 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Demographic Attribute Guided Approach to Age Estimation
May 20, 2022
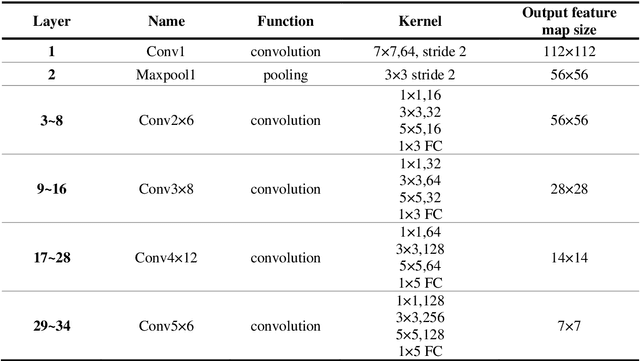
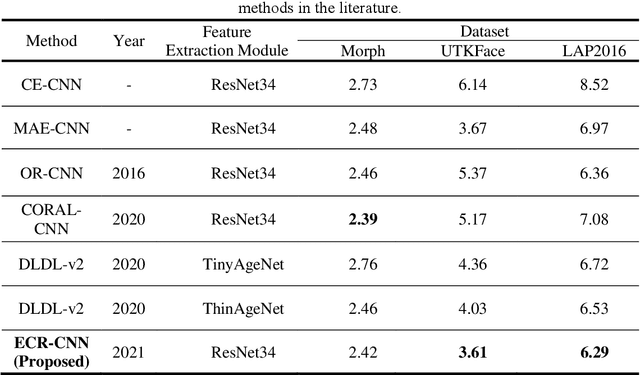
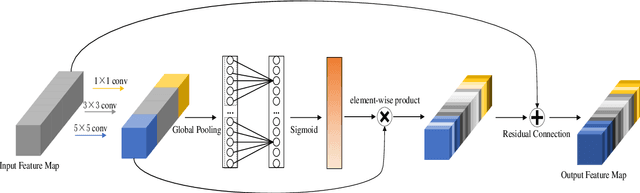
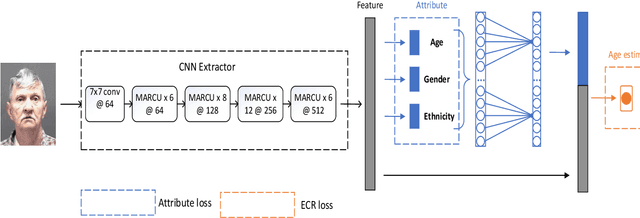
Face-based age estimation has attracted enormous attention due to wide applications to public security surveillance, human-computer interaction, etc. With vigorous development of deep learning, age estimation based on deep neural network has become the mainstream practice. However, seeking a more suitable problem paradigm for age change characteristics, designing the corresponding loss function and designing a more effective feature extraction module still needs to be studied. What is more, change of face age is also related to demographic attributes such as ethnicity and gender, and the dynamics of different age groups is also quite different. This problem has so far not been paid enough attention to. How to use demographic attribute information to improve the performance of age estimation remains to be further explored. In light of these issues, this research makes full use of auxiliary information of face attributes and proposes a new age estimation approach with an attribute guidance module. We first design a multi-scale attention residual convolution unit (MARCU) to extract robust facial features other than simply using other standard feature modules such as VGG and ResNet. Then, after being especially treated through full connection (FC) layers, the facial demographic attributes are weight-summed by 1*1 convolutional layer and eventually merged with the age features by a global FC layer. Lastly, we propose a new error compression ranking (ECR) loss to better converge the age regression value. Experimental results on three public datasets of UTKFace, LAP2016 and Morph show that our proposed approach achieves superior performance compared to other state-of-the-art methods.
