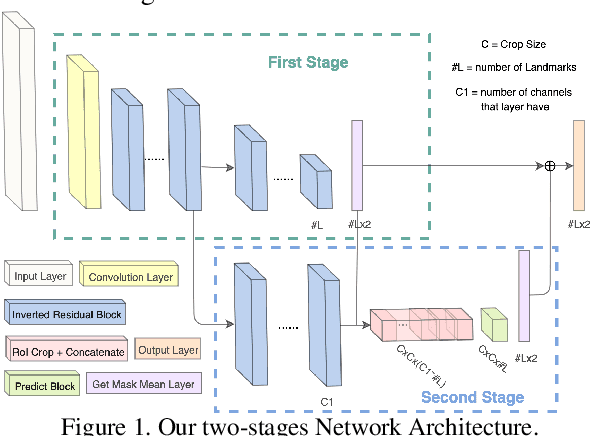

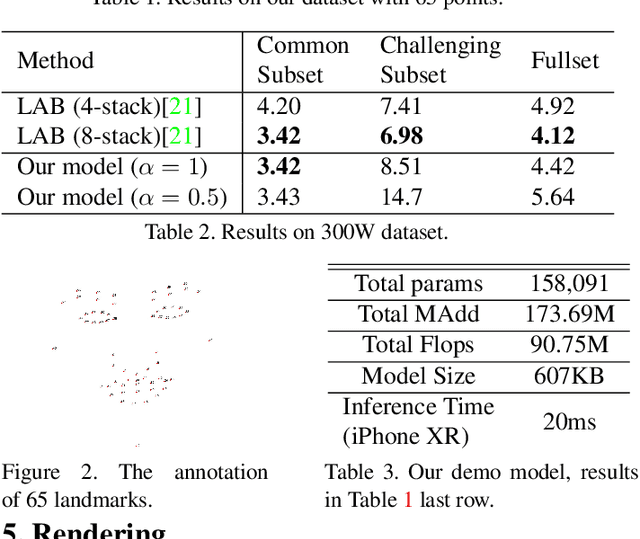
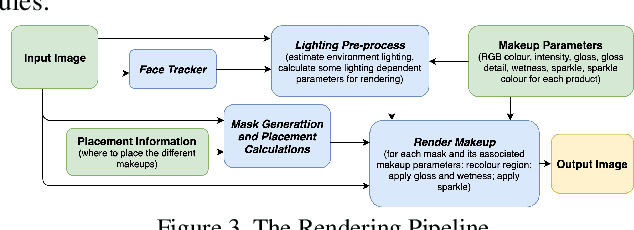
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. We prepared a demo link to our Web demo that can be tested in Chrome and Firefox on Android, or in Safari on iOS: https://s3.amazonaws.com/makeup-paper-demo/index.html
Pose-adaptive Hierarchical Attention Network for Facial Expression Recognition
May 24, 2019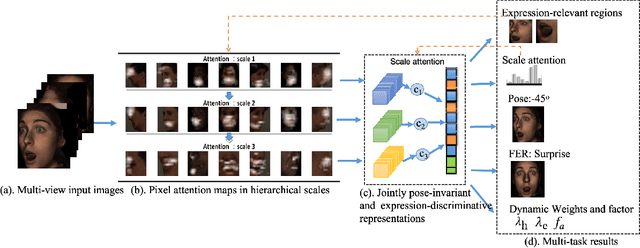


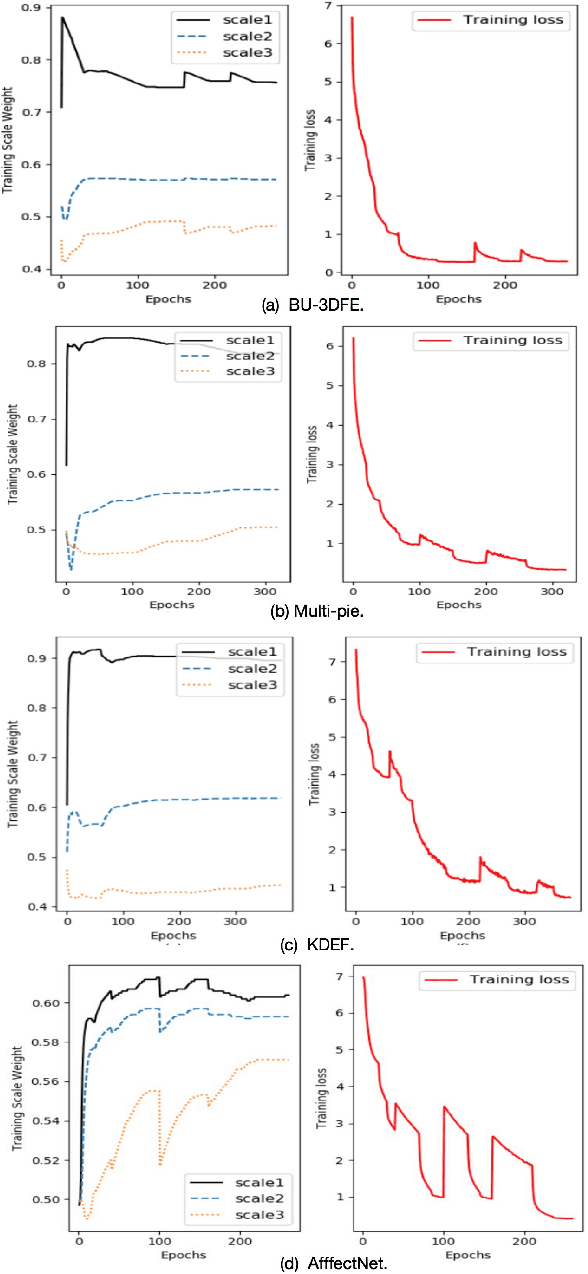
Multi-view facial expression recognition (FER) is a challenging task because the appearance of an expression varies in poses. To alleviate the influences of poses, recent methods either perform pose normalization or learn separate FER classifiers for each pose. However, these methods usually have two stages and rely on good performance of pose estimators. Different from existing methods, we propose a pose-adaptive hierarchical attention network (PhaNet) that can jointly recognize the facial expressions and poses in unconstrained environment. Specifically, PhaNet discovers the most relevant regions to the facial expression by an attention mechanism in hierarchical scales, and the most informative scales are then selected to learn the pose-invariant and expression-discriminative representations. PhaNet is end-to-end trainable by minimizing the hierarchical attention losses, the FER loss and pose loss with dynamically learned loss weights. We validate the effectiveness of the proposed PhaNet on three multi-view datasets (BU-3DFE, Multi-pie, and KDEF) and two in-the-wild FER datasets (AffectNet and SFEW). Extensive experiments demonstrate that our framework outperforms the state-of-the-arts under both within-dataset and cross-dataset settings, achieving the average accuracies of 84.92\%, 93.53\%, 88.5\%, 54.82\% and 31.25\% respectively.