Mugeetion: Musical Interface Using Facial Gesture and Emotion
Oct 07, 2018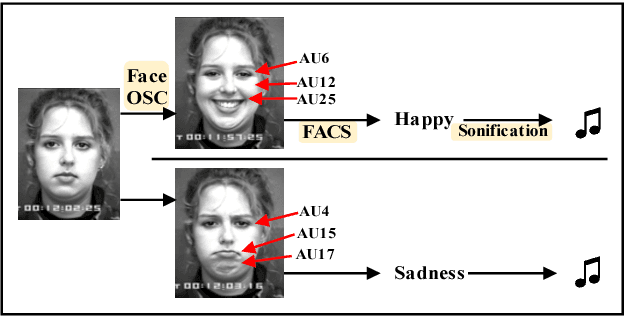
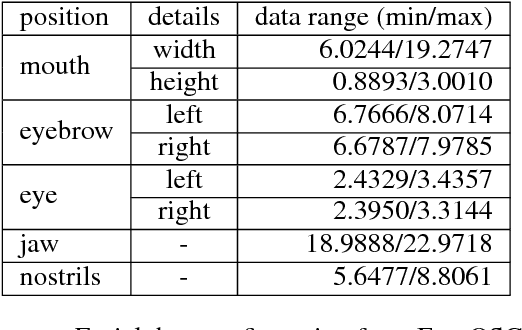
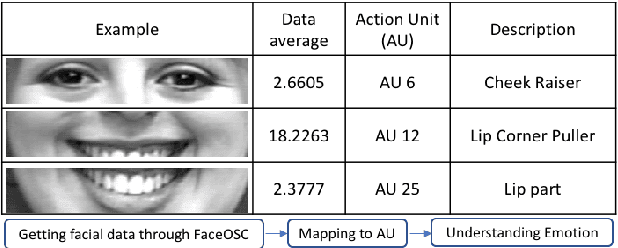

People feel emotions when listening to music. However, emotions are not tangible objects that can be exploited in the music composition process as they are difficult to capture and quantify in algorithms. We present a novel musical interface, Mugeetion, designed to capture occurring instances of emotional states from users' facial gestures and relay that data to associated musical features. Mugeetion can translate qualitative data of emotional states into quantitative data, which can be utilized in the sound generation process. We also presented and tested this work in the exhibition of sound installation, Hearing Seascape, using the audiences' facial expressions. Audiences heard changes in the background sound based on their emotional state. The process contributes multiple research areas, such as gesture tracking systems, emotion-sound modeling, and the connection between sound and facial gesture.
RAZE: Region Guided Self-Supervised Gaze Representation Learning
Aug 05, 2022
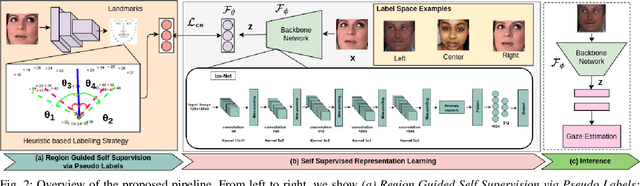


Automatic eye gaze estimation is an important problem in vision based assistive technology with use cases in different emerging topics such as augmented reality, virtual reality and human-computer interaction. Over the past few years, there has been an increasing interest in unsupervised and self-supervised learning paradigms as it overcomes the requirement of large scale annotated data. In this paper, we propose RAZE, a Region guided self-supervised gAZE representation learning framework which leverage from non-annotated facial image data. RAZE learns gaze representation via auxiliary supervision i.e. pseudo-gaze zone classification where the objective is to classify visual field into different gaze zones (i.e. left, right and center) by leveraging the relative position of pupil-centers. Thus, we automatically annotate pseudo gaze zone labels of 154K web-crawled images and learn feature representations via `Ize-Net' framework. `Ize-Net' is a capsule layer based CNN architecture which can efficiently capture rich eye representation. The discriminative behaviour of the feature representation is evaluated on four benchmark datasets: CAVE, TabletGaze, MPII and RT-GENE. Additionally, we evaluate the generalizability of the proposed network on two other downstream task (i.e. driver gaze estimation and visual attention estimation) which demonstrate the effectiveness of the learnt eye gaze representation.
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 05, 2022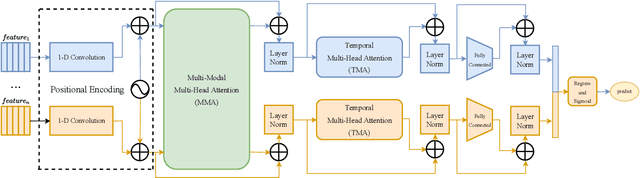
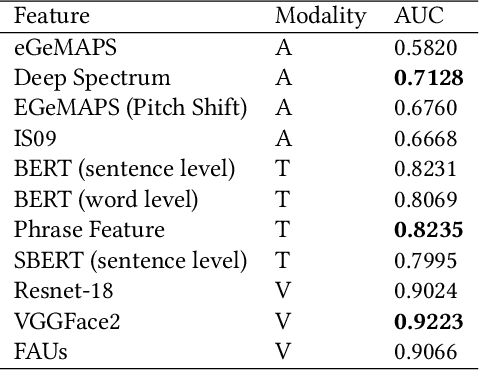
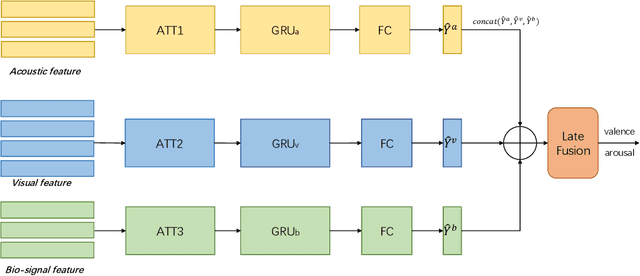
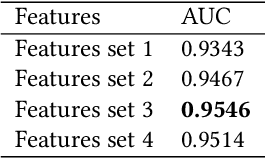
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilising different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability for multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model form learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.
Video Manipulations Beyond Faces: A Dataset with Human-Machine Analysis
Jul 27, 2022


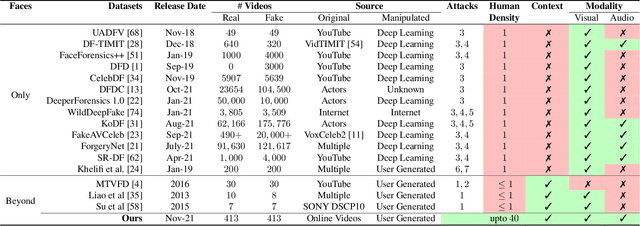
As tools for content editing mature, and artificial intelligence (AI) based algorithms for synthesizing media grow, the presence of manipulated content across online media is increasing. This phenomenon causes the spread of misinformation, creating a greater need to distinguish between "real" and "manipulated" content. To this end, we present VideoSham, a dataset consisting of 826 videos (413 real and 413 manipulated). Many of the existing deepfake datasets focus exclusively on two types of facial manipulations -- swapping with a different subject's face or altering the existing face. VideoSham, on the other hand, contains more diverse, context-rich, and human-centric, high-resolution videos manipulated using a combination of 6 different spatial and temporal attacks. Our analysis shows that state-of-the-art manipulation detection algorithms only work for a few specific attacks and do not scale well on VideoSham. We performed a user study on Amazon Mechanical Turk with 1200 participants to understand if they can differentiate between the real and manipulated videos in VideoSham. Finally, we dig deeper into the strengths and weaknesses of performances by humans and SOTA-algorithms to identify gaps that need to be filled with better AI algorithms.
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 11, 2019

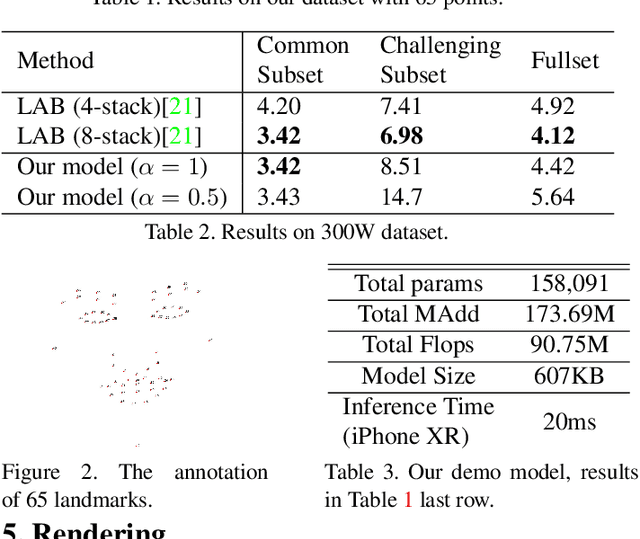
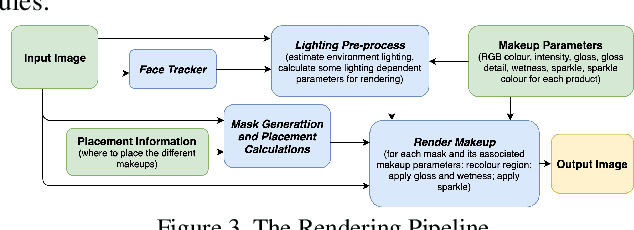
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. More results and demo are in our project page: http://research.modiface.com/makeup-try-on-cvprw2019/
HIME: Efficient Headshot Image Super-Resolution with Multiple Exemplars
Mar 28, 2022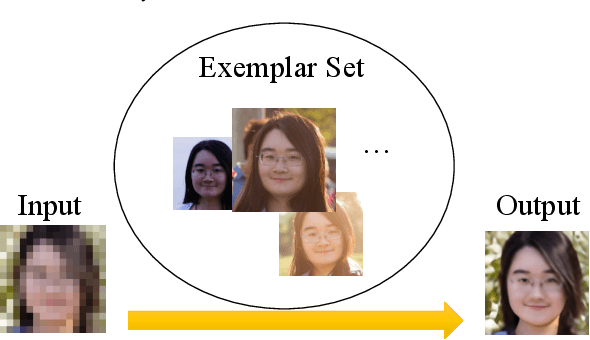
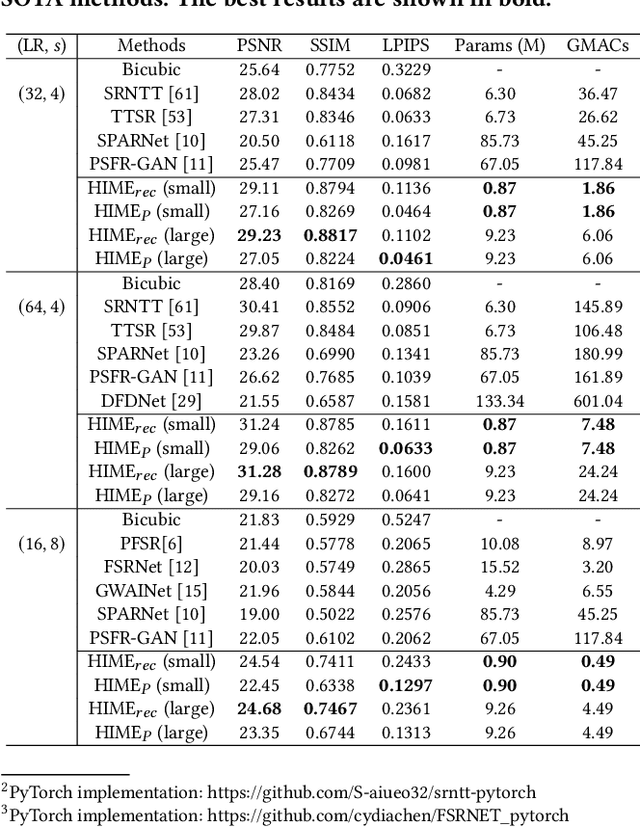
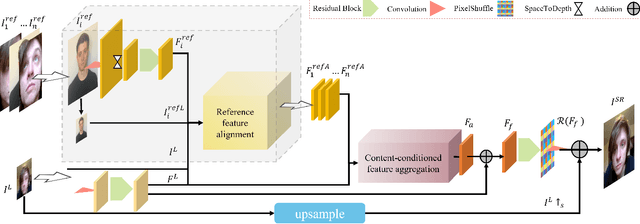
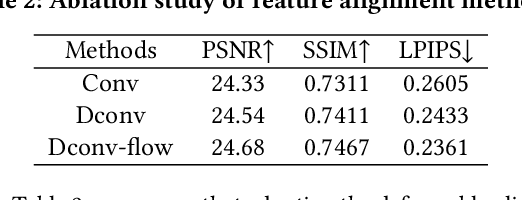
A promising direction for recovering the lost information in low-resolution headshot images is utilizing a set of high-resolution exemplars from the same identity. Complementary images in the reference set can improve the generated headshot quality across many different views and poses. However, it is challenging to make the best use of multiple exemplars: the quality and alignment of each exemplar cannot be guaranteed. Using low-quality and mismatched images as references will impair the output results. To overcome these issues, we propose an efficient Headshot Image Super-Resolution with Multiple Exemplars network (HIME) method. Compared with previous methods, our network can effectively handle the misalignment between the input and the reference without requiring facial priors and learn the aggregated reference set representation in an end-to-end manner. Furthermore, to reconstruct more detailed facial features, we propose a correlation loss that provides a rich representation of the local texture in a controllable spatial range. Experimental results demonstrate that the proposed framework not only has significantly fewer computation cost than recent exemplar-guided methods but also achieves better qualitative and quantitative performance.
Masked Faces with Faced Masks
Jan 17, 2022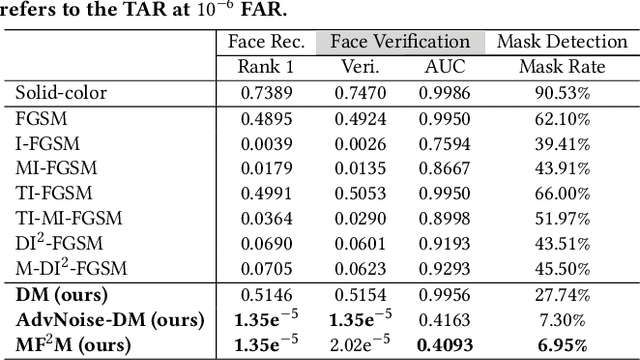
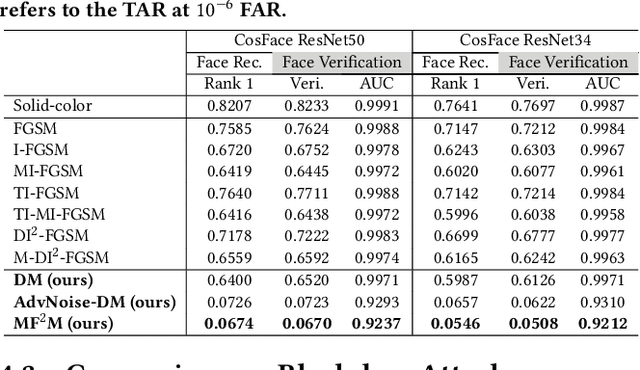
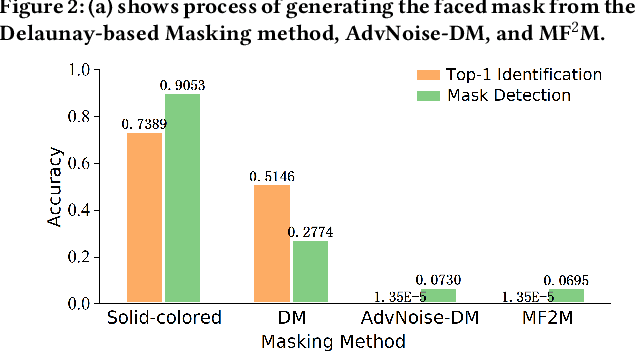
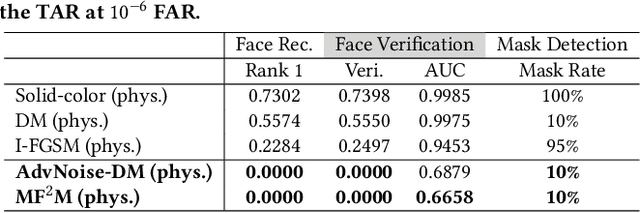
Modern face recognition systems (FRS) still fall short when the subjects are wearing facial masks, a common theme in the age of respiratory pandemics. An intuitive partial remedy is to add a mask detector to flag any masked faces so that the FRS can act accordingly for those low-confidence masked faces. In this work, we set out to investigate the potential vulnerability of such FRS, equipped with a mask detector, on large-scale masked faces. As existing face recognizers and mask detectors have high performance in their respective tasks, it is a challenge to simultaneously fool them and preserve the transferability of the attack. To this end, we devise realistic facial masks that exhibit partial face patterns (i.e., faced masks) and stealthily add adversarial textures that can not only lead to significant performance deterioration of the SOTA deep learning-based FRS, but also remain undetected by the SOTA facial mask detector, thus successfully fooling both systems at the same time. The proposed method unveils the vulnerability of the FRS when dealing with masked faces wearing faced masks.
Graph-based Generative Face Anonymisation with Pose Preservation
Dec 10, 2021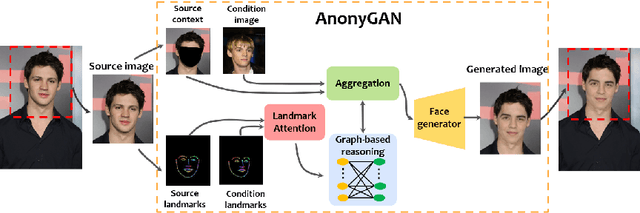
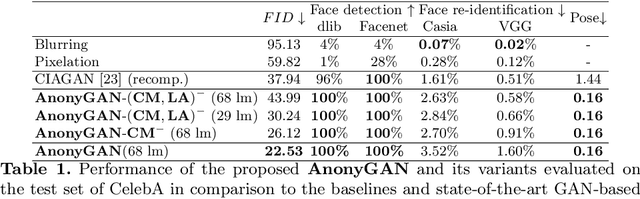
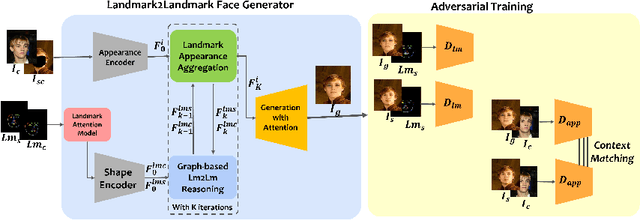
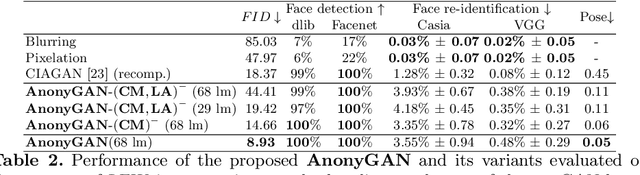
We propose AnonyGAN, a GAN-based solution for face anonymisation which replaces the visual information corresponding to a source identity with a condition identity provided as any single image. With the goal to maintain the geometric attributes of the source face, i.e., the facial pose and expression, and to promote more natural face generation, we propose to exploit a Bipartite Graph to explicitly model the relations between the facial landmarks of the source identity and the ones of the condition identity through a deep model. We further propose a landmark attention model to relax the manual selection of facial landmarks, allowing the network to weight the landmarks for the best visual naturalness and pose preservation. Finally, to facilitate the appearance learning, we propose a hybrid training strategy to address the challenge caused by the lack of direct pixel-level supervision. We evaluate our method and its variants on two public datasets, CelebA and LFW, in terms of visual naturalness, facial pose preservation and of its impacts on face detection and re-identification. We prove that AnonyGAN significantly outperforms the state-of-the-art methods in terms of visual naturalness, face detection and pose preservation.
Multi-task Learning of Cascaded CNN for Facial Attribute Classification
May 03, 2018
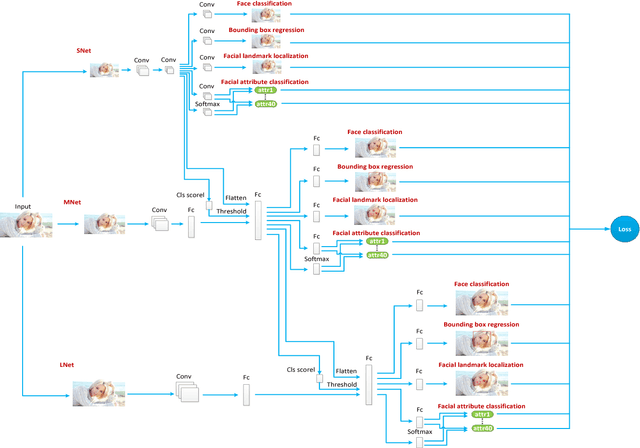
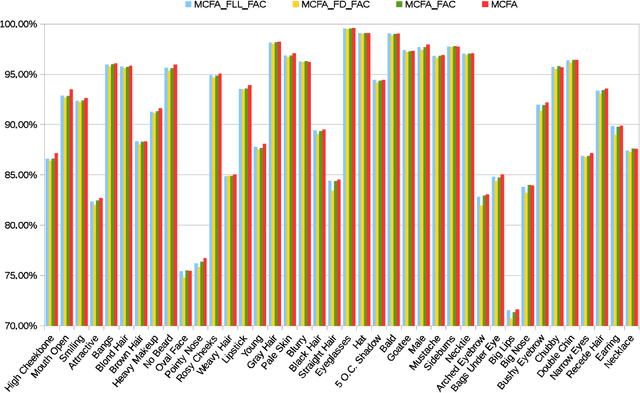

Recently, facial attribute classification (FAC) has attracted significant attention in the computer vision community. Great progress has been made along with the availability of challenging FAC datasets. However, conventional FAC methods usually firstly pre-process the input images (i.e., perform face detection and alignment) and then predict facial attributes. These methods ignore the inherent dependencies among these tasks (i.e., face detection, facial landmark localization and FAC). Moreover, some methods using convolutional neural network are trained based on the fixed loss weights without considering the differences between facial attributes. In order to address the above problems, we propose a novel multi-task learning of cas- caded convolutional neural network method, termed MCFA, for predicting multiple facial attributes simultaneously. Specifically, the proposed method takes advantage of three cascaded sub-networks (i.e., S_Net, M_Net and L_Net corresponding to the neural networks under different scales) to jointly train multiple tasks in a coarse-to-fine manner, which can achieve end-to-end optimization. Furthermore, the proposed method automatically assigns the loss weight to each facial attribute based on a novel dynamic weighting scheme, thus making the proposed method concentrate on predicting the more difficult facial attributes. Experimental results show that the proposed method outperforms several state-of-the-art FAC methods on the challenging CelebA and LFWA datasets.